
Curso
Desarrollo de aplicaciones LLM con LangChain
3 h
46.2K
LangManus es un marco de automatización de IA de código abierto, impulsado por la comunidad y diseñado para construir sistemas multiagente estructurados utilizando modelos lingüísticos. Con LangManus, puedes crear agentes inteligentes que combinen la planificación, la investigación, la codificación, la interacción con el navegador y la elaboración de informes en un único proceso cohesionado.
En este tutorial, te guiaré para que construyas una demo funcional con LangManus que:
La arquitectura de LangManus admite un control detallado, auditabilidad y extensibilidad. Se basa en potentes herramientas como:
Con LangManus, puedes crear agentes inteligentes que combinen la planificación, la investigación, la codificación, la interacción con el navegador y la elaboración de informes en un único proceso cohesivo impulsado por:
YAML o .env-based configuración de modelos y teclas.La aplicación que construiremos es un asistente interactivo que utiliza las capacidades multiagente de LangManus para analizar un repositorio GitHub en tendencia. Para configurar los Agentes LangManus, necesitamos una estructura de varios archivos en la que cada archivo desempeñe un papel distinto en el sistema multiagente:
Pongámoslos en práctica uno por uno.
Antes de empezar, asegurémonos de que tenemos instaladas las siguientes herramientas y bibliotecas:
python3 --version # Python 3.8+
pip install requests beautifulsoup4 matplotlib streamlitComprueba la versión de Python, que debe ser al menos 3.8 o superior. Después, simplemente instala todas las demás dependencias mencionadas anteriormente. También necesitarás un token de la API de GitHub para evitar los límites de velocidad y establecerlo como variable de entorno utilizando el terminal.
Para generar tokens de GitHub:
Ahora, ejecuta el siguiente comando:
export GITHUB_TOKEN=your_personal_token_hereAhora que tenemos todas las dependencias instaladas, vamos a construir el planificador y el controlador del agente para nuestra aplicación.
El archivo planner.py define un sencillo plan de 4 pasos para cubrir cada tarea requerida, como investigar, explorar, analizar e informar.
def plan_task(user_query):
return [
{'agent': 'researcher', 'task': 'Find trending repo'},
{'agent': 'browser', 'task': 'Scrape GitHub activity'},
{'agent': 'coder', 'task': 'Analyze recent commits and features'},
{'agent': 'reporter', 'task': 'Generate Markdown report'}
]La función anterior devuelve un plan de tareas paso a paso para el sistema en el que cada paso:
El archivo del agente define el núcleo de la clase LangManusAgent, que orquesta a todos los agentes y mantiene un contexto compartido mientras realizan sus tareas.
from planner import plan_task
from agents.researcher import find_trending_repo
from agents.browser import scrape_github_activity
from agents.coder import analyze_code_activity
from agents.reporter import generate_report
class LangManusAgent:
def __init__(self, task):
self.task = task
self.context = {}
def run(self):
steps = plan_task(self.task)
for step in steps:
agent = step['agent']
task = step['task']
if agent == 'researcher':
self.context['repo'] = find_trending_repo()
elif agent == 'browser':
self.context['repo_data'] = scrape_github_activity(self.context['repo'])
elif agent == 'coder':
self.context['analysis'], self.context['chart_path'] = analyze_code_activity(self.context['repo_data'])
elif agent == 'reporter':
report = generate_report(
self.context['repo'],
self.context['repo_data'],
self.context['analysis'],
self.context['chart_path']
)
print(report)
def run_and_return(self):
self.run()
report = generate_report(
self.context['repo'],
self.context['repo_data'],
self.context['analysis'],
self.context['chart_path']
)
return report, self.context['chart_path']El código comienza llamando a la función plan_task() para recuperar una lista de pasos (definida en planner.py). A continuación, ejecuta cada paso invocando al agente especializado adecuado en el siguiente orden:
Cada agente almacena sus resultados en el diccionario context, lo que permite a los agentes posteriores acceder a los resultados anteriores y basarse en ellos.
Ahora que tenemos listas las funciones básicas, vamos a construir los agentes de nuestra aplicación.
Este agente identifica un proyecto Python de código abierto popular de GitHub raspando el Tendencias de GitHub de GitHub.
import requests
from bs4 import BeautifulSoup
def find_trending_repo():
url = "https://github.com/trending/python"
res = requests.get(url)
soup = BeautifulSoup(res.text, 'html.parser')
repo = soup.select_one('article h2 a')['href'].strip()
return f"https://github.com{repo}"Funciona así:
El agente del navegador se utiliza para obtener la actividad reciente del repositorio de GitHub seleccionado. Utiliza la API REST de GitHub para recopilar el historial de confirmaciones y los metadatos.
import requests
import os
def scrape_github_activity(repo_url):
token = os.getenv("GITHUB_TOKEN") # Set via environment or .env
headers = {"Authorization": f"Bearer {token}"} if token else {}
user_repo = "/".join(repo_url.split('/')[-2:])
api_url = f"https://api.github.com/repos/{user_repo}/commits"
res = requests.get(api_url, headers=headers)
res.raise_for_status()
data = res.json()
commits = []
commit_dates = []
for item in data[:20]: # optional: increase window for better activity chart
message = item['commit']['message']
author = item['commit']['author']['name']
date = item['commit']['author']['date']
sha = item['sha'][:7]
commits.append(f"[{sha}] {message} — {author} @ {date}")
commit_dates.append(date) # in ISO 8601 format (perfect for parsing)
return {
'repo_url': repo_url,
'commits': commits,
'commit_dates': commit_dates
}Esto es lo que hace la función anterior:
commits y commit_dates. Este agente procesa y analiza el historial de commits recopilado de GitHub y genera tanto un resumen textual como una visión visual utilizando matplotlib.
# agents/coder.py
import matplotlib.pyplot as plt
from collections import defaultdict, Counter
from datetime import datetime
import matplotlib.dates as mdates
import re
import os
def categorize_commit(message):
message = message.lower()
if any(kw in message for kw in ["fix", "bug"]):
return "🐛 Bug Fixes"
elif any(kw in message for kw in ["add", "feature", "implement"]):
return "✨ Features"
elif any(kw in message for kw in ["doc", "readme"]):
return "📄 Documentation"
elif any(kw in message for kw in ["remove", "delete"]):
return "🔥 Removals"
elif any(kw in message for kw in ["update", "upgrade"]):
return "🔧 Updates"
elif any(kw in message for kw in ["merge", "pull"]):
return "🔀 Merges"
else:
return "📦 Others"
def analyze_code_activity(repo_data):
commit_messages = repo_data['commits']
commit_dates = repo_data.get('commit_dates', [])
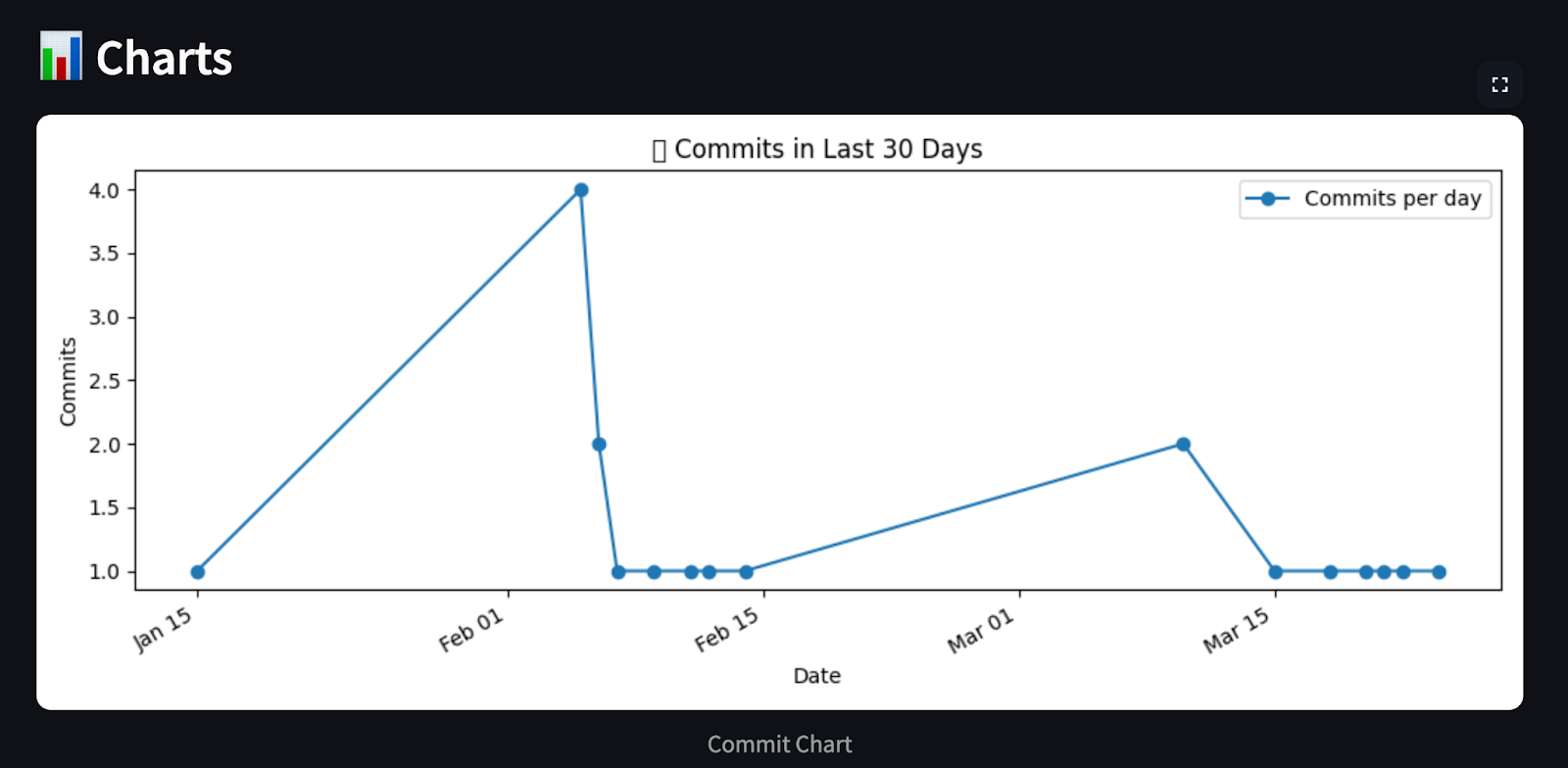
# Chart 1: Commits per day (last 30 days)
commit_day_counts = defaultdict(int)
for date in commit_dates:
day = datetime.fromisoformat(date).date()
commit_day_counts[day] += 1
recent_days = sorted(commit_day_counts.keys())
counts = [commit_day_counts[day] for day in recent_days]
plt.figure(figsize=(10, 4))
plt.plot(recent_days, counts, marker='o', linestyle='-', color='tab:blue', label='Commits per day')
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%b %d'))
plt.gcf().autofmt_xdate()
plt.xlabel("Date")
plt.ylabel("Commits")
plt.title("📈 Commits in Last 30 Days")
plt.legend()
path1 = "commit_chart.png"
plt.tight_layout()
plt.savefig(path1)
plt.close()
# Chart 2: Commits per category
commit_categories = defaultdict(list)
category_counter = Counter()
for msg in commit_messages:
short_msg = re.split(r'—|@', msg)[0].strip()
category = categorize_commit(short_msg)
commit_categories[category].append(short_msg)
category_counter[category] += 1
plt.figure(figsize=(8, 4))
cats, values = zip(*category_counter.items())
plt.bar(cats, values, color='tab:green')
plt.ylabel("Commits")
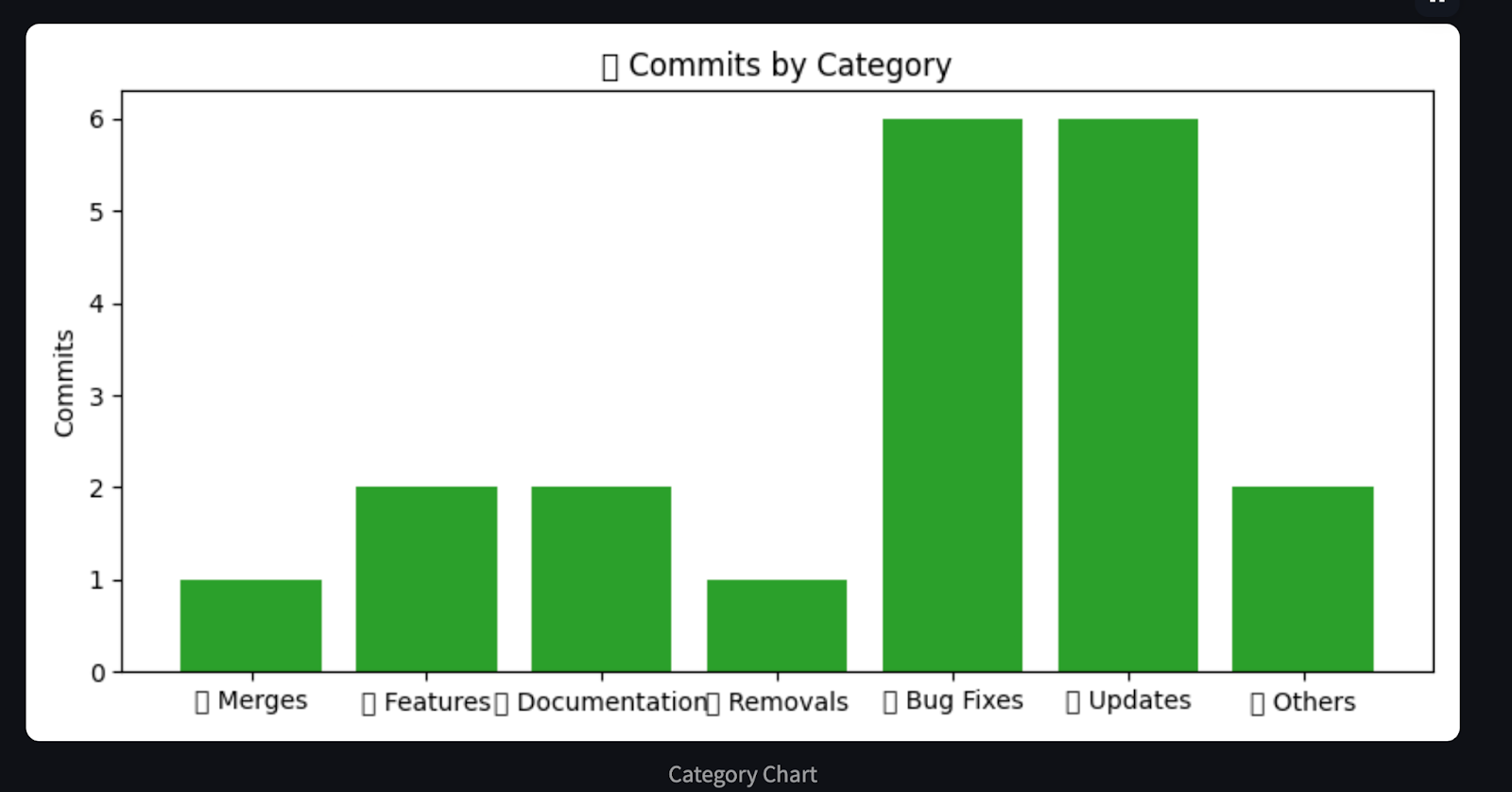
plt.title("🧩 Commits by Category")
path2 = "category_chart.png"
plt.tight_layout()
plt.savefig(path2)
plt.close()
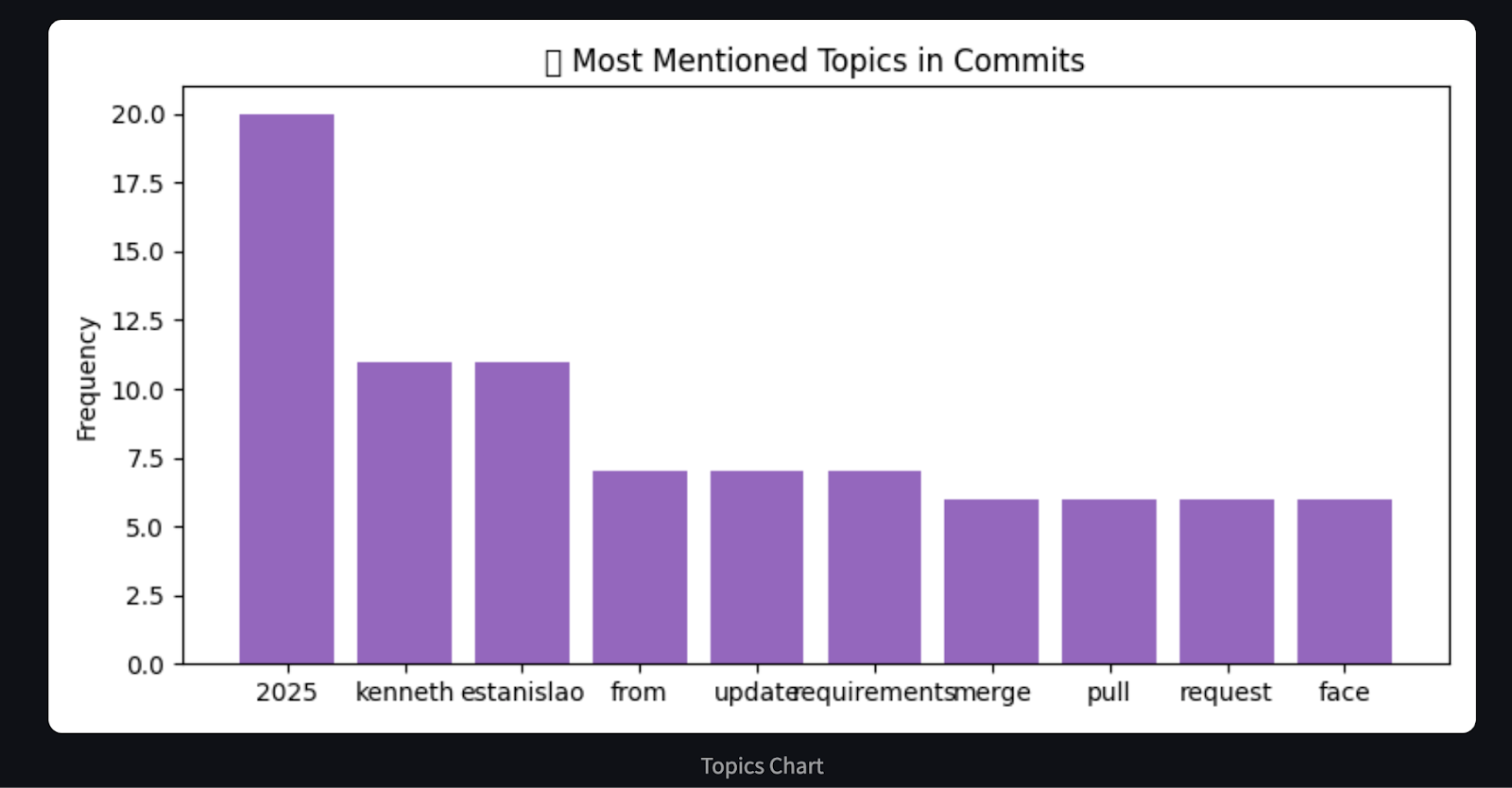
# Chart 3: Word frequency in commit messages (basic proxy for hot areas)
word_freq = Counter()
for msg in commit_messages:
words = re.findall(r'\b\w{4,}\b', msg.lower()) # only words with length >= 4
word_freq.update(words)
most_common = word_freq.most_common(10)
labels, freqs = zip(*most_common)
plt.figure(figsize=(8, 4))
plt.bar(labels, freqs, color='tab:purple')
plt.ylabel("Frequency")
plt.title("🔥 Most Mentioned Topics in Commits")
path3 = "topics_chart.png"
plt.tight_layout()
plt.savefig(path3)
plt.close()
# Build markdown report
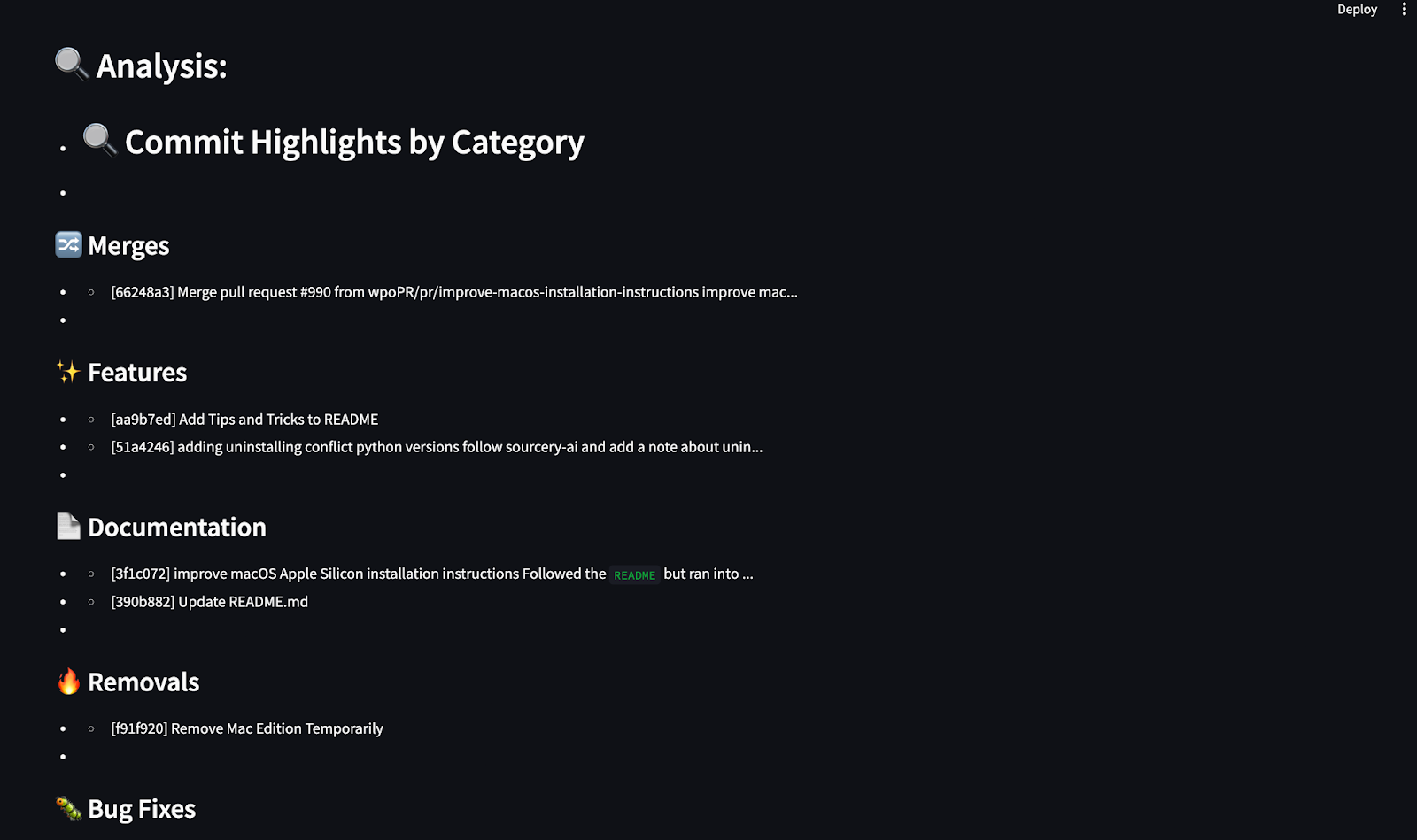
analysis = ["## 🔍 Commit Highlights by Category"]
for cat, msgs in commit_categories.items():
analysis.append(f"\n### {cat}")
for m in msgs[:3]:
clean_msg = m.replace("\n", " ").strip()
analysis.append(f"- {clean_msg[:100]}{'...' if len(clean_msg) > 100 else ''}")
charts = [path1, path2, path3]
return analysis, chartsEste agente procesa el historial de commits de GitHub y genera un resumen Markdown y gráficos visuales utilizando matplotlib. Categoriza los commits en grupos predefinidos, como correcciones de errores, características, documentación, etc., mediante la concordancia de palabras clave. A continuación, utiliza matplotlib para generar tres gráficos esclarecedores que muestran:
Por último, el agente crea un resumen markdown destacando los commits clave de cada categoría y devuelve tanto el resumen como las rutas del gráfico para su representación en el informe.
El agente informador genera el informe Markdown final que combina:
def generate_report(repo_url, repo_data, analysis, chart_path):
md = f"""# 🧠 GitHub Repo Analysis
## 🔗 Repo: [{repo_url}]({repo_url})
## 📝 Recent Commits:
"""
for c in repo_data['commits']:
md += f"- {c}\n"
md += "\n## 🔍 Analysis:\n"
for line in analysis:
md += f"- {line}\n"
return mdLa función generate_report() ensambla el informe Markdown final utilizando la URL de GitHub, los datos de commit, el análisis categorizado y las rutas de los gráficos. Devuelve una única cadena con formato Markdown que puede mostrarse en el terminal o representarse en una interfaz de usuario como Streamlit. Devuelve una única cadena con formato Markdown que puede imprimirse en la consola o representarse en Streamlit.
La aplicación Streamlit permite a los usuarios ejecutar todo el pipeline con un solo clic. Crea un archivo streamlit_app.py y añade el siguiente código:
import streamlit as st
from agent import LangManusAgent
import os
from PIL import Image
st.set_page_config(page_title="LangManus GitHub Analyzer", layout="wide")
st.title("🧠 LangManus GitHub Repo Analyzer")
if st.button("🔍 Run Analysis on Trending Repo"):
with st.spinner("Running LangManus agents..."):
agent = LangManusAgent(task="Find a popular open-source project updated recently and summarize its new features with examples and charts.")
report, chart_paths = agent.run_and_return()
st.markdown(report)
st.subheader("📊 Charts")
for path in chart_paths:
if os.path.exists(path):
st.image(Image.open(path), caption=os.path.basename(path).replace('_', ' ').replace('.png', '').title(), use_container_width=True)
else:
st.info("Click the button to run analysis on a trending GitHub Python repo.")Esto es lo que hace el código
streamlit para crear un tablero de mandos mínimo, de forma que al pulsar el botón analizar el, se active la función LangManusAgent.run_and_return().st.markdown() y realiza un bucle a través de cada ruta del gráfico, y luego los renderiza utilizando la función st.image().La estructura final de nuestro proyecto de análisis en GitHub potenciado por LangManus debería tener este aspecto:
LangManus-GitHub-Demo/
├── main.py
├── agent.py
├── planner.py
├── streamlit_app.py
├── agents/
│ ├── researcher.py
│ ├── browser.py
│ ├── coder.py
│ └── reporter.py
├── commit_chart.png
├── category_chart.png
├── topics_chart.pngAhora que ya tenemos todos los componentes, vamos a ejecutar nuestra aplicación Streamlit. Ejecuta el siguiente comando en el terminal:
streamlit run streamlit_app.py
Haz clic en el botón "Ejecutar análisis en repositorio en tendencia" de tu navegador, y tus agentes potenciados por LangManus obtendrán, analizarán y presentarán información sobre el repositorio de GitHub en cuestión de segundos.

LangManus nos permite construir sistemas multiagente estructurados que interactúan con datos del mundo real. En esta guía, hemos creado un analizador de repositorios de GitHub totalmente automatizado en el que:
LangManus tiene un gran potencial para crear agentes de investigación, cuadros de mando y asistentes basados en datos.
Aprende IA con estos cursos
Curso
Curso
Curso
blog
Abid Ali Awan
10 min
Tutorial
Moez Ali
Tutorial
Bex Tuychiev
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan


