
Cursus
Ingénieur de données en Python
40 h
Une bonne pratique lors de la mise en place d'un nouveau projet Python est de le faire dans un environnement virtuel. Je vous montrerai comment procéder avec conda et venv.
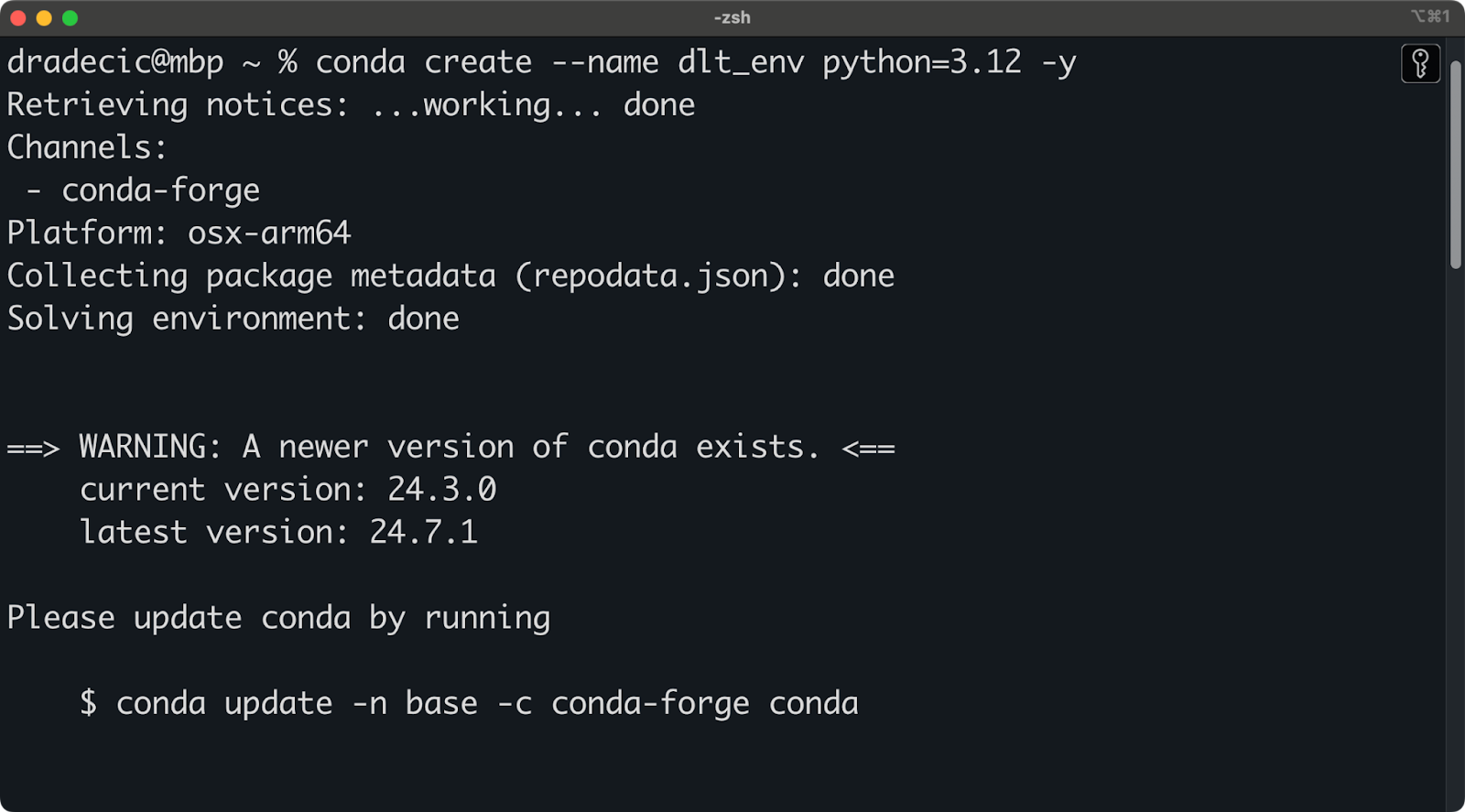
J'utilise Anaconda pour gérer les environnements et les dépendances. Si c'est le cas, exécutez l'extrait suivant pour créer un nouvel environnement virtuel nommé dlt_env basé sur Python 3.12 :
conda create --name dlt_env python=3.12 -y
conda activate dlt_envVous devriez voir une sortie similaire à celle-ci dans votre terminal :
Configuration de l'environnement Conda
En revanche, si vous n'utilisez pas Anaconda, exécutez la commande suivante pour créer et activer un nouvel environnement Python :
python -m venv ./env
source ./env/bin/activateVous êtes maintenant prêt à installer dlt.
Avant de poursuivre, vous devez avoir créé et activé un environnement virtuel
Pour installer dlt, exécutez la commande suivante dans l'environnement :
pip install dlt
dlt version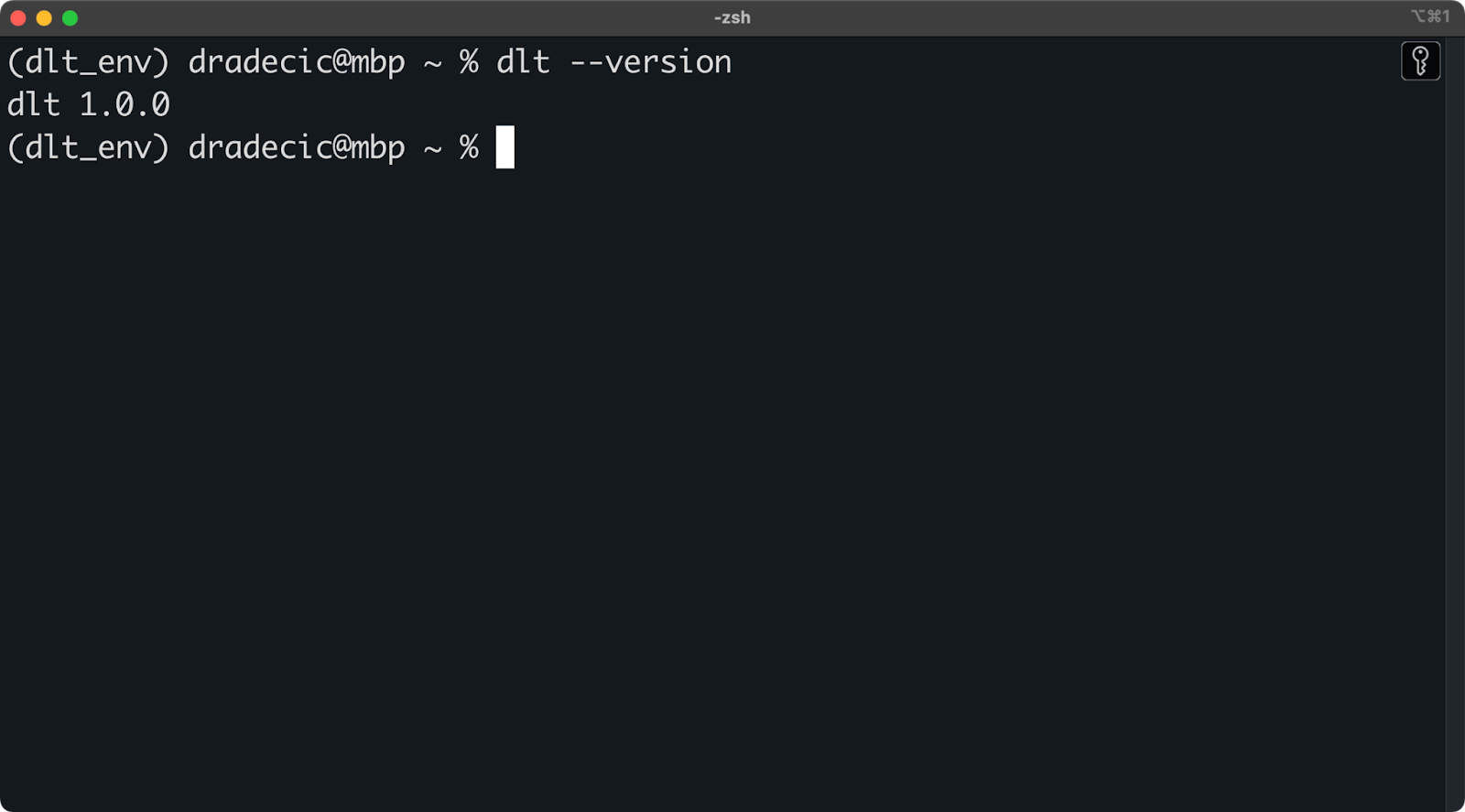
Version de dlt installée
Tant que vous n'obtenez pas de message d'erreur ou de message vous indiquant que dlt n'est pas reconnu, vous pouvez commencer !
Vous pouvez désormais utiliser l'interface de ligne de commande dlt pour créer de nouveaux projets à partir d'un modèle.
Cette opération s'effectue par le biais de la commande dlt init . Dans l'extrait suivant, je vous montre comment créer un pipeline qui utilise une API REST comme source de données et la technologie DuckDB comme destination (cible) :
dlt init rest_api_test duckdb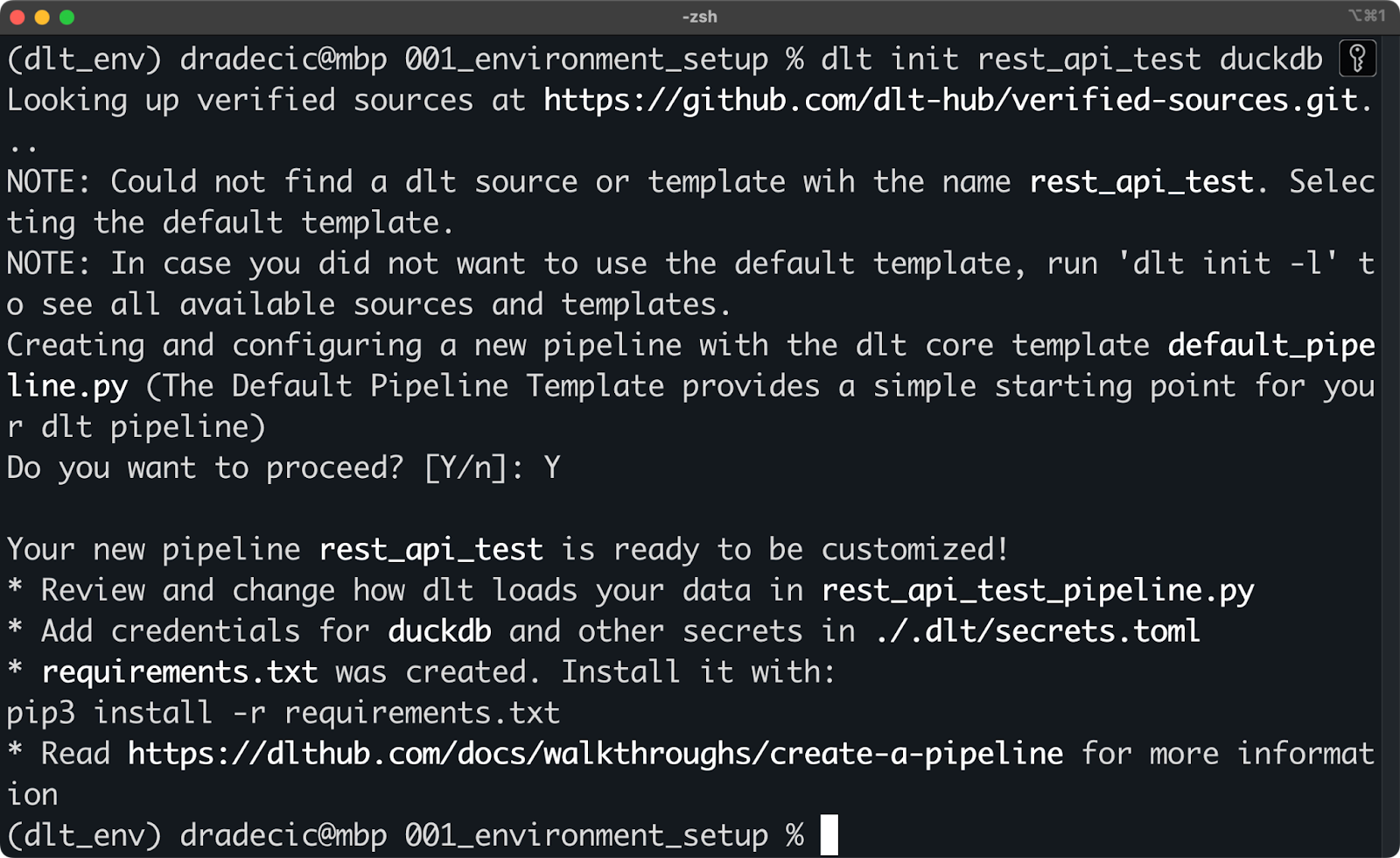
Initialisation d'un nouveau projet dlt avec DuckDB
Rien ne vous empêche de créer les fichiers manuellement - assurez-vous simplement que la structure de vos dossiers ressemble à celle créée par dlt CLI. Par exemple, voici ce que la commande shell précédente a créé sur mon système :
.
├── requirements.txt
├── rest_api_test_pipeline.py
├── .dlt
│ ├── config.toml
│ ├── secrets.tomlLa magie opère dans le dossier .dlt. Il contient deux fichiers qui couvrent tout ce qui concerne laconfiguration du pipeline et les sources et destinations des données, telles que les clés API et les informations d'identification de la base de données.
Le site rest_api_test_pipeline.py est un fichier Python généré automatiquement qui vous montre quelques façons de connecter une API REST à DuckDB.
Pour commencer, vous devez installer tous les éléments énumérés à l'adresse requirements.txt. Pour ce faire, exécutez la commande suivante :
pip install -r requirements.txtUne fois installé, vous êtes prêt à lancer votre premier pipeline dlt!
Voici le contenu du fichier rest_api_test_pipeline.py:
"""The Default Pipeline Template provides a simple starting point for your dlt pipeline"""
# mypy: disable-error-code="no-untyped-def,arg-type"
import dlt
from dlt.common import Decimal
@dlt.resource(name="customers", primary_key="id")
def rest_api_test_customers():
"""Load customer data from a simple python list."""
yield [
{"id": 1, "name": "simon", "city": "berlin"},
{"id": 2, "name": "violet", "city": "london"},
{"id": 3, "name": "tammo", "city": "new york"},
]
@dlt.resource(name="inventory", primary_key="id")
def rest_api_test_inventory():
"""Load inventory data from a simple python list."""
yield [
{"id": 1, "name": "apple", "price": Decimal("1.50")},
{"id": 2, "name": "banana", "price": Decimal("1.70")},
{"id": 3, "name": "pear", "price": Decimal("2.50")},
]
@dlt.source(name="my_fruitshop")
def rest_api_test_source():
"""A source function groups all resources into one schema."""
return rest_api_test_customers(), rest_api_test_inventory()
def load_stuff() -> None:
# specify the pipeline name, destination and dataset name when configuring pipeline,
# otherwise the defaults will be used that are derived from the current script name
p = dlt.pipeline(
pipeline_name='rest_api_test',
destination='duckdb',
dataset_name='rest_api_test_data',
)
load_info = p.run(rest_api_test_source())
# pretty print the information on data that was loaded
print(load_info) # noqa: T201
if __name__ == "__main__":
load_stuff()Laissez-moi d'abord vous expliquer ce que sont les décorateurs, car vous ne les avez sûrement jamais vus auparavant :
@dlt.resource: Utilisé pour créer une ressource générique, par exemple un tableau de base de données avec un nom et un nom de colonne de clé primaire. Vous souhaiterez yield un jeu de données (par exemple, une liste Python, un DataFrame pandas) au lieu de le renvoyer.@dlt.source: Utilisé pour regrouper plusieurs ressources, par exemple, plusieurs tableaux dans un seul schéma de base de données. La fonction doit renvoyer des appels de fonction à vos ressources.Les fonctions Python de ce fichier sont assez simples, mais laissez-moi vous expliquer la logique :
rest_api_test_customers(): Génère des données aléatoires sur le nom et la ville du client.rest_api_test_inventory(): Génère des données aléatoires sur le nom et le prix du produit.rest_api_test_source(): Regroupe les deux ressources précédentes en un seul schéma.load_stuff(): Crée et exécute un pipeline qui déplace des données Python fictives dans une base de données DuckDB.Notez que les données ne sont pas réellement extraites d'une API REST, mais que leur structure ressemble exactement à JSON que n'importe quelle API REST renverrait. Plus loin dans l'article, je vous montrerai comment travailler avec des API réelles.
Pour l'instant, exécutez le pipeline à l'aide de la commande shell suivante :
python rest_api_test_pipeline.py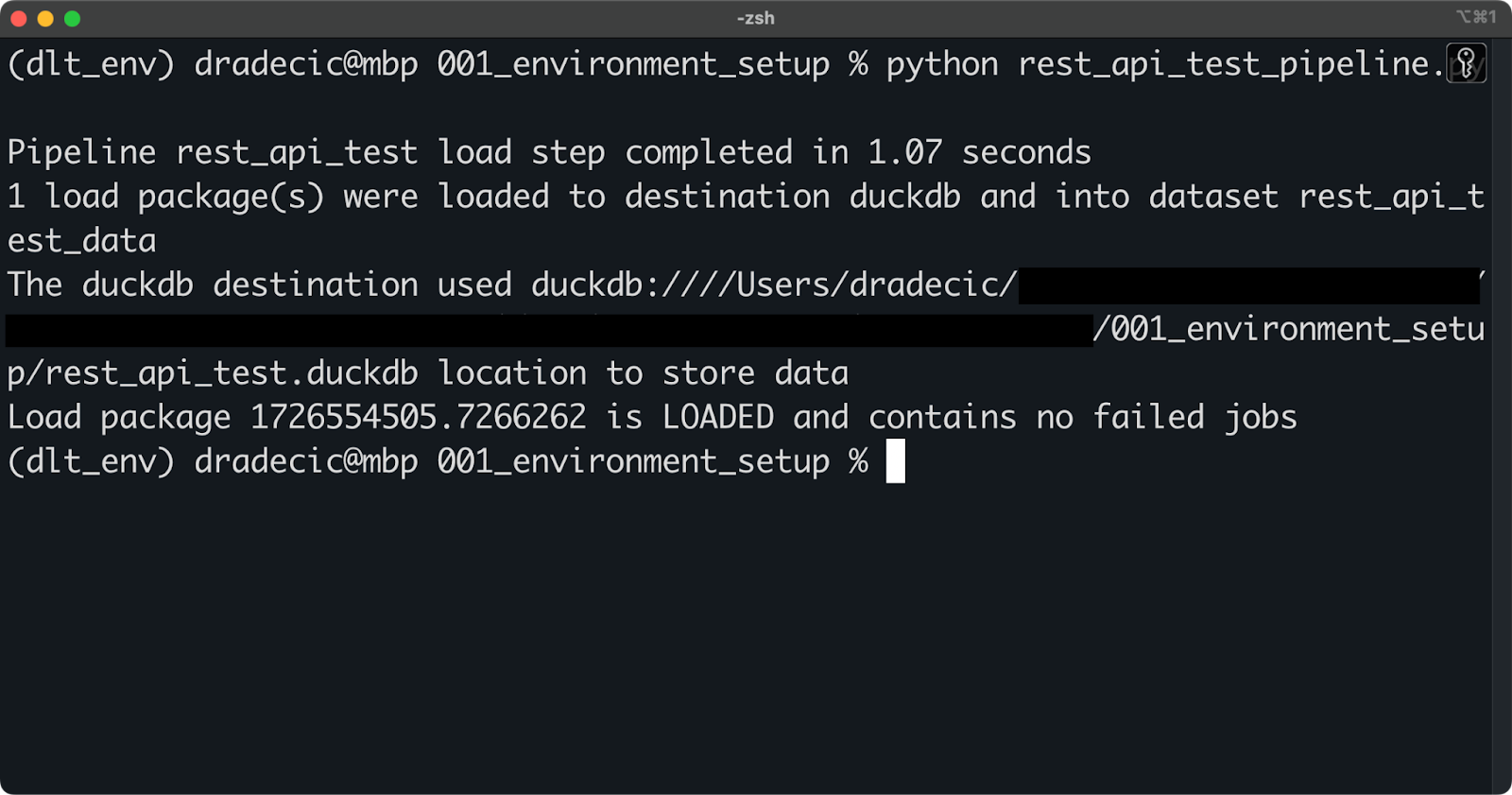
Exploitation de la canalisation
Si vous voyez un message similaire à celui ci-dessus, l'exécution du pipeline s'est déroulée avec succès.
Vous pouvez vous connecter au fichier DuckDB local à l'aide de n'importe quel outil de base de données (j'utilise TablePlus). Une fois sur place, vos données se trouveront dans un schéma spécifié sous le paramètre dataset_name dans dlt.pipeline().
Le tableau customers présente les données générées avec Python, avec l'ajout de deux colonnes de lignage des données :
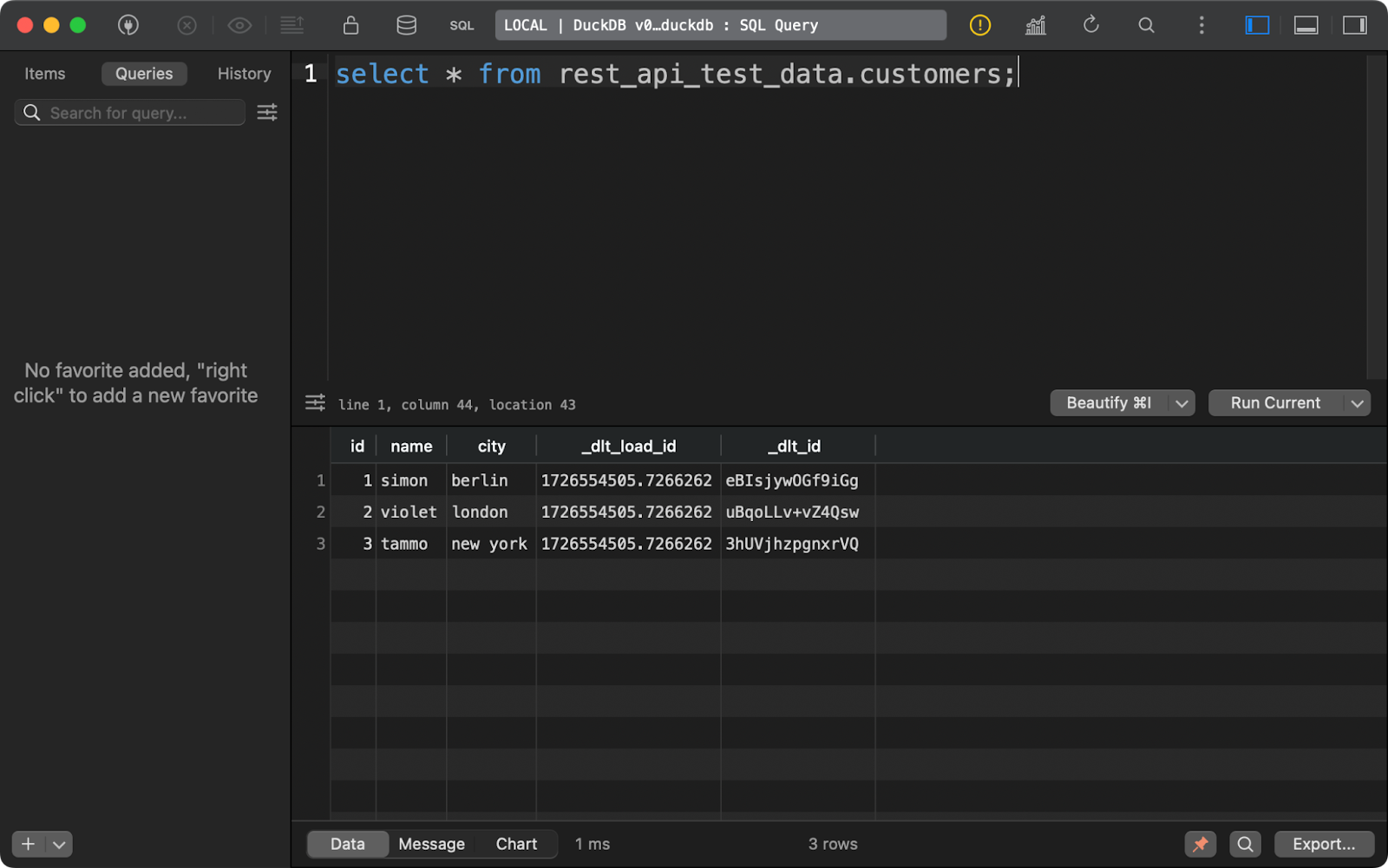
Table des matières des clients
Il en va de même pour le tableau inventory. Notez que la colonne price contient des NULL. Il y a probablement un problème avec le type de données Decimal que dlt utilise par défaut dans cet exemple :
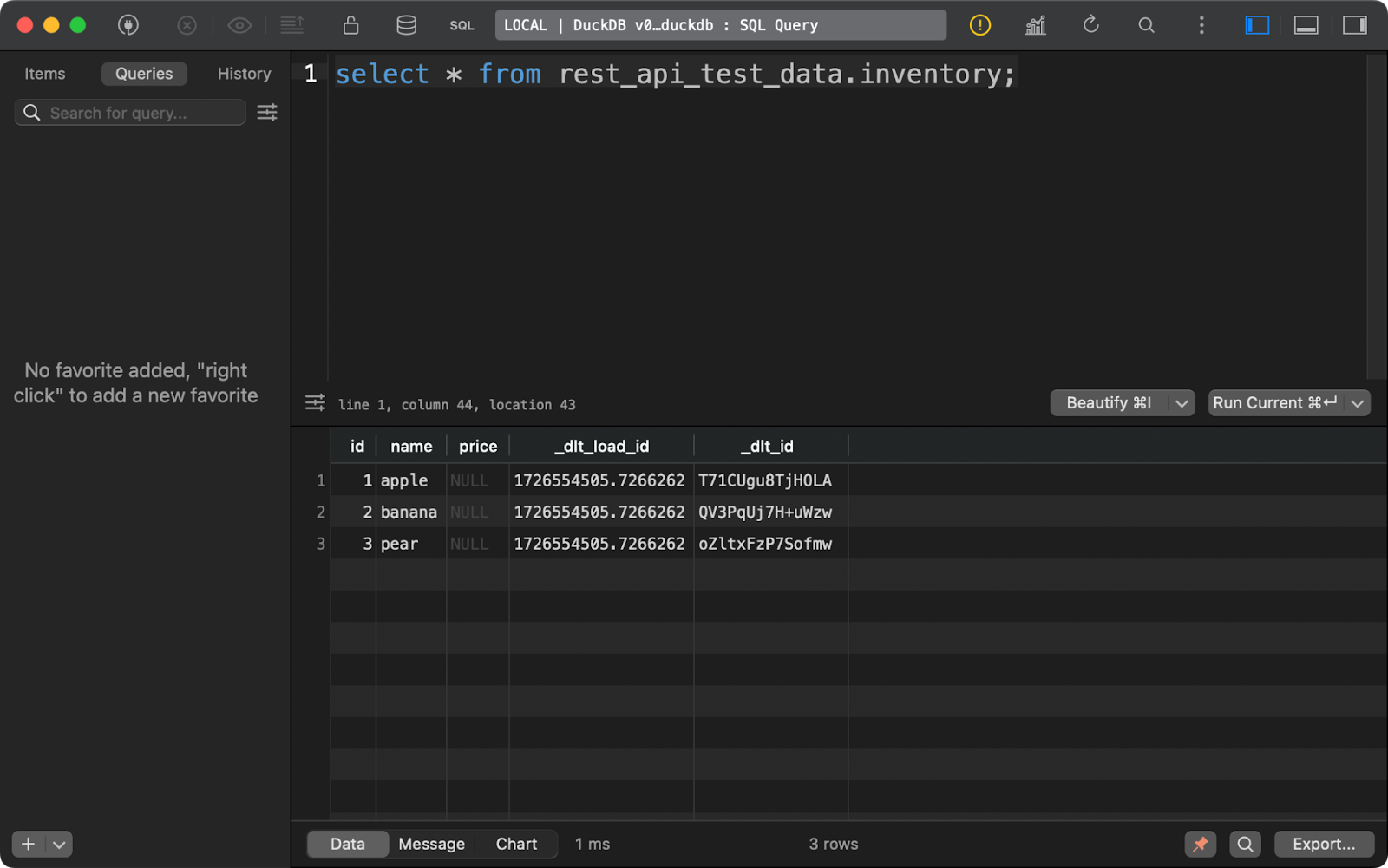
Contenu du tableau d'inventaire
Chaque fois que vous exécutez un pipeline, dlt crée (ou ajoute) trois tableaux de métadonnées.
Le premier, _dlt_loads, retrace l'historique des chargements de données effectués par le pipeline. Il indique notamment le nom du schéma, l'état du chargement et l'heure du chargement :
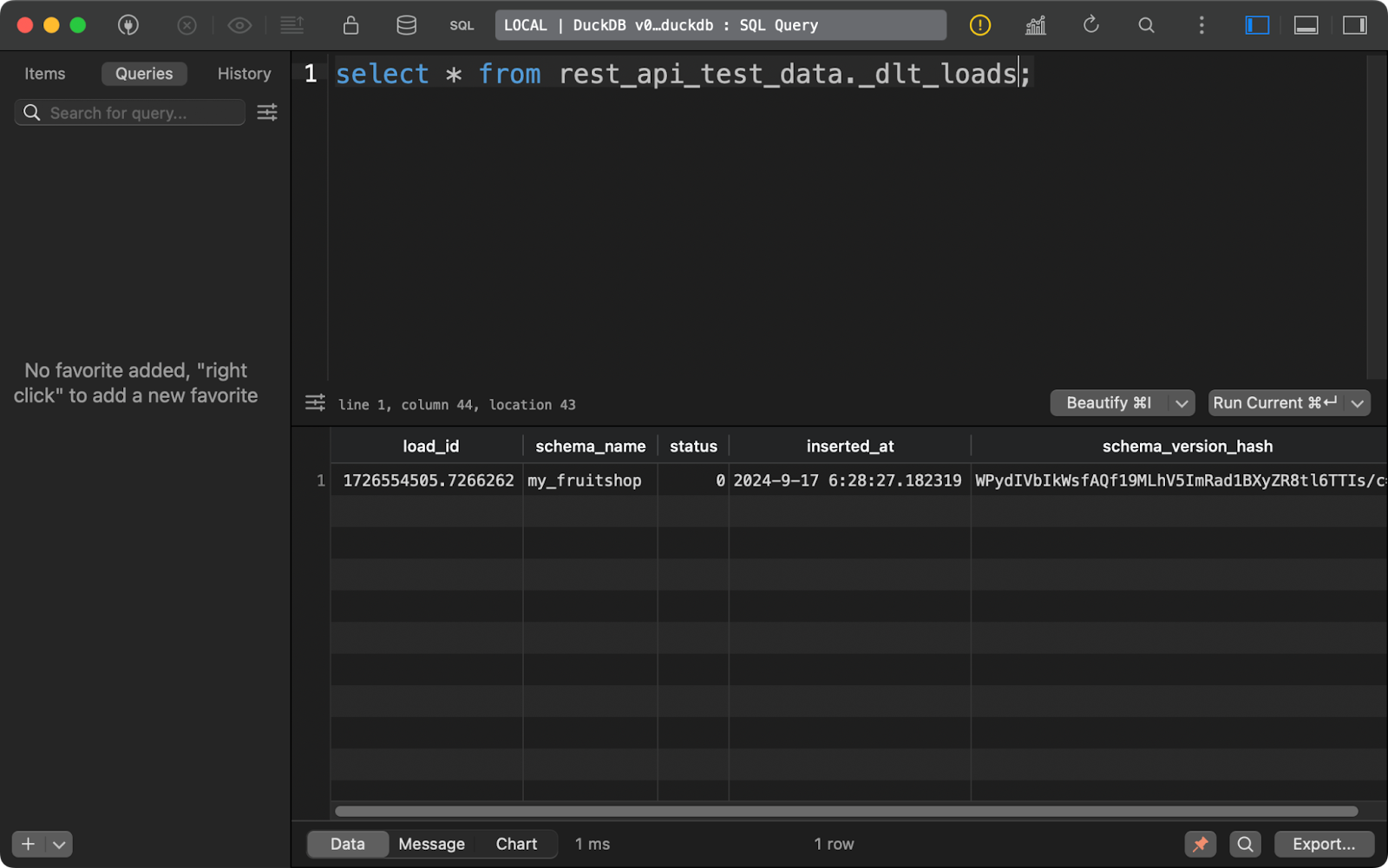
Historique des chargements de données
Le tableau _dlt_pipeline_state présente les détails de la configuration, des points de contrôle et de la progression du pipeline. Il est également utile lorsque votre pipeline s'arrête pour une raison quelconque, car les données de ce tableau peuvent le reprendre là où il s'est arrêté :
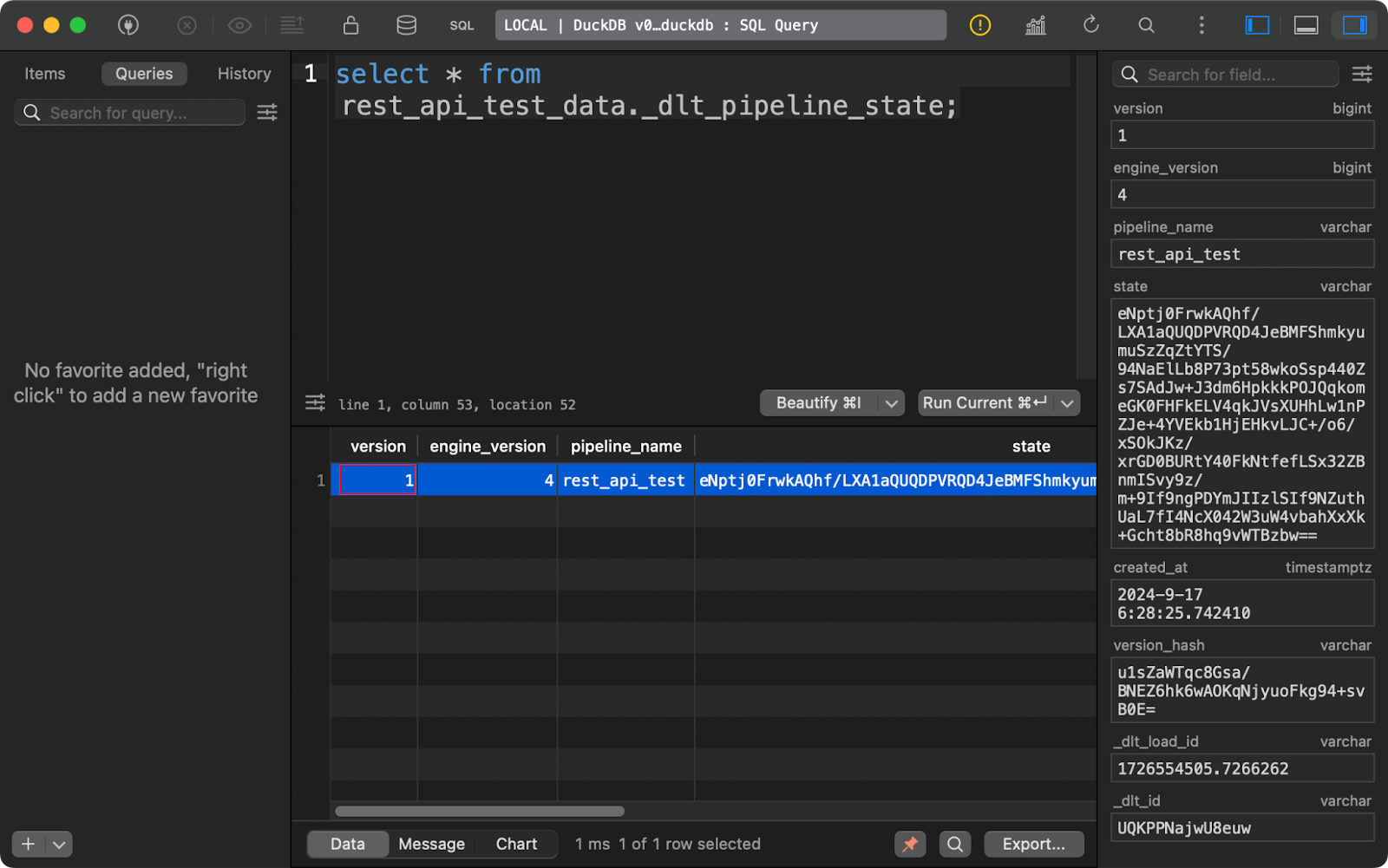
Tableau d'état du pipeline
Enfin, le tableau _dlt_version stocke des informations sur la bibliothèque elle-même afin d'en assurer la compatibilité :
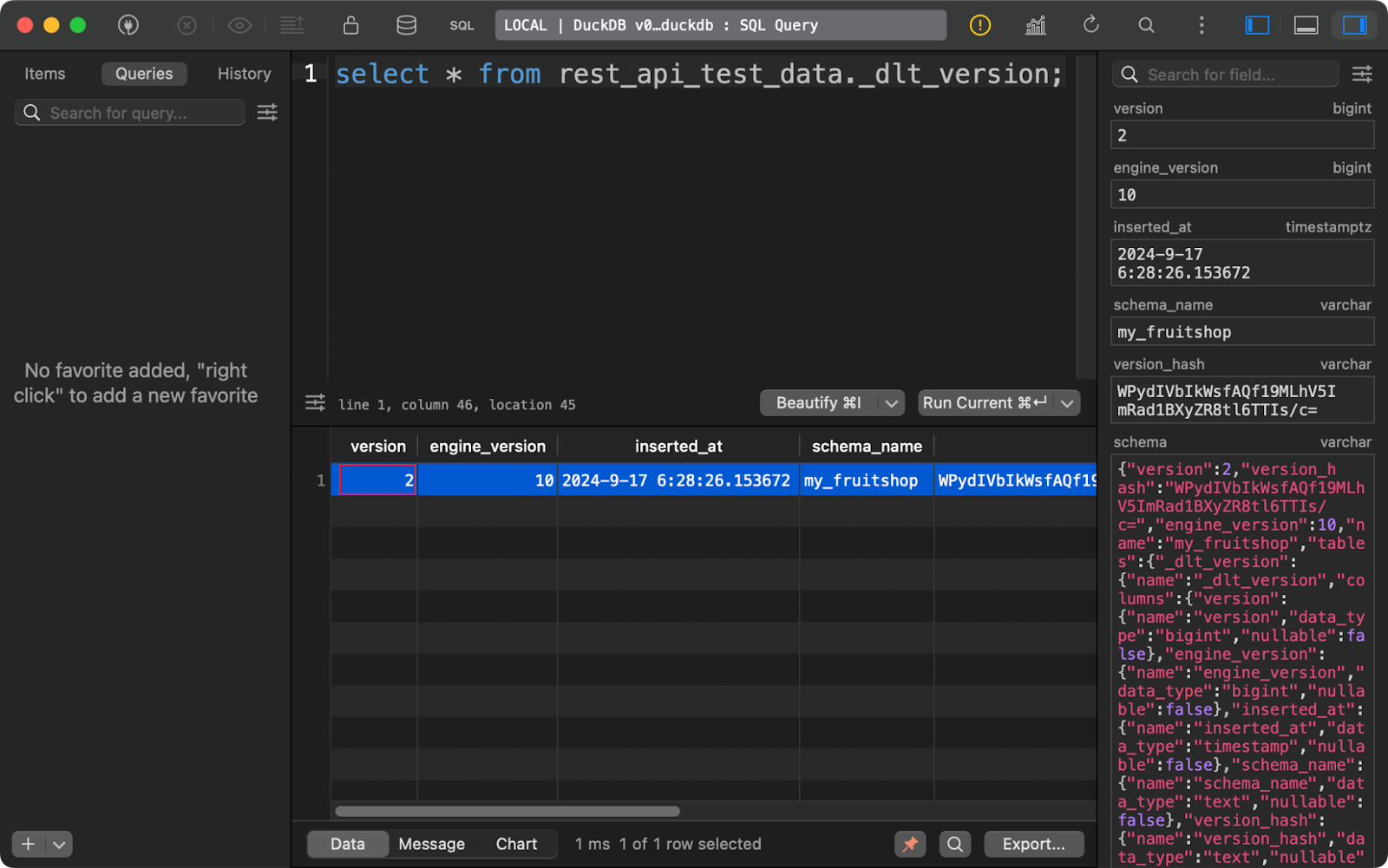
tableau des versions dlt
Lorsqu'ils sont combinés, ces trois tableaux de métadonnées fournissent tous les détails que vous souhaitez suivre au fil du temps pour gérer efficacement vos pipelines de données.
Vous avez maintenant une vue d'ensemble du fonctionnement de dlt. Ensuite, je vous montrerai comment extraire des données de différentes sources.
Dans cette section, j'aborderai quatre types de sources de données:: API REST, bases de données, stockage dans le cloud et système de fichiers local.
Les API REST sont au cœur des sources des pipelines de données. La bibliothèque dlt permet de travailler avec eux sans effort.
Pour la démonstration, j'utiliserai l'API JSONPlaceholder qui a des points de terminaison pour récupérer les messages, les commentaires et les utilisateurs, entre autres choses. Pour ce qui est de la destination des données, j'opterai pour DuckDB, qui ne nécessite aucune configuration.
Pour vous connecter à une API REST, utilisez la fonction rest_api_source(). Vous pouvez fournir un dictionnaire contenant l'URL de l'API de base et les règles de pagination. Vous pouvez ajouter d'autres propriétés, par exemple pour l'authentification , mais l'API que j'ai choisie est accessible au public et n'est donc pas nécessaire.
La partie intéressante vient de la propriété resources. Ici, vous fournirez une liste de points d'accès à partir desquels dlt doit récupérer les données. Par exemple, la ressource posts se connectera à https://jsonplaceholder.typicode.com/posts. Vous pouvez modifier les ressources individuelles de manière beaucoup plus approfondie, mais je vous laisse le soin de le faire.
Le reste de ce fichier Python reste plus ou moins inchangé :
import dlt
from dlt.sources.rest_api import rest_api_source
def load_rest_api_data() -> None:
data_source = rest_api_source({
"client": {
"base_url": "https://jsonplaceholder.typicode.com/",
"paginator": {
"type": "json_response",
"next_url_path": "paging.next"
}
},
"resources": [
"posts",
"comments",
"users"
]
})
pipeline = dlt.pipeline(
pipeline_name="rest_api_jsonplaceholder",
destination="duckdb",
dataset_name="jsonplaceholder"
)
load_info = pipeline.run(data_source)
print(load_info)
if __name__ == "__main__":
load_rest_api_data()Après avoir exécuté le pipeline, vous verrez trois tableaux de données, un pour chaque ressource spécifiée.
La première montre des postes fictifs :
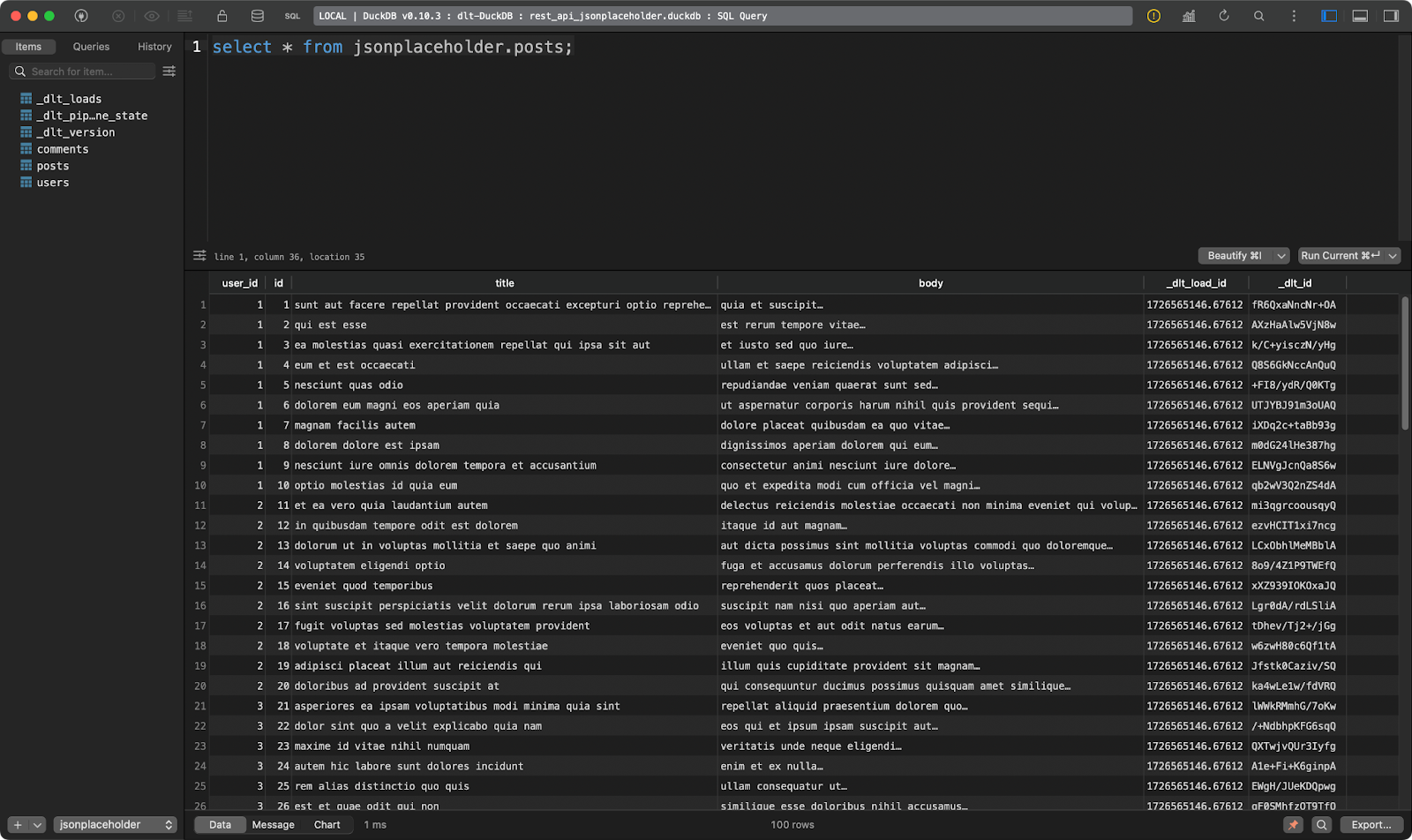
Tableau des postes
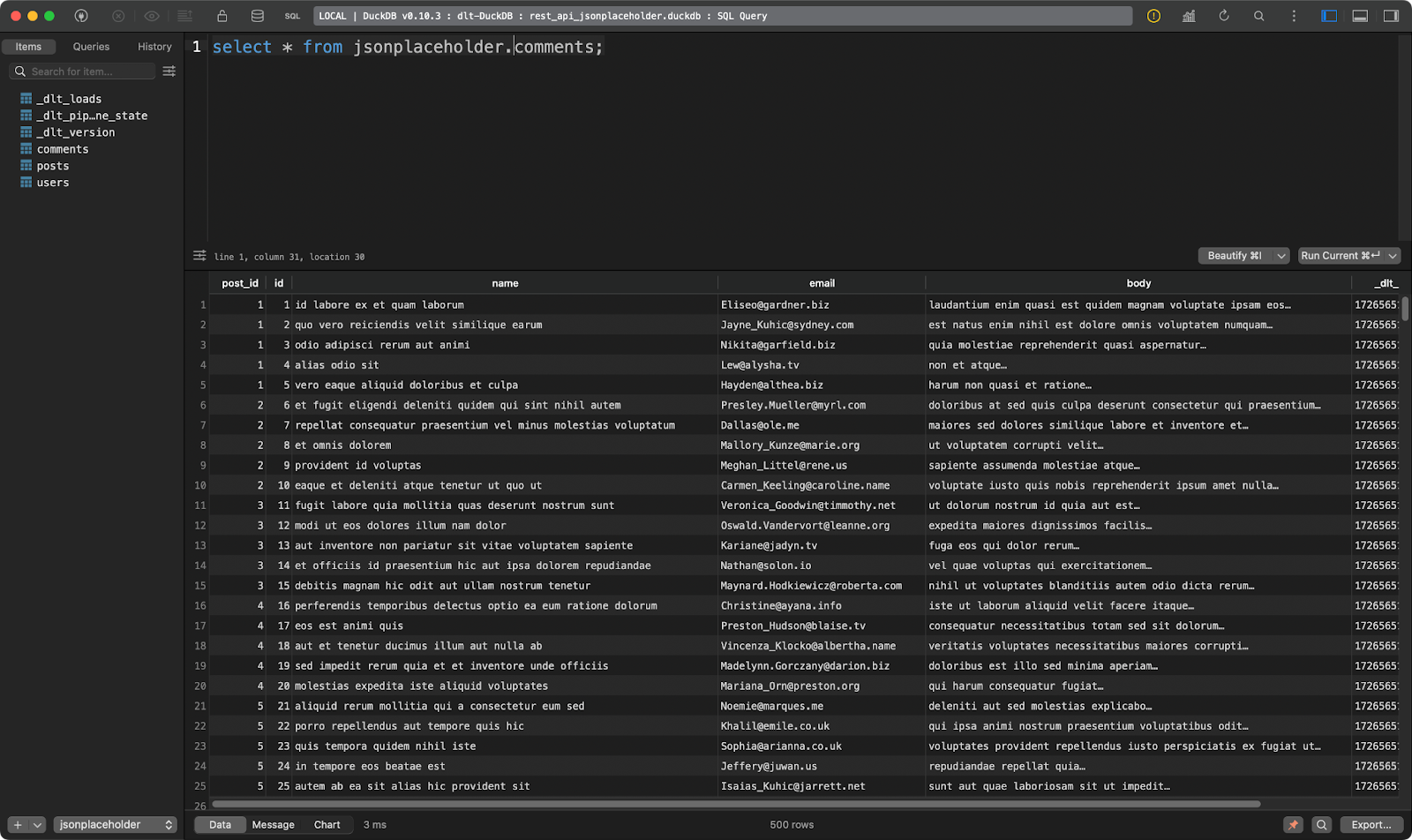
La seconde affiche les commentaires des messages :
Tableau des commentaires
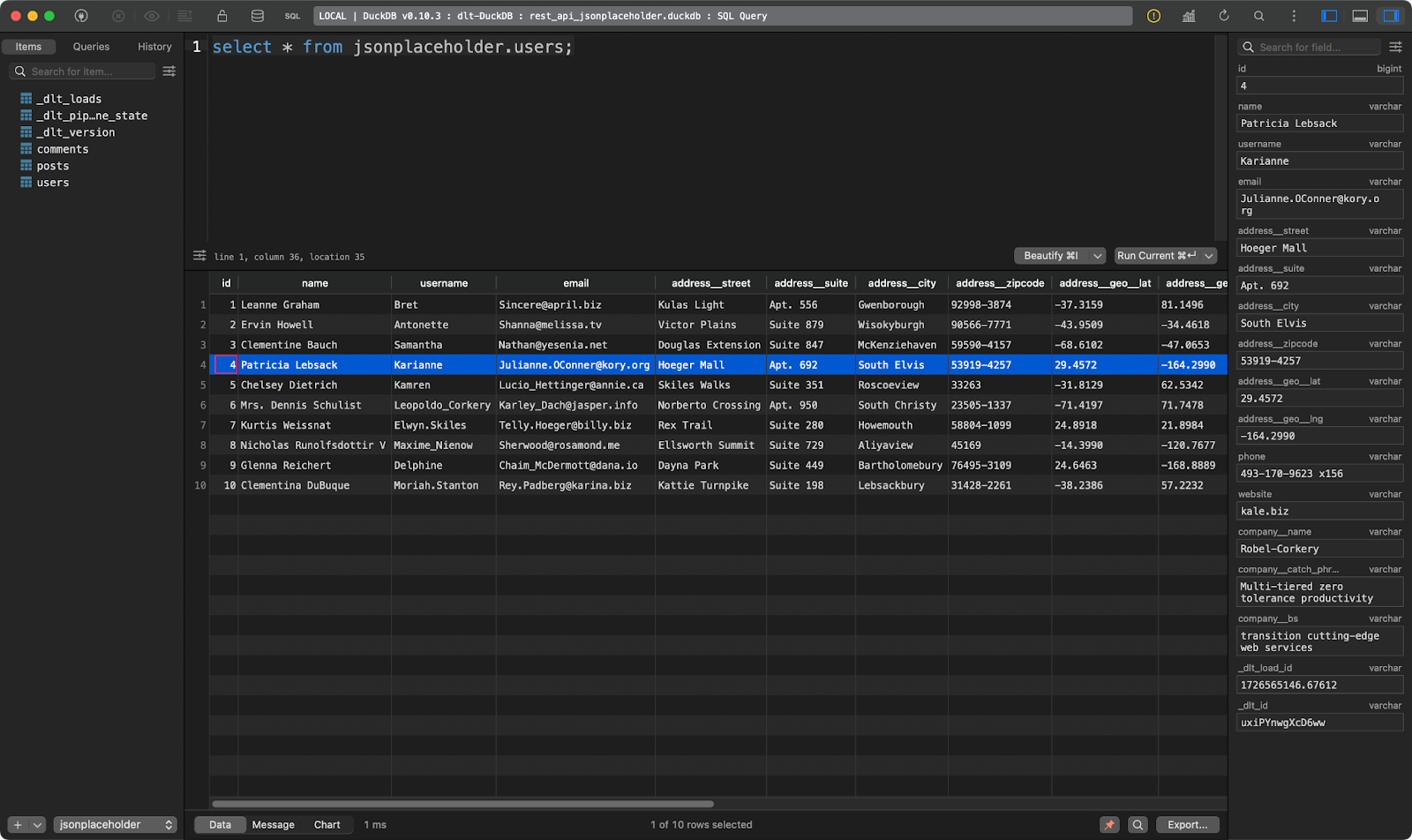
La troisième montre les utilisateurs. Celui-ci est intéressant car il contient des données JSON imbriquées. La bibliothèque dlt l'a aplati, de sorte qu'il peut être stocké sans problème dans un tableau unique :
users tableau
Sympathique, non ? Vous ne devez plus analyser JSON manuellement.
S'il existe une source de données plus couramment utilisée que les API REST, c'est bien une base de données relationnelle.
Pour les besoins de la démonstration, j'ai provisionné une base de données Postgres libre sur AWS :
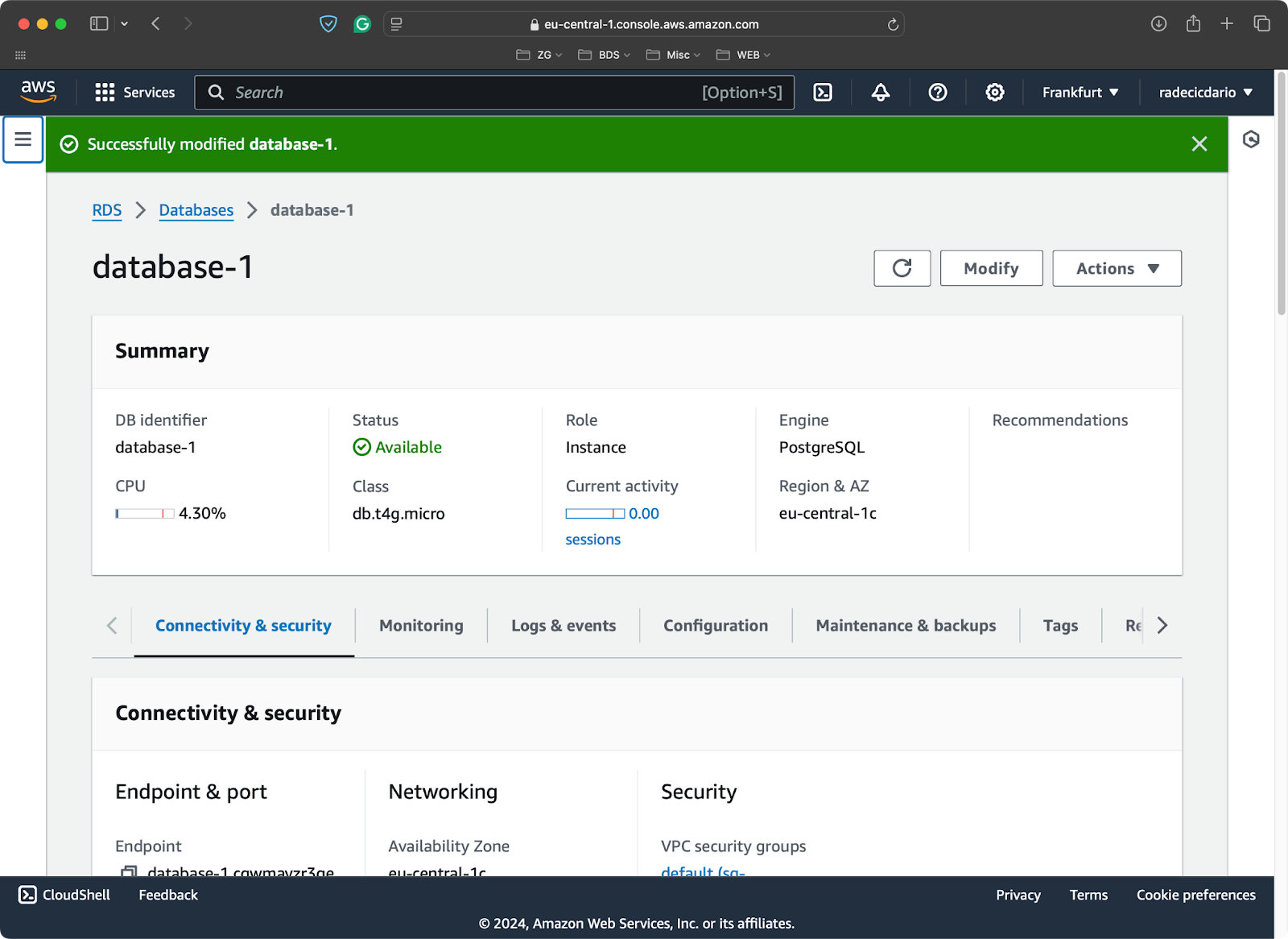
Base de données PostgreSQL sur AWS
et y a chargé l'ensemble de données Iris bien connu sous la forme d'un tableau :
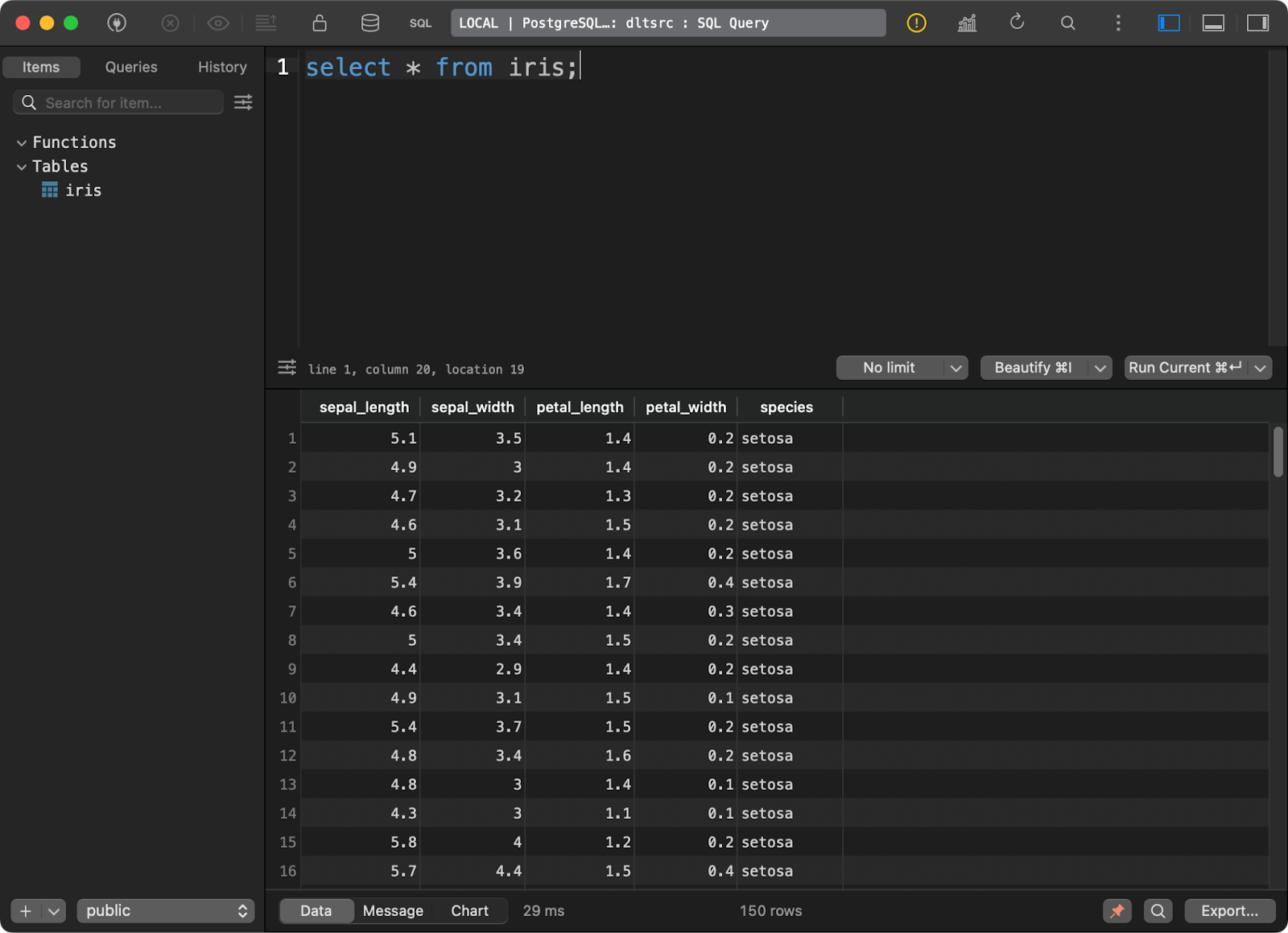
Données dans la base de données Postgres
Je vais maintenant vous montrer comment vous connecter à une source Postgres à partir de dlt. Il s'agit d'un processus plus complexe que vous ne le pensez à première vue.
Commencez par installer un sous-module pour travailler avec des bases de données SQL :
pip install "dlt[sql_database]"Ensuite, initialisez un pipeline qui utilise une base de données SQL générique comme source et DuckDB comme destination :
dlt init sql_database duckdbC'est la première fois que vous manipulez les fichiers du dossier .dtl. Dans config.toml, indiquez le nom du tableau source à partir duquel vous souhaitez extraire les données :
[sources.sql_database]
table = "table" # please set me up!
[runtime]
dlthub_telemetry = trueRemplacez ”table” par “iris” et vous serez prêt.
Dans secrets.toml, vous devrez spécifier les paramètres de connexion à la base de données source. Notez que vous devez absolument ajouter le nom [sources.sql_database.credentials] avant de spécifier les paramètres de connexion. Sinon, dlt ne saura pas à quoi ils font référence :
[sources.sql_database.credentials]
drivername = "drivername" # please set me up!
database = "database" # please set me up!
password = "password" # please set me up!
username = "username" # please set me up!
host = "host" # please set me up!
port = 0 # please set me up!Et c'est tout pour la configuration. Vous pouvez maintenant passer au fichier pipeline Python.
En bref, il vous suffit d'appeler la fonction sql_database() pour vous connecter à la base de données et extraire les données sources. Chaque détail de la configuration est spécifié dans les fichiers TOML, vous pouvez donc appeler cette fonction sans aucun paramètre.
Le reste du scénario n'apporte rien de nouveau :
import dlt
from dlt.sources.sql_database import sql_database
def load_database_data() -> None:
source = sql_database()
pipeline = dlt.pipeline(
pipeline_name="postgres_to_duckdb_pipeline",
destination="duckdb",
dataset_name="iris_from_postgres"
)
load_info = pipeline.run(source)
print(load_info)
if __name__ == "__main__":
load_database_data()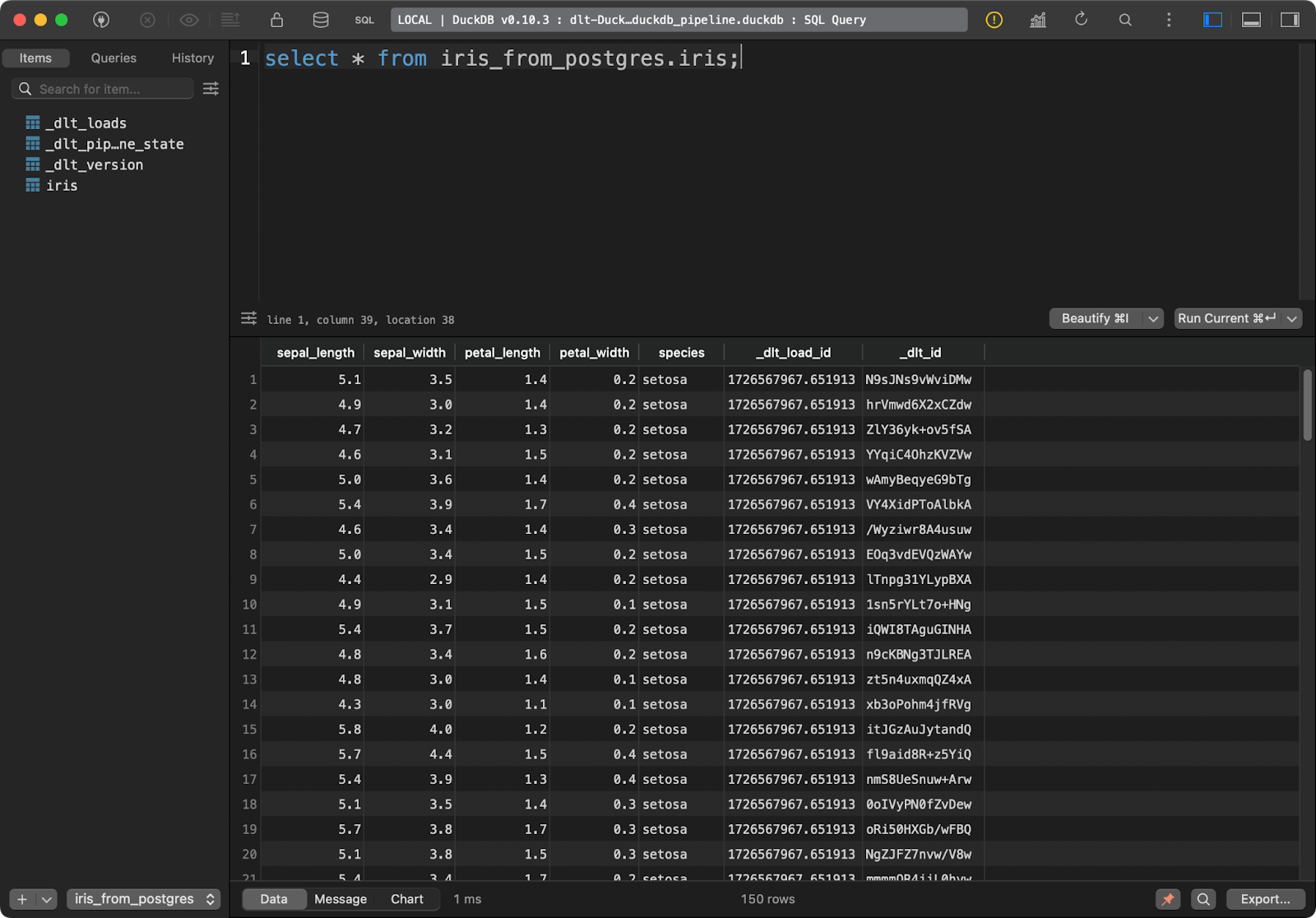
Tableau Iris
Le tableau cible dans DuckDB contient toutes les données Iris avec les deux colonnes supplémentaires de lignage des données.
Le plus souvent, vous voudrez que vos pipelines se connectent au stockage dans le cloud, comme les buckets AWS S3.
J'ai créé un seau S3 pour les besoins de cet article et j'ai téléchargé un fichier Parquet unique contenant des ensembles de données provenant du projet trajets en taxi à New York:
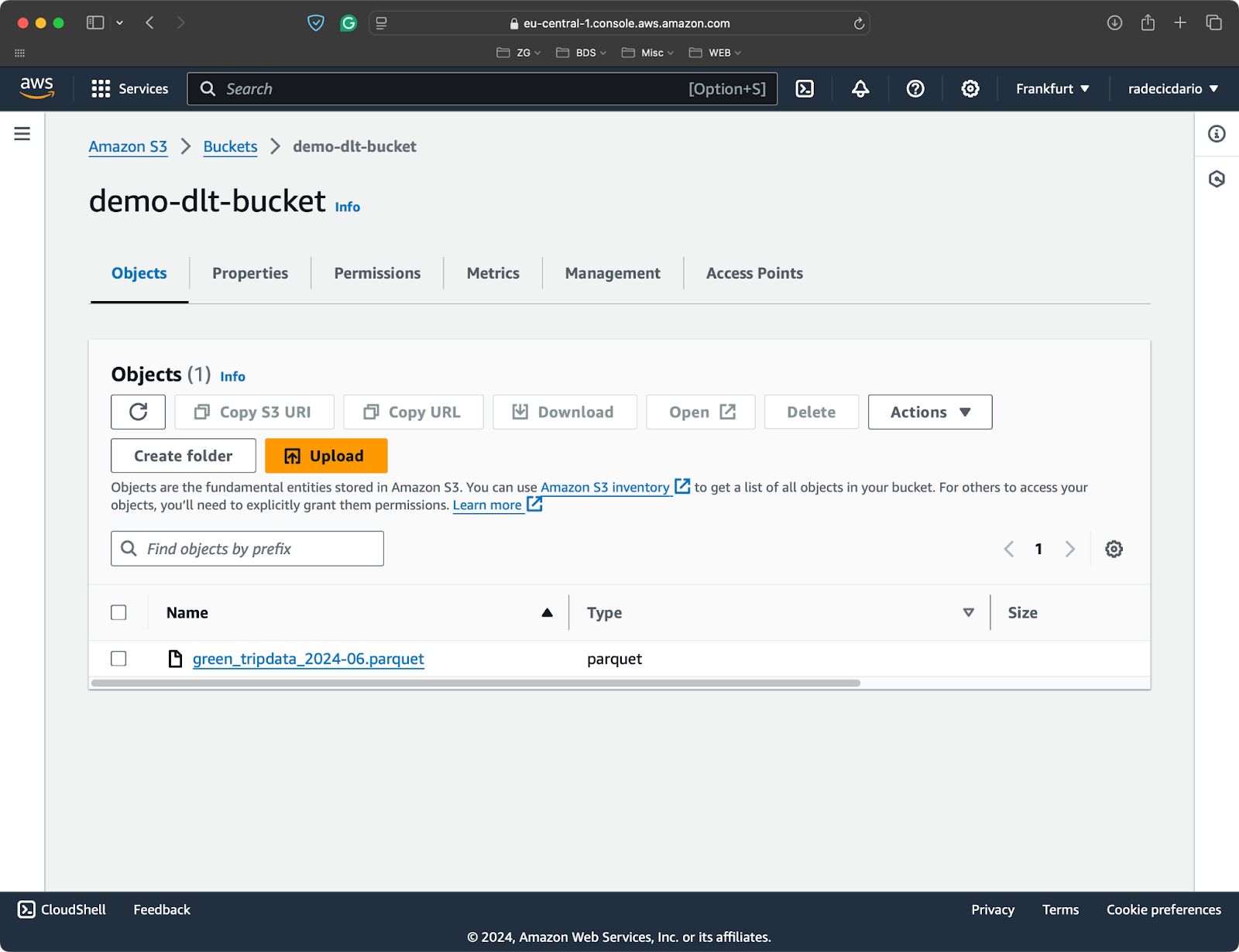
Un fichier S3 avec un seul fichier Parquet
Pour connecter un système de fichiers local ou distant à dlt, vous devez installer un sous-module supplémentaire :
pip install "dlt[filesystem]"Vous pouvez maintenant initialiser un nouveau pipeline qui utilise un système de fichiers comme source et DuckDB comme destination :
dlt init filesystem duckdbLa première chose à faire est de remplir les fichiers de configuration. Le fichier config.toml doit contenir l'URL complète de votre panier S3 :
[sources.filesystem]
bucket_url = "bucket_url" # please set me up!
[runtime]
dlthub_telemetry = trueLe fichier secrets.toml a besoin d'informations sur votre rôle IAM (clé d'accès et clé d'accès secrète), ainsi que sur la région dans laquelle votre bucket est provisionné :
[sources.filesystem.credentials]
aws_access_key_id = "aws_access_key_id" # please set me up!
aws_secret_access_key = "aws_secret_access_key" # please set me up!
region_name = "region_name" # please set me up!Passons au code du pipeline.
Utilisez la fonction readers() pour lire les données de la source configurée. Le paramètre file_glob détermine les fichiers à lire. Je l'ai configuré de manière à ce que renvoie tous les fichiers Parquet. Il suffit ensuite d'enchaîner la fonction read_parquet() pour lire les données :
import dlt
from dlt.sources.filesystem import readers, read_parquet
def load_s3_data() -> None:
source = readers(file_glob="*.parquet").read_parquet()
pipeline = dlt.pipeline(
pipeline_name="s3_to_duckdb_pipeline",
destination="duckdb",
dataset_name="nyc_data_from_s3"
)
load_info = pipeline.run(source.with_name("nyc_taxi_data"))
print(load_info)
if __name__ == "__main__":
load_s3_data()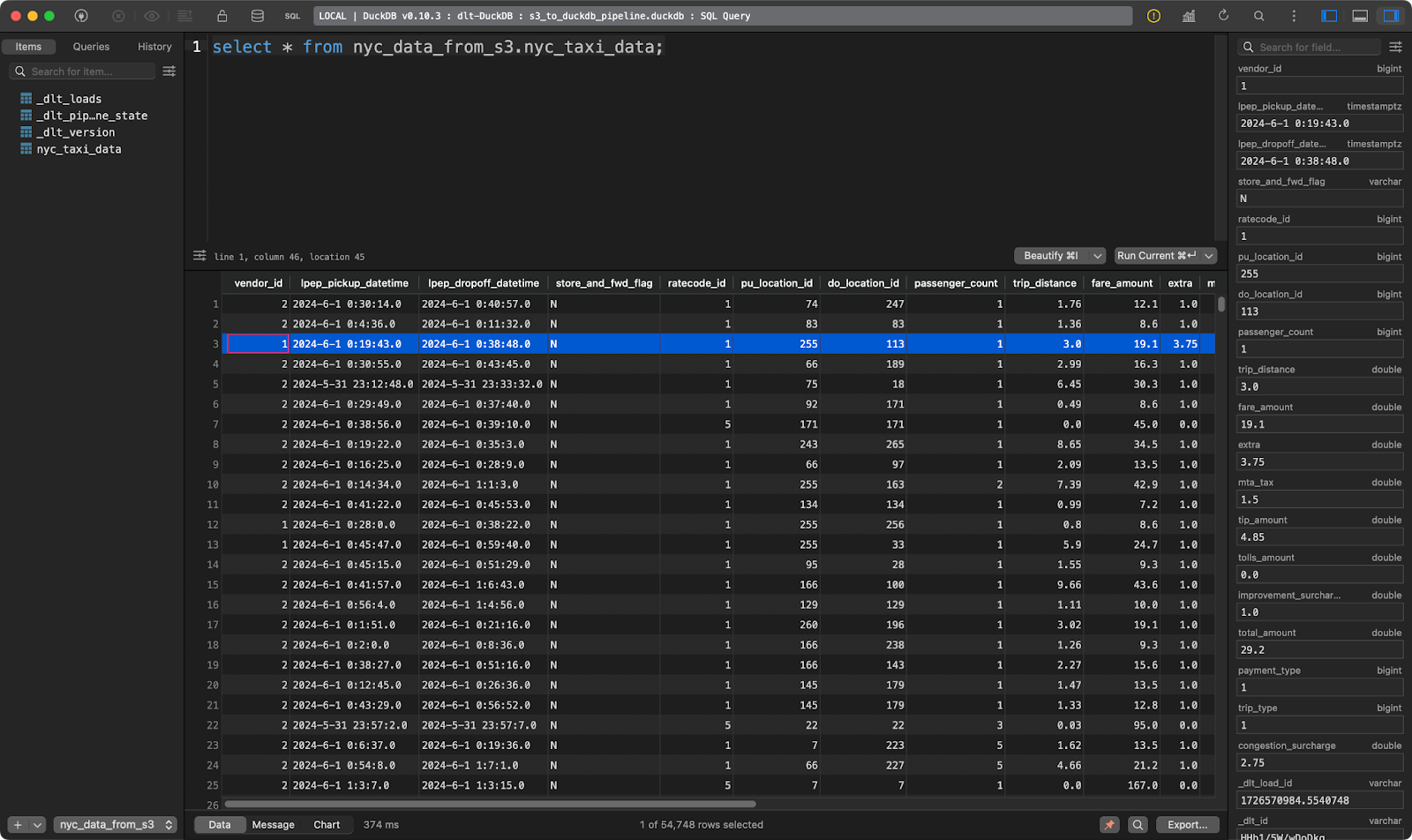
Tableau des courses de taxi à NYC
Et voilà, des dizaines de milliers d'enregistrements sont chargés en quelques secondes !
La lecture de données à partir d'un système de fichiers local est presque identique à la lecture de données à partir de S3.
Cette fois, j'utilise le jeu de données mtcars dataset enregistré localement dans un dossier localbucket:
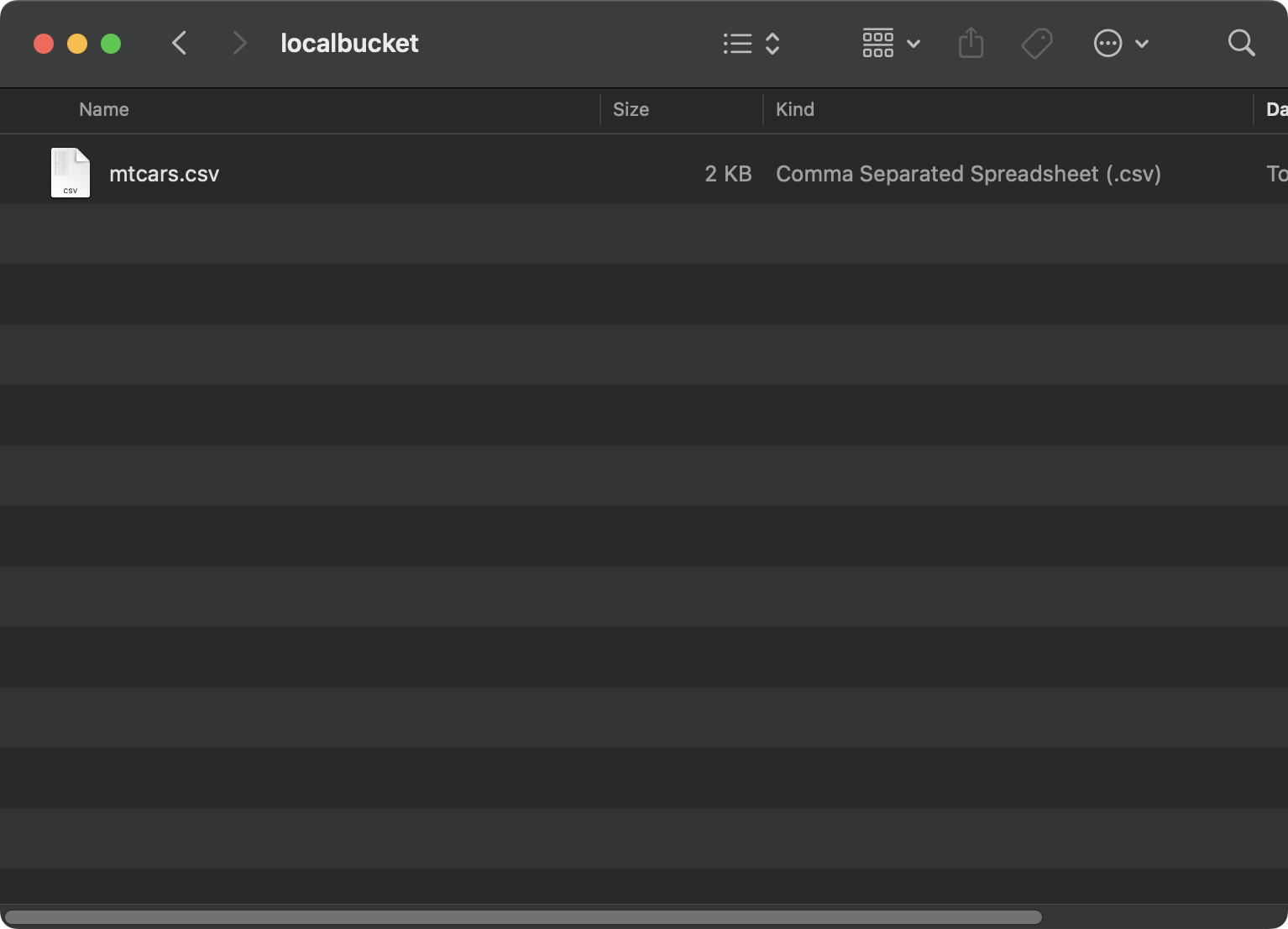
Fichier sur un système local
Dans votre fichier config.toml, indiquez un chemin absolu vers votre dossier local. Il est important de préfixer le chemin par file:///. Cela fait trois entailles :
[sources.filesystem]
bucket_url = "file:///absolute/path/to/local/folder"
[runtime]
dlthub_telemetry = truePuisque vous ne vous connectez plus à S3, vous pouvez supprimer le contenu de secrets.toml.
Le code de l'oléoduc sera presque identique à celui de la section précédente. Le seul changement est que dans file_glob vous fournissez maintenant un nom de fichier et que vous utilisez une fonction différente pour lire les données (format CSV) :
import dlt
from dlt.sources.filesystem import filesystem, read_csv_duckdb
def load_local_data() -> None:
source = filesystem(file_glob="mtcars.csv") | read_csv_duckdb()
pipeline = dlt.pipeline(
pipeline_name="local_filesystem_to_duckdb_pipeline",
destination="duckdb",
dataset_name="mtcars_data_from_local_disk"
)
load_info = pipeline.run(source.with_name("mtcars"))
print(load_info)
if __name__ == "__main__":
load_local_data()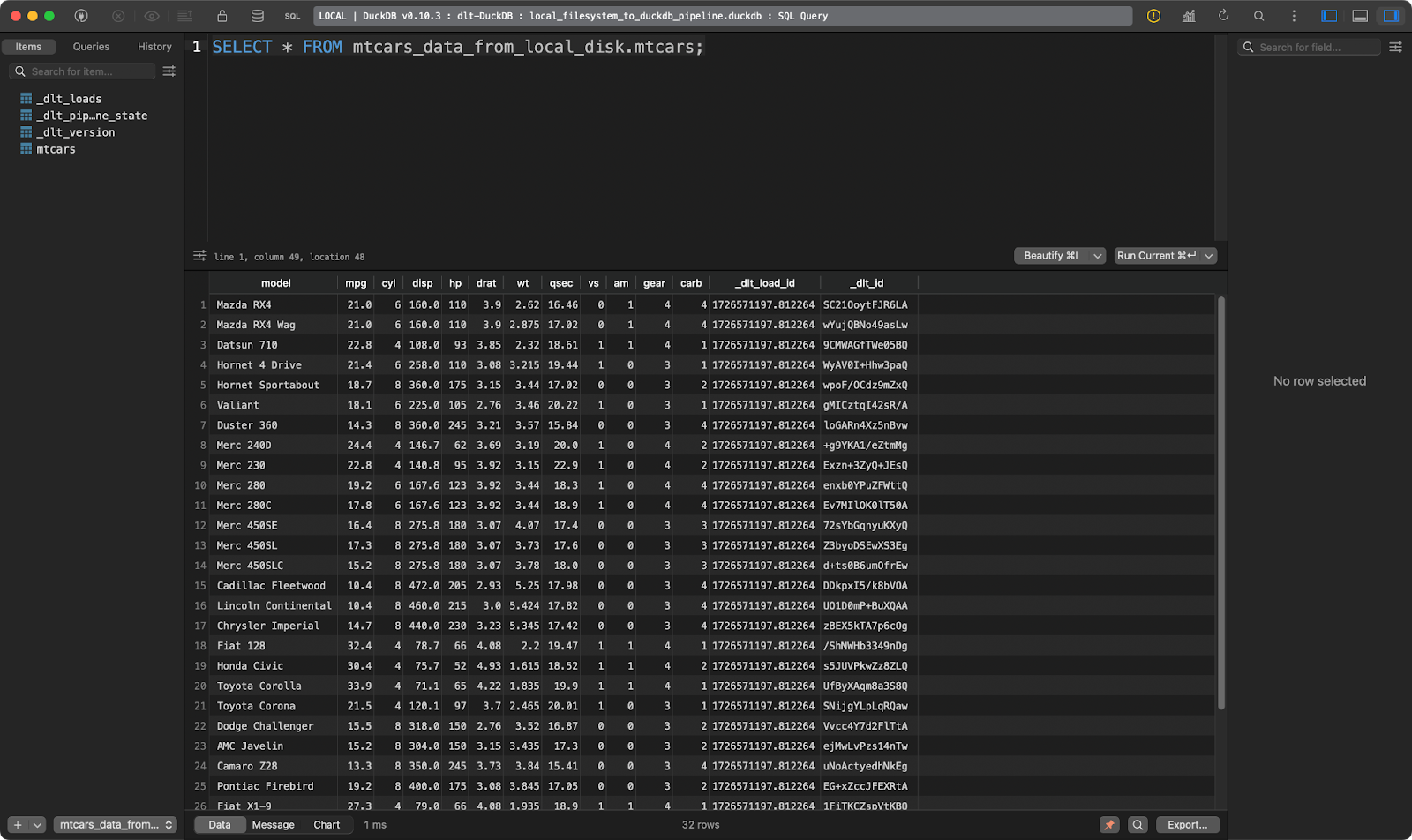
Le tableau mtcars
Fonctionne comme un charme !
C'est tout ce que je voulais vous montrer concernant les sources de données. Vous pouvez en trouver de nombreuses autres pour répondre à vos besoins spécifiques surdans la page de documentation dlt pour les sources de données.
Il ne suffit pas de déplacer des données d'un point A à un point B. Vous souhaitez généralement appliquer une transformation avant d'écrire les données vers la destination (ETL) ou après (ELT).
Si les acronymes ETL et ELT ne vous disent rien, nous vous recommandons de suivrenotre cours sur le pipeline de données avec Python.
Dans cette section, je vais vous montrer comment appliquer des transformations à vos données avec SQL et Python.
Les ingénieurs de données vivent et respirent SQL. Dans cette section, je vous montrerai comment charger un fichier local dans une base de données Postgres, le transformer et l'écrire à nouveau dans un autre tableau (ELT).
Commencez par modifier le fichier secrets.toml afin d'inclure les détails de connexion à la base de données pour la source et la destination. Les valeurs seront identiques, il suffit de les spécifier deux fois :
[sources.sql_database.credentials]
drivername = "drivername" # please set me up!
database = "database" # please set me up!
password = "password" # please set me up!
username = "username" # please set me up!
host = "host" # please set me up!
port = 0 # please set me up!
[destinations.sql_database.credentials]
drivername = "drivername" # please set me up!
database = "database" # please set me up!
password = "password" # please set me up!
username = "username" # please set me up!
host = "host" # please set me up!
port = 0 # please set me up!À l'intérieur de config.toml, écrivez un chemin absolu vers un dossier situé sur votre système de fichiers :
[sources.filesystem]
bucket_url = "file:///absolute/path/to/local/folder"
[runtime]
dlthub_telemetry = trueLe fichier pipeline de Python aura deux fonctions :
load_source_data(): Il charge un fichier CSV local et l'enregistre dans un tableau d'une base de données Postgres.transform_data(): Il extrait les données d'un tableau Postgres et crée un nouveau tableau sur la base du tableau d'origine. Je n'ajouterai que quelques colonnes pour prouver ce que j'avance. Le tableau cible est d'abord supprimé s'il existe.Vous devez appeler les fonctions l'une après l'autre :
import dlt
from dlt.sources.filesystem import filesystem, read_csv
def load_source_data() -> None:
source = filesystem(file_glob="iris.csv") | read_csv()
pipeline = dlt.pipeline(
pipeline_name="load_source_data",
destination="postgres",
dataset_name="data"
)
load_info = pipeline.run(source.with_name("iris_src"), write_disposition="replace")
print(load_info)
def transform_data() -> None:
pipeline = dlt.pipeline(
pipeline_name="transform_data",
destination="postgres",
dataset_name="data"
)
try:
with pipeline.sql_client() as client:
client.execute_sql("""
DROP TABLE iris_tgt;
""")
print(f"Table iris_tgt deleted!")
except Exception as e:
print(f"Table iris_tgt does not exists, proceeding!")
try:
with pipeline.sql_client() as client:
client.execute_sql("""
CREATE TABLE iris_tgt AS (
SELECT
sepal_length,
sepal_width,
petal_length,
petal_width,
sepal_length + sepal_width AS total_sepal,
petal_length + petal_width AS total_petal,
UPPER(species) AS species_upper
FROM iris_src
);
""")
print(f"Table iris_tgt created and filled!")
except Exception as e:
print(f"Unable to transform data! Error: {str(e)}")
if __name__ == "__main__":
load_source_data()
transform_data()Le tableau source contient l'ensemble de données Iris avec deux colonnes supplémentaires de lignage des données :
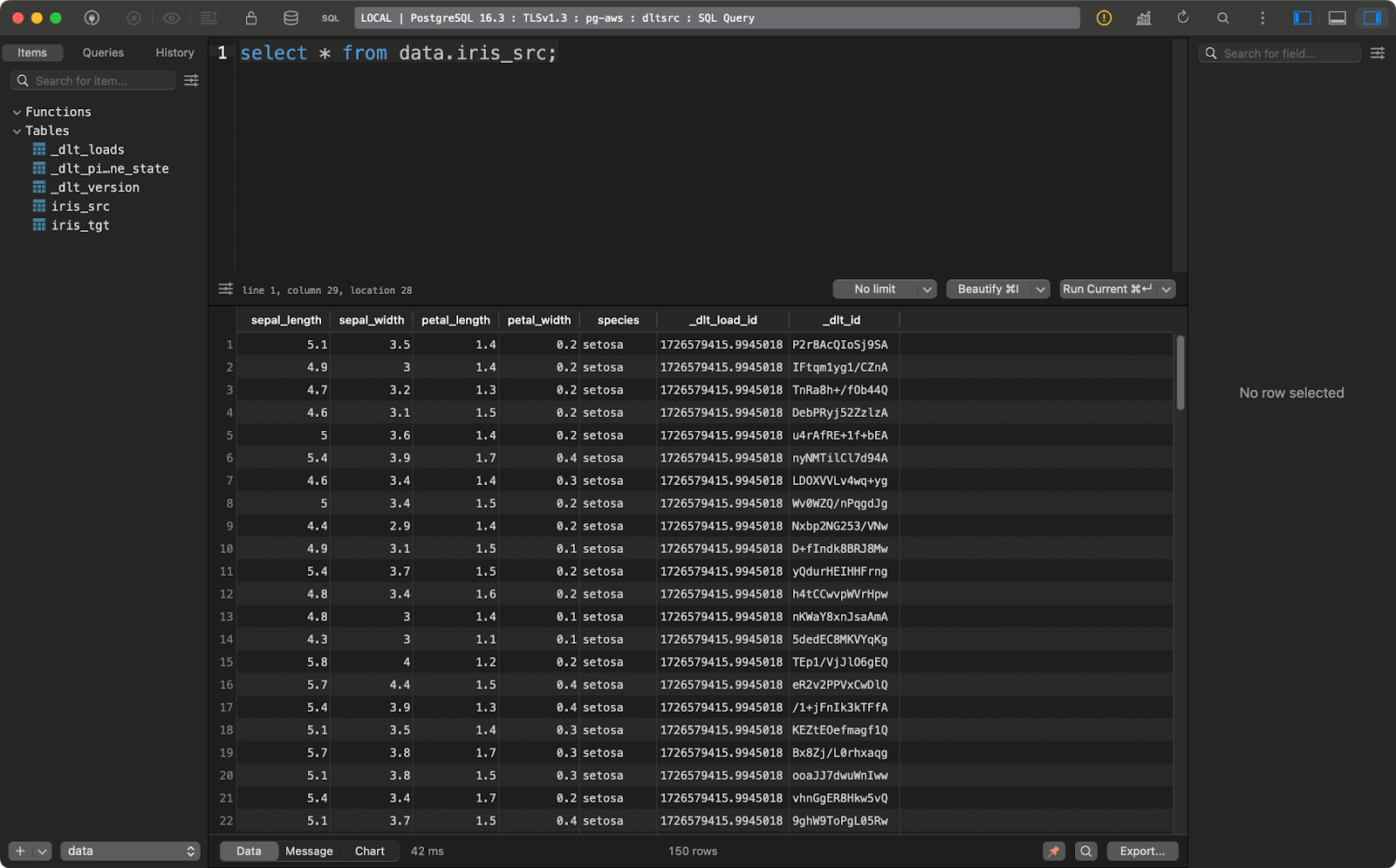
Tableau des sources d'iris
Le tableau cible contient la version transformée de l'ensemble de données Iris :
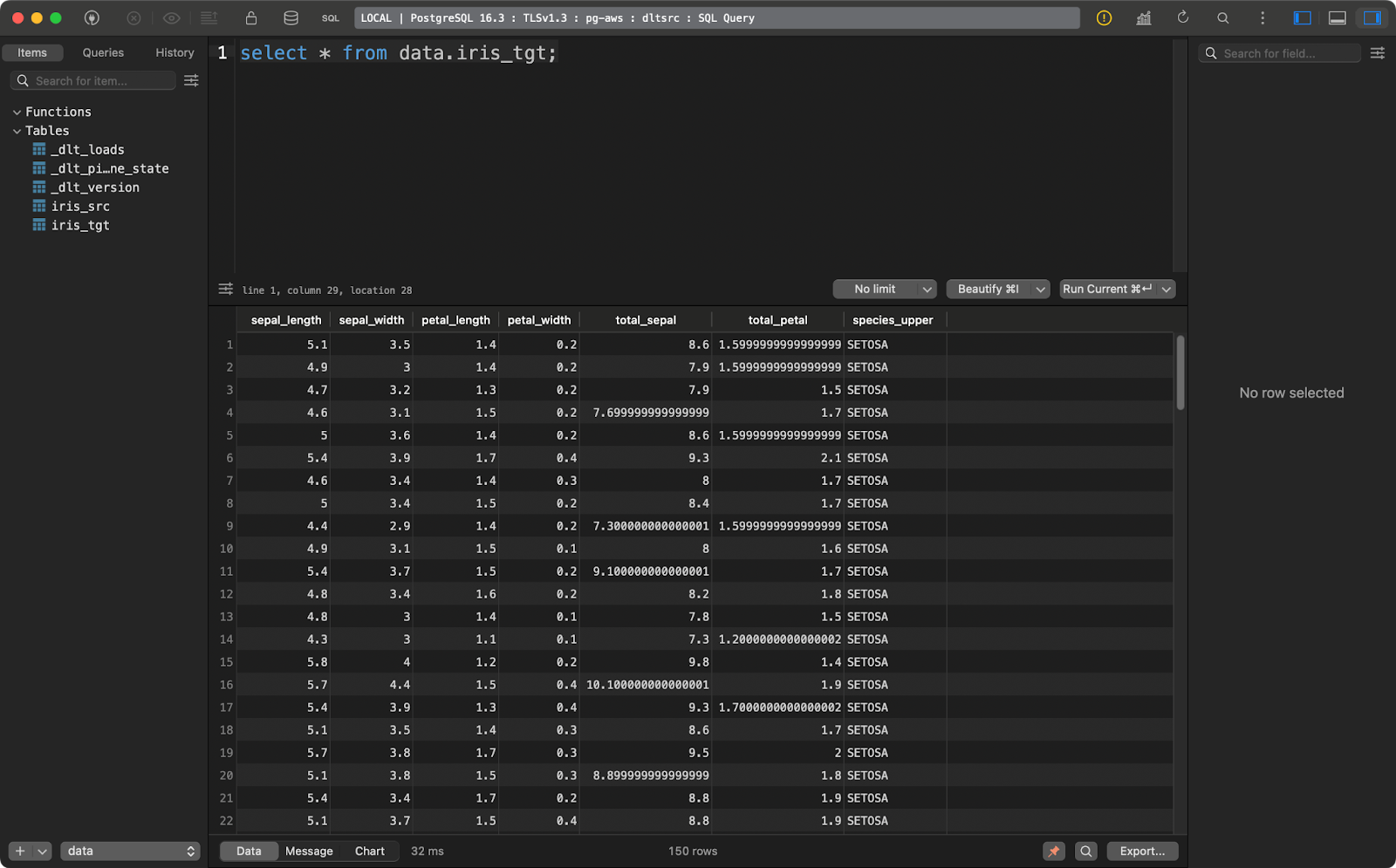
Tableau des cibles d'iris
Cet exemple de transformation est assez basique mais explique comment transformer vos données lorsqu'elles sont déjà chargées vers la destination.
Que faire si vous souhaitez transformer les données avant de les écrire dans la base de données ( ) ? En d'autres termes, si vous ne souhaitez pas sauvegarder les données brutes et transformées ? Il s'agit en fait d'une description d'un pipeline ETL. Je vous montrerai comment en mettre un en place avec pandas.
Vos fichiers TOML restent inchangés.
Dans le code du pipeline, vous devez maintenant mettre en œuvre quelques fonctions supplémentaires :
extract_data(): Utilise pandas pour lire un fichier CSV local.transform_data(): Applique des transformations de données en utilisant pandas plutôt que SQL.data(): Une fonction décorée avec @dlt.resource qui produit l'ensemble de données transformé.load_data(): Charge le site dlt.resource dans le tableau iris_tgt.Le code de ce pipeline vous semblera familier si vous avez de l'expérience avec pandas:
import dlt
import pandas as pd
def extract_data() -> pd.DataFrame:
return pd.read_csv("iris.csv")
def transform_data(df: pd.DataFrame) -> pd.DataFrame:
df["sepal_sum"] = df["sepal_length"] + df["sepal_width"]
df["petal_sum"] = df["petal_length"] + df["petal_width"]
df = df.drop(["sepal_length", "sepal_width", "petal_length", "petal_width"], axis=1)
return df
@dlt.resource
def data():
yield transform_data(df=extract_data())
def load_data() -> None:
pipeline = dlt.pipeline(
pipeline_name="pandas_etl_pipeline",
destination="duckdb",
dataset_name="data"
)
load_info = pipeline.run(data(), table_name="iris_tgt")
print(load_info)
if __name__ == "__main__":
load_data()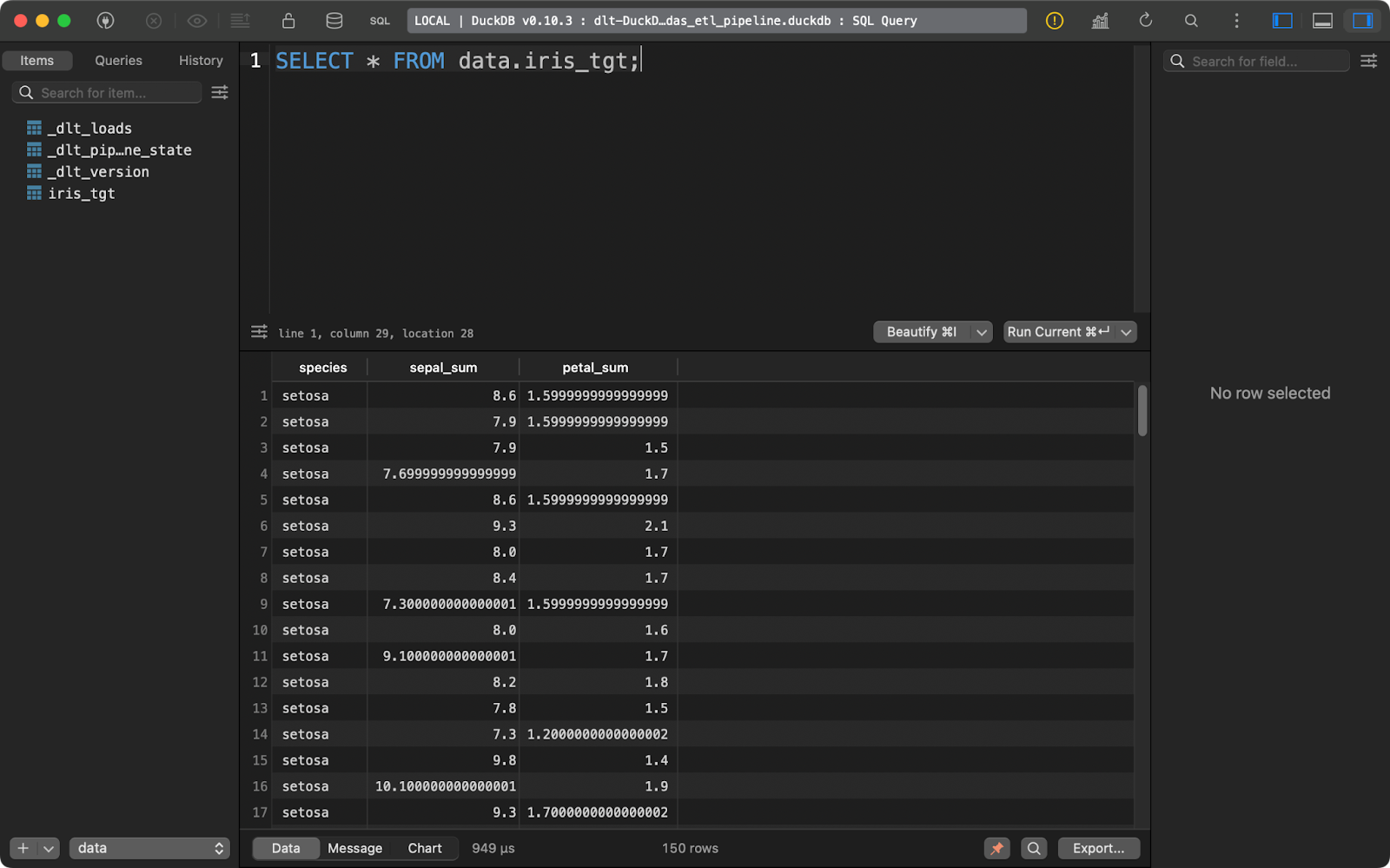
Tableau des cibles d'iris
Une fois de plus, dlt a été conçu en tenant compte de l'ELT, mais les flux de travail ETL ne nécessitent pas trop de modifications du code.
SQL et pandas sont des moyens simples de transformer les données avant et après leur chargement vers la destination.
Les auteurs de dlt vous recommandent d'utiliser le dbt ide Python à la place. C'est une option bien meilleure et plus polyvalente, mais c'est un outil trop complexe pour être traité dans un seul article. Si vous ou votre équipe utilisez déjà dbt, son utilisation dans les pipelines dlt vous semblera une extension naturelle.
Si vous souhaitez en savoir plus sur le dbt en Python, nous avons un cours complet de cours complet de 4 modules disponible.
En revanche, si vous êtes un débutant ayant des connaissances de base en SQL et en pandas, les deux approches de transformation que j'ai présentées sont suffisantes pour vous permettre de démarrer.
Jusqu'à présent, j'ai utilisé DuckDB comme destination de choix parce qu'elle est simple et ne nécessite aucune installation. Dans cette section, je vous montrerai comment travailler avec quelques of plus de destinations,notamment un système de fichiers local, un stockage dans le cloud et des bases de données.
Il arrive que vous souhaitiez enregistrer le résultat d'un pipeline de données sur le disque. Certes, dlt n'est pas le candidat idéal pour cette tâche, car il stocke également de nombreuses métadonnées, mais vous pouvez l'utiliser si vous en avez absolument besoin.
Commencez par modifier le fichier config.toml. Indiquez les chemins d'accès aux dossiers source et destination sur votre système local :
[sources.filesystem]
bucket_url = "file:///path/to/source/folder"
[destination.filesystem]
bucket_url = "file:///path/to/target/folder"
[runtime]
dlthub_telemetry = trueMaintenant, dans le fichier Python, il suffit de charger le fichier source à partir d'un système de fichiers et de l'exécuter à travers le pipeline. Par souci de simplicité, je n'ai appliqué aucune transformation de données :
import dlt
from dlt.sources.filesystem import filesystem, read_csv
def load_local_data() -> None:
source = filesystem(file_glob="iris.csv") | read_csv()
pipeline = dlt.pipeline(
pipeline_name="local_to_local",
destination="filesystem",
dataset_name="data"
)
load_info = pipeline.run(source.with_name("iris"), loader_file_format="csv")
print(load_info)
if __name__ == "__main__":
load_local_data()Il s'agit du contenu du dossier cible :
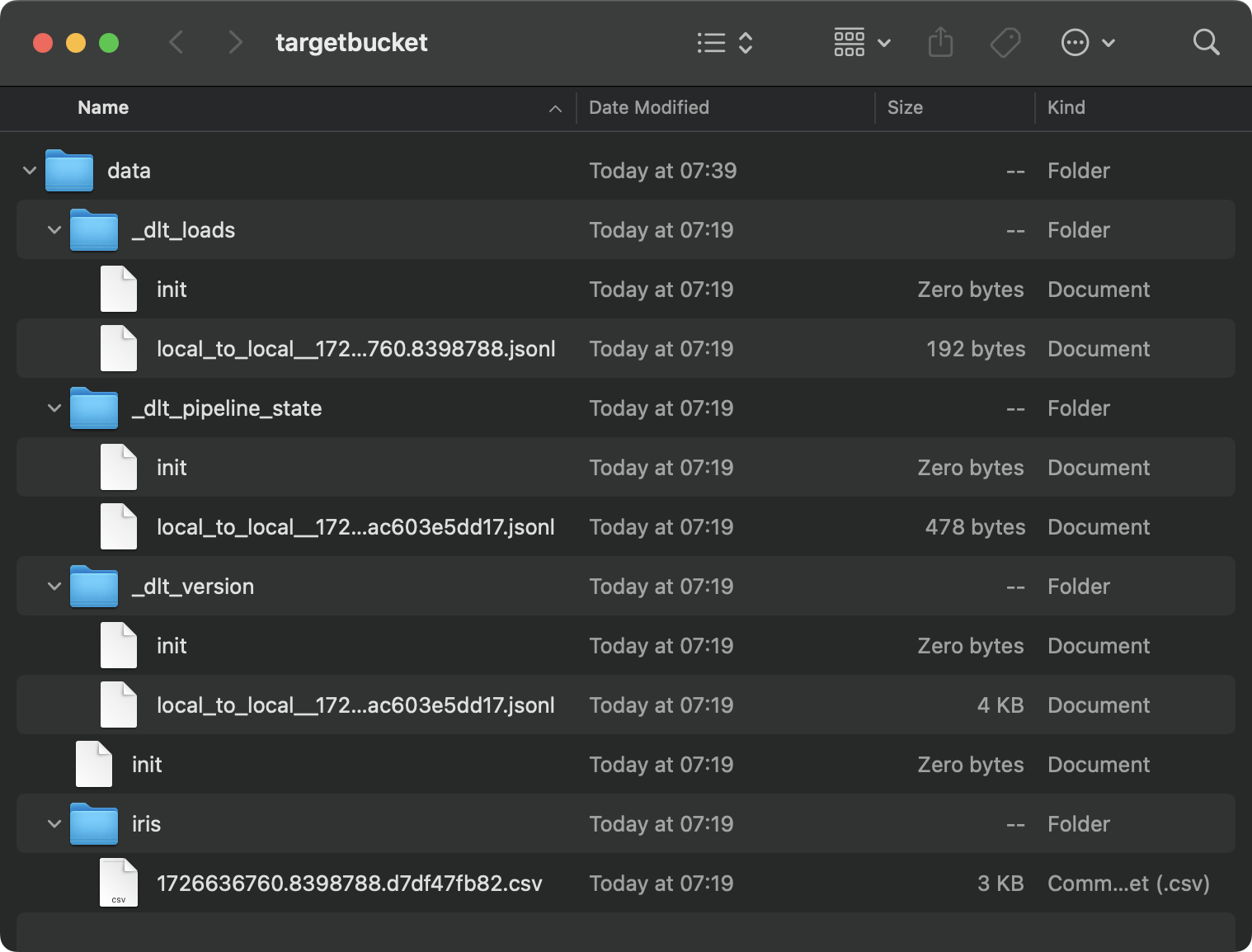
Contenu du dossier local
C'est un véritable gâchis, et ce n'est que le résultat d'un seul pipeline. Imaginez que vous en ayez des dizaines.
Les bases de données sont des endroits plus naturels pour stocker ces informations.
J'utilise une base de données Postgres provisionnée sur AWS, mais ce n'est pas nécessaire. N'hésitez pas à utiliser d'autres fournisseurs de bases de données et de cloud.
À l'intérieur de config.toml, vous devrez fournir un chemin d'accès au dossier sur votre système de fichiers local :
[sources.filesystem]
bucket_url = "file:///your-local-bucket"
[runtime]
dlthub_telemetry = trueEt dans secrets.toml, écrivez les détails de la connexion à la base de données :
[destination.postgres.credentials]
drivername = "drivername" # please set me up!
database = "database" # please set me up!
password = "password" # please set me up!
username = "username" # please set me up!
host = "host" # please set me up!
port = 0 # please set me up!Le chargement des données sources dans la base de données se résume maintenant à modifier la valeur du paramètre destination dans dlt.pipeline(). La fonction with_name() appelée sur la source de données contrôle la manière dont le tableau de la base de données sera nommé :
import dlt
from dlt.sources.filesystem import filesystem, read_csv
def load_to_database() -> None:
source = filesystem(file_glob="iris.csv") | read_csv()
pipeline = dlt.pipeline(
pipeline_name="local_to_db",
destination="postgres",
dataset_name="local_load"
)
load_info = pipeline.run(source.with_name("iris_from_local"))
print(load_info)
if __name__ == "__main__":
load_to_database()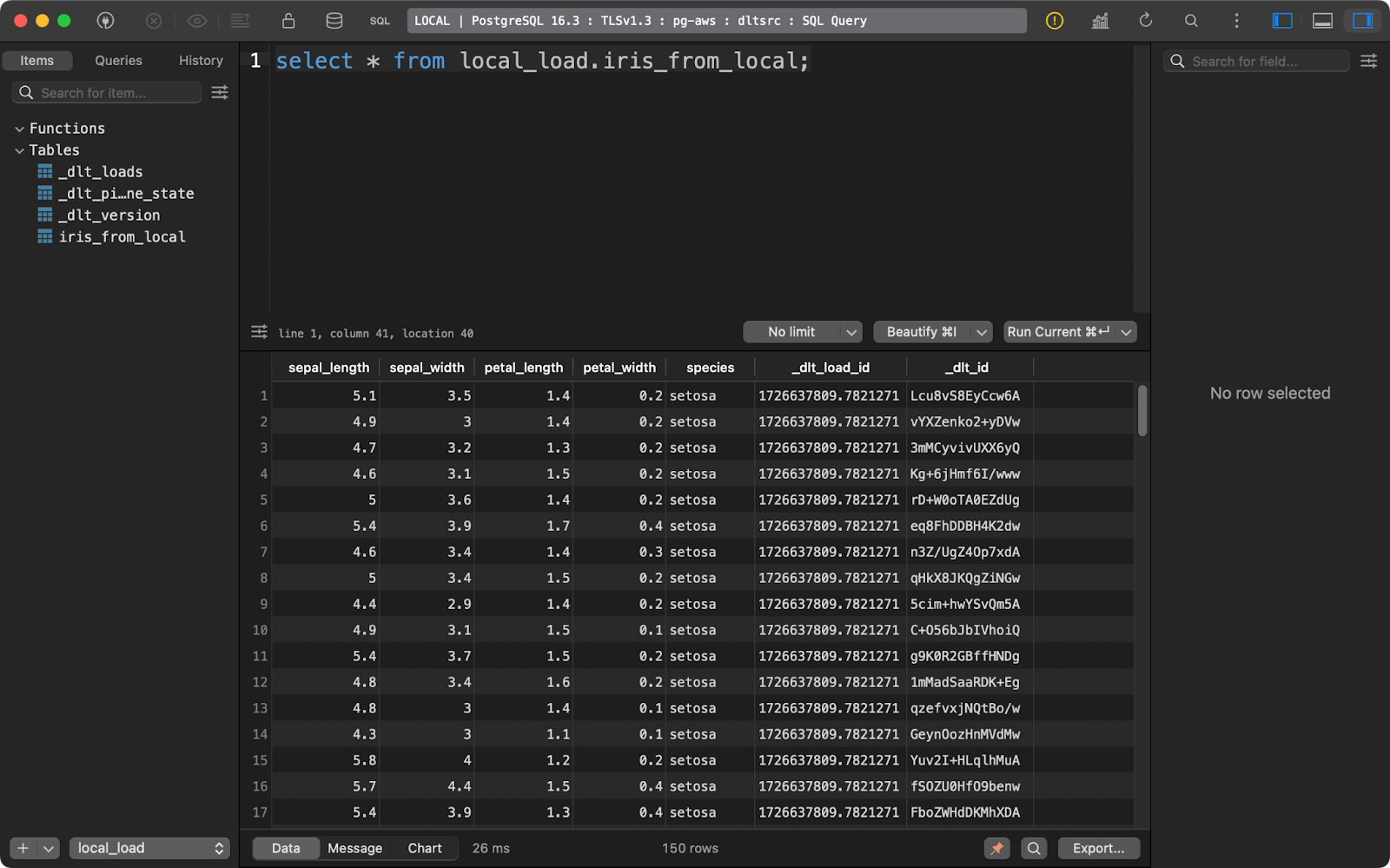
Données d'iris chargées
Explorons une autre option de destination avant d'aborder les aspects plus avancés de dlt.
Comme pour votre système de fichiers local, le stockage dans le cloud (par exemple, S3) stockera également les métadonnées dans des fichiers et des dossiers distincts.
Si vous voulez l'essayer, commencez par ajuster le fichier config.toml pour inclure les chemins d'accès à un dossier local et au seau S3 :
[sources.filesystem]
bucket_url = "file:///path/to/local/folder"
[destination.filesystem]
bucket_url = "s3://bucket-name"
[runtime]
dlthub_telemetry = trueComme pour secrets.toml, entrez vos identifiants IAM et le nom de la région du seau S3 :
[destination.filesystem.credentials]
aws_access_key_id = "aws_access_key_id" # please set me up!
aws_secret_access_key = "aws_secret_access_key" # please set me up!
region_name = "region_name" # please set me up!L'exécution du pipeline transfère le fichier CSV local vers S3 et le stocke au format JSONL (lignes JSON) :
import dlt
from dlt.sources.filesystem import filesystem, read_csv
def load_to_s3() -> None:
source = filesystem(file_glob="iris.csv") | read_csv()
pipeline = dlt.pipeline(
pipeline_name="local_to_db",
destination="filesystem",
dataset_name="iris_data"
)
load_info = pipeline.run(source.with_name("iris"))
print(load_info)
if __name__ == "__main__":
load_to_s3()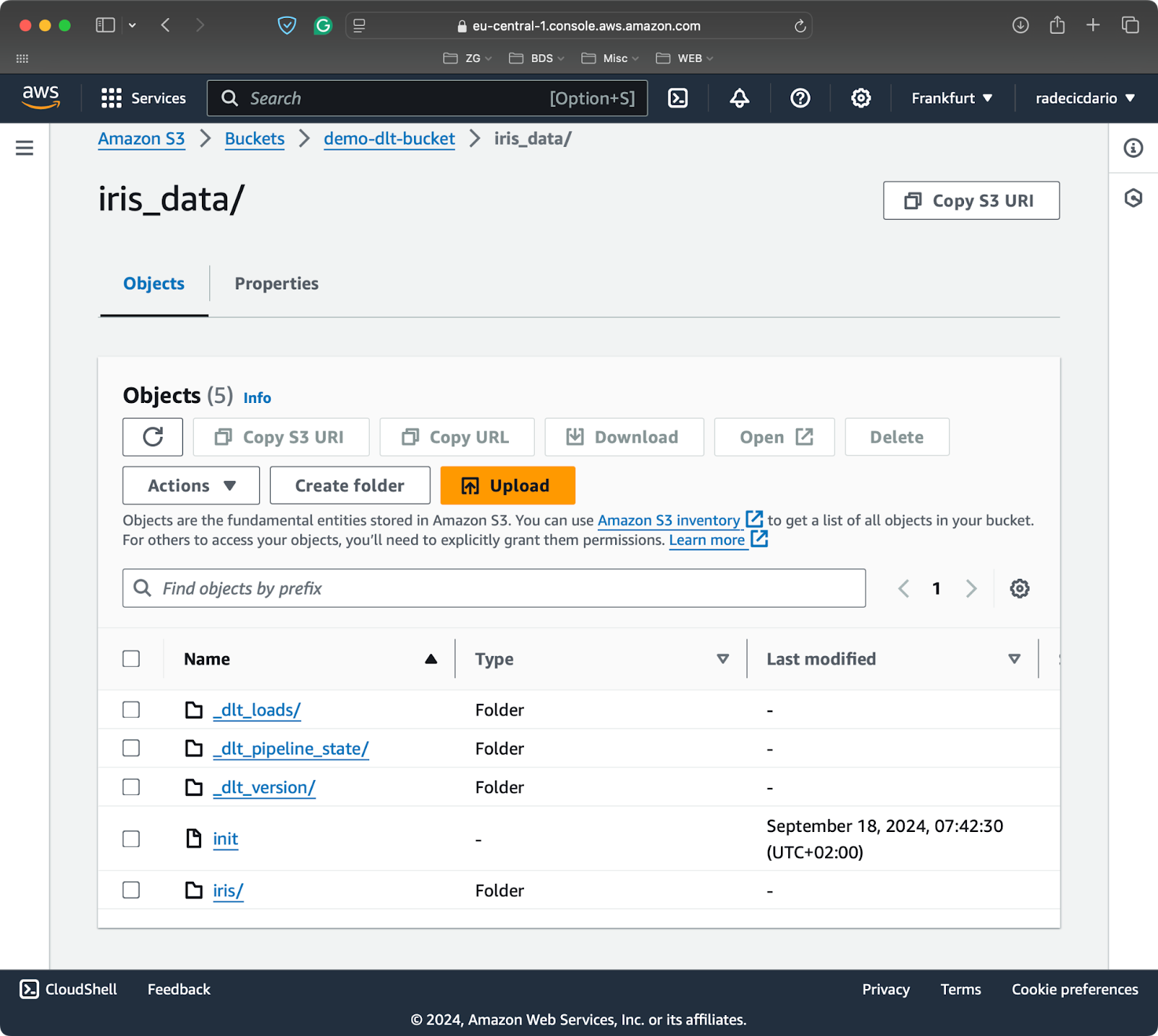
Contenu du seau S3
Vous connaissez maintenant les bases du déplacement des données et de leur transformation en cours de route. Mais que se passe-t-il lorsque vous exécutez le pipeline plusieurs fois? C'est ce dont je vais parler maintenant.
Vous ne ferez presque jamais fonctionner la canalisation une seule fois. Il est plus courant de programmer l'exécution d'un pipeline, par exemple, une fois par jour ou une fois par semaine.
Si c'est le cas, vous voudrez probablement contrôler davantage la manière dont les nouvelles données sont insérées et dont les données existantes sont mises à jour.
Chaque fois que vous exécutez votre pipeline, de nouvelles données sont ajoutées au tableau de votre choix.
Laissez-moi vous le démontrer en écrivant un simple pipeline qui insère un DataFrame pandas factice dans un tableau DuckDB :
import dlt
import pandas as pd
@dlt.resource(primary_key="index")
def data():
data = pd.DataFrame({
"index": [1, 2, 3, 4, 5],
"a": [10, 15, 20, 25, 30],
"b": [22.5, 30.5, 35.5, 50.5, 10.5],
"c": ["row 1", "row 2", "row 3", "row 4", "row 5"]
})
yield data
def load_local_data() -> None:
pipeline = dlt.pipeline(
pipeline_name="pipeline_incremental_load",
destination="duckdb",
dataset_name="data"
)
load_info = pipeline.run(data=data(), table_name="dataset")
print(load_info)
if __name__ == "__main__":
load_local_data()L'exécution unique du pipeline permet d'insérer cinq lignes de données :
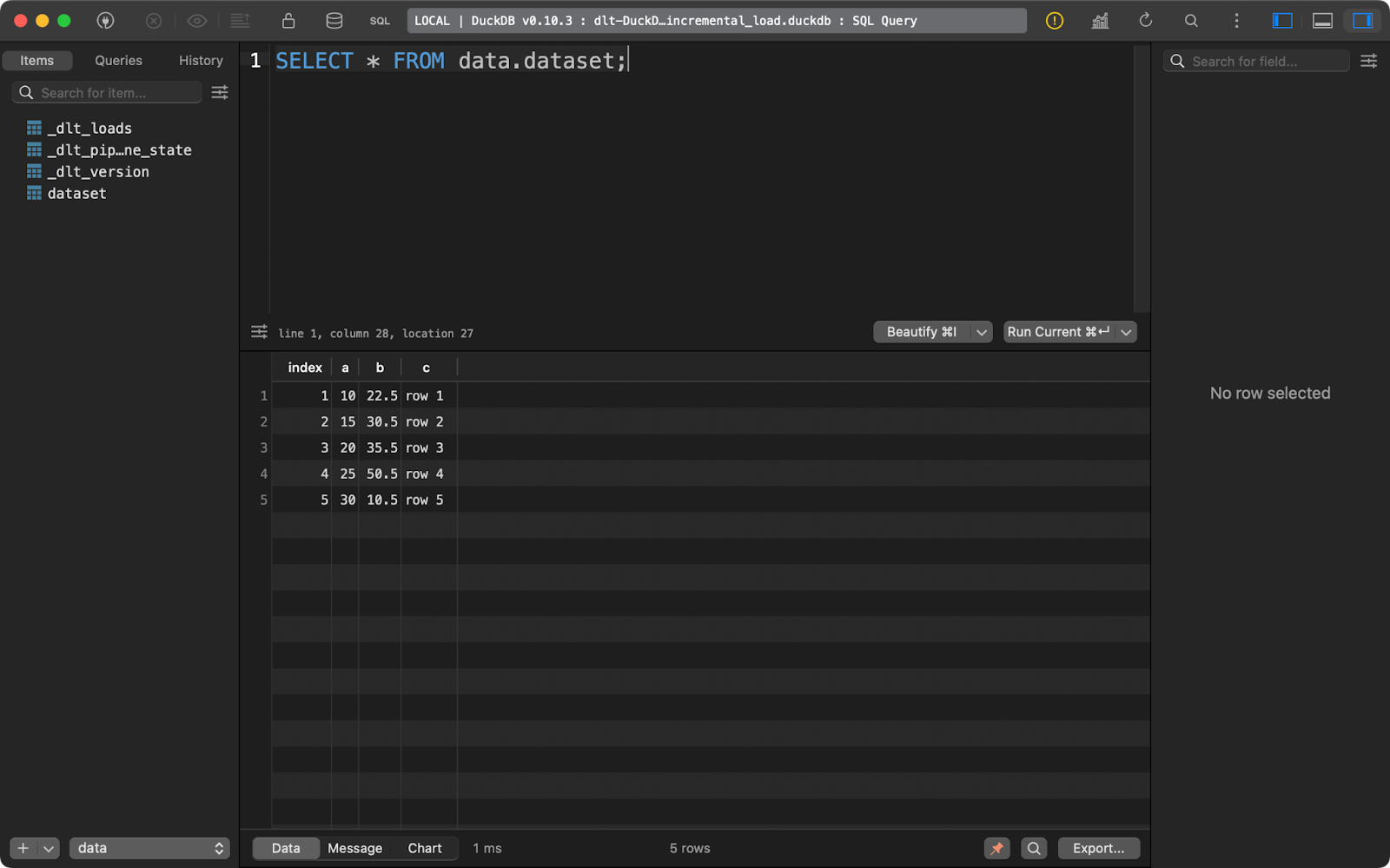
Première exécution de l'appendice
En le relançant, vous insérez les cinq mêmes lignes :
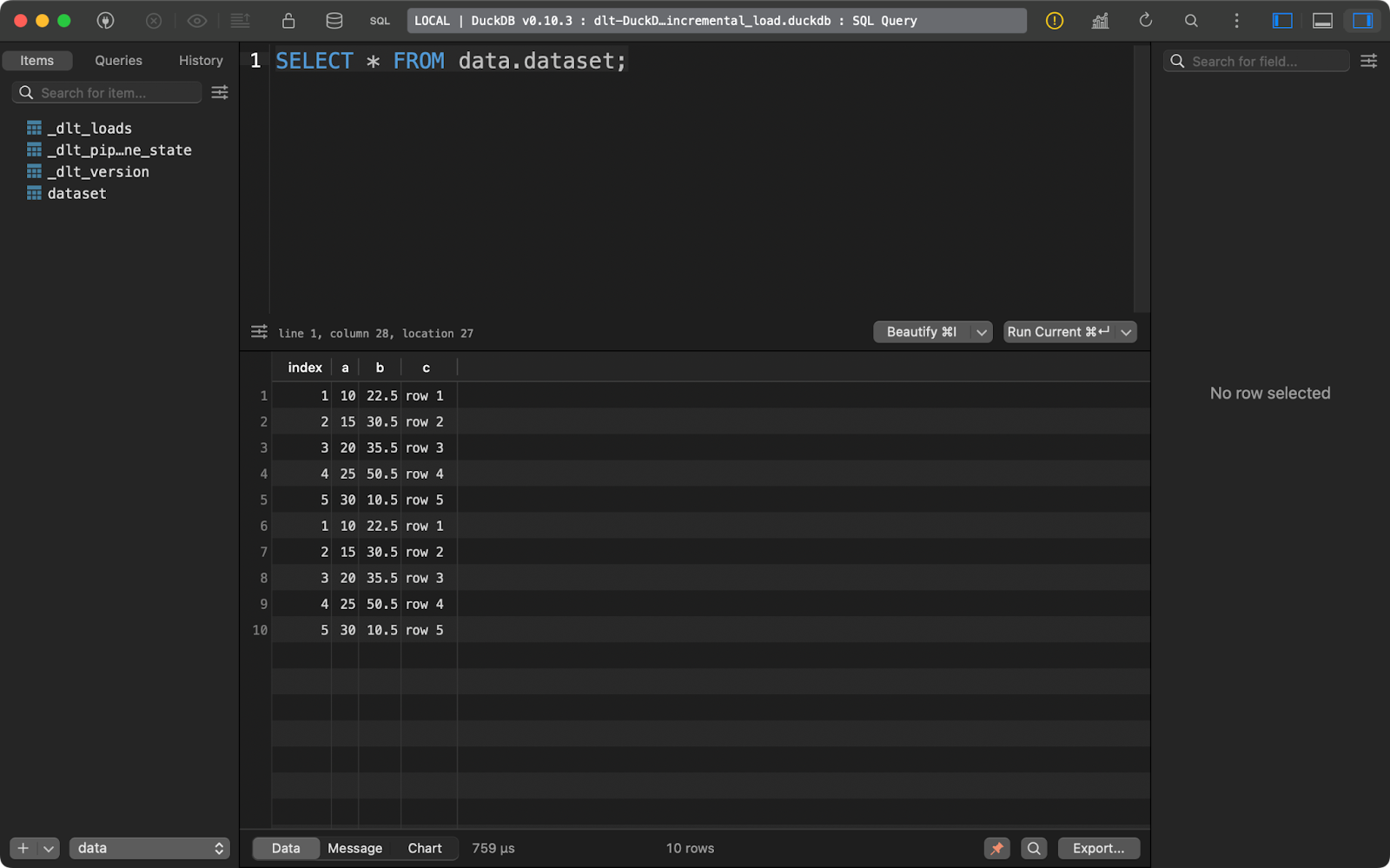
Deuxième exécution de l'appendice
Avec ce type de données, il est facile de conclure qu'il s'agit d'une duplication. Laissez-moi vous montrer ce que vous pouvez faire.
Si vous souhaitez supprimer des enregistrements existants et les remplacer par de nouveaux, ajoutez write_disposition=”replace” à pipeline.run():
load_info = pipeline.run(data=data(), table_name="dataset", write_disposition="replace")Après avoir fait cela, j'ai exécuté le pipeline quatre fois, comme vous pouvez le voir dans le tableau des métadonnées de _dlt_loads:
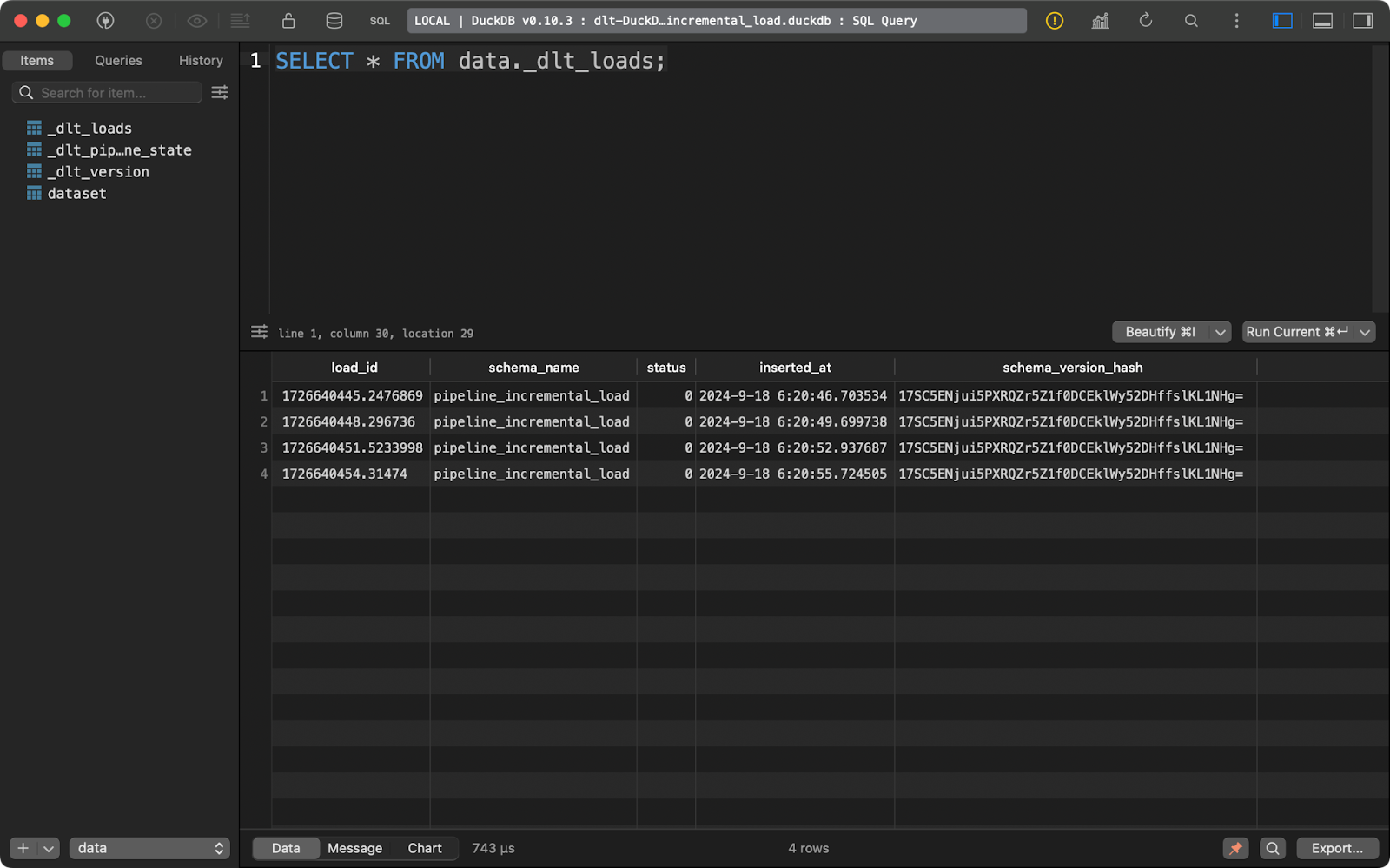
Exécuter le pipeline plusieurs fois
Et le tableau dataset ne contient que 5 enregistrements :
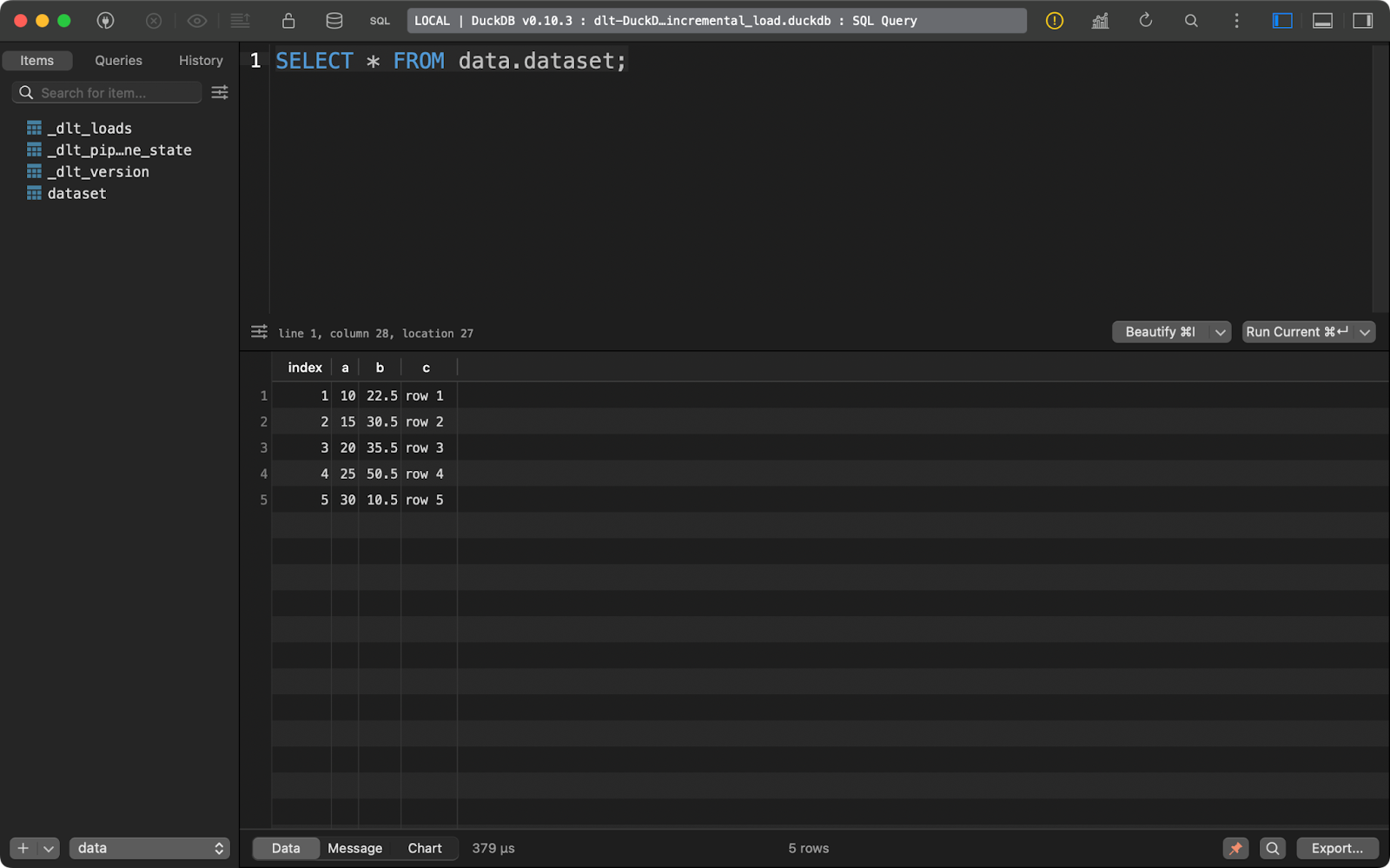
dataset tableau des matières
En bref, cette approche remplacera toujours les données existantes.
Mais qu'en est-il si vous disposez d'un mélange de données nouvelles et actualisées ? C'est là qu'intervient l'opération upsert. Elle est mise en œuvre par le biais de la disposition d'écriture merge dans dlt.
Pour référence, j'ai exécuté le pipeline une fois de plus avec les données de la section précédente pour m'assurer qu'il y a bien 5 lignes présentes.
Ensuite, j'ai mis à jour les données en ajoutant une ligne supplémentaire et en modifiant les valeurs de certains enregistrements avec les valeurs existantes de index.
Le paquet dlt examinera la colonne primary_key que vous avez spécifiée et la comparera aux données présentes sur le système de destination. Les enregistrements comportant la colonne de clé primaire existante seront mis à jour et les nouveaux seront insérés.:
import dlt
import pandas as pd
@dlt.resource(primary_key="index")
def data():
data = pd.DataFrame({
"index": [1, 2, 3, 4, 5, 6],
"a": [10, 15, 200000, 25, -3000, 50],
"b": [22.5, 30.5, 3555555.5, 50.5, -100.5, 15.5],
"c": ["row 1", "row 2", "row 3 updated", "row 4", "row 5 updated", "row 6 new"]
})
yield data
def load_local_data() -> None:
pipeline = dlt.pipeline(
pipeline_name="pipeline_incremental_load",
destination="duckdb",
dataset_name="data"
)
load_info = pipeline.run(data=data(), table_name="dataset", write_disposition="merge")
print(load_info)
if __name__ == "__main__":
load_local_data()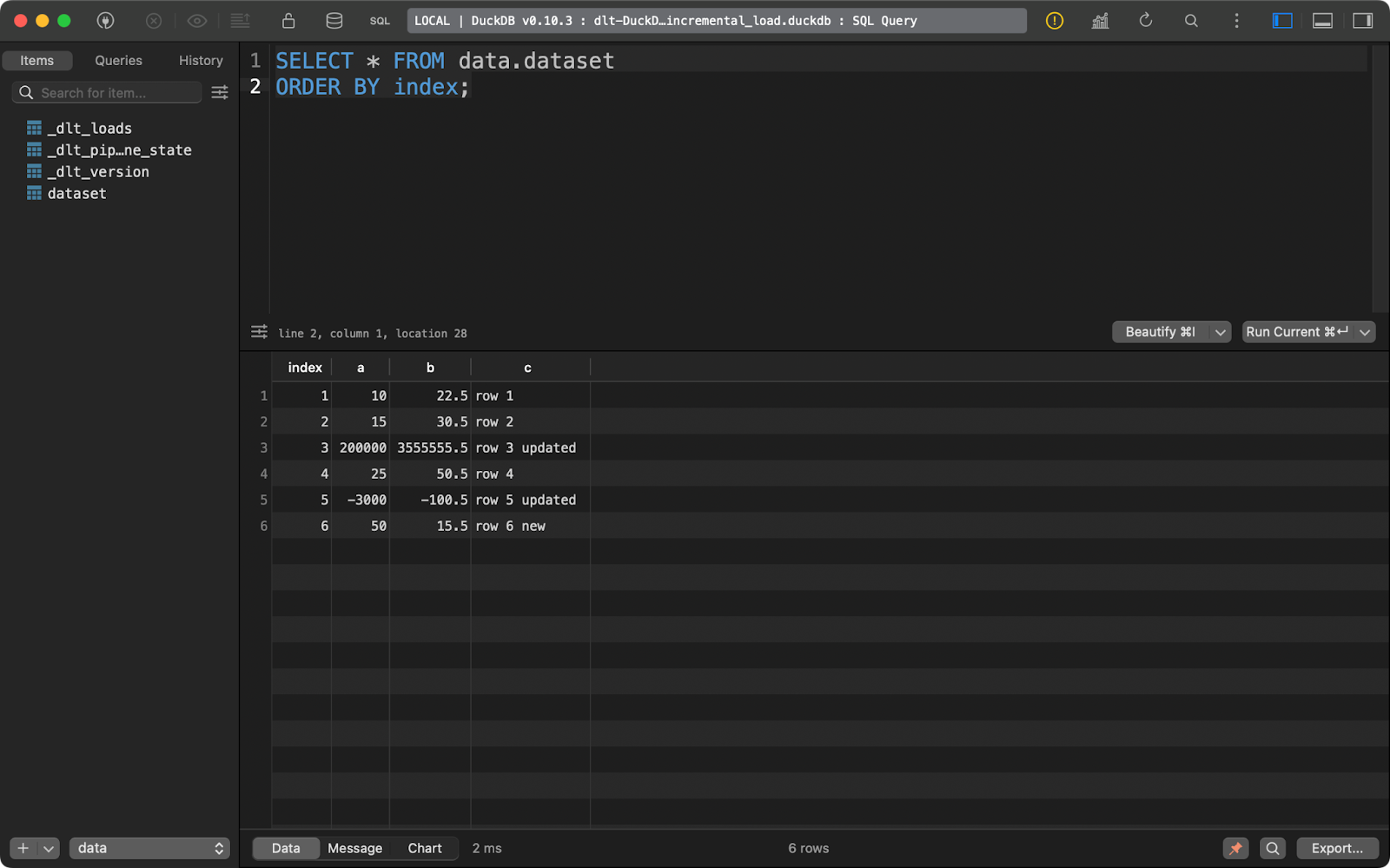
Ensemble de données après l'opération d'insertion
En résumé, vous obtenez une nouvelle ligne et deux lignes mises à jour.
C'est probablement le comportement que vous souhaitez pour la plupart de vos pipelines, en particulier lorsque vous voulez éviter la duplication des données.
En conclusion, l'ingénierie des données est plus complexe qu'il n'y paraît. La circulation des données n'est qu'un aspect de la question. Néanmoins, il s'agit d'une partie essentielle et la plupart des autres aspects de l'ingénierie des données tournent autour d'elle.
Si vous connaissez déjà Python, vous ne cherchez probablement pas à apprendre un outil d'interface graphique pour le déplacement de données à partir de zéro, ou à migrer vers un tout nouveau langage. Vous souhaitez rester dans un environnement familier. La bibliothèque dlt de Python est tout ce dont vous et votre équipe avez besoin pour moderniser les systèmes hérités et réduire les coûts de cloud. Il a été testé par de nombreux grands acteurs, tels que Hugging Face, Taktile, Untitled Data Company et Harness, et je pense donc qu'il répondra également à vos besoins.
Cela dit, dlt n'est probablement pas le seul outil dont vous avez besoin pour mettre en œuvre des pipelines de données efficaces. Vous souhaiterez apprendre d'autres outils de données tels que dbt pour passer à l'étape suivante du traitement des données.
Si vous souhaitez démarrer une carrière en tant qu'ingénieur en données, notre cours en 3 modules est le moyen idéal pour commencer.
Nos programmes de certification vous aident à vous démarquer et à prouver aux employeurs potentiels que vos compétences sont adaptées à l'emploi.

Apprenez-en plus sur l'ingénierie des données avec ces cours !
Cursus
Cours
Cours
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach
8 min
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min