
Kurs
Entwickeln von LLM-Anwendungen mit LangChain
3 Std.
46.3K
LangManus ist ein von der Community entwickeltes Open-Source-Framework zur KI-Automatisierung, mit dem strukturierte Multi-Agenten-Systeme mit Sprachmodellen erstellt werden können. Mit LangManus kannst du intelligente Agenten erstellen, die Planung, Recherche, Codierung, Browser-Interaktion und Berichterstattung in einer einzigen, zusammenhängenden Pipeline kombinieren.
In diesem Tutorial zeige ich dir, wie du eine funktionierende Demo mit LangManus erstellst:
Die Architektur von LangManus unterstützt eine fein abgestufte Kontrolle, Nachvollziehbarkeit und Erweiterbarkeit. Es basiert auf leistungsstarken Tools wie:
Mit LangManus kannst du intelligente Agenten erstellen, die Planung, Recherche, Codierung, Browser-Interaktion und Berichterstattung in einer einzigen, zusammenhängenden Pipeline vereinen:
YAML oder .env-based Konfiguration für Modelle und Schlüssel.Die App, die wir bauen werden, ist ein interaktiver Assistent, der die Multi-Agenten-Fähigkeiten von LangManus nutzt, um ein GitHub-Repository zu analysieren. Um LangManus-Agenten einzurichten, brauchen wir eine Struktur mit mehreren Dateien, wobei jede Datei eine bestimmte Rolle im Multi-Agenten-System spielt:
Lass uns diese nacheinander umsetzen.
Bevor wir beginnen, müssen wir sicherstellen, dass wir die folgenden Tools und Bibliotheken installiert haben:
python3 --version # Python 3.8+
pip install requests beautifulsoup4 matplotlib streamlitÜberprüfe die Python-Version, die mindestens 3.8 oder höher sein sollte. Dann installierst du einfach alle anderen oben genannten Abhängigkeiten. Du brauchst außerdem ein GitHub-API-Token, um Ratenbeschränkungen zu vermeiden, und legst es als Umgebungsvariable im Terminal fest.
So generierst du GitHub-Tokens:
Führe nun den folgenden Befehl aus:
export GITHUB_TOKEN=your_personal_token_hereJetzt, wo wir alle Abhängigkeiten installiert haben, können wir den Planer und den Agent Controller für unsere Anwendung erstellen.
Die Datei planner.py definiert einen einfachen 4-Schritte-Plan für jede erforderliche Aufgabe, z. B. Recherche, Durchsuchen, Analysieren und Berichten.
def plan_task(user_query):
return [
{'agent': 'researcher', 'task': 'Find trending repo'},
{'agent': 'browser', 'task': 'Scrape GitHub activity'},
{'agent': 'coder', 'task': 'Analyze recent commits and features'},
{'agent': 'reporter', 'task': 'Generate Markdown report'}
]Die obige Funktion gibt einen Schritt-für-Schritt-Aufgabenplan für das System zurück, bei dem jeder Schritt:
Die Agentendatei definiert die Kernklasse LangManusAgent, die alle Agenten orchestriert und einen gemeinsamen Kontext aufrechterhält, während sie ihre Aufgaben erfüllen.
from planner import plan_task
from agents.researcher import find_trending_repo
from agents.browser import scrape_github_activity
from agents.coder import analyze_code_activity
from agents.reporter import generate_report
class LangManusAgent:
def __init__(self, task):
self.task = task
self.context = {}
def run(self):
steps = plan_task(self.task)
for step in steps:
agent = step['agent']
task = step['task']
if agent == 'researcher':
self.context['repo'] = find_trending_repo()
elif agent == 'browser':
self.context['repo_data'] = scrape_github_activity(self.context['repo'])
elif agent == 'coder':
self.context['analysis'], self.context['chart_path'] = analyze_code_activity(self.context['repo_data'])
elif agent == 'reporter':
report = generate_report(
self.context['repo'],
self.context['repo_data'],
self.context['analysis'],
self.context['chart_path']
)
print(report)
def run_and_return(self):
self.run()
report = generate_report(
self.context['repo'],
self.context['repo_data'],
self.context['analysis'],
self.context['chart_path']
)
return report, self.context['chart_path']Der Code beginnt mit dem Aufruf der Funktion plan_task(), um eine Liste von Schritten abzurufen (definiert in planner.py). Dann führt er jeden Schritt aus, indem er den entsprechenden spezialisierten Agenten in der folgenden Reihenfolge aufruft:
Jeder Agent speichert seine Ergebnisse im context Wörterbuch, so dass die nachgeschalteten Agenten auf die vorherigen Ergebnisse zugreifen und darauf aufbauen können.
Jetzt, wo wir die Kernfunktionen fertig haben, können wir die Agenten für unsere Anwendung erstellen.
Dieser Agent identifiziert ein beliebtes Open-Source-Python-Projekt auf GitHub, indem er die GitHub Trending Seite.
import requests
from bs4 import BeautifulSoup
def find_trending_repo():
url = "https://github.com/trending/python"
res = requests.get(url)
soup = BeautifulSoup(res.text, 'html.parser')
repo = soup.select_one('article h2 a')['href'].strip()
return f"https://github.com{repo}"So funktioniert es:
Der Browser-Agent wird verwendet, um die jüngsten Aktivitäten aus dem ausgewählten GitHub-Repository abzurufen. Sie nutzt die GitHub REST API, um Commit-Historie und Metadaten zu sammeln.
import requests
import os
def scrape_github_activity(repo_url):
token = os.getenv("GITHUB_TOKEN") # Set via environment or .env
headers = {"Authorization": f"Bearer {token}"} if token else {}
user_repo = "/".join(repo_url.split('/')[-2:])
api_url = f"https://api.github.com/repos/{user_repo}/commits"
res = requests.get(api_url, headers=headers)
res.raise_for_status()
data = res.json()
commits = []
commit_dates = []
for item in data[:20]: # optional: increase window for better activity chart
message = item['commit']['message']
author = item['commit']['author']['name']
date = item['commit']['author']['date']
sha = item['sha'][:7]
commits.append(f"[{sha}] {message} — {author} @ {date}")
commit_dates.append(date) # in ISO 8601 format (perfect for parsing)
return {
'repo_url': repo_url,
'commits': commits,
'commit_dates': commit_dates
}Die obige Funktion funktioniert folgendermaßen:
commits und commit_dates. Dieser Agent verarbeitet und analysiert den von GitHub gesammelten Commit-Verlauf und erstellt sowohl eine textliche Zusammenfassung als auch visuelle Einblicke mithilfe von Matplotlib.
# agents/coder.py
import matplotlib.pyplot as plt
from collections import defaultdict, Counter
from datetime import datetime
import matplotlib.dates as mdates
import re
import os
def categorize_commit(message):
message = message.lower()
if any(kw in message for kw in ["fix", "bug"]):
return "🐛 Bug Fixes"
elif any(kw in message for kw in ["add", "feature", "implement"]):
return "✨ Features"
elif any(kw in message for kw in ["doc", "readme"]):
return "📄 Documentation"
elif any(kw in message for kw in ["remove", "delete"]):
return "🔥 Removals"
elif any(kw in message for kw in ["update", "upgrade"]):
return "🔧 Updates"
elif any(kw in message for kw in ["merge", "pull"]):
return "🔀 Merges"
else:
return "📦 Others"
def analyze_code_activity(repo_data):
commit_messages = repo_data['commits']
commit_dates = repo_data.get('commit_dates', [])
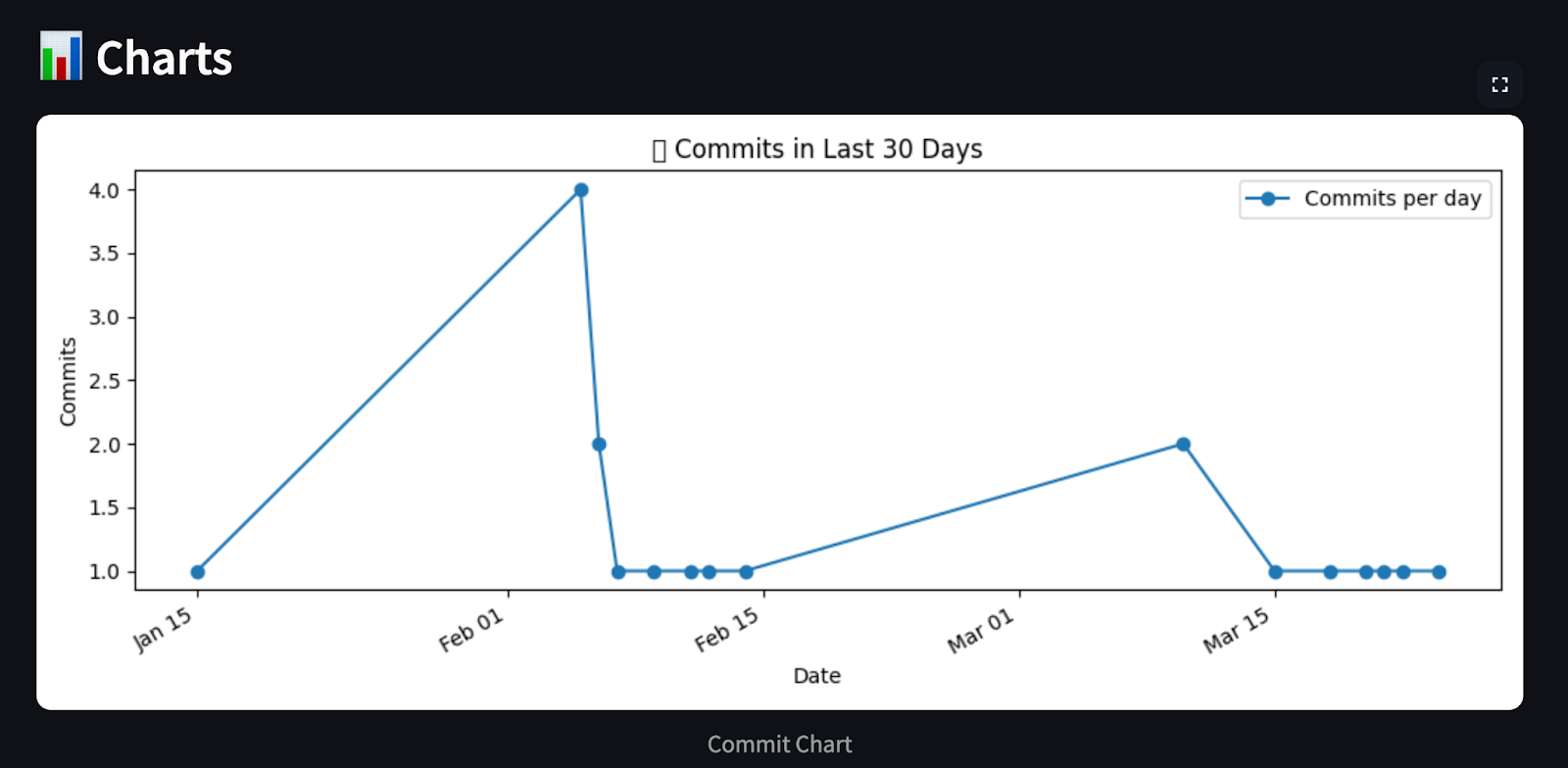
# Chart 1: Commits per day (last 30 days)
commit_day_counts = defaultdict(int)
for date in commit_dates:
day = datetime.fromisoformat(date).date()
commit_day_counts[day] += 1
recent_days = sorted(commit_day_counts.keys())
counts = [commit_day_counts[day] for day in recent_days]
plt.figure(figsize=(10, 4))
plt.plot(recent_days, counts, marker='o', linestyle='-', color='tab:blue', label='Commits per day')
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%b %d'))
plt.gcf().autofmt_xdate()
plt.xlabel("Date")
plt.ylabel("Commits")
plt.title("📈 Commits in Last 30 Days")
plt.legend()
path1 = "commit_chart.png"
plt.tight_layout()
plt.savefig(path1)
plt.close()
# Chart 2: Commits per category
commit_categories = defaultdict(list)
category_counter = Counter()
for msg in commit_messages:
short_msg = re.split(r'—|@', msg)[0].strip()
category = categorize_commit(short_msg)
commit_categories[category].append(short_msg)
category_counter[category] += 1
plt.figure(figsize=(8, 4))
cats, values = zip(*category_counter.items())
plt.bar(cats, values, color='tab:green')
plt.ylabel("Commits")
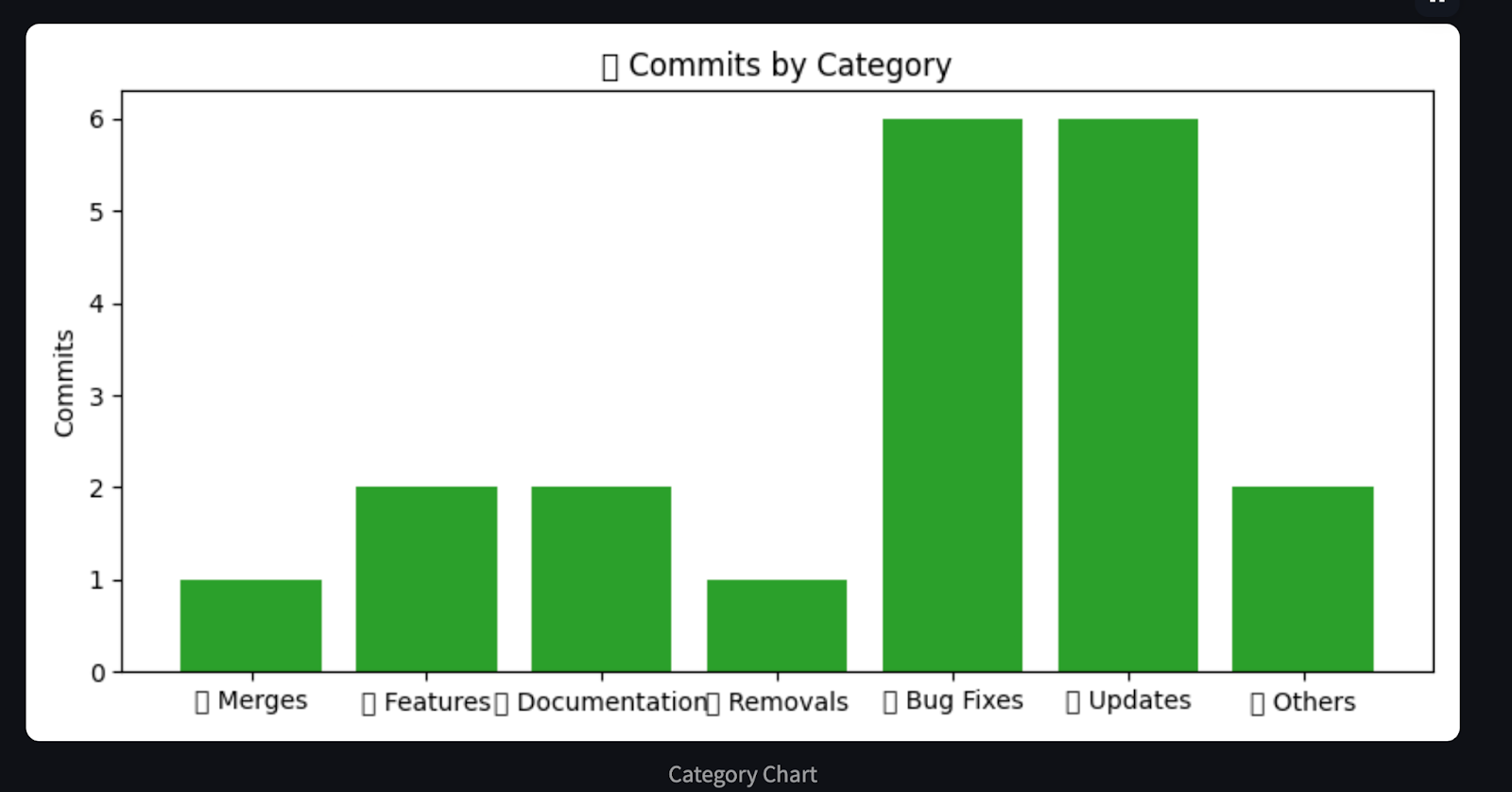
plt.title("🧩 Commits by Category")
path2 = "category_chart.png"
plt.tight_layout()
plt.savefig(path2)
plt.close()
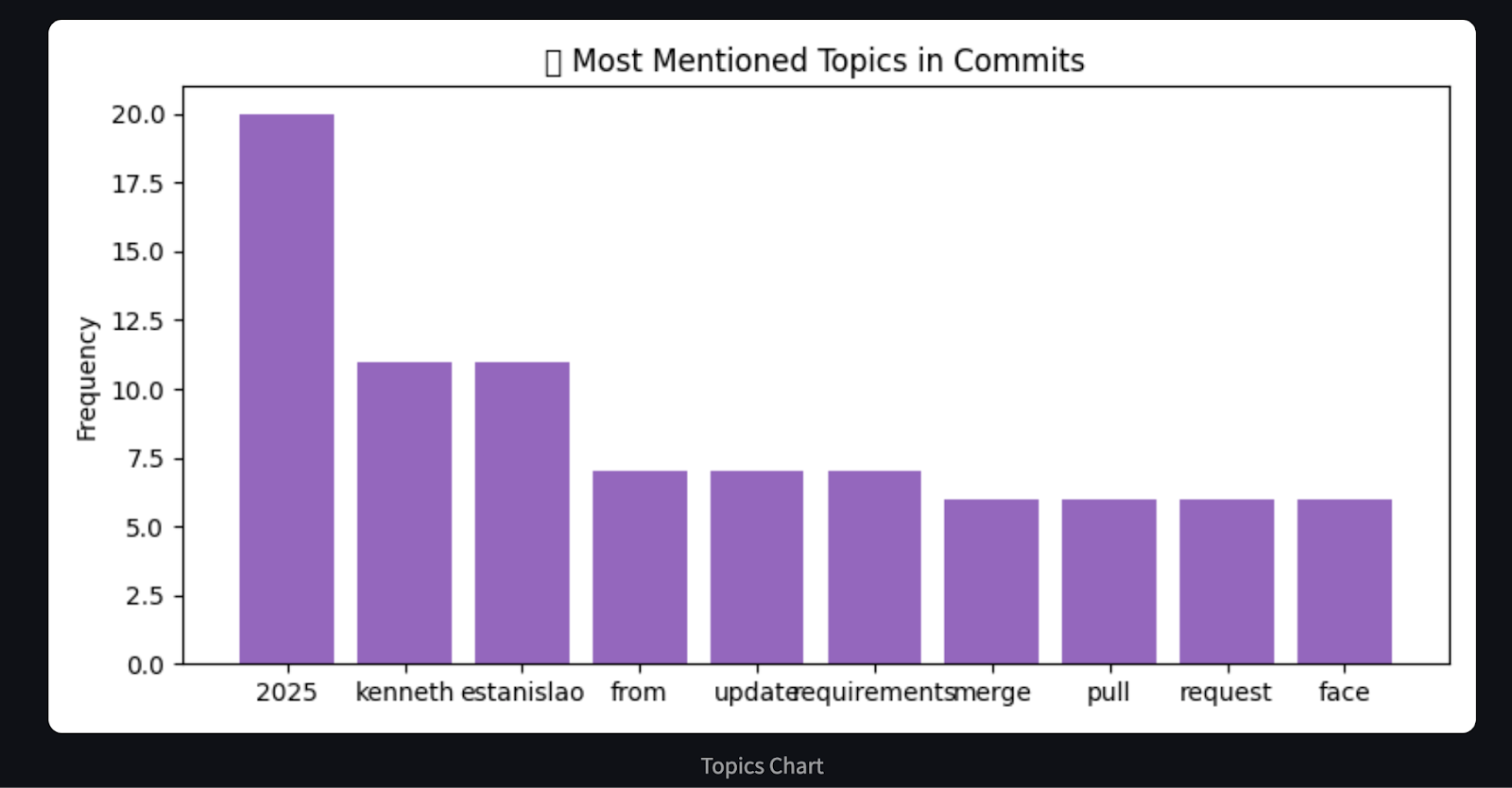
# Chart 3: Word frequency in commit messages (basic proxy for hot areas)
word_freq = Counter()
for msg in commit_messages:
words = re.findall(r'\b\w{4,}\b', msg.lower()) # only words with length >= 4
word_freq.update(words)
most_common = word_freq.most_common(10)
labels, freqs = zip(*most_common)
plt.figure(figsize=(8, 4))
plt.bar(labels, freqs, color='tab:purple')
plt.ylabel("Frequency")
plt.title("🔥 Most Mentioned Topics in Commits")
path3 = "topics_chart.png"
plt.tight_layout()
plt.savefig(path3)
plt.close()
# Build markdown report
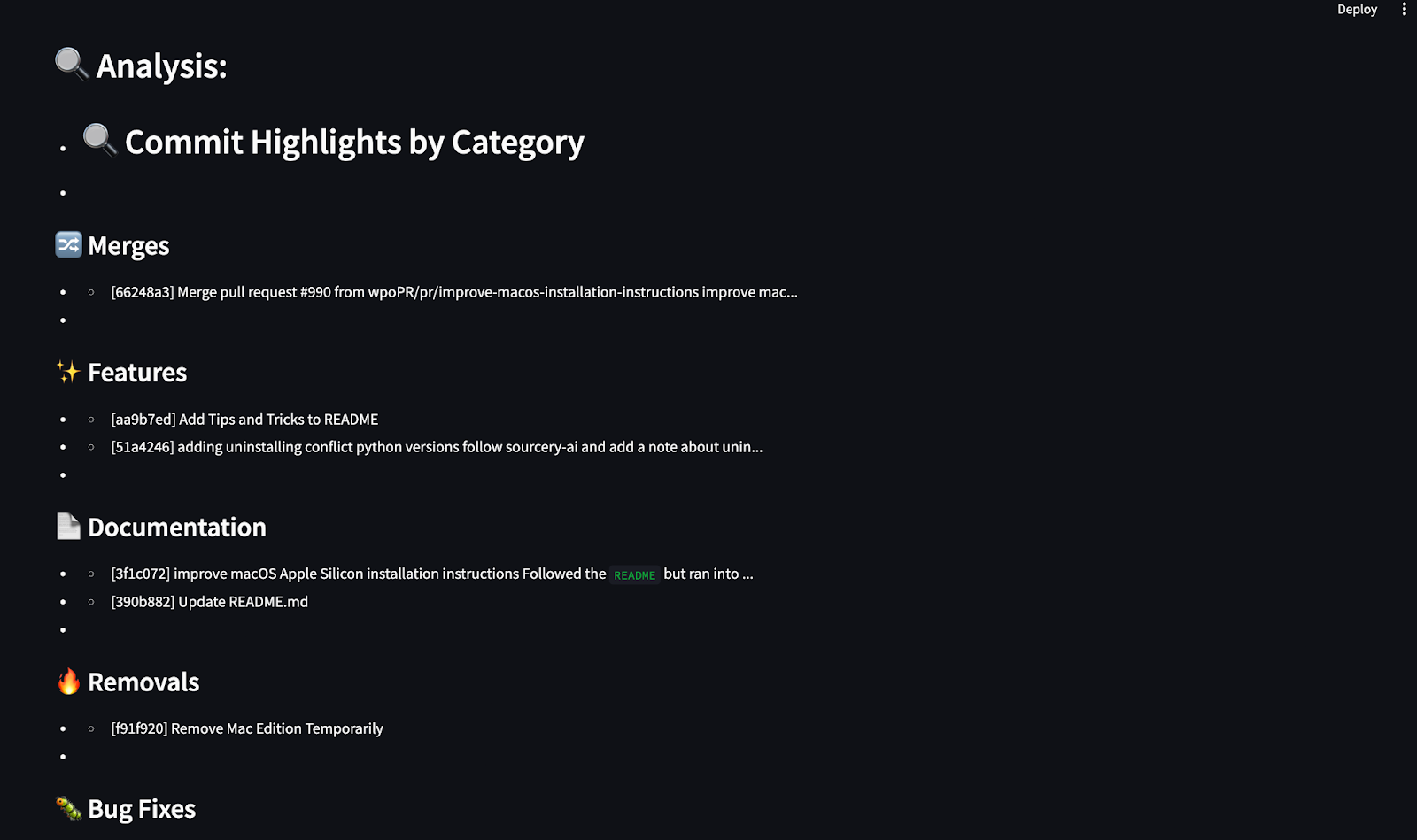
analysis = ["## 🔍 Commit Highlights by Category"]
for cat, msgs in commit_categories.items():
analysis.append(f"\n### {cat}")
for m in msgs[:3]:
clean_msg = m.replace("\n", " ").strip()
analysis.append(f"- {clean_msg[:100]}{'...' if len(clean_msg) > 100 else ''}")
charts = [path1, path2, path3]
return analysis, chartsDieser Agent verarbeitet die GitHub-Commit-Historie und erstellt eine Markdown-Zusammenfassung und visuelle Diagramme mit matplotlib. Es kategorisiert Commits in vordefinierte Gruppen wie Bugfixes, Features, Dokumentation und mehr, indem es Schlüsselwörter abgleicht. Unter matplotlib werden dann drei aufschlussreiche Diagramme erstellt, die zeigen:
Schließlich erstellt der Agent eine Markdown-Zusammenfassung, die die wichtigsten Commits in jeder Kategorie hervorhebt, und gibt sowohl die Zusammenfassung als auch die Diagramm-Pfade zur Darstellung im Bericht zurück.
Der Reporter-Agent erstellt den abschließenden Markdown-Bericht, der alles zusammenfasst:
def generate_report(repo_url, repo_data, analysis, chart_path):
md = f"""# 🧠 GitHub Repo Analysis
## 🔗 Repo: [{repo_url}]({repo_url})
## 📝 Recent Commits:
"""
for c in repo_data['commits']:
md += f"- {c}\n"
md += "\n## 🔍 Analysis:\n"
for line in analysis:
md += f"- {line}\n"
return mdDie Funktion generate_report() stellt den endgültigen Markdown-Bericht mit der GitHub-URL, den Commit-Daten, der kategorisierten Analyse und den Diagramm-Pfaden zusammen. Sie gibt einen einzelnen Markdown-formatierten String zurück, der im Terminal angezeigt oder in einer Benutzeroberfläche wie Streamlit. Sie gibt einen einzelnen Markdown-formatierten String zurück, der auf der Konsole ausgegeben oder in Streamlit gerendert werden kann.
Mit der Streamlit-App kannst du die gesamte Pipeline mit einem einzigen Klick ausführen. Erstelle eine streamlit_app.py Datei und füge den folgenden Code hinzu:
import streamlit as st
from agent import LangManusAgent
import os
from PIL import Image
st.set_page_config(page_title="LangManus GitHub Analyzer", layout="wide")
st.title("🧠 LangManus GitHub Repo Analyzer")
if st.button("🔍 Run Analysis on Trending Repo"):
with st.spinner("Running LangManus agents..."):
agent = LangManusAgent(task="Find a popular open-source project updated recently and summarize its new features with examples and charts.")
report, chart_paths = agent.run_and_return()
st.markdown(report)
st.subheader("📊 Charts")
for path in chart_paths:
if os.path.exists(path):
st.image(Image.open(path), caption=os.path.basename(path).replace('_', ' ').replace('.png', '').title(), use_container_width=True)
else:
st.info("Click the button to run analysis on a trending GitHub Python repo.")Der Code funktioniert folgendermaßen:
streamlit Bibliothek, um ein minimales Dashboard zu erstellen, das beim Klicken auf die Schaltfläche "Analysieren" die Funktion LangManusAgent.run_and_return() auslöst.st.markdown() an und durchläuft die einzelnen Diagrammpfade in einer Schleife, um sie dann mit der Funktion st.image() wiederzugeben.Die endgültige Struktur unseres von LangManus betriebenen GitHub-Analyseprojekts sollte wie folgt aussehen:
LangManus-GitHub-Demo/
├── main.py
├── agent.py
├── planner.py
├── streamlit_app.py
├── agents/
│ ├── researcher.py
│ ├── browser.py
│ ├── coder.py
│ └── reporter.py
├── commit_chart.png
├── category_chart.png
├── topics_chart.pngJetzt, wo alle Komponenten vorhanden sind, können wir unsere Streamlit-Anwendung starten. Führe den folgenden Befehl im Terminal aus:
streamlit run streamlit_app.py
Wenn du in deinem Browser auf die Schaltfläche "Run Analysis on Trending Repo" klickst, werden deine LangManus-gesteuerten Agenten innerhalb von Sekunden Einblicke in das GitHub-Repository abrufen, analysieren und präsentieren.

Mit LangManus können wir strukturierte Multiagentensysteme aufbauen, die mit Daten aus der realen Welt interagieren. In diesem Leitfaden haben wir einen vollautomatischen GitHub Repo Analyzer erstellt, in dem wir:
LangManus hat großes Potenzial für den Aufbau von Forschungsagenten, Dashboards und datengesteuerten Assistenten.
Lerne KI mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
