
Cours
Développement d'applications LLM avec LangChain
3 h
46.2K
LangManus est un cadre d'automatisation de l'IA open-source et communautaire conçu pour construire des systèmes multi-agents structurés à l'aide de modèles linguistiques. Avec LangManus, vous pouvez créer des agents intelligents qui combinent la planification, la recherche, le codage, l'interaction avec le navigateur et la création de rapports en un seul processus cohérent.
Dans ce tutoriel, je vous guiderai pour construire une démo fonctionnelle avec LangManus :
L'architecture de LangManus permet un contrôle fin, l'auditabilité et l'extensibilité. Il s'appuie sur des outils puissants tels que :
Avec LangManus, vous pouvez créer des agents intelligents qui combinent la planification, la recherche, le codage, l'interaction avec le navigateur et la création de rapports en un seul pipeline cohérent alimenté par.. :
YAML ou .env-based pour les modèles et les clés.L'application que nous allons créer est un assistant interactif qui utilise les capacités multi-agents de LangManus pour analyser un dépôt GitHub. Pour mettre en place les agents LangManus, nous avons besoin d'une structure à fichiers multiples où chaque fichier joue un rôle distinct dans le système multi-agents :
Mettons-les en œuvre l'une après l'autre.
Avant de commencer, nous devons nous assurer que les outils et bibliothèques suivants sont installés :
python3 --version # Python 3.8+
pip install requests beautifulsoup4 matplotlib streamlitVérifiez la version de Python, qui doit être au moins 3.8 ou plus. Ensuite, installez simplement toutes les autres dépendances mentionnées ci-dessus. Vous aurez également besoin d'un jeton API GitHub pour éviter les limites de taux et le définir en tant que variable d'environnement à l'aide du terminal.
Pour générer des jetons GitHub :
Exécutez ensuite la commande suivante :
export GITHUB_TOKEN=your_personal_token_hereMaintenant que toutes les dépendances sont installées, construisons le planificateur et le contrôleur de l'agent pour notre application.
Le fichier planner.py définit un plan simple en quatre étapes pour couvrir chaque tâche requise, comme la recherche, la navigation, l'analyse et le rapport.
def plan_task(user_query):
return [
{'agent': 'researcher', 'task': 'Find trending repo'},
{'agent': 'browser', 'task': 'Scrape GitHub activity'},
{'agent': 'coder', 'task': 'Analyze recent commits and features'},
{'agent': 'reporter', 'task': 'Generate Markdown report'}
]La fonction ci-dessus renvoie un plan de travail étape par étape pour le système, où chaque étape est indiquée :
Le fichier de l'agent définit la classe principale LangManusAgent, qui orchestre tous les agents et maintient un contexte partagé pendant qu'ils exécutent leurs tâches.
from planner import plan_task
from agents.researcher import find_trending_repo
from agents.browser import scrape_github_activity
from agents.coder import analyze_code_activity
from agents.reporter import generate_report
class LangManusAgent:
def __init__(self, task):
self.task = task
self.context = {}
def run(self):
steps = plan_task(self.task)
for step in steps:
agent = step['agent']
task = step['task']
if agent == 'researcher':
self.context['repo'] = find_trending_repo()
elif agent == 'browser':
self.context['repo_data'] = scrape_github_activity(self.context['repo'])
elif agent == 'coder':
self.context['analysis'], self.context['chart_path'] = analyze_code_activity(self.context['repo_data'])
elif agent == 'reporter':
report = generate_report(
self.context['repo'],
self.context['repo_data'],
self.context['analysis'],
self.context['chart_path']
)
print(report)
def run_and_return(self):
self.run()
report = generate_report(
self.context['repo'],
self.context['repo_data'],
self.context['analysis'],
self.context['chart_path']
)
return report, self.context['chart_path']Le code commence par appeler la fonction plan_task() pour récupérer une liste d'étapes (définie dans planner.py). Ensuite, il exécute chaque étape en invoquant l'agent spécialisé approprié dans l'ordre suivant :
Chaque agent stocke ses résultats dans le dictionnaire context, ce qui permet aux agents en aval d'accéder aux résultats précédents et de s'en inspirer.
Maintenant que les fonctions de base sont prêtes, construisons les agents de notre application.
Cet agent identifie un projet Python open-source populaire à partir de GitHub en scrappant la base de données de GitHub Trending de GitHub.
import requests
from bs4 import BeautifulSoup
def find_trending_repo():
url = "https://github.com/trending/python"
res = requests.get(url)
soup = BeautifulSoup(res.text, 'html.parser')
repo = soup.select_one('article h2 a')['href'].strip()
return f"https://github.com{repo}"Voici comment cela fonctionne :
L'agent de navigation est utilisé pour récupérer l'activité récente du dépôt GitHub sélectionné. Il utilise l'API REST de GitHub pour collecter l'historique des livraisons et les métadonnées.
import requests
import os
def scrape_github_activity(repo_url):
token = os.getenv("GITHUB_TOKEN") # Set via environment or .env
headers = {"Authorization": f"Bearer {token}"} if token else {}
user_repo = "/".join(repo_url.split('/')[-2:])
api_url = f"https://api.github.com/repos/{user_repo}/commits"
res = requests.get(api_url, headers=headers)
res.raise_for_status()
data = res.json()
commits = []
commit_dates = []
for item in data[:20]: # optional: increase window for better activity chart
message = item['commit']['message']
author = item['commit']['author']['name']
date = item['commit']['author']['date']
sha = item['sha'][:7]
commits.append(f"[{sha}] {message} — {author} @ {date}")
commit_dates.append(date) # in ISO 8601 format (perfect for parsing)
return {
'repo_url': repo_url,
'commits': commits,
'commit_dates': commit_dates
}Voici ce que fait la fonction ci-dessus :
commits et commit_dates. Cet agent traite et analyse l'historique des livraisons collecté sur GitHub et génère à la fois un résumé textuel et des aperçus visuels à l'aide de matplotlib.
# agents/coder.py
import matplotlib.pyplot as plt
from collections import defaultdict, Counter
from datetime import datetime
import matplotlib.dates as mdates
import re
import os
def categorize_commit(message):
message = message.lower()
if any(kw in message for kw in ["fix", "bug"]):
return "🐛 Bug Fixes"
elif any(kw in message for kw in ["add", "feature", "implement"]):
return "✨ Features"
elif any(kw in message for kw in ["doc", "readme"]):
return "📄 Documentation"
elif any(kw in message for kw in ["remove", "delete"]):
return "🔥 Removals"
elif any(kw in message for kw in ["update", "upgrade"]):
return "🔧 Updates"
elif any(kw in message for kw in ["merge", "pull"]):
return "🔀 Merges"
else:
return "📦 Others"
def analyze_code_activity(repo_data):
commit_messages = repo_data['commits']
commit_dates = repo_data.get('commit_dates', [])
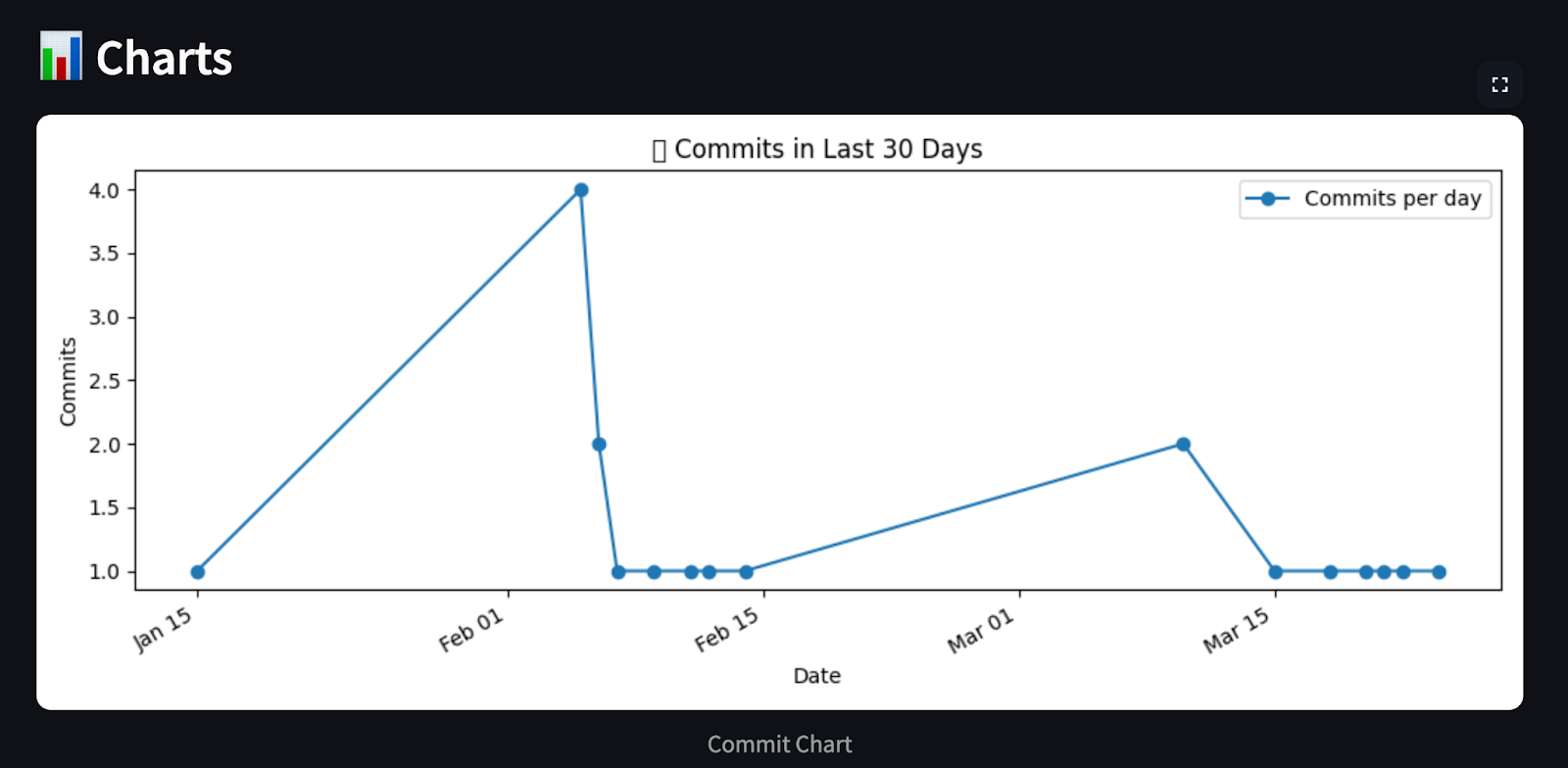
# Chart 1: Commits per day (last 30 days)
commit_day_counts = defaultdict(int)
for date in commit_dates:
day = datetime.fromisoformat(date).date()
commit_day_counts[day] += 1
recent_days = sorted(commit_day_counts.keys())
counts = [commit_day_counts[day] for day in recent_days]
plt.figure(figsize=(10, 4))
plt.plot(recent_days, counts, marker='o', linestyle='-', color='tab:blue', label='Commits per day')
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%b %d'))
plt.gcf().autofmt_xdate()
plt.xlabel("Date")
plt.ylabel("Commits")
plt.title("📈 Commits in Last 30 Days")
plt.legend()
path1 = "commit_chart.png"
plt.tight_layout()
plt.savefig(path1)
plt.close()
# Chart 2: Commits per category
commit_categories = defaultdict(list)
category_counter = Counter()
for msg in commit_messages:
short_msg = re.split(r'—|@', msg)[0].strip()
category = categorize_commit(short_msg)
commit_categories[category].append(short_msg)
category_counter[category] += 1
plt.figure(figsize=(8, 4))
cats, values = zip(*category_counter.items())
plt.bar(cats, values, color='tab:green')
plt.ylabel("Commits")
plt.title("🧩 Commits by Category")
path2 = "category_chart.png"
plt.tight_layout()
plt.savefig(path2)
plt.close()
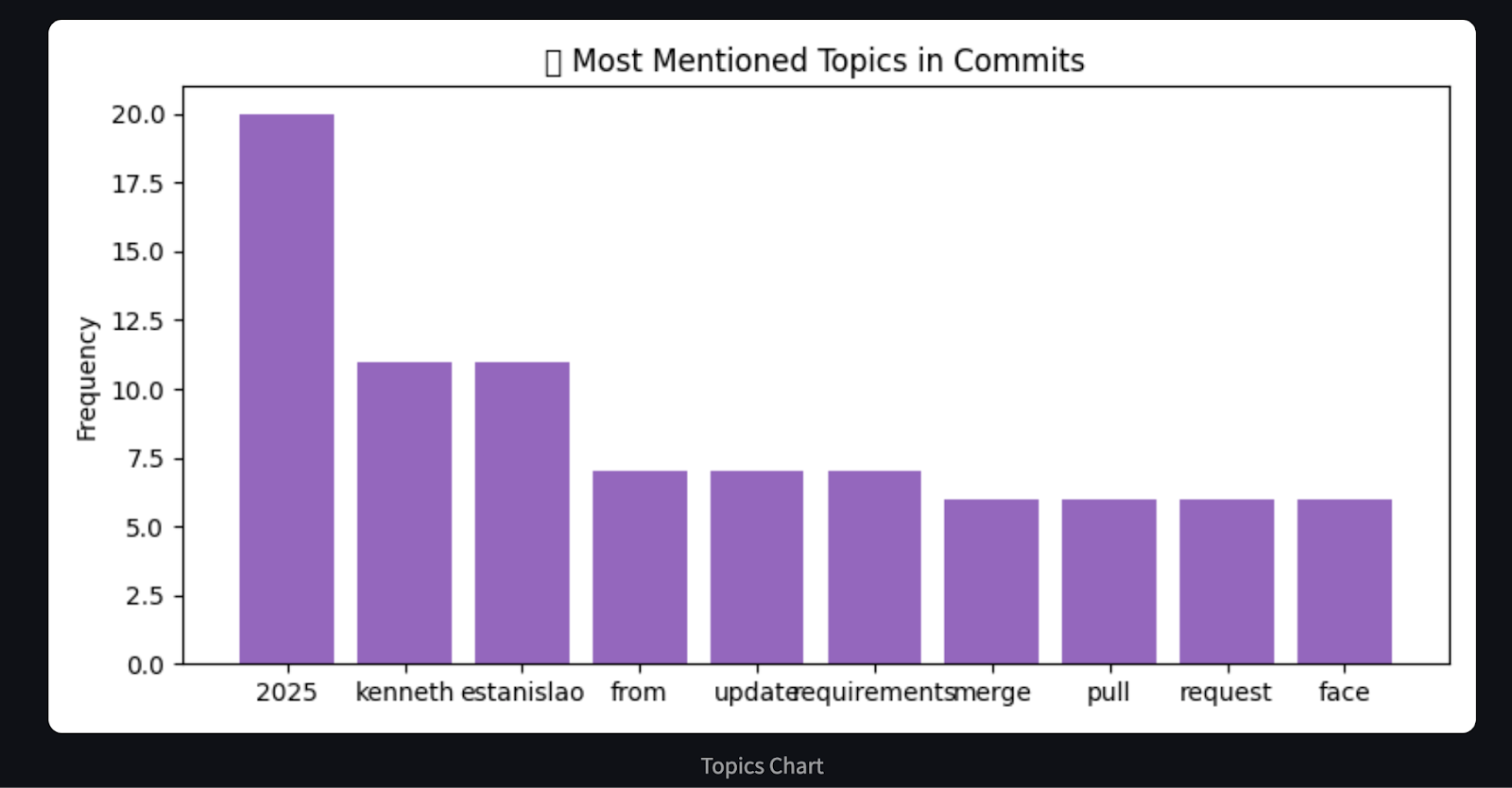
# Chart 3: Word frequency in commit messages (basic proxy for hot areas)
word_freq = Counter()
for msg in commit_messages:
words = re.findall(r'\b\w{4,}\b', msg.lower()) # only words with length >= 4
word_freq.update(words)
most_common = word_freq.most_common(10)
labels, freqs = zip(*most_common)
plt.figure(figsize=(8, 4))
plt.bar(labels, freqs, color='tab:purple')
plt.ylabel("Frequency")
plt.title("🔥 Most Mentioned Topics in Commits")
path3 = "topics_chart.png"
plt.tight_layout()
plt.savefig(path3)
plt.close()
# Build markdown report
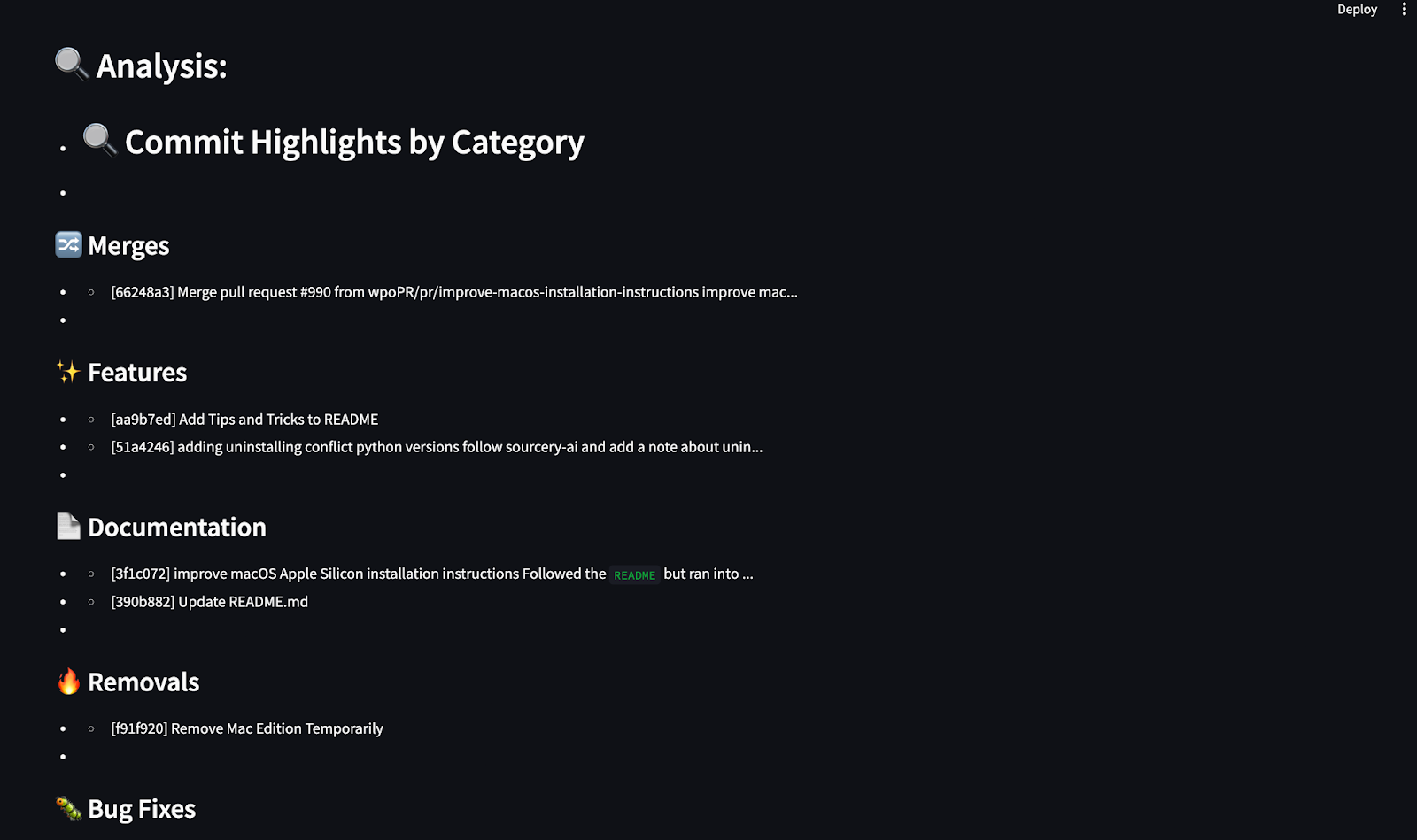
analysis = ["## 🔍 Commit Highlights by Category"]
for cat, msgs in commit_categories.items():
analysis.append(f"\n### {cat}")
for m in msgs[:3]:
clean_msg = m.replace("\n", " ").strip()
analysis.append(f"- {clean_msg[:100]}{'...' if len(clean_msg) > 100 else ''}")
charts = [path1, path2, path3]
return analysis, chartsCet agent traite l'historique des commits de GitHub et génère un résumé en Markdown et des graphiques visuels en utilisant matplotlib. Il catégorise les livraisons dans des groupes prédéfinis tels que les corrections de bogues, les fonctionnalités, la documentation, et plus encore, en utilisant des mots-clés. Il utilise ensuite le site matplotlib pour générer trois graphiques détaillés :
Enfin, l'agent crée un résumé en markdown mettant en évidence les principaux engagements dans chaque catégorie et renvoie les chemins du résumé et du graphique pour qu'ils soient affichés dans le rapport.
L'agent rapporteur génère le rapport Markdown final qui combine :
def generate_report(repo_url, repo_data, analysis, chart_path):
md = f"""# 🧠 GitHub Repo Analysis
## 🔗 Repo: [{repo_url}]({repo_url})
## 📝 Recent Commits:
"""
for c in repo_data['commits']:
md += f"- {c}\n"
md += "\n## 🔍 Analysis:\n"
for line in analysis:
md += f"- {line}\n"
return mdLa fonction generate_report() assemble le rapport Markdown final en utilisant l'URL GitHub, les données de livraison, l'analyse catégorisée et les chemins d'accès aux graphiques. Elle renvoie une chaîne unique formatée en markdown qui peut être affichée dans le terminal ou rendue dans une interface utilisateur comme Streamlit. Elle renvoie une chaîne unique formatée en markdown qui peut être imprimée sur la console ou rendue dans Streamlit.
L'application Streamlit permet aux utilisateurs d'exécuter l'ensemble du pipeline en un seul clic. Créez un fichier streamlit_app.py et ajoutez le code suivant :
import streamlit as st
from agent import LangManusAgent
import os
from PIL import Image
st.set_page_config(page_title="LangManus GitHub Analyzer", layout="wide")
st.title("🧠 LangManus GitHub Repo Analyzer")
if st.button("🔍 Run Analysis on Trending Repo"):
with st.spinner("Running LangManus agents..."):
agent = LangManusAgent(task="Find a popular open-source project updated recently and summarize its new features with examples and charts.")
report, chart_paths = agent.run_and_return()
st.markdown(report)
st.subheader("📊 Charts")
for path in chart_paths:
if os.path.exists(path):
st.image(Image.open(path), caption=os.path.basename(path).replace('_', ' ').replace('.png', '').title(), use_container_width=True)
else:
st.info("Click the button to run analysis on a trending GitHub Python repo.")Voici ce que fait le code :
streamlit pour créer un tableau de bord minimal qui déclenche la fonction LangManusAgent.run_and_return() lorsque l'on clique sur le bouton "Analyser".st.markdown() et parcourt en boucle chaque chemin de graphique, puis les rend à l'aide de la fonction st.image().La structure finale de notre projet d'analyse GitHub alimenté par LangManus devrait ressembler à ceci :
LangManus-GitHub-Demo/
├── main.py
├── agent.py
├── planner.py
├── streamlit_app.py
├── agents/
│ ├── researcher.py
│ ├── browser.py
│ ├── coder.py
│ └── reporter.py
├── commit_chart.png
├── category_chart.png
├── topics_chart.pngMaintenant que tous les composants sont en place, lançons notre application Streamlit. Exécutez la commande suivante dans le terminal :
streamlit run streamlit_app.py
Cliquez sur le bouton "Run Analysis on Trending Repo" dans votre navigateur, et vos agents LangManus récupéreront, analyseront et présenteront des informations sur les dépôts GitHub en quelques secondes.

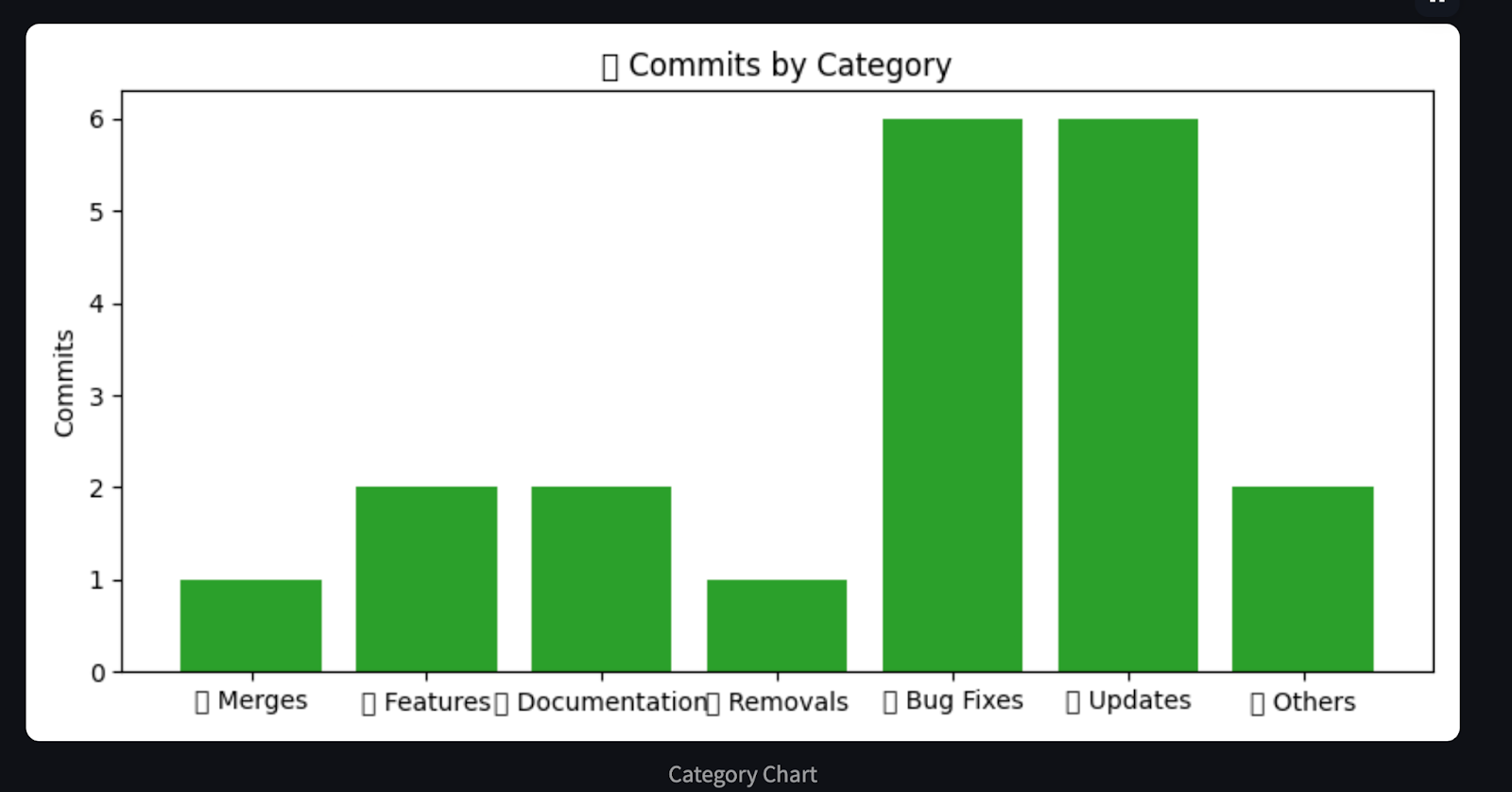
LangManus nous permet de construire des systèmes multi-agents structurés qui interagissent avec des données du monde réel. Dans ce guide, nous avons créé un analyseur de repo GitHub entièrement automatisé :
LangManus présente un potentiel important pour la création d'agents de recherche, de tableaux de bord et d'assistants axés sur les données.
Apprenez l'IA avec ces cours !
Cours
Cours
Cours
blog
Kurtis Pykes
15 min
blog
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach
blog
Nisha Arya Ahmed
15 min