Curso
Uniones en pandas para usuarios de hojas de cálculo
4 h
4.5K
Antes de leer un archivo CSV en un marco de datos de pandas, debes tener alguna idea de lo que contienen los datos. Por tanto, es recomendable que hojees el archivo antes de intentar cargarlo en la memoria: esto te dará una idea más clara de qué columnas son necesarias y cuáles pueden descartarse.
Ahora, escribamos un poco de código para importar un archivo utilizando read_csv(). A continuación, podemos hablar sobre lo que está sucediendo y cómo podemos personalizar el resultado que recibimos mientras leemos los datos en la memoria.
# Tip: For faster performance on large files in pandas 2.0+, use the pyarrow engine
# airbnb_data = pd.read_csv("data/listings_austin.csv", engine="pyarrow")
import pandas as pd
# Read the CSV file
airbnb_data = pd.read_csv("data/listings_austin.csv")
# View the first 5 rows
airbnb_data.head()
Todo lo que ha pasado en el código anterior es que tenemos:
read_csv() para leer los datos en la memoria como un marco de datos pandas.Pero la función « read_csv() » ofrece mucho más.
El comportamiento por defecto de pandas es añadir un índice inicial al marco de datos devuelto por el archivo CSV que ha cargado en memoria. Sin embargo, puedes especificar explícitamente qué columna se utilizará como índice para la función ` read_csv() ` estableciendo el parámetro ` index_col`.
Ten en cuenta que el valor que asignes a index_col puede ser un nombre de cadena, un índice de columna o una secuencia de nombres de cadenas o índices de columna. Asignar al parámetro una secuencia dará como resultado un multiíndice (una agrupación de datos por varios niveles).
Leamos los datos de nuevo y establezcamos la columna « id » como índice.
# Setting the id column as the index
airbnb_data = pd.read_csv("data/listings_austin.csv", index_col="id")
# airbnb_data = pd.read_csv("data/listings_austin.csv", index_col=0)
# Preview first 5 rows
airbnb_data.head()
¿Y si sólo quieres leer en memoria determinadas columnas porque no todas son importantes? Este es un escenario común que se da en el mundo real. Con la función « read_csv() », puedes seleccionar solo las columnas que necesitas después de cargar el archivo, pero esto significa que debes saber qué columnas necesitas antes de cargar los datos si deseas realizar esta operación desde la función « read_csv() ».
Si conoces las columnas que necesitas, estás de suerte; puedes ahorrar tiempo y memoria pasando un objeto similar a una lista al parámetro « usecols » de la función « read_csv() ».
# Defining the columns to read
usecols = ["id", "name", "host_id", "neighbourhood", "room_type", "price", "minimum_nights"]
# Read data with subset of columns
airbnb_data = pd.read_csv("data/listings_austin.csv", index_col="id", usecols=usecols)
# Preview first 5 rows
airbnb_data.head()
Apenas hemos arañado la superficie de las diferentes formas de personalizar el resultado de la función read_csv(), pero profundizar más en el tema supondría sin duda una sobrecarga de información. Para ello, puedes utilizar la siguiente tabla como referencia:
| Parámetro | Descripción | Ejemplo de uso |
|---|---|---|
| filepath_or_buffer | La ruta o URL del archivo CSV que se va a leer. | pd.read_csv("data/listings_austin.csv") |
| sep | Delimitador que se va a utilizar. El valor predeterminado es , . | pd.read_csv("data.csv", sep=';') |
| index_col | Columna(s) que se establecerá(n) como índice. Puede ser una etiqueta de columna o un número entero. | pd.read_csv("data.csv", index_col="id") |
| usecols | Devuelve un subconjunto de las columnas. Toma una lista de nombres de columnas o índices. | pd.read_csv("data.csv", usecols=["id", "name", "price"]) |
| nombres | Lista de nombres de columnas que se van a utilizar. Si el archivo no contiene una fila de encabezado. | pd.read_csv("data.csv", names=["A", "B", "C"]) |
| encabezado | Número(s) de fila(s) que se utilizarán como nombres de columna. El valor predeterminado es 0 (primera línea). | pd.read_csv("data.csv", header=1) |
| tipo de datos | Tipo de datos para datos o columnas. | pd.read_csv("data.csv", dtype={"id": int, "price": float}) |
| na_values | Cadenas adicionales que se deben reconocer como NA/NaN. | pd.read_csv("data.csv", na_values=["NA", "N/A"]) |
| parse_dates | Intenta analizar las fechas. Puede ser booleano o una lista de nombres de columnas. | pd.read_csv("data.csv", parse_dates=["date"]) |
Cuando se trabaja con conjuntos de datos grandes, puede que no sea viable cargar todo el archivo en la memoria de una sola vez, especialmente en entornos con limitaciones de memoria. La función read_csv() ofrece un práctico parámetro chunksize, que te permite leer los datos en fragmentos más pequeños y manejables.
Al establecer el parámetro « chunksize », « read_csv() » devuelve un objeto iterable en el que cada iteración proporciona un fragmento de datos como un DataFrame de pandas. Este enfoque resulta especialmente útil cuando se procesan datos por lotes o cuando el tamaño del conjunto de datos supera la memoria disponible.
A continuación te explicamos cómo puedes utilizar el parámetro « chunksize »:
import pandas as pd
import os # Import the standard OS library
file_path = "data/large_dataset.csv"
output_file = "data/processed_large_dataset.csv"
chunk_size = 10000
# Process and write chunks
for chunk in pd.read_csv(file_path, chunksize=chunk_size):
# Example: Filter rows based on a condition
filtered_chunk = chunk[chunk['column_name'] > 50]
# Check if header is needed (only if file doesn't exist yet)
write_header = not os.path.exists(output_file)
# Append to a new CSV file
filtered_chunk.to_csv(output_file, mode='a', header=write_header, index=False)Si tu objetivo es realizar una operación en todo el conjunto de datos, como calcular la suma total de una columna, puedes agregar los resultados a medida que iterás a través de los fragmentos:
total_sum = 0
for chunk in pd.read_csv(file_path, chunksize=chunk_size):
# Add the sum of the specific column for each chunk
total_sum += chunk['column_name'].sum()
print(f"Total sum of the column: {total_sum}")También puedes utilizar chunksize para procesar y guardar fragmentos de datos en un nuevo archivo de forma incremental:
# Output file path
output_file = "data/processed_large_dataset.csv"
# Process and write chunks
for chunk in pd.read_csv(file_path, chunksize=chunk_size):
# Example: Filter rows based on a condition
filtered_chunk = chunk[chunk['column_name'] > 50]
# Append to a new CSV file
filtered_chunk.to_csv(output_file, mode='a', header=not pd.io.common.file_exists(output_file), index=False)Veremos más sobre el método ` to_csv() ` en las próximas secciones.
El parámetro chunksize es indispensable cuando:
Una vez que sepas cómo leer un archivo CSV del almacenamiento local a la memoria, leer datos de otras fuentes es pan comido. En definitiva, es el mismo proceso, salvo que ya no pasas una ruta de archivo.
Supongamos que hay datos que quieres de una página web concreta; ¿cómo los leerías en memoria?
Utilizaremos como ejemplo el conjunto de datos Iris del repositorio de la UCI:
# Webpage URL
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
# Define the column names
col_names = ["sepal_length_in_cm",
"sepal_width_in_cm",
"petal_length_in_cm",
"petal_width_in_cm",
"class"]
# Read data from URL
iris_data = pd.read_csv(url, names=col_names)
iris_data.head() 
¡Voilà!
Asignamos una lista de cadenas al parámetro names. Dado que los datos sin procesar de Iris no tienen una fila de encabezado, este argumento le indica a pandas que utilice nuestra lista como nombres de columna. (Nota: Si el archivo tuviera una fila de encabezado, también tendrías que utilizar header=0 para indicar a pandas que la sustituya).
El objeto más común de la biblioteca pandas es, con diferencia, el objeto dataframe. Es una estructura de datos bidimensional etiquetada, formada por filas y columnas que pueden ser de distintos tipos de datos (es decir, flotantes, numéricos, categóricos, etc.).
Conceptualmente, puedes pensar en un marco de datos de pandas como en una hoja de cálculo, una tabla SQL o un diccionario de objetos de series, lo que te resulte más familiar. Lo bueno del marco de datos pandas es que viene con muchos métodos que te facilitan familiarizarte con tus datos lo más rápidamente posible.
Ya has visto uno de esos métodos: iris_data.head(), que muestra las primeras n filas (el valor predeterminado es 5). El método «opuesto» a head() es tail(), que muestra las últimas n (5 por defecto) filas del objeto DataFrame. Por ejemplo:
iris_data.tail()
Puedes descubrir rápidamente los nombres de las columnas utilizando el atributo « columns » en tu objeto dataframe:
# Discover the column names
iris_data.columns
"""
Index(['sepal_length_in_cm', 'sepal_width_in_cm', 'petal_length_in_cm',
'petal_width_in_cm', 'class'],
dtype='object')
"""Otro método importante que puedes utilizar en tu objeto DataFrame es info(). Este método imprime un resumen conciso del marco de datos, incluyendo información sobre el índice, los tipos de datos, las columnas, los valores no nulos y el uso de memoria.
# Get summary information of the dataframe
iris_data.info()
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sepal_length_in_cm 150 non-null float64
1 sepal_width_in_cm 150 non-null float64
2 petal_length_in_cm 150 non-null float64
3 petal_width_in_cm 150 non-null float64
4 class 150 non-null object
dtypes: float64(4), object(1)
memory usage: 6.0+ KB
"""DataFrame.describe() Genera estadísticas descriptivas, incluidas aquellas que resumen la tendencia central, la dispersión y la forma de la distribución del conjunto de datos. Si tus datos tienen valores perdidos, no te preocupes; no se incluyen en las estadísticas descriptivas.
Llamemos al método describir sobre el conjunto de datos Iris:
# Get descriptive statistics
iris_data.describe()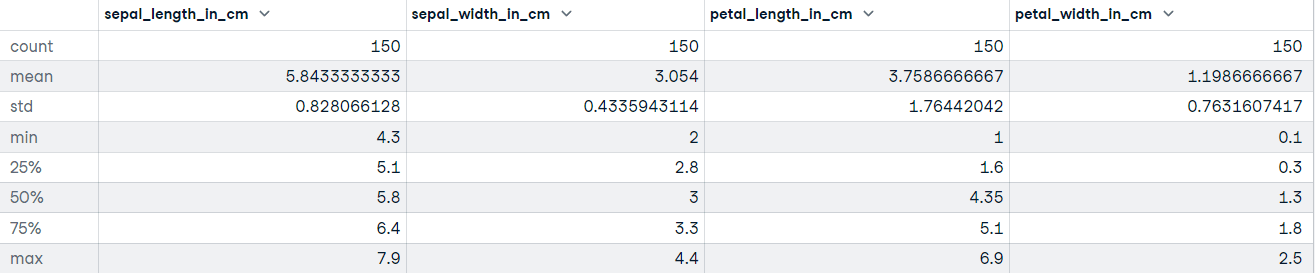
Otro método disponible para los objetos de DataFrame de pandas es to_csv(). Cuando hayas limpiado y preprocesado tus datos, el siguiente paso puede ser exportar el marco de datos a un archivo; esto es bastante sencillo:
# Export the file to the current working directory
iris_data.to_csv("cleaned_iris_data.csv")Al ejecutar este código, se creará un archivo CSV en el directorio de trabajo actual llamado cleaned_iris_data.csv.
Pero, ¿qué ocurre si deseas utilizar un delimitador diferente para marcar el inicio y el final de una unidad de datos, o si deseas especificar cómo deben representarse los valores que faltan? Quizá no quieras que las cabeceras se exporten al archivo.
Bueno, puedes ajustar los parámetros del método to_csv() para que se adapten a tus necesidades en cuanto a los datos que deseas exportar.
Veamos algunos ejemplos de cómo puedes ajustar la salida de to_csv():
# Change the delimiter to a tab
iris_data.to_csv("tab_seperated_iris_data.csv", sep="\t")# Export data without the index
iris_data.to_csv("tab_seperated_iris_data.csv", sep="\t", index=False
# If you get UnicodeEncodeError use this...
# iris_data.to_csv("tab_seperated_iris_data.csv", sep="\t", index=False, encoding='utf-8')““ »):# Replace missing values with "Unknown"
iris_data.to_csv("tab_seperated_iris_data.csv", sep="\t", na_rep="Unknown")# Do not include headers when exporting the data
iris_data.to_csv("tab_seperated_iris_data.csv", sep="\t", na_rep="Unknown", header=False)En ocasiones, es posible que se produzcan errores de codificación, especialmente si trabajas en sistemas que no utilizan UTF-8 como codificación predeterminada o si tus datos contienen caracteres no ASCII. Para resolver estos problemas, puedes especificar una codificación adecuada utilizando el parámetro encoding.
# Export data with a specified encoding
iris_data.to_csv("cleaned_iris_data.csv", encoding="utf-8")
Si tu sistema utiliza una codificación diferente, como Windows-1252 (común en los sistemas Windows), puedes especificarla explícitamente:
# Export data using a different encoding
iris_data.to_csv("cleaned_iris_data.csv", encoding="cp1252")
Ejemplo con parámetros adicionales:
# Handle missing values and encoding issues
iris_data.to_csv("cleaned_iris_data.csv", na_rep="Unknown", encoding="utf-8", index=False)El ejemplo anterior garantiza que tu archivo CSV exportado sea compatible con diversos sistemas y aplicaciones.
| Parámetro | Descripción | Ejemplo de uso |
|---|---|---|
| path_or_buf | Ruta del archivo u objeto; si no se proporciona nada, el resultado se devuelve como una cadena. | df.to_csv("output.csv") |
| sep | Cadena de longitud 1. Delimitador de campo para el archivo de salida. El valor predeterminado es «,». | df.to_csv("output.csv", sep=';') |
| na_rep | Representación de datos faltantes. | df.to_csv("output.csv", na_rep='Unknown') |
| float_format | Cadena de formato para números de coma flotante. | df.to_csv("output.csv", float_format='%.2f') |
| columnas | Columnas para escribir. De forma predeterminada, escribe todas las columnas. | df.to_csv("output.csv", columns=["id", "name"]) |
| encabezado | Escribe los nombres de las columnas. Si se proporciona una lista de cadenas, se supone que son alias para los nombres de las columnas. | df.to_csv("output.csv", header=False) |
| índice | Escribe los nombres de las filas (índice). El valor predeterminado es True. | df.to_csv("output.csv", index=False) |
| modo | Modo de escritura Python. El valor predeterminado es «w». | df.to_csv("output.csv", mode='a') |
| codificación | Una cadena que representa la codificación que se utilizará en el archivo de salida. | df.to_csv("output.csv", encoding='utf-8') |
Aunque pandas es una biblioteca potente y versátil para trabajar con archivos CSV, no es la única opción disponible en Python. Dependiendo de tu caso de uso, otras bibliotecas pueden ser más adecuadas para tareas específicas:
El módulo csv forma parte de la biblioteca estándar de Python y es una alternativa ligera para manejar archivos CSV. Proporciona funciones básicas para leer y escribir archivos CSV sin necesidad de instalaciones adicionales. Las ventajas de csv son:
Ejemplo:
import csv
# Reading a CSV file
with open("data/sample.csv", mode="r") as file:
reader = csv.reader(file)
for row in reader:
print(row)
# Writing to a CSV file
with open("data/output.csv", mode="w", newline="") as file:
writer = csv.writer(file)
writer.writerow(["Column1", "Column2"])
writer.writerow(["Value1", "Value2"])NumPy es una biblioteca para cálculos numéricos en Python que también admite el manejo de archivos CSV. Es especialmente útil cuando se trabaja con datos numéricos o cuando el rendimiento es un factor importante. Las ventajas son:
Ejemplo:
import numpy as np
# Reading a CSV file into a NumPy array
data = np.loadtxt("data/sample.csv", delimiter=",", skiprows=1)
# Writing a NumPy array to a CSV file
np.savetxt("data/output.csv", data, delimiter=",")Aunque NumPy es eficiente, no ofrece las completas funciones de manipulación de datos y exploración que están disponibles en pandas.
Si trabajas con conjuntos de datos muy grandes en los que pandas se ralentiza o se queda sin memoria, Polars es el sucesor moderno que debes conocer. Es una biblioteca DataFrame escrita en Rust que está diseñada para ofrecer un rendimiento ultrarrápido y un procesamiento paralelo.
Como exploramos en nuestro tutorial sobre Polars, las ventajas de Polars son:
Ejemplo: La sintaxis suele ser muy similar a la de pandas, lo que facilita su aprendizaje:
import polars as pl
# Read a CSV file (automatically uses multiple threads)
df = pl.read_csv("data/large_dataset.csv")
# View the first 5 rows
print(df.head())
# Write to a CSV file
df.write_csv("data/polars_output.csv")Recapitulemos lo que hemos tratado en este tutorial; has aprendido a:
read_csv() ` de la biblioteca pandas.read_csv().pandas.read_csv()to_csv().En este tutorial, nos hemos centrado únicamente en la importación y exportación de datos desde la perspectiva de un archivo CSV; ahora ya tienes una buena idea de lo útil que es pandas a la hora de importar y exportar archivos CSV. CSV es uno de los formatos de almacenamiento de datos más comunes, pero no es el único. Existen otros formatos de archivo utilizados en la ciencia de datos, como parquet, JSON y excel.
En la web se alojan muchos conjuntos de datos útiles y de alta calidad, a los que puedes acceder mediante API, por ejemplo. Si quieres entender cómo manejar la carga de datos en Python con más detalle, el curso Introducción a la importación de datos en Python de DataCamp te enseñará todas las mejores prácticas.
También hay tutoriales sobre cómo importar datos JSON y HTML en pandas y una guía definitiva para principiantes sobre pandas. No dejes de consultarlos para profundizar en el framework de pandas.
Nuestros programas de certificación te ayudan a destacar y a demostrar que tus aptitudes están preparadas para el trabajo a posibles empleadores.

Más información sobre Python y pandas
Curso
Curso
Curso
Tutorial
Karlijn Willems
Tutorial
DataCamp Team
Tutorial
Vidhi Chugh
Tutorial
Natassha Selvaraj
Tutorial
Abid Ali Awan
Tutorial
DataCamp Team
