
Cours
Concevoir des systèmes agentiques avec LangChain
3 h
12.2K
Kimi K2.5 est un modèle multimodal open source développé par Moonshot AI, conçu pour les flux de travail agentifs, et pas seulement pour le chat. Plutôt que de répondre à des demandes isolées, il est capable de décomposer des tâches complexes, de coordonner l'utilisation d'outils et de produire des résultats structurés tels que des tableaux, des rapports, des plans et du code, dans le cadre de workflows en plusieurs étapes.
Ce qui rend Kimi K2.5 particulièrement intéressant, c'est l'Agent Swarm. Un mode autonome dans lequel le modèle peut démarrer et coordonner de manière dynamique plusieurs sous-agents en parallèle afin d'accélérer la recherche, la vérification et l'exécution.
Dans ce tutoriel, je présenterai Kimi K2.5 et ses domaines de prédilection, puis je me concentrerai sur quatre expériences pratiques qui démontrent le comportement d'Agent Swarm dans la réalité, notamment ses performances impressionnantes, ses limites et les cas où il surpasse une configuration à agent unique.
Kimi K2.5 est le modèle open source et nativement multimodal de Moonshot AI, conçu pour traiter du texte, des images, des vidéos et des documents dans un seul système. Il s'étend Kimi K2 avec un pré-entraînement continu sur environ 15T de tokens mixtes textuels et visuels. Il est conçu pour fonctionner non seulement comme un chatbot, mais aussi comme un système agentique capable de planifier, d'utiliser des outils et (en mode essaim) d'exécuter des tâches en parallèle.
Dans la pratique, Kimi K2.5 se distingue par trois caractéristiques :
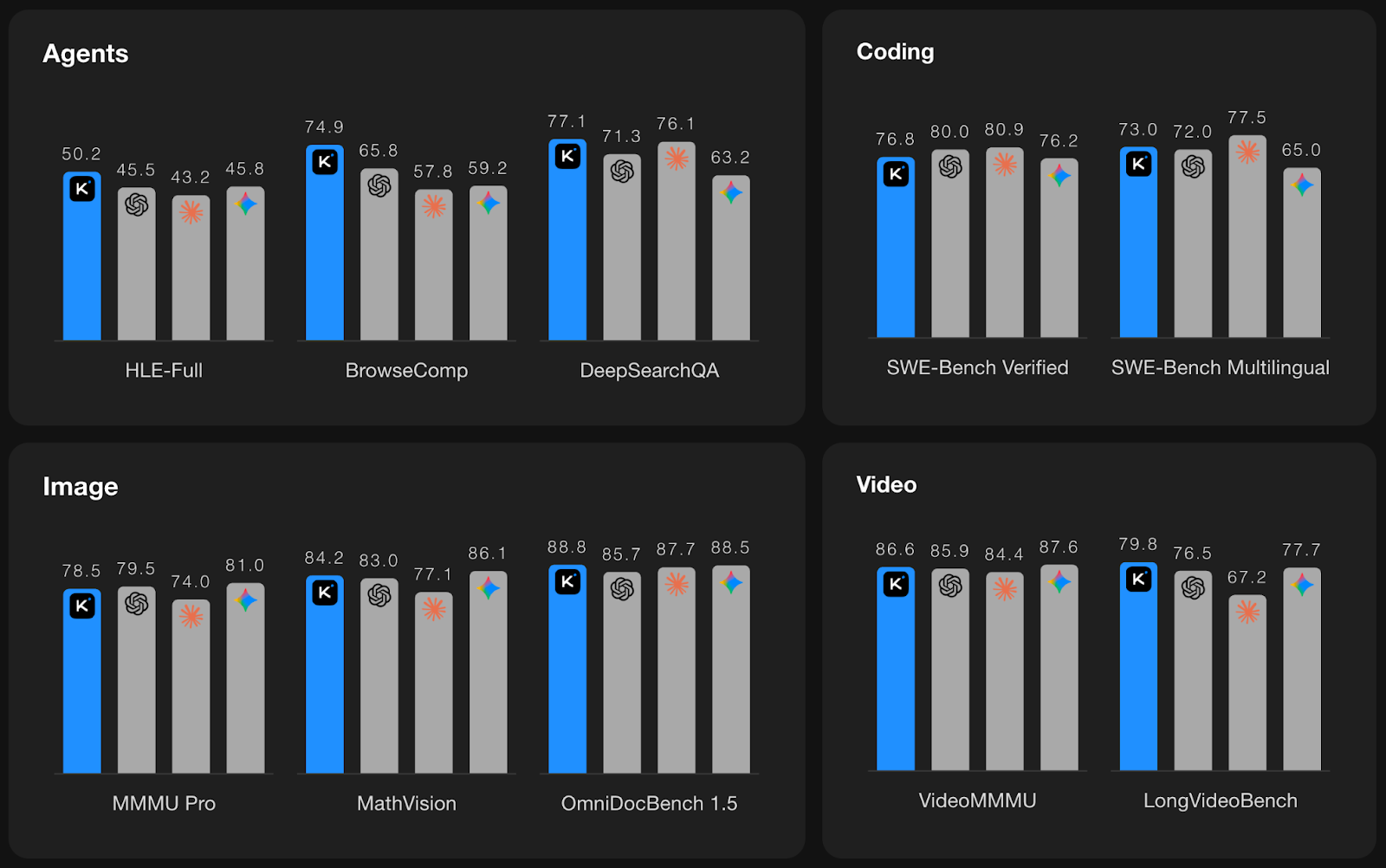
Source : Kimi K2.5
Les graphiques ci-dessus résument les performances de Kimi K2.5 dans quatre catégories : Agents, codage, image et vidéo, avec Kimi représenté en bleu et les autres modèles de pointe représentés par des barres grises.
Vous pouvez essayer Kimi K2.5 de différentes manières :
https://platform.moonshot.aiPour obtenir des benchmarks reproductibles, Moonshot recommande d'utiliser l'API officielle ou des fournisseurs vérifiés via Kimi Vendor Verifier.
La plupart des configurations multi-agents actuelles sont encore élaborées manuellement ; vous définissez les rôles, vous établissez un flux de travail et vous espérez que l'orchestration tiendra le coup à mesure que les tâches deviennent plus importantes. Kimi K2.5 Agent Swarm renverse ce modèle.
Au lieu de prédéfinir les agents et les pipelines, K2.5 est capable de diriger de manière autonome un essaim, en déterminant quand paralléliser, combien d'agents générer, quels outils utiliser et comment fusionner les résultats, en fonction de la tâche elle-même.
Il est capable de créer et de coordonner de manière autonome un essaim d'agents pouvant compter jusqu'à 100 sous-agents, exécutant des flux de travail parallèles sur un maximum de 1 500 appels d'outils, sans rôles prédéfinis.
En arrière-plan, Agent Swarm intègre un orchestrateur entraînable qui apprend à décomposer le travail en sous-tâches parallèles et à les planifier efficacement :
Le comportement grégaire de Kimi K2.5 est entraîné à l'aide de l'apprentissage par renforcement parallèle (PARL), une configuration d'entraînement qui fait du parallélisme lui-même une compétence pouvant être apprise. Ceci est important car les systèmes multi-agents naïfs échouent souvent de deux manières :
PARL aborde cette question en modulant les récompenses tout au long de la formation. Il favorise le parallélisme dès le début et oriente progressivement l'optimisation vers la qualité des tâches de bout en bout, évitant ainsi le faux parallélisme. Afin de rendre l'optimisation sensible à la latence, K2.5 évalue les performances à l'aide de Critical Steps, car la création d'agents supplémentaires n'est utile que si elle permet réellement de raccourcir le chemin d'exécution le plus lent, plutôt que d'augmenter la charge de coordination.
Lorsque la tâche est vaste et nécessite de nombreux outils, Agent Swarm peut réduire considérablement le temps nécessaire à la production. Moonshot indique que, par rapport à une configuration à agent unique, K2.5 Swarm peut réduire le temps d'exécution d'environ 3 à 4,5 fois, et des évaluations internes montrent une réduction pouvant atteindre environ 80 % du temps d'exécution de bout en bout sur des charges de travail complexes grâce à une véritable parallélisation.
Dans cette section, je vais partager mon expérience personnelle après avoir testé Kimi K2.5 Agent Swarm dans divers scénarios. Chaque exemple met en évidence la manière dont l'essaim décompose les tâches, affecte les agents, et montre où cette approche est réellement utile ou présente des lacunes dans la pratique.
Pour ma première expérience, j'ai évalué si Kimi K2.5 Agent Swarm était capable de s'acquitter d'une tâche complexe et concrète, telle que la rédaction d'un plan de déploiement pour des modèles linguistiques open source.
Invite :
I want you to research best practices for deploying open-source LLMs in production. Focus on real deployment patterns rather than theory. If possible, have different agents look into, Inference stacks like vLLM, TGI, llama.cpp, Quantization strategies and hardware trade-offs, and cost control techniques. I want a short, structured guide with common architectures, trade-offs, and concrete recommendations for small teams vs large-scale deployments.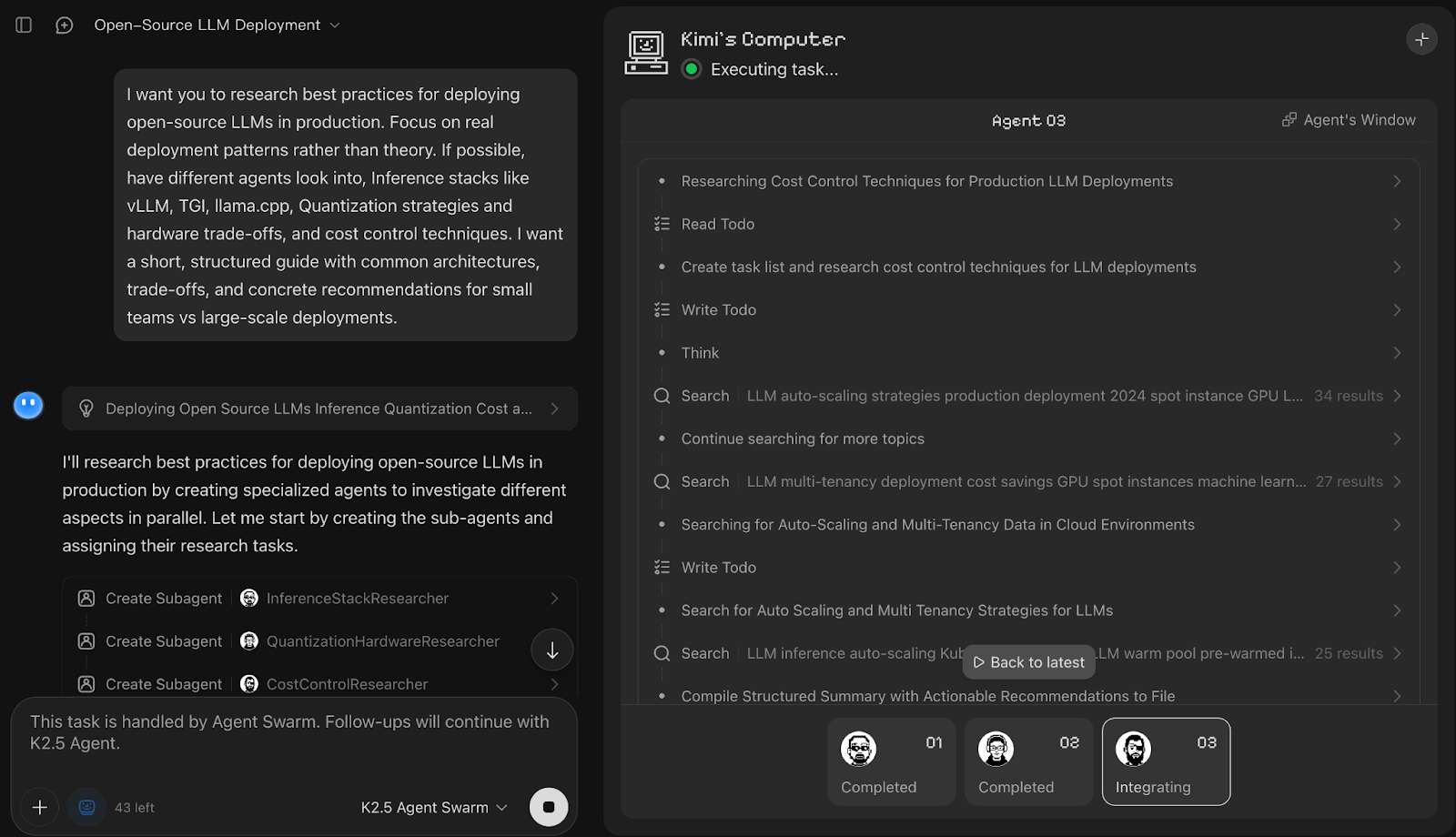
Dans cette démonstration, Kimi K2.5 Agent Swarm a immédiatement décomposé la requête en coursus de recherche parallèles et a lancé trois sous-agents dédiés, à savoir InferenceStackResearcher, QuantizationHardwareResearcher et CostControlResearcher. Bien que chaque nom de sous-agent fasse référence au travail qui lui a été attribué, celui-ci a ensuite été réparti entre plusieurs profils de travailleurs.
Ce qui m'a le plus plu, c'est que le résultat final était un tableau comparatif clair des piles d'inférence, accompagné de recommandations et de remarques concises sur la quantification. Vous pouvez également utiliser la barre de progression des tâches pour visualiser comment le travail a été décomposé dès le départ et suivre chaque sous-tâche jusqu'à son achèvement.
Ensuite, j'ai évalué Agent Swarm dans le cadre d'une tâche de création d'ensemble de données en demandant à Kimi K2.5 de générer un benchmark de 100 problèmes mathématiques avec leurs solutions et leur niveau de difficulté. J'ai également demandé explicitement d'utiliser 20 agents afin d'évaluer dans quelle mesure il respecte la contrainte relative à la taille de l'essaim tout en maintenant la qualité.
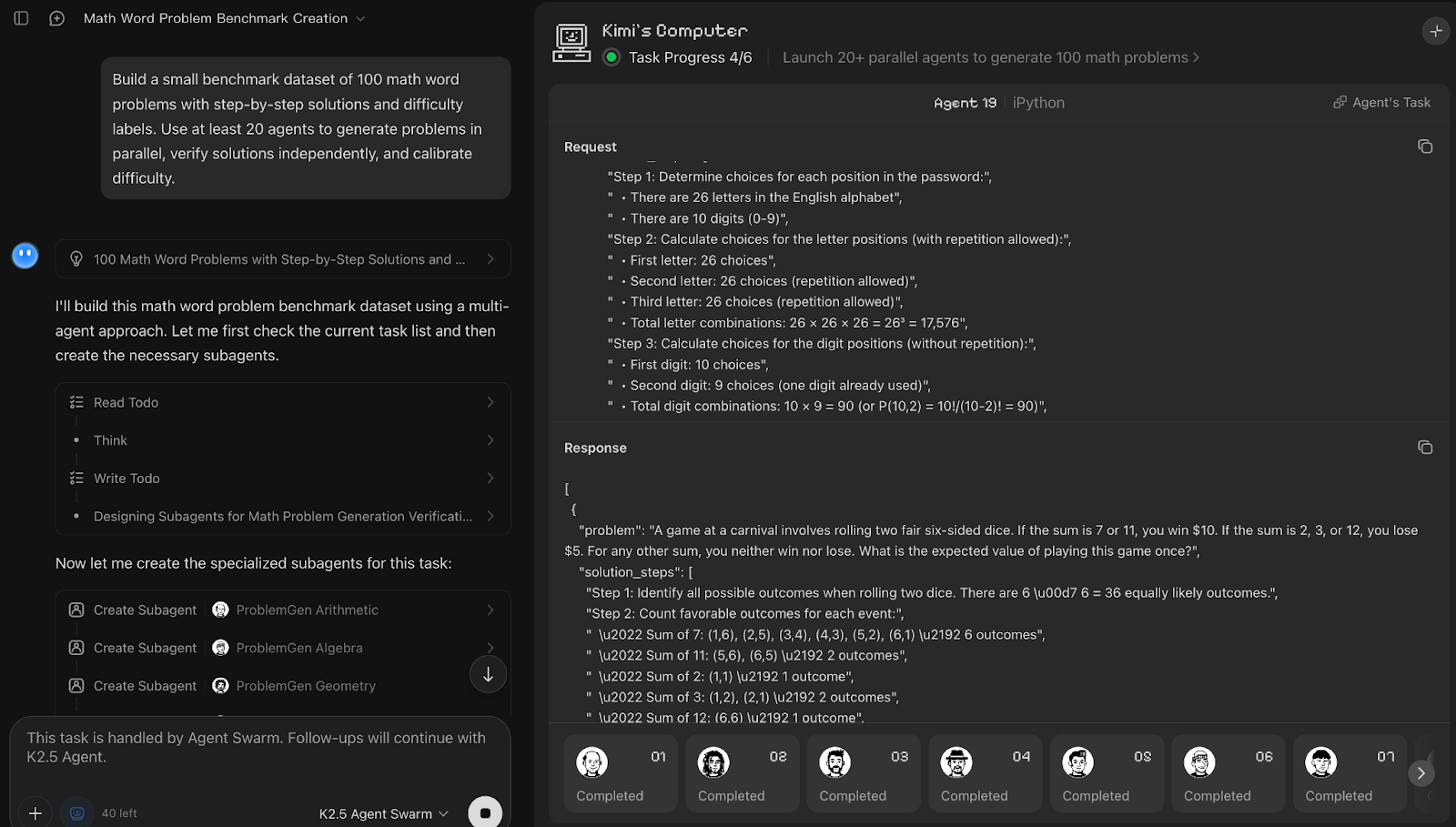
Invite :
Build a small benchmark dataset of 100 math word problems with step-by-step solutions and difficulty labels. Use at least 20 agents to generate problems in parallel, verify solutions independently, and calibrate difficulty.Kimi K2.5 Agent Swarm a traité la création de l'ensemble de données comme un pipeline en trois phases, comprenant la génération, la vérification et l'étalonnage. Bien que l'invite ait demandé au moins 20 agents, le système a généré de manière autonome 25 sous-agents, privilégiant l'exactitude plutôt que le respect strict du nombre demandé. Il était intéressant de constater qu'environ cinq agents travaillaient activement à la fois, tandis que les autres attendaient leur tour et reprenaient leur activité une fois les sous-tâches précédentes terminées, ce qui suggère l'existence d'un mécanisme de planification interne.
Chaque agent générationnel traitait un domaine mathématique distinct et produisait cinq problèmes accompagnés de solutions étape par étape. Par la suite, dix agents ont été affectés à la vérification, tandis qu'un groupe plus restreint de cinq agents s'est concentré sur l'ajustement du niveau de difficulté.
Ensuite, j'ai intégré Kimi K2.5 dans un flux de travail multimodal en fournissant plusieurs images d'étiquettes nutritionnelles et en demandant une comparaison structurée. L'objectif était d'évaluer sa capacité à extraire, normaliser et vérifier des données visuelles.
Invite:
I’m sharing images of nutrition labels from 7 packaged food items. Analyze them and produce a clear comparison specifically:
Extract fields like: calories, protein, total fat, sugar, sodium, from each label.Normalize all values to a per-100g basis so items are comparableDouble-check numeric consistency (e.g. serving size vs totals)Rank the products from healthiest to least healthy, explaining the reasoningReturn a comparison table with normalized values for all items. Also include a summary highlighting, best high-protein option, the lowest sugar option, and items to avoid and why.
Assume the labels may vary in format and serving size. Resolve ambiguities where possible and note any missing or unclear values.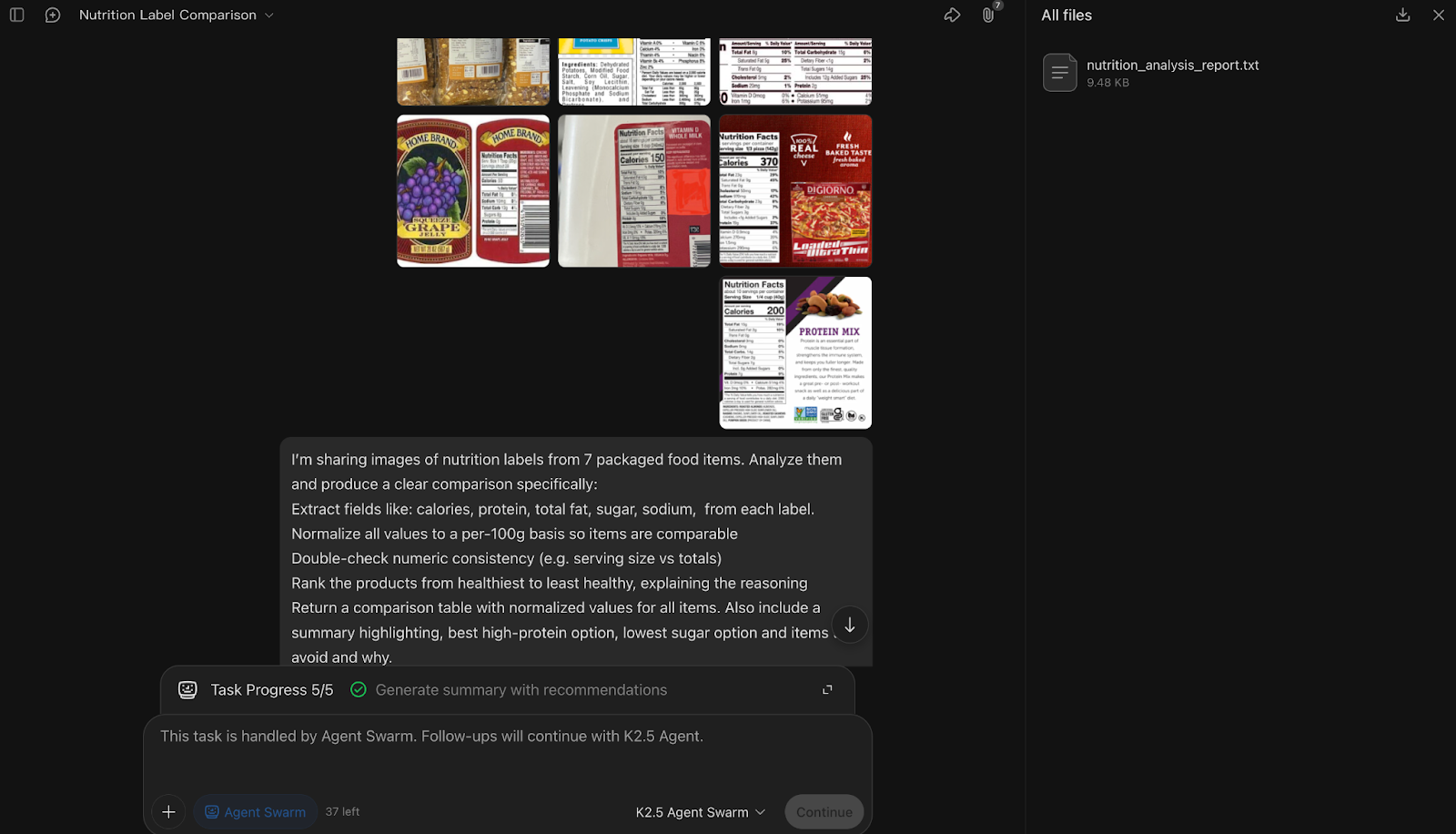
Dans cette expérience d'assurance qualité multimodale, Kimi K2.5 Agent Swarm a décomposé la tâche en attribuant environ une étiquette par sous-agent, lançant sept sous-agents parallèles pour extraire les champs nutritionnels de chaque image, tandis qu'un agent de coordination se chargeait de la normalisation, de la vérification croisée et du classement.
Une caractéristique intéressante de Kimi est que les contraintes que vous spécifiez dans l'invite (extraction, normalisation, vérification, classement) deviennent effectivement le modèle selon lequel Kimi instancie et attribue des sous-agents.
Ce qui m'a particulièrement marqué, c'est la manière dont le groupe a considéré la vérification comme une étape importante. En effet, après l'extraction, l'orchestrateur a explicitement harmonisé les tailles des portions, normalisé les valeurs et signalé les ambiguïtés au lieu de se contenter de faire des suppositions. La dernière étape de synthèse, qui a classé les produits et mis en avant les meilleures options riches en protéines et pauvres en sucre, a démontré une logique d'agrégation solide à travers les entrées visuelles.
Enfin, j'ai évalué les capacités de codage de Kimi K2.5 en lui demandant de créer un jeu Bubble Shooter entièrement interactif à partir de zéro. Cette expérience met en évidence la manière dont le modèle gère la génération de code de bout en bout avec état, où la cohérence est plus importante que le parallélisme.
Invite :
```markdown
Développez un jeu Bubble Shooter entièrement jouable qui s'exécute localement dans un navigateur Web. Le jeu devrait prendre en charge la visée à la souris et au toucher, afficher un guide de visée en temps réel, tirer des bulles colorées depuis le centre inférieur, faire rebondir les tirs sur les parois latérales et faire coller les bulles à une grille en haut lors de la collision.
Mettre en œuvre la logique de jeu principale, notamment faire éclater des groupes de trois bulles ou plus de la même couleur reliées entre elles, faire tomber les grappes non reliées, suivre et afficher le score, afficher un aperçu de la bulle suivante et terminer le jeu lorsque les bulles franchissent une ligne de danger près du bas.
Veuillez garder les éléments visuels simples mais réactifs, inclure un bouton de redémarrage et terminer par de brèves instructions sur la manière d'exécuter et de tester le jeu localement.
```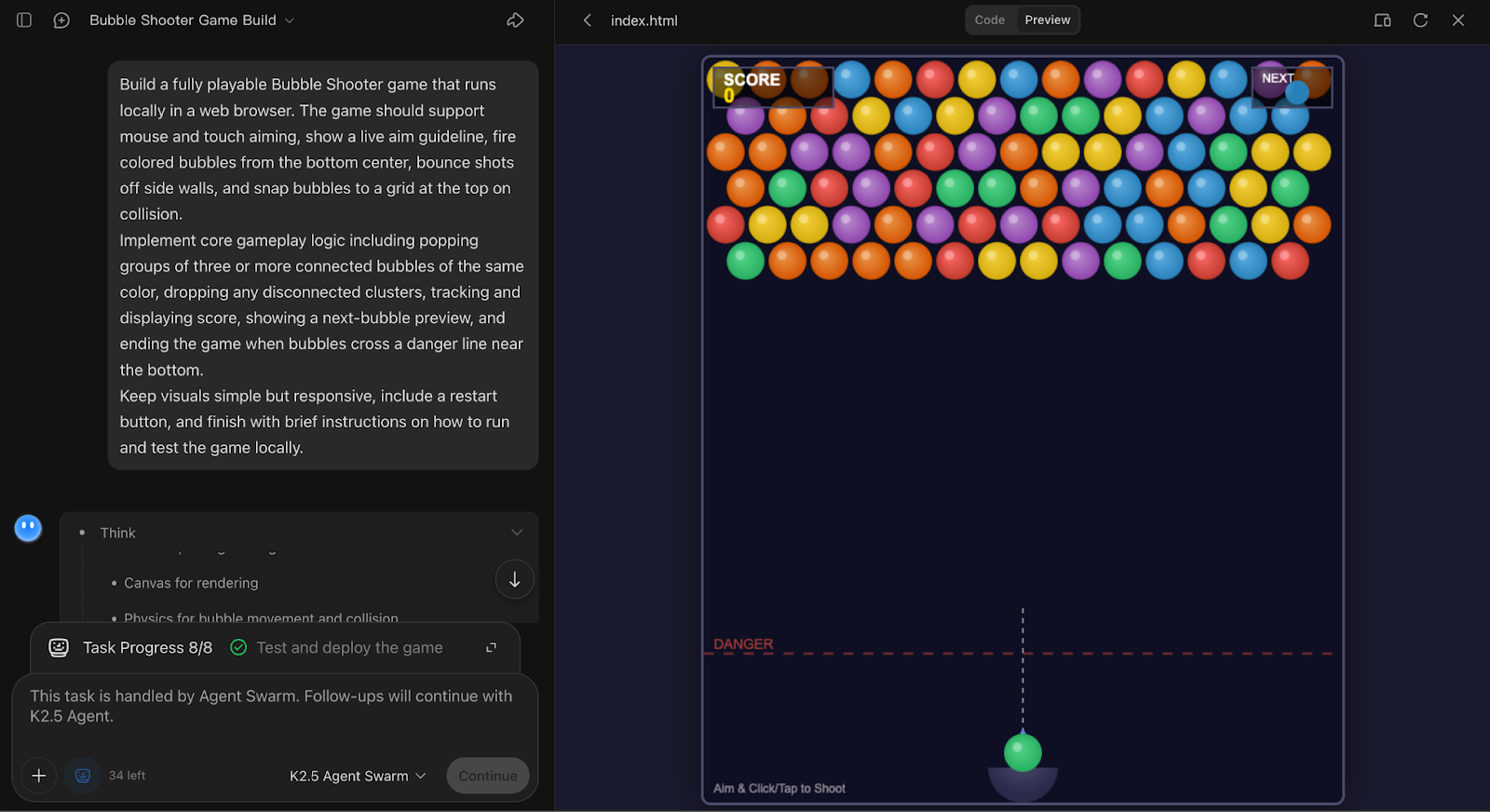
Dans cette expérience de création de jeu, Kimi K2.5 Agent Swarm a fait un choix particulièrement prudent en n'affectant qu'un seul sous-agent à la gestion de l'ensemble de la tâche.
Cette décision est en soi une observation intéressante, car le système a correctement identifié qu'il s'agissait d'un problème de codage étroitement couplé et avec état, où un parallélisme intensif ajouterait une surcharge de coordination sans aucun avantage.
L'agent a produit une implémentation complète et exécutable localement de Bubble Shooter avec visée, rebonds sur les murs, alignement sur la grille, éclatement par trois, suivi des scores et logique de redémarrage, illustrant à la fois les mécanismes de jeu et le flux de l'interface utilisateur.
Meilleurs cours DataCamp
Cours
Cours
Cours
blog
blog
Kurtis Pykes
9 min
blog
Lynn Heidmann
Tutoriel
Tutoriel
Mark Pedigo

