programa
Ingeniero de datos en Python
40 h
Una buena práctica a la hora de configurar un nuevo proyecto Python es hacerlo en un entorno virtual. Te mostraré cómo hacerlo con conda y venv.
Utilizo Anaconda para gestionar entornos y dependencias. Si también lo haces, ejecuta el siguiente fragmento para crear un nuevo entorno virtual llamado dlt_env basado en Python 3.12:
conda create --name dlt_env python=3.12 -y
conda activate dlt_envDeberías ver una salida similar a ésta en tu terminal:
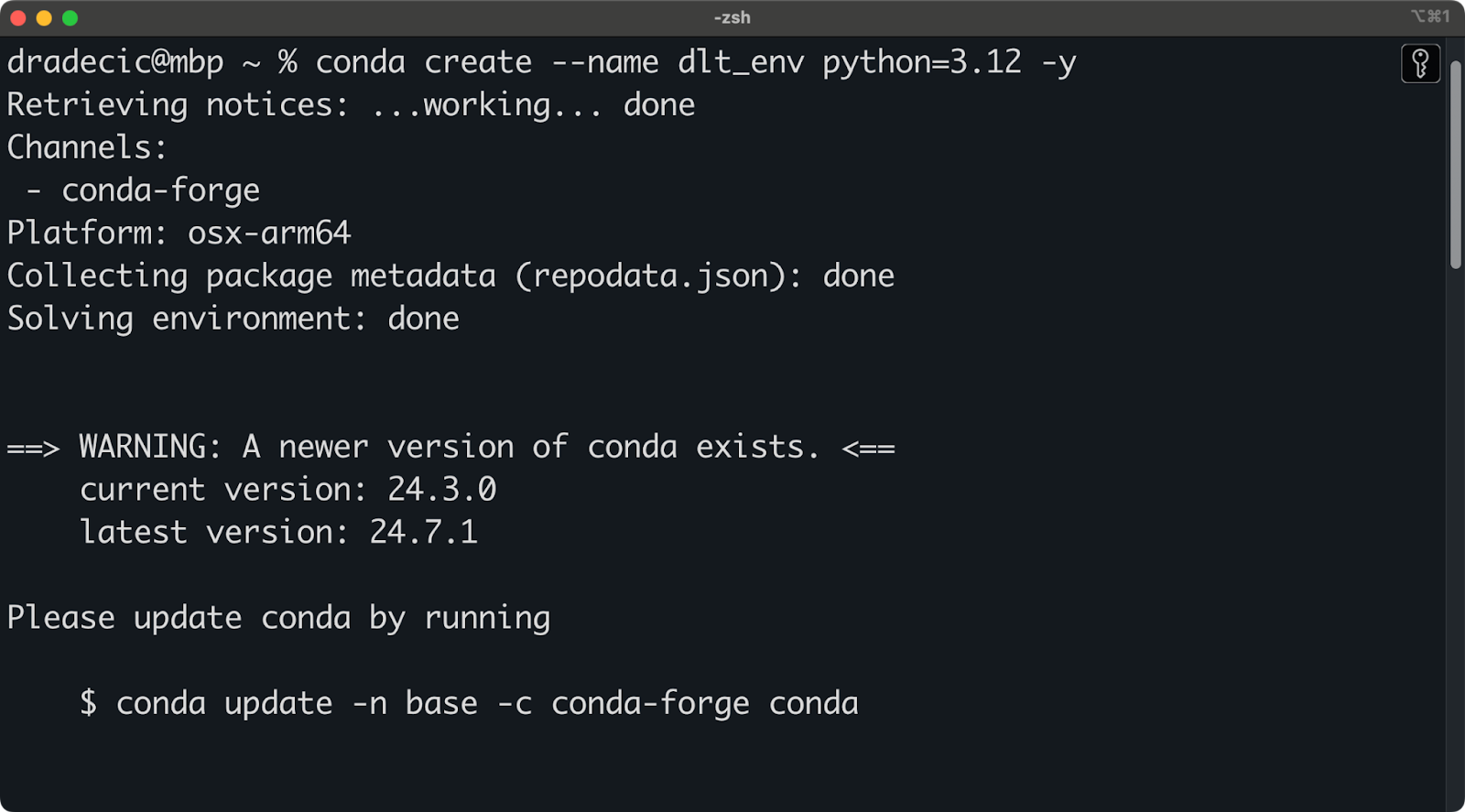
Configuración del entorno Conda
Por otro lado, si no utilizas Anaconda, ejecuta el siguiente comando para crear y activar un nuevo entorno Python:
python -m venv ./env
source ./env/bin/activateYa estás preparado para instalar dlt.
Antes de proceder, debes tener un entorno virtual creado y activado
Para instalar dlt, ejecuta lo siguiente dentro del entorno:
pip install dlt
dlt version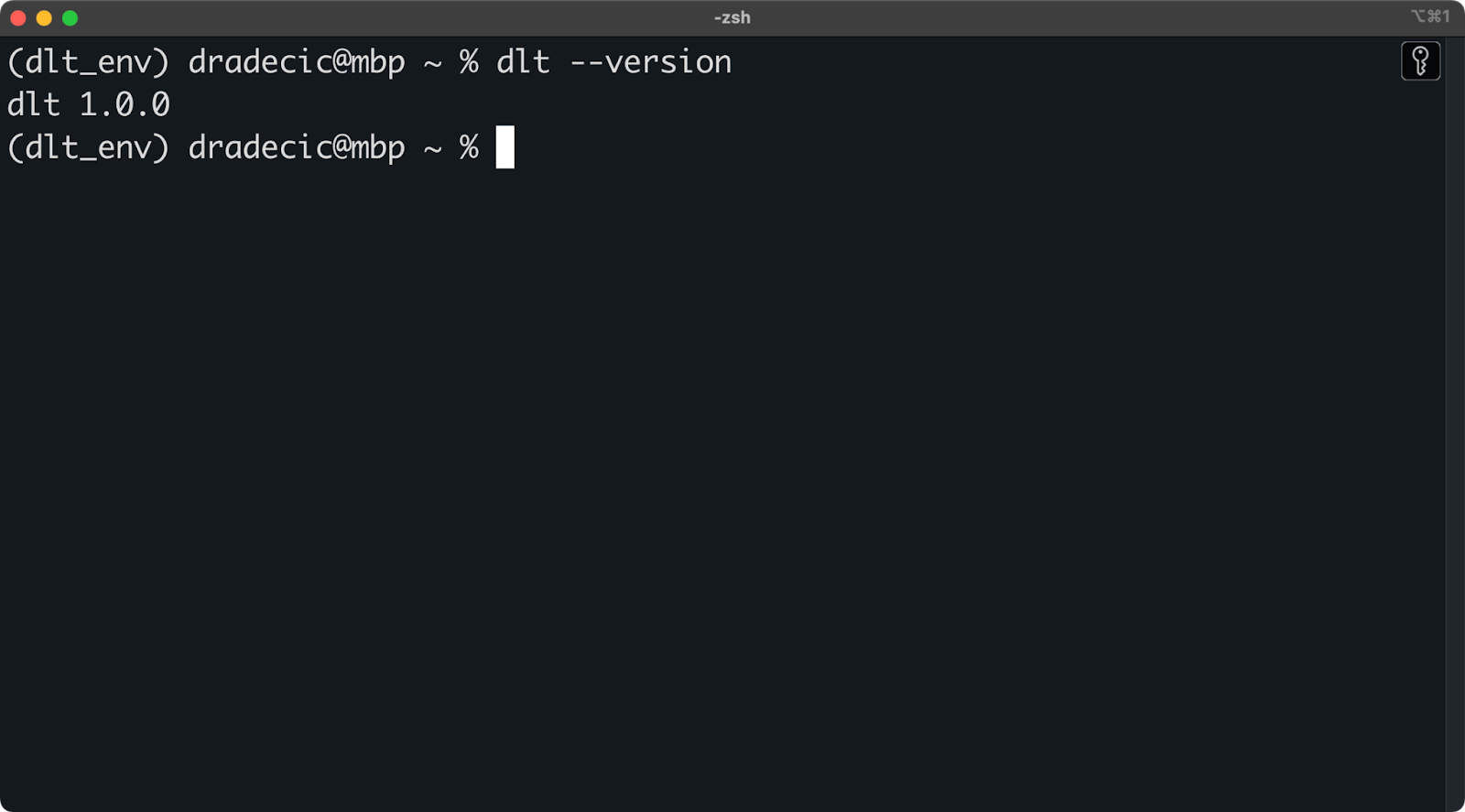
Versión dlt instalada
Mientras no aparezca un mensaje de error o un mensaje que te indique que no se reconoce dlt, ¡ya puedes continuar!
Ahora puedes utilizar la interfaz de línea de comandos dlt para crear nuevos proyectos a partir de una plantilla.
Esto se hace mediante el comando dlt init . En el siguiente fragmento, te muestro cómo crear una canalización que utilice una API REST como fuente de datos y DuckDB como destino (target):
dlt init rest_api_test duckdb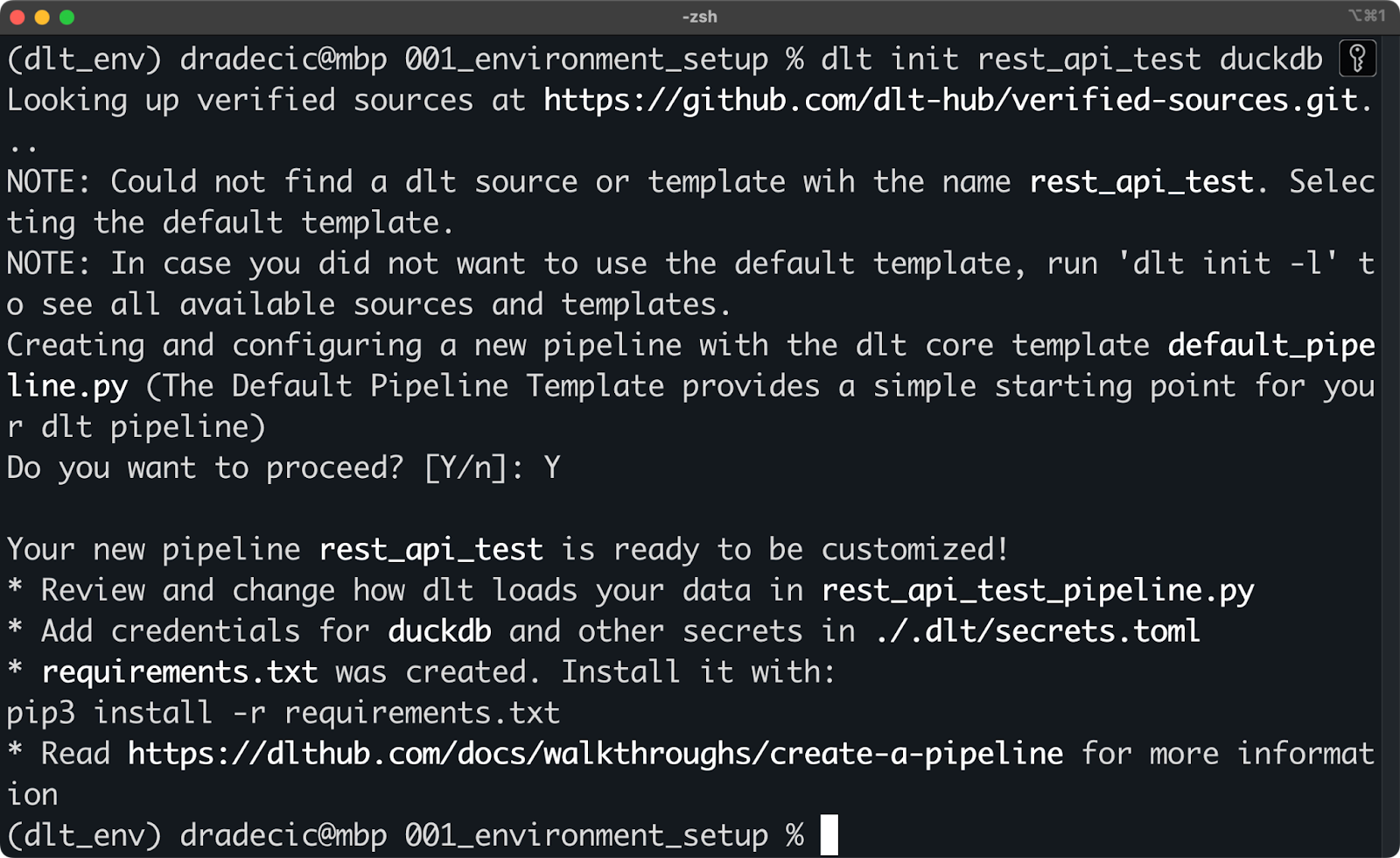
Inicializar un nuevo proyecto dlt con DuckDB
Nadie te impide crear los archivos manualmente, sólo asegúrate de que tu estructura de carpetas se parece a la que crea dlt CLI. Por ejemplo, esto es lo que el comando shell anterior creó en mi sistema:
.
├── requirements.txt
├── rest_api_test_pipeline.py
├── .dlt
│ ├── config.toml
│ ├── secrets.tomlLa magia ocurre en la carpeta .dlt. Contiene dos archivos que cubren todo lo relativo a laconfiguración del canal y las fuentes y destinos de los datos, como las claves de la API y las credenciales de la base de datos.
El rest_api_test_pipeline.py es un archivo Python generado automáticamente que te muestra un par de formas de conectar una API REST con DuckDB.
Para empezar, deberás instalar todo lo que se indica en requirements.txt. Hazlo ejecutando el siguiente comando:
pip install -r requirements.txtUna vez instalado, ¡estás listo para ejecutar tu primer canal dlt!
Aquí tienes el contenido del archivo rest_api_test_pipeline.py:
"""The Default Pipeline Template provides a simple starting point for your dlt pipeline"""
# mypy: disable-error-code="no-untyped-def,arg-type"
import dlt
from dlt.common import Decimal
@dlt.resource(name="customers", primary_key="id")
def rest_api_test_customers():
"""Load customer data from a simple python list."""
yield [
{"id": 1, "name": "simon", "city": "berlin"},
{"id": 2, "name": "violet", "city": "london"},
{"id": 3, "name": "tammo", "city": "new york"},
]
@dlt.resource(name="inventory", primary_key="id")
def rest_api_test_inventory():
"""Load inventory data from a simple python list."""
yield [
{"id": 1, "name": "apple", "price": Decimal("1.50")},
{"id": 2, "name": "banana", "price": Decimal("1.70")},
{"id": 3, "name": "pear", "price": Decimal("2.50")},
]
@dlt.source(name="my_fruitshop")
def rest_api_test_source():
"""A source function groups all resources into one schema."""
return rest_api_test_customers(), rest_api_test_inventory()
def load_stuff() -> None:
# specify the pipeline name, destination and dataset name when configuring pipeline,
# otherwise the defaults will be used that are derived from the current script name
p = dlt.pipeline(
pipeline_name='rest_api_test',
destination='duckdb',
dataset_name='rest_api_test_data',
)
load_info = p.run(rest_api_test_source())
# pretty print the information on data that was loaded
print(load_info) # noqa: T201
if __name__ == "__main__":
load_stuff()Déjame que te explique primero los decoradores, ya que seguramente no los has visto antes:
@dlt.resource: Sirve para crear un recurso genérico, por ejemplo, una tabla de base de datos con un nombre y un nombre de columna de clave primaria. Querrás yield un conjunto de datos (por ejemplo, una lista Python, un DataFrame pandas) en lugar de devolverlo.@dlt.source: Se utiliza para agrupar varios recursos, por ejemplo, varias tablas en un único esquema de base de datos. La función debe devolver llamadas a tus recursos.Las funciones Python de este archivo son bastante sencillas, pero déjame que te explique la lógica:
rest_api_test_customers(): Genera datos aleatorios sobre el nombre y la ciudad del cliente.rest_api_test_inventory(): Genera datos aleatorios sobre el nombre y el precio del producto.rest_api_test_source(): Agrupa los dos recursos anteriores en un solo esquema.load_stuff(): Crea y ejecuta una canalización que mueve datos ficticios de Python a una base de datos DuckDB.Ten en cuenta que los datos no se obtienen realmente de una API REST, sino que su estructura se parece exactamente al JSON que devolvería cualquier API REST. Más adelante en el artículo, te mostraré cómo trabajar con APIs reales.
De momento, ejecuta la tubería con el siguiente comando shell:
python rest_api_test_pipeline.py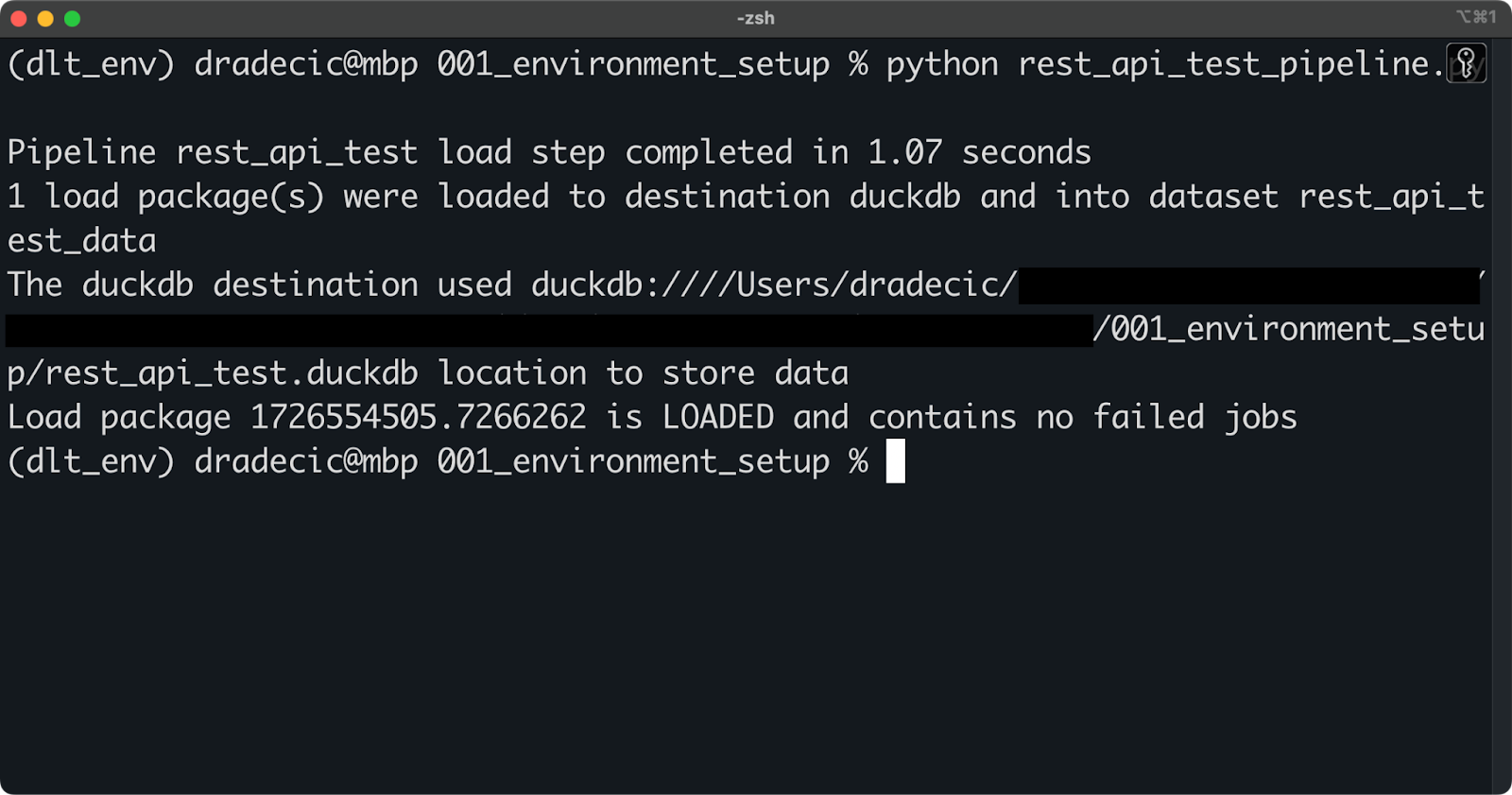
Ejecutar el oleoducto
Si ves un mensaje similar al anterior, la ejecución de la canalización se ha realizado correctamente.
Puedes conectarte al archivo local DuckDB a través de cualquier herramienta de base de datos (yo utilizo TablePlus). Una vez allí, tus datos estarán dentro de un esquema especificado bajo el parámetro dataset_name en dlt.pipeline().
La tabla customers muestra datos generados con Python, con la adición de dos columnas de linaje de datos:
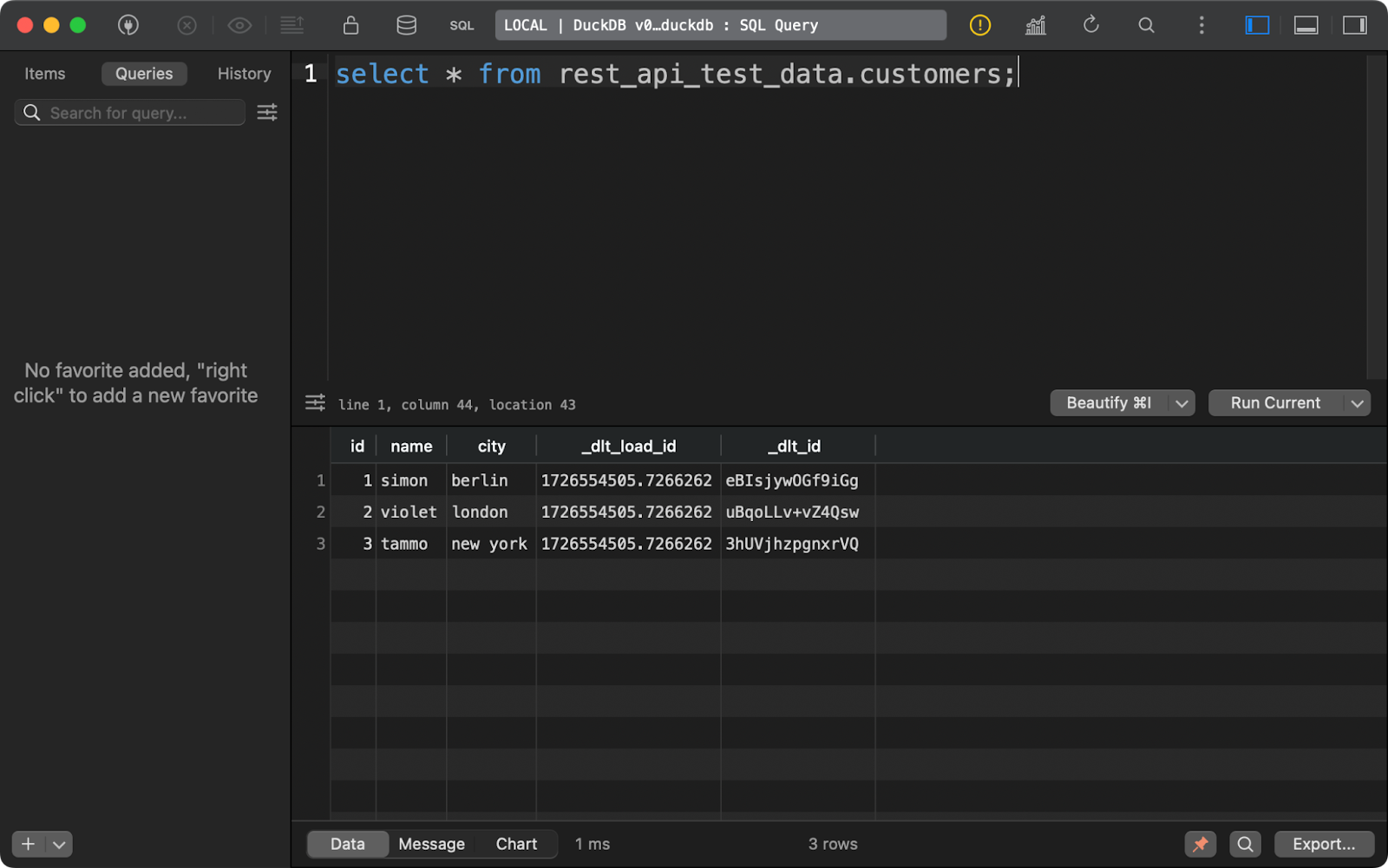
Contenido de la tabla de clientes
Lo mismo ocurre con la tabla inventory. Ten en cuenta que la columna price contiene NULLs. Es probable que haya un problema con el tipo de datos Decimal que dlt utilizó por defecto en este ejemplo:
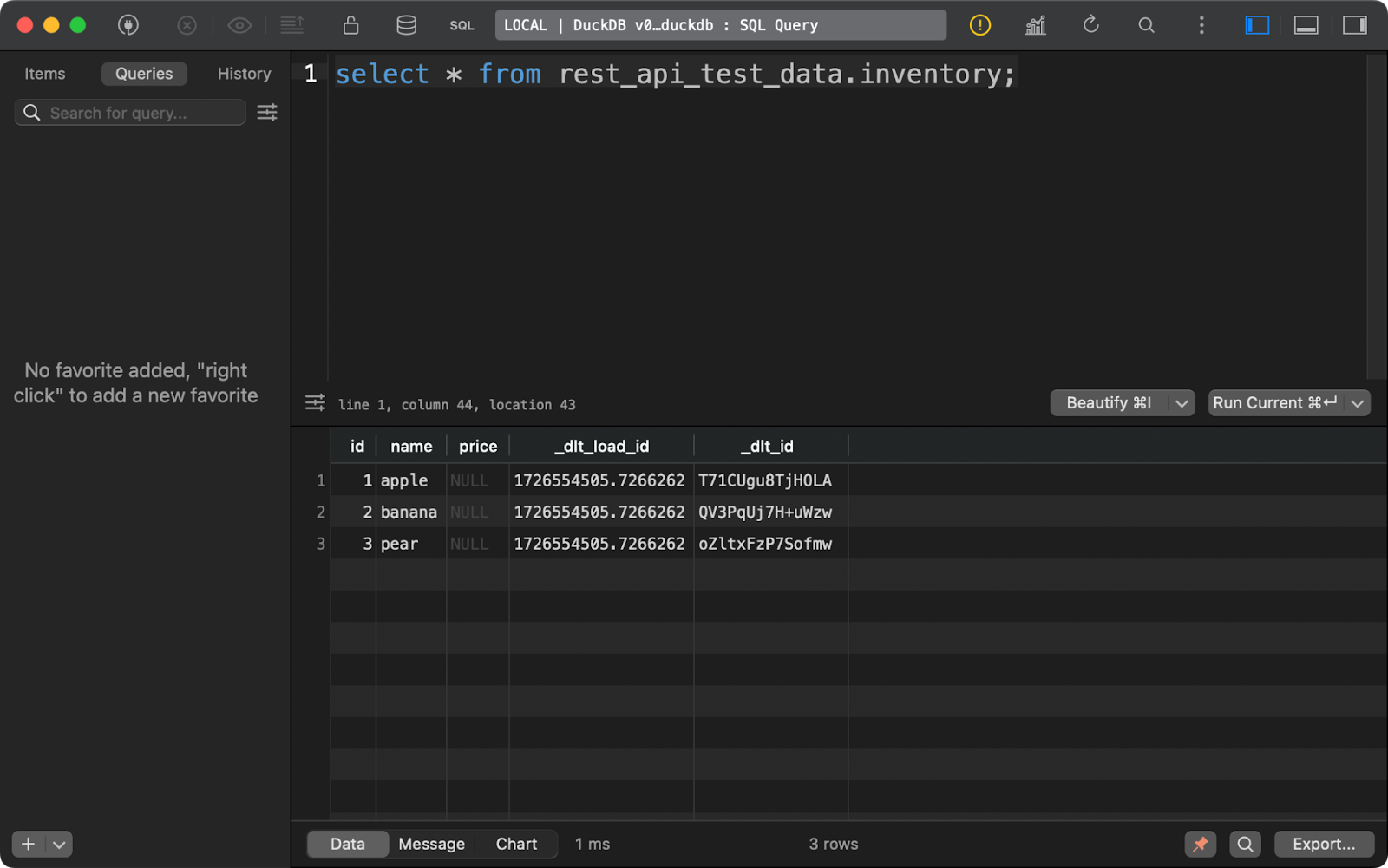
Contenido de la tabla de inventario
Cada vez que ejecutes una canalización, dlt creará (o añadirá) tres tablas de metadatos.
El primero, _dlt_loads, rastrea el historial de cargas de datos realizadas por la tubería. Muestra el nombre del esquema, el estado de la carga y la hora de la carga, entre otras cosas:
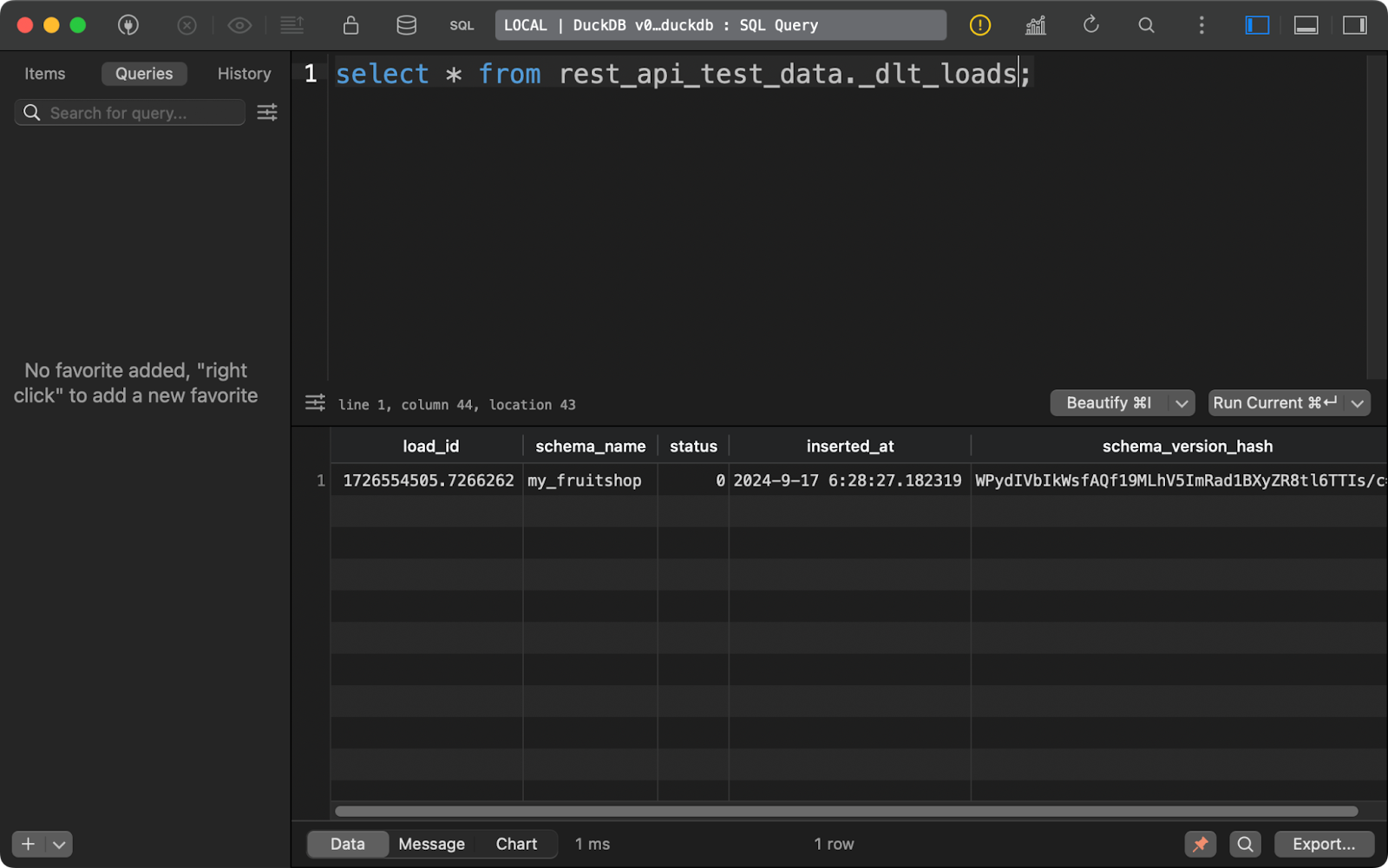
Historial de cargas de datos
La tabla _dlt_pipeline_state muestra detalles sobre la configuración, los puntos de control y el progreso de la canalización. También es útil para los casos en que tu oleoducto se detiene por cualquier motivo, ya que los datos de esta tabla pueden reanudarlo desde donde lo dejó:
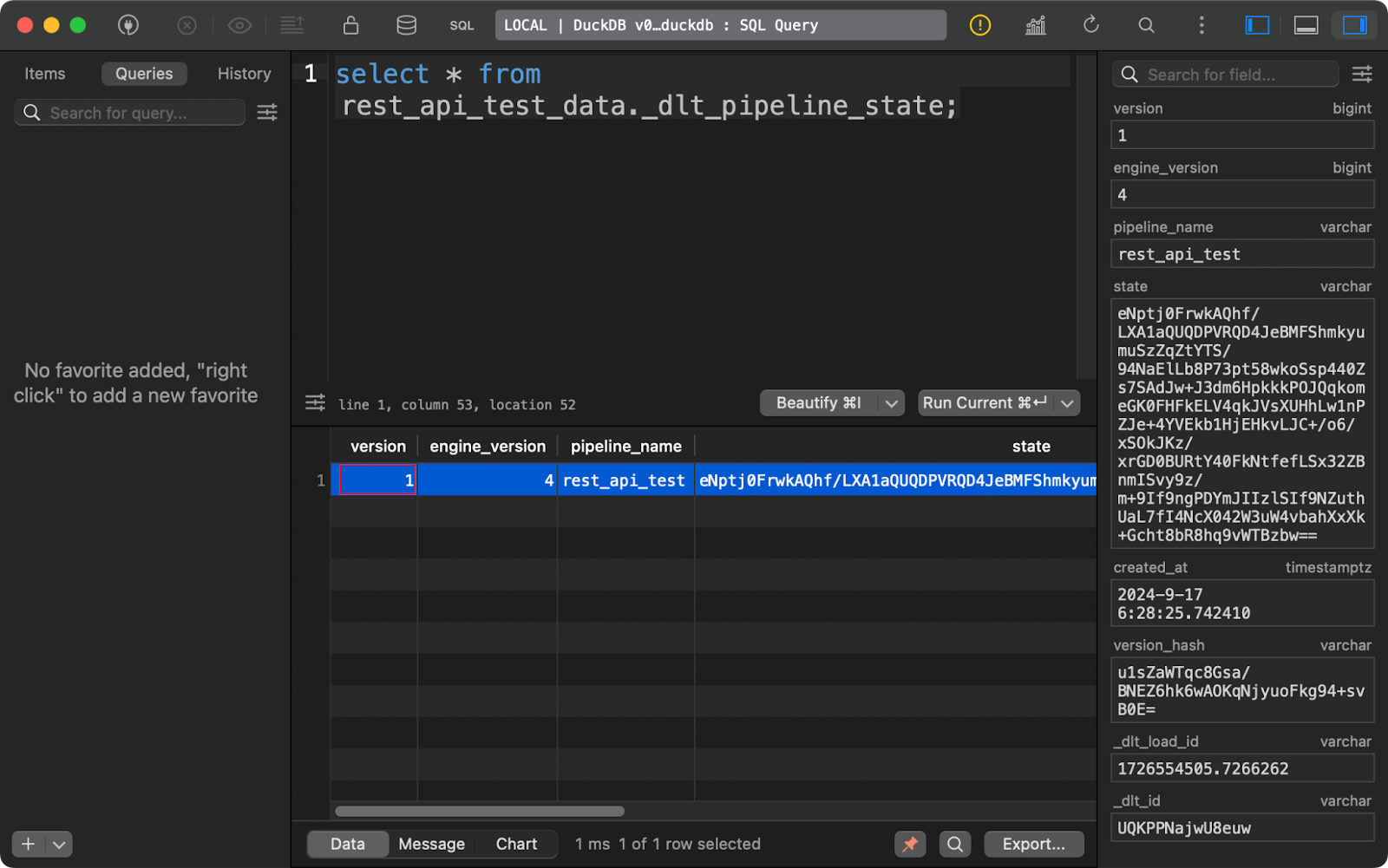
Tabla de estado de la tubería
Por último, la tabla _dlt_version almacena información sobre la propia biblioteca para garantizar la compatibilidad:
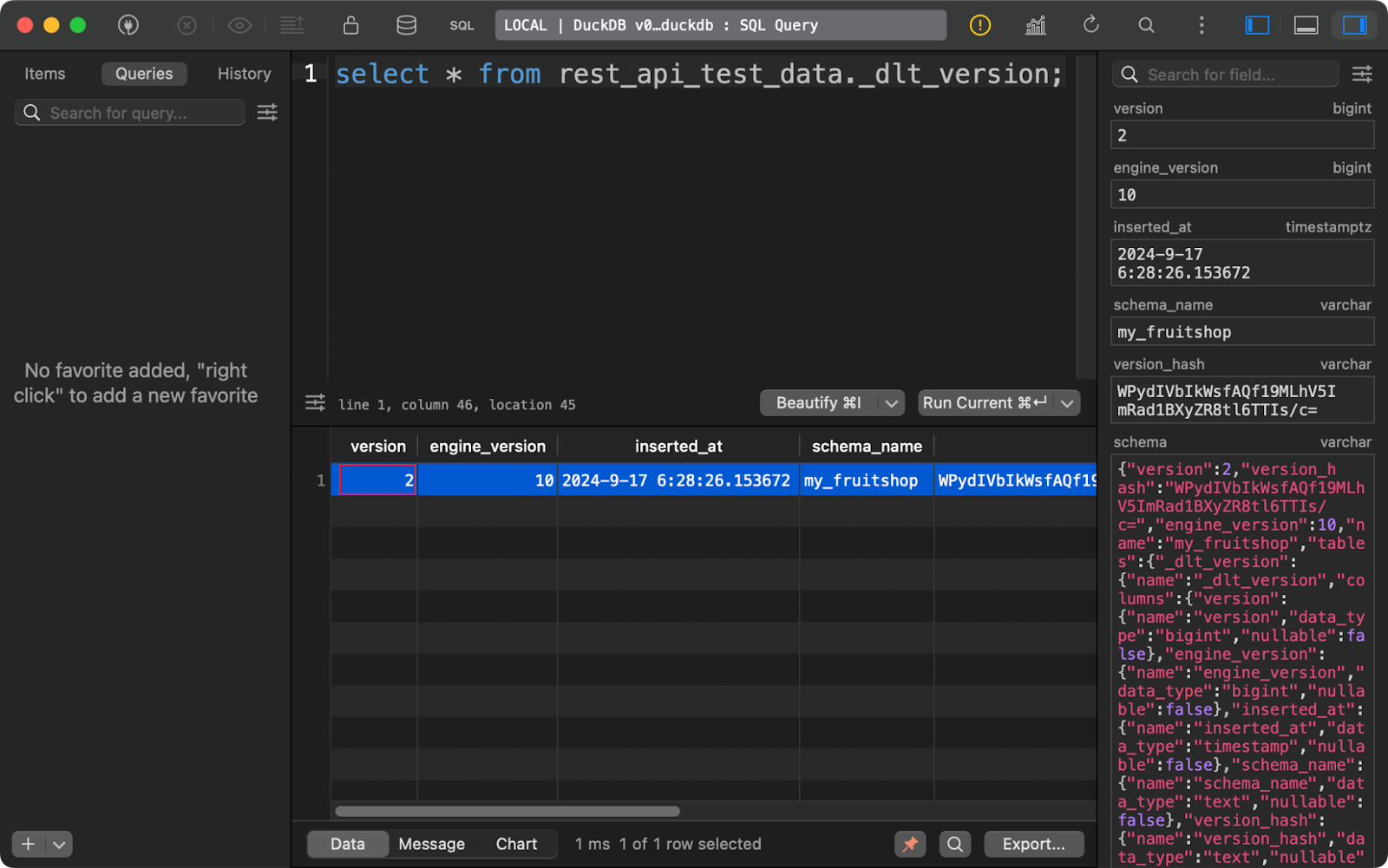
tabla de versiones dlt
Combinadas, estas tres tablas de metadatos proporcionan todos los detalles que quieres seguir a lo largo del tiempo para gestionar eficazmente tus canalizaciones de datos.
Ahora tienes una visión general de alto nivel de cómo funciona dlt. A continuación, te mostraré cómo extraer datos de distintas fuentes.
En esta sección trataré cuatro tipos de fuentes de datos: API REST, bases de datos, almacenamiento en la nube y sistema de archivos local.
Las API REST son el núcleo cuando se trata de fuentes para canalizaciones de datos. La biblioteca dlt permite trabajar con ellos sin esfuerzo.
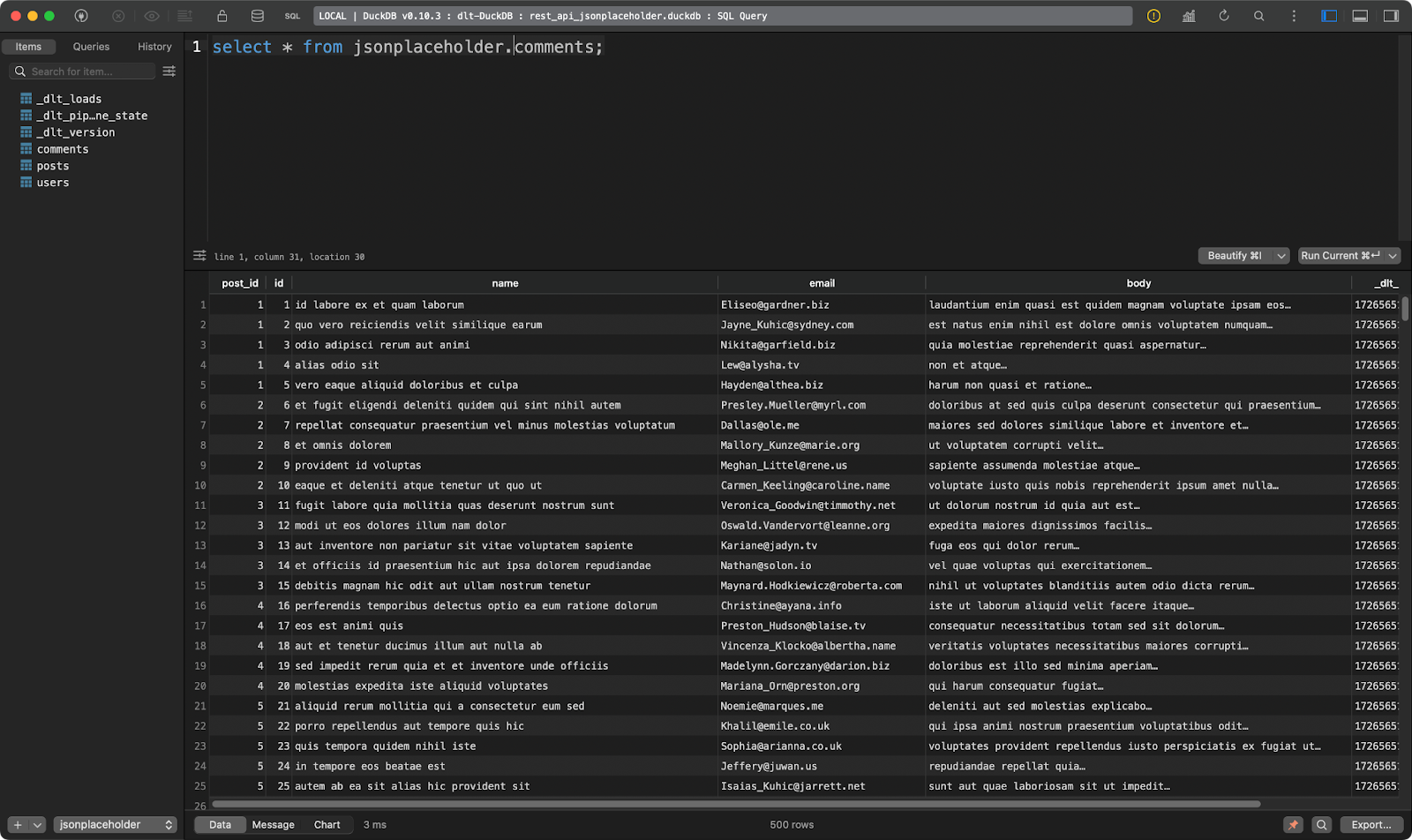
Para la demostración, utilizaré la API JSONPlaceholder que tiene puntos finales para obtener entradas, comentarios y usuarios, entre otras cosas. En cuanto al destino de los datos, optaré por DuckDB, ya que no requiere ninguna configuración.
Para conectarte a una API REST, utiliza la función rest_api_source(). Puedes pasar un diccionario que proporcione la URL de la API base y las reglas de paginación. Puedes añadir otras propiedades, por ejemplo, para laautenticación , pero mi API preferida es de acceso público, así que no es necesario.
Lo interesante viene de la propiedad resources. Aquí, proporcionarás una lista de puntos finales desde los que dlt debe obtener los datos. Por ejemplo, el recurso posts se conectará a https://jsonplaceholder.typicode.com/posts. Puedes ajustar los recursos individuales con mucha más profundidad, pero eso te lo dejo a ti.
El resto de este archivo Python permanece más o menos sin cambios:
import dlt
from dlt.sources.rest_api import rest_api_source
def load_rest_api_data() -> None:
data_source = rest_api_source({
"client": {
"base_url": "https://jsonplaceholder.typicode.com/",
"paginator": {
"type": "json_response",
"next_url_path": "paging.next"
}
},
"resources": [
"posts",
"comments",
"users"
]
})
pipeline = dlt.pipeline(
pipeline_name="rest_api_jsonplaceholder",
destination="duckdb",
dataset_name="jsonplaceholder"
)
load_info = pipeline.run(data_source)
print(load_info)
if __name__ == "__main__":
load_rest_api_data()Tras ejecutar la canalización, verás tres tablas de datos, una por cada recurso especificado.
El primero muestra puestos ficticios:
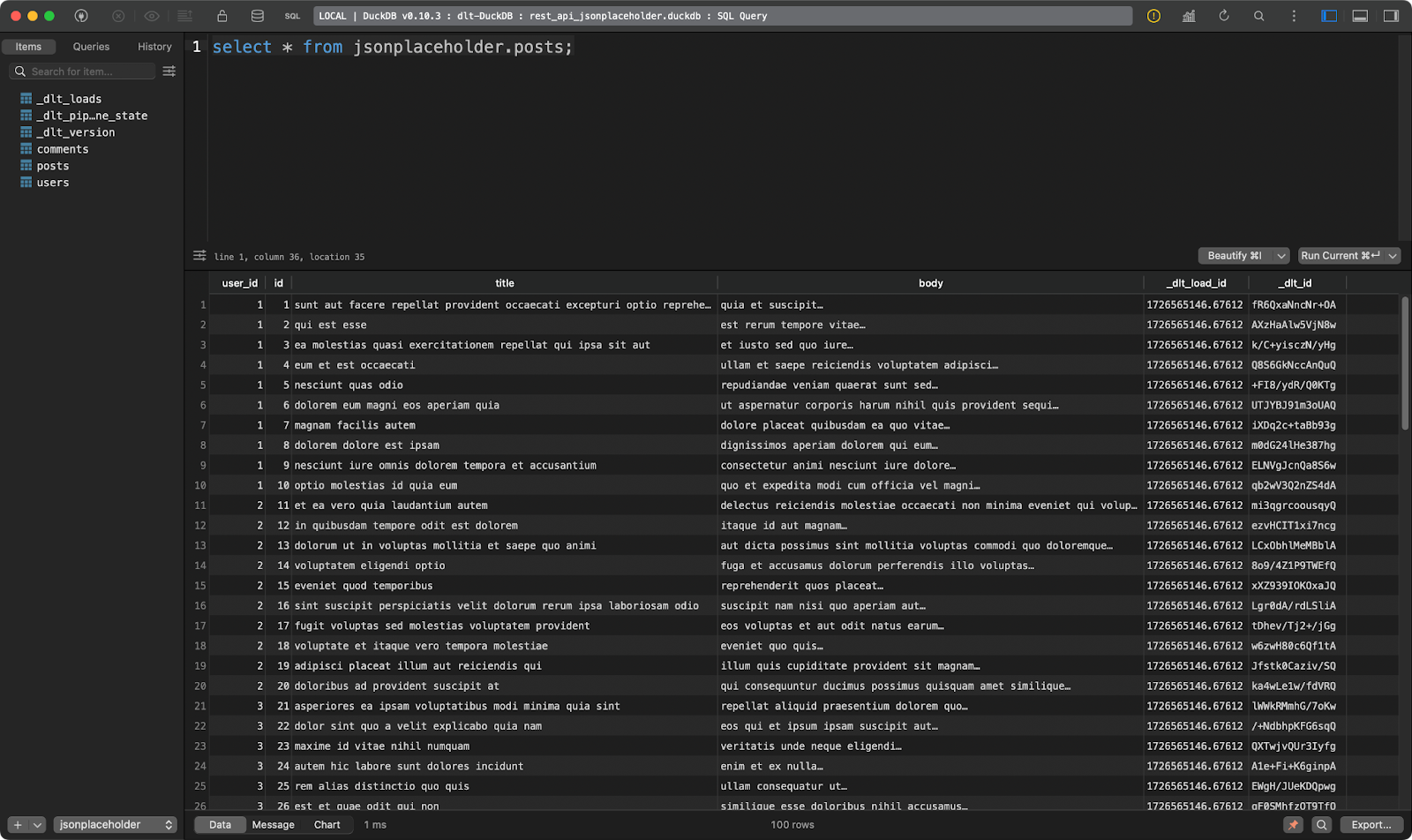
Tabla de puestos
El segundo muestra los comentarios del post:
Tabla de comentarios
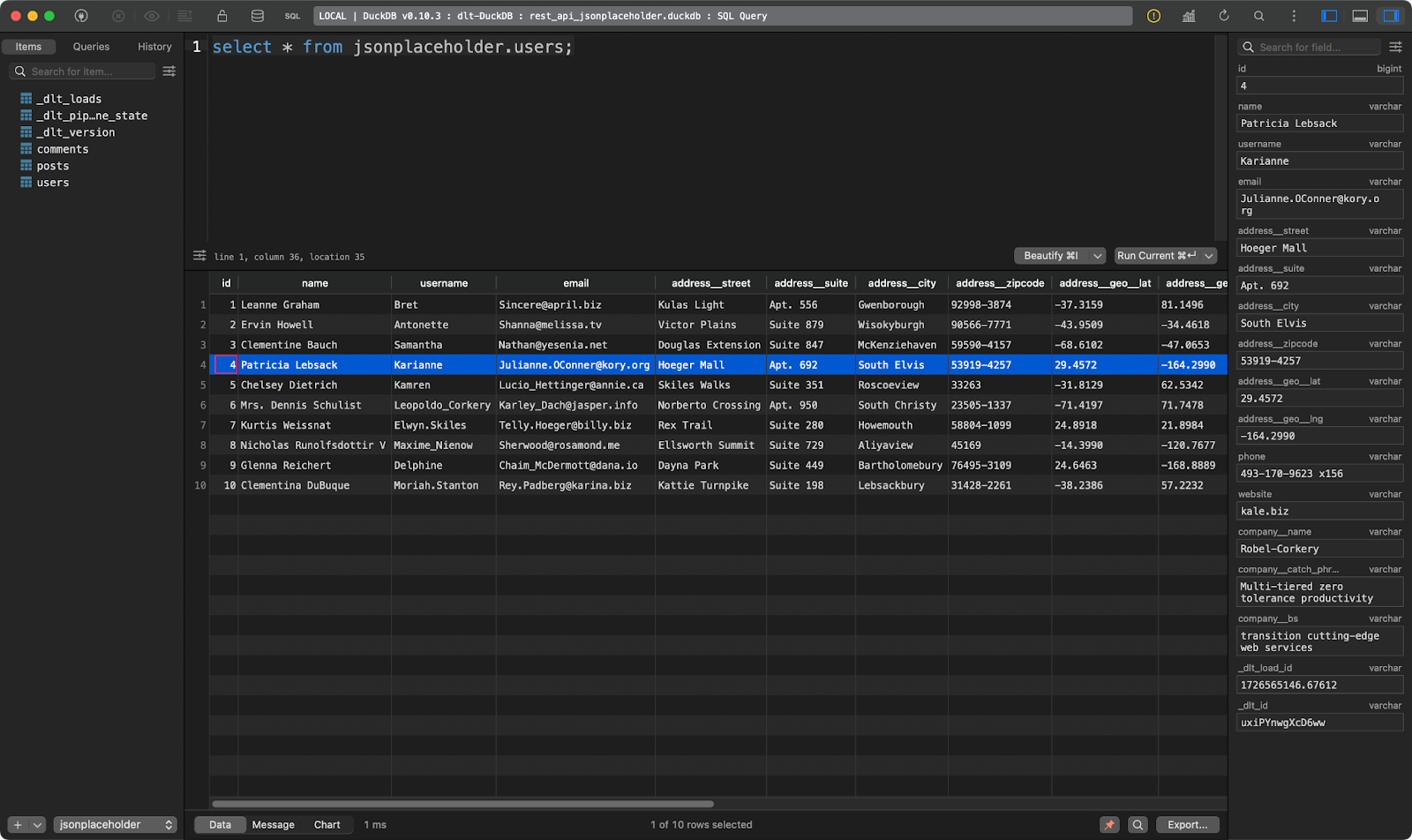
Y el tercero muestra a los usuarios. Éste es interesante porque contiene datos JSON anidados. La biblioteca dlt lo aplanó, de modo que puede almacenarse sin problemas en una sola tabla:
users tabla
Genial, ¿verdad? Ya no tienes que analizar JSON manualmente.
Si hay una fuente de datos más utilizada que las API REST, tiene que ser una base de datos relacional.
Para la demostración, he aprovisionado una base de datos Postgres de nivel libre en AWS:
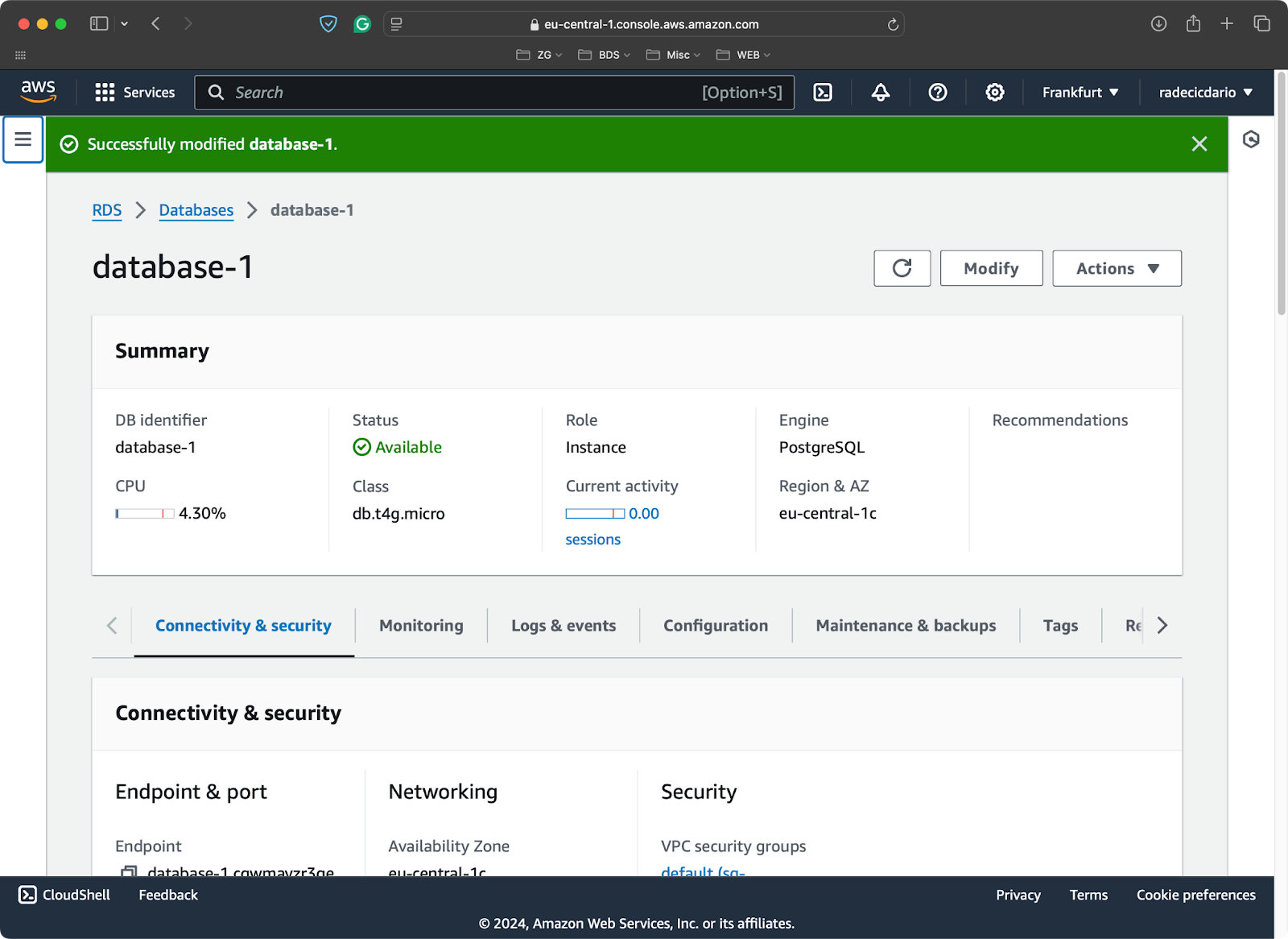
Base de datos PostgreSQL en AWS
Y cargué en él el conocido conjunto de datos Iris como tabla:
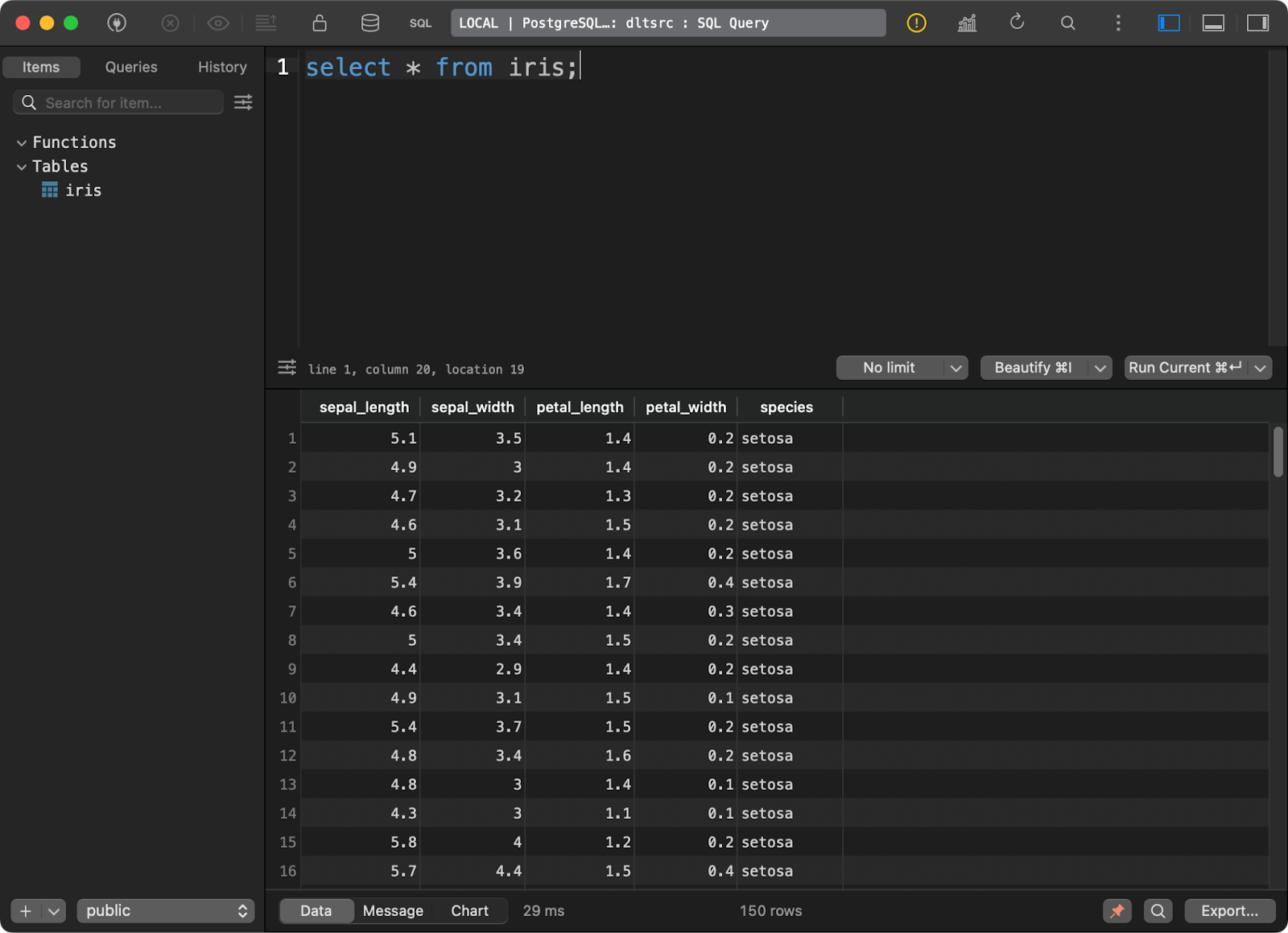
Datos en la base de datos Postgres
A continuación te mostraré cómo conectarte a una fuente Postgres desde dlt. Es un proceso más complicado de lo que podrías pensar en un principio.
Primero, empieza por instalar un submódulo para trabajar con bases de datos SQL:
pip install "dlt[sql_database]"A continuación, inicializa una canalización que utilice una base de datos SQL genérica como origen y DuckDB como destino:
dlt init sql_database duckdbEsta es la primera vez que jugarás con los archivos de la carpeta .dtl. Dentro de config.toml, especifica el nombre de la tabla de origen de la que quieres extraer los datos:
[sources.sql_database]
table = "table" # please set me up!
[runtime]
dlthub_telemetry = trueSustituye ”table” por “iris” y listo.
Dentro de secrets.toml, querrás especificar los parámetros de conexión para conectarte a la base de datos de origen. Ten en cuenta que es absolutamente necesario que añadas el nombre [sources.sql_database.credentials] antes de especificar los parámetros de conexión. De lo contrario, dlt no sabrá a qué se refieren:
[sources.sql_database.credentials]
drivername = "drivername" # please set me up!
database = "database" # please set me up!
password = "password" # please set me up!
username = "username" # please set me up!
host = "host" # please set me up!
port = 0 # please set me up!Y eso es todo en cuanto a configuración. Ahora puedes pasar al archivo pipeline de Python.
En resumen, sólo tienes que llamar a la función sql_database() para conectarte a la base de datos y extraer los datos de origen. Todos los detalles de configuración se especifican en los archivos TOML, por lo que puedes llamar a esta función sin ningún parámetro.
El resto del guión no introduce nada nuevo:
import dlt
from dlt.sources.sql_database import sql_database
def load_database_data() -> None:
source = sql_database()
pipeline = dlt.pipeline(
pipeline_name="postgres_to_duckdb_pipeline",
destination="duckdb",
dataset_name="iris_from_postgres"
)
load_info = pipeline.run(source)
print(load_info)
if __name__ == "__main__":
load_database_data()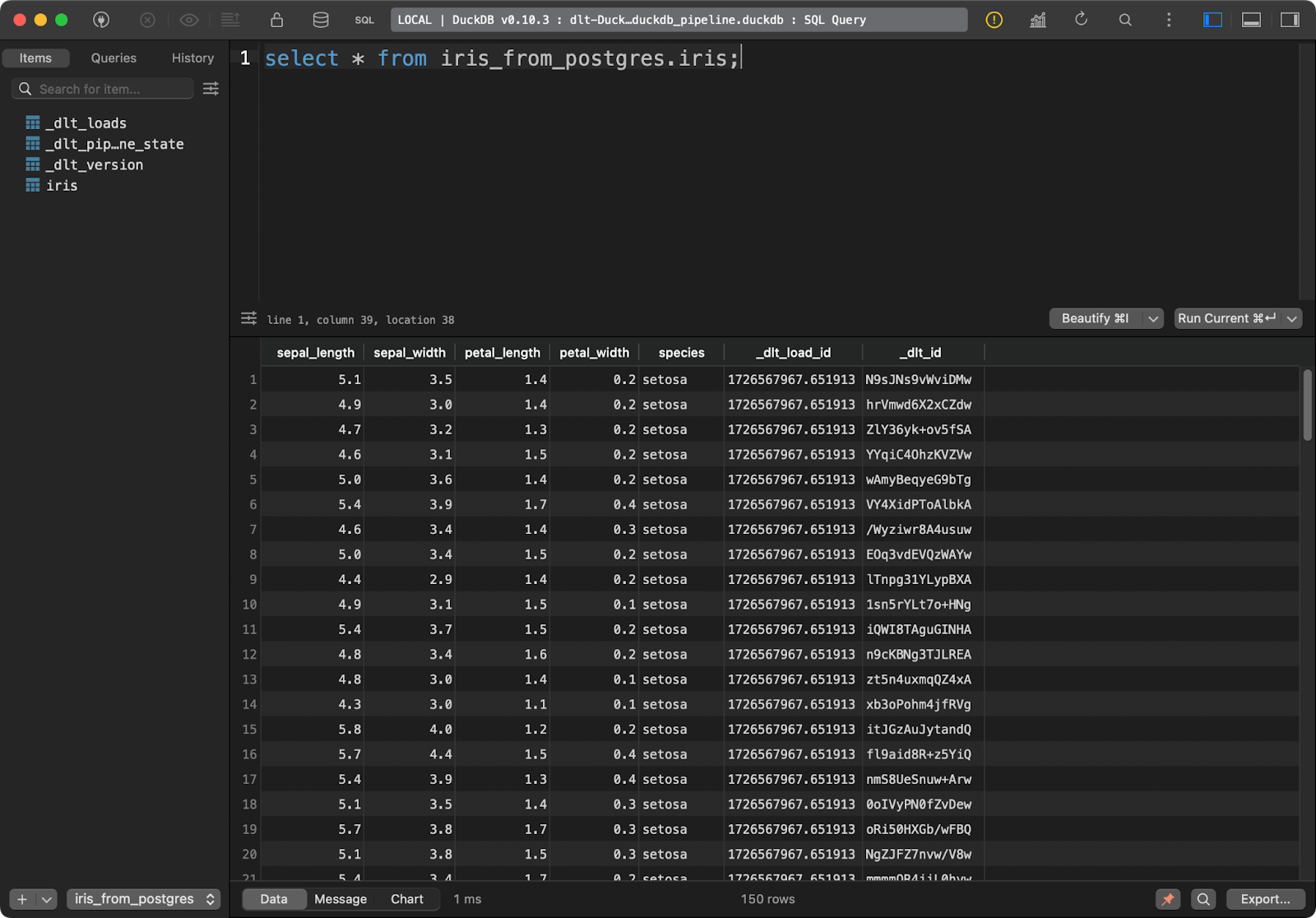
Mesa Iris
La tabla de destino en DuckDB tiene todos los datos de Iris con las dos columnas adicionales de linaje de datos.
La mayoría de las veces, querrás que tus canalizaciones se conecten al almacenamiento en la nube, como los buckets S3 de AWS.
He creado un bucket de S3 para este artículo y he subido un único archivo Parquet con conjuntos de datos de los viajes en taxi en NYC:
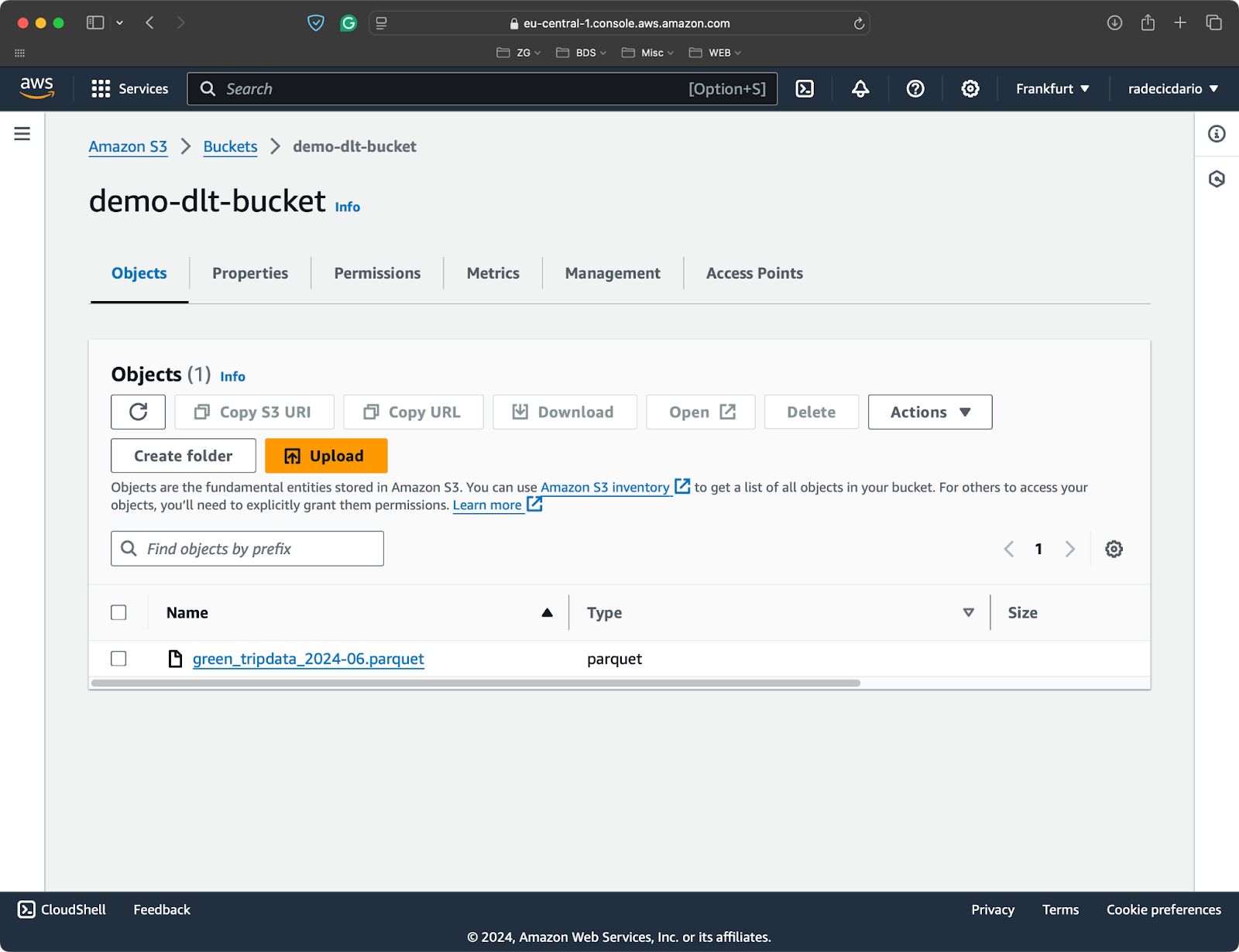
Bucket S3 con un único archivo Parquet
Para conectar un sistema de archivos local o remoto a dlt, tendrás que instalar un submódulo adicional:
pip install "dlt[filesystem]"Ahora puedes inicializar una nueva canalización que utilice un sistema de archivos como origen y DuckDB como destino:
dlt init filesystem duckdbLo primero es rellenar los archivos de configuración. El archivo config.toml necesita la URL completa de tu cubo S3:
[sources.filesystem]
bucket_url = "bucket_url" # please set me up!
[runtime]
dlthub_telemetry = trueY el archivo secrets.toml necesita información sobre tu rol IAM (clave de acceso y clave de acceso secreta), junto con la región en la que está aprovisionado tu cubo:
[sources.filesystem.credentials]
aws_access_key_id = "aws_access_key_id" # please set me up!
aws_secret_access_key = "aws_secret_access_key" # please set me up!
region_name = "region_name" # please set me up!Sobre el código de la tubería.
Utiliza la función readers() para leer los datos de la fuente que hayas configurado. El parámetro file_glob controla qué archivos deben leerse. Lo he configurado de forma que devuelva todos los archivos Parquet. Después, basta con encadenar la función read_parquet() para leer los datos:
import dlt
from dlt.sources.filesystem import readers, read_parquet
def load_s3_data() -> None:
source = readers(file_glob="*.parquet").read_parquet()
pipeline = dlt.pipeline(
pipeline_name="s3_to_duckdb_pipeline",
destination="duckdb",
dataset_name="nyc_data_from_s3"
)
load_info = pipeline.run(source.with_name("nyc_taxi_data"))
print(load_info)
if __name__ == "__main__":
load_s3_data()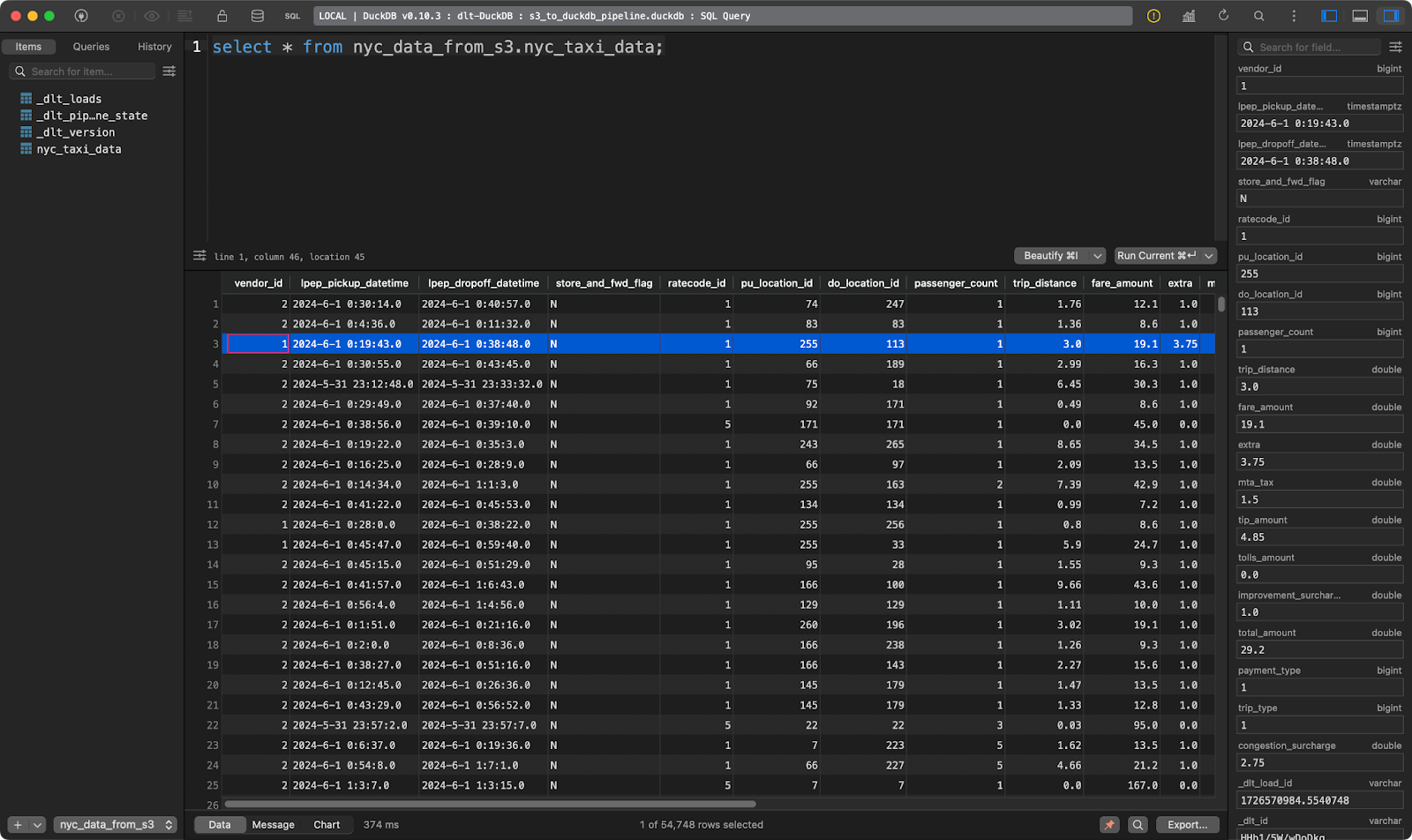
Tabla de viajes en taxi en NYC
Y ahí lo tienes: ¡decenas de miles de registros cargados en cuestión de segundos!
Leer datos de un sistema de archivos local es casi idéntico a leer datos de S3.
Esta vez, estoy utilizando conjunto de datos mtcars guardado localmente en una carpeta localbucket:
Archivo en un sistema local
Ahora, en tu archivo config.toml, proporciona una ruta absoluta a tu carpeta local. Es importante anteponer a la ruta file:///. Son tres cuchilladas:
[sources.filesystem]
bucket_url = "file:///absolute/path/to/local/folder"
[runtime]
dlthub_telemetry = trueComo ya no te conectas a S3, puedes borrar el contenido de secrets.toml.
El código real de la tubería será casi idéntico al de la sección anterior. El único cambio es que en file_glob ahora proporcionas un nombre de archivo y utilizas una función diferente para leer los datos (formato CSV):
import dlt
from dlt.sources.filesystem import filesystem, read_csv_duckdb
def load_local_data() -> None:
source = filesystem(file_glob="mtcars.csv") | read_csv_duckdb()
pipeline = dlt.pipeline(
pipeline_name="local_filesystem_to_duckdb_pipeline",
destination="duckdb",
dataset_name="mtcars_data_from_local_disk"
)
load_info = pipeline.run(source.with_name("mtcars"))
print(load_info)
if __name__ == "__main__":
load_local_data()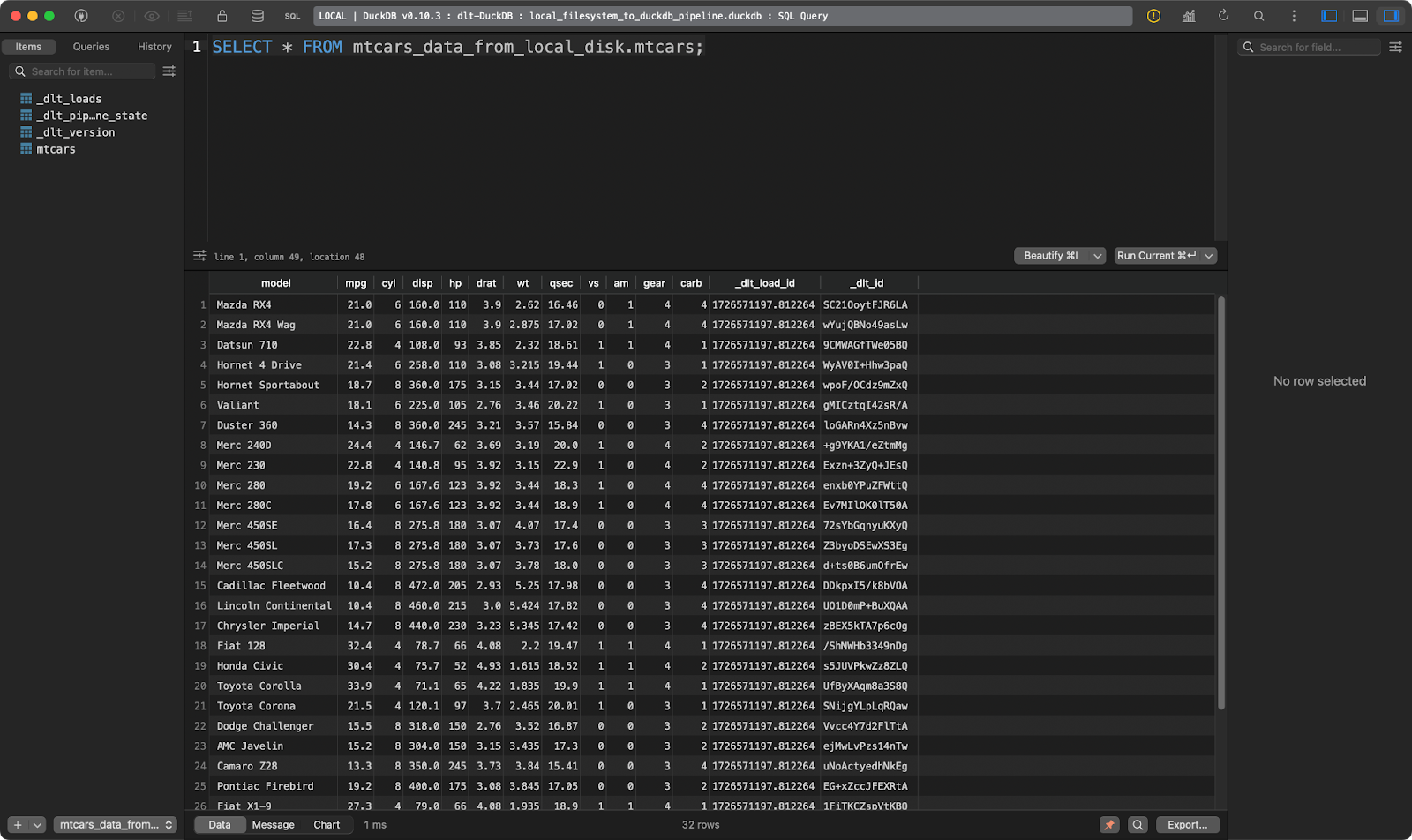
La tabla mtcars
¡Funciona de maravilla!
Eso es todo lo que quiero mostrar en relación con las fuentes de datos. Puedes encontrar muchos más que se adapten a tus necesidades específicas oen la página de documentación de dlt sobre fuentes de datos.
No tiene sentido limitarse a mover los datos del punto A al punto B. Normalmente quieres aplicar la transformación antes de escribir los datos en el destino (ETL) o después (ELT).
Si no te suenan las siglas ETL y ELT, te recomendamos que sigasnuestro curso de canalización de datos con Python.
En esta sección, te mostraré cómo aplicar transformaciones a tus datos con SQL y Python.
Los ingenieros de datos viven y respiran SQL. En esta sección, te mostraré cómo cargar un archivo local en una base de datos Postgres, transformarlo y escribirlo de nuevo en otra tabla (ELT).
Empieza por modificar el archivo secrets.toml para incluir los detalles de conexión a la base de datos para el origen y el destino. Los valores serán idénticos, sólo tienes que especificarlos dos veces:
[sources.sql_database.credentials]
drivername = "drivername" # please set me up!
database = "database" # please set me up!
password = "password" # please set me up!
username = "username" # please set me up!
host = "host" # please set me up!
port = 0 # please set me up!
[destinations.sql_database.credentials]
drivername = "drivername" # please set me up!
database = "database" # please set me up!
password = "password" # please set me up!
username = "username" # please set me up!
host = "host" # please set me up!
port = 0 # please set me up!Dentro de config.toml, escribe una ruta absoluta a una carpeta situada en tu sistema de archivos:
[sources.filesystem]
bucket_url = "file:///absolute/path/to/local/folder"
[runtime]
dlthub_telemetry = trueEl archivo pipeline de Python tendrá dos funciones:
load_source_data(): Carga un archivo CSV local y lo guarda en una tabla de una base de datos Postgres.transform_data(): Extrae datos de una tabla Postgres y crea una tabla nueva basada en la original. Sólo añadiré un par de columnas para demostrar un punto. Primero se borra la tabla de destino, si existe.Querrás llamar a las funciones una tras otra:
import dlt
from dlt.sources.filesystem import filesystem, read_csv
def load_source_data() -> None:
source = filesystem(file_glob="iris.csv") | read_csv()
pipeline = dlt.pipeline(
pipeline_name="load_source_data",
destination="postgres",
dataset_name="data"
)
load_info = pipeline.run(source.with_name("iris_src"), write_disposition="replace")
print(load_info)
def transform_data() -> None:
pipeline = dlt.pipeline(
pipeline_name="transform_data",
destination="postgres",
dataset_name="data"
)
try:
with pipeline.sql_client() as client:
client.execute_sql("""
DROP TABLE iris_tgt;
""")
print(f"Table iris_tgt deleted!")
except Exception as e:
print(f"Table iris_tgt does not exists, proceeding!")
try:
with pipeline.sql_client() as client:
client.execute_sql("""
CREATE TABLE iris_tgt AS (
SELECT
sepal_length,
sepal_width,
petal_length,
petal_width,
sepal_length + sepal_width AS total_sepal,
petal_length + petal_width AS total_petal,
UPPER(species) AS species_upper
FROM iris_src
);
""")
print(f"Table iris_tgt created and filled!")
except Exception as e:
print(f"Unable to transform data! Error: {str(e)}")
if __name__ == "__main__":
load_source_data()
transform_data()La tabla de origen contiene el conjunto de datos Iris con dos columnas adicionales de linaje de datos:
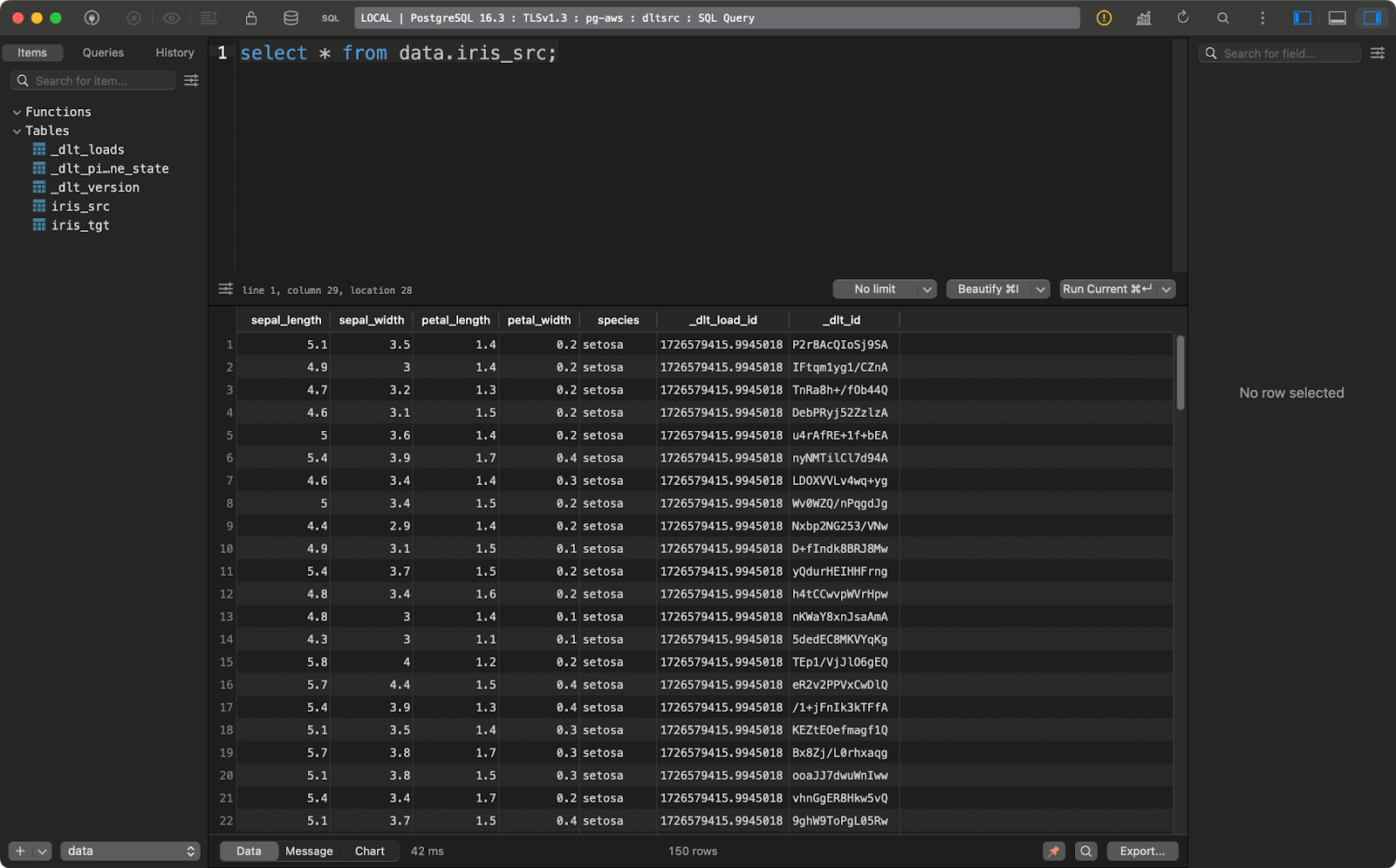
Tabla fuente Iris
Y la tabla de destino contiene la versión transformada del conjunto de datos Iris:
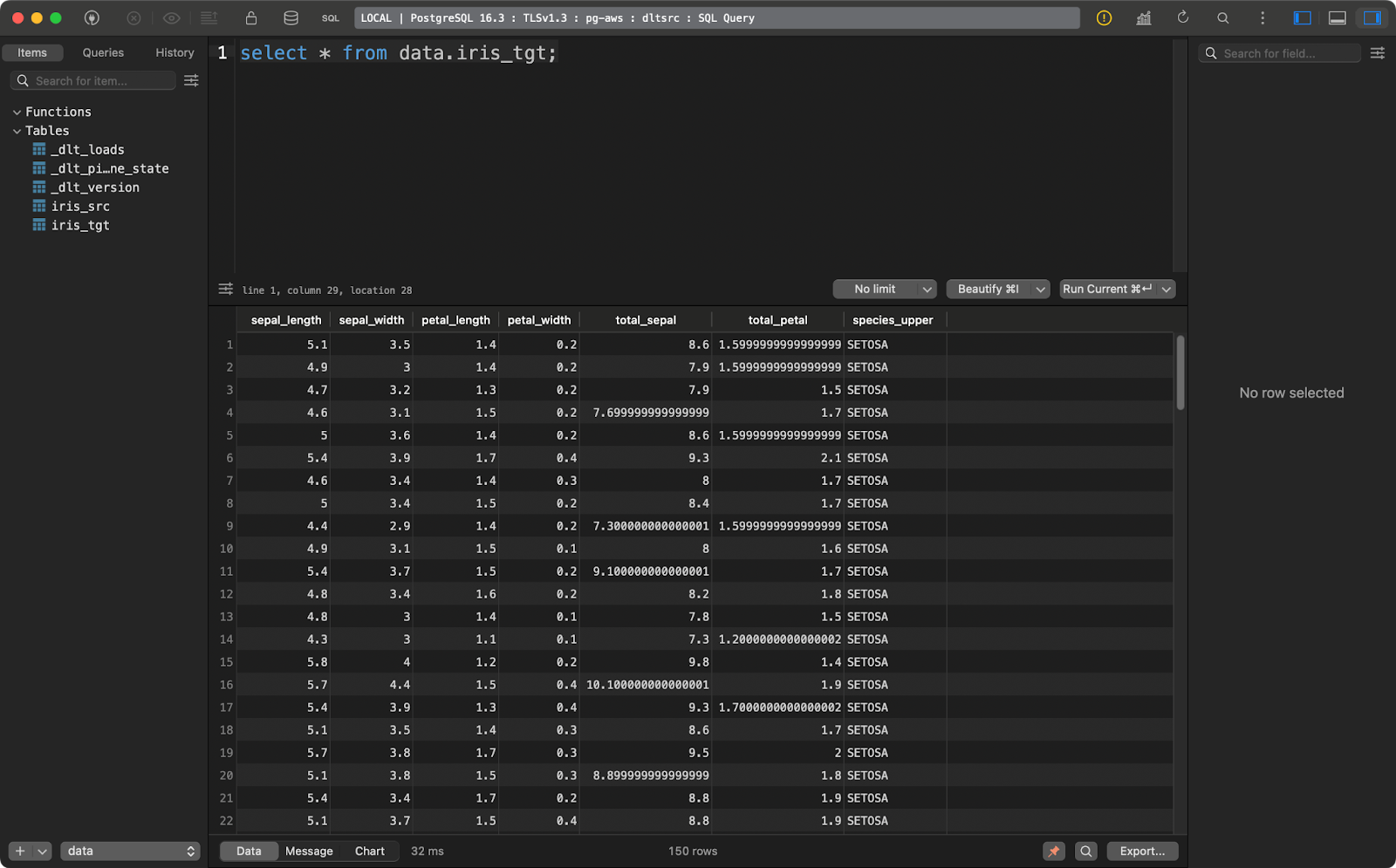
Tabla de destino Iris
Este ejemplo de transformación es bastante básico, pero explica cómo transformar tus datos cuando ya están cargados en el destino.
¿Y si quieres transformar los datos antes de escribirlos en la base de datos? En otras palabras, ¿si no quieres guardar los datos brutos y transformados? Eso es básicamente la descripción de un ETL pipeline. Te mostraré cómo implementar uno con pandas.
Tus archivos TOML permanecen inalterados.
En el código de la tubería, ahora tendrás que implementar un par de funciones adicionales:
extract_data(): Utiliza pandas para leer un archivo CSV local.transform_data(): Aplica transformaciones de datos utilizando pandas en lugar de SQL.data(): Una función decorada con @dlt.resource que produce el conjunto de datos transformado.load_data(): Carga el dlt.resource en la tabla iris_tgt.El código de este pipeline te resultará familiar si tienes experiencia con pandas:
import dlt
import pandas as pd
def extract_data() -> pd.DataFrame:
return pd.read_csv("iris.csv")
def transform_data(df: pd.DataFrame) -> pd.DataFrame:
df["sepal_sum"] = df["sepal_length"] + df["sepal_width"]
df["petal_sum"] = df["petal_length"] + df["petal_width"]
df = df.drop(["sepal_length", "sepal_width", "petal_length", "petal_width"], axis=1)
return df
@dlt.resource
def data():
yield transform_data(df=extract_data())
def load_data() -> None:
pipeline = dlt.pipeline(
pipeline_name="pandas_etl_pipeline",
destination="duckdb",
dataset_name="data"
)
load_info = pipeline.run(data(), table_name="iris_tgt")
print(load_info)
if __name__ == "__main__":
load_data()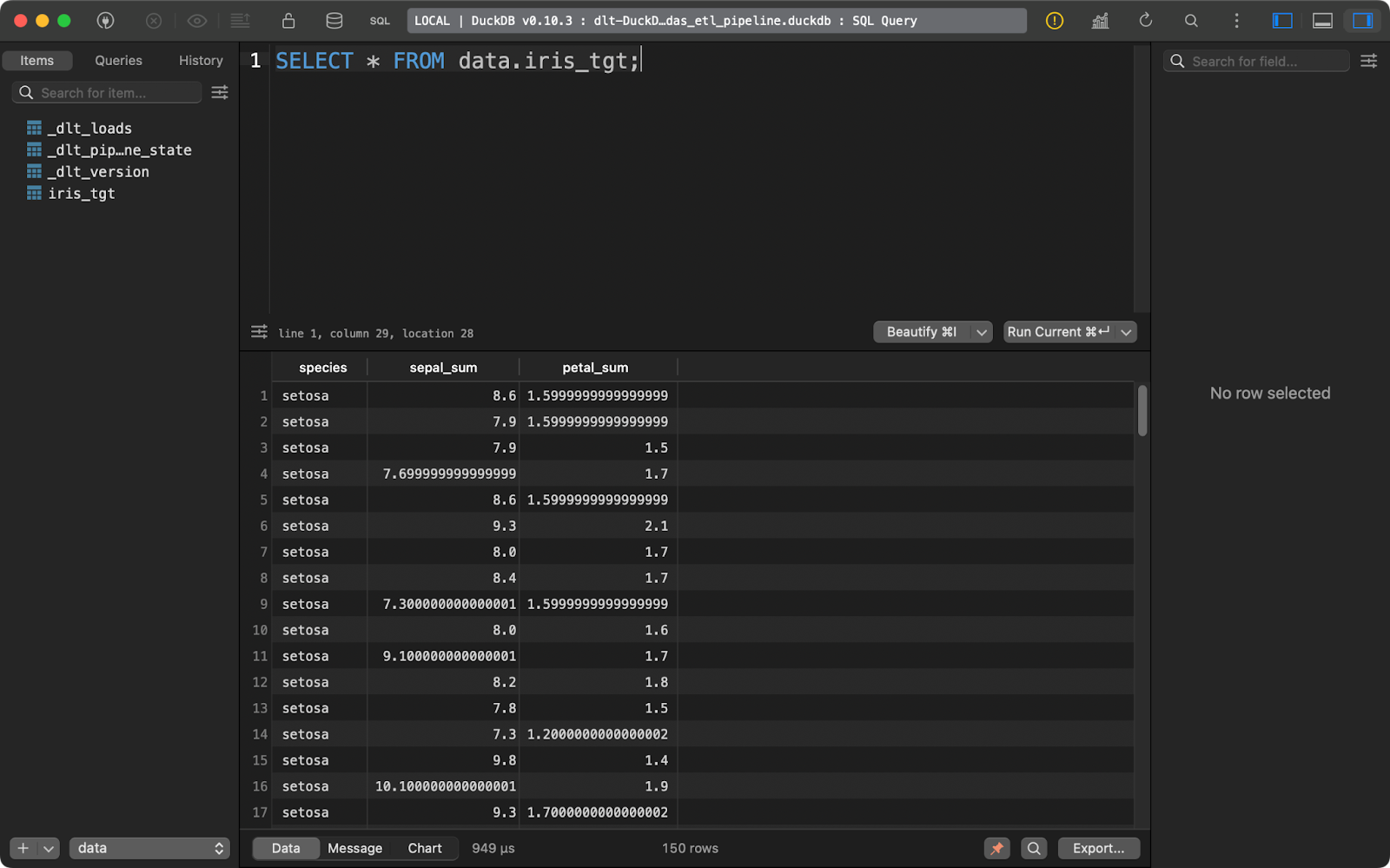
Tabla de destino Iris
Una vez más, dlt se diseñó teniendo en cuenta la ELT, pero los flujos de trabajo ETL no requieren demasiados cambios de código.
Tanto SQL como pandas son formas sencillas de transformar los datos antes y después de cargarlos en el destino.
Los autores de dlt recomiendan que utilicesen su lugar el dbt de Python i. Es una opción mucho mejor y más versátil, pero es una herramienta demasiado compleja para que la tratemos en un solo artículo. Si tú o tu equipo ya utilizáis dbt, entonces su uso en dlt pipelines os parecerá una extensión natural.
Si quieres aprender más sobre dbt en Python, tenemos un curso completo de curso de 4 módulos disponible.
Por otra parte, si eres un principiante con conocimientos básicos de SQL y pandas, los dos enfoques de transformación que te he mostrado son suficientes para empezar.
Hasta ahora, he utilizado DuckDB como destino preferido porque es sencillo y no requiere configuración. En esta sección, te mostraré cómo trabajar con un par of más de destinos,incluyendo un sistema de archivos local, almacenamiento en la nube y bases de datos.
A veces, quieres guardar en disco el resultado de una canalización de datos. Ahora bien, dlt no es el candidato perfecto para el trabajo, ya que también almacena muchos metadatos, pero puedes utilizarlo si es absolutamente necesario.
Empieza por modificar el archivo config.toml. Proporciona las rutas a las carpetas de origen y destino en tu sistema local:
[sources.filesystem]
bucket_url = "file:///path/to/source/folder"
[destination.filesystem]
bucket_url = "file:///path/to/target/folder"
[runtime]
dlthub_telemetry = trueAhora, en el archivo Python, simplemente carga el archivo fuente desde un sistema de archivos y ejecútalo a través de la tubería. No he aplicado ninguna transformación de datos en aras de la simplicidad:
import dlt
from dlt.sources.filesystem import filesystem, read_csv
def load_local_data() -> None:
source = filesystem(file_glob="iris.csv") | read_csv()
pipeline = dlt.pipeline(
pipeline_name="local_to_local",
destination="filesystem",
dataset_name="data"
)
load_info = pipeline.run(source.with_name("iris"), loader_file_format="csv")
print(load_info)
if __name__ == "__main__":
load_local_data()Es el contenido de la carpeta de destino:
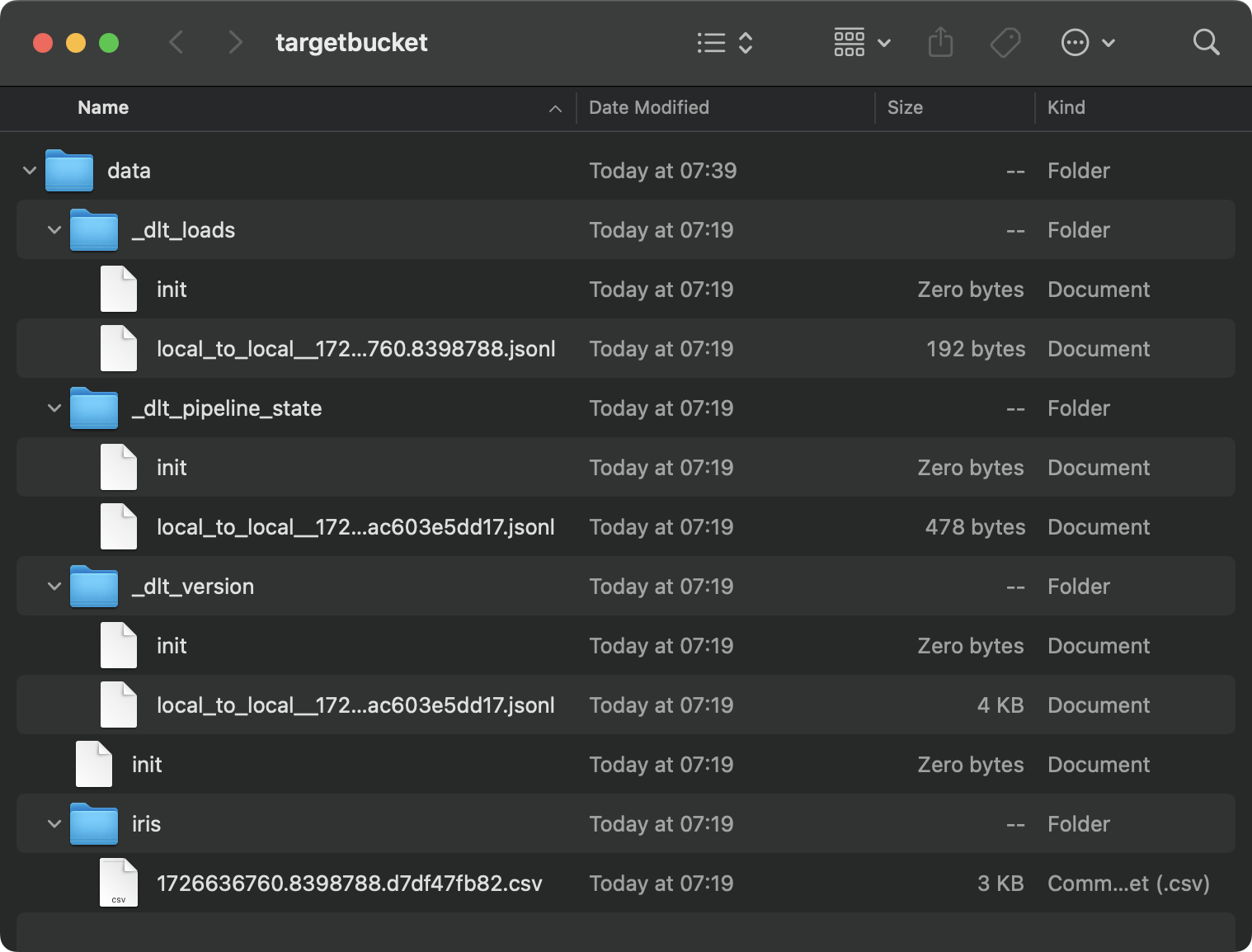
Contenido de la carpeta local
Es un desastre, y eso es sólo el resultado de una única tubería. Imagina que tuvieras docenas de ellos.
Las bases de datos son lugares más naturales para almacenar esta información.
Estoy utilizando una base de datos Postgres aprovisionada en AWS, pero no tienes por qué hacerlo. Siéntete libre de utilizar cualquier otro proveedor de bases de datos y nubes.
Dentro de config.toml, querrás proporcionar una ruta a la carpeta en tu sistema de archivos local:
[sources.filesystem]
bucket_url = "file:///your-local-bucket"
[runtime]
dlthub_telemetry = trueY en secrets.toml, escribe los datos de conexión a la base de datos:
[destination.postgres.credentials]
drivername = "drivername" # please set me up!
database = "database" # please set me up!
password = "password" # please set me up!
username = "username" # please set me up!
host = "host" # please set me up!
port = 0 # please set me up!Cargar los datos de origen en la base de datos se reduce ahora a cambiar el valor del parámetro destination en dlt.pipeline(). La función with_name() invocada en la fuente de datos controla cómo se nombrará la tabla de la base de datos:
import dlt
from dlt.sources.filesystem import filesystem, read_csv
def load_to_database() -> None:
source = filesystem(file_glob="iris.csv") | read_csv()
pipeline = dlt.pipeline(
pipeline_name="local_to_db",
destination="postgres",
dataset_name="local_load"
)
load_info = pipeline.run(source.with_name("iris_from_local"))
print(load_info)
if __name__ == "__main__":
load_to_database()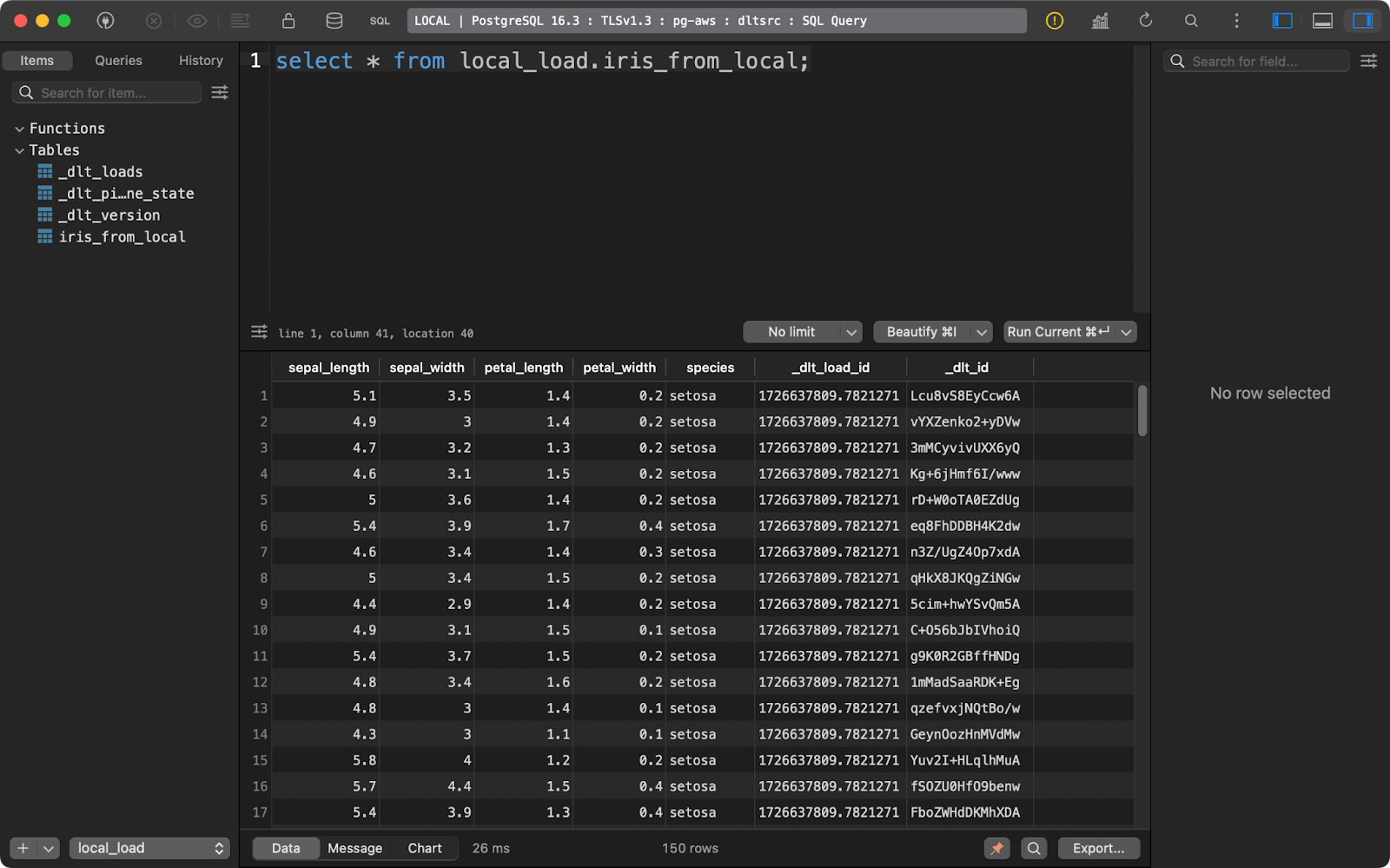
Datos del iris cargados
Exploremos una opción de destino más antes de hablar de cosas más avanzadas de dlt.
Al igual que con tu sistema de archivos local, el almacenamiento en la nube (por ejemplo, S3) también almacenará los metadatos en archivos y carpetas independientes.
Si quieres probarlo, empieza ajustando el archivo config.toml para incluir las rutas a una carpeta local y al cubo de S3:
[sources.filesystem]
bucket_url = "file:///path/to/local/folder"
[destination.filesystem]
bucket_url = "s3://bucket-name"
[runtime]
dlthub_telemetry = trueEn cuanto a secrets.toml, introduce tus credenciales IAM y el nombre de la región del bucket S3:
[destination.filesystem.credentials]
aws_access_key_id = "aws_access_key_id" # please set me up!
aws_secret_access_key = "aws_secret_access_key" # please set me up!
region_name = "region_name" # please set me up!La ejecución de la canalización transferirá el archivo CSV local a S3, y lo almacenará en formato JSONL (líneas JSON):
import dlt
from dlt.sources.filesystem import filesystem, read_csv
def load_to_s3() -> None:
source = filesystem(file_glob="iris.csv") | read_csv()
pipeline = dlt.pipeline(
pipeline_name="local_to_db",
destination="filesystem",
dataset_name="iris_data"
)
load_info = pipeline.run(source.with_name("iris"))
print(load_info)
if __name__ == "__main__":
load_to_s3()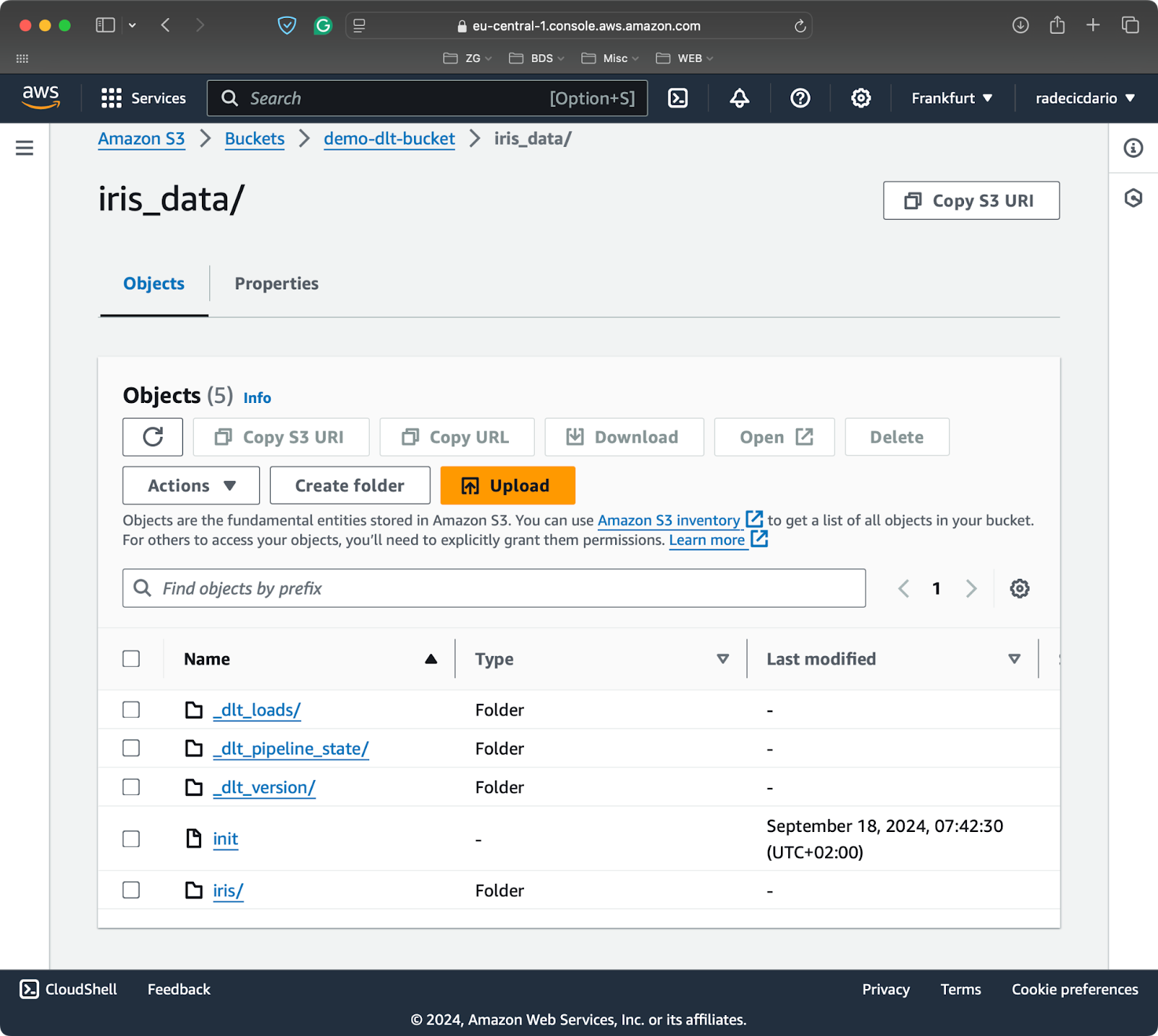
Contenido del cubo S3
Ya conoces los conceptos básicos para mover datos y transformarlos por el camino. Pero, ¿qué ocurre cuando ejecuta la tubería varias veces? De eso hablaré a continuación.
Casi nunca ejecutarás la tubería una sola vez. Es más típico programar las ejecuciones de los oleoductos, por ejemplo, para que se ejecuten una vez al día o una vez cada semana.
Si es así, probablemente querrás controlar más cómo se insertan los datos nuevos y cómo se actualizan los existentes.
Cada vez que ejecutes tu canalización, se añadirán nuevos datos a la tabla que elijas.
Te lo demostraré escribiendo una sencilla canalización que inserte un DataFrame pandas ficticio en una tabla DuckDB:
import dlt
import pandas as pd
@dlt.resource(primary_key="index")
def data():
data = pd.DataFrame({
"index": [1, 2, 3, 4, 5],
"a": [10, 15, 20, 25, 30],
"b": [22.5, 30.5, 35.5, 50.5, 10.5],
"c": ["row 1", "row 2", "row 3", "row 4", "row 5"]
})
yield data
def load_local_data() -> None:
pipeline = dlt.pipeline(
pipeline_name="pipeline_incremental_load",
destination="duckdb",
dataset_name="data"
)
load_info = pipeline.run(data=data(), table_name="dataset")
print(load_info)
if __name__ == "__main__":
load_local_data()Ejecutando la canalización una vez se insertarán cinco filas de datos:
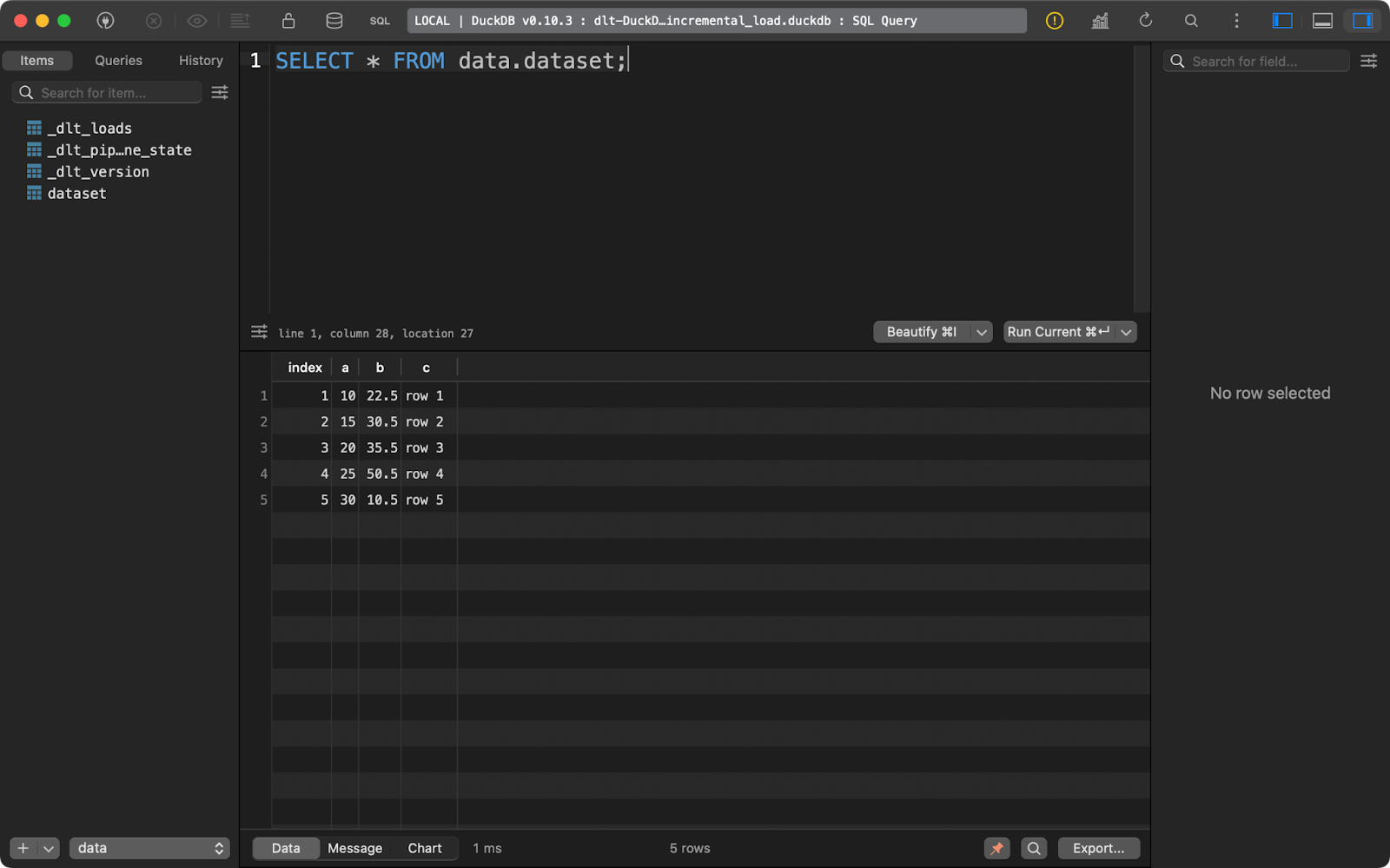
Primera ejecución de anexión
Y ejecutándolo de nuevo inserta las mismas cinco filas:
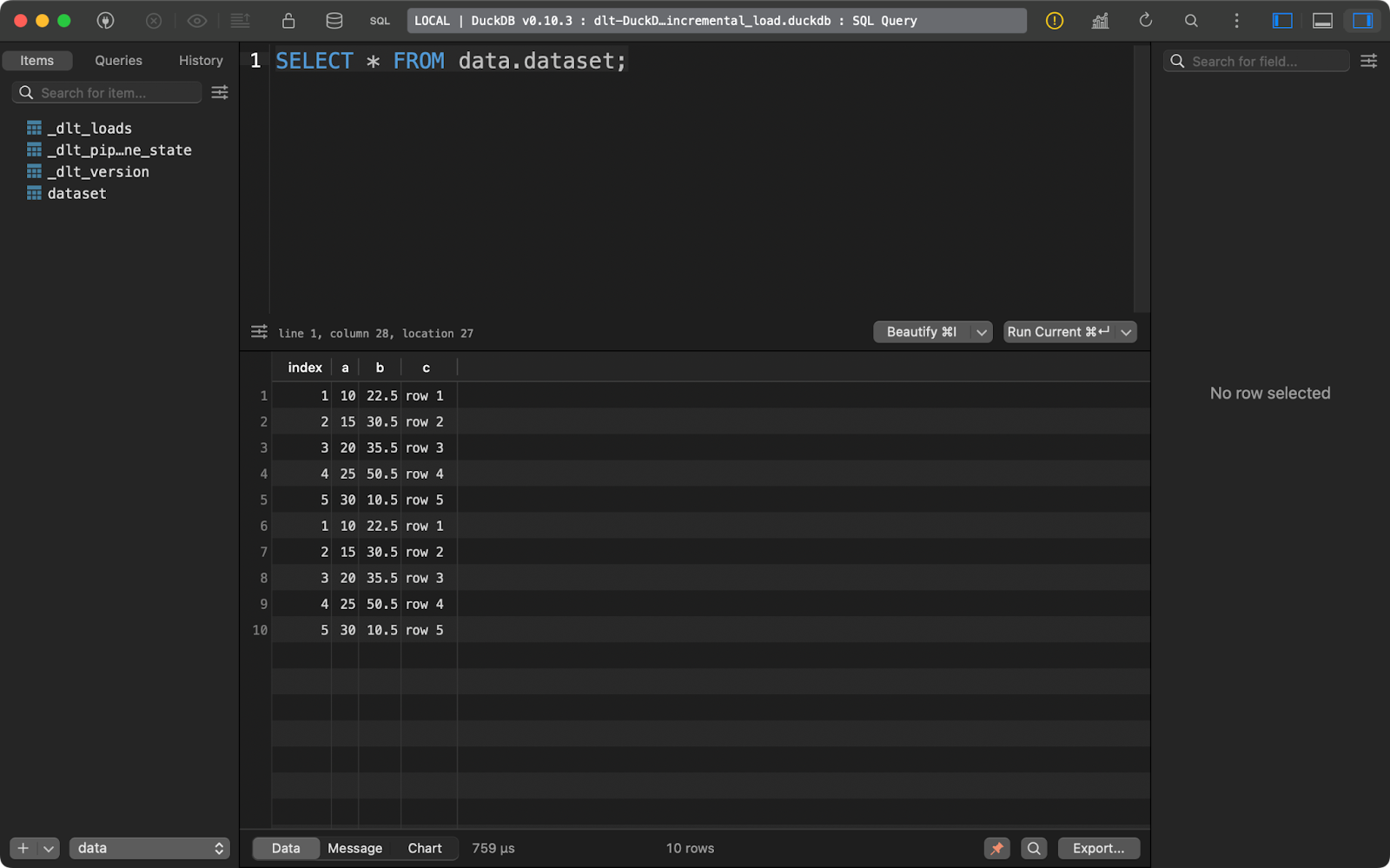
Segunda ejecución de anexión
Con este tipo de datos es fácil concluir una cosa: está duplicado. Deja que te muestre lo que puedes hacer al respecto.
Si quieres borrar registros existentes y sustituirlos por otros nuevos, añade write_disposition=”replace” a pipeline.run():
load_info = pipeline.run(data=data(), table_name="dataset", write_disposition="replace")Después de hacer esto, he ejecutado la canalización cuatro veces, como puedes ver en la tabla de metadatos _dlt_loads:
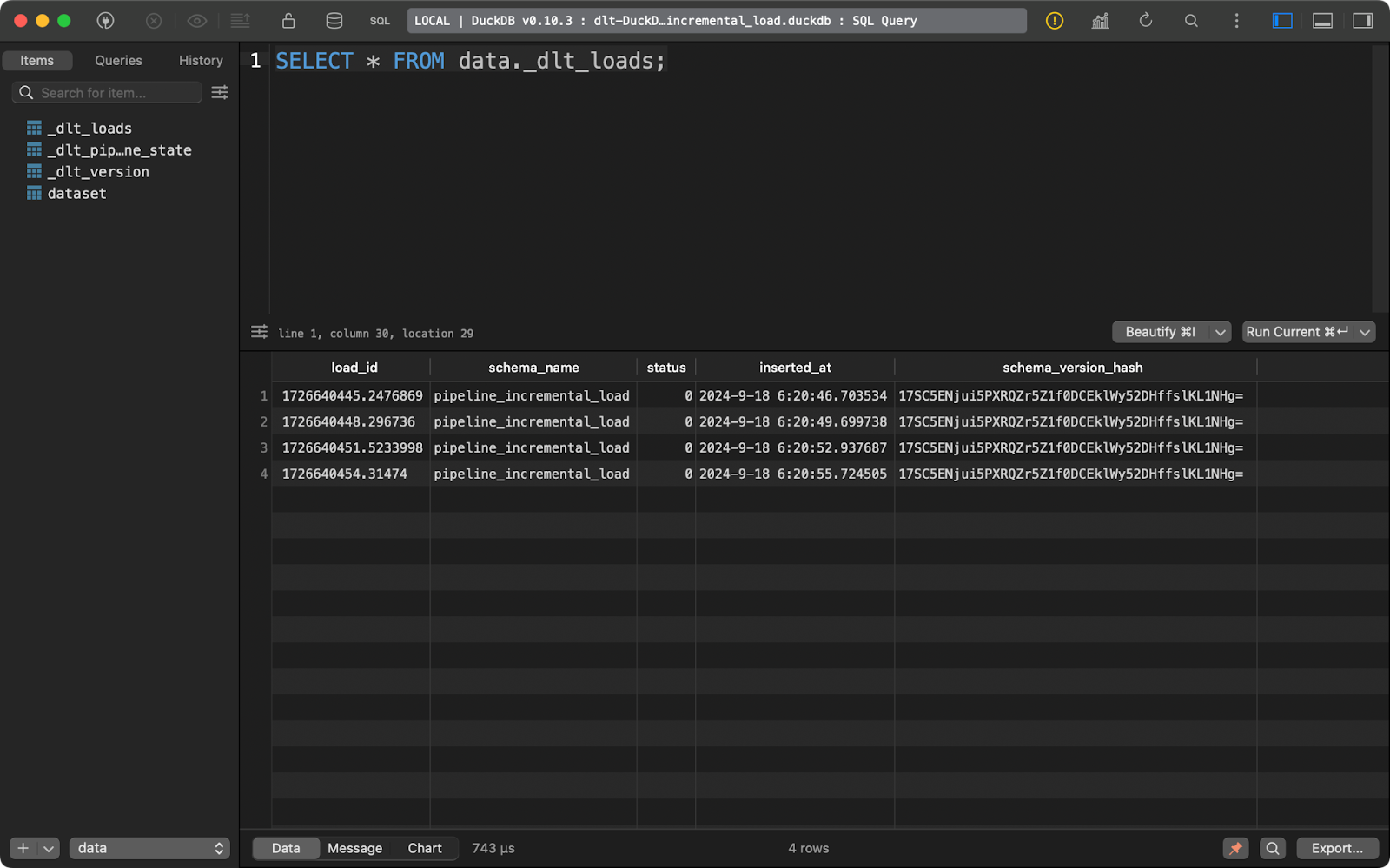
Ejecutar la canalización varias veces
Y la tabla dataset sólo contiene 5 registros:
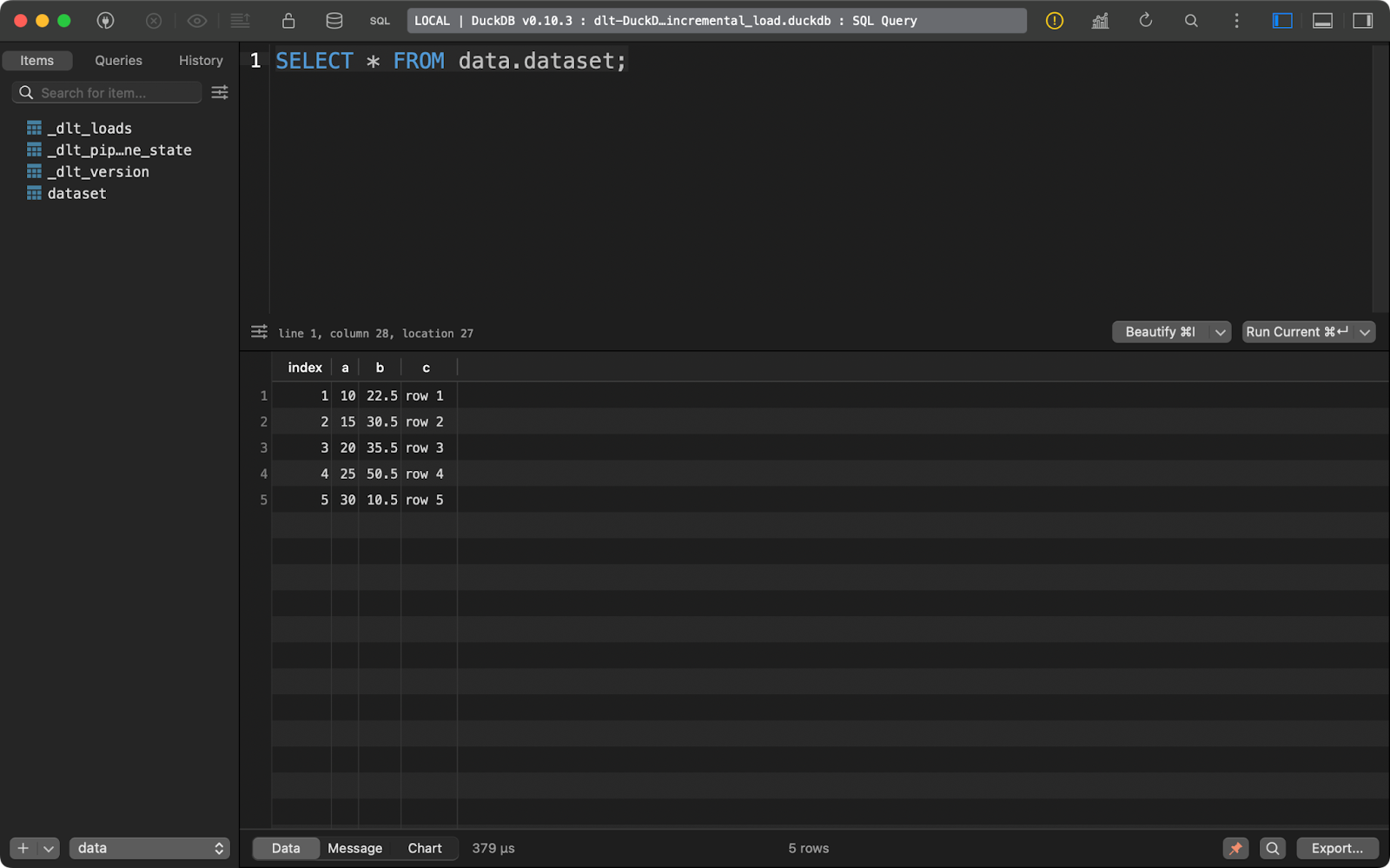
dataset ÍNDICE
En resumen, este enfoque siempre sustituirá a los datos existentes.
Pero, ¿y si tienes una mezcla de datos nuevos y actualizados? Ahí es donde entra en juego la operación upsert. Se implementa a través de la disposición de escritura merge en dlt.
Como referencia, he vuelto a ejecutar la canalización con los datos de la sección anterior para asegurarme de que hay 5 filas presentes.
A continuación, actualicé los datos para añadir una fila más y cambiar los valores de algunos registros con los valores existentes en index.
El paquete dlt consultará la columna primary_key que hayas especificado y la comparará con los datos presentes en el sistema de destino. Los registros con la columna de clave primaria existente se actualizarán, y los nuevos se insertarán:
import dlt
import pandas as pd
@dlt.resource(primary_key="index")
def data():
data = pd.DataFrame({
"index": [1, 2, 3, 4, 5, 6],
"a": [10, 15, 200000, 25, -3000, 50],
"b": [22.5, 30.5, 3555555.5, 50.5, -100.5, 15.5],
"c": ["row 1", "row 2", "row 3 updated", "row 4", "row 5 updated", "row 6 new"]
})
yield data
def load_local_data() -> None:
pipeline = dlt.pipeline(
pipeline_name="pipeline_incremental_load",
destination="duckdb",
dataset_name="data"
)
load_info = pipeline.run(data=data(), table_name="dataset", write_disposition="merge")
print(load_info)
if __name__ == "__main__":
load_local_data()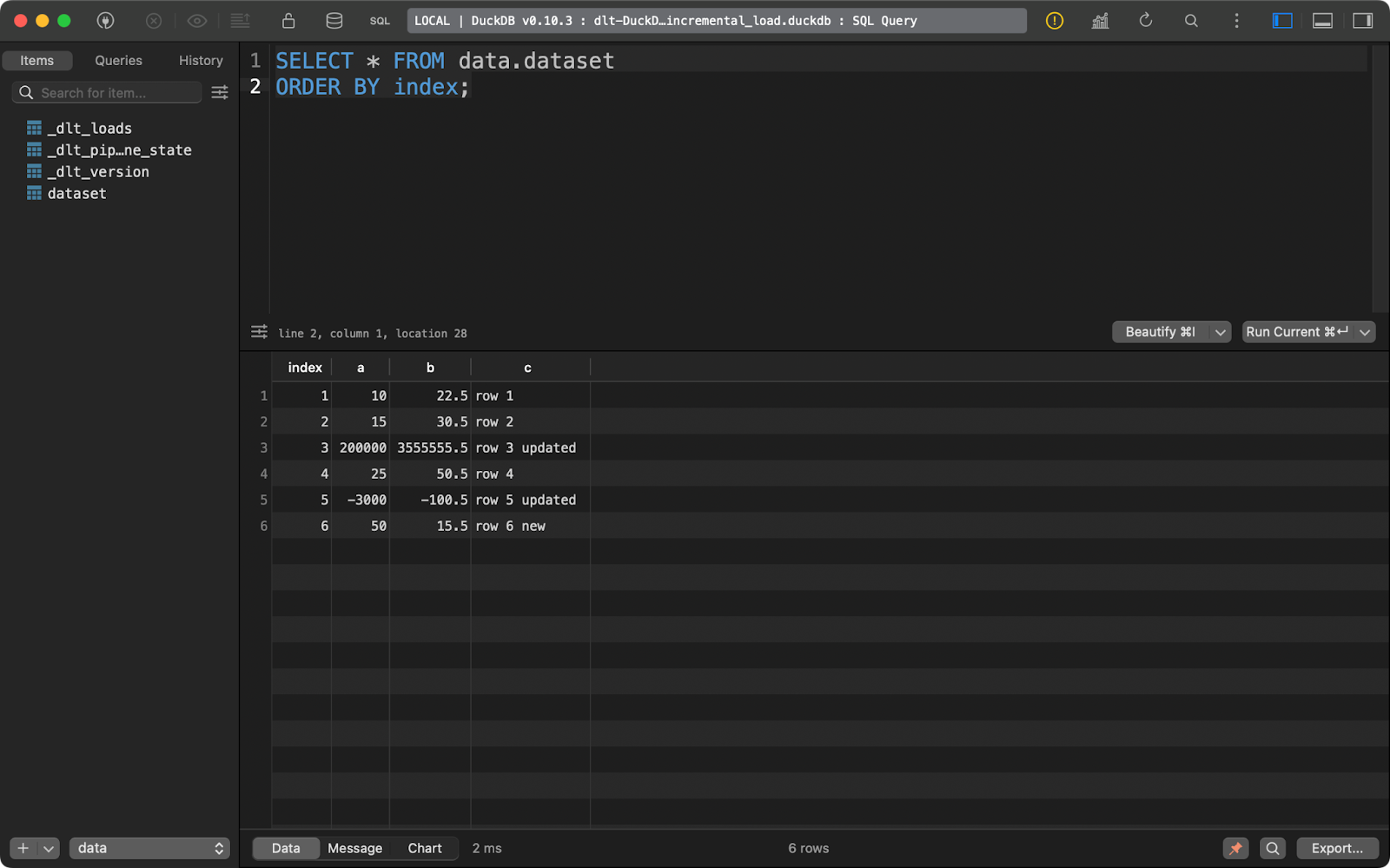
Conjunto de datos después de la operación upsert
En resumen, acabas con una fila nueva y dos actualizadas.
Este es probablemente el comportamiento que quieres para la mayoría de tus pipelines, especialmente cuando quieres evitar la duplicación de datos.
En conclusión, la ingeniería de datos es más de lo que parece. El movimiento de datos es sólo una parte. Sin embargo, es una parte vital y la mayoría de los demás aspectos de la ingeniería de datos giran en torno a ella.
Si ya estás familiarizado con Python, probablemente no estés buscando aprender desde cero una herramienta GUI para mover datos, o migrar a un lenguaje completamente nuevo. Quieres ceñirte a un entorno familiar. La biblioteca dlt de Python es todo lo que tú y tu equipo necesitáis para modernizar los sistemas heredados y reducir los costes de cloud. Lo han probado muchos grandes, como Hugging Face, Taktile, Untitled Data Company y Harness, así que creo que también se adaptará a tus necesidades.
Dicho esto, es probable que dlt no sea la única herramienta que necesites para implantar canalizaciones de datos eficientes. Querrás aprender herramientas de datos adicionales, como dbt, para llevar el procesamiento de datos al siguiente nivel.
Si quieres iniciar una carrera como ingeniero de datos, nuestro curso de 3 módulos es la forma perfecta de empezar.
Nuestros programas de certificación te ayudan a destacar y a demostrar que tus aptitudes están preparadas para el trabajo a posibles empleadores.

¡Aprende más sobre ingeniería de datos con estos cursos!
programa
Curso
Curso
blog
DataCamp Team
12 min
Tutorial
Karlijn Willems
Tutorial
DataCamp Team
Tutorial
Abid Ali Awan
Tutorial
Nadia mhadhbi
Tutorial
Natassha Selvaraj
