
programa
Llama Fundamentals
4 h
Recientemente, NVIDIA ha lanzado un modelo innovador llamado LLaMA-Mallaque es capaz de generar mallas 3D a partir de descripciones en texto plano.
También funciona a la inversa: dada una malla 3D, el modelo puede identificar el objeto.
Se trata de un avance significativo para el aprendizaje automático, ya que comprender el espacio 3D es un paso crucial hacia la AGI. LLaMA-Mesh es también una valiosa herramienta para los profesionales y aficionados que trabajan frecuentemente con software como Blender, ya que agiliza el proceso de generación y uso de mallas 3D.
En esta breve guía, te explicaré las capacidades del modelo y pondré algunos ejemplos para ayudarte a comprender su potencial y sus limitaciones.
LLaMA-Mesh es un modelo innovador desarrollado por NVIDIA que amplía las capacidades de los grandes modelos lingüísticos (LLM) al dominio 3D.
A diferencia de cualquier modelo anterior, LLaMA-Mesh unifica las modalidades de texto y 3D, permitiendo a los usuarios crear mallas 3D mediante sencillas indicaciones en lenguaje natural.
Bajo el capó, el modelo es un afinado LLaMa-3.1-8B-Instrucción. El modelo funciona codificando los datos de la malla 3D en un formato basado en texto, concretamente utilizando el estándar de archivo OBJ, que describe los vértices y las caras como texto sin formato.
Hay tres formas de utilizar el modelo:
Este es el aspecto de la WebApp de demostración:
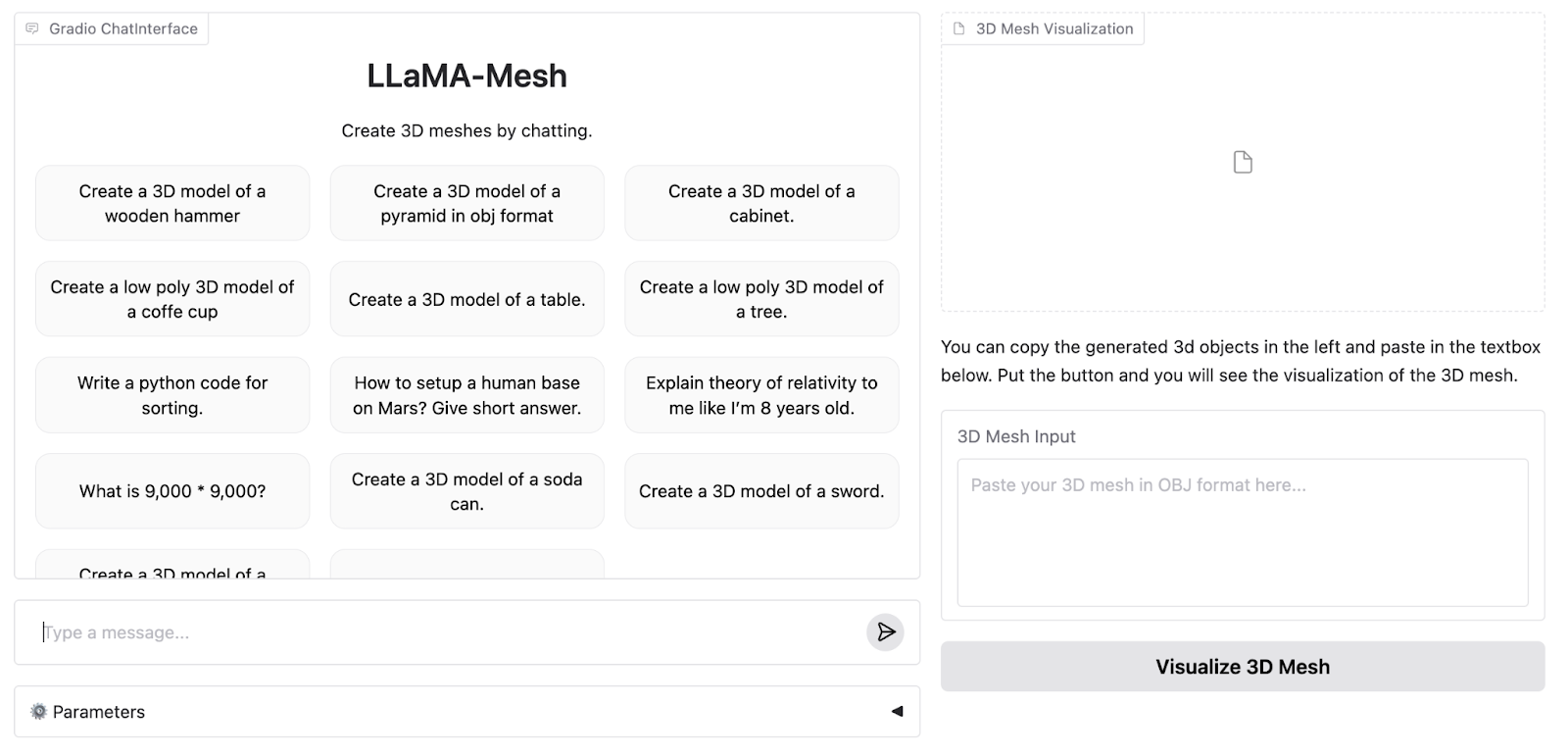
La demo online admite hasta 4096 fichas, mientras que el modelo completo admite 8K. Por lo tanto, necesitamos ejecutar el modelo localmente para experimentar todas sus capacidades.
A continuación, generaré tres ejemplos de formas de dificultad creciente para probar las limitaciones del modelo. Ejecutaré los ejemplos tanto en la versión 4K como en la versión 8K del modelo para ver en qué se diferencian.
Para esta guía, demostraré la ejecución del modelo utilizando el tiempo de ejecución de la GPU A100 de Google Colab. Si tienes suficiente potencia de cálculo a nivel local, el mismo código se puede adaptar para que funcione en tu hardware personal. El repositorio Cara Abrazada está disponible aquí.
Para empezar, tenemos que importar las bibliotecas necesarias y descargar el modelo y el tokenizador:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = "Zhengyi/LLaMA-Mesh"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto").cuda()También tenemos que fijar la dirección pad_token:
if tokenizer.pad_token_id is None:
tokenizer.pad_token_id = tokenizer.eos_token_idPor último, tenemos que tokenizar el aviso y alimentarlo a un modelo para su inferencia (todo esto es un flujo de trabajo estándar de Huggingface que funciona con casi cualquier otro modelo):
prompt = "Create a 3D model of an original designer chair."
inputs = tokenizer(prompt, return_tensors="pt", padding=True)
input_ids = inputs.input_ids.cuda()
output = model.generate(
input_ids,
attention_mask=inputs['attention_mask'], # Provide the attention_mask
max_length=8000,
)Los autores no especifican los hiperparámetros que utilizan en la demostración de la aplicación web, así que, para ser justos, utilizaré los predeterminados para nuestra comparación.
A continuación, repasaré tres ejemplos de dificultad creciente y compararé los resultados de la aplicación de demostración con los que obtuve ejecutando el modelo en Colab.
Empezaremos con algo sencillo pero creativo: una silla de diseño. Aquí tienes la solicitud (añado al final una petición para que la malla se genere en formato OBJ porque el modelo que se ejecuta localmente a veces se niega a generar nada de otro modo):
Create a 3D model of an original designer chair in OBJ format.Aquí tienes el objeto generado en la demo online:

Es sin duda una silla chula y extraña, aunque se parece más a la silla de un director de cine que a la de un diseñador.
Ahora, vamos a intentar ejecutar la consulta localmente y visualizar el resultado. Esto es lo que conseguimos:

Visualización en malla 3D de una silla
La malla con un contexto mayor parece más detallada. Sin embargo, la silla se parece más a un sofá, en mi opinión.
A continuación, probemos con un objeto geométrico: un toroide (un donut en 3D). La indicación para este ejemplo es:
Create a 3D model of a torus in OBJ format.Este es el aspecto de la malla generada por un modelo 4096:

Torus generado por el modelo
Por otro lado, aquí tienes la visualización de la malla generada por el modelo que se ejecuta en Colab:

Torus generado por el modelo
Como puedes ver, esta malla tiene muchos más polígonos. Sin embargo, sigue sin tener un agujero en el centro. Este es el aspecto que debe tener un toroide:
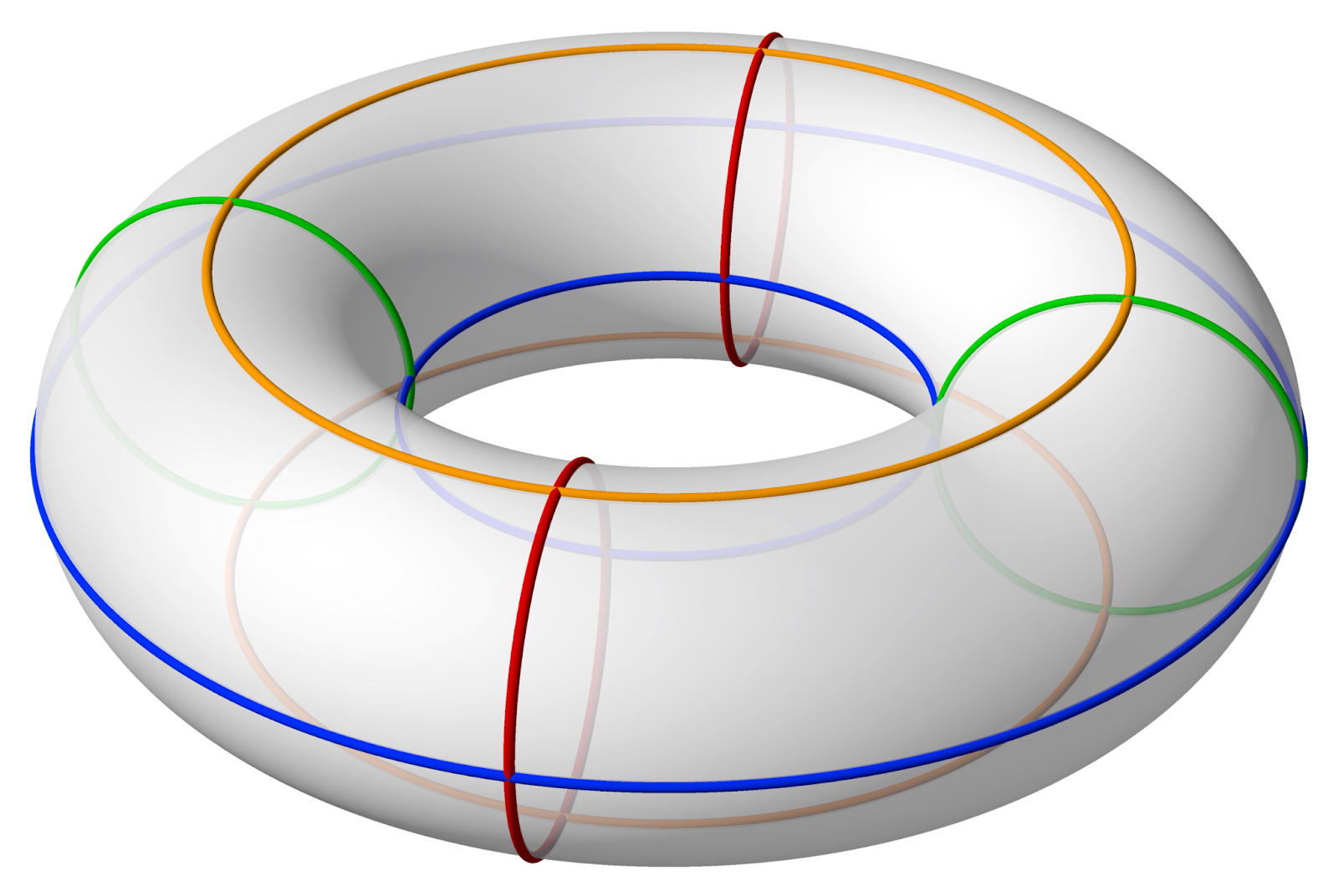
Fuente: Wikipedia
Por último, superemos los límites con una botella de Klein, una compleja estructura tridimensional. La indicación para ello será:
Create a 3D model of a Klein bottle in OBJ format.El modelo en línea sigue generando una malla sin cesar a partir de esta entrada, hasta que finalmente se agota y da un error.
Ejecutar la consulta localmente con una ventana contextual más grande soluciona el problema, sin embargo la malla que obtenemos no se parece en nada a una botella klein:

Botella de Klein generada por el modelo
Este es el aspecto de la botella Klein para los que estén interesados:
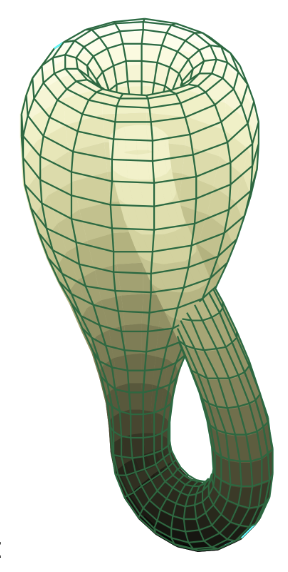
Fuente: Wikipedia
De las pruebas anteriores se desprende claramente que, aunque LLaMA-Mesh (tanto en su versión en línea como local) destaca en diseños creativos y sencillos, se enfrenta a limitaciones con formas geométricas precisas y matemáticas muy complejas. A medida que evolucione el modelo, será emocionante ver cómo se amplían estas capacidades.
En esta guía, exploramos el nuevo modelo LLaMa-Mesh de Nvidia y realizamos algunos ejemplos en su plataforma de demostración. Aunque el modelo está en sus primeras fases, sigue siendo muy prometedor para los profesionales y aficionados que necesitan soluciones rápidas e intuitivas para generar mallas 3D.
A medida que evolucione el marco, las futuras actualizaciones pueden aportar capacidades ampliadas, como el manejo de geometrías más complejas o la compatibilidad con impresoras 3D.
¡Aprende Llama con estos cursos!
programa
Curso
Curso
blog
Stanislav Karzhev
9 min
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
Tutorial
Ryan Ong
Tutorial
Zoumana Keita

