
Curso
Desenvolvimento de aplicativos de LLM com LangChain
3 h
46.2K
LangManus é uma estrutura de automação de IA de código aberto e orientada pela comunidade, projetada para criar sistemas estruturados e multiagentes usando modelos de linguagem. Com o LangManus, você pode criar agentes inteligentes que combinam planejamento, pesquisa, codificação, interação com o navegador e geração de relatórios em um único pipeline coeso.
Neste tutorial, orientarei você a criar uma demonstração funcional com o LangManus:
A arquitetura do LangManus oferece suporte a controle refinado, capacidade de auditoria e extensibilidade. Ele se baseia em ferramentas poderosas como:
Com o LangManus, você pode criar agentes inteligentes que combinam planejamento, pesquisa, codificação, interação com o navegador e geração de relatórios em um único pipeline coeso, alimentado por:
YAML ou .env-based configuração para modelos e chaves.O aplicativo que criaremos é um assistente interativo que usa os recursos multiagentes do LangManus para analisar um repositório de tendências do GitHub. Para configurar os agentes LangManus, precisamos de uma estrutura de vários arquivos em que cada arquivo desempenhe uma função distinta no sistema de vários agentes:
Vamos implementá-las uma a uma.
Antes de começarmos, vamos garantir que você tenha as seguintes ferramentas e bibliotecas instaladas:
python3 --version # Python 3.8+
pip install requests beautifulsoup4 matplotlib streamlitVerifique a versão do Python, que deve ser pelo menos 3.8 ou superior. Em seguida, basta instalar todas as outras dependências mencionadas acima. Você também precisará de um token da API do GitHub para evitar limites de taxa e defini-lo como uma variável de ambiente usando o terminal.
Para gerar tokens do GitHub:
Agora, execute o seguinte comando:
export GITHUB_TOKEN=your_personal_token_hereAgora que temos todas as dependências instaladas, vamos criar o planejador e o controlador do agente para o nosso aplicativo.
O arquivo planner.py define um plano simples de quatro etapas para cobrir cada tarefa necessária, como pesquisa, navegação, análise e relatório.
def plan_task(user_query):
return [
{'agent': 'researcher', 'task': 'Find trending repo'},
{'agent': 'browser', 'task': 'Scrape GitHub activity'},
{'agent': 'coder', 'task': 'Analyze recent commits and features'},
{'agent': 'reporter', 'task': 'Generate Markdown report'}
]A função acima retorna um plano de tarefas passo a passo para o sistema em que cada etapa:
O arquivo do agente define o núcleo da classe LangManusAgent, que orquestra todos os agentes e mantém um contexto compartilhado à medida que eles executam suas tarefas.
from planner import plan_task
from agents.researcher import find_trending_repo
from agents.browser import scrape_github_activity
from agents.coder import analyze_code_activity
from agents.reporter import generate_report
class LangManusAgent:
def __init__(self, task):
self.task = task
self.context = {}
def run(self):
steps = plan_task(self.task)
for step in steps:
agent = step['agent']
task = step['task']
if agent == 'researcher':
self.context['repo'] = find_trending_repo()
elif agent == 'browser':
self.context['repo_data'] = scrape_github_activity(self.context['repo'])
elif agent == 'coder':
self.context['analysis'], self.context['chart_path'] = analyze_code_activity(self.context['repo_data'])
elif agent == 'reporter':
report = generate_report(
self.context['repo'],
self.context['repo_data'],
self.context['analysis'],
self.context['chart_path']
)
print(report)
def run_and_return(self):
self.run()
report = generate_report(
self.context['repo'],
self.context['repo_data'],
self.context['analysis'],
self.context['chart_path']
)
return report, self.context['chart_path']O código começa chamando a função plan_task() para recuperar uma lista de etapas (definida em planner.py). Em seguida, ele executa cada etapa invocando o agente especializado apropriado na seguinte ordem:
Cada agente armazena seus resultados no dicionário context, permitindo que os agentes posteriores acessem e se baseiem nos resultados anteriores.
Agora que temos as funções principais prontas, vamos criar os agentes para o nosso aplicativo.
Esse agente identifica um projeto popular de Python de código aberto do GitHub, raspando os dados de tendências do Tendências do GitHub do GitHub.
import requests
from bs4 import BeautifulSoup
def find_trending_repo():
url = "https://github.com/trending/python"
res = requests.get(url)
soup = BeautifulSoup(res.text, 'html.parser')
repo = soup.select_one('article h2 a')['href'].strip()
return f"https://github.com{repo}"Veja como isso funciona:
O agente do navegador é usado para buscar a atividade recente do repositório GitHub selecionado. Ele usa a API REST do GitHub para reunir o histórico e os metadados do commit.
import requests
import os
def scrape_github_activity(repo_url):
token = os.getenv("GITHUB_TOKEN") # Set via environment or .env
headers = {"Authorization": f"Bearer {token}"} if token else {}
user_repo = "/".join(repo_url.split('/')[-2:])
api_url = f"https://api.github.com/repos/{user_repo}/commits"
res = requests.get(api_url, headers=headers)
res.raise_for_status()
data = res.json()
commits = []
commit_dates = []
for item in data[:20]: # optional: increase window for better activity chart
message = item['commit']['message']
author = item['commit']['author']['name']
date = item['commit']['author']['date']
sha = item['sha'][:7]
commits.append(f"[{sha}] {message} — {author} @ {date}")
commit_dates.append(date) # in ISO 8601 format (perfect for parsing)
return {
'repo_url': repo_url,
'commits': commits,
'commit_dates': commit_dates
}Veja o que a função acima faz:
commits e commit_dates. Esse agente processa e analisa o histórico de commits coletado do GitHub e gera um resumo textual e insights visuais usando o matplotlib.
# agents/coder.py
import matplotlib.pyplot as plt
from collections import defaultdict, Counter
from datetime import datetime
import matplotlib.dates as mdates
import re
import os
def categorize_commit(message):
message = message.lower()
if any(kw in message for kw in ["fix", "bug"]):
return "🐛 Bug Fixes"
elif any(kw in message for kw in ["add", "feature", "implement"]):
return "✨ Features"
elif any(kw in message for kw in ["doc", "readme"]):
return "📄 Documentation"
elif any(kw in message for kw in ["remove", "delete"]):
return "🔥 Removals"
elif any(kw in message for kw in ["update", "upgrade"]):
return "🔧 Updates"
elif any(kw in message for kw in ["merge", "pull"]):
return "🔀 Merges"
else:
return "📦 Others"
def analyze_code_activity(repo_data):
commit_messages = repo_data['commits']
commit_dates = repo_data.get('commit_dates', [])
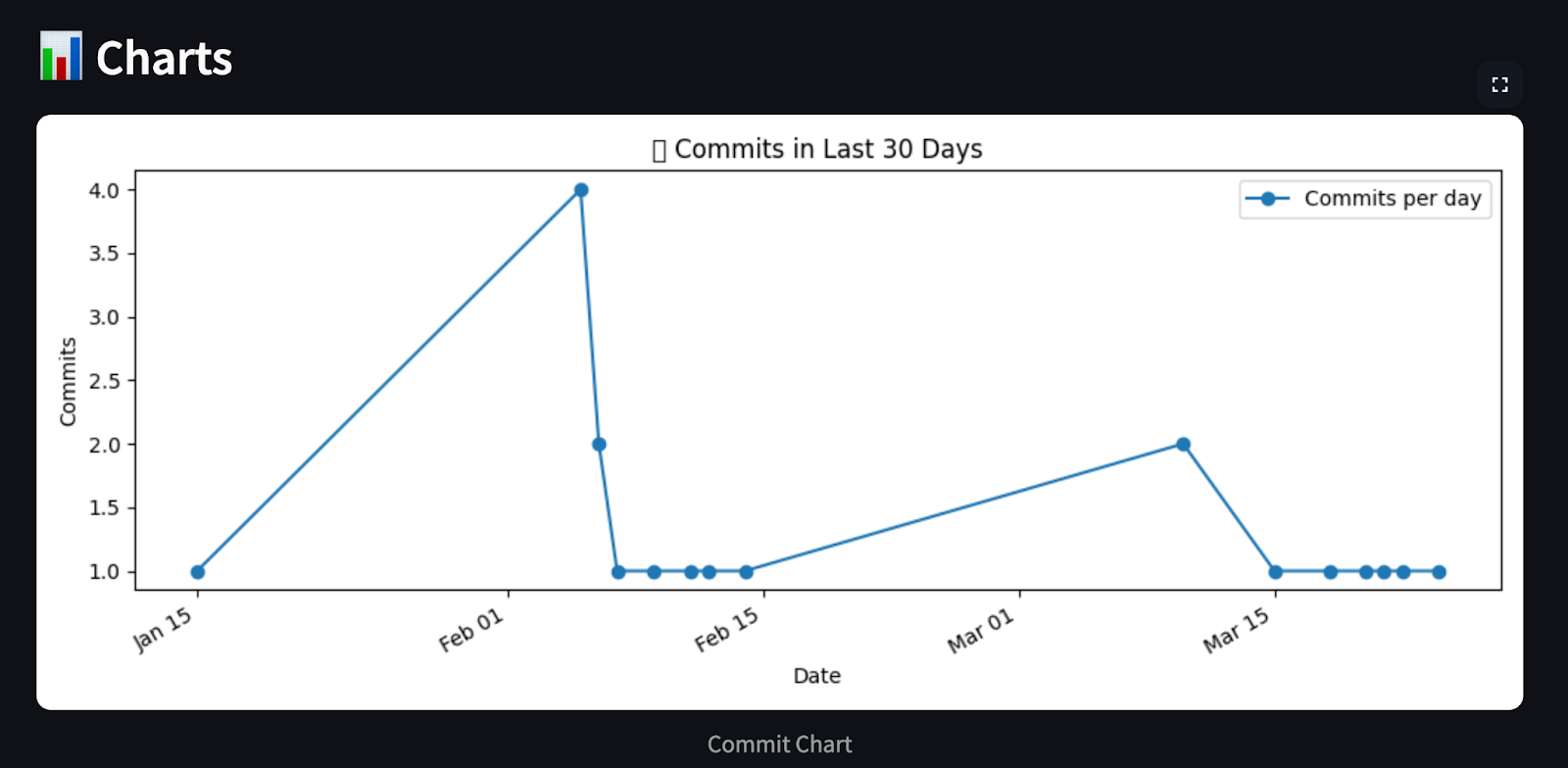
# Chart 1: Commits per day (last 30 days)
commit_day_counts = defaultdict(int)
for date in commit_dates:
day = datetime.fromisoformat(date).date()
commit_day_counts[day] += 1
recent_days = sorted(commit_day_counts.keys())
counts = [commit_day_counts[day] for day in recent_days]
plt.figure(figsize=(10, 4))
plt.plot(recent_days, counts, marker='o', linestyle='-', color='tab:blue', label='Commits per day')
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%b %d'))
plt.gcf().autofmt_xdate()
plt.xlabel("Date")
plt.ylabel("Commits")
plt.title("📈 Commits in Last 30 Days")
plt.legend()
path1 = "commit_chart.png"
plt.tight_layout()
plt.savefig(path1)
plt.close()
# Chart 2: Commits per category
commit_categories = defaultdict(list)
category_counter = Counter()
for msg in commit_messages:
short_msg = re.split(r'—|@', msg)[0].strip()
category = categorize_commit(short_msg)
commit_categories[category].append(short_msg)
category_counter[category] += 1
plt.figure(figsize=(8, 4))
cats, values = zip(*category_counter.items())
plt.bar(cats, values, color='tab:green')
plt.ylabel("Commits")
plt.title("🧩 Commits by Category")
path2 = "category_chart.png"
plt.tight_layout()
plt.savefig(path2)
plt.close()
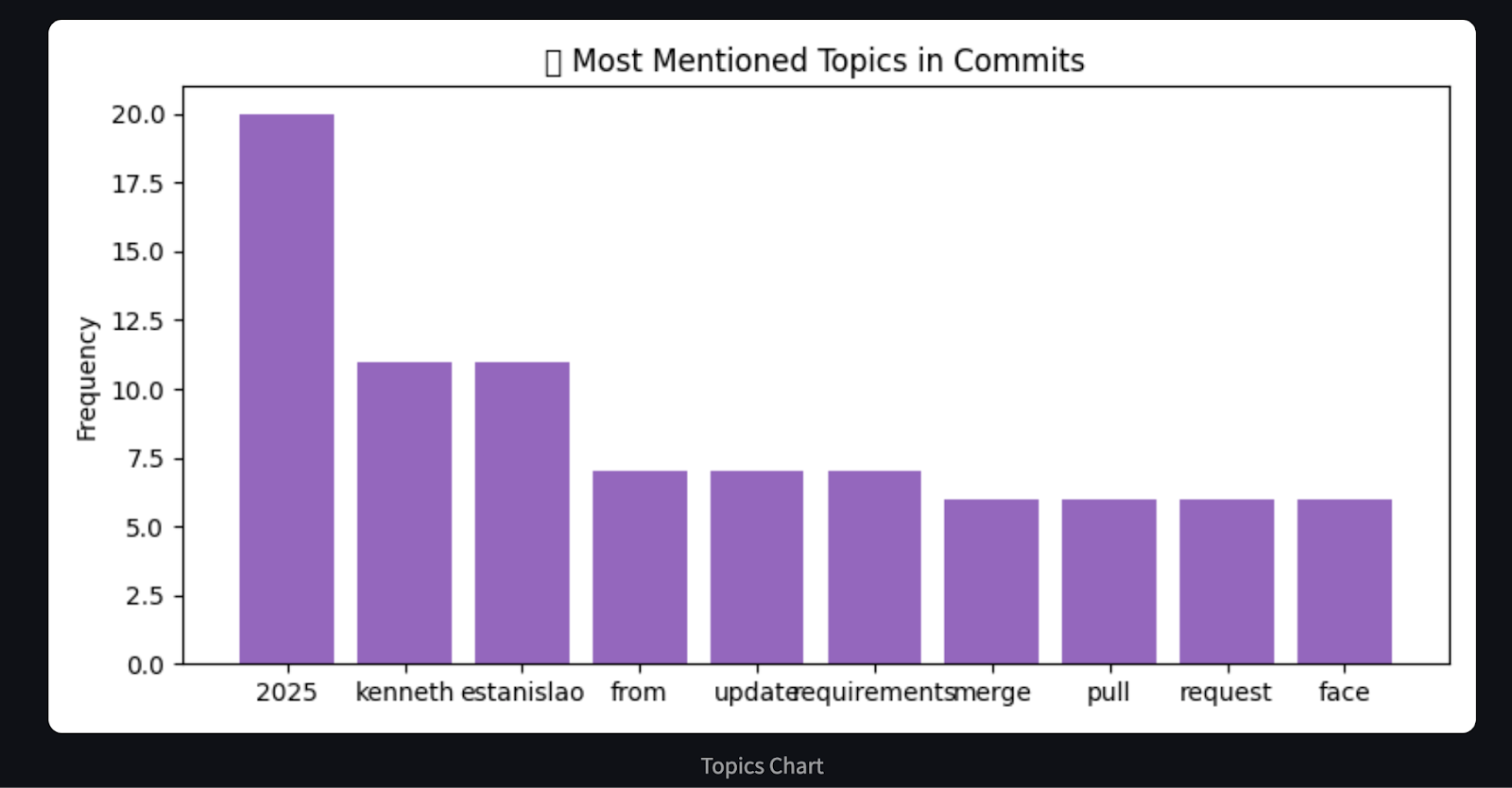
# Chart 3: Word frequency in commit messages (basic proxy for hot areas)
word_freq = Counter()
for msg in commit_messages:
words = re.findall(r'\b\w{4,}\b', msg.lower()) # only words with length >= 4
word_freq.update(words)
most_common = word_freq.most_common(10)
labels, freqs = zip(*most_common)
plt.figure(figsize=(8, 4))
plt.bar(labels, freqs, color='tab:purple')
plt.ylabel("Frequency")
plt.title("🔥 Most Mentioned Topics in Commits")
path3 = "topics_chart.png"
plt.tight_layout()
plt.savefig(path3)
plt.close()
# Build markdown report
analysis = ["## 🔍 Commit Highlights by Category"]
for cat, msgs in commit_categories.items():
analysis.append(f"\n### {cat}")
for m in msgs[:3]:
clean_msg = m.replace("\n", " ").strip()
analysis.append(f"- {clean_msg[:100]}{'...' if len(clean_msg) > 100 else ''}")
charts = [path1, path2, path3]
return analysis, chartsEsse agente processa o histórico de commits do GitHub e gera um resumo Markdown e gráficos visuais usando matplotlib. Ele categoriza os commits em grupos predefinidos, como correções de bugs, recursos, documentação e muito mais, usando a correspondência de palavras-chave. Em seguida, ele usa o site matplotlib para gerar três gráficos detalhados que mostram o que você precisa saber:
Por fim, o agente cria um resumo markdown destacando os principais commits em cada categoria e retorna os caminhos do resumo e do gráfico para renderização no relatório.
O agente repórter gera o relatório Markdown final que combina:
def generate_report(repo_url, repo_data, analysis, chart_path):
md = f"""# 🧠 GitHub Repo Analysis
## 🔗 Repo: [{repo_url}]({repo_url})
## 📝 Recent Commits:
"""
for c in repo_data['commits']:
md += f"- {c}\n"
md += "\n## 🔍 Analysis:\n"
for line in analysis:
md += f"- {line}\n"
return mdA função generate_report() monta o relatório Markdown final usando o URL do GitHub, os dados do commit, a análise categorizada e os caminhos do gráfico. Ele retorna uma única string formatada em markdown que pode ser exibida no terminal ou renderizada em uma interface do usuário como Streamlit. Ele retorna uma única string formatada em markdown que pode ser impressa no console ou renderizada no Streamlit.
O aplicativo Streamlit permite que os usuários executem todo o pipeline com um único clique. Crie um arquivo streamlit_app.py e adicione o seguinte código:
import streamlit as st
from agent import LangManusAgent
import os
from PIL import Image
st.set_page_config(page_title="LangManus GitHub Analyzer", layout="wide")
st.title("🧠 LangManus GitHub Repo Analyzer")
if st.button("🔍 Run Analysis on Trending Repo"):
with st.spinner("Running LangManus agents..."):
agent = LangManusAgent(task="Find a popular open-source project updated recently and summarize its new features with examples and charts.")
report, chart_paths = agent.run_and_return()
st.markdown(report)
st.subheader("📊 Charts")
for path in chart_paths:
if os.path.exists(path):
st.image(Image.open(path), caption=os.path.basename(path).replace('_', ' ').replace('.png', '').title(), use_container_width=True)
else:
st.info("Click the button to run analysis on a trending GitHub Python repo.")Aqui está o que o código faz:
streamlit para criar um painel mínimo que, ao clicar no botão "analyse the", aciona a função LangManusAgent.run_and_return().st.markdown() e percorre cada caminho de gráfico e, em seguida, os renderiza usando a função st.image().A estrutura final do nosso projeto de análise do GitHub com tecnologia LangManus deve ter a seguinte aparência:
LangManus-GitHub-Demo/
├── main.py
├── agent.py
├── planner.py
├── streamlit_app.py
├── agents/
│ ├── researcher.py
│ ├── browser.py
│ ├── coder.py
│ └── reporter.py
├── commit_chart.png
├── category_chart.png
├── topics_chart.pngAgora que temos todos os componentes instalados, vamos executar nosso aplicativo Streamlit. Execute o seguinte comando no terminal:
streamlit run streamlit_app.py
Clique no botão "Run Analysis on Trending Repo" (Executar análise no repositório de tendências) em seu navegador e seus agentes com tecnologia LangManus buscarão, analisarão e apresentarão insights sobre o repositório do GitHub em segundos.

O LangManus nos permite criar sistemas multiagentes estruturados que interagem com dados do mundo real. Neste guia, criamos um analisador de repositório do GitHub totalmente automatizado, no qual você pode usar o GitHub:
O LangManus tem um grande potencial para a criação de agentes de pesquisa, painéis de controle e assistentes orientados por dados.
Aprenda IA com estes cursos!
Curso
Curso
Curso
Tutorial
Moez Ali
Tutorial
Bex Tuychiev
Tutorial
Josep Ferrer
Tutorial
Moez Ali
Tutorial
Matt Crabtree

