
Cursus
Associate AI Engineer pour développeurs
26 h
Vous informez votre chatbot que vous êtes végétarien. Le lendemain, il propose une recette de steak. Ceci n'est pas un bug. C'est simplement ainsi que fonctionnent les LLM. Ils n'ont aucune mémoire entre les sessions, considérant chaque conversation comme une nouvelle page blanche.
Pour un usage occasionnel, cela convient parfaitement. Cependant, si vous développez des applications concrètes destinées à des utilisateurs réels, cette absence d'état devient un véritable problème. Vos utilisateurs s'attendent à ce que l'IA se souvienne d'eux.
Mem0 résout ce problème en ajoutant une couche mémoire à tout LLM. Il stocke, récupère et met à jour les informations relatives aux utilisateurs d'une session à l'autre, ce qui permet à votre IA d'apprendre et de s'adapter au fil du temps.
Dans ce tutoriel, vous allez créer un assistant IA personnel qui mémorise les préférences de l'utilisateur, suit le cursus des conversations et devient plus intelligent à chaque interaction. Nous aborderons à la fois les configurations cloud et auto-hébergées afin que vous puissiez choisir celle qui convient le mieux à votre projet.
Si vous n'avez jamais utilisé cette API auparavant, veuillez suivre ce courspour apprendre à utiliser l'API OpenAI.
Mem0 est une couche mémoire open source qui se situe entre votre application et le LLM. Il extrait automatiquement les informations pertinentes des conversations, les stocke et les récupère lorsque cela est nécessaire. Le projet a levé 24 millions de dollars en octobre 2025 et est compatible avec tous les fournisseurs de LLM : OpenAI, Anthropic, Ollama ou vos propres modèles.
Mem0 organise les souvenirs en trois catégories :
Mémoire utilisateur : Persiste dans toutes les conversations avec une personne en particulier. Si quelqu'un indique qu'il préfère les sessions d'étude le matin, cette information restera disponible pour toutes les sessions futures.
Mémoire de session : Cursus du contexte au sein d'une conversation unique, comme la recette actuellement discutée.
Mémoire de l'agent : Stocke les informations spécifiques à une instance particulière d'agent IA.
Vous pouvez combiner ces champs d'application pour créer des applications complexes dans lesquelles différents agents partagent (ou isolent) ce qu'ils savent sur les utilisateurs.
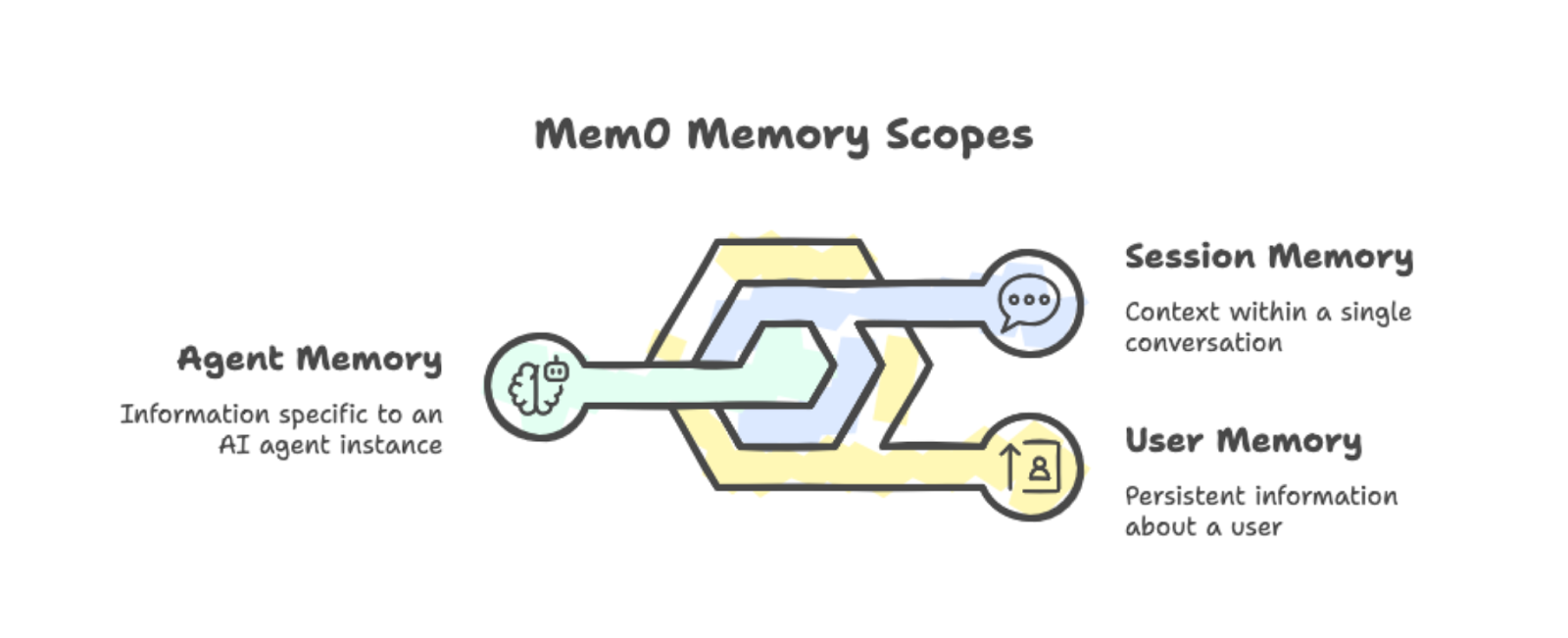
Les trois types de mémoire : utilisateur, session et agent, avec des exemples.
En arrière-plan, Mem0 combine la recherche vectorielle avec les relations graphiques. Lorsque vous ajoutez une conversation à la mémoire, les éléments importants sont automatiquement extraits. Il n'est pas nécessaire de marquer manuellement ce qui doit être mémorisé.
Lorsque votre application a besoin de contexte, Mem0 récupère les souvenirs pertinents en fonction de la requête actuelle et les intègre dans l'invite. Cela est préférable à l'alternative qui consiste à inclure l'intégralité de l'historique de vos conversations dans chaque demande.
Vous pouvez exécuter Mem0 de deux manières :
Plateforme : Le service géré dans le cloud sur app.mem0.ai offre une configuration rapide et une API.
Auto-hébergé : Vous offre un contrôle total sur votre infrastructure, vous permettant de choisir votre base de données vectorielle et votre modèle d'intégration.
Les deux options utilisent le même SDK Python, il est donc facile de passer de l'une à l'autre.
Les gains de performance sont réels, comme le démontre l'article de recherche de Mem0s. Dans le benchmark LOCOMO, Mem0 a obtenu un score supérieur de 26 % à celui de la fonctionnalité de mémoire intégrée d'OpenAI. Il répond également 91 % plus rapidement en récupérant de manière sélective les souvenirs pertinents au lieu de traiter l'historique complet de la conversation. L'utilisation des jetons diminue d'environ 90 % par rapport aux approches en contexte complet.
Maintenant que vous comprenez le fonctionnement de Mem0, nous allons procéder à sa configuration.
Veuillez installer le paquet avec python-dotenv pour gérer les clés API :
pip install mem0ai python-dotenvVeuillez vous inscrire sur app.mem0.ai et récupérer votre clé API depuis le tableau de bord. Veuillez créer un fichier .env dans le répertoire de votre projet :
MEM0_API_KEY=your-api-key-hereVeuillez maintenant initialiser le client à l'aide de la clé API :
from mem0 import MemoryClient
from dotenv import load_dotenv
import os
load_dotenv()
client = MemoryClient(api_key=os.getenv("MEM0_API_KEY"))Pour enregistrer un souvenir, veuillez transmettre une conversation au format de chat OpenAI. Le paramètre user_id limite les mémoires à un utilisateur spécifique :
messages = [
{"role": "user", "content": "I'm a vegetarian and allergic to nuts."},
{"role": "assistant", "content": "Got it! I'll remember that."}
]
client.add(messages, user_id="user123")Le traitement de la mémoire s'effectue en arrière-plan. La méthode ` add() ` renvoie immédiatement un statut en attente pendant que Mem0 extrait et stocke les faits pertinents.
Pour récupérer des souvenirs, veuillez utiliser search() avec une requête en langage naturel :
results = client.search("dietary restrictions", filters={"user_id": "user123"})La réponse contient les souvenirs extraits avec des scores de pertinence :
{'results': [
{'memory': 'User is allergic to nuts', 'user_id': 'user123', 'score': 0.66},
{'memory': 'User is a vegetarian', 'user_id': 'user123', 'score': 0.65}
]}Veuillez noter que Mem0 a automatiquement divisé « végétarien » et « allergique aux noix » en deux faits distincts. Le système gère l'extraction et, lorsque vous effectuez une recherche, il renvoie les souvenirs les plus pertinents en fonction de leur similarité sémantique.
Maintenant que nous avons abordé les bases, nous allons créer quelque chose de plus concret.
Le processus de base d'ajout/recherche est utile, mais les applications réelles nécessitent davantage de sophistication. Développons un agent d'accompagnement à l'apprentissage qui décide de manière autonome quand stocker, récupérer et mettre à jour les souvenirs. Nous utiliserons le SDK OpenAI Agents pour doter notre agent d'outils de mémoire qu'il pourra utiliser de manière autonome.
Si vous débutez dans la création d'agents avec les LLM, veuillez consulter notre tutoriel sur la création d'agents LangChain pour obtenir des informations générales sur les concepts. Pour approfondir vos connaissances sur le SDK OpenAI Agents, veuillez consulter le tutoriel SDK OpenAI Agents.
Veuillez installer le SDK OpenAI Agents avec Mem0 :
pip install openai-agents mem0ai python-dotenvVeuillez ajouter votre clé API OpenAI au fichier .env:
MEM0_API_KEY=your-mem0-key
OPENAI_API_KEY=your-openai-keyMaintenant, veuillez initialiser les deux clients et créer une classe de contexte pour transmettre les informations utilisateur aux outils :
import os
from dataclasses import dataclass
from agents import Agent, Runner, function_tool, RunContextWrapper
from mem0 import MemoryClient
from dotenv import load_dotenv
load_dotenv()
mem0 = MemoryClient(api_key=os.getenv("MEM0_API_KEY"))
@dataclass
class UserContext:
user_id: strLa classe de données UserContext contient les données spécifiques à l'utilisateur requises par les outils. RunContextWrapper nous permet de transmettre ce contexte à tout outil appelé par l'agent.
L'agent a besoin de trois outils : recherche, enregistrement et mise à jour. Nous utilisons le décorateur @function_tool pour les exposer à l'agent.
Tout d'abord, l'outil de recherche récupère les souvenirs pertinents. Nous incluons les identifiants de mémoire dans la sortie afin que l'agent puisse s'y référer pour les mises à jour :
@function_tool
def search_memory(ctx: RunContextWrapper[UserContext], query: str) -> str:
"""Search through past learning history and memories."""
memories = mem0.search(
query,
filters={"user_id": ctx.context.user_id},
limit=5
)
if memories and memories.get("results"):
return "\n".join([
f"- [ID: {m['id']}] {m['memory']}" for m in memories["results"]
])
return "No relevant memories found."Ensuite, l'outil d'enregistrement stocke les nouvelles informations :
@function_tool
def save_memory(ctx: RunContextWrapper[UserContext], content: str) -> str:
"""Save new information about the user's learning journey."""
mem0.add(
[{"role": "user", "content": content}],
user_id=ctx.context.user_id
)
return "Memory saved successfully."Enfin, l'outil de mise à jour modifie les mémoires existantes lorsque les informations changent :
@function_tool
def update_memory(ctx: RunContextWrapper[UserContext], memory_id: str, new_text: str) -> str:
"""Update an existing memory with new information."""
mem0.update(memory_id=memory_id, text=new_text)
return f"Memory {memory_id} updated."Nous créons maintenant l'agent avec des instructions sur le moment où utiliser chaque outil :
agent = Agent(
name="Learning Companion",
instructions="""You are a helpful learning companion with memory.
Use search_memory to recall what the user is learning and their level.
Search results include memory IDs in format [ID: xxx].
Use save_memory to store new topics, preferences, or progress.
Use update_memory when information changes. First search to find the memory ID, then call update_memory with that ID and the new text.
Always check memory before responding to personalize your answers.""",
tools=[search_memory, save_memory, update_memory],
model="gpt-4o"
)Nous utilisons ici gpt-4o, mais pour améliorer le raisonnement lié à l'utilisation des outils, je recommande d'utiliser GPT-5. Nous vous invitons à consulter notre tutoriel sur l'API GPT-5 pour découvrirses nouvelles fonctionnalités en action.
La fonction de chat transmet le contexte utilisateur à l'agent :
def chat(user_input: str, user_id: str) -> str:
result = Runner.run_sync(
agent,
user_input,
context=UserContext(user_id=user_id)
)
return result.final_outputChaque appel à Runner.run_sync() est totalement indépendant de tous les autres appels. Le SDK OpenAI Agents ne conserve pas l'historique des conversations entre les appels par défaut.
Ceci est intentionnel pour notre démonstration : lorsque l'agent mémorise les informations utilisateur d'un appel à l'autre, cette mémoire doit provenir de Mem0, et non d'un état caché de l'agent.
Vérifions à l'aide de requêtes qui nécessitent une récupération réelle de la mémoire. L'agent ne peut pas deviner correctement les réponses sans accéder aux informations stockées.
Tout d'abord, veuillez enregistrer certaines informations utilisateur :
response = chat(
"My name is Alex. I am learning data visualization with matplotlib. "
"I am at intermediate level.",
"student_01"
)
print(response)Got it, Alex! You're learning data visualization with Matplotlib at an intermediate level. How can I assist you today?Après avoir attendu quelques secondes pour le traitement asynchrone, veuillez vérifier le rappel :
response = chat("What is my name and what library am I learning?", "student_01")
print(response)Your name is Alex, and you're learning data visualization using Matplotlib at an intermediate level.Veuillez maintenant tester la fonctionnalité de mise à jour :
response = chat(
"I switched from matplotlib to seaborn. Please update your memory.",
"student_01"
)
print(response)Got it! I've updated your learning preference to Seaborn for data visualization at an intermediate level. If you need help with anything specific, just let me know!Vérifiez que la mise à jour a été effectuée avec succès :
response = chat("What visualization library am I using now?", "student_01")
print(response)You are currently using Seaborn for data visualization at an intermediate level.Enfin, veuillez tester la persistance entre les conversations :
response = chat("Give me a summary of everything you know about me.", "student_01")
print(response)Here's what I know about you:
- Your name is Alex.
- You are learning data visualization with Seaborn at an intermediate level.
Is there anything else you'd like to update or add?L'agent choisit l'outil à utiliser en fonction de la conversation.
Lorsque l'utilisateur demande des informations sur son profil, cela appelle search_memory. Lorsqu'ils partagent de nouvelles informations, cela requiert l'save_memory. Lorsqu'ils indiquent que les informations ont été modifiées, le système recherche d'abord l'ID de mémoire, puis appelle update_memory.
Nous ne lui indiquons jamais explicitement quel outil utiliser pour chaque message.
Ceci diffère du processus manuel d'ajout/recherche décrit à la section 3. Dans ce cas, nous avons explicitement appelé des méthodes. Dans ce cas, l'agent prend ces décisions. Ce modèle s'adapte mieux aux applications complexes où il n'est pas possible de prévoir tous les types d'interactions.

Comparaison des flux de travail manuels et automatisés en termes d'évolutivité
Remarque importante : le traitement de la mémoireest asynchrone . asynchrone. Après avoir appelé save_memory, il y a un bref délai avant que la nouvelle mémoire ne devienne consultable. En production, il est recommandé de prendre cela en compte dans votre interface utilisateur.
L'agent de base gère les opérations de mémoire, mais les applications de production nécessitent un contrôle plus précis sur ce qui est stocké et comment cela est récupéré. Mem0 propose des paramètres au niveau du projet qui améliorent la qualité de la mémoire, notamment des catégories personnalisées pour l'organisation, des instructions définies par l'utilisateur pour le filtrage, des recherches ciblées et des opérations de nettoyage.
Par défaut, Mem0 utilise des catégories génériques telles que l'alimentation, les voyages et les loisirs. Pour des applications spécifiques telles que notre compagnon d'apprentissage, ces éléments ne sont pas d'une grande utilité pour l' . Vous pouvez définir vos propres catégories en fonction de votre domaine :
client.project.update(custom_categories=[
{"name": "topics", "description": "Programming languages, frameworks, or subjects"},
{"name": "skill_levels", "description": "Proficiency: beginner, intermediate, advanced"},
{"name": "goals", "description": "Learning objectives and targets"},
{"name": "progress", "description": "Completed courses, chapters, or milestones"},
{"name": "preferences", "description": "Learning style, schedule, or format preferences"}
])Une fois configuré, le classificateur de Mem0 attribue automatiquement vos catégories aux souvenirs entrants. Lorsque Alex déclare : « J'apprends Python au niveau débutant », le système associe cette déclaration aux balises topics et skill_levels. Il n'est pas nécessaire de modifier votre code d'agent. La catégorisation est effectuée lors de l'extraction de la mémoire.
Les instructions personnalisées vous permettent de contrôler précisément les éléments extraits des conversations. Vous rédigez des directives en langage naturel, et Mem0 les suit lors du traitement de nouveaux souvenirs :
client.project.update(custom_instructions="""
Extract and remember:
- Programming topics and technologies mentioned
- Current skill level for each topic
- Learning goals and deadlines
- Progress updates and completions
- Preferred learning resources (videos, docs, exercises)
Do not store:
- Personal identifiers beyond the user_id
- Payment or financial information
- Off-topic conversation that isn't about learning
""")Ceci est important pour les applications de production. Sans instructions, Mem0 pourrait stocker des détails non pertinents ou des informations sensibles. Les instructions personnalisées agissent comme un filtre, permettant de concentrer les souvenirs sur ce dont votre application a réellement besoin. Pour les scénarios de conformité tels que le RGPD, il est possible d'exclure explicitement certaines catégories de données à caractère personnel.
Grâce aux souvenirs classés par catégorie, votre outil de recherche peut être plus précis. Au lieu de rechercher dans tous les souvenirs, veuillez filtrer par catégorie pour obtenir exactement ce dont vous avez besoin :
@function_tool
def search_memory(
ctx: RunContextWrapper[UserContext],
query: str,
category: str = None
) -> str:
"""Search learning history. Optionally filter by category."""
filters = {"user_id": ctx.context.user_id}
if category:
filters["categories"] = {"contains": category}
memories = mem0.search(query, filters=filters, limit=5)
if memories and memories.get("results"):
return "\n".join([
f"- [ID: {m['id']}] {m['memory']}" for m in memories["results"]
])
return "No relevant memories found."Lorsque l'agent doit répondre à la question « Quels sujets ai-je appris ? », il peut effectuer une recherche avec category="topics" et ignorer les souvenirs non pertinents concernant les préférences ou les objectifs. Les instructions destinées à l'agent doivent mentionner ces catégories afin qu'il sache quand utiliser les recherches filtrées.
Les utilisateurs peuvent souhaiter supprimer des souvenirs obsolètes ou incorrects. Veuillez ajouter un outil de suppression pour permettre à l'agent d'effectuer cette opération :
@function_tool
def delete_memory(ctx: RunContextWrapper[UserContext], memory_id: str) -> str:
"""Delete a specific memory by ID."""
mem0.delete(memory_id=memory_id)
return f"Memory {memory_id} deleted."Pour les opérations en masse, vous pouvez effacer directement toutes les mémoires d'un utilisateur :
mem0.delete_all(user_id="student_01")La suppression est utile lorsque les informations changent complètement plutôt que lorsqu'elles sont mises à jour. Si un utilisateur exprime le souhait d'« oublier tout ce qu'il a appris sur Python », l'agent peut rechercher les souvenirs pertinents et les supprimer un par un, ou bien vous pouvez proposer une option de réinitialisation qui efface entièrement son profil.
Ces quatre options de configuration permettent de transformer l'agent d'une version de démonstration en un produit prêt à être commercialisé. Les catégories organisent automatiquement les souvenirs, les instructions garantissent que seules les informations pertinentes sont stockées, les recherches filtrées permettent de retrouver précisément ce dont on a besoin et la suppression permet de faire le ménage. Les modifications apportées au code de l'agent sont minimes, car la plupart d'entre elles se produisent au niveau de la configuration du projet.
Pour plus de détails sur ces fonctionnalités, veuillez consulter la documentation officielle Mem0.
La mémoire standard stocke des faits isolés, tels que « Alex étudie l'Seaborn » et « Alex connaît l'matplotlib ». Cependant, cela ne reflète pas le fait qu'Alex a d'abord appris l' matplotlib, puis est passé à l' Seaborn. La mémoire graphique ajoute cette couche relationnelle. Lorsque l'ordre, la progression ou les liens entre les entités sont importants, la mémoire graphique offre à votre agent un contexte plus riche.
Remarque : La mémoire graphique est uniquement disponible avec un abonnement Pro (249 $/mois) ou supérieur.
Vous pouvez activer la mémoire graphique au niveau du projet :
client.project.update(enable_graph=True)enable_graph=TrueUne autre option consiste à transmettre des informations sur les requêtes individuelles :
client.add(messages, user_id="student_01", enable_graph=True)Une fois activé, Mem0 extrait automatiquement les entités (personnes, sujets, outils, dates) et les relations entre elles à partir d'une conversation naturelle.
Lorsque vous effectuez une recherche avec la mémoire graphique, Mem0 renvoie à la fois les mémoires et un tableau d' relations s indiquant comment les entités sont connectées :
results = client.search(
"What has Alex learned?",
filters={"user_id": "student_01"},
enable_graph=True
)
# Results include both memories and relations
print(results.get("relations"))Les relations indiquent des liens tels que « Alex → a appris → matplotlib » et « Alex → est passé à → seaborn ». Votre agent peut désormais répondre à des questions sur la progression sans que vous ayez à stocker explicitement ces relations.
La mémoire graphique ajoute une charge de traitement supplémentaire, veuillez donc l'utiliser lorsque les relations sont importantes :
Plateformes d'apprentissage permettant de suivre le cursus des compétences
Service client analysant l'historique des interactions
Cartographie des dépendances des tâches dans la gestion de projet
Soins de santé reliant les symptômes et les traitements au fil du temps
Pour la simple mémorisation de faits, la mémoire standard est plus rapide. Activez la mémoire graphique lorsque votre agent doit raisonner sur des séquences ou des connexions entre des informations stockées.
Mem0 est disponible en deux versions : Plateforme et open source.
Tout au long de ce tutoriel, nous avons utilisé la version Platform, qui est le service cloud géré accessible via MemoryClient et une clé APIprovenant de app.mem0.ai. Les deuxversions partagent les mêmes opérations de mémoire centrale (add(), search(), update(), delete()), mais elles diffèrent en termes de configuration, de prix et de contrôle.
La plateforme est un service hébergé par Mem0. Inscrivez-vous, obtenez une clé API et commencez à ajouter des souvenirs en quelques minutes. Mem0 gère l'infrastructure, la mise à l'échelle et les certifications de sécurité (telles que SOC 2 Type II ou RGPD).
Il existe quatre niveaux de tarification :
Gratuit : 10 000 mémoires, idéales pour le prototypage.
Forfait de base : 19 $ par mois , avec des limites plus élevées.
Pro : 249 $ par mois , pour les charges de travail de production.
Entreprise : Tarification personnalisée avec assistance dédiée.
La plateforme comprend des fonctionnalités qui ne sont pas disponibles en open source : mémoire graphique pour le suivi des relations, webhooks pour les notifications en temps réel, chat de groupe avec attribution des intervenants et analyses intégrées.
Vous payez à l'utilisation, mais vous économisez sur l'infrastructure et le temps consacré au DevOps.
La version open source fonctionne sur vos propres serveurs. Vous installez le package mem0ai, configurez votre base de données vectorielle et gérez vous-même le déploiement. Cela nécessite davantage de configuration, mais vous offre un contrôle total.
Plusieurs options sont disponibles pour l'infrastructure :
Bases de données vectorielles : Plus de 24 options, dont Qdrant, Chroma, Pinecone, PostgreSQL (pgvector) et MongoDB
Fournisseurs de LLM : Plus de 16 options, dont OpenAI, Anthropic, Ollama, Groq et des modèles locaux
Modèles d'intégration : OpenAI, HuggingFace ou des intégrateurs personnalisés
L'open source utilise la Memory classe au lieu de MemoryClient.
Vos coûts correspondent à ce que vous payez pour l'infrastructure (machines virtuelles cloud, hébergement de bases de données, appels API vers les fournisseurs LLM). À grande échelle, cette solution peut s'avérer plus économique que les tarifs proposés par la plateforme, mais vous êtes responsable de la maintenance, des sauvegardes et de la conformité.
Veuillez consulter le tableau suivant pour une comparaison entre les versions hébergées et open source de Mem0 :
|
Aspect |
Plateforme |
Open Source |
|
Temps de configuration |
Minutes |
De quelques heures à plusieurs jours |
|
Infrastructure |
Entièrement géré |
Autogéré |
|
Tarification |
0 à 249 $ par mois |
Vos coûts d'infrastructure |
|
Options de la base de données vectorielle |
Géré |
Plus de 24 choix |
|
Options LLM |
Géré |
Plus de 16 choix |
|
Certificats de conformité |
SOC 2, RGPD inclus |
Vous mettez en œuvre |
|
Emplacement des données |
Les serveurs de Mem0 |
Vos serveurs |
Je recommande de choisirPlatform pour le prototypage rapide, les applications de production sans frais généraux DevOps ou lorsque vous avez besoin d'une conformité intégrée.
Si vous privilégiez la souveraineté des données, les configurations de modèles personnalisées ou l'optimisation des coûts à grand volume, l'open source est le choix approprié.
Pour obtenir des guides de configuration détaillés, veuillez consulter le guide de démarrage rapide de la plateforme ou la présentation de l'open source.
Ce tutoriel a abordé l'ajout de mémoire persistante aux applications LLM avec Mem0. Vous avez commencé par des opérations de mémoire de base, puis vous avez créé un agent d'apprentissage qui gère de manière autonome sa propre mémoire à l'aide du SDK OpenAI Agents. À partir de là, vous avez configuré le comportement de la mémoire à l'aide de catégories personnalisées, d'instructions et de recherches filtrées. Enfin, vous avez comparé les options de déploiement de la plateforme et de l'open source.
Pour une utilisation en production, veuillez intégrer la gestion des erreurs autour des opérations mémoire et tenir compte des brefs délais après l'enregistrement de nouveaux souvenirs. Veuillez tenir compte des limites de débit si vous utilisez la version gratuite de la plateforme.
Êtes-vous prêt à aller au-delà des composants individuels et à maîtriser l'ensemble du développement d'applications d'IA ? Inscrivez-vous à la carrière d'ingénieur en IA pour développeurs sur.
Cours sur les agents IA
Cursus
Cours
Cours