
Lernpfad
Associate AI Engineer für Entwickler
26 Std.
Du sagst deinem Chatbot, dass du Vegetarier bist. Am nächsten Tag schlägt es ein Steak-Rezept vor. Das ist kein Fehler. So funktionieren LLMs eben. Sie haben zwischen den Sitzungen kein Gedächtnis und sehen jedes Gespräch als Neuanfang.
Für den normalen Gebrauch ist das okay. Aber wenn du echte Anwendungen mit echten Nutzern entwickelst, wird diese Zustandslosigkeit zu einem echten Problem. Deine Nutzer erwarten, dass die KI sich an sie erinnert.
Mem0 löst das, indem es jedem LLM eine Speicherschicht hinzufügt. Es speichert, ruft ab und aktualisiert Infos über Nutzer über mehrere Sitzungen hinweg, sodass deine KI mit der Zeit wirklich lernen und sich anpassen kann.
In diesem Tutorial baust du einen persönlichen KI-Assistenten, der sich die Vorlieben der Nutzer merkt, den Lernpfad von Unterhaltungen verfolgt und mit jeder Interaktion schlauer wird. Wir zeigen dir sowohl Cloud- als auch selbst gehostete Setups, damit du das für dein Projekt passende auswählen kannst.
Wenn du es noch nie benutzt hast, mach diesen Kurs, um zu lernen, wie man mit der OpenAI-API arbeitet.
Mem0 ist eine Open-Source-Speicherschicht, die zwischen deiner Anwendung und dem LLM sitzt. Es holt automatisch wichtige Infos aus Gesprächen raus, speichert sie und kann sie bei Bedarf wieder abrufen. Das Projekt hat im Oktober 2025 24 Millionen Dollar eingesammelt und funktioniert mit jedem LLM-Anbieter: OpenAI, Anthropic, Ollama oder deine eigenen Modelle.
Mem0 sortiert Erinnerungen in drei Bereiche:
Benutzerspeicher: Bleibt in allen Unterhaltungen mit einer bestimmten Person bestehen. Wenn jemand sagt, dass er lieber morgens lernt, wird das bei allen zukünftigen Lernsitzungen berücksichtigt.
Sitzungsspeicher: Lernpfad den Kontext innerhalb einer einzelnen Unterhaltung, wie zum Beispiel das gerade besprochene Rezept.
Agentenspeicher: Speichert Infos, die für eine bestimmte KI-Agenteninstanz wichtig sind.
Du kannst diese Bereiche kombinieren, um komplexe Anwendungen zu erstellen, bei denen verschiedene Agenten ihre Informationen über Benutzer teilen (oder isolieren).
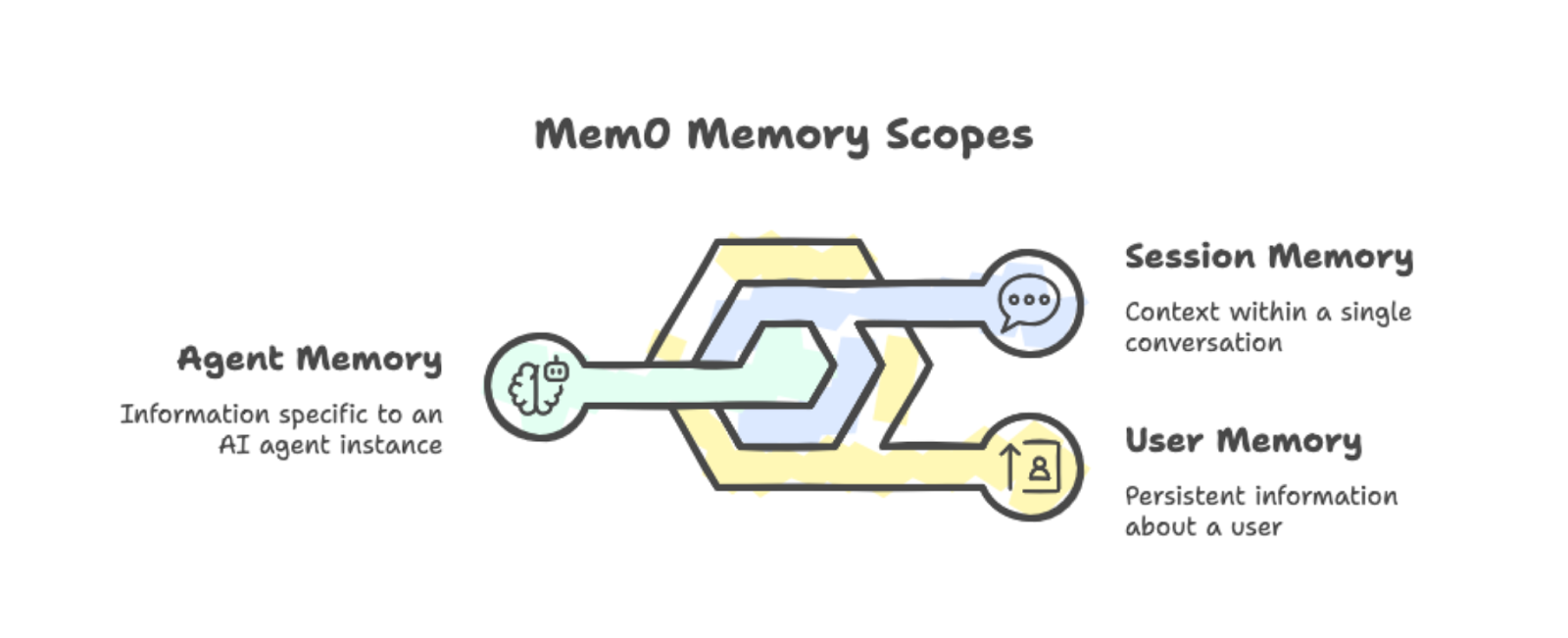
Die drei Speicherbereiche: Benutzer, Sitzung und Agent, mit Beispielen.
Im Hintergrund kombiniert Mem0 Vektorsuche mit Graphenbeziehungen. Wenn du eine Unterhaltung speicherst, werden automatisch die wichtigen Teile rausgesucht. Du musst nicht manuell markieren, was du dir merken solltest.
Wenn deine App Kontext braucht, holt Mem0 die passenden Erinnerungen anhand der aktuellen Anfrage und fügt sie in die Eingabeaufforderung ein. Das ist besser, als bei jeder Anfrage den ganzen Gesprächsverlauf mitzuschicken.
Du kannst Mem0 auf zwei Arten ausführen:
Plattform: Der Cloud-basierte Managed Service von app.mem0.ai lässt sich schnell einrichten und hat eine API.
Selbst gehostet: Du hast die volle Kontrolle über deine Infrastruktur und kannst deine Vektordatenbank und dein Einbettungsmodell selbst auswählen.
Beide Optionen nutzen dasselbe Python SDK, sodass man ganz einfach zwischen ihnen wechseln kann.
Die Leistungssteigerungen sind echt, wie die Forschungsarbeit von Mem0 zeigt:s. Beim LOCOMO-Benchmark hat Mem0 26 % besser abgeschnitten als die eingebaute Speicherfunktion von OpenAI. Außerdem reagiert es 91 % schneller, weil es nur die relevanten Erinnerungen abruft, statt den ganzen Gesprächsverlauf durchzugehen. Die Verwendung von Token geht im Vergleich zu Ansätzen mit vollem Kontext um etwa 90 % zurück.
Jetzt, wo du weißt, was Mem0 macht, lass es uns einrichten.
Installiere das Paket zusammen mit python-dotenv, um API-Schlüssel zu verwalten:
pip install mem0ai python-dotenvMelde dich bei app.mem0.ai an und hol dir deinen API-Schlüssel aus dem Dashboard. Mach eine Datei namens „ .env “ in deinem Projektverzeichnis:
MEM0_API_KEY=your-api-key-hereJetzt startest du den Client mit dem API-Schlüssel:
from mem0 import MemoryClient
from dotenv import load_dotenv
import os
load_dotenv()
client = MemoryClient(api_key=os.getenv("MEM0_API_KEY"))Um eine Erinnerung zu speichern, gib einfach eine Unterhaltung im OpenAI-Chat-Format weiter. Der Parameter „ user_id “ beschränkt den Speicher auf einen bestimmten Benutzer:
messages = [
{"role": "user", "content": "I'm a vegetarian and allergic to nuts."},
{"role": "assistant", "content": "Got it! I'll remember that."}
]
client.add(messages, user_id="user123")Die Speicherverarbeitung läuft im Hintergrund ab. Die Methode „ add() “ kommt sofort mit einem ausstehenden Status zurück, während Mem0 die relevanten Fakten extrahiert und speichert.
Um Erinnerungen abzurufen, benutze search() mit einer natürlichen Sprachabfrage:
results = client.search("dietary restrictions", filters={"user_id": "user123"})Die Antwort hat die extrahierten Erinnerungen mit Relevanzbewertungen:
{'results': [
{'memory': 'User is allergic to nuts', 'user_id': 'user123', 'score': 0.66},
{'memory': 'User is a vegetarian', 'user_id': 'user123', 'score': 0.65}
]}Schau mal, Mem0 hat „vegetarisch” und „nussallergisch” automatisch in zwei separate Fakten aufgeteilt. Das System kümmert sich um die Extraktion und zeigt bei der Suche die relevantesten Erinnerungen an, basierend auf semantischer Ähnlichkeit.
Nachdem wir die Grundlagen geklärt haben, lass uns was Praktischeres machen.
Der grundlegende Arbeitsablauf zum Hinzufügen/Suchen ist nützlich, aber echte Anwendungen brauchen mehr Raffinesse. Lass uns einen Lernbegleiter entwickeln, der selbstständig entscheidet, wann Erinnerungen gespeichert, abgerufen und aktualisiert werden. Wir nutzen das OpenAI Agents SDK, um unserem Agenten Speicher-Tools zu geben, die er selbstständig nutzen kann.
Wenn du noch keine Erfahrung mit der Entwicklung von Agenten mit LLMs hast, schau dir unser Tutorial zur Entwicklung von LangChain-Agenten an, um mehr über die Konzepte zu erfahren. Wenn du dich genauer mit dem OpenAI Agents SDK beschäftigen willst, schau dir das OpenAI Agents SDK-Tutorial an.
Installiere das OpenAI Agents SDK zusammen mit Mem0:
pip install openai-agents mem0ai python-dotenvFüge deinen OpenAI-API-Schlüssel zur Datei „ .env “ hinzu:
MEM0_API_KEY=your-mem0-key
OPENAI_API_KEY=your-openai-keyJetzt initialisierst du beide Clients und erstellst eine Kontextklasse, um Benutzerinfos an Tools weiterzugeben:
import os
from dataclasses import dataclass
from agents import Agent, Runner, function_tool, RunContextWrapper
from mem0 import MemoryClient
from dotenv import load_dotenv
load_dotenv()
mem0 = MemoryClient(api_key=os.getenv("MEM0_API_KEY"))
@dataclass
class UserContext:
user_id: strDie Datenklasse „ UserContext “ hat benutzerspezifische Daten, die von Tools gebraucht werden. Mit „ RunContextWrapper “ können wir diesen Kontext an jedes Tool weitergeben, das der Agent aufruft.
Der Agent braucht drei Tools: Suchen, Speichern und Aktualisieren. Wir benutzen den Dekorator „ @function_tool “, um diese für den Agenten sichtbar zu machen.
Zuerst holt die Suchfunktion relevante Erinnerungen raus. Wir packen Speicher-IDs in die Ausgabe, damit der Agent sie für Updates nutzen kann:
@function_tool
def search_memory(ctx: RunContextWrapper[UserContext], query: str) -> str:
"""Search through past learning history and memories."""
memories = mem0.search(
query,
filters={"user_id": ctx.context.user_id},
limit=5
)
if memories and memories.get("results"):
return "\n".join([
f"- [ID: {m['id']}] {m['memory']}" for m in memories["results"]
])
return "No relevant memories found."Als Nächstes speichert das Speicher-Tool neue Infos:
@function_tool
def save_memory(ctx: RunContextWrapper[UserContext], content: str) -> str:
"""Save new information about the user's learning journey."""
mem0.add(
[{"role": "user", "content": content}],
user_id=ctx.context.user_id
)
return "Memory saved successfully."Schließlich ändert das Update-Tool die vorhandenen Speicher, wenn sich die Infos ändern:
@function_tool
def update_memory(ctx: RunContextWrapper[UserContext], memory_id: str, new_text: str) -> str:
"""Update an existing memory with new information."""
mem0.update(memory_id=memory_id, text=new_text)
return f"Memory {memory_id} updated."Jetzt erstellen wir den Agenten mit Anweisungen, wann welches Tool eingesetzt werden soll:
agent = Agent(
name="Learning Companion",
instructions="""You are a helpful learning companion with memory.
Use search_memory to recall what the user is learning and their level.
Search results include memory IDs in format [ID: xxx].
Use save_memory to store new topics, preferences, or progress.
Use update_memory when information changes. First search to find the memory ID, then call update_memory with that ID and the new text.
Always check memory before responding to personalize your answers.""",
tools=[search_memory, save_memory, update_memory],
model="gpt-4o"
)Wir nutzen hier gpt-4o, aber um besser mit dem Tool umgehen zu können, empfehle ich, GPT-5 zu verwenden. Schau dir doch mal an, unser GPT-5-API-Tutorial, umdie neuen Funktionen in Aktion zu sehen.
Die Chat-Funktion gibt den Benutzerkontext an den Agenten weiter:
def chat(user_input: str, user_id: str) -> str:
result = Runner.run_sync(
agent,
user_input,
context=UserContext(user_id=user_id)
)
return result.final_outputJeder Aufruf von „ Runner.run_sync() “ ist komplett unabhängig von allen anderen Aufrufen. Das OpenAI Agents SDK speichert standardmäßig keine Konversationshistorie zwischen Anrufen.
Das ist bei unserer Demo absichtlich so gemacht: Wenn der Agent sich die Infos vom Nutzer über mehrere Anrufe hinweg merkt, muss das aus Mem0 kommen, nicht aus irgendeinem versteckten Zustand des Agenten.
Probieren wir mal ein paar Abfragen aus, die echtes Abrufen von Speicher brauchen. Der Agent kann die Antworten nicht richtig erraten, ohne auf gespeicherte Infos zuzugreifen.
Speichere zuerst ein paar Nutzerinfos:
response = chat(
"My name is Alex. I am learning data visualization with matplotlib. "
"I am at intermediate level.",
"student_01"
)
print(response)Got it, Alex! You're learning data visualization with Matplotlib at an intermediate level. How can I assist you today?Warte ein paar Sekunden für die asynchrone Verarbeitung und teste dann den Abruf:
response = chat("What is my name and what library am I learning?", "student_01")
print(response)Your name is Alex, and you're learning data visualization using Matplotlib at an intermediate level.Jetzt probier mal die Update-Funktion aus:
response = chat(
"I switched from matplotlib to seaborn. Please update your memory.",
"student_01"
)
print(response)Got it! I've updated your learning preference to Seaborn for data visualization at an intermediate level. If you need help with anything specific, just let me know!Überprüfe, ob das Update geklappt hat:
response = chat("What visualization library am I using now?", "student_01")
print(response)You are currently using Seaborn for data visualization at an intermediate level.Teste zum Schluss die Persistenz über mehrere Unterhaltungen hinweg:
response = chat("Give me a summary of everything you know about me.", "student_01")
print(response)Here's what I know about you:
- Your name is Alex.
- You are learning data visualization with Seaborn at an intermediate level.
Is there anything else you'd like to update or add?Der Mitarbeiter entscheidet anhand des Gesprächs, welches Tool er nutzt.
Wenn der Nutzer nach seinem Profil fragt, wird search_memory aufgerufen. Wenn sie neue Infos teilen, ruft das save_memory auf. Wenn sie sagen, dass sich die Infos geändert haben, sucht es erst nach der Speicher-ID und ruft dann „ update_memory “ auf.
Wir sagen ihm nie direkt, welches Tool für welche Nachricht benutzt werden soll.
Das ist anders als der manuelle Hinzufügen/Suchen-Vorgang in Abschnitt 3. Dort haben wir Methoden explizit aufgerufen. Hier trifft der Agent diese Entscheidungen. Dieses Muster eignet sich besser für komplexe Anwendungen, bei denen man nicht jede Art von Interaktion vorhersagen kann.

Vergleich von manuellen und agentenbasierten Arbeitsabläufen hinsichtlich ihrer Skalierbarkeit
Ein wichtiger Hinweis: Die Speicherverarbeitungläuft nicht synchron. Nachdem du „ save_memory “ aufgerufen hast , dauert es kurz, bis der neue Speicher durchsuchbar ist. In der Produktion solltest du das in deiner Benutzeroberfläche berücksichtigen.
Der Basisagent kümmert sich um Speicheroperationen, aber Produktionsanwendungen brauchen eine genauere Kontrolle darüber, was gespeichert und wie es abgerufen wird. Mem0 hat Einstellungen auf Projektebene, die die Speicherqualität verbessern, wie zum Beispiel eigene Kategorien zum Organisieren, benutzerdefinierte Anweisungen zum Filtern, gezielte Suchen und Bereinigungsvorgänge.
Standardmäßig nutzt Mem0 allgemeine Kategorien wie Essen, Reisen und Hobbys. Für bestimmte Anwendungen wie unseren Lernbegleiter sind diese nicht besonders hilfreich . Du kannst deine eigenen Kategorien festlegen, die zu deinem Bereich passen:
client.project.update(custom_categories=[
{"name": "topics", "description": "Programming languages, frameworks, or subjects"},
{"name": "skill_levels", "description": "Proficiency: beginner, intermediate, advanced"},
{"name": "goals", "description": "Learning objectives and targets"},
{"name": "progress", "description": "Completed courses, chapters, or milestones"},
{"name": "preferences", "description": "Learning style, schedule, or format preferences"}
])Sobald du ihn eingerichtet hast, sortiert der Mem0-Klassifikator neue Erinnerungen automatisch in deine Kategorien. Wenn Alex sagt: „Ich lerne Python auf Anfängerniveau“, markiert das System das mit den Tags „ topics “ und „ skill_levels “. Du musst deinen Agentencode nicht ändern. Die Kategorisierung passiert beim Auslesen des Speichers.
Mit benutzerdefinierten Anweisungen kannst du genau festlegen, was aus Unterhaltungen extrahiert werden soll:. Du schreibst Richtlinien in natürlicher Sprache, und Mem0 hält sich daran, wenn es neue Erinnerungen verarbeitet:
client.project.update(custom_instructions="""
Extract and remember:
- Programming topics and technologies mentioned
- Current skill level for each topic
- Learning goals and deadlines
- Progress updates and completions
- Preferred learning resources (videos, docs, exercises)
Do not store:
- Personal identifiers beyond the user_id
- Payment or financial information
- Off-topic conversation that isn't about learning
""")Das ist wichtig für Produktions-Apps. Ohne Anweisungen könnte Mem0 unwichtige Details oder sensible Infos speichern. Benutzerdefinierte Anweisungen sind wie ein Filter, der dafür sorgt, dass die Erinnerungen auf das konzentriert bleiben, was deine Anwendung wirklich braucht. Für Compliance-Szenarien wie die DSGVO kannst du bestimmte Kategorien personenbezogener Daten ganz klar ausschließen.
Mit kategorisierten Erinnerungen kannst du deine Suche genauer machen. Anstatt alle Erinnerungen zu durchsuchen, filter nach Kategorie, um genau das zu finden, was du brauchst:
@function_tool
def search_memory(
ctx: RunContextWrapper[UserContext],
query: str,
category: str = None
) -> str:
"""Search learning history. Optionally filter by category."""
filters = {"user_id": ctx.context.user_id}
if category:
filters["categories"] = {"contains": category}
memories = mem0.search(query, filters=filters, limit=5)
if memories and memories.get("results"):
return "\n".join([
f"- [ID: {m['id']}] {m['memory']}" for m in memories["results"]
])
return "No relevant memories found."Wenn der Agent die Frage „Welche Themen habe ich gelernt?“ beantworten muss, kann er mit „ category="topics" “ suchen und nicht relevante Erinnerungen zu Vorlieben oder Zielen überspringen. Die Anweisungen für den Agenten sollten diese Kategorien erwähnen, damit er weiß, wann er gefilterte Suchen verwenden soll.
Manche Leute möchten vielleicht alte oder falsche Erinnerungen löschen. Füge ein Löschwerkzeug hinzu, damit der Agent das machen kann:
@function_tool
def delete_memory(ctx: RunContextWrapper[UserContext], memory_id: str) -> str:
"""Delete a specific memory by ID."""
mem0.delete(memory_id=memory_id)
return f"Memory {memory_id} deleted."Für Massenoperationen kannst du alle Speicher eines Benutzers direkt löschen:
mem0.delete_all(user_id="student_01")Löschen ist sinnvoll, wenn sich Infos komplett ändern und nicht nur aktualisiert werden. Wenn jemand sagt: „Vergiss alles über mein Python-Lernen“, kann der Agent nach den entsprechenden Erinnerungen suchen und sie einzeln löschen, oder du kannst eine Reset-Option anbieten, die das Profil komplett löscht.
Mit diesen vier Konfigurationsoptionen wird der Agent von einer Demo zu einem Produkt, das du ausliefern kannst. Kategorien sortieren Erinnerungen automatisch, Anweisungen sorgen dafür, dass nur wichtige Infos gespeichert werden, gefilterte Suchen finden genau das, was man braucht, und das Löschen kümmert sich um die Aufräumarbeiten. Die Änderungen am Agentencode sind minimal, weil das meiste auf der Ebene der Projektkonfiguration passiert.
Mehr Infos zu diesen Funktionen findest du in der offiziellen Mem0-Dokumentation.
Der normale Speicher speichert einzelne Fakten, wie zum Beispiel „Alex lernt Seaborn “ und „Alex weiß matplotlib “. Aber es wird nicht erfasst, dass Alex zuerst matplotlib gelernt hat und dann zu Seaborn gewechselt ist. Der Graphenspeicher fügt diese Beziehungsebene hinzu. Wenn es auf Reihenfolge, Ablauf oder Verbindungen zwischen Entitäten ankommt, gibt der Graphspeicher deinem Agenten einen reichhaltigeren Kontext.
Anmerkung: Der Grafikspeicher ist nur mit einem Pro-Tarif (249 $/Monat) oder höher verfügbar.
Du kannst den Grafikspeicher auf Projektebene einschalten:
client.project.update(enable_graph=True)Eine andere Möglichkeit ist, „ enable_graph=True “ bei einzelnen Anfragen zu übergeben:
client.add(messages, user_id="student_01", enable_graph=True)Sobald Mem0 aktiv ist, zieht es automatisch Entitäten (Personen, Themen, Tools, Daten) und die Beziehungen zwischen ihnen aus natürlichen Gesprächen raus.
Wenn du mit dem Graphspeicher suchst, gibt Mem0 sowohl Speicher als auch ein Array „ relations “ zurück, das zeigt, wie Entitäten miteinander verbunden sind:
results = client.search(
"What has Alex learned?",
filters={"user_id": "student_01"},
enable_graph=True
)
# Results include both memories and relations
print(results.get("relations"))Die Beziehungen zeigen Verbindungen wie „Alex → gelernt → matplotlib “ und „Alex → gewechselt zu → seaborn “. Dein Agent kann jetzt Fragen zum Fortschritt beantworten, ohne dass du diese Beziehungen explizit speichern musst.
Der Graphenspeicher erhöht den Verarbeitungsaufwand, also nutze ihn nur, wenn Beziehungen wichtig sind:
Lernplattformen, die den Fortschritt beim Lernen verfolgen
Kundensupport, der die Interaktionshistorie checkt
Projektmanagement: Abhängigkeiten zwischen Aufgaben abbilden
Gesundheitswesen, das Symptome und Behandlungen über einen längeren Zeitraum miteinander verbindet
Zum Abrufen einfacher Fakten ist der Standard-Speicher schneller. Schalte den Graphenspeicher ein, wenn dein Agent über Sequenzen oder Verbindungen zwischen gespeicherten Infos nachdenken muss.
Mem0 gibt's in zwei Versionen: Plattform und Open Source.
In diesem Tutorial haben wir die Plattformversion benutzt, also den verwalteten Cloud, auf den man über MemoryClient und einen API-Schlüsselvon app.mem0.ai zugreifen kann. BeideVersionen haben die gleichen Kernspeicherfunktionen (add(), search(), update(), delete()), unterscheiden sich aber in der Einrichtung, den Preisen und der Steuerung.
Platform ist der gehostete Dienst von Mem0. Du meldest dich an, holst dir einen API-Schlüssel und kannst schon nach wenigen Minuten mit dem Hinzufügen von Erinnerungen loslegen. Mem0 kümmert sich um die Infrastruktur, Skalierung und Sicherheitszertifizierungen (wie SOC 2 Typ II oder DSGVO).
Es gibt vier Preisstufen:
Kostenlos: 10.000 Speicherplätze, super für Prototypen.
Starter: 19 $ pro Monat , mit höheren Limits.
Pro: 249 $/Monat für Produktions-Workloads.
Unternehmen: Individuelle Preise mit persönlichem Support.
Die Plattform hat ein paar coole Features, die man bei Open Source nicht findet: Graphspeicher für die Verfolgung von Beziehungen, Webhooks für Echtzeit-Benachrichtigungen, Gruppenchat mit Sprecherzuordnung und integrierte Analysen.
Du zahlst nur, wenn du es benutzt, sparst aber bei der Infrastruktur und der DevOps-Zeit.
Die Open-Source-Version läuft auf deinen eigenen Servern. Du installierst das Paket „ mem0ai “, richtest deine Vektordatenbank ein und kümmerst dich selbst um die Bereitstellung. Das braucht zwar mehr Einrichtung, gibt dir aber die volle Kontrolle.
Für die Infrastruktur gibt's mehrere Optionen:
Vektordatenbanken: Über 24 Optionen, darunter Qdrant, Chroma, Pinecone, PostgreSQL (pgvector) und MongoDB
LLM-Anbieter: Über 16 Optionen, darunter OpenAI, Anthropic, Ollama, Groq und lokale Modelle
Einbettungsmodelle: OpenAI, HuggingFace oder benutzerdefinierte Einbettungen
Open Source nutzt die Memory Klasse anstelle von MemoryClient.
Deine Kosten sind das, was du für die Infrastruktur bezahlst (Cloud-VMs, Datenbank-Hosting, API-Aufrufe an LLM-Anbieter). Bei großem Umfang kann das günstiger sein als die Preise der Plattform, aber du musst dich selbst um Wartung, Backups und Compliance kümmern.
Schau dir die folgende Tabelle an, um die gehostete und die Open-Source-Version von Mem0 zu vergleichen :
|
Aspekt |
Plattform |
Open Source |
|
Einrichtungszeit |
Protokoll |
Stunden bis Tage |
|
Infrastruktur |
Vollständig verwaltet |
Selbstverwaltet |
|
Preise |
0–249 $+/Monat |
Deine Infrastrukturkosten |
|
Vektor-DB-Optionen |
Verwaltet |
Über 24 Optionen |
|
LLM-Optionen |
Verwaltet |
Über 16 Optionen |
|
Konformitätsbescheinigungen |
SOC 2, DSGVO inklusive |
Du implementierst |
|
Wo sind die Daten? |
Mem0-Server |
Deine Server |
Ich empfehle,die Plattform für schnelles Prototyping, Produktions-Apps ohne DevOps-Aufwand oder wenn du integrierte Compliance brauchst, zu wählen.
Wenn du dich auf Datenhoheit, individuelle Modellkonfigurationen oder Kostenoptimierung bei großen Datenmengen konzentrierst, ist Open Source die richtige Wahl.
Detaillierte Anleitungen zur Einrichtung findest du im Schnellstart für die Plattform oder in der Open-Source-Übersicht.
In diesem Tutorial ging's darum, wie man mit Mem0 persistenten Speicher zu LLM-Anwendungen hinzufügt. Du hast mit einfachen Speicheroperationen angefangen und dann einen Lernbegleiter-Agenten gebaut, der seinen eigenen Speicher mit dem OpenAI Agents SDK selbstständig verwaltet. Von dort aus hast du das Speicherverhalten mit benutzerdefinierten Kategorien, Anweisungen und gefilterten Suchen eingerichtet. Schließlich hast du die Bereitstellungsoptionen für Plattformen und Open Source verglichen.
Für den produktiven Einsatz solltest du eine Fehlerbehandlung für Speicheroperationen einbauen und kurze Verzögerungen nach dem Speichern neuer Speicherstände berücksichtigen. Denk an die Ratenbeschränkungen, wenn du die kostenlose Version der Plattform nutzt.
Bist du bereit, über einzelne Komponenten hinauszugehen und die komplette Entwicklung von KI-Anwendungen zu meistern? Melde dich für den Kurs „” an, um zum KI-Ingenieur für Entwickler zu werden..
AI-Agent-Kurse
Lernpfad
Kurs
Kurs
Blog
Blog
Nathaniel Taylor-Leach
4 Min.
Tutorial
Stephen Gruppetta
Tutorial
Javier Canales Luna
Tutorial
Mark Pedigo

