
Curso
Diseño de sistemas agénticos con LangChain
3 h
12.1K
Kimi K2.5 es un modelo multimodal de código abierto de Moonshot AI creado para flujos de trabajo de agentes, no solo para chats. En lugar de responder a indicaciones aisladas, puede desglosar tareas complejas, coordinar el uso de herramientas y producir resultados estructurados, como tablas, informes, planes y códigos, en flujos de trabajo de varios pasos.
Lo que hace que Kimi K2.5 sea especialmente interesante es Agent Swarm. Un modo autodirigido en el que el modelo puede activar y coordinar dinámicamente varios subagentes en paralelo para acelerar la investigación, la verificación y la ejecución.
En este tutorial, explicaré qué es Kimi K2.5 y en qué ámbitos funciona bien, y luego me centraré en cuatro experimentos prácticos que muestran cómo se comporta Agent Swarm en la práctica, incluyendo lo que hace de manera impresionante, en qué aspectos se queda corto y cuándo supera realmente a una configuración de un solo agente.
Kimi K2.5 es el modelo multimodal nativo y de código abierto de Moonshot AI, diseñado para gestionar texto, imágenes, vídeo y documentos en un solo sistema. Se extiende Kimi K2 con un preentrenamiento continuo en aproximadamente 15T de tokens mixtos de texto y visuales, y está diseñado para funcionar no solo como un chatbot, sino como un sistema agencial que puede planificar, utilizar herramientas y (en modo enjambre) ejecutar tareas en paralelo.
En la práctica, Kimi K2.5 destaca por tres cosas:
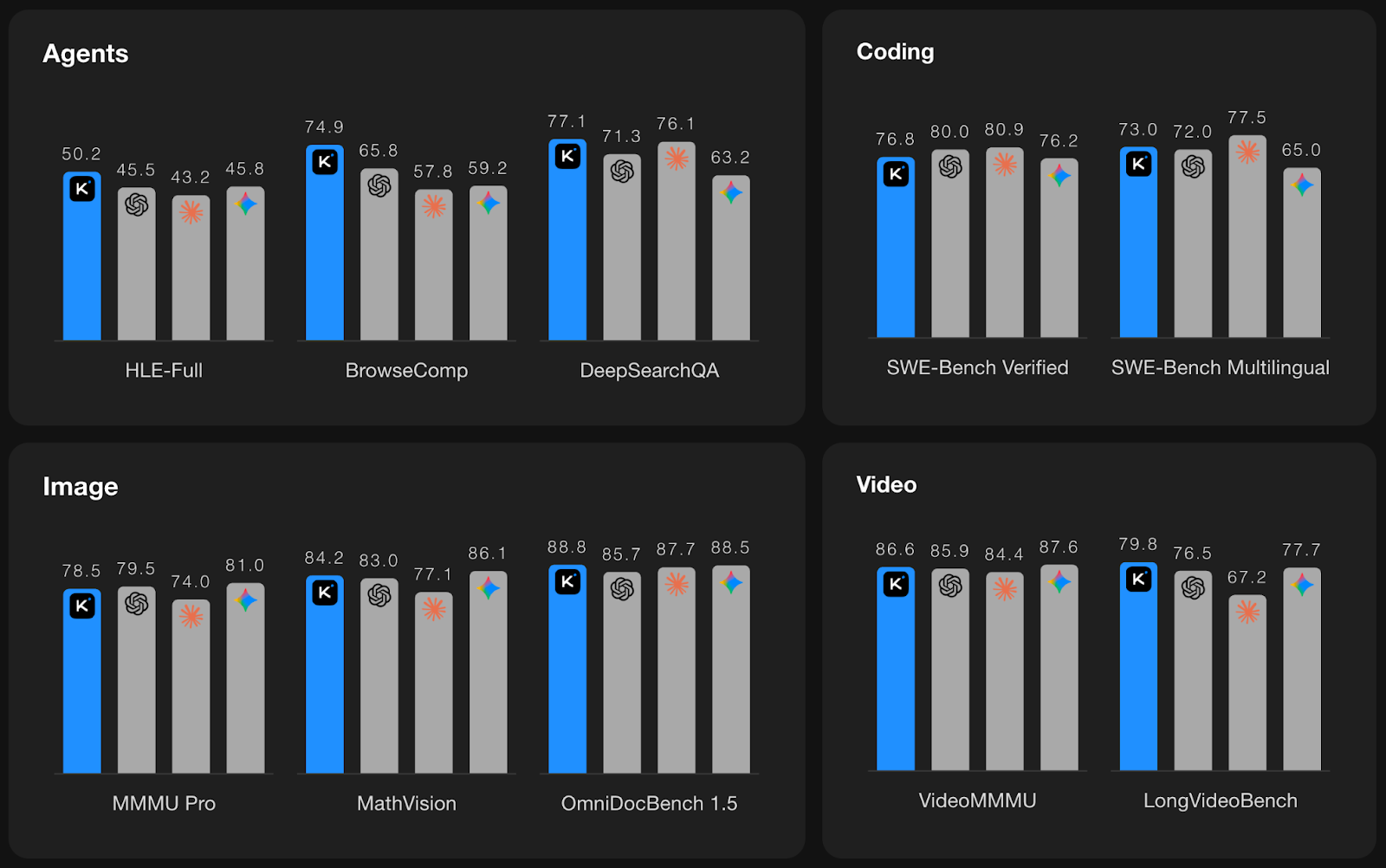
Fuente: Kimi K2.5
Los gráficos anteriores resumen el rendimiento de Kimi K2.5 en cuatro categorías: Agentes, codificación, imagen y vídeo, con Kimi en azul y otros modelos pioneros destacados en barras grises.
Puedes probar Kimi K2.5 de varias maneras:
https://platform.moonshot.aiPara obtener puntos de referencia reproducibles, Moonshot recomienda utilizar la API oficial o proveedores verificados a través de Kimi Vendor Verifier.
La mayoría de las configuraciones multiagente actuales siguen siendo manuales: tú defines las funciones, conectas un flujo de trabajo y esperas que la coordinación se mantenga a medida que las tareas se hacen más grandes. Kimi K2.5 Agent Swarm da la vuelta a ese modelo.
En lugar de predefinir agentes y procesos, K2.5 puede autodirigir un enjambre, decidiendo cuándo paralelizar, cuántos agentes generar, qué herramientas utilizar y cómo fusionar los resultados, basándose en la propia tarea.
Puede crear y coordinar de forma autónoma un enjambre de agentes de hasta 100 subagentes, ejecutando flujos de trabajo paralelos en hasta 1500 llamadas a herramientas, sin roles predefinidos.
En segundo plano, Agent Swarm introduce un coordinador entrenable que aprende a descomponer el trabajo en subtareas paralelas y a programarlas de manera eficiente:
El comportamiento gregario de Kimi K2.5 se entrena mediante el aprendizaje por refuerzo con agentes paralelos (PARL), una configuración de entrenamiento que convierte el paralelismo en sí mismo en una habilidad que se puede aprender. Esto es importante porque los sistemas multiagente ingenuos suelen fallar de dos maneras:
PARL aborda este problema configurando las recompensas durante el entrenamiento. Fomenta el paralelismo desde el principio y cambia gradualmente la optimización hacia la calidad de las tareas de principio a fin, evitando el paralelismo falso. Para que la optimización tenga en cuenta la latencia, K2.5 evalúa el rendimiento utilizando pasos críticos, ya que generar más agentes solo ayuda si realmente acorta la ruta de ejecución más lenta, en lugar de aumentar la sobrecarga de coordinación.
Cuando la tarea es amplia y requiere muchas herramientas, Agent Swarm puede reducir considerablemente el tiempo necesario para obtener resultados. Moonshot informa de que, en comparación con una configuración de un solo agente, K2.5 Swarm puede reducir el tiempo de ejecución entre 3 y 4,5 veces, y las evaluaciones internas muestran una reducción de hasta el 80 % en el tiempo de ejecución de principio a fin en cargas de trabajo complejas gracias a la paralelización real.
En esta sección, compartiré mi experiencia de primera mano probando Kimi K2.5 Agent Swarm en diversos escenarios. Cada ejemplo destaca cómo el enjambre descompone las tareas, asigna agentes y dónde este enfoque realmente ayuda o se queda corto en la práctica.
Para mi primer experimento, probé si Kimi K2.5 Agent Swarm podía abordar una tarea real de alto riesgo, como redactar un plan de implementación para LLM de código abierto.
Indicación:
I want you to research best practices for deploying open-source LLMs in production. Focus on real deployment patterns rather than theory. If possible, have different agents look into, Inference stacks like vLLM, TGI, llama.cpp, Quantization strategies and hardware trade-offs, and cost control techniques. I want a short, structured guide with common architectures, trade-offs, and concrete recommendations for small teams vs large-scale deployments.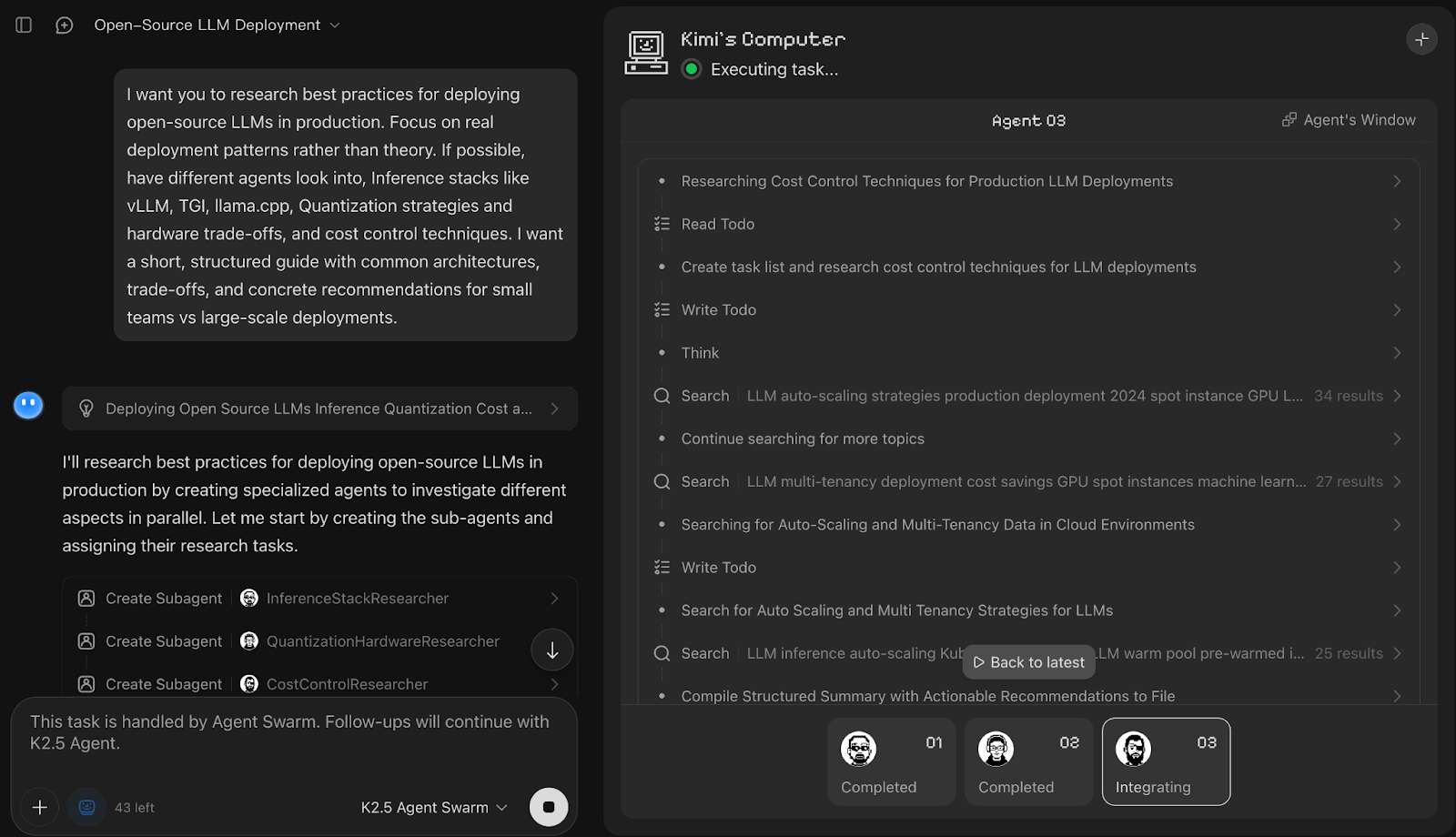
En esta demostración, Kimi K2.5 Agent Swarm descompuso inmediatamente la solicitud en programas de investigación paralelos y activó tres subagentes dedicados, a saber, InferenceStackResearcher, QuantizationHardwareResearcher y CostControlResearcher. Si bien cada nombre de subagente hace referencia al trabajo que se les asignó, luego se distribuyó el trabajo entre múltiples perfiles de trabajadores.
Lo que más me gustó fue que el resultado final fue una tabla comparativa clara de las pilas de inferencia, junto con recomendaciones concisas y notas para la cuantificación. También puedes utilizar la barra de progreso de la tarea para ver cómo se descompuso el trabajo por adelantado y se realizó el seguimiento de cada subtarea hasta su finalización.
A continuación, probé Agent Swarm en una tarea de creación de conjuntos de datos pidiendo a Kimi K2.5 que generara una prueba de referencia de 100 problemas matemáticos con soluciones y etiquetas de dificultad. También solicité explícitamente que utilizases20 agentes para ver hasta qué punto se ajusta a la restricción del tamaño del enjambre sin perder calidad.
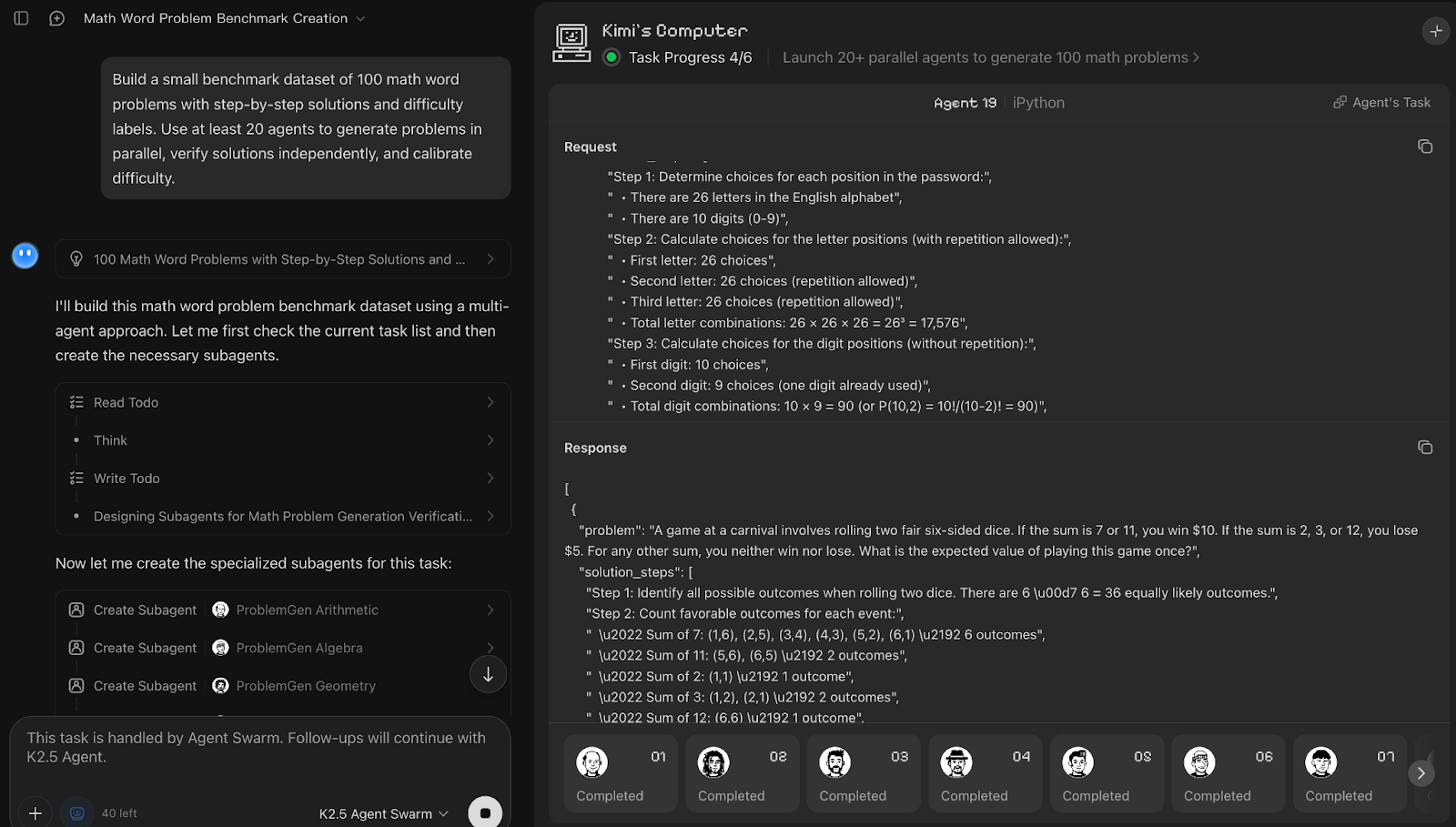
Indicación:
Build a small benchmark dataset of 100 math word problems with step-by-step solutions and difficulty labels. Use at least 20 agents to generate problems in parallel, verify solutions independently, and calibrate difficulty.Kimi K2.5 Agent Swarm trató la creación del conjunto de datos como un proceso en tres fases, que incluía la generación, la verificación y la calibración. Aunque la solicitud pedía al menos 20 agentes, el sistema activó de forma autónoma 25 subagentes, dando prioridad a la corrección sobre el cumplimiento estricto del recuento solicitado. Fue interesante observar que unos cinco agentes trabajaban activamente al mismo tiempo, mientras que otros hacían cola y reanudaban su trabajo una vez completadas las subtareas anteriores, lo que sugiere la existencia de un mecanismo interno de programación.
Cada agente generacional se encargaba de un ámbito matemático distinto y generaba cinco problemas con soluciones paso a paso, tras lo cual se asignaban diez agentes a la verificación y un grupo más reducido de cinco agentes se centraba en la calibración de la dificultad.
A continuación, introduje Kimi K2.5 en un flujo de trabajo multimodal proporcionando varias imágenes de etiquetas nutricionales y solicitando una comparación estructurada. El objetivo era comprobar tu capacidad para extraer, normalizar y verificar datos visuales.
Solicitud:
I’m sharing images of nutrition labels from 7 packaged food items. Analyze them and produce a clear comparison specifically:
Extract fields like: calories, protein, total fat, sugar, sodium, from each label.Normalize all values to a per-100g basis so items are comparableDouble-check numeric consistency (e.g. serving size vs totals)Rank the products from healthiest to least healthy, explaining the reasoningReturn a comparison table with normalized values for all items. Also include a summary highlighting, best high-protein option, the lowest sugar option, and items to avoid and why.
Assume the labels may vary in format and serving size. Resolve ambiguities where possible and note any missing or unclear values.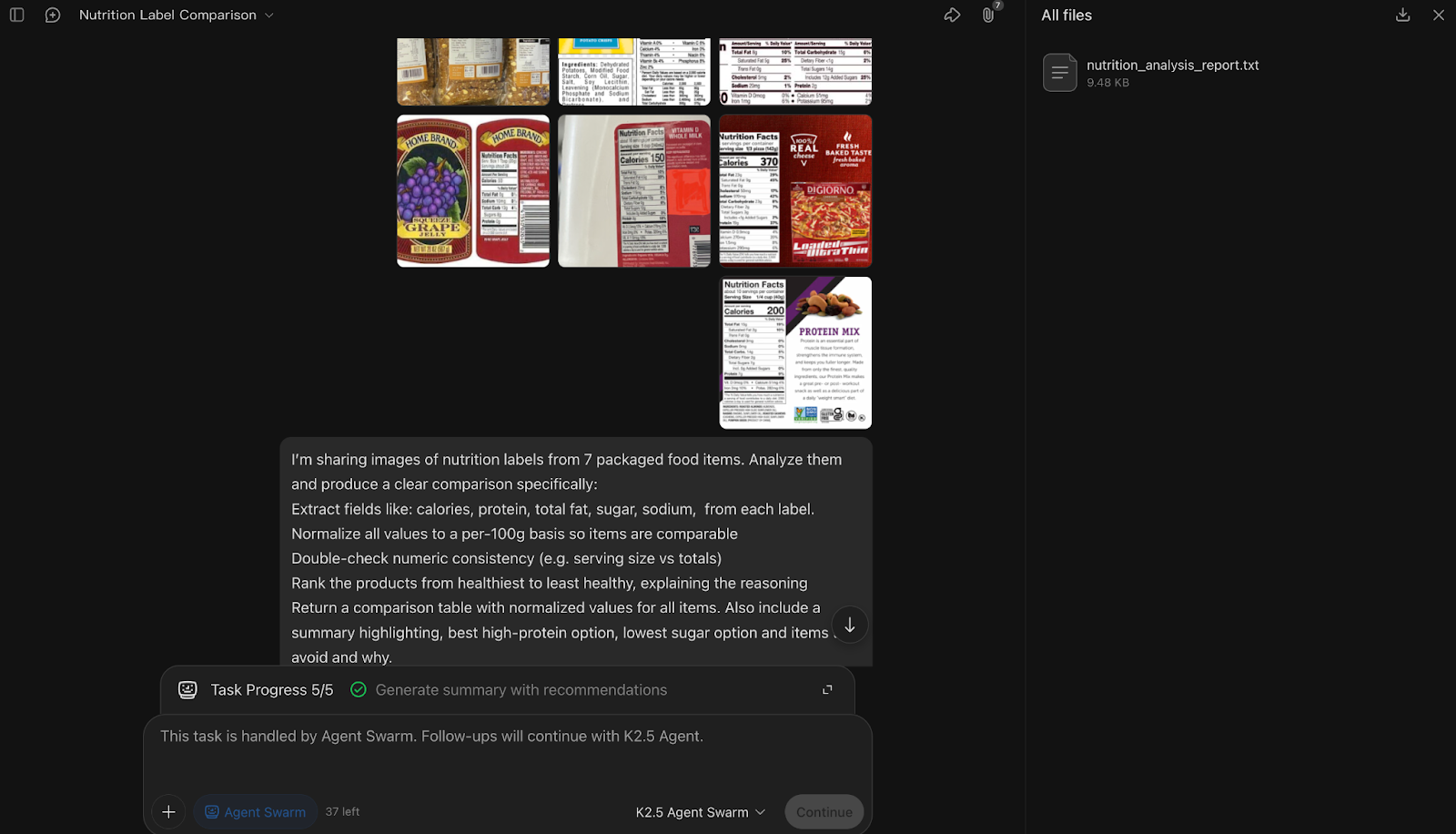
En este experimento multimodal de control de calidad, Kimi K2.5 Agent Swarm descompuso la tarea en torno a una etiqueta por subagente, activando siete subagentes paralelos para extraer campos nutricionales de cada imagen, mientras que un agente coordinador se encargaba de la normalización, la verificación cruzada y la clasificación.
Una cosa interesante de Kimi es que las restricciones que especificas en el prompt (extracción, normalización, verificación, clasificación) se convierten efectivamente en el modelo para la forma en que Kimi instancia y asigna subagentes.
Lo que más me llamó la atención fue cómo el grupo consideró la verificación como un paso importante, es decir, después de la extracción, el coordinador concilió explícitamente los tamaños de las porciones, normalizó los valores y señaló las ambigüedades en lugar de hacer conjeturas en silencio. El paso final de síntesis, en el que se clasificaron los productos y se destacaron las mejores opciones con alto contenido proteico y bajo contenido en azúcar, demostró una sólida lógica de agregación en todas las entradas visuales.
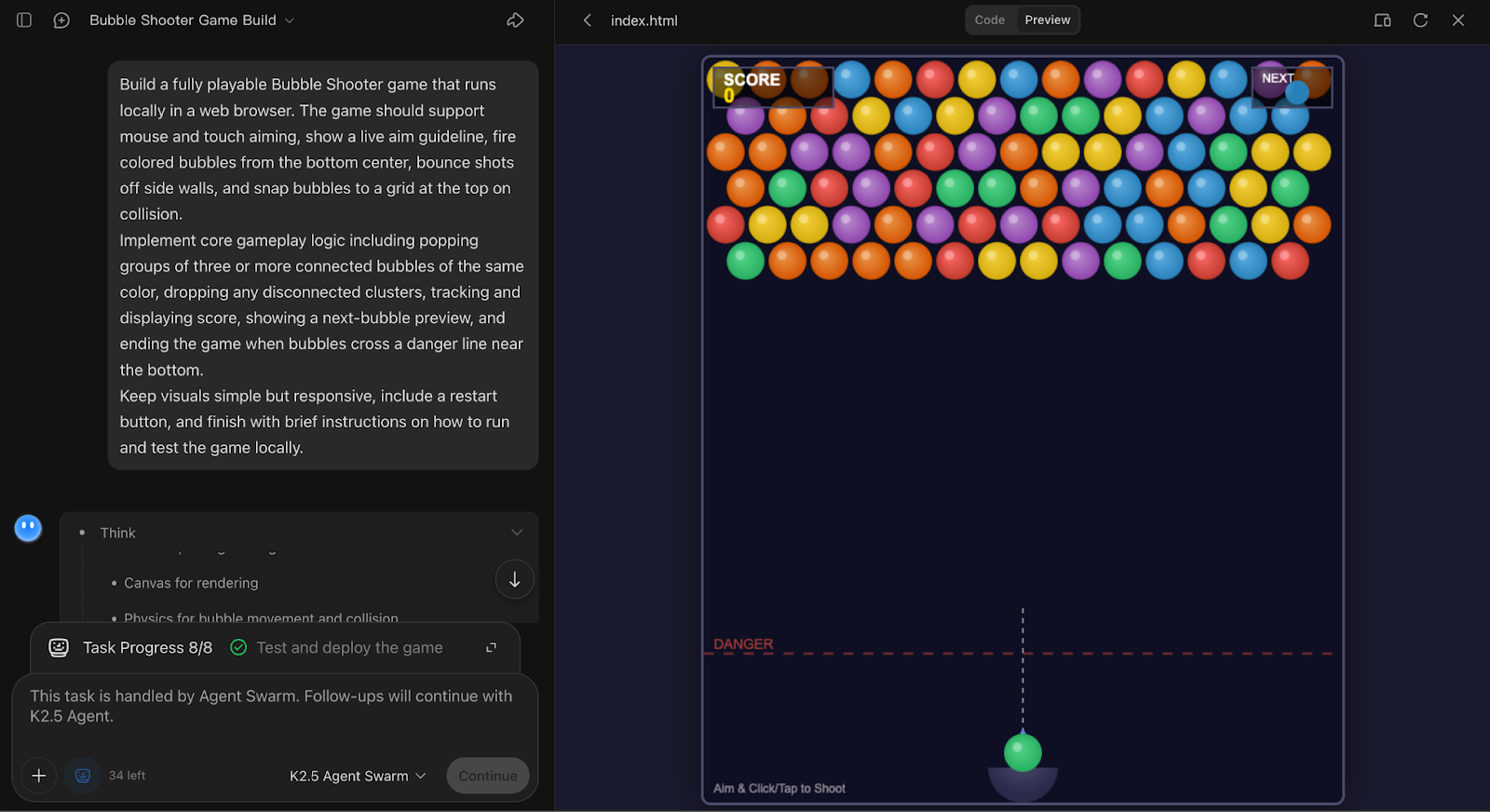
Por último, probé las capacidades de programación de Kimi K2.5 pidiéndole que creara desde cero un juego Bubble Shooter totalmente interactivo. Este experimento destaca cómo el modelo maneja la generación de código con estado de extremo a extremo, donde la coherencia es más importante que el paralelismo.
Indicación:
```markdown
Crea un juego Bubble Shooter totalmente jugable que se ejecute localmente en un navegador web. El juego debe admitir el apuntado con el ratón y táctil, mostrar una guía de apuntado en tiempo real, disparar burbujas de colores desde la parte inferior central, rebotar los disparos en las paredes laterales y fijar las burbujas a una parilla en la parte superior al colisionar.
Implementar la lógica básica del juego, incluyendo hacer estallar grupos de tres o más burbujas conectadas del mismo color, eliminar cualquier grupo desconectado, realizar un seguimiento y mostrar la puntuación, mostrar una vista previa de la siguiente burbuja y finalizar el juego cuando las burbujas crucen una línea de peligro cerca de la parte inferior.
Mantén los elementos visuales sencillos pero receptivos, incluye un botón de reinicio y termina con unas breves instrucciones sobre cómo ejecutar y probar el juego localmente.
```
En este experimento de creación de juegos, Kimi K2.5 Agent Swarm tomó una decisión notablemente conservadora al asignar un solo subagente para gestionar toda la tarea.
Esa decisión en sí misma es una observación interesante, ya que el sistema reconoció correctamente que se trataba de un problema de codificación con estado y estrechamente acoplado, en el que un paralelismo intenso añadiría una sobrecarga de coordinación sin ningún beneficio.
El agente creó una implementación completa y ejecutable localmente de Bubble Shooter con puntería, rebotes en las paredes, ajuste a la cuadrícula, explosión al combinar tres, seguimiento de la puntuación y lógica de reinicio, mostrando tanto la mecánica del juego como el flujo de la interfaz de usuario.
Los mejores cursos de DataCamp
Curso
Curso
Curso
blog
Abid Ali Awan
10 min
Tutorial
Arunn Thevapalan
Tutorial
Arunn Thevapalan
Tutorial
Tutorial
Dimitri Didmanidze
Tutorial
Zoumana Keita



