
Kurs
Agentische Systeme mit LangChain entwerfen
3 Std.
12.1K
Kimi K2.5 ist ein Open-Source-Modell von Moonshot AI, das für verschiedene Aufgaben entwickelt wurde, nicht nur für Chats. Anstatt auf einzelne Eingaben zu reagieren, kann es komplexe Aufgaben aufteilen, den Einsatz von Tools koordinieren und strukturierte Ergebnisse wie Tabellen, Berichte, Pläne und Codes über mehrstufige Arbeitsabläufe hinweg erstellen.
Was Kimi K2.5 so interessant macht, ist Agent Swarm. Ein selbstgesteuerter Modus, in dem das Modell mehrere Unteragenten dynamisch parallel hochfahren und koordinieren kann, um die Recherche, Überprüfung und Ausführung zu beschleunigen.
In diesem Tutorial erkläre ich, was Kimi K2.5 ist und wo es gut funktioniert. Dann zeige ich dir vier praktische Experimente, die zeigen, wie sich Agent Swarm in der Praxis verhält, was es beeindruckend macht, wo es noch nicht so gut ist und wann es tatsächlich besser ist als ein Setup mit nur einem Agenten.
Kimi K2.5 ist das Open-Source-Modell von Moonshot AI, das von Anfang an multimodal ist und so gemacht wurde, dass es Text, Bilder, Videos und Dokumente in einem System verarbeiten kann. Es geht weiter Kimi K2 mit einem fortgesetzten Vortraining auf etwa 15 T gemischten Text- und Bild-Tokens und ist so konzipiert, dass es nicht nur als Chatbot, sondern als agentenbasiertes System funktioniert, das planen, Tools verwenden und (im Schwarmmodus) Aufgaben parallel ausführen kann.
In der Praxis sticht Kimi K2.5 durch drei Sachen hervor:
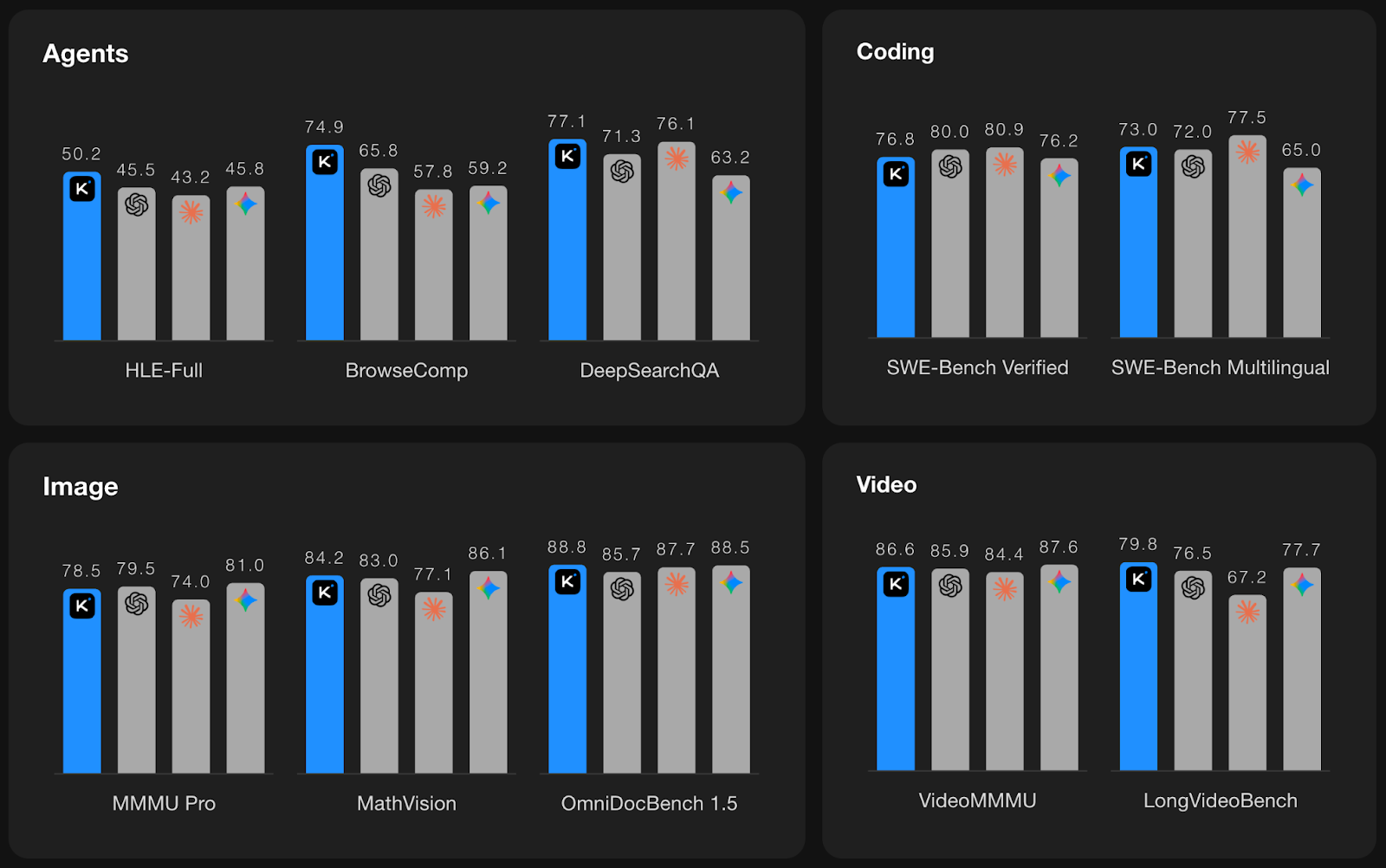
Quelle: Kimi K2.5
Die obigen Diagramme zeigen, wie gut Kimi K2.5 in vier Bereichen abschneidet: Agenten, Codierung, Bild und Video, wobei Kimi blau und andere führende Frontier-Modelle als graue Balken dargestellt sind.
Du kannst Kimi K2.5 auf verschiedene Arten ausprobieren:
https://platform.moonshot.aiFür reproduzierbare Benchmarks empfiehlt Moonshot, die offizielle API oder geprüfte Anbieter über Kimi Vendor Verifier zu nutzen.
Die meisten Multi-Agenten-Setups werden heute immer noch von Hand erstellt: Man legt Rollen fest, verknüpft einen Workflow und hofft, dass die Koordination auch bei größeren Aufgaben funktioniert. Kimi K2.5 Agent Swarm dreht dieses Modell um.
Anstatt Agenten und Pipelines vorab festzulegen, kann K2.5 einen Schwarm selbst steuern und je nach Aufgabe entscheiden, wann parallelisiert wird, wie viele Agenten gestartet werden, welche Tools verwendet werden und wie die Ergebnisse zusammengeführt werden.
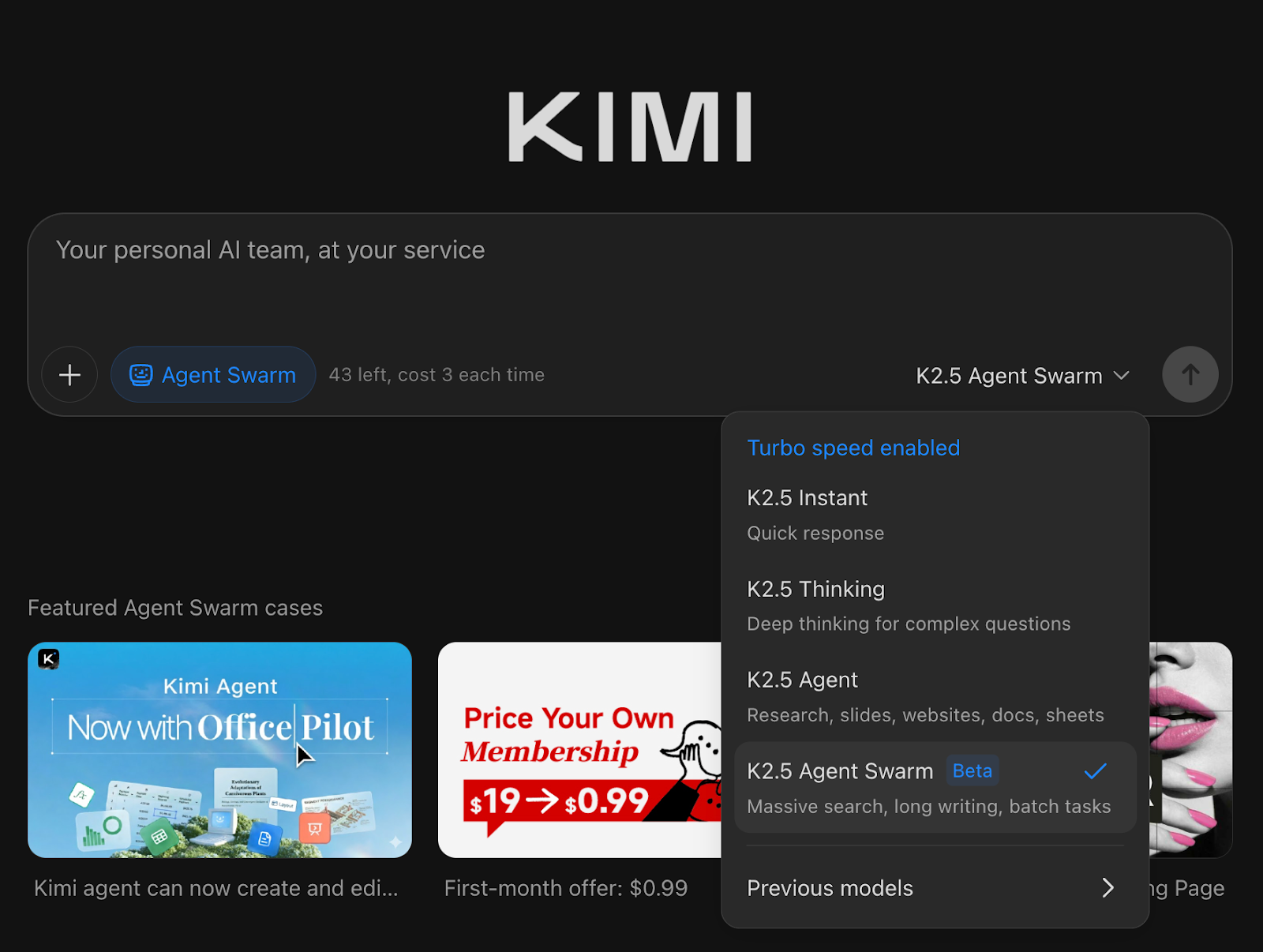
Es kann selbstständig einen Agentenschwarm mit bis zu 100 Unteragenten erstellen und koordinieren und dabei parallele Arbeitsabläufe mit bis zu 1.500 Toolaufrufen ausführen, ohne dass Rollen vorher festgelegt werden müssen.
Agent Swarm hat einen trainierbaren Orchestrator eingebaut, der lernt, Aufgaben in parallele Teilaufgaben aufzuteilen und sie effizient zu planen:
Das Schwarmverhalten von Kimi K2.5 wird mit Parallel-Agent Reinforcement Learning trainiert (PARL) trainiert, einem Trainingssetup, das Parallelität selbst zu einer erlernbaren Fähigkeit macht. Das ist wichtig, weil einfache Multi-Agenten-Systeme oft in zweierlei Hinsicht versagen:
PARL geht das an, indem es Belohnungen während des Trainings gestaltet. Es fördert frühzeitig Parallelität und verlagert die Optimierung nach und nach auf die End-to-End-Aufgabenqualität, wodurch falsche Parallelität vermieden wird. Damit die Optimierung die Latenz berücksichtigt, checkt K2.5 die Leistung mit Critical Steps, weil das Erzeugen von mehr Agenten nur dann hilft, wenn es den langsamsten Ausführungspfad tatsächlich verkürzt und nicht den Koordinationsaufwand erhöht.
Wenn die Aufgabe umfangreich und mit vielen Tools verbunden ist, kann Agent Swarm die Zeit bis zur Fertigstellung echt verkürzen. Moonshot sagt, dass K2.5 Swarm im Vergleich zu einem Einzelsystem die Ausführungszeit um das 3- bis 4,5-fache verkürzen kann. Interne Tests zeigen, dass die Gesamtlaufzeit bei komplexen Aufgaben durch echte Parallelisierung um bis zu 80 % reduziert werden kann.
In diesem Abschnitt erzähle ich euch von meinen Erfahrungen beim Testen von Kimi K2.5 Agent Swarm in verschiedenen Szenarien. Jedes Beispiel zeigt, wie der Schwarm Aufgaben aufteilt, Agenten zuweist und wo dieser Ansatz in der Praxis wirklich hilft oder nicht so gut funktioniert.
In meinem ersten Versuch habe ich getestet, ob Kimi K2.5 Agent Swarm eine anspruchsvolle, reale Aufgabe wie die Erstellung eines Einsatzplans für Open-Source-LLMs bewältigen kann.
Prompt:
I want you to research best practices for deploying open-source LLMs in production. Focus on real deployment patterns rather than theory. If possible, have different agents look into, Inference stacks like vLLM, TGI, llama.cpp, Quantization strategies and hardware trade-offs, and cost control techniques. I want a short, structured guide with common architectures, trade-offs, and concrete recommendations for small teams vs large-scale deployments.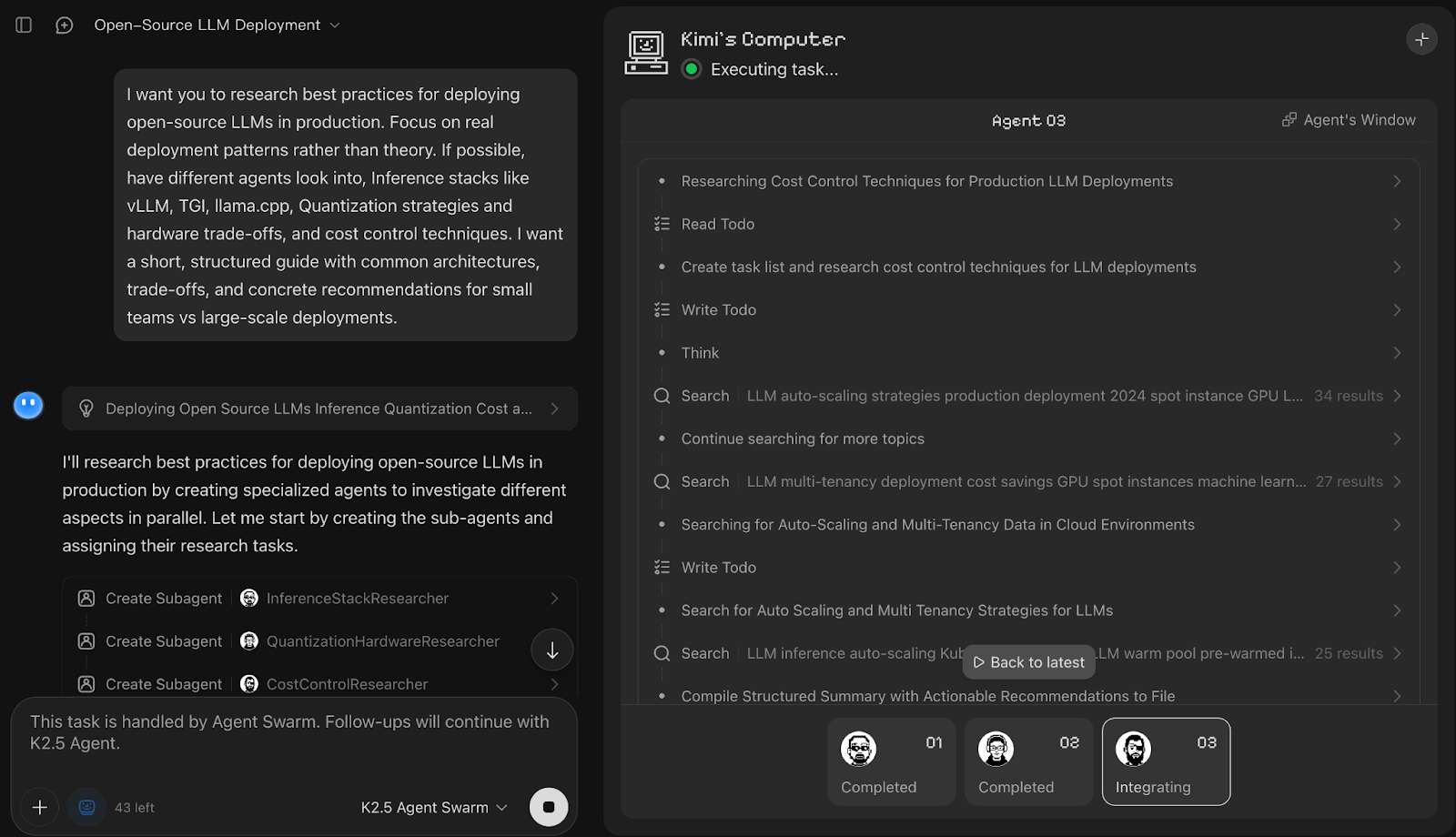
In dieser Demo hat Kimi K2.5 Agent Swarm die Eingabe sofort in parallele Lernpfade zerlegt und drei spezielle Unteragenten gestartet, nämlich InferenceStackResearcher, QuantizationHardwareResearcher und CostControlResearcher. Jeder Subagent-Name steht für die Arbeit, die ihm zugeteilt wurde, und diese wurde dann auf mehrere Mitarbeiter verteilt.
Am besten hat mir gefallen, dass das Endergebnis eine übersichtliche Vergleichstabelle für Inferenzstapel war, zusammen mit knappen Empfehlungen und Hinweisen zur Quantisierung. Du kannst auch die Aufgabenfortschrittsanzeige nutzen, um zu sehen, wie die Arbeit im Voraus aufgeteilt und jede Teilaufgabe bis zur Fertigstellung verfolgt wurde.
Als Nächstes habe ich Agent Swarm bei einer Aufgabe zum Aufbau von Datensätzen getestet, indem ich Kimi K2.5 gebeten habe, einen Benchmark mit 100 mathematischen Textaufgaben mit Lösungen und Schwierigkeitsstufen zu erstellen. Ich hab auch extra gesagt, dass es20 Agenten von nutzen soll, um zu sehen, wie gut es die Schwarmgrößenbeschränkung einhält und dabei die Qualität beibehält.
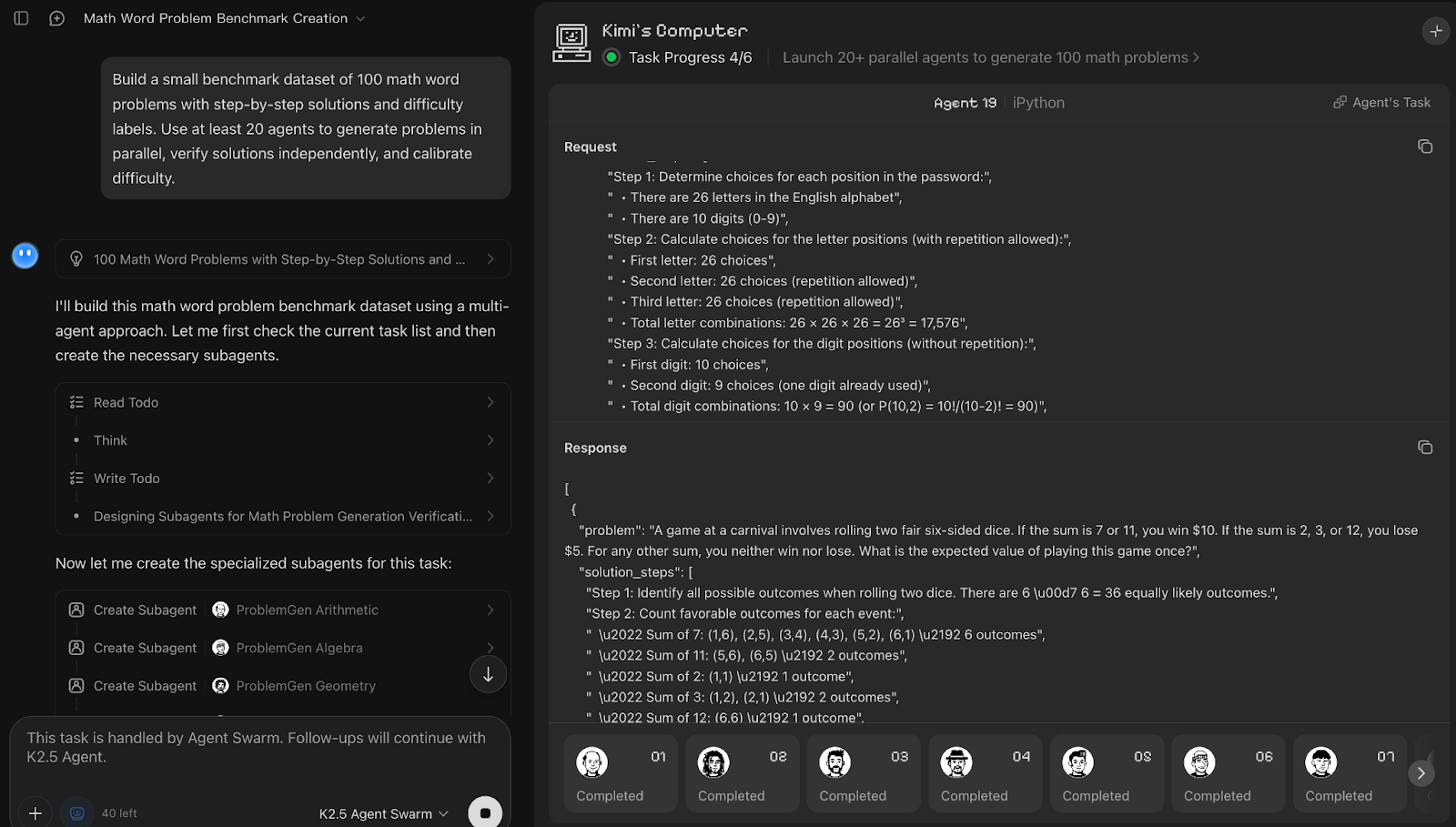
Prompt:
Build a small benchmark dataset of 100 math word problems with step-by-step solutions and difficulty labels. Use at least 20 agents to generate problems in parallel, verify solutions independently, and calibrate difficulty.Kimi K2.5 Agent Swarm hat die Erstellung von Datensätzen als dreistufigen Prozess gesehen, mit den Schritten Generierung, Überprüfung und Kalibrierung. Obwohl die Eingabeaufforderung mindestens 20 Agenten verlangte, hat das System selbstständig 25 Unteragenten gestartet und dabei die Richtigkeit über die strikte Einhaltung der geforderten Anzahl gestellt. Es war interessant zu sehen, dass ungefähr fünf Agenten gleichzeitig aktiv waren, während andere in der Warteschlange standen und weitermachten, sobald frühere Teilaufgaben erledigt waren, was auf einen internen Planungsmechanismus hindeutet.
Jeder Generationsagent hat sich um einen bestimmten Mathebereich gekümmert und fünf Aufgaben mit Schritt-für-Schritt-Lösungen erstellt. Danach wurden zehn Agenten für die Überprüfung eingesetzt, und eine kleinere Gruppe von fünf Agenten hat sich auf die Schwierigkeitskalibrierung konzentriert.
Als Nächstes habe ich Kimi K2.5 in einen multimodalen Arbeitsablauf eingebunden, indem ich mehrere Bilder von Nährwertangaben bereitgestellt und um einen strukturierten Vergleich gebeten habe. Das Ziel war, zu sehen, wie gut es visuelle Daten extrahieren, normalisieren und überprüfen kann.
Aufforderung:
I’m sharing images of nutrition labels from 7 packaged food items. Analyze them and produce a clear comparison specifically:
Extract fields like: calories, protein, total fat, sugar, sodium, from each label.Normalize all values to a per-100g basis so items are comparableDouble-check numeric consistency (e.g. serving size vs totals)Rank the products from healthiest to least healthy, explaining the reasoningReturn a comparison table with normalized values for all items. Also include a summary highlighting, best high-protein option, the lowest sugar option, and items to avoid and why.
Assume the labels may vary in format and serving size. Resolve ambiguities where possible and note any missing or unclear values.
In diesem multimodalen QA-Experiment hat Kimi K2.5 Agent Swarm die Aufgabe auf die einzelnen Sub-Agenten verteilt, wobei jeder ein Label bekam. Sieben Sub-Agenten haben parallel gearbeitet, um die Nährwertangaben aus den Bildern zu holen, während ein Koordinierungsagent für die Normalisierung, Gegenprüfung und Bewertung zuständig war.
Das Coole an Kimi ist, dass die Vorgaben, die du in der Eingabe machst (Extrahieren, Normalisieren, Überprüfen, Bewerten), quasi die Blaupause dafür sind, wie Kimi Subagenten instanziiert und zuweist.
Was mir aufgefallen ist, ist, wie wichtig dem Schwarm die Überprüfung war, d. h. nach der Extraktion hat der Orchestrator die Serviergrößen, normalisierten Werte und markierten Unklarheiten explizit abgeglichen, anstatt stillschweigend zu raten. Der letzte Schritt, bei dem die Produkte bewertet und die besten proteinreichen und zuckerarmen Optionen herausgestellt wurden, zeigte eine starke Aggregationslogik über alle visuellen Eingaben hinweg.
Zum Schluss habe ich die Programmierfähigkeiten von Kimi K2.5 getestet, indem ich es gebeten habe, ein komplett interaktives Bubble-Shooter-Spiel von Grund auf neu zu erstellen. Dieses Experiment zeigt, wie das Modell die End-to-End-Generierung von zustandsbehaftetem Code handhabt, bei der Kohärenz wichtiger ist als Parallelität.
Aufforderung:
```markdown
Mach ein voll spielbares Bubble-Shooter-Spiel, das lokal in einem Webbrowser läuft. Das Spiel sollte Maus- und Touch-Zielfunktionen haben, eine Live-Zielhilfe zeigen, farbige Blasen von der unteren Mitte aus abfeuern, Schüsse von den Seitenwänden abprallen lassen und Blasen bei Kollisionen an einem Raster oben einrasten lassen.
Mach die Hauptspiel-Logik, wie zum Beispiel Gruppen von drei oder mehr verbundenen Blasen derselben Farbe zum Platzen bringen, nicht verbundene Gruppen fallen lassen, Punkte zählen und anzeigen, eine Vorschau der nächsten Blase zeigen und das Spiel beenden, wenn die Blasen eine Gefahrenlinie am unteren Rand erreichen.
Halt die Grafik einfach, aber reaktionsschnell, füge einen Neustart-Button hinzu und schließ mit einer kurzen Anleitung ab, wie man das Spiel lokal ausführt und testet.
```
In diesem Experiment zum Spielaufbau hat Kimi K2.5 Agent Swarm eine ziemlich konservative Entscheidung getroffen, indem er nur einen einzigen Unteragenten für die ganze Aufgabe eingesetzt hat.
Diese Entscheidung ist echt interessant, weil das System richtig erkannt hat, dass es sich um ein eng gekoppeltes, zustandsbehaftetes Codierungsproblem handelte, bei dem starke Parallelität nur Koordinationsaufwand ohne Nutzen verursacht hätte.
Der Agent hat eine komplette, lokal lauffähige Bubble-Shooter-Implementierung mit Zielen, Wandabprallern, Rasterausrichtung, Match-Three-Popping, Punktestandverfolgung und Neustartlogik erstellt, die sowohl die Spielmechanik als auch den UI-Ablauf zeigt.
Die besten DataCamp-Kurse
Kurs
Kurs
Kurs
Blog
Blog
Hesam Sheikh Hassani
15 Min.
Tutorial
Matt Crabtree
Tutorial
Mark Pedigo