
Programa
Associate AI Engineer para desenvolvedores
26 h
Você diz ao seu chatbot que é vegetariano. No dia seguinte, ele sugere uma receita de bife. Isso não é um bug. É assim que os LLMs funcionam. Eles não têm memória entre as sessões, tratando cada conversa como uma tela em branco.
Pra um uso casual, tá bom. Mas se você estiver criando aplicativos reais com usuários reais, essa falta de estado se torna um problema sério. Seus usuários esperam que a IA se lembre deles.
O Mem0 resolve isso adicionando uma camada de memória a qualquer LLM. Ele guarda, pega e atualiza informações sobre os usuários entre as sessões, pra que sua IA possa realmente aprender e se adaptar com o tempo.
Neste tutorial, você vai criar um assistente pessoal de IA que lembra as preferências do usuário, programa o histórico de conversas e fica mais inteligente a cada interação. Vamos falar sobre configurações na nuvem e auto-hospedadas pra você escolher o que é melhor pro seu projeto.
Se você nunca usou antes, faça este cursopara aprender a trabalhar com a API OpenAI.
Mem0 é uma camada de memória de código aberto que fica entre o seu aplicativo e o LLM. Ele pega automaticamente as informações importantes das conversas, guarda e mostra quando você precisar. O projeto arrecadou US$ 24 milhões em outubro de 2025 e funciona com qualquer provedor de LLM: OpenAI, Anthropic, Ollama ou seus próprios modelos.
O Mem0 organiza as memórias em três categorias:
Memória do usuário: Persiste em todas as conversas com uma pessoa específica. Se alguém disser que prefere estudar de manhã, essa informação vai ficar disponível em todas as sessões futuras.
Memória da sessão: Programa o contexto dentro de uma única conversa, como a receita atual que está sendo discutida.
Memória do agente: Armazena informações específicas de uma instância específica de um agente de IA.
Você pode juntar esses escopos para criar aplicativos complexos onde diferentes agentes compartilham (ou isolam) o que sabem sobre os usuários.
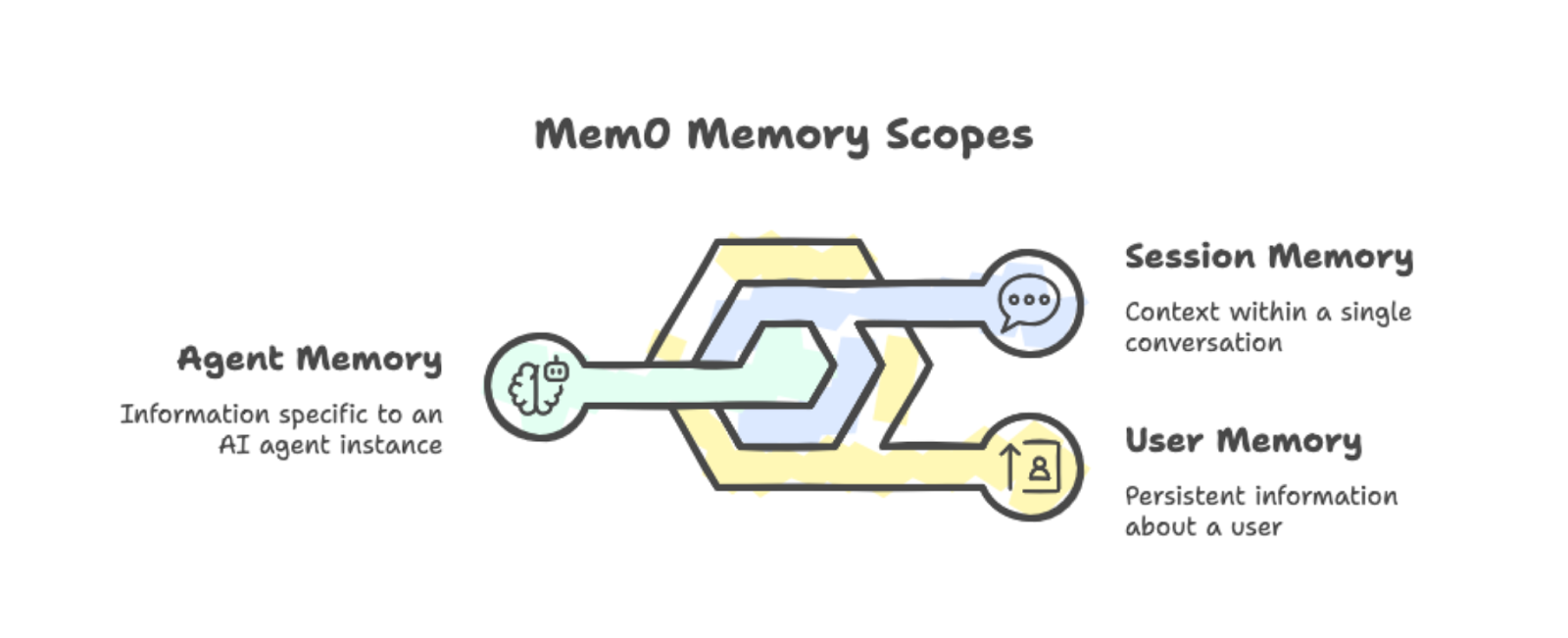
Os três escopos de memória: usuário, sessão e agente, com exemplos.
Nos bastidores, o Mem0 junta a pesquisa vetorial com as relações gráficas. Quando você adiciona uma conversa à memória, ela automaticamente pega as partes importantes. Você não precisa marcar manualmente o que deve ser lembrado.
Quando seu aplicativo precisa de contexto, o Mem0 busca memórias relevantes com base na consulta atual e as insere no prompt. Isso é melhor do que ter que colocar todo o seu histórico de conversas em cada solicitação.
Você pode usar o Mem0 de duas maneiras:
Plataforma: O serviço gerenciado baseado em nuvem em app.mem0.ai oferece configuração rápida e uma API.
Auto-hospedado: Dá a você controle total sobre sua infraestrutura, permitindo que você escolha seu banco de dados vetorial e modelo de incorporação.
As duas opções usam o mesmo SDK Python, então é fácil trocar entre elas.
Os ganhos de desempenho são reais, como mostra o artigo de pesquisa de Mem0s. No benchmark LOCOMO, o Mem0 teve uma pontuação 26% maior do que o recurso de memória integrado da OpenAI. Ele também responde 91% mais rápido, recuperando seletivamente as memórias relevantes em vez de processar todo o histórico de conversas. O uso de tokens cai cerca de 90% em comparação com abordagens de contexto completo.
Agora que você já sabe o que o Mem0 faz, vamos configurá-lo.
Instale o pacote junto com o python-dotenv para gerenciar chaves de API:
pip install mem0ai python-dotenvCadastre-se em app.mem0.ai e pegue sua chave API no painel de controle. Crie um arquivo .env no diretório do seu projeto:
MEM0_API_KEY=your-api-key-hereAgora, inicialize o cliente usando a chave da API:
from mem0 import MemoryClient
from dotenv import load_dotenv
import os
load_dotenv()
client = MemoryClient(api_key=os.getenv("MEM0_API_KEY"))Pra guardar uma memória, manda uma conversa no formato de chat da OpenAI. O parâmetro user_id define o escopo das memórias para um usuário específico:
messages = [
{"role": "user", "content": "I'm a vegetarian and allergic to nuts."},
{"role": "assistant", "content": "Got it! I'll remember that."}
]
client.add(messages, user_id="user123")O processamento da memória rola em segundo plano. O método ` add() ` volta rapidinho com um status pendente enquanto o Mem0 pega e guarda os fatos relevantes.
Para recuperar memórias, use search() com uma consulta em linguagem natural:
results = client.search("dietary restrictions", filters={"user_id": "user123"})A resposta tem as memórias extraídas com pontuações de relevância:
{'results': [
{'memory': 'User is allergic to nuts', 'user_id': 'user123', 'score': 0.66},
{'memory': 'User is a vegetarian', 'user_id': 'user123', 'score': 0.65}
]}Observe que o Mem0 automaticamente separou “vegetariano” e “alérgico a nozes” em dois fatos diferentes. O sistema cuida da extração e, quando você faz uma busca, ele mostra as memórias mais relevantes com base na semelhança semântica.
Agora que já vimos o básico, vamos criar algo mais prático.
O fluxo de trabalho básico de adicionar/pesquisar é útil, mas as aplicações reais precisam de mais sofisticação. Vamos criar um agente de aprendizagem que decide sozinho quando guardar, recuperar e atualizar memórias. Vamos usar o OpenAI Agents SDK para dar ao nosso agente ferramentas de memória que ele mesmo pode usar.
Se você é novo na criação de agentes com LLMs, dê uma olhada no nosso tutorial sobre como criar agentes LangChain para entender melhor os conceitos. Para saber mais sobre o SDK do OpenAI Agents, dá uma olhada no tutorial do SDK do OpenAI Agents.
Instale o OpenAI Agents SDK junto com o Mem0:
pip install openai-agents mem0ai python-dotenvAdicione sua chave API OpenAI ao arquivo ` .env `:
MEM0_API_KEY=your-mem0-key
OPENAI_API_KEY=your-openai-keyAgora, inicialize os dois clientes e crie uma classe de contexto para passar as informações do usuário para as ferramentas:
import os
from dataclasses import dataclass
from agents import Agent, Runner, function_tool, RunContextWrapper
from mem0 import MemoryClient
from dotenv import load_dotenv
load_dotenv()
mem0 = MemoryClient(api_key=os.getenv("MEM0_API_KEY"))
@dataclass
class UserContext:
user_id: strA classe de dados UserContext guarda os dados específicos do usuário que as ferramentas precisam. O objeto ` RunContextWrapper ` permite passar esse contexto para qualquer ferramenta que o agente chamar.
O agente precisa de três ferramentas: pesquisa, salvar e atualizar. Usamos o decorador ` @function_tool ` para expor esses dados ao agente.
Primeiro, a ferramenta de busca pega as memórias que são relevantes. Incluímos IDs de memória na saída para que o agente possa consultá-las para atualizações:
@function_tool
def search_memory(ctx: RunContextWrapper[UserContext], query: str) -> str:
"""Search through past learning history and memories."""
memories = mem0.search(
query,
filters={"user_id": ctx.context.user_id},
limit=5
)
if memories and memories.get("results"):
return "\n".join([
f"- [ID: {m['id']}] {m['memory']}" for m in memories["results"]
])
return "No relevant memories found."Depois, a ferramenta de salvar guarda as novas informações:
@function_tool
def save_memory(ctx: RunContextWrapper[UserContext], content: str) -> str:
"""Save new information about the user's learning journey."""
mem0.add(
[{"role": "user", "content": content}],
user_id=ctx.context.user_id
)
return "Memory saved successfully."Por fim, a ferramenta de atualização modifica as memórias existentes quando as informações mudam:
@function_tool
def update_memory(ctx: RunContextWrapper[UserContext], memory_id: str, new_text: str) -> str:
"""Update an existing memory with new information."""
mem0.update(memory_id=memory_id, text=new_text)
return f"Memory {memory_id} updated."Agora vamos criar o agente com instruções sobre quando usar cada ferramenta:
agent = Agent(
name="Learning Companion",
instructions="""You are a helpful learning companion with memory.
Use search_memory to recall what the user is learning and their level.
Search results include memory IDs in format [ID: xxx].
Use save_memory to store new topics, preferences, or progress.
Use update_memory when information changes. First search to find the memory ID, then call update_memory with that ID and the new text.
Always check memory before responding to personalize your answers.""",
tools=[search_memory, save_memory, update_memory],
model="gpt-4o"
)A gente usa o gpt-4o aqui, mas pra melhorar o raciocínio sobre o uso de ferramentas, recomendo usar o GPT-5. Fique à vontade para conferir nosso tutorial da API GPT-5 para verseus novos recursos em ação.
A função de chat passa o contexto do usuário para o agente:
def chat(user_input: str, user_id: str) -> str:
result = Runner.run_sync(
agent,
user_input,
context=UserContext(user_id=user_id)
)
return result.final_outputCada chamada para Runner.run_sync() é totalmente independente de todas as outras chamadas. O SDK do OpenAI Agents não guarda o histórico de conversas entre chamadas por padrão.
Isso é de propósito na nossa demonstração: quando o agente lembra das informações do usuário entre chamadas, essa memória precisa vir do Mem0, não de nenhum estado oculto do agente.
Vamos testar com consultas que exigem a recuperação real da memória. O agente não consegue adivinhar as respostas corretamente sem acessar as informações armazenadas.
Primeiro, guarda algumas informações do usuário:
response = chat(
"My name is Alex. I am learning data visualization with matplotlib. "
"I am at intermediate level.",
"student_01"
)
print(response)Got it, Alex! You're learning data visualization with Matplotlib at an intermediate level. How can I assist you today?Depois de esperar alguns segundos pelo processamento assíncrono, teste a recuperação:
response = chat("What is my name and what library am I learning?", "student_01")
print(response)Your name is Alex, and you're learning data visualization using Matplotlib at an intermediate level.Agora, teste a funcionalidade de atualização:
response = chat(
"I switched from matplotlib to seaborn. Please update your memory.",
"student_01"
)
print(response)Got it! I've updated your learning preference to Seaborn for data visualization at an intermediate level. If you need help with anything specific, just let me know!Confira se a atualização deu certo:
response = chat("What visualization library am I using now?", "student_01")
print(response)You are currently using Seaborn for data visualization at an intermediate level.Por fim, teste a persistência entre conversas:
response = chat("Give me a summary of everything you know about me.", "student_01")
print(response)Here's what I know about you:
- Your name is Alex.
- You are learning data visualization with Seaborn at an intermediate level.
Is there anything else you'd like to update or add?O agente escolhe qual ferramenta usar com base na conversa.
Quando o usuário pergunta sobre seu perfil, ele chama search_memory. Quando eles compartilham novas informações, isso chama save_memory. Quando dizem que a informação mudou, ele procura primeiro para obter o ID da memória e, em seguida, chama update_memory.
Nunca dizemos explicitamente qual ferramenta usar para cada mensagem.
Isso é diferente do fluxo de trabalho de adicionar/pesquisar manualmente da Seção 3. Lá, chamamos métodos explicitamente. Aqui, o agente toma essas decisões. Esse padrão funciona melhor para aplicativos complexos, onde você não consegue prever todos os tipos de interação.

Comparando fluxos de trabalho manuais e orientados por agentes para escalabilidade
Uma observação importante: o processamento da memóriaé assíncrono. Depois de chamar save_memory, tem um pequeno atraso antes que a nova memória fique disponível para pesquisa. Na produção, você vai querer levar isso em conta na sua interface de usuário.
O agente básico cuida das operações de memória, mas os aplicativos de produção precisam de um controle mais preciso sobre o que é armazenado e como é recuperado. O Mem0 oferece configurações no nível do projeto que melhoram a qualidade da memória, incluindo categorias personalizadas para organização, instruções definidas pelo usuário para filtragem, pesquisas direcionadas e operações de limpeza.
Por padrão, o Mem0 usa categorias genéricas como comida, viagens e hobbies. Para aplicações específicas, como o nosso companheiro de aprendizagem, isso não ajuda muito . Você pode definir suas próprias categorias que combinam com o seu domínio:
client.project.update(custom_categories=[
{"name": "topics", "description": "Programming languages, frameworks, or subjects"},
{"name": "skill_levels", "description": "Proficiency: beginner, intermediate, advanced"},
{"name": "goals", "description": "Learning objectives and targets"},
{"name": "progress", "description": "Completed courses, chapters, or milestones"},
{"name": "preferences", "description": "Learning style, schedule, or format preferences"}
])Depois de configurado, o classificador do Mem0 marca automaticamente as memórias recebidas com suas categorias. Quando Alex diz: “Estou aprendendo Python no nível iniciante”, o sistema marca isso com as tags topics e skill_levels. Você não precisa mudar o seu código de agente. A categorização rola durante a extração da memória.
As instruções personalizadas permitem que você controle exatamente o que é extraído das conversas. Você escreve diretrizes em linguagem natural, e o Mem0 segue essas diretrizes ao processar novas memórias:
client.project.update(custom_instructions="""
Extract and remember:
- Programming topics and technologies mentioned
- Current skill level for each topic
- Learning goals and deadlines
- Progress updates and completions
- Preferred learning resources (videos, docs, exercises)
Do not store:
- Personal identifiers beyond the user_id
- Payment or financial information
- Off-topic conversation that isn't about learning
""")Isso é importante para aplicativos de produção. Sem instruções, o Mem0 pode guardar detalhes irrelevantes ou informações confidenciais. As instruções personalizadas funcionam como um filtro, mantendo as memórias focadas no que a sua aplicação realmente precisa. Para cenários de conformidade como o GDPR, você pode excluir explicitamente categorias de dados pessoais.
Com as memórias organizadas por categorias, sua ferramenta de busca pode ser mais precisa. Em vez de procurar em todas as memórias, use um filtro por categoria pra achar exatamente o que você precisa:
@function_tool
def search_memory(
ctx: RunContextWrapper[UserContext],
query: str,
category: str = None
) -> str:
"""Search learning history. Optionally filter by category."""
filters = {"user_id": ctx.context.user_id}
if category:
filters["categories"] = {"contains": category}
memories = mem0.search(query, filters=filters, limit=5)
if memories and memories.get("results"):
return "\n".join([
f"- [ID: {m['id']}] {m['memory']}" for m in memories["results"]
])
return "No relevant memories found."Quando o agente precisa responder “Que tópicos eu aprendi?”, ele pode pesquisar com “ category="topics" ” e pular as memórias que não têm a ver com preferências ou objetivos. As instruções do agente devem mencionar essas categorias, para que ele saiba quando usar pesquisas filtradas.
Os usuários podem querer tirar memórias antigas ou erradas. Adicione uma ferramenta de exclusão para dar ao agente essa capacidade:
@function_tool
def delete_memory(ctx: RunContextWrapper[UserContext], memory_id: str) -> str:
"""Delete a specific memory by ID."""
mem0.delete(memory_id=memory_id)
return f"Memory {memory_id} deleted."Para operações em massa, você pode limpar todas as memórias de um usuário diretamente:
mem0.delete_all(user_id="student_01")A exclusão é útil quando as informações mudam completamente, em vez de serem atualizadas. Se um usuário disser “esqueça tudo sobre meu aprendizado de Python”, o agente pode procurar memórias relevantes e apagá-las uma a uma, ou você pode oferecer uma opção de reinicialização que limpa totalmente o perfil dele.
Essas quatro opções de configuração transformam o agente de uma demonstração em algo que você pode enviar. As categorias organizam as memórias automaticamente, as instruções garantem que só as informações relevantes sejam guardadas, as pesquisas filtradas recuperam exatamente o que é necessário e a exclusão cuida da limpeza. As alterações no código do agente são mínimas, já que a maior parte disso acontece no nível da configuração do projeto.
Para mais detalhes sobre esses recursos, veja a documentação oficial do Mem0.
A memória padrão guarda fatos isolados, tipo “Alex está aprendendo Seaborn ” e “Alex sabe matplotlib ”. Mas isso não mostra que o Alex aprendeu primeiro matplotlib e depois mudou para Seaborn. A memória gráfica adiciona essa camada de relacionamento. Quando ordem, progressão ou conexões entre entidades são importantes, a memória gráfica dá ao seu agente um contexto mais rico.
Observação: A memória gráfica só está disponível com um plano Pro (US$ 249/mês) ou superior.
Você pode ativar a memória gráfica no nível do projeto:
client.project.update(enable_graph=True)Outra opção é passar um enable_graph=True e em solicitações individuais:
client.add(messages, user_id="student_01", enable_graph=True)Uma vez ativado, o Mem0 pega automaticamente as entidades (pessoas, assuntos, ferramentas, datas) e as relações entre elas a partir de conversas naturais.
Quando você faz uma busca com a memória de grafos, Mem0 mostra as memórias e uma matriz de conexões ( relations ) que mostra como as entidades se conectam:
results = client.search(
"What has Alex learned?",
filters={"user_id": "student_01"},
enable_graph=True
)
# Results include both memories and relations
print(results.get("relations"))As relações mostram conexões como “Alex → aprendeu → matplotlib ” e “Alex → mudou para → seaborn ”. Agora, seu agente pode responder perguntas sobre progressão sem que você precise armazenar essas relações explicitamente.
A memória gráfica adiciona sobrecarga de processamento, então use-a quando as relações forem importantes:
Plataformas de aprendizagem que acompanham o progresso das habilidades
Suporte ao cliente analisando o histórico de interações
Mapeamento das dependências das tarefas do gerenciamento de projetos
Saúde conectando sintomas e tratamentos ao longo do tempo
Para lembrar fatos simples, a memória padrão é mais rápida. Ative a memória gráfica quando seu agente precisar raciocinar sobre sequências ou conexões entre informações armazenadas.
O Mem0 vem em duas versões: Plataforma e código aberto.
Ao longo deste tutorial, usamos a versão Platform, que é o serviço de nuvem gerenciado acessado por MemoryClient e uma chave APIdo app.mem0.ai. As duasversões têm as mesmas operações de memória central (add(), search(), update(), delete()), mas são diferentes em configuração, preço e controle.
A plataforma é um serviço hospedado pela Mem0. Você se inscreve, pega uma chave API e começa a adicionar memórias em poucos minutos. A Mem0 cuida da infraestrutura, do dimensionamento e das certificações de segurança (como SOC 2 Tipo II ou GDPR).
Existem quatro níveis de preços:
De graça: 10.000 memórias, ótimas para prototipagem.
Inicial: US$ 19/mês , com limites mais altos.
Prós: US$ 249/mês , para cargas de trabalho de produção.
Enterprise: Preços personalizados com suporte dedicado.
A plataforma tem recursos que não estão disponíveis em código aberto: memória gráfica para rastreamento de relacionamentos, webhooks para notificações em tempo real, chat em grupo com atribuição de falante e análises integradas.
Você paga por uso, mas economiza em infraestrutura e tempo de DevOps.
A versão de código aberto funciona nos seus próprios servidores. Você instala o pacote mem0ai, configura seu banco de dados vetorial e gerencia a implantação por conta própria. Isso exige mais configuração, mas dá a você controle total.
Tem várias opções disponíveis para infraestrutura:
Bancos de dados vetoriais: Mais de 24 opções, incluindo Qdrant, Chroma, Pinecone, PostgreSQL (pgvector) e MongoDB
Provedores de LLM: Mais de 16 opções, incluindo OpenAI, Anthropic, Ollama, Groq e modelos locais
Modelos incorporados: OpenAI, HuggingFace ou incorporadores personalizados
O código aberto usa a Memory classe em vez de MemoryClient.
Seus custos são o que você paga pela infraestrutura (VMs na nuvem, hospedagem de banco de dados, chamadas de API para provedores de LLM). Em grande escala, isso pode ser mais barato do que os preços da plataforma, mas você é responsável por cuidar da manutenção, dos backups e da conformidade.
Dá uma olhada na tabela abaixo pra comparar as versões hospedada e de código aberto do Mem0 :
|
Aspecto |
Plataforma |
Código aberto |
|
Tempo de configuração |
Ata |
De horas a dias |
|
Infraestrutura |
Totalmente gerenciado |
Autogerenciado |
|
Preços |
R$ 0-249+/mês |
Seus custos de infraestrutura |
|
Opções do banco de dados vetorial |
Gerenciado |
Mais de 24 opções |
|
Opções de LLM |
Gerenciado |
Mais de 16 opções |
|
Certificados de conformidade |
SOC 2, GDPR incluído |
Você implementa |
|
Localização dos dados |
Servidores da Mem0 |
Seus servidores |
Minha dica é escolhera Plataforma para prototipagem rápida, apps de produção sem sobrecarga de DevOps ou quando você precisar de conformidade integrada.
Se você está focado em soberania de dados, configurações personalizadas de modelos ou otimização de custos em grandes volumes, o código aberto é a escolha certa.
Para guias detalhados de configuração, veja o guia rápido da plataforma ou a visão geral do código aberto.
Este tutorial abordou a adição de memória persistente a aplicativos LLM com o Mem0. Você começou com operações básicas de memória e, em seguida, criou um agente de aprendizagem que gerencia sua própria memória de forma autônoma usando o OpenAI Agents SDK. A partir daí, você configurou o comportamento da memória com categorias personalizadas, instruções e pesquisas filtradas. Por fim, você comparou as opções de implantação da plataforma e do código aberto.
Para uso em produção, adicione tratamento de erros em torno das operações de memória e leve em consideração breves atrasos após salvar novas memórias. Pense nos limites de taxa se você estiver usando o plano gratuito da Plataforma.
Pronto para ir além dos componentes individuais e dominar todo o desenvolvimento de aplicativos de IA? Inscreva-se no curso de Engenheiro de IA para Desenvolvedores d.
Cursos de Agente de IA
Programa
Curso
Curso
Tutorial
Moez Ali
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita

