
programa
Fundamentos de la IA
10 h
Los grandes modelos lingüísticos (LLM) están revolucionando diversos sectores. Desde los chatbots de atención al cliente hasta las sofisticadas herramientas de análisis de datos, las capacidades de esta potente tecnología están remodelando el panorama de la interacción digital y la automatización.
Sin embargo, las aplicaciones prácticas de los LLM pueden verse limitadas por la necesidad de una informática de gran potencia o la necesidad de tiempos de respuesta rápidos. Estos modelos suelen requerir un hardware sofisticado y amplias dependencias, lo que puede dificultar su adopción en entornos más restringidos.
Aquí es donde LLaMa.cpp (o LLaMa C++) viene al rescate, proporcionando una alternativa más ligera y portátil a los frameworks pesados.

Llama.cpp logo(fuente)
Llama.cpp fue desarrollado por Georgi Gerganov. Implementa la arquitectura LLaMa de Meta en C/C++ eficiente, y es una de las comunidades de código abierto más dinámicas en torno a la inferencia LLM, con más de 900 colaboradores, más de 69000 estrellas en el repositorio oficial de GitHub y más de 2600 versiones.
Algunas ventajas clave de utilizar LLama.cpp para la inferencia LLM
Con este conocimiento de Llama.cpp, las siguientes secciones de este tutorial recorren el proceso de implementación de un caso de uso de generación de texto. Empezaremos explorando los fundamentos de LLama.cpp, comprendiendo el flujo de trabajo global de principio a fin del proyecto que nos ocupa y analizando algunas de sus aplicaciones en distintos sectores.
La columna vertebral de Llama.cpp son los modelos originales de Llama, que también se basan en la arquitectura de transformadores. Los autores de Llama aprovecharon varias mejoras que se propusieron posteriormente y utilizaron distintos modelos, como el PaLM.
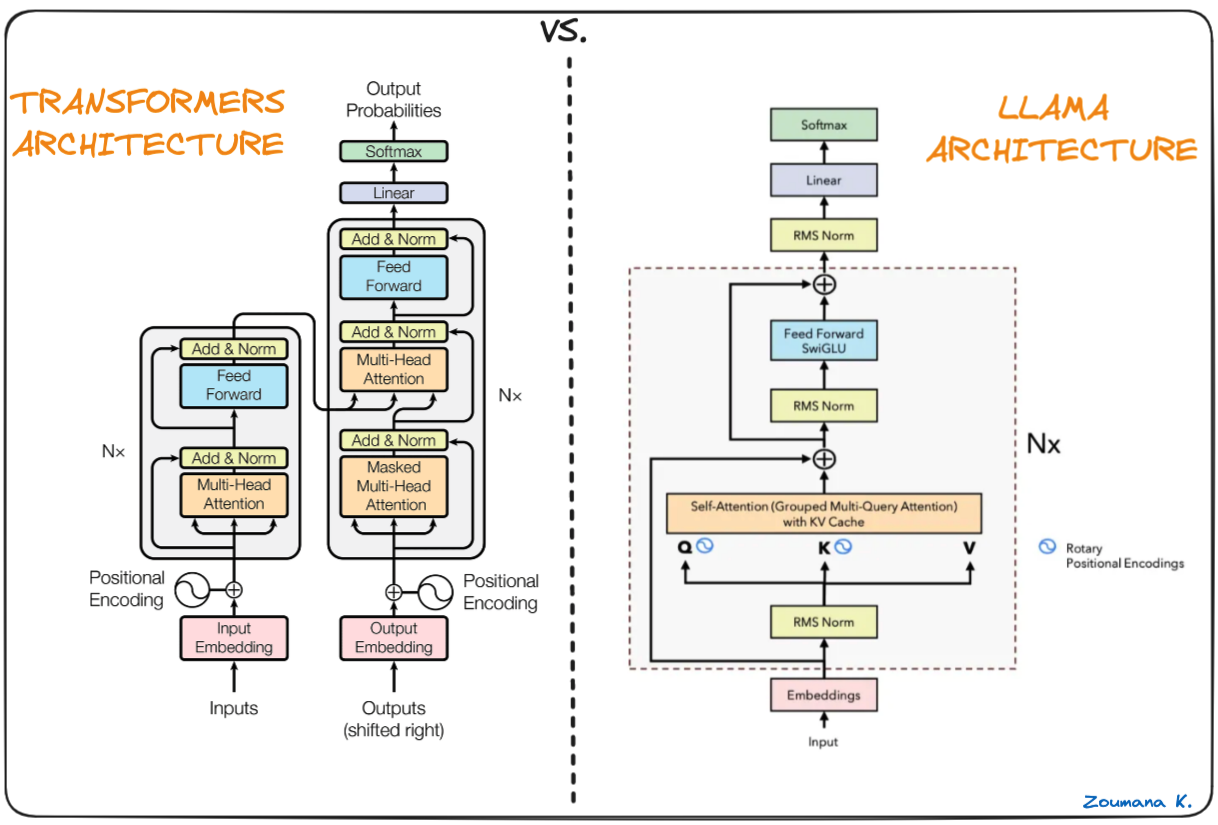
Diferencia entre los Transformers y la arquitectura Llama (Arquitectura Llama por Umar Jamil)
La principal diferencia entre la arquitectura LLaMa y la de los transformadores:
Los requisitos previos para empezar a trabajar con LLama.cpp son:
Python: para poder ejecutar pip, que es el gestor de paquetes de PythonLlama-cpp-python: el enlace Python para llama.cppSe recomienda crear un entorno virtual para evitar cualquier problema relacionado con el proceso de instalación, y conda puede ser un buen candidato para la creación del entorno.
Todos los comandos de esta sección se ejecutan desde un terminal. Utilizando la sentencia conda create, creamos un entorno virtual llamado llama-cpp-env.
conda create --name llama-cpp-envUna vez creado con éxito el entorno virtual, lo activamos mediante la sentencia conda activate, como se indica a continuación de:
conda activate llama-cpp-envLa declaración anterior debería mostrar el nombre de la variable de entorno entre paréntesis al principio del terminal, como se indica a continuación:

Nombre del entorno virtual tras la activación
Ahora, podemos instalar el paquete llama-cpp-python del siguiente modo:
pip install llama-cpp-python
or
pip install llama-cpp-python==0.1.48La ejecución correcta de llama_cpp_script.py significa que la biblioteca está correctamente instalada.
Para asegurarnos de que la instalación se realiza correctamente, vamos a crear y añadir la declaración import y, a continuación, a ejecutar el script.
from llama_cpp import Llama al archivo llama_cpp_script.py, y luegollama_cpp_script.py. Si la biblioteca no se importa, se produce un error; por lo tanto, necesita un diagnóstico más detallado para el proceso de instalación.En esta fase, el proceso de instalación debería ser satisfactorio. Vamos a sumergirnos en la comprensión de los fundamentos de LLama.cpp.
La clase Llama importada anteriormente es el constructor principal que se aprovecha al utilizar Llama.cpp, y toma varios parámetros y no se limita a los que se indican a continuación. La lista completa de parámetros figura en la documentación oficial:
model_path: La ruta al archivo del modelo Llama que se está utilizandoprompt: El mensaje de entrada al modelo. Este texto se tokeniza y se pasa al modelo.device: El dispositivo que se utilizará para ejecutar el modelo Llama; dicho dispositivo puede ser una CPU o una GPU.max_tokens: El número máximo de fichas que se generarán en la respuesta del modelostop: Una lista de cadenas que harán que se detenga el proceso de generación del modelotemperature: Este valor oscila entre 0 y 1. Cuanto menor sea el valor, más determinista será el resultado final. Por otra parte, un valor más alto conduce a una mayor aleatoriedad y, por tanto, a una producción más diversa y creativa.top_p: Se utiliza para controlar la diversidad de las predicciones, lo que significa que selecciona los tokens más probables cuya probabilidad acumulada supere un umbral determinado. Partiendo de cero, un valor más alto aumenta la probabilidad de encontrar un resultado mejor, pero requiere cálculos adicionales.echo: Un booleano utilizado para determinar si el modelo incluye la indicación original al principio (Verdadero) o no la incluye (Falso).Por ejemplo, consideremos que queremos utilizar un gran modelo lingüístico llamado almacenado en el directorio de trabajo actual. El proceso de instanciación será así:
# Instanciate the model
my_aweseome_llama_model = Llama(model_path="./MY_AWESOME_MODEL")
prompt = "This is a prompt"
max_tokens = 100
temperature = 0.3
top_p = 0.1
echo = True
stop = ["Q", "\n"]
# Define the parameters
model_output = my_aweseome_llama_model(
prompt,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
echo=echo,
stop=stop,
)
final_result = model_output["choices"][0]["text"].strip()El código se explica por sí mismo y puede entenderse fácilmente a partir de las viñetas iniciales que indican el significado de cada parámetro.
El resultado del modelo es un diccionario que contiene la respuesta generada junto con algunos metadatos adicionales. El formato de la salida se explora en las siguientes secciones del artículo.
Ahora, es el momento de empezar con la ejecución del proyecto de generación de texto. Iniciar un nuevo proyecto Llama.El cpp no tiene más que seguir la plantilla de código Python anterior, que explica todos los pasos desde la carga del gran modelo lingüístico de interés hasta la generación de la respuesta final.
El proyecto aprovecha la versión GGUF del Zephyr-7B-Beta de Hugging Face. Es una versión perfeccionada del mistralai/Mistral-7B-v0.1 que se entrenó con una mezcla de conjuntos de datos sintéticos de acceso público mediante la Optimización de Preferencia Directa (OPD).
Nuestra Introducción al uso de Transformadores y Cara de Abrazo proporciona una mejor comprensión de los Transformadores y de cómo aprovechar su poder para resolver problemas de la vida real. También tenemos un tutorial de Mistral 7B.
Modelo Zephyr de Hugging Face(fuente)
Una vez descargado el modelo localmente, podemos moverlo a la ubicación del proyecto en la carpeta model. Antes de sumergirnos en la aplicación, entendamos la estructura del proyecto:

La estructura del proyecto
El primer paso es cargar el modelo utilizando el constructor Llama. Como se trata de un modelo grande, es importante especificar el tamaño máximo del contexto del modelo que se va a cargar. En este proyecto concreto, utilizamos 512 fichas.
from llama_cpp import Llama
# GLOBAL VARIABLES
my_model_path = "./model/zephyr-7b-beta.Q4_0.gguf"
CONTEXT_SIZE = 512
# LOAD THE MODEL
zephyr_model = Llama(model_path=my_model_path,
n_ctx=CONTEXT_SIZE)Una vez cargado el modelo, el siguiente paso es la fase de generación de texto, utilizando el modelo de código original, pero en su lugar utilizamos una función de ayuda llamada generate_text_from_prompt.
def generate_text_from_prompt(user_prompt,
max_tokens = 100,
temperature = 0.3,
top_p = 0.1,
echo = True,
stop = ["Q", "\n"]):
# Define the parameters
model_output = zephyr_model(
user_prompt,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
echo=echo,
stop=stop,
)
return model_outputDentro de la cláusula __main__, la función puede ejecutarse utilizando un indicador dado.
if __name__ == "__main__":
my_prompt = "What do you think about the inclusion policies in Tech companies?"
zephyr_model_response = generate_text_from_prompt(my_prompt)
print(zephyr_model_response)A continuación se ofrece la respuesta del modelo:

La respuesta del modelo
La respuesta generada por el modelo es y la respuesta exacta del modelo está resaltada en el recuadro naranja.
Aunque esta salida completa puede ser útil para usos posteriores, puede que sólo nos interese la respuesta textual del modelo. Podemos formatear la respuesta para obtener dicho resultado seleccionando el campo “text” del elemento "choices” de la siguiente manera:
final_result = model_output["choices"][0]["text"].strip()
La función strip() se utiliza para eliminar los espacios en blanco iniciales y finales de una cadena y el resultado es:
Tech companies want diverse workforces to build better products.Esta sección recorre una aplicación real de LLama.cpp y proporciona el problema subyacente, la posible solución y las ventajas de utilizar Llama.cpp.
Imagina ETP4Africa, una startup tecnológica que necesita un modelo lingüístico que pueda funcionar eficazmente en varios dispositivos para su aplicación educativa sin causar retrasos.
Implementan Llama.cpp, aprovechando su rendimiento optimizado para CPU y la capacidad de interactuar con su backend basado en Go.
La integración de Llama.cpp permite a la aplicación ETP4Africa ofrecer una guía de programación inmediata e interactiva, mejorando la experiencia y el compromiso del usuario.
La Ingeniería de Datos es un componente clave de cualquier proyecto de Ciencia de Datos e IA, y nuestro tutorial Introducción a LangChain para la Ingeniería de Datos y Aplicaciones de Datos proporciona una guía completa para incluir la IA de grandes modelos lingüísticos dentro de las canalizaciones y aplicaciones de datos.
En resumen, este artículo ha proporcionado una visión global de la configuración y utilización de grandes modelos lingüísticos con LLama.cpp.
Se proporcionaron instrucciones detalladas para ayudarte a comprender los fundamentos de Llama.cpp, configurar el entorno de trabajo, instalar la biblioteca necesaria e implementar un caso de uso de generación de texto (respuesta a preguntas).
Por último, se proporcionaron ideas prácticas para una aplicación del mundo real y cómo puede utilizarse Llama.cpp para abordar eficazmente el problema subyacente.
¿Estás listo para sumergirte más profundamente en el mundo de los grandes modelos lingüísticos? Mejora tus habilidades con los potentes marcos de aprendizaje profundo LangChain y Pytorch utilizados por los profesionales de la IA con nuestro tutorial Cómo crear aplicaciones LLM con LangChain y Cómo entrenar un LLM con PyTorch.
¡Comienza hoy tu viaje a la IA!
programa
Curso
Curso
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan
Tutorial
Ryan Ong
Tutorial
Arunn Thevapalan
Tutorial
Abid Ali Awan


