
Track
Llama Fundamentals
4 hr
Recently, NVIDIA released an innovative model called LLaMA-Mesh, which is capable of generating 3D meshes from plain text descriptions.
It also works the other way around: given a 3D mesh, the model can identify the object.
This is a significant advancement for machine learning, since understanding the 3D space is a crucial step towards AGI. LLaMA-Mesh is also a valuable tool for professionals and enthusiasts who frequently work with software like Blender, making the process of generating and using 3D meshes faster.
In this short guide, I’ll explain the model’s capabilities and run a few examples to help you understand its potential and limitations.
LLaMA-Mesh is an innovative model developed by NVIDIA that extends the capabilities of large language models (LLMs) to the 3D domain.
Unlike any model before it, LLaMA-Mesh unifies text and 3D modalities, allowing users to create 3D meshes through simple natural language prompts.
Under the hood, the model is a fine-tuned LLaMa-3.1-8B-Instruct. The model works by encoding 3D mesh data in a text-based format, specifically using the OBJ file standard, which describes vertices and faces as plain text.
There are three ways you can go about using the model:
This is what the demo WebApp looks like:
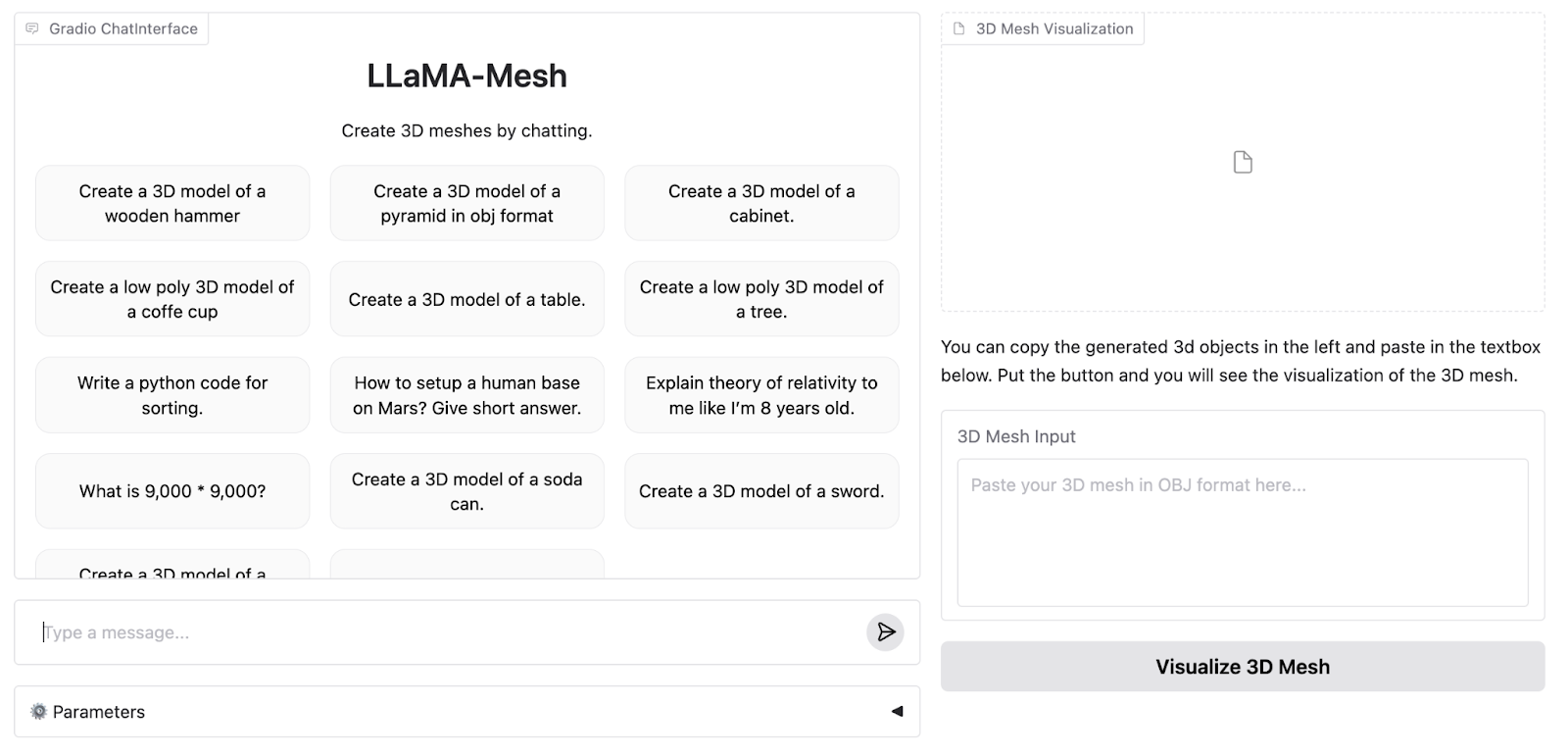
The online demo supports up to 4096 tokens, while the full model supports 8K. Therefore, we need to run the model locally to experience its full capabilities.
Next, I’ll generate three examples of shapes of increasing difficulty to test the model's limitations. I will run the examples on both the 4K and 8K token versions of the model to see how they differ.
For this guide, I will demonstrate running the model using Google Colab’s A100 GPU runtime. If you have sufficient computational power locally, the same code can be adapted to run on your personal hardware. The Hugging Face repository is available here.
To get started, we need to import the necessary libraries and download the model and the tokenizer:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = "Zhengyi/LLaMA-Mesh"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto").cuda()We also need to set the pad_token:
if tokenizer.pad_token_id is None:
tokenizer.pad_token_id = tokenizer.eos_token_idLastly, we need to tokenize the prompt and feed it into a model for inference (all of this is standard Huggingface workflow that works with almost any other model):
prompt = "Create a 3D model of an original designer chair."
inputs = tokenizer(prompt, return_tensors="pt", padding=True)
input_ids = inputs.input_ids.cuda()
output = model.generate(
input_ids,
attention_mask=inputs['attention_mask'], # Provide the attention_mask
max_length=8000,
)The authors do not specify the hyperparameters they use in the web app demo, so to be fair, I will use the defaults for our comparison.
I’ll now go through three examples of increasing difficulty and compare the output from the demo app with the output I got by running the model on Colab.
We’ll start with something simple but creative—a designer chair. Here’s the prompt (I am adding a request for the mesh to be generated in OBJ format at the end because the model running locally sometimes refuses to generate anything otherwise):
Create a 3D model of an original designer chair in OBJ format.Here is the generated object in the online demo:

It’s definitely a cool and strange chair, though it resembles a film director’s chair more than a designer’s.
Now, let’s try running the prompt locally and visualizing the outcome. This is what we get:

3D mesh visualization of a chair
The mesh with a bigger context looks more detailed. However, the chair looks more like a couch, in my opinion.
Next, let’s try a geometric object: a torus (a 3D donut). The prompt for this example is:
Create a 3D model of a torus in OBJ format.This is what the mesh generated by a 4096 model looks like:

Torus generated by the model
On the other hand, here is the visualization of the mesh generated by the model running on Colab:

Torus generated by the model
As you can see, this mesh has many more polygons. However, it still does not have a hole in the middle. This is what a torus should look like:
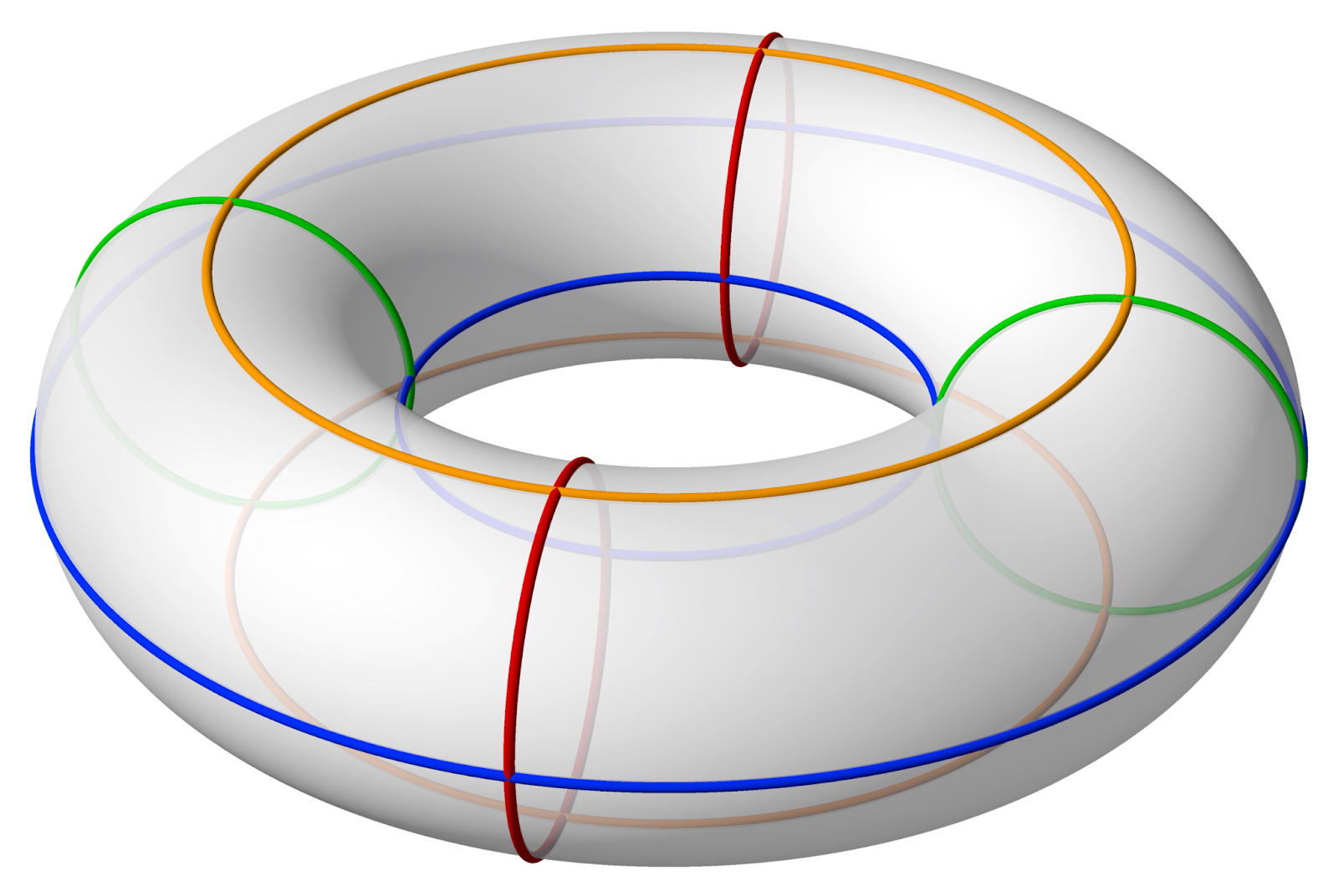
Source: Wikipedia
Finally, let’s push the limits with a Klein bottle—a complex 3D structure. The prompt for this will be:
Create a 3D model of a Klein bottle in OBJ format.The online model keeps generating a mesh endlessly given this input, until it finally times out itself and gives an error.
Running the prompt locally with a larger context window fixes the issue, however the mesh that we get looks nothing like a klein bottle:

Klein bottle generated by the model
This is what the Klein bottle looks like for those who are interested:
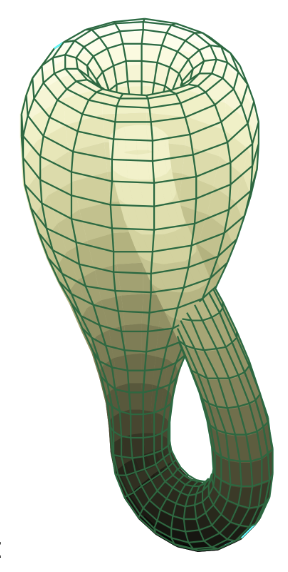
Source: Wikipedia
From the tests above, it’s clear that while LLaMA-Mesh (both online and local versions) excels at creative and simple designs, it faces limitations with precise geometric and highly complex mathematical shapes. As the model evolves, it will be exciting to see how these capabilities expand.
In this guide, we explored the new Nvidia LLaMa-Mesh model and did a few examples on their demo platform. While the model is in its early stages, it still shows tremendous promise for professionals and enthusiasts who need quick and intuitive solutions for generating 3D meshes.
As the framework evolves, future updates may bring expanded capabilities, such as handling more complex geometries or being compatible with 3D printers.
Learn Llama with these courses!
Track
Course
Course
blog
Alex Olteanu
8 min
blog
Bhavishya Pandit
8 min
Tutorial
Hesam Sheikh Hassani
Tutorial
Ryan Ong
Tutorial
Dr Ana Rojo-Echeburúa
Tutorial
Zoumana Keita


