
programa
Associate AI Engineer para desarrolladores
26 h
Le dices a tu chatbot que eres vegetariano. Al día siguiente, sugiere una receta de filete. Esto no es un error. Así es como funcionan los LLM. No tienen memoria entre sesiones, por lo que tratan cada conversación como si fuera una pizarra en blanco.
Para un uso ocasional, esto está bien. Pero si estás creando aplicaciones para el mundo real con usuarios reales, esta falta de estado se convierte en un verdadero problema. Tus usuarios esperan que la IA los recuerde.
Mem0 resuelve este problema añadiendo una capa de memoria a cualquier LLM. Almacena, recupera y actualiza información sobre los usuarios a lo largo de las sesiones, por lo que tu IA puede realmente aprender y adaptarse con el tiempo.
En este tutorial, crearás un asistente personal de IA que recuerda las preferencias del usuario, programa el historial de conversaciones y se vuelve más inteligente con cada interacción. Cubriremos tanto las configuraciones en la nube como las autohospedadas para que puedas elegir la que mejor se adapte a tu proyecto.
Si no lo has utilizado antes, realiza este cursopara aprender a trabajar con la API de OpenAI.
Mem0 es una capa de memoria de código abierto que se encuentra entre tu aplicación y el LLM. Extrae automáticamente la información relevante de las conversaciones, la almacena y la recupera cuando es necesario. El proyecto recaudó 24 millones de dólares en octubre de 2025 y funciona con cualquier proveedor de LLM: OpenAI, Anthropic, Ollama o tus propios modelos.
Mem0 organiza los recuerdos en tres ámbitos:
Memoria de usuario: Persiste en todas las conversaciones con una persona específica. Si alguien menciona que prefiere las sesiones de estudio matutinas, ese dato permanecerá disponible en todas las sesiones futuras.
Memoria de sesión: Realiza un programa del contexto dentro de una sola conversación, como la receta actual que se está discutiendo.
Memoria del agente: Almacena información específica de una instancia concreta de agente de IA.
Puedes combinar estos ámbitos para crear aplicaciones complejas en las que diferentes agentes compartan (o aíslen) lo que saben sobre los usuarios.
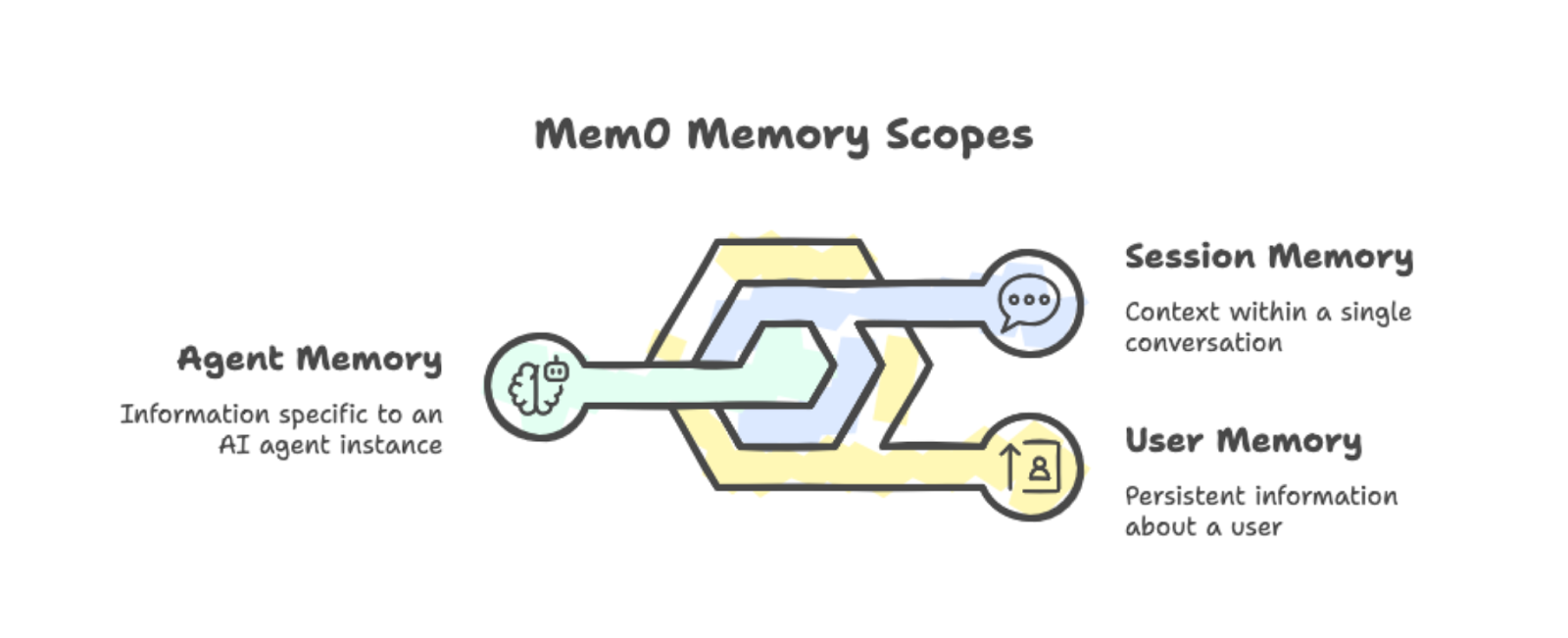
Los tres ámbitos de memoria: usuario, sesión y agente, con ejemplos.
En tu interior, Mem0 combina la búsqueda vectorial con las relaciones gráficas. Cuando añades una conversación a la memoria, esta extrae automáticamente los fragmentos importantes. No es necesario que etiquetes manualmente lo que debes recordar.
Cuando tu aplicación necesita contexto, Mem0 recupera recuerdos relevantes basados en la consulta actual y los inserta en el mensaje. Esto es mejor que la alternativa de incluir todo el historial de conversaciones en cada solicitud.
Puedes ejecutar Mem0 de dos maneras:
Plataforma: El servicio gestionado basado en la nube de app.mem0.ai ofrece una configuración rápida y una API.
Autoalojado: Te ofrece un control total sobre tu infraestructura, permitiéndote elegir tu base de datos vectorial y tu modelo de integración.
Ambas opciones utilizan el mismo SDK de Python, por lo que cambiar entre ellas es muy sencillo.
Las mejoras en el rendimiento son reales, tal y como revela el artículo de investigación de Mem0s. En la prueba de rendimiento LOCOMO, Mem0 obtuvo una puntuación un 26 % superior a la función de memoria integrada de OpenAI. También responde un 91 % más rápido al recuperar selectivamente los recuerdos relevantes en lugar de procesar todo el historial de conversaciones. El uso de tokens se reduce en aproximadamente un 90 % en comparación con los enfoques de contexto completo.
Ahora que ya sabes lo que hace Mem0, vamos a configurarlo.
Instala el paquete junto con python-dotenv para gestionar las claves API:
pip install mem0ai python-dotenvRegístrate en app.mem0.ai y obtén tu clave API desde el panel de control. Crea un archivo .env en el directorio de tu proyecto:
MEM0_API_KEY=your-api-key-hereAhora, inicializa el cliente utilizando la clave API:
from mem0 import MemoryClient
from dotenv import load_dotenv
import os
load_dotenv()
client = MemoryClient(api_key=os.getenv("MEM0_API_KEY"))Para almacenar un recuerdo, pasa una conversación en el formato de chat de OpenAI. El parámetro user_id limita las memorias a un usuario específico:
messages = [
{"role": "user", "content": "I'm a vegetarian and allergic to nuts."},
{"role": "assistant", "content": "Got it! I'll remember that."}
]
client.add(messages, user_id="user123")El procesamiento de la memoria se realiza en segundo plano. El método ` add() ` devuelve inmediatamente un estado pendiente mientras Mem0 extrae y almacena los datos relevantes.
Para recuperar recuerdos, utiliza search() con una consulta en lenguaje natural:
results = client.search("dietary restrictions", filters={"user_id": "user123"})La respuesta contiene los recuerdos extraídos con puntuaciones de relevancia:
{'results': [
{'memory': 'User is allergic to nuts', 'user_id': 'user123', 'score': 0.66},
{'memory': 'User is a vegetarian', 'user_id': 'user123', 'score': 0.65}
]}Ten en cuenta que Mem0 divide automáticamente «vegetariano» y «alérgico a los frutos secos» en dos datos distintos. El sistema se encarga de la extracción y, cuando realizas una búsqueda, te devuelve los recuerdos más relevantes basándose en la similitud semántica.
Ahora que ya tenemos los conceptos básicos, construyamos algo más práctico.
El flujo de trabajo básico de añadir/buscar es útil, pero las aplicaciones reales necesitan más sofisticación. Creemos un agente de aprendizaje que decida de forma autónoma cuándo almacenar, recuperar y actualizar recuerdos. Usaremos el SDK de OpenAI Agents para dotar a nuestro agente de herramientas de memoria a las que pueda recurrir por sí mismo.
Si eres nuevo en la creación de agentes con LLM, consulta nuestro tutorial sobre la creación de agentes LangChain para obtener información básica sobre los conceptos. Para obtener más información sobre el SDK de OpenAI Agents, consulta el tutorial del SDK de OpenAI Agents.
Instala el SDK de OpenAI Agents junto con Mem0:
pip install openai-agents mem0ai python-dotenvAñade tu clave API de OpenAI al archivo .env:
MEM0_API_KEY=your-mem0-key
OPENAI_API_KEY=your-openai-keyAhora, inicializa ambos clientes y crea una clase de contexto para pasar la información del usuario a las herramientas:
import os
from dataclasses import dataclass
from agents import Agent, Runner, function_tool, RunContextWrapper
from mem0 import MemoryClient
from dotenv import load_dotenv
load_dotenv()
mem0 = MemoryClient(api_key=os.getenv("MEM0_API_KEY"))
@dataclass
class UserContext:
user_id: strLa clase de datos UserContext contiene datos específicos del usuario que requieren las herramientas. RunContextWrapper nos permite pasar este contexto a cualquier herramienta que invoque el agente.
El agente necesita tres herramientas: buscar, guardar y actualizar. Utilizamos el decorador « @function_tool » para exponerlos al agente.
En primer lugar, la herramienta de búsqueda recupera los recuerdos relevantes. Incluimos los ID de memoria en la salida para que el agente pueda consultarlos para las actualizaciones:
@function_tool
def search_memory(ctx: RunContextWrapper[UserContext], query: str) -> str:
"""Search through past learning history and memories."""
memories = mem0.search(
query,
filters={"user_id": ctx.context.user_id},
limit=5
)
if memories and memories.get("results"):
return "\n".join([
f"- [ID: {m['id']}] {m['memory']}" for m in memories["results"]
])
return "No relevant memories found."A continuación, la herramienta de guardado almacena la nueva información:
@function_tool
def save_memory(ctx: RunContextWrapper[UserContext], content: str) -> str:
"""Save new information about the user's learning journey."""
mem0.add(
[{"role": "user", "content": content}],
user_id=ctx.context.user_id
)
return "Memory saved successfully."Por último, la herramienta de actualización modifica las memorias existentes cuando cambia la información:
@function_tool
def update_memory(ctx: RunContextWrapper[UserContext], memory_id: str, new_text: str) -> str:
"""Update an existing memory with new information."""
mem0.update(memory_id=memory_id, text=new_text)
return f"Memory {memory_id} updated."Ahora creamos el agente con instrucciones sobre cuándo utilizar cada herramienta:
agent = Agent(
name="Learning Companion",
instructions="""You are a helpful learning companion with memory.
Use search_memory to recall what the user is learning and their level.
Search results include memory IDs in format [ID: xxx].
Use save_memory to store new topics, preferences, or progress.
Use update_memory when information changes. First search to find the memory ID, then call update_memory with that ID and the new text.
Always check memory before responding to personalize your answers.""",
tools=[search_memory, save_memory, update_memory],
model="gpt-4o"
)Aquí utilizamos gpt-4o, pero para mejorar el razonamiento sobre el uso de herramientas, recomiendo utilizar GPT-5. No dudes en visitar y consultar nuestro tutorial sobre la API GPT-5 para versus nuevas funciones en acción.
La función de chat pasa el contexto del usuario al agente:
def chat(user_input: str, user_id: str) -> str:
result = Runner.run_sync(
agent,
user_input,
context=UserContext(user_id=user_id)
)
return result.final_outputCada llamada a Runner.run_sync() es completamente independiente de todas las demás llamadas. El SDK de OpenAI Agents no guarda el historial de conversaciones entre llamadas de forma predeterminada.
Esto es intencionado para nuestra demostración: cuando el agente recuerda la información del usuario entre llamadas, esa memoria debe provenir de Mem0, no de ningún estado oculto del agente.
Probemos con consultas que requieran la recuperación real de memoria. El agente no puede adivinar las respuestas correctamente sin acceder a la información almacenada.
Primero, almacena cierta información del usuario:
response = chat(
"My name is Alex. I am learning data visualization with matplotlib. "
"I am at intermediate level.",
"student_01"
)
print(response)Got it, Alex! You're learning data visualization with Matplotlib at an intermediate level. How can I assist you today?Después de esperar unos segundos para el procesamiento asíncrono, prueba la recuperación:
response = chat("What is my name and what library am I learning?", "student_01")
print(response)Your name is Alex, and you're learning data visualization using Matplotlib at an intermediate level.Ahora, prueba la funcionalidad de actualización:
response = chat(
"I switched from matplotlib to seaborn. Please update your memory.",
"student_01"
)
print(response)Got it! I've updated your learning preference to Seaborn for data visualization at an intermediate level. If you need help with anything specific, just let me know!Comprueba que la actualización ha funcionado:
response = chat("What visualization library am I using now?", "student_01")
print(response)You are currently using Seaborn for data visualization at an intermediate level.Por último, comprueba la persistencia entre conversaciones:
response = chat("Give me a summary of everything you know about me.", "student_01")
print(response)Here's what I know about you:
- Your name is Alex.
- You are learning data visualization with Seaborn at an intermediate level.
Is there anything else you'd like to update or add?El agente elige qué herramienta utilizar en función de la conversación.
Cuando el usuario pregunta por su perfil, se llama a search_memory. Cuando compartís información nueva, se llama a save_memory. Cuando dicen que la información ha cambiado, primero busca la ID de memoria y luego llama a update_memory.
Nunca indicamos explícitamente qué herramienta utilizar para cada mensaje.
Esto difiere del flujo de trabajo de añadir/buscar manualmente que se describe en la sección 3. Allí, llamamos explícitamente a los métodos. Aquí, el agente toma esas decisiones. Este patrón se adapta mejor a aplicaciones complejas en las que no es posible predecir todos los tipos de interacción.

Comparación entre los flujos de trabajo manuales y los impulsados por agentes en cuanto a escalabilidad
Una nota importante: el procesamiento de la memoriaes asíncrono. Después de llamar a save_memory, hay un breve retraso antes de que la nueva memoria sea consultable. En producción, querrás tener esto en cuenta en tu interfaz de usuario.
El agente básico se encarga de las operaciones de memoria, pero las aplicaciones de producción necesitan un control más preciso sobre lo que se almacena y cómo se recupera. Mem0 ofrece ajustes a nivel de proyecto que mejoran la calidad de la memoria, incluyendo categorías personalizadas para la organización, instrucciones definidas por el usuario para el filtrado, búsquedas específicas y operaciones de limpieza.
Por defecto, Mem0 utiliza categorías genéricas como comida, viajes y aficiones. Para aplicaciones específicas como nuestro compañero de aprendizaje, esto no ayuda mucho . Puedes definir tus propias categorías que se ajusten a tu dominio:
client.project.update(custom_categories=[
{"name": "topics", "description": "Programming languages, frameworks, or subjects"},
{"name": "skill_levels", "description": "Proficiency: beginner, intermediate, advanced"},
{"name": "goals", "description": "Learning objectives and targets"},
{"name": "progress", "description": "Completed courses, chapters, or milestones"},
{"name": "preferences", "description": "Learning style, schedule, or format preferences"}
])Una vez configurado, el clasificador de Mem0 etiqueta automáticamente los recuerdos entrantes con tus categorías. Cuando Alex dice: «Estoy aprendiendo Python a nivel principiante», el sistema lo etiqueta con topics y skill_levels. No es necesario que cambies tu código de agente. La categorización se realiza durante la extracción de la memoria.
Las instrucciones personalizadas te permiten controlar exactamente qué se extrae de las conversaciones. Tú escribes las pautas del lenguaje natural y Mem0 las sigue al procesar nuevos recuerdos:
client.project.update(custom_instructions="""
Extract and remember:
- Programming topics and technologies mentioned
- Current skill level for each topic
- Learning goals and deadlines
- Progress updates and completions
- Preferred learning resources (videos, docs, exercises)
Do not store:
- Personal identifiers beyond the user_id
- Payment or financial information
- Off-topic conversation that isn't about learning
""")Esto es importante para las aplicaciones de producción. Sin instrucciones, Mem0 podría almacenar detalles irrelevantes o información confidencial. Las instrucciones personalizadas actúan como un filtro, manteniendo los recuerdos centrados en lo que tu aplicación realmente necesita. Para escenarios de cumplimiento normativo como el RGPD, puedes excluir explícitamente categorías de datos personales.
Con recuerdos categorizados, tu herramienta de búsqueda puede ser más precisa. En lugar de buscar en todos los recuerdos, filtra por categoría para obtener exactamente lo que necesitas:
@function_tool
def search_memory(
ctx: RunContextWrapper[UserContext],
query: str,
category: str = None
) -> str:
"""Search learning history. Optionally filter by category."""
filters = {"user_id": ctx.context.user_id}
if category:
filters["categories"] = {"contains": category}
memories = mem0.search(query, filters=filters, limit=5)
if memories and memories.get("results"):
return "\n".join([
f"- [ID: {m['id']}] {m['memory']}" for m in memories["results"]
])
return "No relevant memories found."Cuando el agente necesita responder a la pregunta «¿Qué temas he aprendido?», puede realizar una búsqueda con category="topics" y omitir los recuerdos no relacionados con las preferencias o los objetivos. Las instrucciones del agente deben mencionar estas categorías, para que sepas cuándo utilizar búsquedas filtradas.
Es posible que los usuarios quieran eliminar recuerdos obsoletos o incorrectos. Añade una herramienta de eliminación para que el agente tenga esta capacidad:
@function_tool
def delete_memory(ctx: RunContextWrapper[UserContext], memory_id: str) -> str:
"""Delete a specific memory by ID."""
mem0.delete(memory_id=memory_id)
return f"Memory {memory_id} deleted."Para operaciones masivas, puedes borrar directamente todas las memorias de un usuario:
mem0.delete_all(user_id="student_01")La eliminación resulta útil cuando la información cambia por completo, en lugar de actualizarse. Si un usuario dice «olvida todo lo que he aprendido sobre Python», el agente puede buscar los recuerdos relevantes y eliminarlos uno por uno, o bien puedes ofrecerte una opción de restablecimiento que borre por completo su perfil.
Estas cuatro opciones de configuración convierten al agente de una versión de demostración en algo que se puede comercializar. Las categorías organizan los recuerdos automáticamente, las instrucciones garantizan que solo se almacene la información relevante, las búsquedas filtradas recuperan exactamente lo que se necesita y la eliminación se encarga de la limpieza. Los cambios en el código del agente son mínimos, ya que la mayor parte de ellos se producen a nivel de configuración del proyecto.
Para obtener más información sobre estas funciones, consulta la documentación oficial de Mem0.
La memoria estándar almacena datos aislados, como «Alex está aprendiendo Seaborn » y «Alex sabe matplotlib ». Pero no refleja que Alex aprendió primero matplotlib y luego cambió a Seaborn. La memoria gráfica añade esta capa de relaciones. Cuando el orden, la progresión o las conexiones entre entidades son importantes, la memoria gráfica proporciona a tu agente un contexto más rico.
Nota: La memoria gráfica solo está disponible con el plan Pro (249 $ al mes) o superior.
Puedes activar la memoria gráfica a nivel de proyecto:
client.project.update(enable_graph=True)Otra opción es pasar enable_graph=True en solicitudes individuales:
client.add(messages, user_id="student_01", enable_graph=True)Una vez activado, Mem0 extrae automáticamente entidades (personas, temas, herramientas, fechas) y las relaciones entre ellas a partir de conversaciones naturales.
Cuando realizas una búsqueda con memoria gráfica, Mem0 devuelve tanto las memorias como un arreglo e relations e que muestra cómo se conectan las entidades:
results = client.search(
"What has Alex learned?",
filters={"user_id": "student_01"},
enable_graph=True
)
# Results include both memories and relations
print(results.get("relations"))Las relaciones muestran conexiones como «Alex → aprendió → matplotlib » y «Alex → cambió a → seaborn ». Tu agente ahora puede responder preguntas sobre la progresión sin que tengas que almacenar esas relaciones de forma explícita.
La memoria gráfica añade una sobrecarga de procesamiento, así que úsala cuando las relaciones sean importantes:
Plataformas de aprendizaje que realizan un seguimiento del progreso de las habilidades
Atención al cliente: análisis del historial de interacciones
Mapeo de dependencias de tareas en la gestión de proyectos
Atención sanitaria que conecta síntomas y tratamientos a lo largo del tiempo
Para recordar datos simples, la memoria estándar es más rápida. Activa la memoria gráfica cuando tu agente necesite razonar sobre secuencias o conexiones entre la información almacenada.
Mem0 viene en dos versiones: Plataforma y código abierto.
A lo largo de este tutorial, hemos utilizado la versión Platform, que es el servicio gestionado en la nube al que se accede a través de MemoryClient y una clave APIde app.mem0.ai. Ambasversiones comparten operaciones de memoria central (add(), search(), update(), delete()), pero difieren en la configuración, el precio y el control.
Platform es el servicio alojado de Mem0. Te registras, obtienes una clave API y empiezas a añadir recuerdos en cuestión de minutos. Mem0 se encarga de la infraestructura, el escalado y las certificaciones de seguridad (como SOC 2 Tipo II o RGPD).
Hay cuatro niveles de precios:
Gratis: 10 000 recuerdos, ideales para crear prototipos.
Starter: 19 $ al mes , con límites más altos.
Pro: 249 $ al mes , para cargas de trabajo de producción.
Enterprise: Precios personalizados con asistencia dedicada.
La plataforma incluye funciones que no están disponibles en el código abierto: memoria gráfica para el seguimiento de relaciones, webhooks para notificaciones en tiempo real, chat grupal con atribución de interlocutor y análisis integrados.
Pagás por uso, pero ahorrás en infraestructura y tiempo de DevOps.
La versión de código abierto se ejecuta en tus propios servidores. Instala el paquete mem0ai, configura tu base de datos vectorial y gestiona tú mismo la implementación. Esto requiere más configuración, pero te ofrece un control total.
Hay varias opciones disponibles para la infraestructura:
Bases de datos vectoriales: Más de 24 opciones, entre las que se incluyen Qdrant, Chroma, Pinecone, PostgreSQL (pgvector) y MongoDB.
Proveedores de LLM: Más de 16 opciones, incluyendo OpenAI, Anthropic, Ollama, Groq y modelos locales.
Modelos de integración: OpenAI, HuggingFace o incrustadores personalizados.
El código abierto utiliza la Memory clase en lugar de MemoryClient.
Tus costes son los que pagas por la infraestructura (máquinas virtuales en la nube, alojamiento de bases de datos, llamadas API a proveedores de LLM). A gran escala, esto puede resultar más económico que los precios de la plataforma, pero tú serás responsable de gestionar el mantenimiento, las copias de seguridad y el cumplimiento normativo.
Consulta la siguiente tabla para ver una comparación entre las versiones alojadas y de código abierto de Mem0 :
|
Aspecto |
Plataforma |
Código abierto |
|
Tiempo de configuración |
Actas |
De horas a días |
|
Infraestructura |
Totalmente gestionado |
Autogestionado |
|
Precios |
0-249 $+/mes |
Tus costes de infraestructura |
|
Opciones de la base de datos vectorial |
Gestionado |
Más de 24 opciones |
|
Opciones de LLM |
Gestionado |
Más de 16 opciones |
|
Certificados de conformidad |
SOC 2, RGPD incluido |
Implementas |
|
Ubicación de los datos |
Servidores de Mem0 |
Tus servidores |
Mi recomendación es elegirPlatform para la creación rápida de prototipos, aplicaciones de producción sin sobrecarga de DevOps o cuando se necesite cumplimiento integrado.
Si tu prioridad es la soberanía de los datos, las configuraciones de modelos personalizados o la optimización de costes en grandes volúmenes, el código abierto es la opción adecuada.
Para obtener guías de configuración detalladas, consulta la guía de inicio rápido de la plataforma o la descripción general del código abierto.
Este tutorial ha tratado sobre cómo añadir memoria persistente a aplicaciones LLM con Mem0. Comenzaste con operaciones básicas de memoria y luego creaste un agente de aprendizaje complementario que gestiona de forma autónoma su propia memoria utilizando el SDK de OpenAI Agents. A partir de ahí, configuraste el comportamiento de la memoria con categorías personalizadas, instrucciones y búsquedas filtradas. Por último, comparaste las opciones de implementación de la plataforma y del código abierto.
Para uso en producción, añade control de errores en las operaciones de memoria y ten en cuenta los breves retrasos tras guardar nuevos recuerdos. Ten en cuenta los límites de velocidad si utilizas el nivel gratuito de la plataforma.
¿Estás listo para ir más allá de los componentes individuales y dominar todo el proceso de desarrollo de aplicaciones de IA? Inscríbete enen la carrera de ingeniero de IA para programadores .
Cursos de agente de IA
programa
Curso
Curso
blog
Abid Ali Awan
10 min
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
Kurtis Pykes
Tutorial
Abid Ali Awan
Tutorial
Arunn Thevapalan



