programa
Desarrollar grandes modelos lingüísticos
16 h
En este tutorial, exploraremos cómo afinar el modelo Llama 3 8B utilizando la WebUI de LlaMA-Factory en el conjunto de datos de preguntas y respuestas de Wikipedia. Comenzaremos presentando la WebUI de LlaMA-Factory, seguida de su configuración en el entorno de Google Colab. Una vez configurado, recorreremos el proceso de ajuste del modelo Llama 3 8B en el conjunto de datos y, a continuación, evaluaremos el rendimiento del modelo a través de la interfaz del chat.
A medida que avancemos, también aprenderás a cargar conjuntos de datos personalizados, fusionar modelos y exportarlos a Cara de Abrazo. Por último, veremos cómo desplegar el modelo ajustado, haciéndolo accesible a través de la API de OpenAI.
Puedes adquirir conocimientos prácticos sobre temas populares de IA como ChatGPT, grandes modelos de lenguaje, IA generativa y mucho más cursando el curso Fundamentos de la IA de AI.

Imagen del autor | Canva
hiyouga/LLaMA-Factory es un proyecto de código abierto que te permite ajustar más de 100 grandes modelos lingüísticos (LLM) a través de una interfaz WebUI. Proporciona un conjunto completo de herramientas y scripts para afinar, chatear, servir y evaluar comparativamente los LLM.
LLaMA-Factory está diseñado específicamente para principiantes y profesionales no técnicos que deseen ajustar LLM de código abierto en sus conjuntos de datos personalizados sin aprender conceptos complejos de IA. Los usuarios sólo tienen que seleccionar un modelo, añadir su conjunto de datos y ajustar algunos parámetros para iniciar el proceso de entrenamiento.
Una vez completado el entrenamiento, se puede utilizar la misma aplicación web para probar el modelo, tras lo cual se puede exportar a Cara Abrazada o guardarlo localmente. Esto proporciona una forma rápida y eficaz de ajustar localmente los LLM.
En esta sección aprenderemos a instalar e iniciar LlaMA-Factory WebUI en Google Colab y Microsoft Windows.
Google Colab proporciona acceso a GPUs gratuitas, por lo que si tu portátil no tiene GPU o CUDA instalado. Te recomendé que empezaras con un cuaderno Colab.
%cd /content/
%rm -rf LLaMA-Factory
!git clone https://github.com/hiyouga/LLaMA-Factory.git
%cd LLaMA-Factory
%ls
%pip install -e .[torch,bitsandbytes]
from huggingface_hub import login
from google.colab import userdata
hf_token = userdata.get("HUGGINGFACE_TOKEN")
login(token = hf_token)llamafactory-cli. Establecemos GRADIO_SHARE=1 para que podamos generar un enlace público para acceder a la aplicación web. %cd /content/LLaMA-Factory/
!GRADIO_SHARE=1 llamafactory-cli webui
La WebUI de LLAMA-Factory parece sencilla pero tiene muchas opciones y pestañas. Los exploraremos en la siguiente sección.
Si tienes problemas para lanzar tu propia WebUI de LlaMA-Factory, consulta el cuaderno Google Colab.
Si quieres ejecutar LlaMA-Factory WebUI localmente en Windows, tienes que instalar una versión preconstruida de la biblioteca bitsandbytes. Es compatible con CUDA 11.1 a 12.2, así que selecciona la versión adecuada en función de la tuya versión CUDA.
$ git clone https://github.com/hiyouga/LLaMA-Factory.git
$ cd LLaMA-Factory
$ pip install -e .[torch,bitsandbytes]
$ pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.41.2.post2-py3-none-win_amd64.whl$ llamafactory-cli webui$ huggingface-cli loginNo habrá codificación en esta sección. Seleccionaremos el modelo y el conjunto de datos para afinarlos, cambiaremos algunos parámetros y pulsaremos algunos botones para un entrenamiento más rápido.
Para comprender la teoría que subyace al ajuste fino de los grandes modelos lingüísticos, consulta esta completa guía: Ajuste fino de grandes modelos lingüísticos.
Iremos afinando el unsloth/llama-3-8b-bnb-4bit en el modelo Microsoft/wiki_qa de Microsoft. El conjunto de datos contiene varias columnas, como se muestra a continuación, pero utilizaremos las columnas "pregunta" y "respuesta" para el ajuste del modelo.
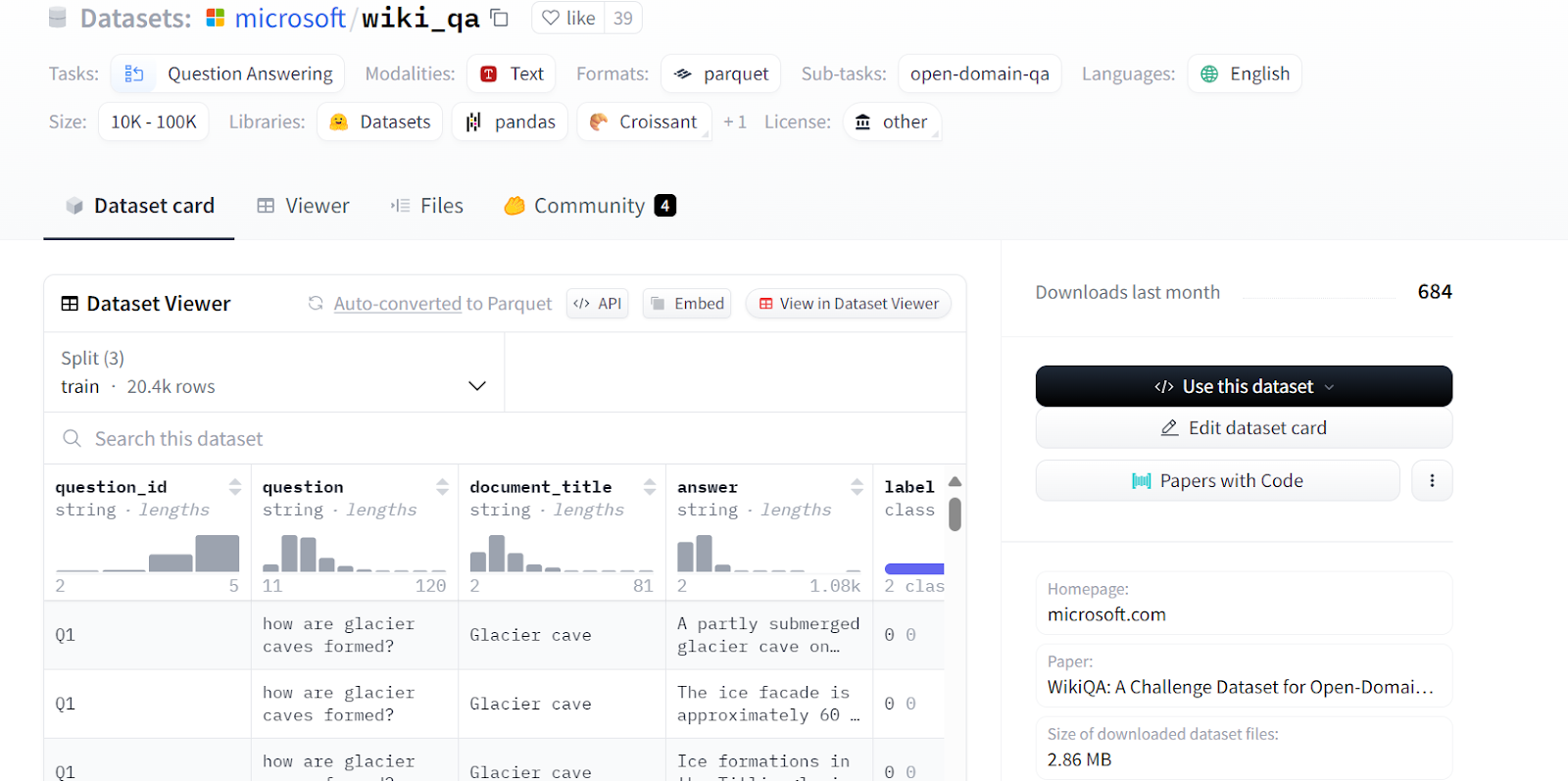
Fuente: microsoft/wiki_qa | Corpus de respuestas a preguntas Wiki de Microsoft
No podemos cargar el modelo de instrucciones LLaMA-3-8B completo en la versión gratuita de Google Colab. En su lugar, cargaremos la versión cuantificada en 4 bits del mismo modelo proporcionada por Unsloth.
Para ello, selecciona el nombre del modelo "Personalizado" y pega el enlace del repositorio "unsloth/llama-3-8b-bnb-4bit" en la ruta del modelo.
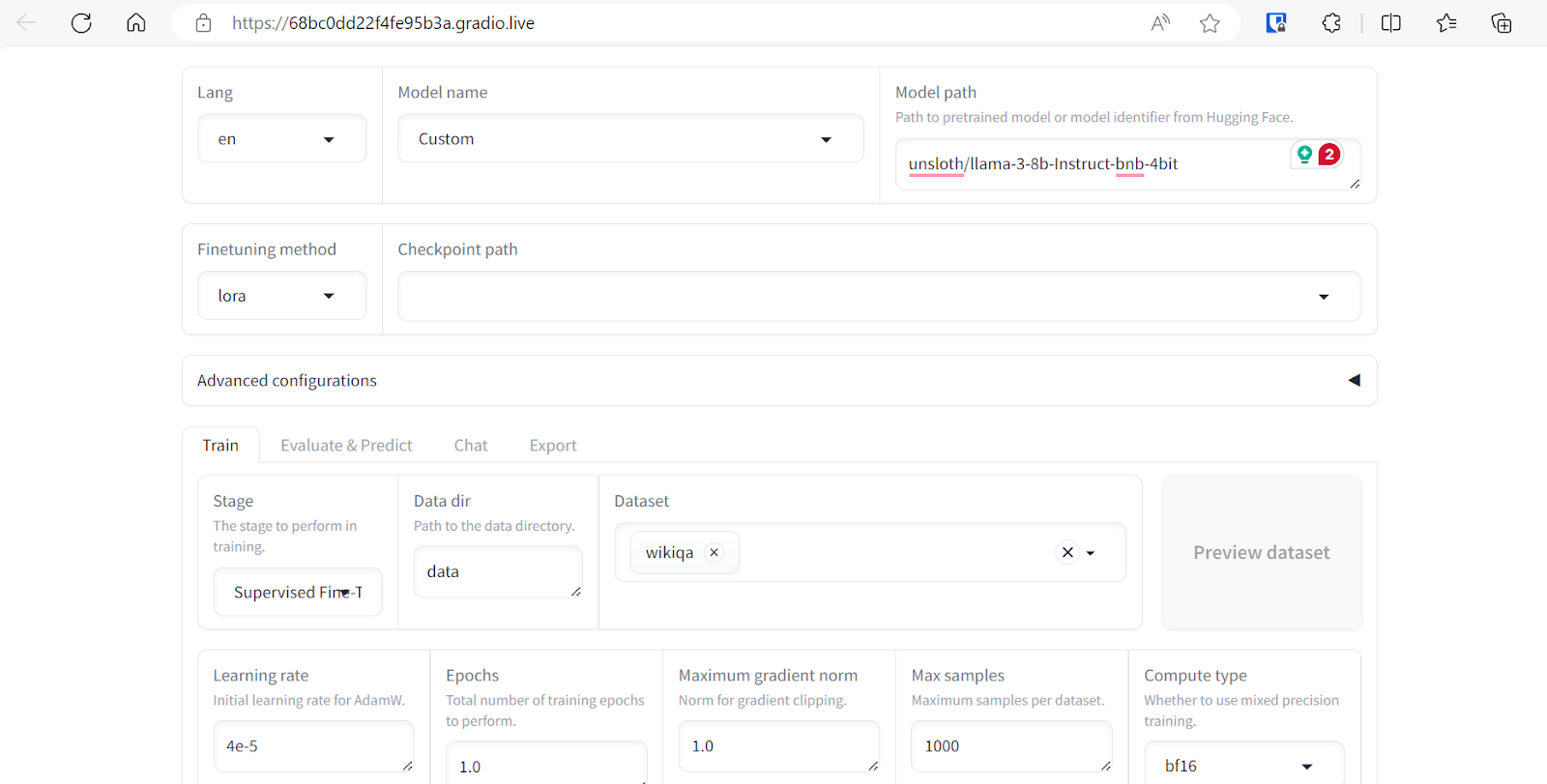
Podemos seleccionar varios conjuntos de datos para afinar nuestro modelo. Sin embargo, para este tutorial, sólo utilizaremos el conjunto de datos "Wikiqa", que puedes seleccionar fácilmente de un conjunto de datos predefinido, como se muestra arriba.
Ajusta los argumentos de entrenamiento del modelo desplazándote hacia abajo en la página. Estableceremos los siguientes parámetros:
El resto de argumentos se mantendrán con sus valores por defecto. Estos valores pueden cambiarse para modificar el comportamiento del modelo afinado.
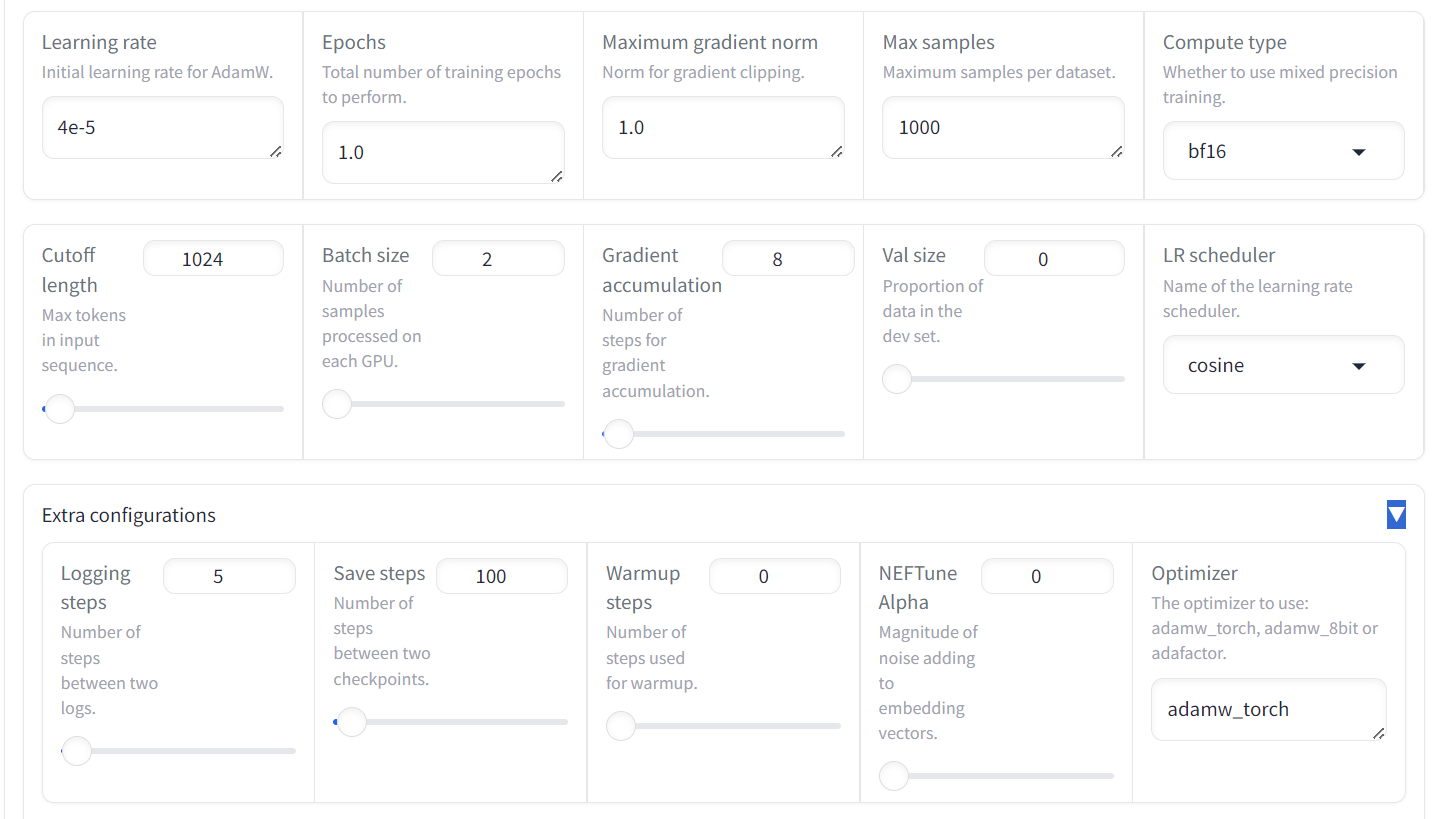
También tenemos la opción de cambiar LoRa y otras configuraciones relacionadas con LoRa. Para este tutorial, mantendremos todos los demás ajustes en sus valores por defecto.
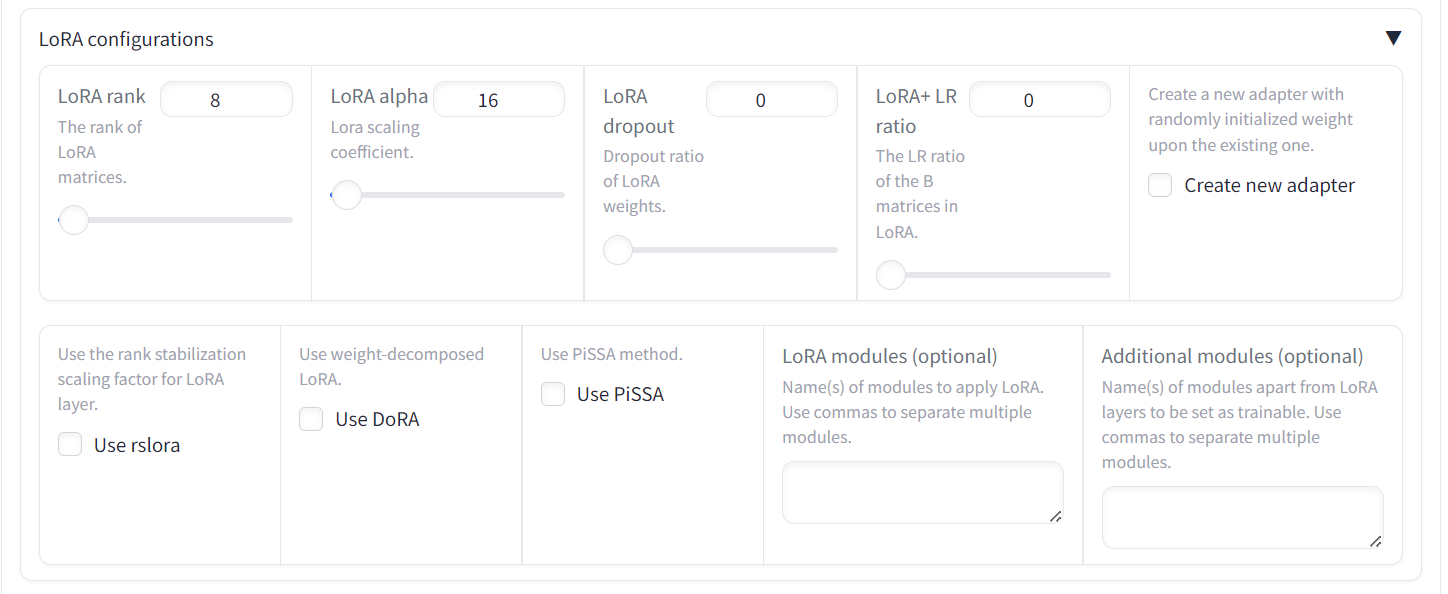
Desplázate más abajo en la página para ver la configuración del entrenamiento. Indica el directorio de salida y la ruta de configuración y pulsa el botón "Iniciar". El gráfico de pérdidas tardará algún tiempo en mostrarse, ya que el LlaMA-Factor descargará primero el modelo y el conjunto de datos y luego cargará ambos, lo que puede tardar al menos 5 minutos.
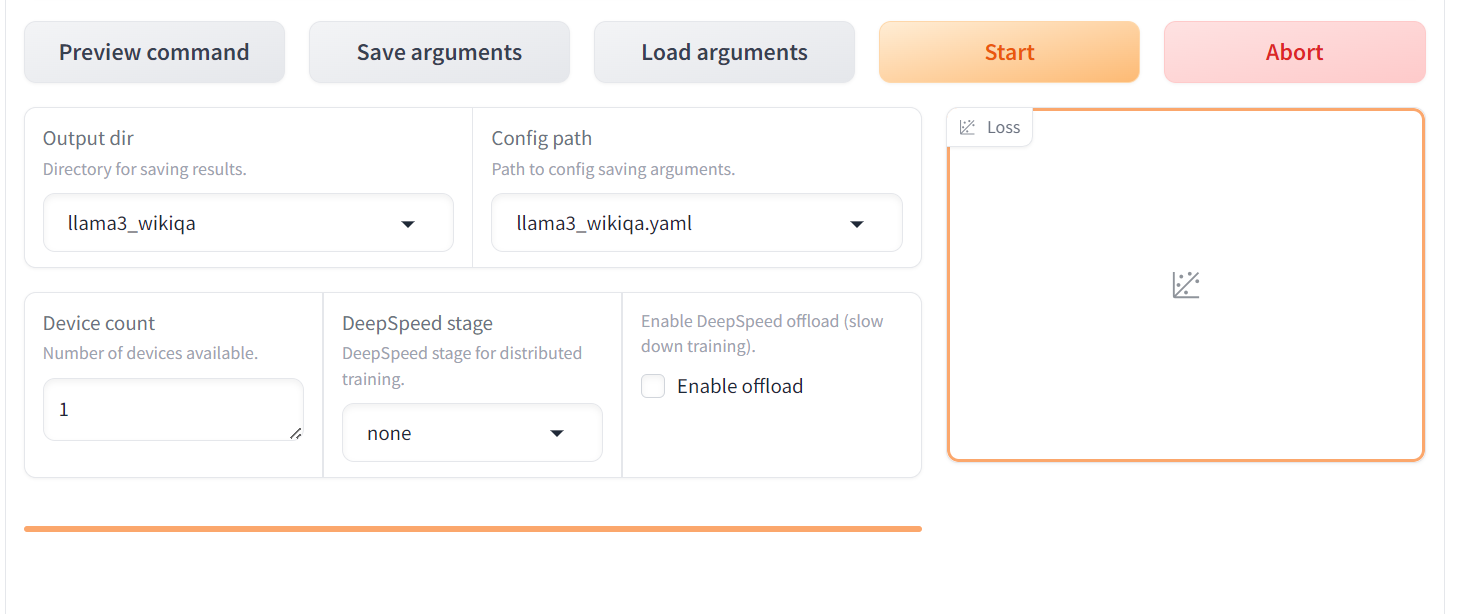
Una vez que el modelo esté completamente cargado y comience el entrenamiento, empezarás a ver visualizaciones en el gráfico de pérdidas. Como podemos observar, la pérdida disminuye gradualmente con el número de pasos, lo que es estupendo.
Cuando finalice el entrenamiento, verás el mensaje de finalización en la parte inferior izquierda. Como podemos observar, la pérdida se ha reducido gradualmente y se ha estabilizado después de 45 pasos.
Si eres un científico de datos o un desarrollador, te resultará fácil afinar tu modelo utilizando el lenguaje Python.
Tenemos una guía detallada para técnicos que quieran entrenar LlaMA-3 aquí: Afinar Llama 3 y utilizarla localmente: Guía paso a paso.
Para evaluar el modelo afinado, tenemos que cambiar el menú de "Entrenar" a "Chat". A continuación, ve a la "Ruta del punto de control" y carga el adoptador afinado guardado.
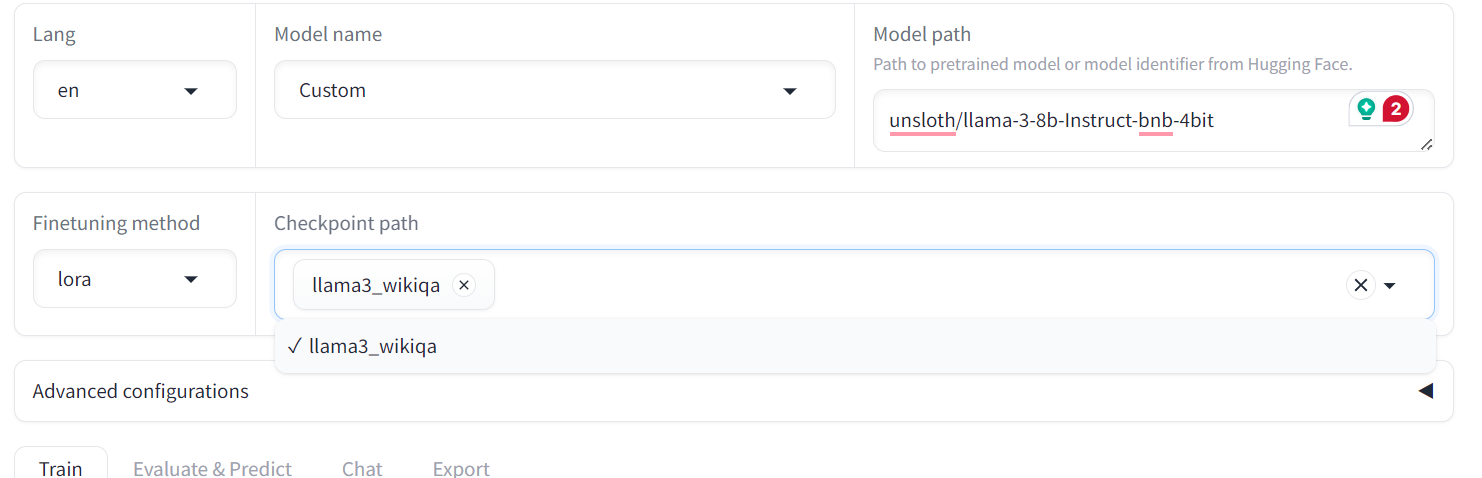
Después, haz clic en el botón "Cargar modelo" y espera unos segundos hasta que el modelo se cargue correctamente.
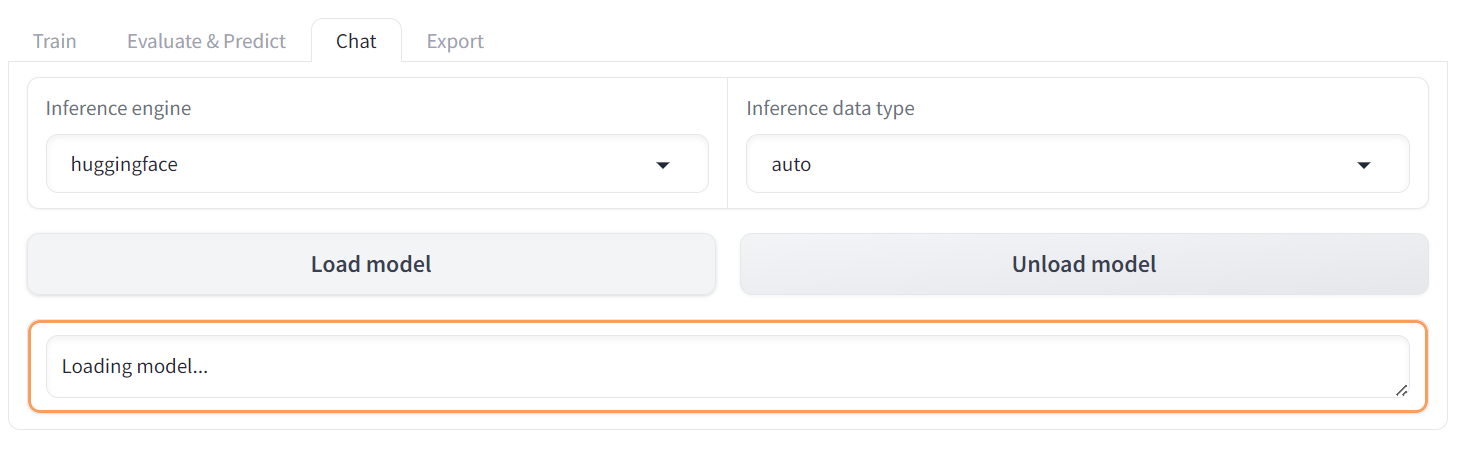
Desplázate hacia abajo para ver el cuadro de entrada del chat y escribe una pregunta general sobre la cordillera.
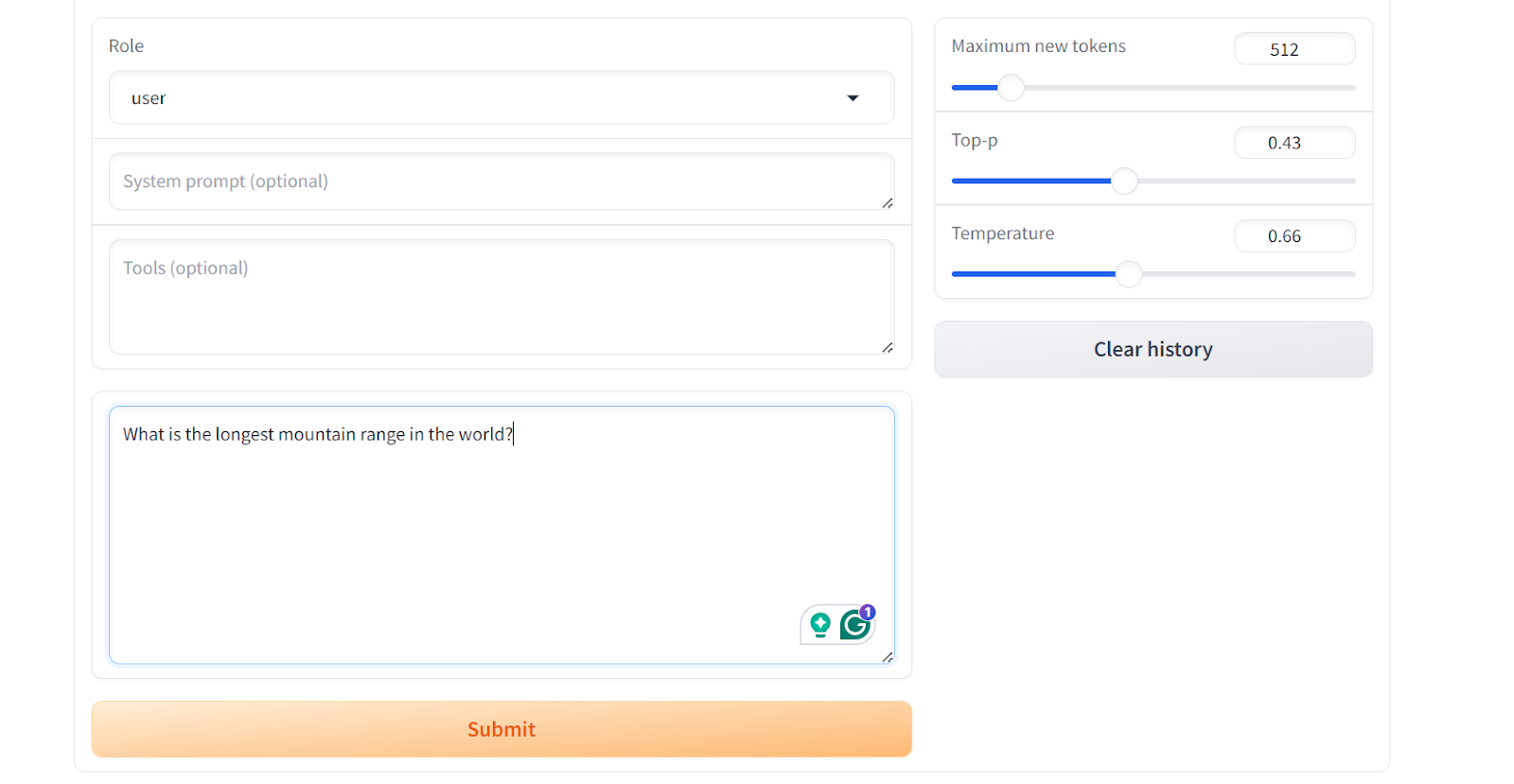
Como resultado, obtendrás una respuesta simple y directa, similar a la del conjunto de datos "wiki_qa".
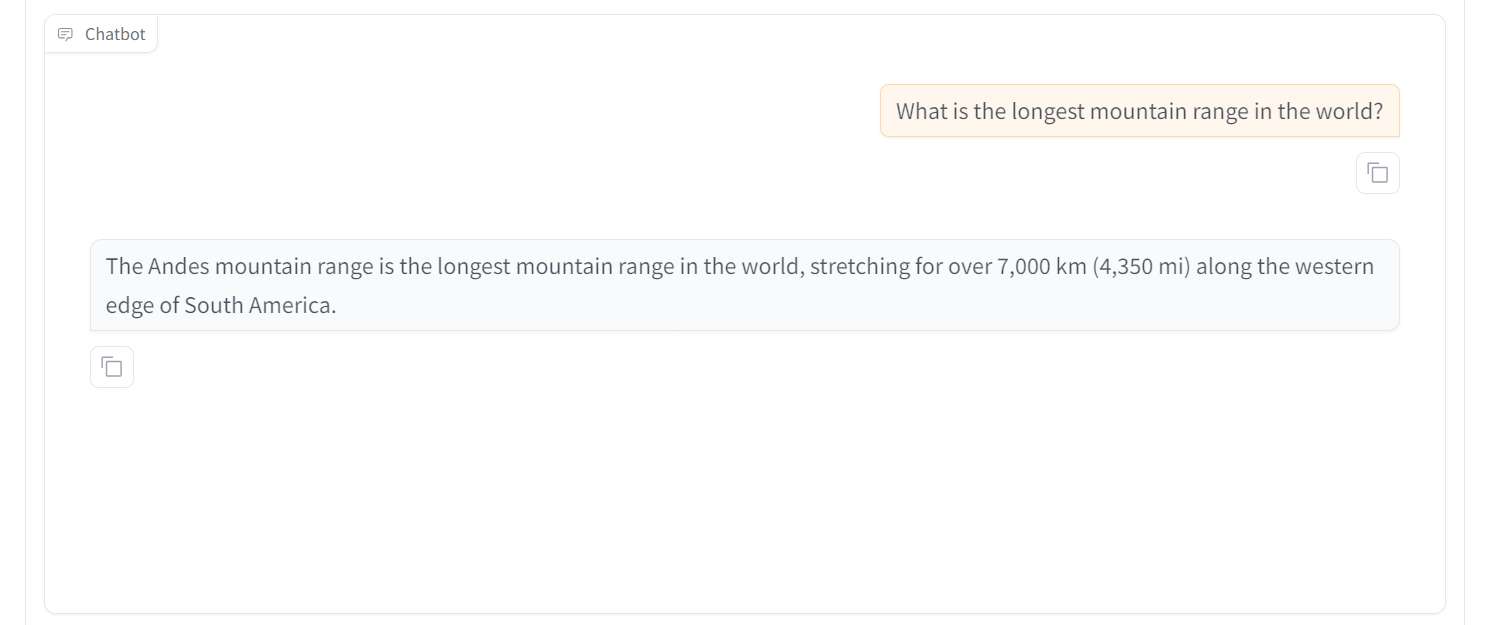
Intentemos hacer otra pregunta. Podemos ver que el modelo tiene un rendimiento excepcional. En 30 minutos hemos afinado el modelo, lo que nos habría llevado más de 4 horas utilizando la biblioteca Transformer. Esto es asombroso.
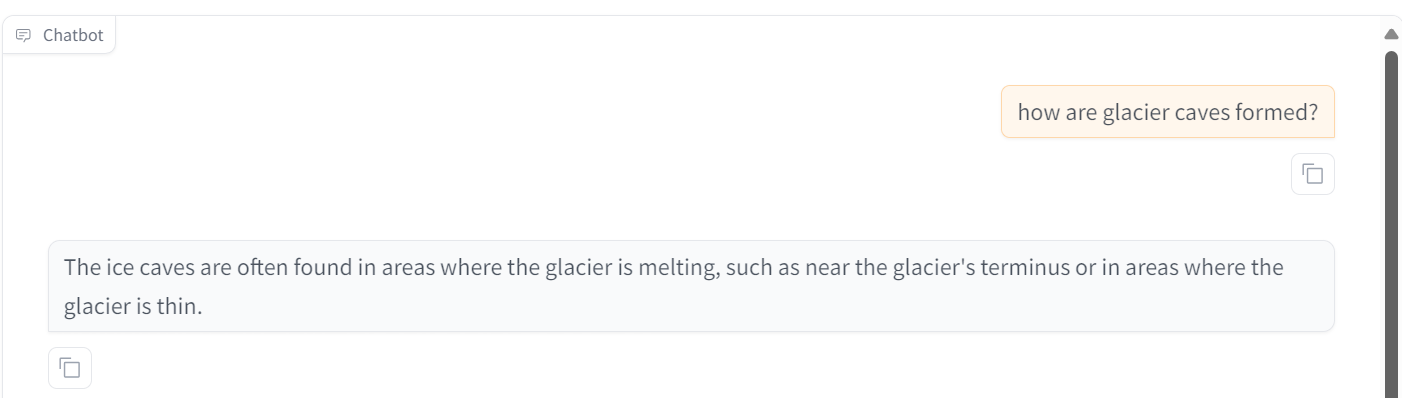
A veces, el ajuste fino no es la solución a todos los problemas del LLM. Por eso deberías leer RAG vs Ajuste fino: Un tutorial completo con ejemplos prácticos y aprende lo que mejor te funciona.
Además de ajustar y probar modelos, el ecosistema LLaMA-Factory ofrece varias funciones básicas, como el uso de datos personalizados para el ajuste, la fusión y exportación de modelos, y el despliegue de los modelos ajustados mediante VLLM.
Para añadir un conjunto de datos personalizado, sólo tienes que modificar el archivo data/dataset_info.json, y estará accesible en la WebUI de LLaMA-Factory.
Para obtener información detallada sobre el formato requerido de los archivos de conjuntos de datos y sobre cómo modificar el archivo dataset_info.json, consulta el archivo datos/README.md documentación.
Puedes elegir utilizar conjuntos de datos de los hubs Cara Abrazada o ModelScope, o puedes cargar el conjunto de datos desde tu disco local.
Vista previa del archivo data/dataset_info.json
Podemos fusionar fácilmente el adaptador LoRA ajustado con el modelo completo y exportarlo al Hugging Face Hub haciendo clic en la pestaña "Exportar".
Ajusta el tamaño máximo del fragmento, establece la ruta del directorio de exportación y especifica el ID del repositorio Hugging Face Hub y el dispositivo de exportación. El proceso tardará unos minutos en fusionar el modelo y subir todos los archivos del modelo al Hugging Face Hub.
Nota: La versión gratuita de Colab sólo ofrece 12 GB de RAM, mientras que para fusionar el LoRA de un modelo de 8.000 millones de parámetros se necesitan al menos 16 GB de RAM. Por tanto, esta operación no puede realizarse en la versión gratuita de Colab.
Fusionar y Experoint el modelo afinado a Hugging Face Hub
LlaMA-Factory viene con el marco vLLM para servir y desplegar modelos. Escribiendo el siguiente comando, podemos servir el modelo Llama-3-8B-Instruct y acceder a él a través de la API Python de OpenAI o la RestAPI.
$ API_PORT=8000 llamafactory-cli api examples/inference/llama3_vllm.yamlIncluso puedes modificar el archivo o crear tu propio archivo .yaml para servir tu modelo afinado en producción. Todo lo que tienes que hacer es proporcionar la ruta a la carpeta del modelo localmente o en Huggin Face Hub.
Fuente: hiyouga/LLaMA-Factory (github.com)
Si buscas una solución similar de bajo código que te permita afinar los LLM, en concreto el modelo propietario GPT-4o, tenemos una guía completa para ti. Consulta nuestro tutorial paso a paso aquí: Ajuste de la GPT-4 de OpenAI: Guía paso a paso.
La WebUI de LLaMA-Factory simplifica el proceso tanto a principiantes como a expertos. Todo lo que tienes que hacer es ajustar algunos parámetros para afinar el modelo en un conjunto de datos personalizado. Utilizando la misma interfaz de usuario, puedes probar el modelo y exportarlo a Cara de Abrazo o guardarlo localmente. Esto te permite desplegar el modelo en producción más tarde utilizando el comando LLaMA-Factory CLI api. Es así de sencillo.
En lugar de escribir cientos de líneas de código y solucionar problemas de ajuste, puedes conseguir resultados similares con unos pocos clics.
En este tutorial, aprendimos sobre la WebUI de LLaMA-Factory, y cómo afinar el modelo LLaMA-3-8B-Instruct en un conjunto de datos de preguntas y respuestas de Wikipedia utilizando este marco. Además, probamos el modelo afinado utilizando el menú incorporado del chatbot y exploramos las funciones adicionales que ofrece LLaMA-Factory.
Aprende a afinar los LLM utilizando Python inscribiéndote gratuitamente en el próximo Webinar Afinar tu propio modelo Llama 3.
Top Cursos DataCamp LLM
programa
Curso
Curso
blog
Stanislav Karzhev
9 min
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita
Tutorial
Dimitri Didmanidze


