
Lernpfad
Dateningenieur in Python
40 Std.
Wenn du ein neues Python-Projekt einrichtest, ist es am besten, wenn du dies in einer virtuellen Umgebung tust. Ich zeige dir, wie du mit conda und venv vorgehen kannst.
Ich verwende Anaconda, um Umgebungen und Abhängigkeiten zu verwalten. Wenn du das auch tust, führe das folgende Snippet aus, um eine neue virtuelle Umgebung namens dlt_env zu erstellen, die auf Python 3.12 basiert:
conda create --name dlt_env python=3.12 -y
conda activate dlt_envDu solltest eine ähnliche Ausgabe wie diese in deinem Terminal sehen:
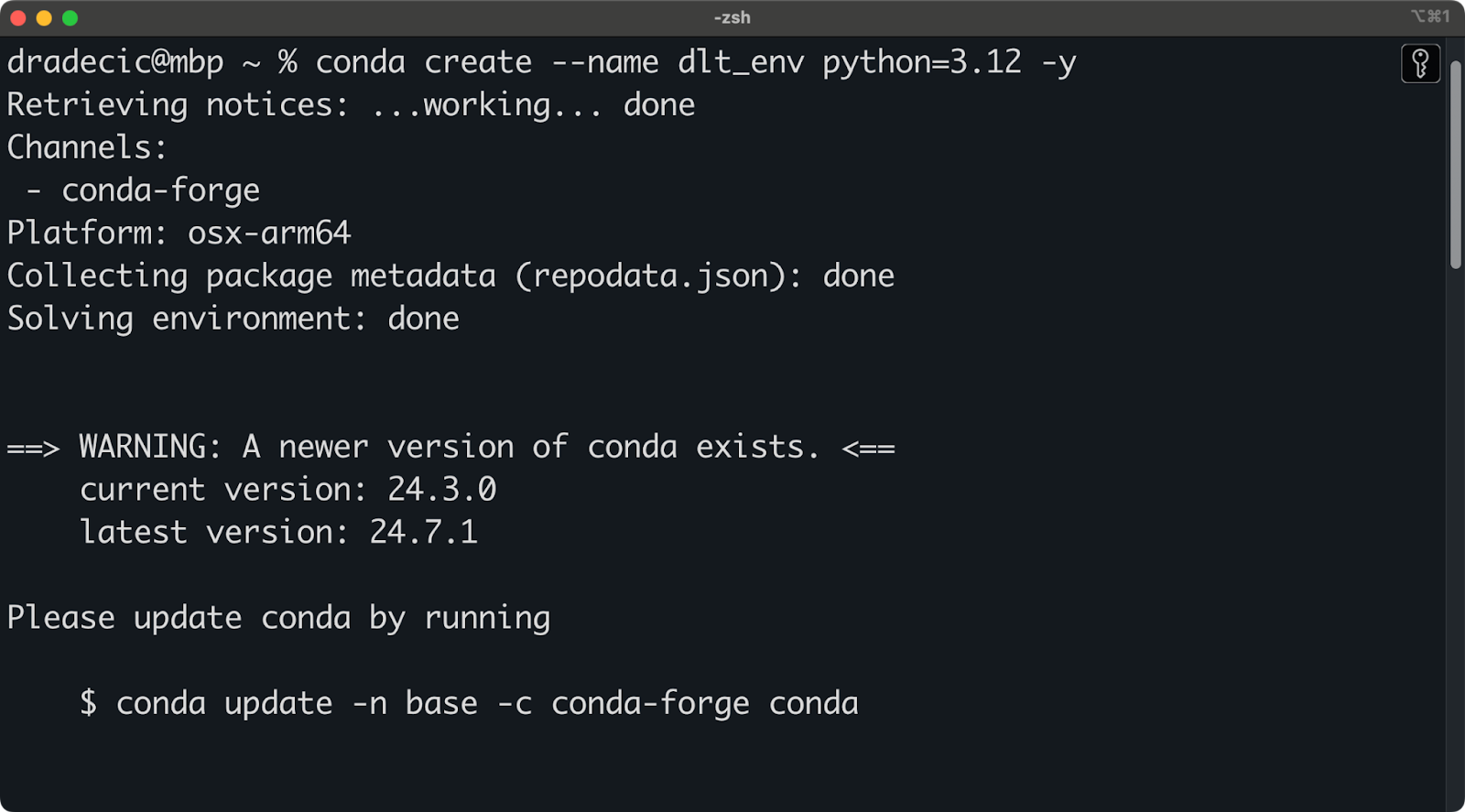
Einrichtung der Conda-Umgebung
Wenn du jedoch nicht mit Anaconda arbeitest, führe den folgenden Befehl aus, um eine neue Python-Umgebung zu erstellen und zu aktivieren:
python -m venv ./env
source ./env/bin/activateJetzt kannst du dlt installieren.
Bevor du fortfährst, solltest du eine virtuelle Umgebung erstellt und aktiviert haben
Um dlt zu installieren, führe Folgendes innerhalb der Umgebung aus:
pip install dlt
dlt version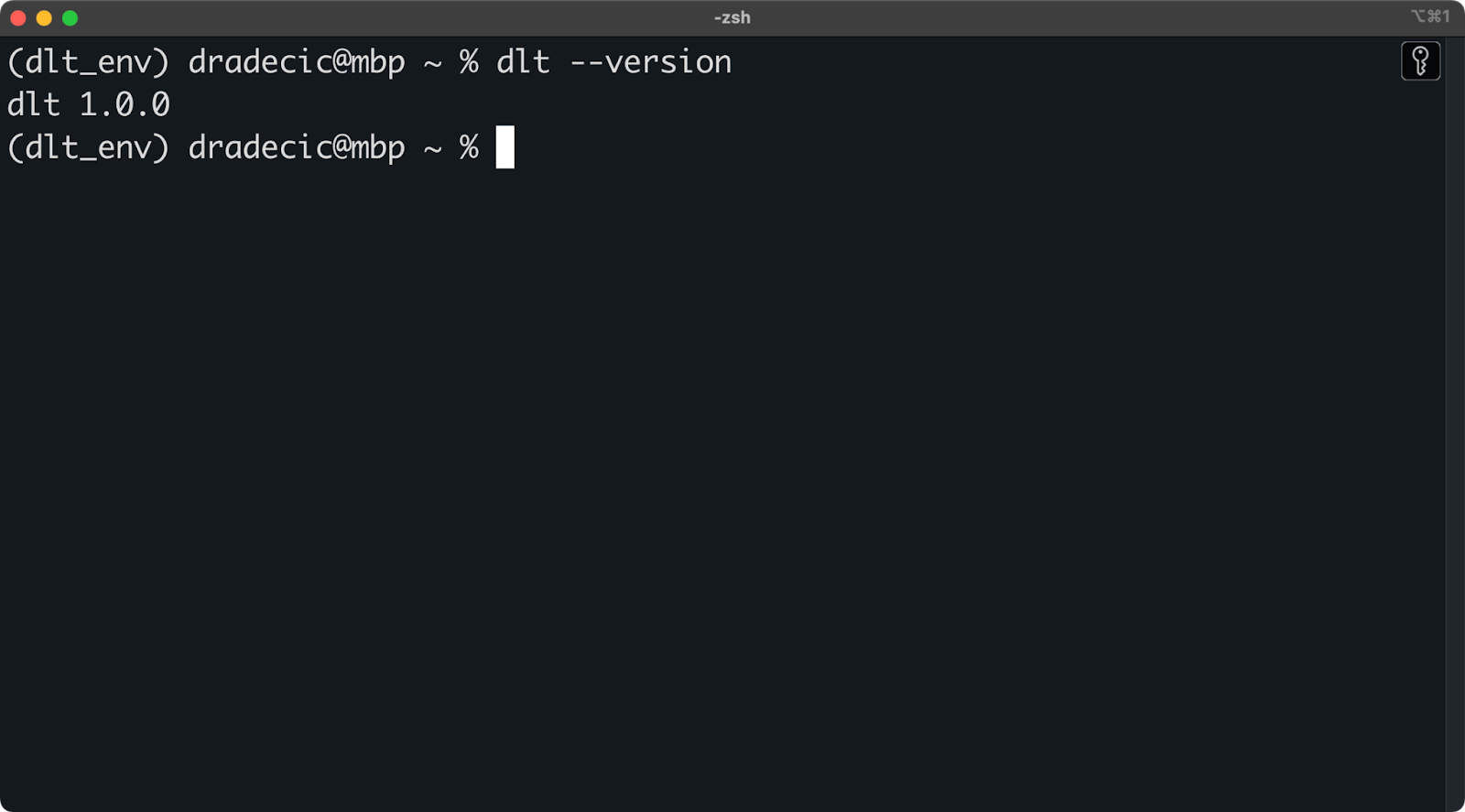
Installierte dlt Version
Solange du keine Fehlermeldung oder eine Meldung erhältst, dass dlt nicht erkannt wird, kannst du loslegen!
Du kannst jetzt die Kommandozeilenschnittstelle dlt verwenden, um neue Projekte aus einer Vorlage zu erstellen.
Dies geschieht über den Befehl dlt init . Im folgenden Snippet zeige ich dir, wie du eine Pipeline erstellst, die eine REST-API als Datenquelle nutzt und DuckDB als Ziel (Target) verwendet:
dlt init rest_api_test duckdb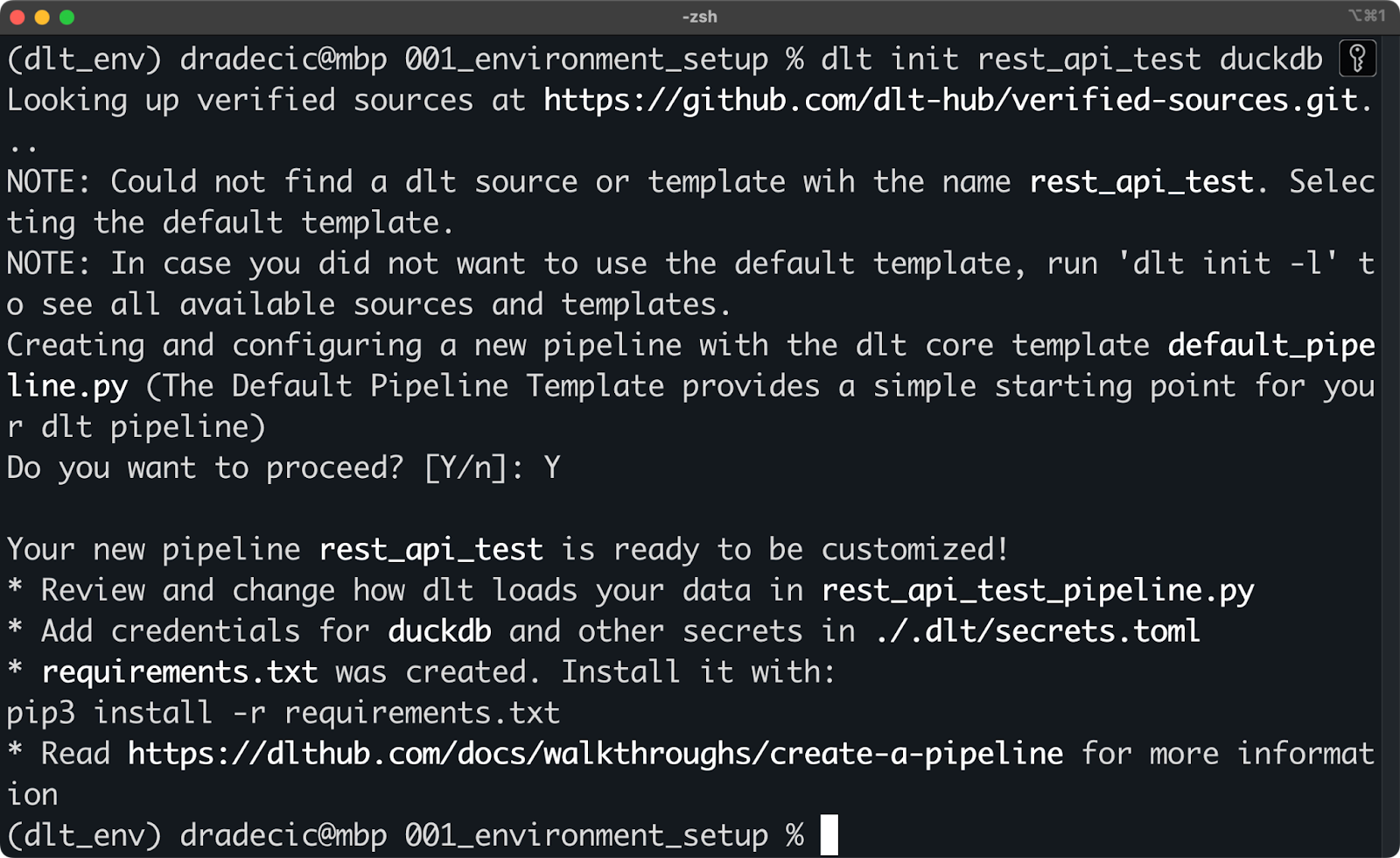
Initialisierung eines neuen dlt-Projekts mit DuckDB
Es hält dich niemand davon ab, die Dateien manuell zu erstellen - achte nur darauf, dass deine Ordnerstruktur derjenigen ähnelt, die dlt CLI erstellt. Das ist zum Beispiel das, was der vorherige Shell-Befehl auf meinem System erzeugt hat:
.
├── requirements.txt
├── rest_api_test_pipeline.py
├── .dlt
│ ├── config.toml
│ ├── secrets.tomlDer Zauber findet im Ordner .dlt statt. Sie enthält zwei Dateien, die alles über dieKonfiguration der Pipeline und die Datenquellen und -ziele, wie API-Schlüssel und Datenbankanmeldeinformationen, enthalten.
Die rest_api_test_pipeline.py ist eine automatisch generierte Python-Datei, die dir einige Möglichkeiten zeigt, wie du eine REST-API mit DuckDB verbinden kannst.
Für den Anfang solltest du alles installieren, was auf requirements.txt aufgelistet ist. Dazu führst du den folgenden Befehl aus:
pip install -r requirements.txtNach der Installation bist du bereit, deine erste dlt Pipeline in Betrieb zu nehmen!
Hier ist der Inhalt der Datei rest_api_test_pipeline.py:
"""The Default Pipeline Template provides a simple starting point for your dlt pipeline"""
# mypy: disable-error-code="no-untyped-def,arg-type"
import dlt
from dlt.common import Decimal
@dlt.resource(name="customers", primary_key="id")
def rest_api_test_customers():
"""Load customer data from a simple python list."""
yield [
{"id": 1, "name": "simon", "city": "berlin"},
{"id": 2, "name": "violet", "city": "london"},
{"id": 3, "name": "tammo", "city": "new york"},
]
@dlt.resource(name="inventory", primary_key="id")
def rest_api_test_inventory():
"""Load inventory data from a simple python list."""
yield [
{"id": 1, "name": "apple", "price": Decimal("1.50")},
{"id": 2, "name": "banana", "price": Decimal("1.70")},
{"id": 3, "name": "pear", "price": Decimal("2.50")},
]
@dlt.source(name="my_fruitshop")
def rest_api_test_source():
"""A source function groups all resources into one schema."""
return rest_api_test_customers(), rest_api_test_inventory()
def load_stuff() -> None:
# specify the pipeline name, destination and dataset name when configuring pipeline,
# otherwise the defaults will be used that are derived from the current script name
p = dlt.pipeline(
pipeline_name='rest_api_test',
destination='duckdb',
dataset_name='rest_api_test_data',
)
load_info = p.run(rest_api_test_source())
# pretty print the information on data that was loaded
print(load_info) # noqa: T201
if __name__ == "__main__":
load_stuff()Lass mich zuerst die Dekorateure erklären, denn du hast sie sicher noch nicht gesehen:
@dlt.resource: Wird verwendet, um eine generische Ressource zu erstellen, z. B. eine Datenbanktabelle mit einem Namen und einem Primärschlüsselspaltennamen. Du willst einen Datensatz (z. B. eine Python-Liste oder einen Pandas DataFrame) nicht zurückgeben, sondern ihn yield.@dlt.source: Wird verwendet, um mehrere Ressourcen, z. B. mehrere Tabellen, in einem einzigen Datenbankschema zusammenzufassen. Die Funktion muss Funktionsaufrufe zu deinen Ressourcen zurückgeben.Die Python-Funktionen in dieser Datei sind ziemlich einfach, aber lass mich die Logik erklären:
rest_api_test_customers(): Erzeugt zufällige Daten zu Kundenname und Stadt.rest_api_test_inventory(): Erzeugt zufällige Daten zu Produktname und Preis.rest_api_test_source(): Fasst die beiden vorherigen Ressourcen in einem Schema zusammen.load_stuff(): Erstellt eine Pipeline, die Python-Dummy-Daten in eine DuckDB-Datenbank verschiebt, und führt sie aus.Beachte, dass die Daten nicht tatsächlich von einer REST-API abgerufen werden, sondern dass ihre Struktur genau wie JSON aussieht , das jede REST-API zurückgeben würde. Später in diesem Artikel zeige ich dir, wie du mit echten APIs arbeiten kannst.
Führe die Pipeline zunächst mit dem folgenden Shell-Befehl aus:
python rest_api_test_pipeline.py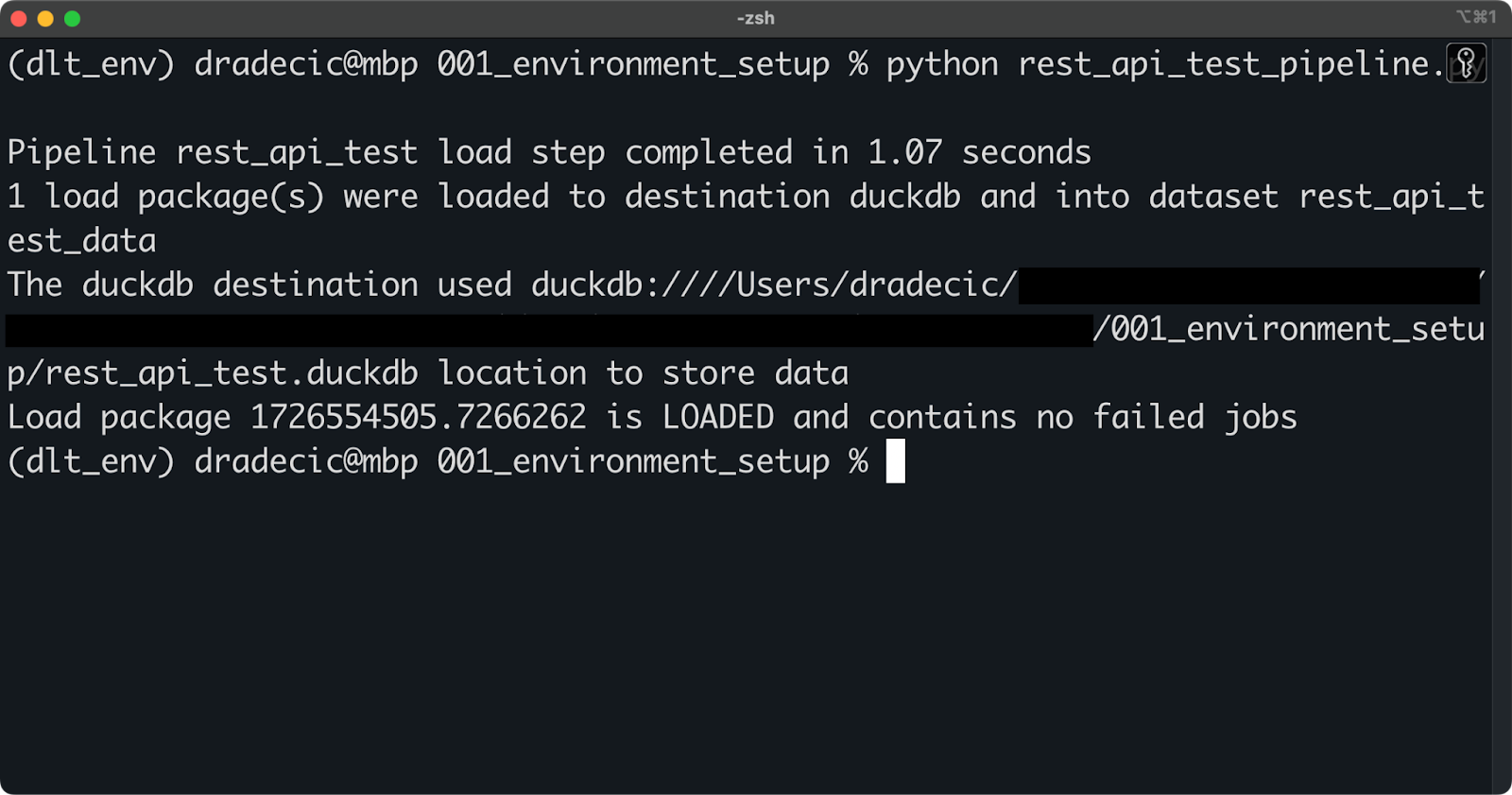
Betrieb der Pipeline
Wenn du eine ähnliche Meldung wie die obige siehst, war die Ausführung der Pipeline erfolgreich.
Du kannst dich mit jedem beliebigen Datenbankprogramm mit der lokalen DuckDB-Datei verbinden (ich verwende TablePlus). Dort befinden sich deine Daten in einem Schema, das unter dem Parameter dataset_name in dlt.pipeline() angegeben ist.
Die Tabelle customers zeigt Daten, die mit Python erzeugt wurden, und enthält zusätzlich zwei Spalten zur Datenabfolge:
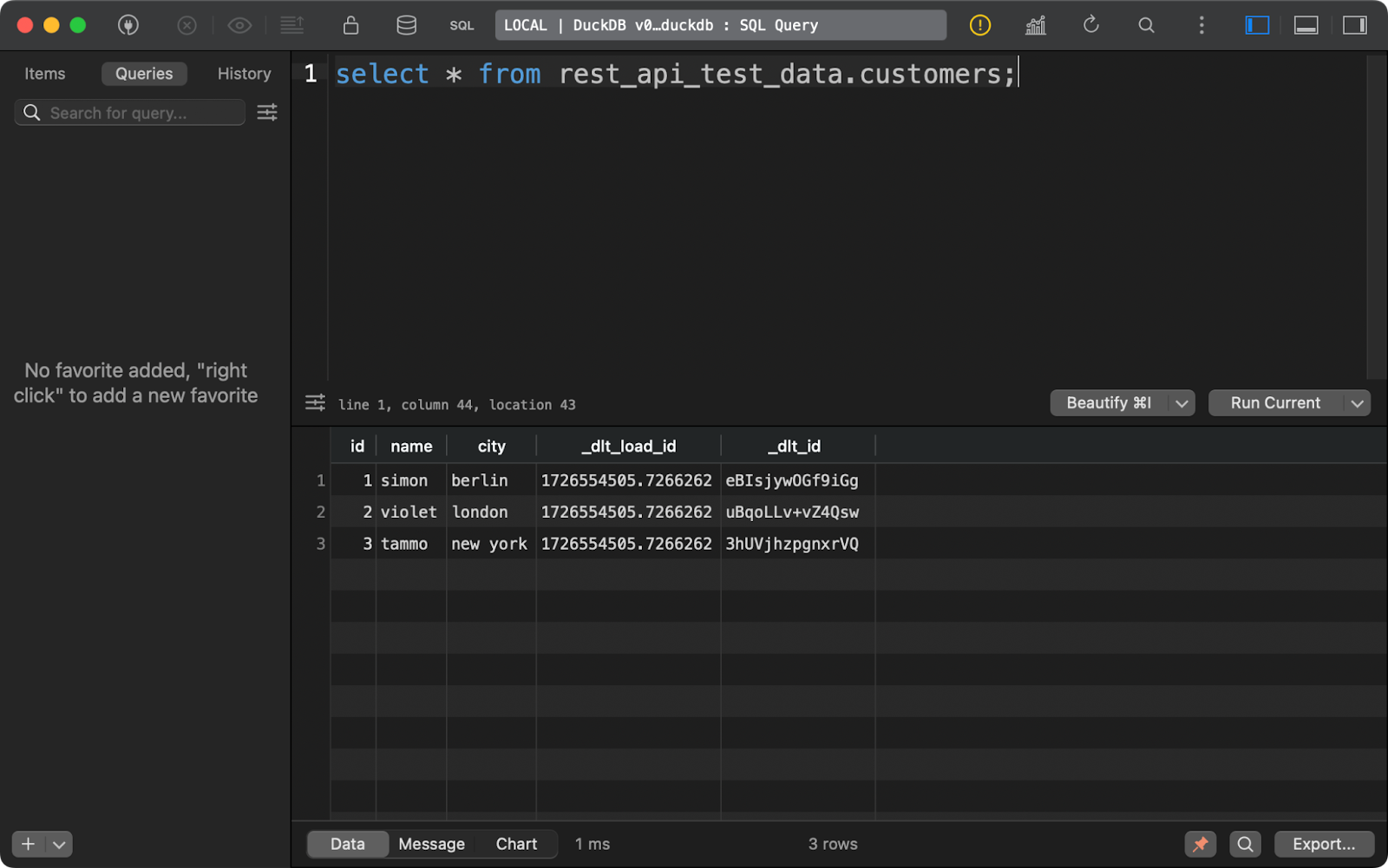
Kunden Tabelle Inhalt
Das Gleiche gilt für die Tabelle inventory. Beachte, dass die Spalte price NULLs enthält. Wahrscheinlich gibt es ein Problem mit dem Datentyp Decimal, den dlt in diesem Beispiel standardmäßig verwendet:
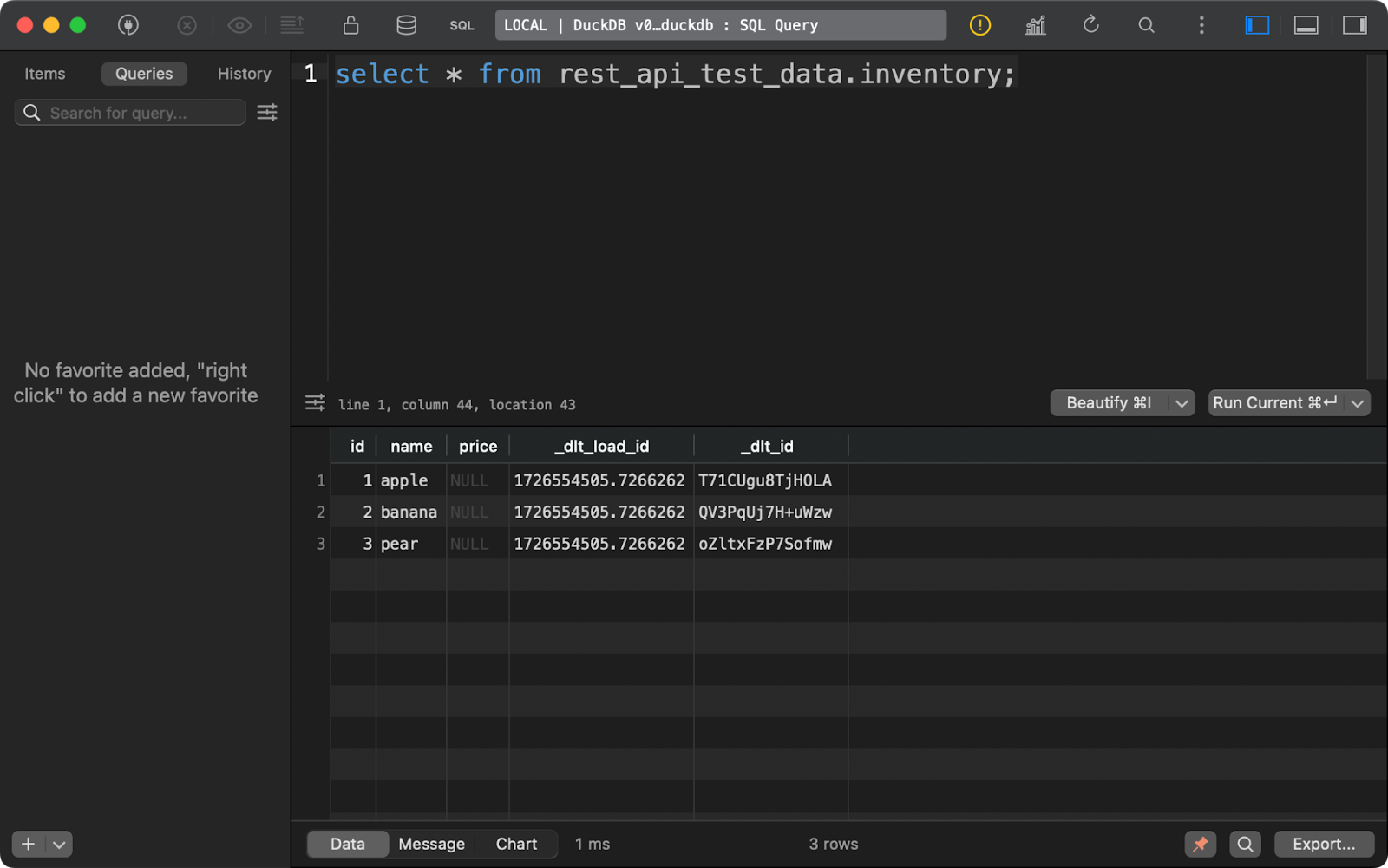
Inhalt der Tabelle für die Bestandsaufnahme
Jedes Mal, wenn du eine Pipeline ausführst, erstellt dlt drei Tabellen mit Metadaten (oder hängt sie an).
Der erste Lernpfad, _dlt_loads, verfolgt den Verlauf der von der Pipeline durchgeführten Datenladungen. Sie zeigt unter anderem den Namen des Schemas, den Ladestatus und den Zeitpunkt des Ladens an:
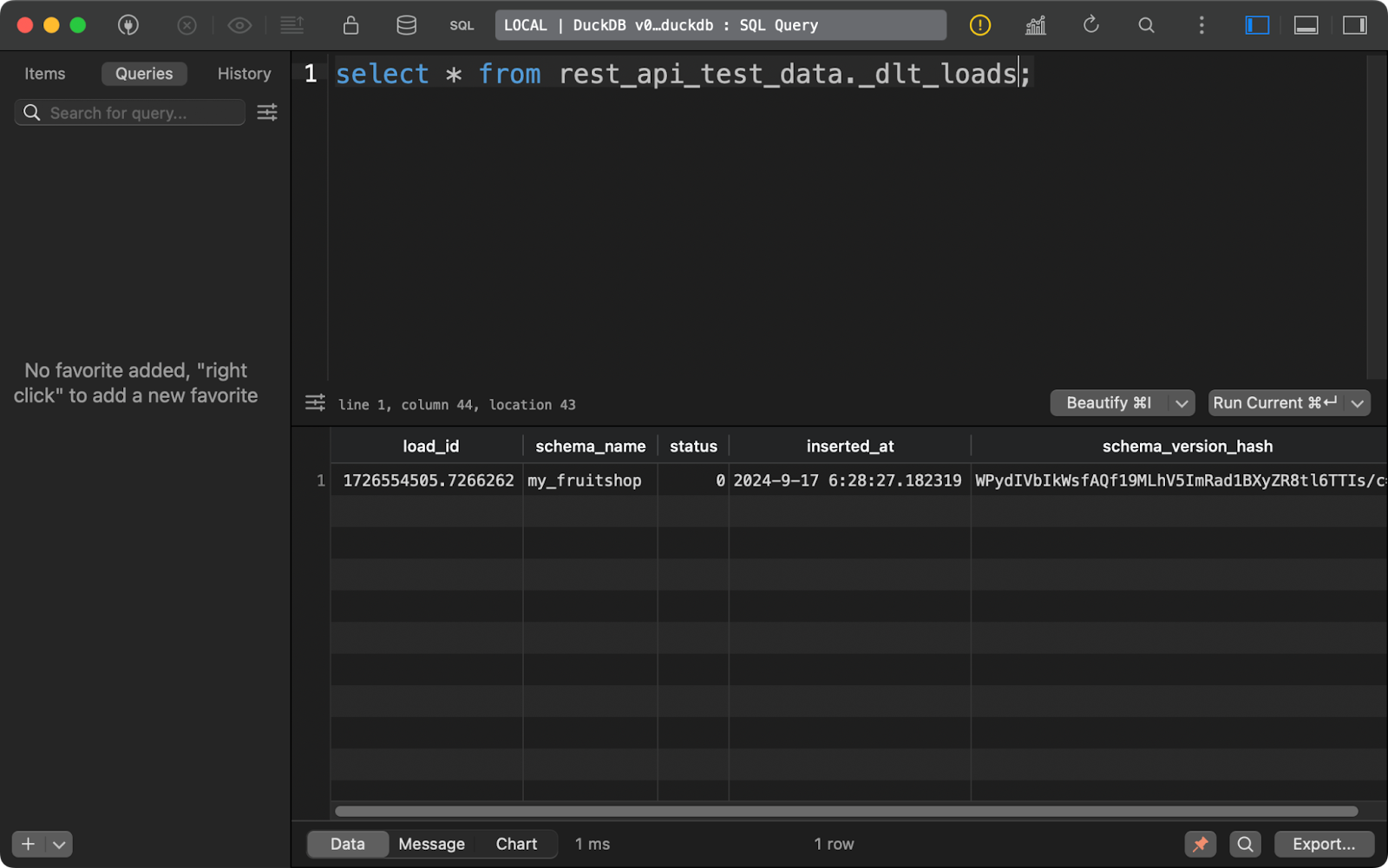
Geschichte der Datenladungen
Die Tabelle _dlt_pipeline_state zeigt Details zur Konfiguration der Pipeline, zu den Kontrollpunkten und zum Fortschritt. Sie ist auch hilfreich, wenn deine Pipeline aus irgendeinem Grund unterbrochen wird, da die Daten aus dieser Tabelle die Pipeline dort fortsetzen können, wo sie unterbrochen wurde:
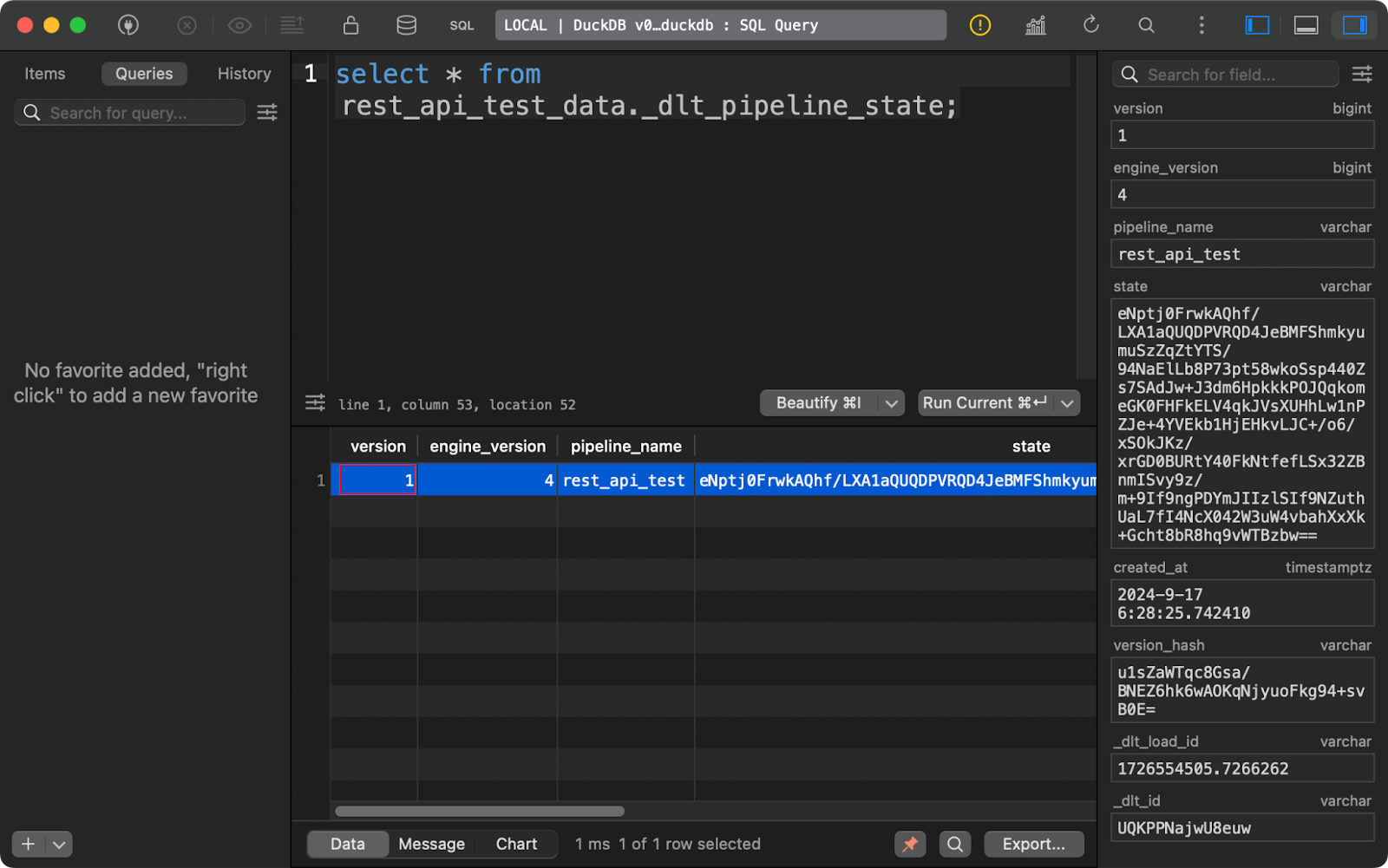
Tabelle zum Zustand der Pipeline
In der Tabelle _dlt_version schließlich werden Informationen über die Bibliothek selbst gespeichert, um die Kompatibilität zu gewährleisten:
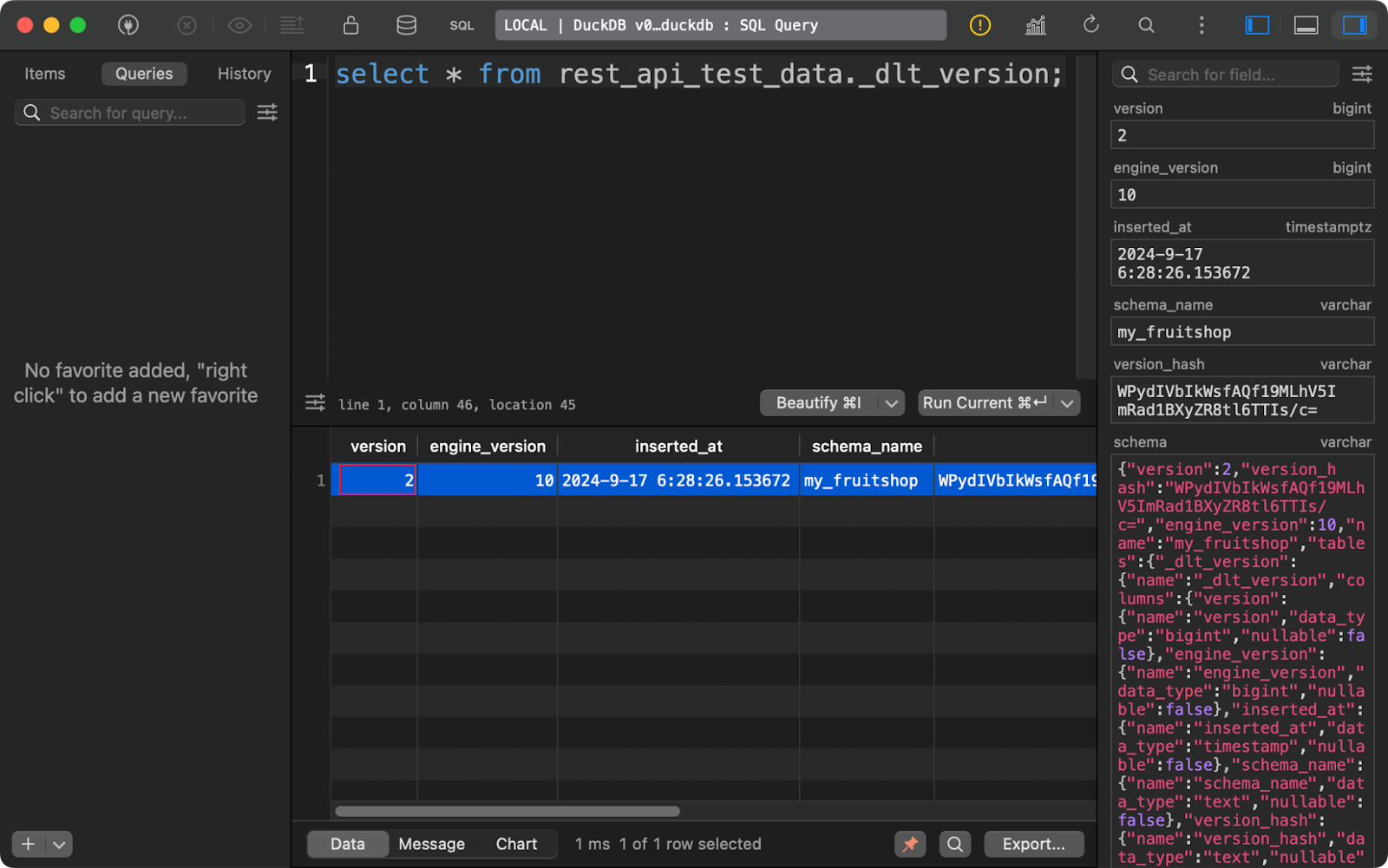
dlt version tabelle
Zusammengenommen liefern diese drei Tabellen alle Details, die du im Laufe der Zeit verfolgen möchtest, um deine Datenpipelines effektiv zu verwalten.
Du hast jetzt einen Überblick darüber, wie dlt funktioniert. Als Nächstes zeige ich dir, wie du Daten aus verschiedenen Quellen extrahieren kannst.
In diesem Abschnitt werde ich vier Arten von Datenquellenbehandeln: REST-APIs, Datenbanken, Cloud-Speicher und lokales Dateisystem.
REST-APIs sind das Herzstück, wenn es um Quellen für Datenpipelines geht. Die Bibliothek dlt macht die Arbeit mit ihnen zum Kinderspiel.
Zur Veranschaulichung verwende ich die JSONPlaceholder-API, die unter anderem Endpunkte zum Abrufen von Beiträgen, Kommentaren und Benutzern hat. Als Datenziel wähle ich DuckDB, da es keine Konfiguration erfordert.
Um eine Verbindung zu einer REST-API herzustellen, verwendest du die Funktion rest_api_source(). Du kannst ein Wörterbuch übergeben, das die Basis-API-URL und die Paginierungsregeln enthält. Du kannst auch andere Eigenschaften hinzufügen, z. B. für die Authentifizierung, aber die von mir gewählte API ist öffentlich zugänglich, sodass sie nicht benötigt wird.
Der interessante Teil kommt von der resources Eigenschaft. Hier gibst du eine Liste von Endpunkten an, von denen dlt die Daten abrufen soll. Zum Beispiel wird die Ressource posts mit https://jsonplaceholder.typicode.com/posts verbunden. Du kannst die einzelnen Ressourcen noch viel genauer einstellen, aber das überlasse ich dir.
Der Rest dieser Python-Datei bleibt mehr oder weniger unverändert:
import dlt
from dlt.sources.rest_api import rest_api_source
def load_rest_api_data() -> None:
data_source = rest_api_source({
"client": {
"base_url": "https://jsonplaceholder.typicode.com/",
"paginator": {
"type": "json_response",
"next_url_path": "paging.next"
}
},
"resources": [
"posts",
"comments",
"users"
]
})
pipeline = dlt.pipeline(
pipeline_name="rest_api_jsonplaceholder",
destination="duckdb",
dataset_name="jsonplaceholder"
)
load_info = pipeline.run(data_source)
print(load_info)
if __name__ == "__main__":
load_rest_api_data()Nachdem du die Pipeline gestartet hast, siehst du drei Tabellen, eine für jede angegebene Ressource.
Das erste Bild zeigt Dummy-Posten:
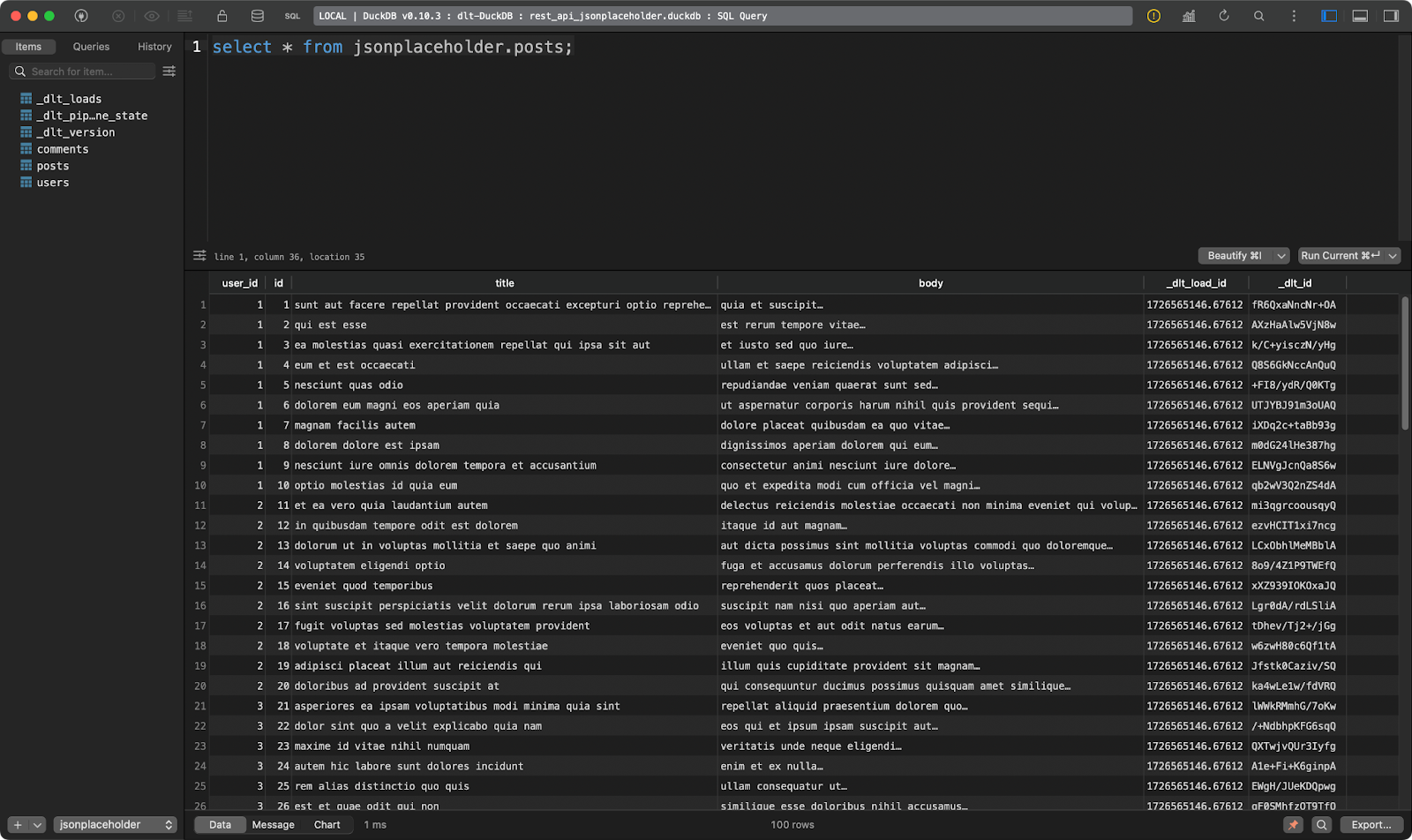
Posts Tabelle
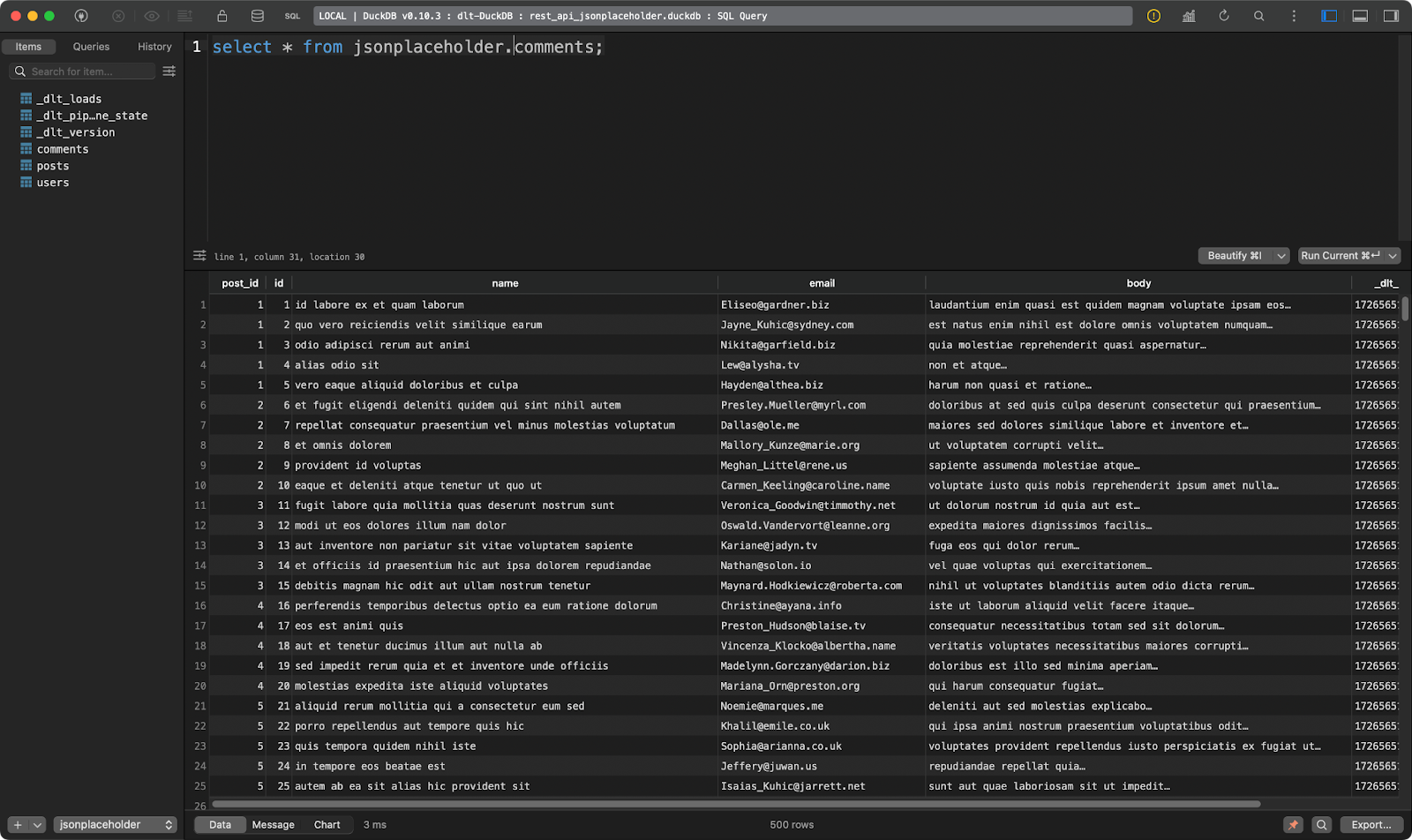
Der zweite zeigt die Kommentare zu den Posts:
Kommentare Tabelle
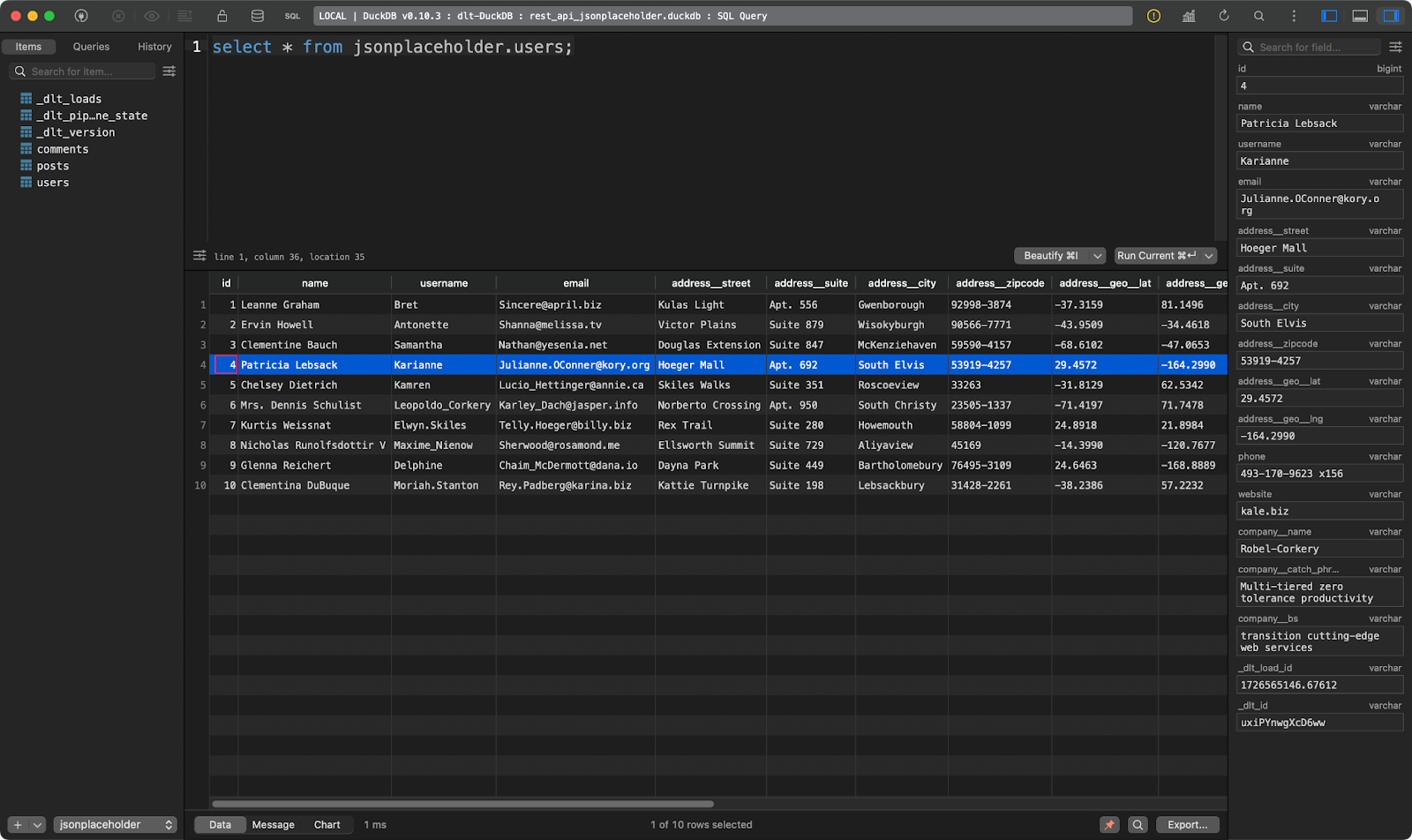
Und der dritte zeigt die Nutzer. Dieser ist interessant, weil er verschachtelte JSON-Daten enthält. Die Bibliothek dlt hat sie geglättet, so dass sie ohne Probleme in einer einzigen Tabelle gespeichert werden können:
users Tabelle
Toll, nicht wahr? Du musst JSON nicht mehr manuell parsen.
Wenn es eine Datenquelle gibt, die häufiger genutzt wird als REST-APIs, dann ist es eine relationale Datenbank.
Zur Veranschaulichung habe ich eine Free-Tier-Postgres-Datenbank auf AWS zur Verfügung gestellt:
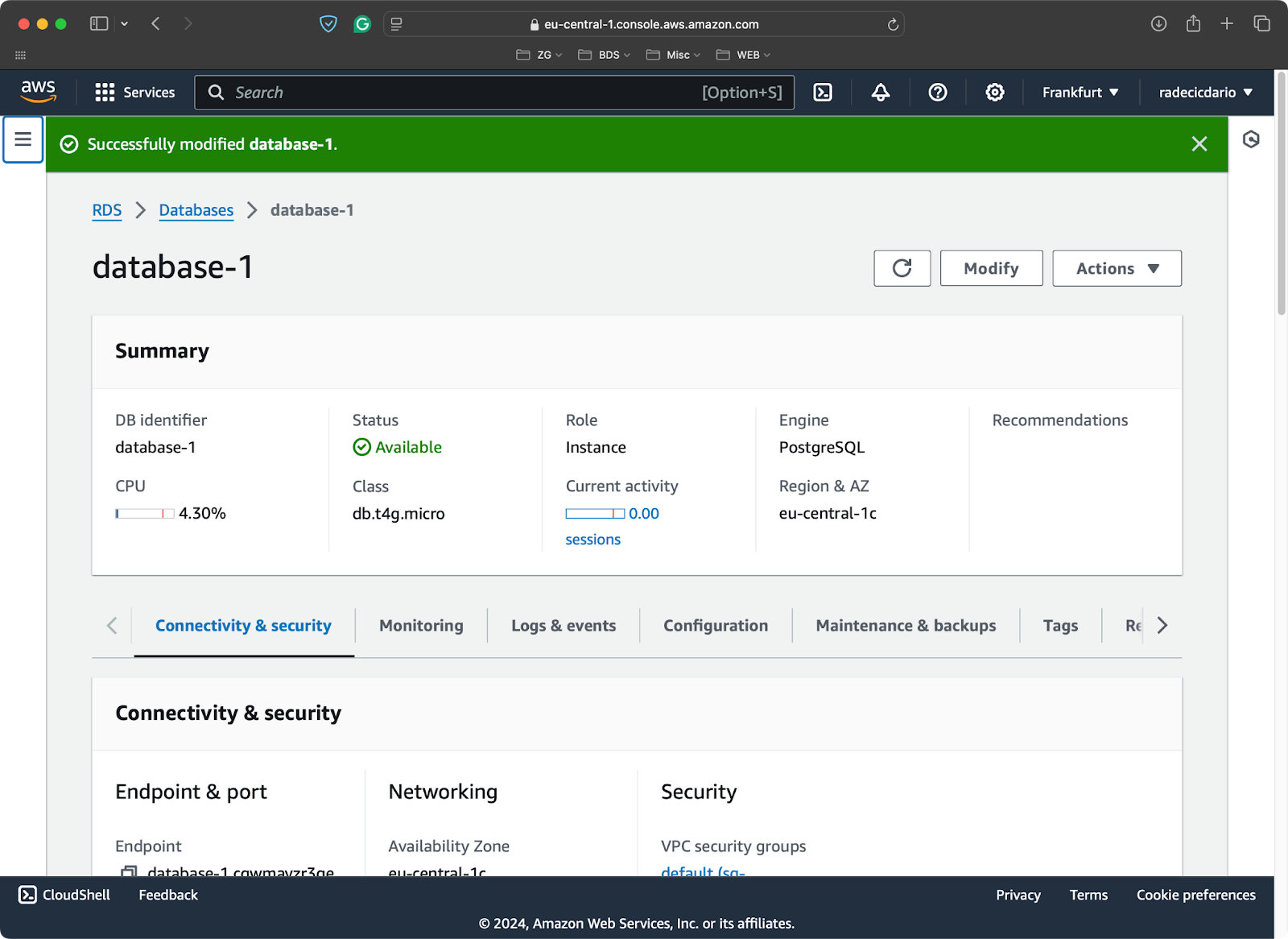
PostgreSQL-Datenbank auf AWS
und lud den bekannten Iris-Datensatz als Tabelle hinein:
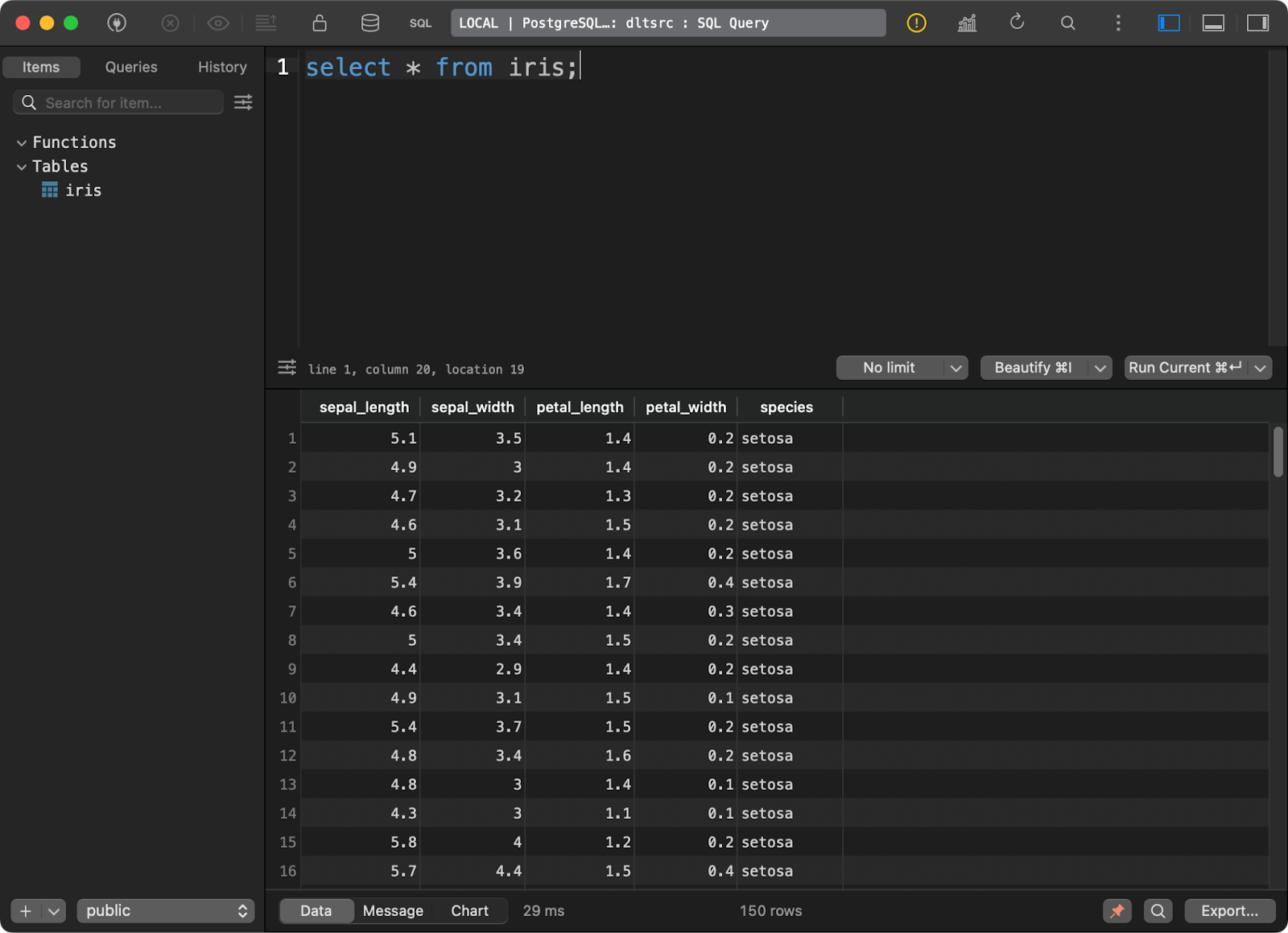
Daten in der Postgres-Datenbank
Ich zeige dir jetzt, wie du dich von dlt aus mit einer Postgres-Quelle verbinden kannst. Es ist ein komplizierterer Prozess, als du vielleicht zunächst denkst.
Installieren Sie zunächst ein Submodul für die Arbeit mit SQL-Datenbanken:
pip install "dlt[sql_database]"Dann initialisierst du eine Pipeline, die eine generische SQL-Datenbank als Quelle und DuckDB als Ziel verwendet:
dlt init sql_database duckdbDies ist das erste Mal, dass du mit den Dateien im Ordner .dtl herumspielst. Gib unter config.toml den Namen der Quelltabelle an, aus der du die Daten extrahieren möchtest:
[sources.sql_database]
table = "table" # please set me up!
[runtime]
dlthub_telemetry = trueErsetze ”table” durch “iris” und du bist startklar.
In secrets.toml musst du die Verbindungsparameter für die Verbindung mit der Quelldatenbank angeben. Beachte, dass du unbedingt [sources.sql_database.credentials] name hinzufügen musst, bevor du Verbindungsparameter angibst. Sonst weiß dlt nicht, worauf sie sich beziehen:
[sources.sql_database.credentials]
drivername = "drivername" # please set me up!
database = "database" # please set me up!
password = "password" # please set me up!
username = "username" # please set me up!
host = "host" # please set me up!
port = 0 # please set me up!Und das war's mit der Konfiguration. Du kannst jetzt zur Python-Pipeline-Datei wechseln.
Lange Rede, kurzer Sinn: Du musst nur die Funktion sql_database() aufrufen, um dich mit der Datenbank zu verbinden und die Quelldaten zu extrahieren. Alle Konfigurationsdetails sind in den TOML-Dateien festgelegt, so dass du diese Funktion ohne Parameter aufrufen kannst.
Der Rest des Drehbuchs bringt nichts Neues:
import dlt
from dlt.sources.sql_database import sql_database
def load_database_data() -> None:
source = sql_database()
pipeline = dlt.pipeline(
pipeline_name="postgres_to_duckdb_pipeline",
destination="duckdb",
dataset_name="iris_from_postgres"
)
load_info = pipeline.run(source)
print(load_info)
if __name__ == "__main__":
load_database_data()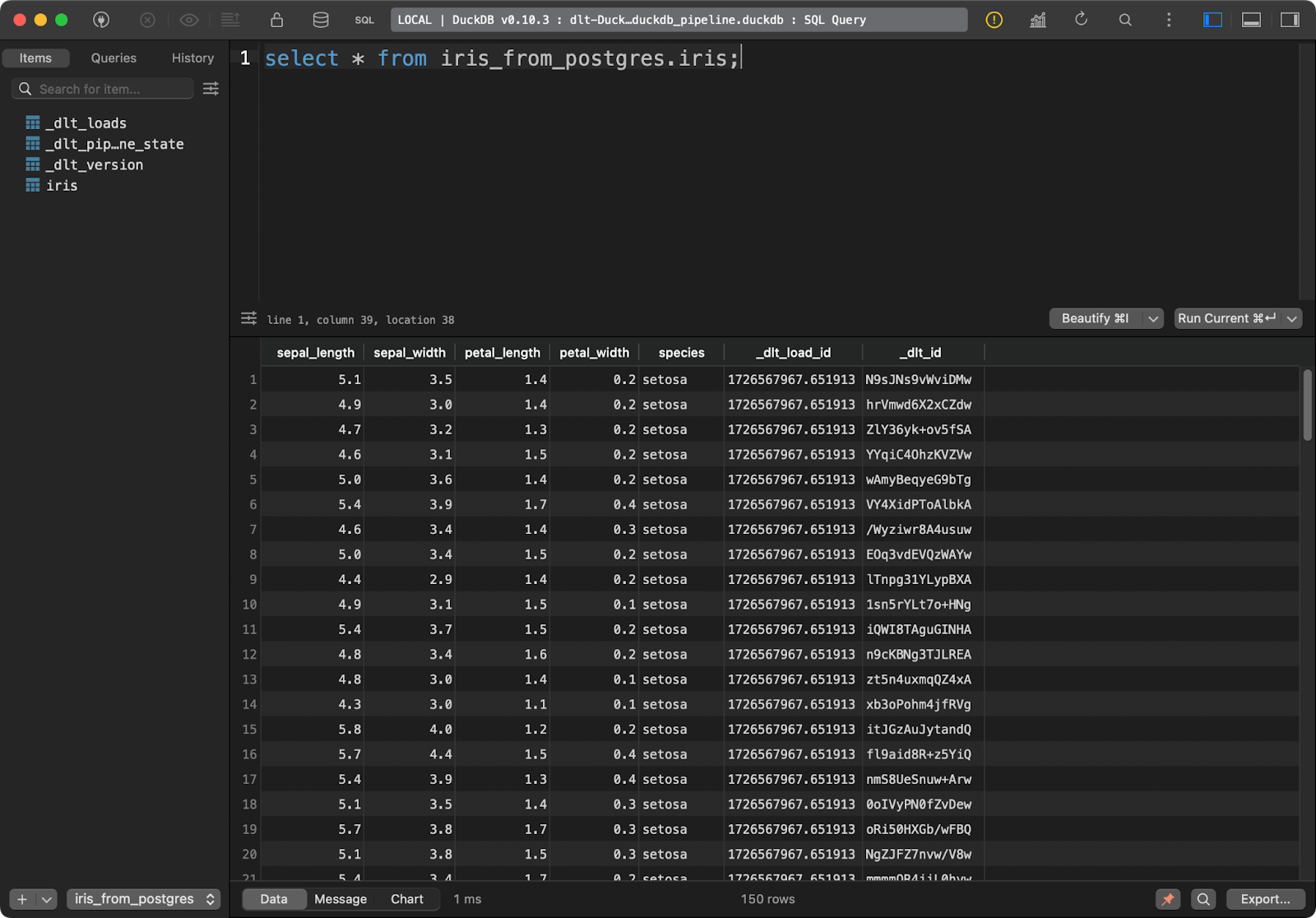
Iris-Tabelle
Die Zieltabelle in DuckDB enthält alle Iris-Daten mit den zusätzlichen zwei Spalten für die Datenabfolge.
In den meisten Fällen möchtest du deine Pipelines mit einem Cloud-Speicher wie AWS S3 verbinden.
Für diesen Artikel habe ich einen S3-Bucket erstellt und eine einzelne Parquet-Datei mit Datensätzen aus den NYC Taxifahrten:
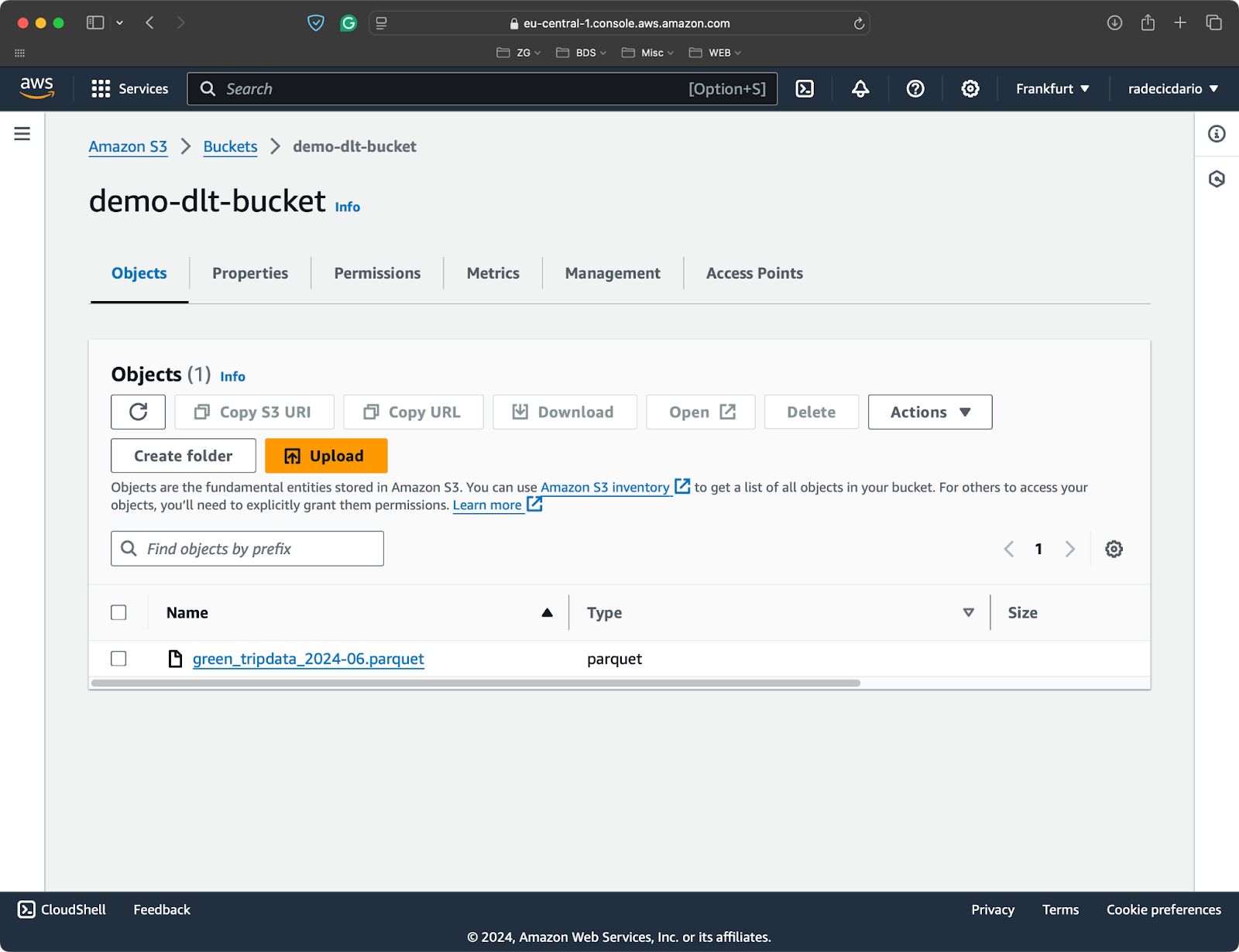
S3 Bucket mit einer einzelnen Parquet-Datei
Um ein lokales oder entferntes Dateisystem mit dlt zu verbinden, musst du ein zusätzliches Submodul installieren:
pip install "dlt[filesystem]"Du kannst jetzt eine neue Pipeline initialisieren, die ein Dateisystem als Quelle und DuckDB als Ziel verwendet:
dlt init filesystem duckdbAls Erstes musst du die Konfigurationsdateien ausfüllen. Die Datei config.toml benötigt die vollständige URL deines S3-Buckets:
[sources.filesystem]
bucket_url = "bucket_url" # please set me up!
[runtime]
dlthub_telemetry = trueUnd die Datei secrets.toml benötigt Informationen über deine IAM-Rolle (Zugangsschlüssel und geheimer Zugangsschlüssel) sowie die Region, in der dein Bucket bereitgestellt wird:
[sources.filesystem.credentials]
aws_access_key_id = "aws_access_key_id" # please set me up!
aws_secret_access_key = "aws_secret_access_key" # please set me up!
region_name = "region_name" # please set me up!Weiter zum Pipeline-Code.
Verwende die Funktion readers(), um Daten aus deiner konfigurierten Quelle zu lesen. Der Parameter file_glob bestimmt, welche Dateien gelesen werden sollen. Ich habe es so eingerichtet, dass alle Parkettdateienzurückgibt. Dann verkette einfach die Funktion read_parquet(), um die Daten zu lesen:
import dlt
from dlt.sources.filesystem import readers, read_parquet
def load_s3_data() -> None:
source = readers(file_glob="*.parquet").read_parquet()
pipeline = dlt.pipeline(
pipeline_name="s3_to_duckdb_pipeline",
destination="duckdb",
dataset_name="nyc_data_from_s3"
)
load_info = pipeline.run(source.with_name("nyc_taxi_data"))
print(load_info)
if __name__ == "__main__":
load_s3_data()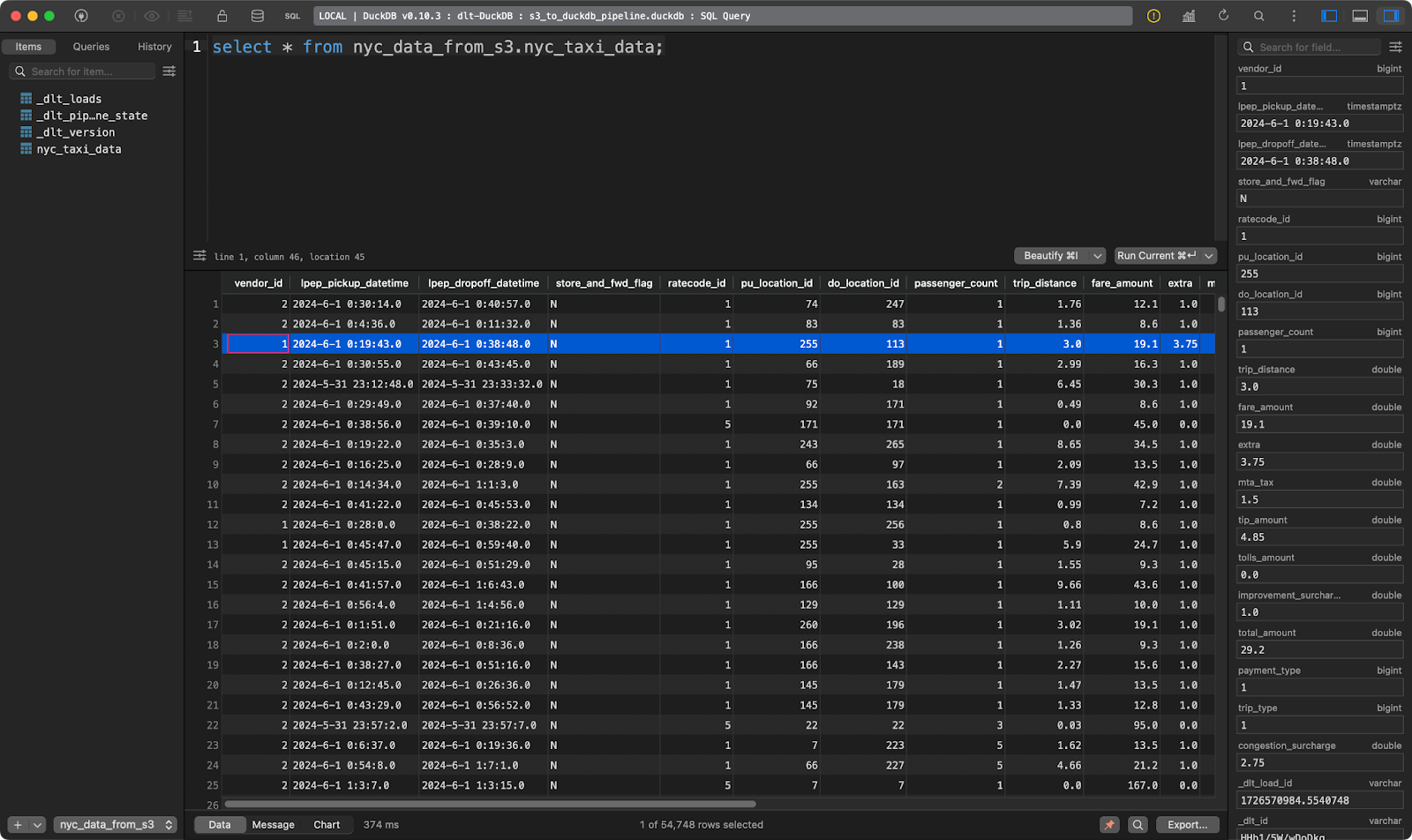
Tabelle der Taxifahrten in NYC
Und schon sind zehntausende von Datensätzen innerhalb von Sekunden geladen!
Das Lesen von Daten aus einem lokalen Dateisystem ist fast identisch mit dem Lesen von Daten aus S3.
Dieses Mal verwende ich den mtcars-Datensatz den ich lokal in einem Ordner localbucket gespeichert habe:
Datei auf einem lokalen System
Gib in deiner config.toml Datei einen absoluten Pfad zu deinem lokalen Ordner an. Es ist wichtig, dem Pfad das Präfix file:/// voranzustellen. Das sind drei Schrägstriche:
[sources.filesystem]
bucket_url = "file:///absolute/path/to/local/folder"
[runtime]
dlthub_telemetry = trueDa du keine Verbindung zu S3 mehr hast, kannst du den Inhalt von secrets.toml löschen.
Der eigentliche Pipeline-Code sieht fast genauso aus wie der aus dem vorherigen Abschnitt. Die einzige Änderung ist, dass du in file_glob jetzt einen Dateinamen angibst und eine andere Funktion zum Lesen der Daten verwendest (CSV-Format):
import dlt
from dlt.sources.filesystem import filesystem, read_csv_duckdb
def load_local_data() -> None:
source = filesystem(file_glob="mtcars.csv") | read_csv_duckdb()
pipeline = dlt.pipeline(
pipeline_name="local_filesystem_to_duckdb_pipeline",
destination="duckdb",
dataset_name="mtcars_data_from_local_disk"
)
load_info = pipeline.run(source.with_name("mtcars"))
print(load_info)
if __name__ == "__main__":
load_local_data()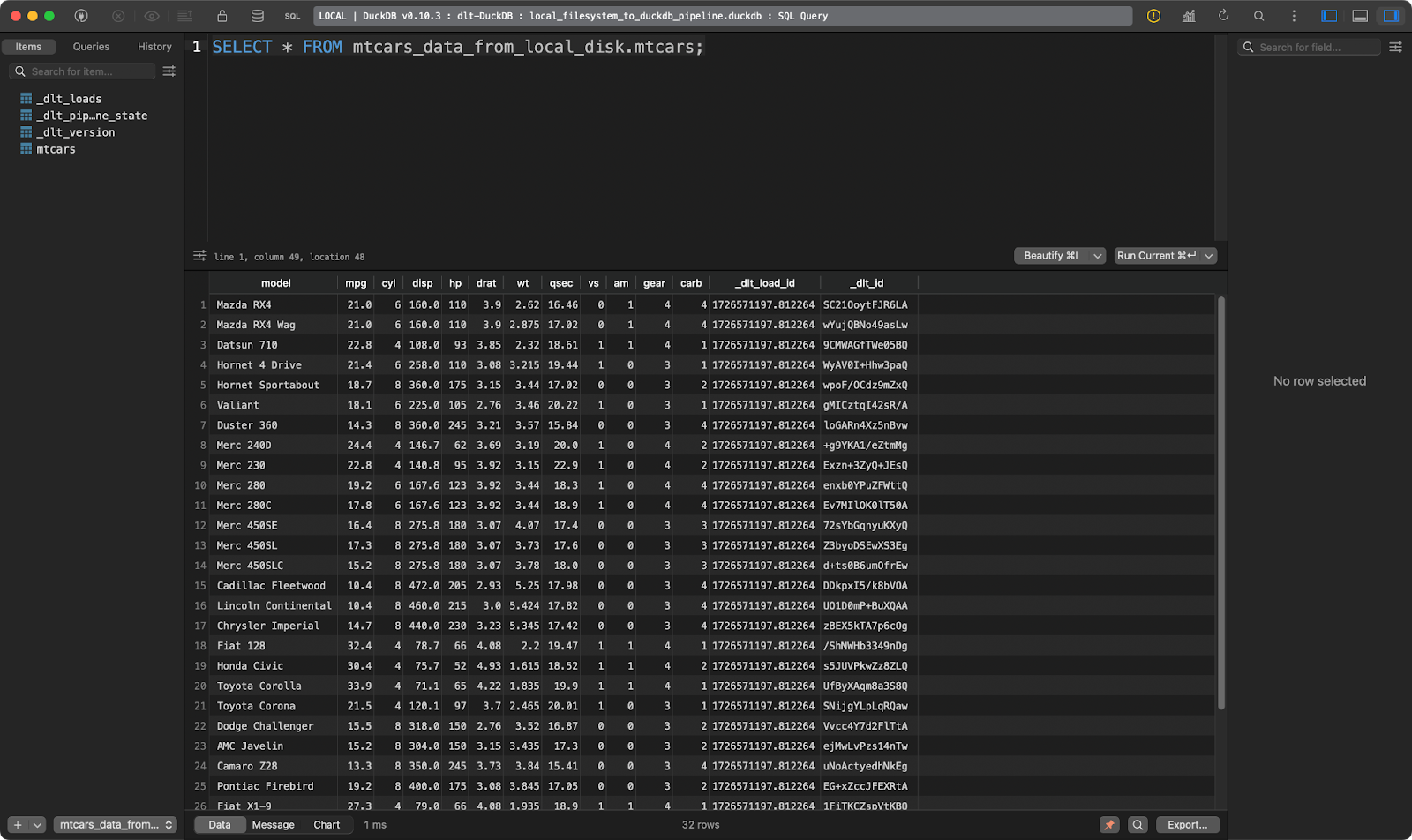
Die Tabelle mtcars
Funktioniert wie ein Zauber!
Das ist alles, was ich zu den Datenquellen sagen will. Auf der dlt-Dokumentationsseite für Datenquellen findest du viele weitere, die deinen speziellen Bedürfnissen entsprechen o.
Es macht keinen Sinn, Daten einfach nur von Punkt A nach Punkt B zu verschieben. In der Regel willst du eine Transformation durchführen, bevor du die Daten an das Ziel schreibst (ETL) oder danach (ELT).
Wenn dir die Akronyme ETL und ELT nichts sagen, empfehlen wir dir,unseren Kurs über Datenpipelines mit Python zu besuchen.
In diesem Abschnitt zeige ich dir, wie du deine Daten mit SQL und Python umwandeln kannst.
Dateningenieure leben und atmen SQL. In diesem Abschnitt zeige ich dir, wie du eine lokale Datei in eine Postgres-Datenbank lädst, sie umwandelst und wieder in eine andere Tabelle (ELT) schreibst.
Beginne damit, die Datei secrets.toml so zu ändern, dass sie die Datenbankverbindungsdetails für Quelle und Ziel enthält. Die Werte werden identisch sein, du musst sie nur zweimal angeben:
[sources.sql_database.credentials]
drivername = "drivername" # please set me up!
database = "database" # please set me up!
password = "password" # please set me up!
username = "username" # please set me up!
host = "host" # please set me up!
port = 0 # please set me up!
[destinations.sql_database.credentials]
drivername = "drivername" # please set me up!
database = "database" # please set me up!
password = "password" # please set me up!
username = "username" # please set me up!
host = "host" # please set me up!
port = 0 # please set me up!In config.toml schreibst du einen absoluten Pfad zu einem Ordner in deinem Dateisystem:
[sources.filesystem]
bucket_url = "file:///absolute/path/to/local/folder"
[runtime]
dlthub_telemetry = trueDie Python-Pipeline-Datei wird zwei Funktionen haben:
load_source_data(): Es lädt eine lokale CSV-Datei und speichert sie in einer Tabelle in einer Postgres-Datenbank.transform_data(): Es extrahiert Daten aus einer Postgres-Tabelle und erstellt eine neue Tabelle auf der Grundlage der ursprünglichen Tabelle. Ich füge nur ein paar Spalten hinzu, um einen Punkt zu beweisen. Die Zieltabelle wird zuerst gelöscht, falls sie existiert.Du wirst die Funktionen nacheinander aufrufen wollen:
import dlt
from dlt.sources.filesystem import filesystem, read_csv
def load_source_data() -> None:
source = filesystem(file_glob="iris.csv") | read_csv()
pipeline = dlt.pipeline(
pipeline_name="load_source_data",
destination="postgres",
dataset_name="data"
)
load_info = pipeline.run(source.with_name("iris_src"), write_disposition="replace")
print(load_info)
def transform_data() -> None:
pipeline = dlt.pipeline(
pipeline_name="transform_data",
destination="postgres",
dataset_name="data"
)
try:
with pipeline.sql_client() as client:
client.execute_sql("""
DROP TABLE iris_tgt;
""")
print(f"Table iris_tgt deleted!")
except Exception as e:
print(f"Table iris_tgt does not exists, proceeding!")
try:
with pipeline.sql_client() as client:
client.execute_sql("""
CREATE TABLE iris_tgt AS (
SELECT
sepal_length,
sepal_width,
petal_length,
petal_width,
sepal_length + sepal_width AS total_sepal,
petal_length + petal_width AS total_petal,
UPPER(species) AS species_upper
FROM iris_src
);
""")
print(f"Table iris_tgt created and filled!")
except Exception as e:
print(f"Unable to transform data! Error: {str(e)}")
if __name__ == "__main__":
load_source_data()
transform_data()Die Tabelle enthält den Iris-Datensatz mit zwei zusätzlichen Spalten für die Datenabfolge:
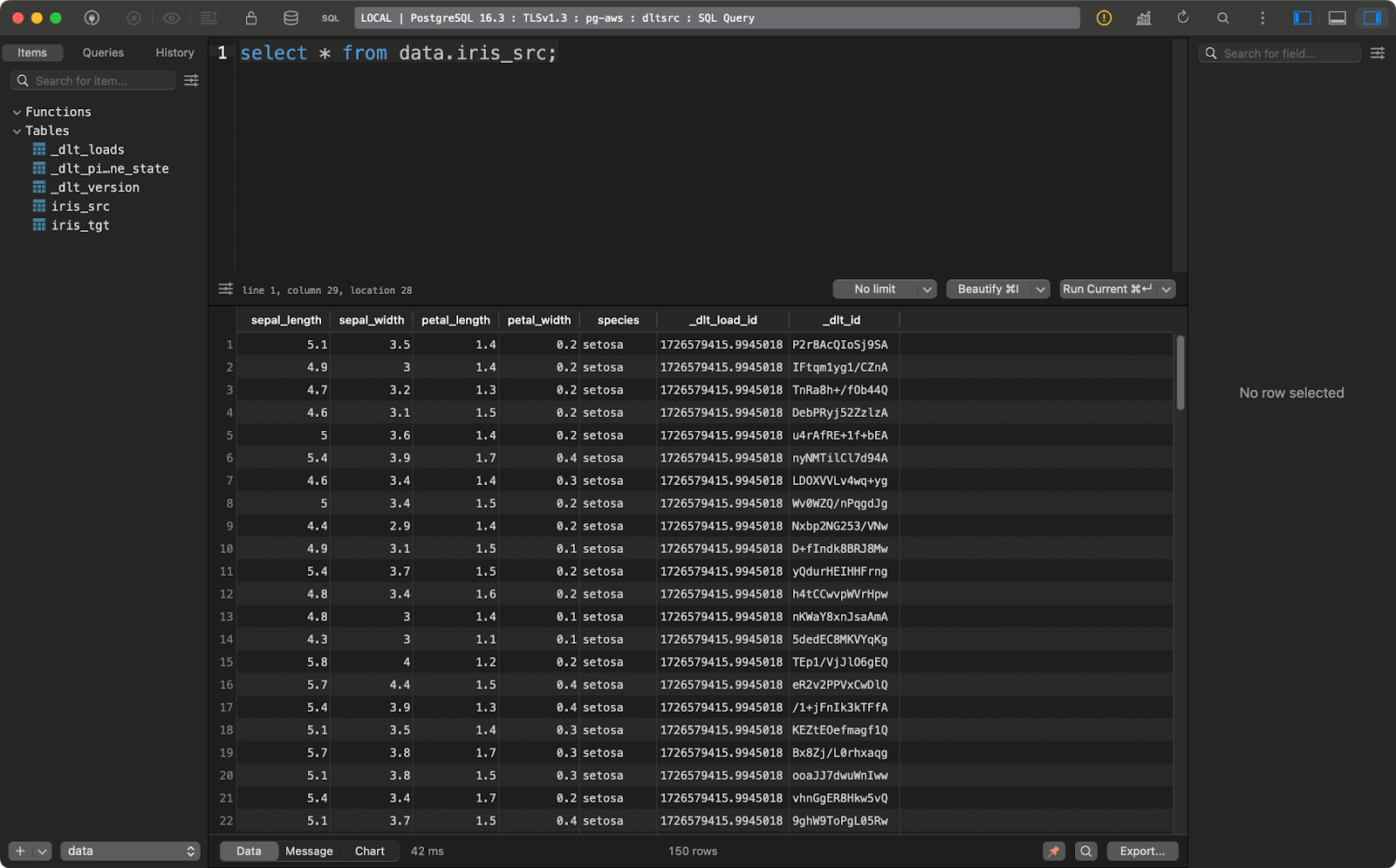
Tabelle der Irisquelle
Und die Zieltabelle enthält die transformierte Version des Iris-Datensatzes:
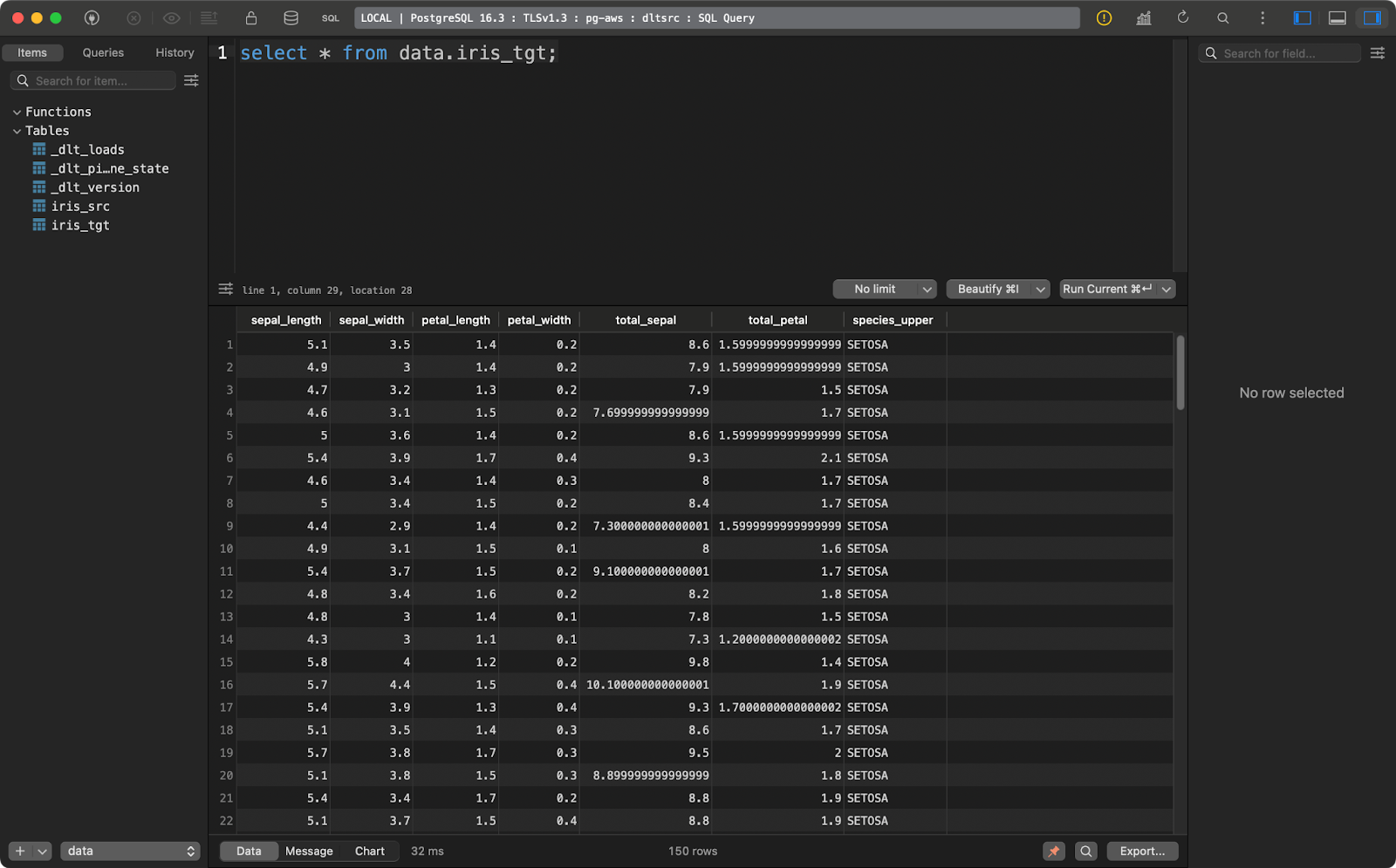
Iris Zieltabelle
Dieses Transformationsbeispiel ist ziemlich einfach, erklärt aber, wie du deine Daten transformierst, wenn sie bereits in das Ziel geladen sind.
Was, wenn du die Daten umwandeln willst , bevor du sie in die Datenbank schreibst? Mit anderen Worten: Wenn du keine rohen und umgewandelten Daten speichern willst? Das ist im Grunde die Beschreibung einer ETL-Pipeline. Ich zeige dir, wie du sie mit pandas umsetzen kannst.
Deine TOML-Dateien bleiben unverändert.
Im Code der Pipeline musst du nun ein paar zusätzliche Funktionen implementieren:
extract_data(): Verwendet pandas, um eine lokale CSV-Datei zu lesen.transform_data(): Wendet Datenumwandlungen mit pandas statt mit SQL an.data(): Eine mit @dlt.resource verzierte Funktion, die den transformierten Datensatz liefert.load_data(): Lädt die dlt.resource in die Tabelle iris_tgt.Der Code dieser Pipeline wird dir vertraut vorkommen, wenn du Erfahrung mit pandas hast:
import dlt
import pandas as pd
def extract_data() -> pd.DataFrame:
return pd.read_csv("iris.csv")
def transform_data(df: pd.DataFrame) -> pd.DataFrame:
df["sepal_sum"] = df["sepal_length"] + df["sepal_width"]
df["petal_sum"] = df["petal_length"] + df["petal_width"]
df = df.drop(["sepal_length", "sepal_width", "petal_length", "petal_width"], axis=1)
return df
@dlt.resource
def data():
yield transform_data(df=extract_data())
def load_data() -> None:
pipeline = dlt.pipeline(
pipeline_name="pandas_etl_pipeline",
destination="duckdb",
dataset_name="data"
)
load_info = pipeline.run(data(), table_name="iris_tgt")
print(load_info)
if __name__ == "__main__":
load_data()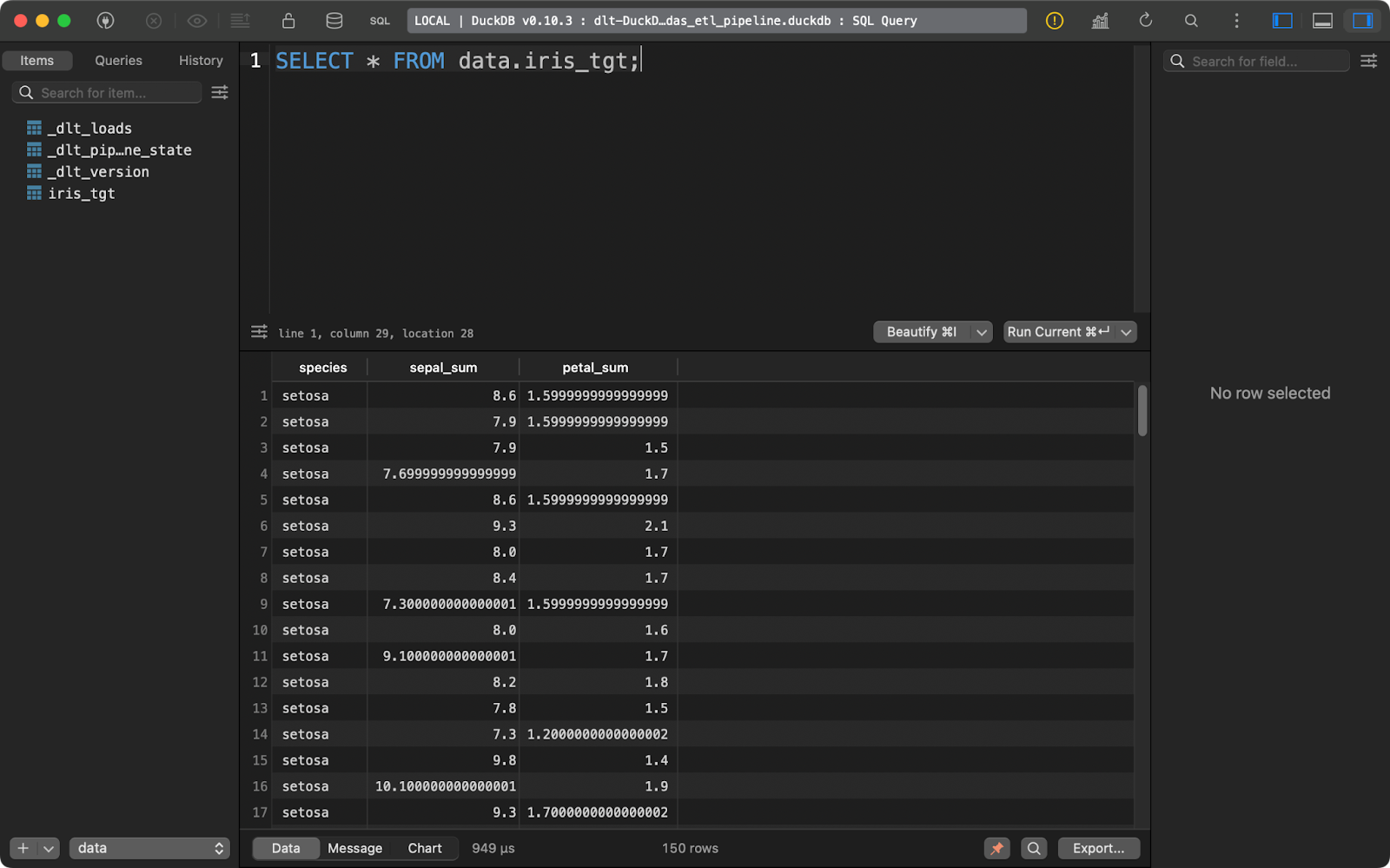
Iris Zieltabelle
Auch hier gilt: dlt wurde mit Blick auf ELT entwickelt, aber die ETL-Workflows erfordern nicht allzu viele Codeänderungen.
Sowohl SQL als auch pandas sind einfache Möglichkeiten, Daten vor und nach dem Laden in das Ziel zu transformieren.
Die Autoren von dlt empfehlen,stattdessen das dbt von Pythonzu verwenden. Es ist eine viel bessere und vielseitigere Option, aber es ist ein zu komplexes Werkzeug, als dass wir es in einem einzigen Artikel behandeln könnten. Wenn du oder dein Team bereits dbt nutzt, wird sich die Verwendung in dlt Pipelines wie eine natürliche Erweiterung anfühlen.
Wenn du mehr über dbt in Python erfahren möchtest, haben wir einen vollständigen 4-Module langen Kurs zur Verfügung.
Wenn du jedoch ein Anfänger mit grundlegenden SQL- und pandas -Kenntnissen bist, reichen die beiden von mir gezeigten Transformationsansätze für den Anfang aus.
Bislang habe ich DuckDB als Ziel verwendet, weil es einfach ist und keine Einrichtung erfordert. In diesem Abschnitt zeige ich dir, wie du mit ein paarf mehr Zielen arbeitest,darunter ein lokales Dateisystem, Cloud-Speicher und Datenbanken.
Manchmal möchtest du das Ergebnis einer Datenpipeline auf der Festplatte speichern. dlt ist zwar nicht der perfekte Kandidat für diese Aufgabe, da es auch viele Metadaten speichert, aber du kannst es verwenden, wenn du es unbedingt brauchst.
Beginne damit, die Datei config.toml zu optimieren. Gib die Pfade zu den Quell- und Zielordnern auf deinem lokalen System an:
[sources.filesystem]
bucket_url = "file:///path/to/source/folder"
[destination.filesystem]
bucket_url = "file:///path/to/target/folder"
[runtime]
dlthub_telemetry = trueIn der Python-Datei lädst du nun einfach die Quelldatei aus einem Dateisystem und lässt sie durch die Pipeline laufen. Der Einfachheit halber habe ich keine Datenumwandlungen vorgenommen:
import dlt
from dlt.sources.filesystem import filesystem, read_csv
def load_local_data() -> None:
source = filesystem(file_glob="iris.csv") | read_csv()
pipeline = dlt.pipeline(
pipeline_name="local_to_local",
destination="filesystem",
dataset_name="data"
)
load_info = pipeline.run(source.with_name("iris"), loader_file_format="csv")
print(load_info)
if __name__ == "__main__":
load_local_data()Dies ist der Inhalt des Zielordners:
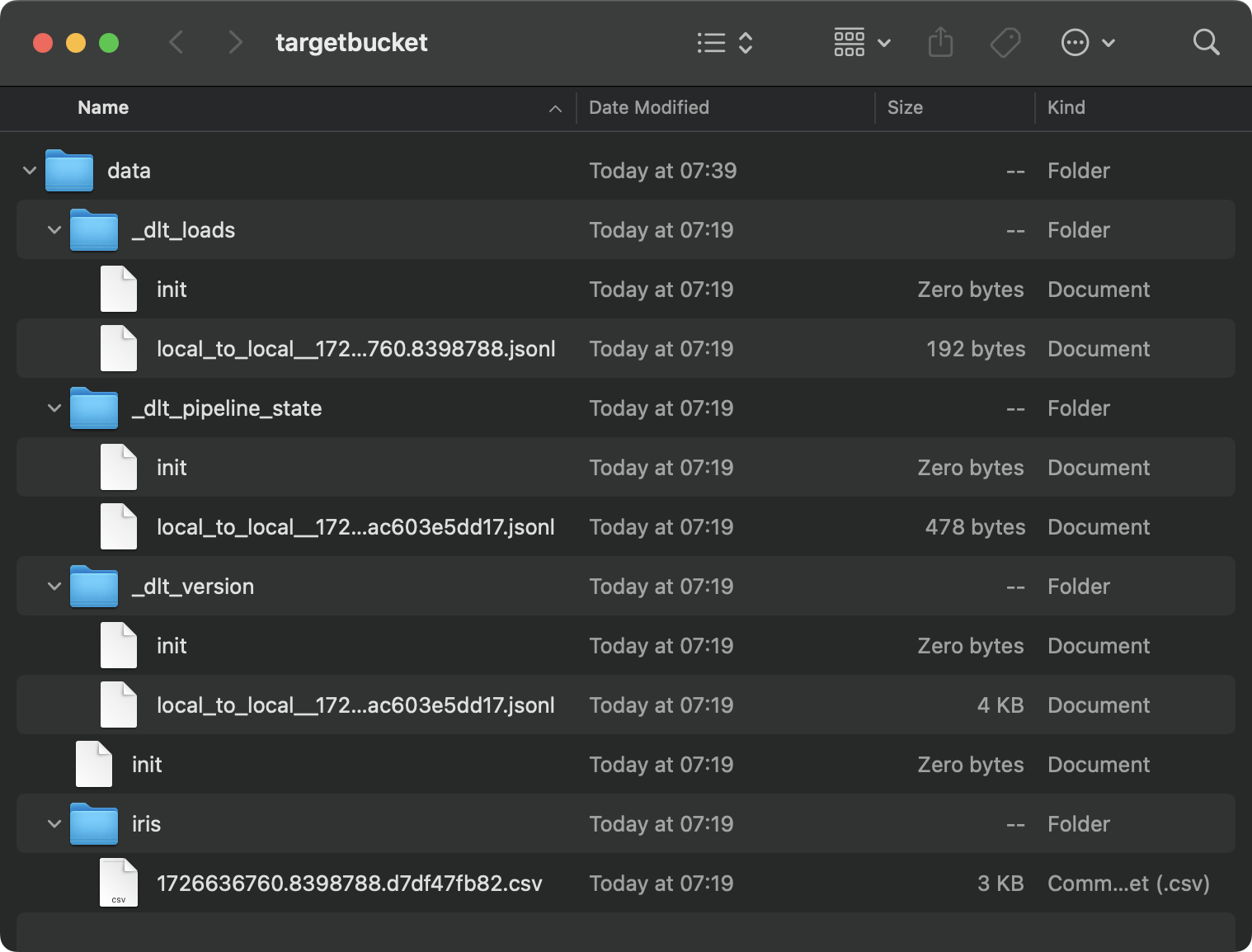
Lokale Ordnerinhalte
Es ist ein Chaos, und das ist nur das Ergebnis einer einzigen Pipeline. Stell dir vor, du hättest Dutzende davon.
Datenbanken sind ein natürlicherer Ort um diese Informationen zu speichern.
Ich verwende eine Postgres-Datenbank, die auf AWS bereitgestellt wird, aber das musst du nicht. Du kannst auch andere Datenbanken und Cloud-Anbieter verwenden.
In config.toml musst du einen Pfad zu dem Ordner in deinem lokalen Dateisystem angeben:
[sources.filesystem]
bucket_url = "file:///your-local-bucket"
[runtime]
dlthub_telemetry = trueUnd schreibe in secrets.toml die Details zur Datenbankverbindung:
[destination.postgres.credentials]
drivername = "drivername" # please set me up!
database = "database" # please set me up!
password = "password" # please set me up!
username = "username" # please set me up!
host = "host" # please set me up!
port = 0 # please set me up!Das Laden von Quelldaten in die Datenbank läuft nun darauf hinaus, den Wert für den Parameter destination in dlt.pipeline() zu ändern. Die Funktion with_name(), die in der Datenquelle aufgerufen wird, bestimmt, wie die Tabelle in der Datenbank benannt wird:
import dlt
from dlt.sources.filesystem import filesystem, read_csv
def load_to_database() -> None:
source = filesystem(file_glob="iris.csv") | read_csv()
pipeline = dlt.pipeline(
pipeline_name="local_to_db",
destination="postgres",
dataset_name="local_load"
)
load_info = pipeline.run(source.with_name("iris_from_local"))
print(load_info)
if __name__ == "__main__":
load_to_database()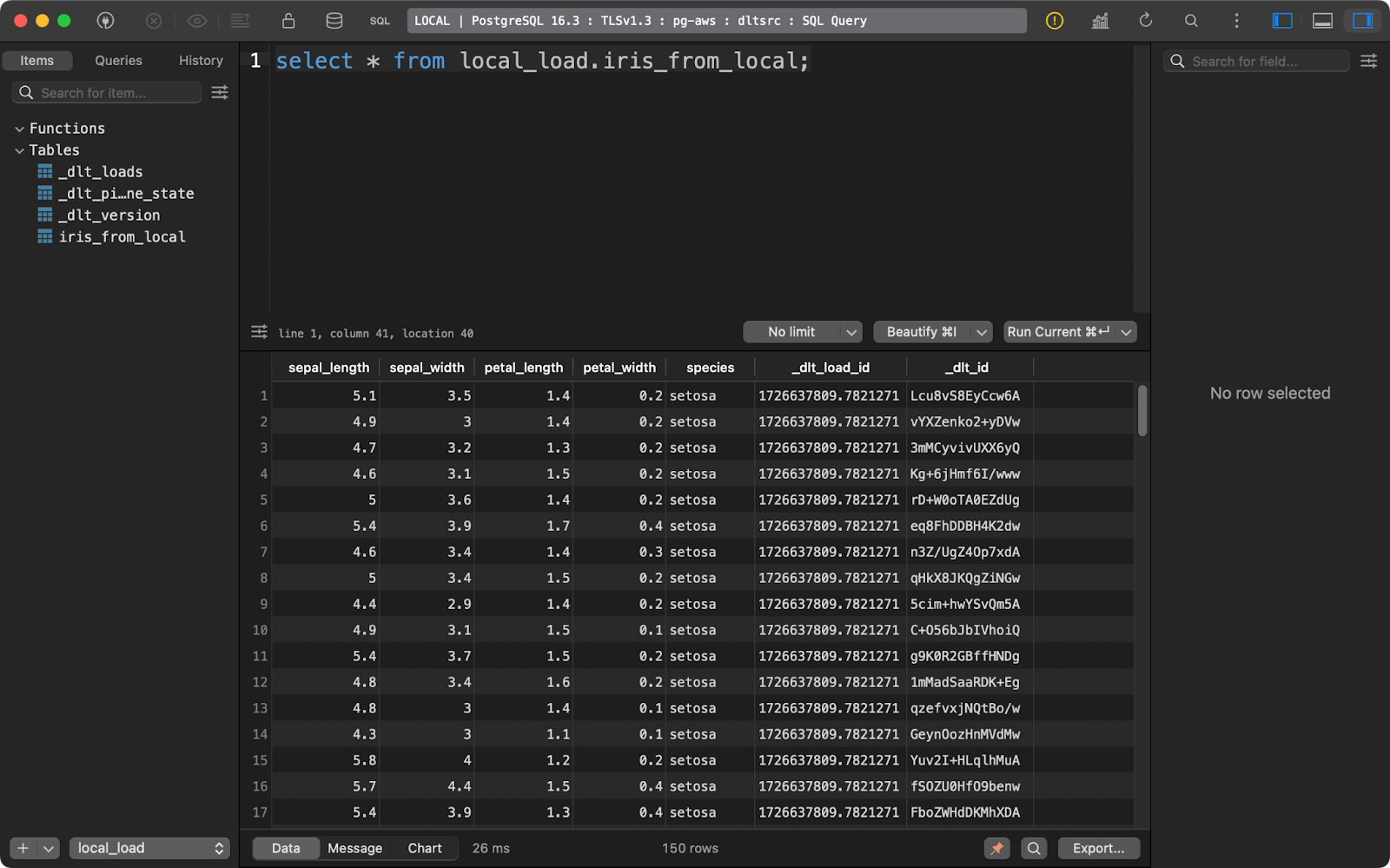
Geladene Irisdaten
Lasst uns noch eine weitere Option für ein Reiseziel erkunden, bevor wir uns mit den fortgeschritteneren dlt Dingen beschäftigen.
Genau wie dein lokales Dateisystem speichert auch der Cloud-Speicher (z. B. S3) Metadaten in separaten Dateien und Ordnern.
Wenn du es ausprobieren möchtest, passe die Datei config.toml so an, dass sie Pfade zu einem lokalen Ordner und dem S3-Bucket enthält:
[sources.filesystem]
bucket_url = "file:///path/to/local/folder"
[destination.filesystem]
bucket_url = "s3://bucket-name"
[runtime]
dlthub_telemetry = trueUnter secrets.toml gibst du deine IAM-Zugangsdaten und den Namen der S3-Bucket-Region ein:
[destination.filesystem.credentials]
aws_access_key_id = "aws_access_key_id" # please set me up!
aws_secret_access_key = "aws_secret_access_key" # please set me up!
region_name = "region_name" # please set me up!Wenn du die Pipeline ausführst, wird die lokale CSV-Datei an S3 übertragen und im JSONL-Format (JSON-Zeilen) gespeichert:
import dlt
from dlt.sources.filesystem import filesystem, read_csv
def load_to_s3() -> None:
source = filesystem(file_glob="iris.csv") | read_csv()
pipeline = dlt.pipeline(
pipeline_name="local_to_db",
destination="filesystem",
dataset_name="iris_data"
)
load_info = pipeline.run(source.with_name("iris"))
print(load_info)
if __name__ == "__main__":
load_to_s3()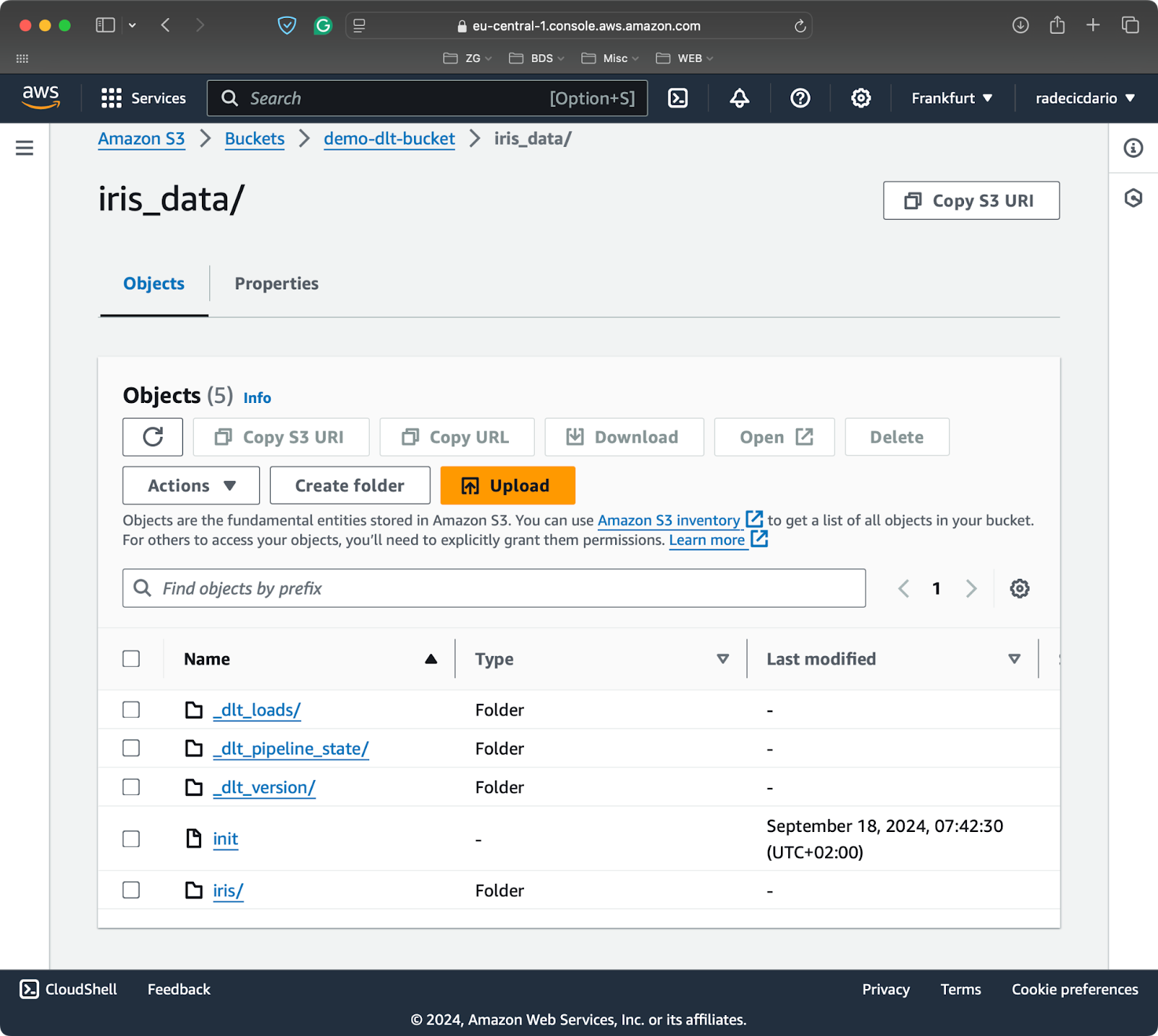
Inhalt des S3-Eimers
Du kennst jetzt die Grundlagen für das Verschieben von Daten und ihre Umwandlung auf dem Weg dorthin. Aber was passiert, wenn du die Pipeline mehrmals laufen lässt? Darauf werde ich als Nächstes eingehen.
Du wirst die Pipeline fast nie nur einmal durchlaufen. Normalerweise werden Pipeline-Läufe zum Beispiel einmal pro Tag oder einmal pro Woche geplant.
Wenn das der Fall ist, möchtest du wahrscheinlich mehr Kontrolle darüber haben, wie neue Daten eingefügt werden und wie bestehende Daten aktualisiert werden.
Jedes Mal, wenn du deine Pipeline ausführst, werden neue Daten an die Tabelle deiner Wahl angehängt.
Ich zeige dir das, indem ich eine einfache Pipeline schreibe, die einen Pandas DataFrame in eine DuckDB Tabelle einfügt:
import dlt
import pandas as pd
@dlt.resource(primary_key="index")
def data():
data = pd.DataFrame({
"index": [1, 2, 3, 4, 5],
"a": [10, 15, 20, 25, 30],
"b": [22.5, 30.5, 35.5, 50.5, 10.5],
"c": ["row 1", "row 2", "row 3", "row 4", "row 5"]
})
yield data
def load_local_data() -> None:
pipeline = dlt.pipeline(
pipeline_name="pipeline_incremental_load",
destination="duckdb",
dataset_name="data"
)
load_info = pipeline.run(data=data(), table_name="dataset")
print(load_info)
if __name__ == "__main__":
load_local_data()Wenn du die Pipeline einmal ausführst, werden fünf Datenzeilen eingefügt:
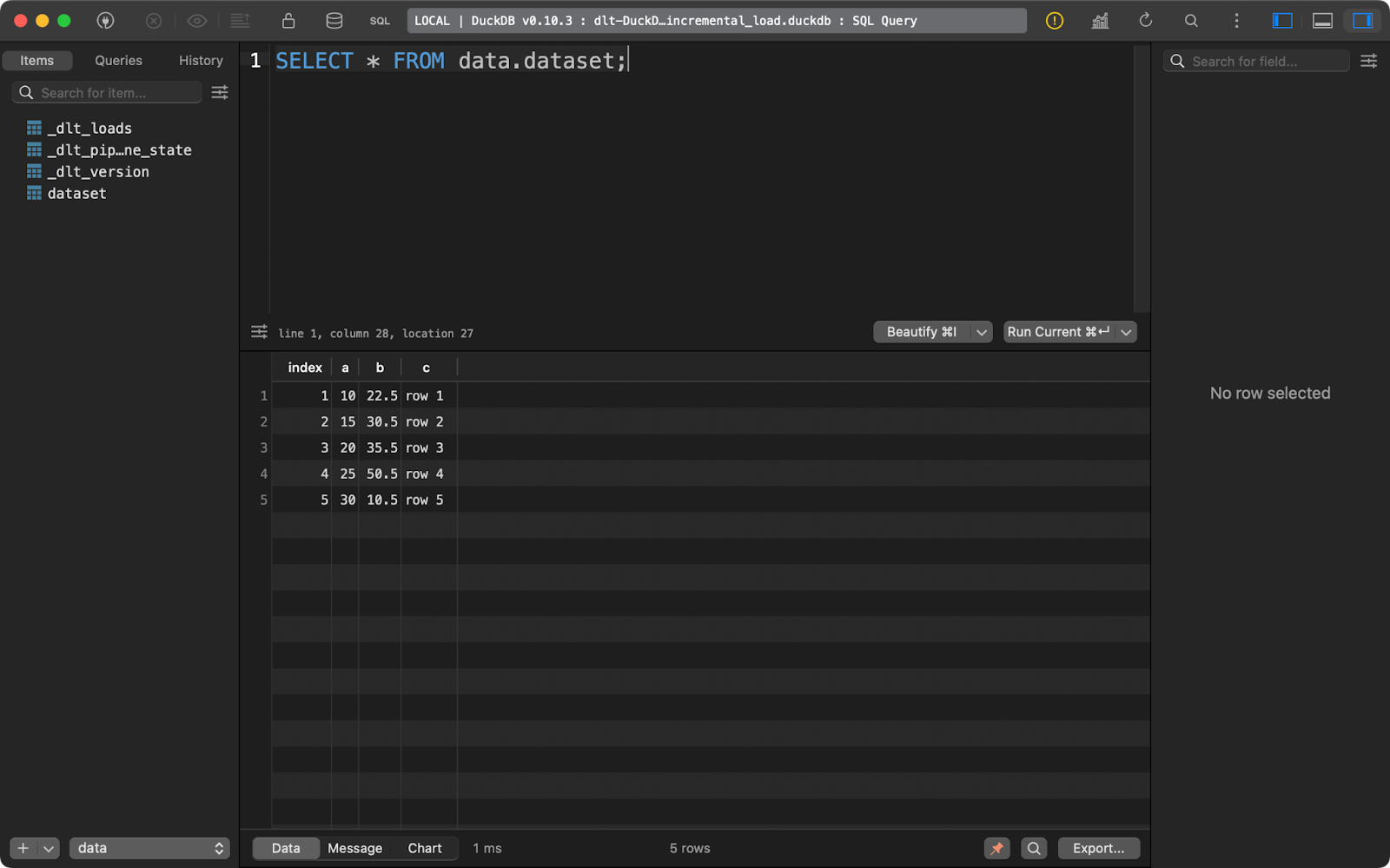
Erster Append-Lauf
Wenn du ihn erneut ausführst, werden die gleichen fünf Zeilen eingefügt:
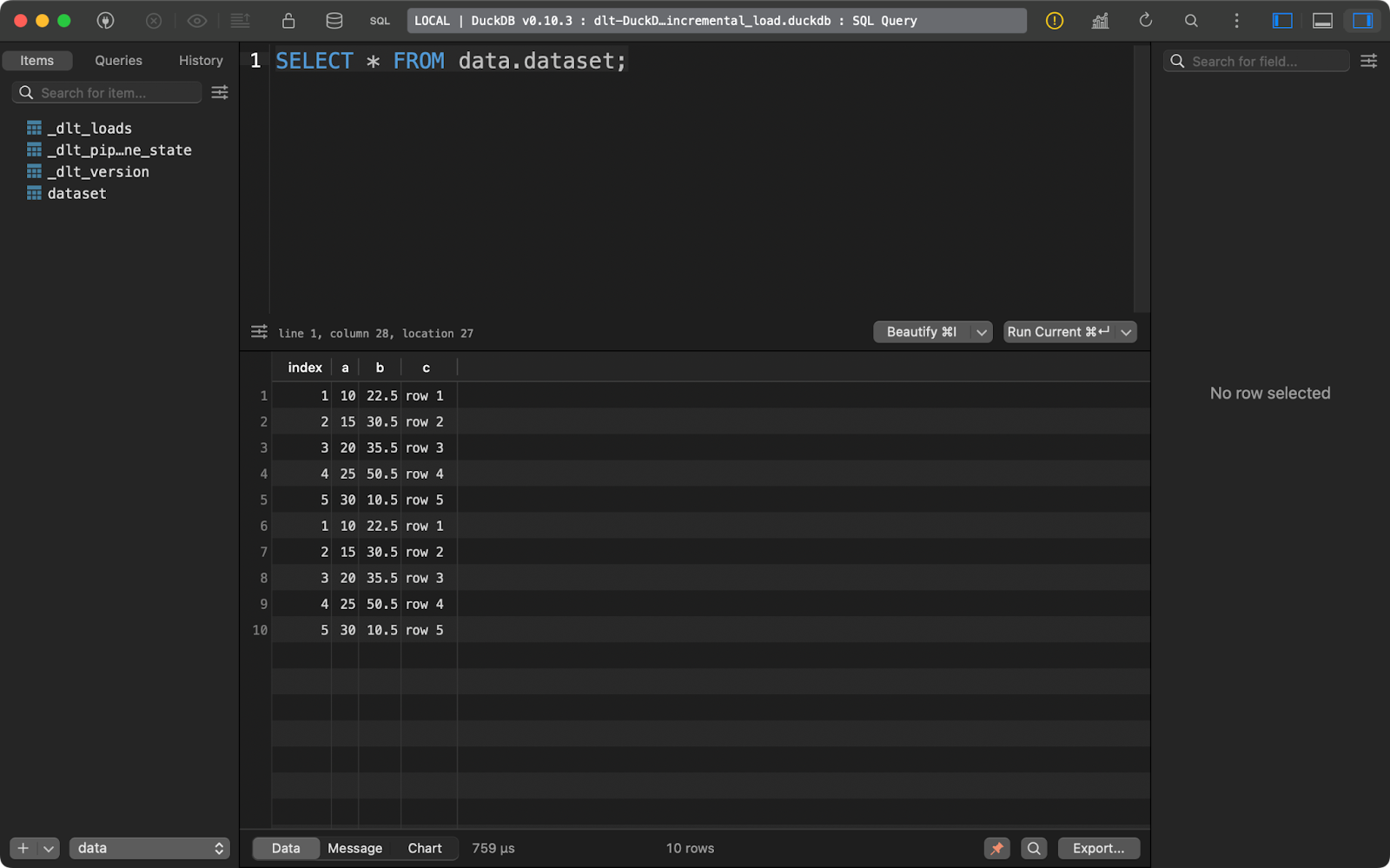
Zweiter Append-Lauf
Bei dieser Art von Daten ist es einfach, eine Schlussfolgerung zu ziehen - es handelt sich um Duplikate. Ich zeige dir, was du dagegen tun kannst.
Wenn du bestehende Datensätze löschen und durch neue ersetzen willst, füge write_disposition=”replace” zu pipeline.run() hinzu:
load_info = pipeline.run(data=data(), table_name="dataset", write_disposition="replace")Nachdem ich das getan habe, habe ich die Pipeline viermal durchlaufen lassen, wie du in der Tabelle _dlt_loads mit den Metadaten sehen kannst:
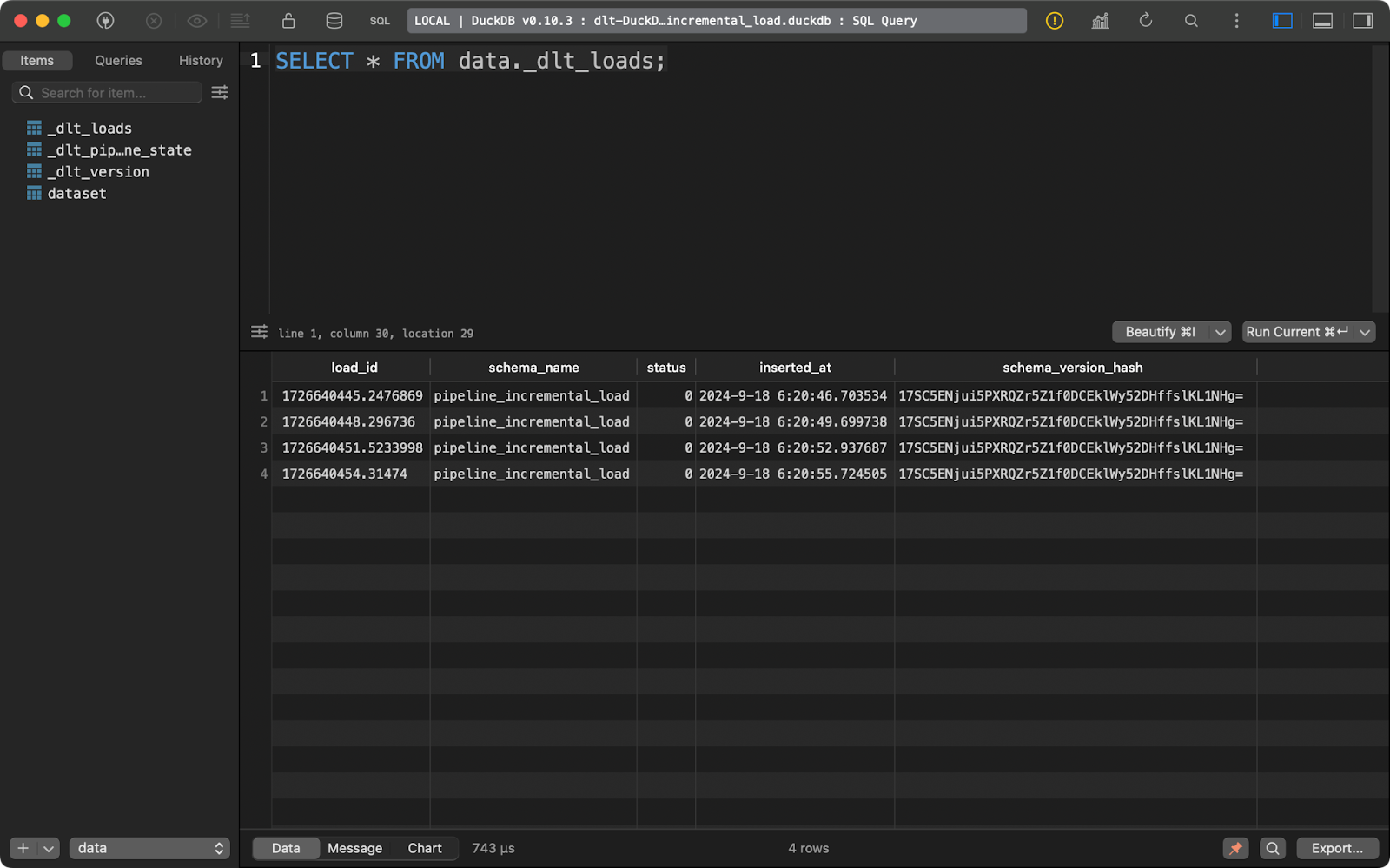
Mehrmaliges Ausführen der Pipeline
Und die Tabelle dataset enthält nur 5 Datensätze:
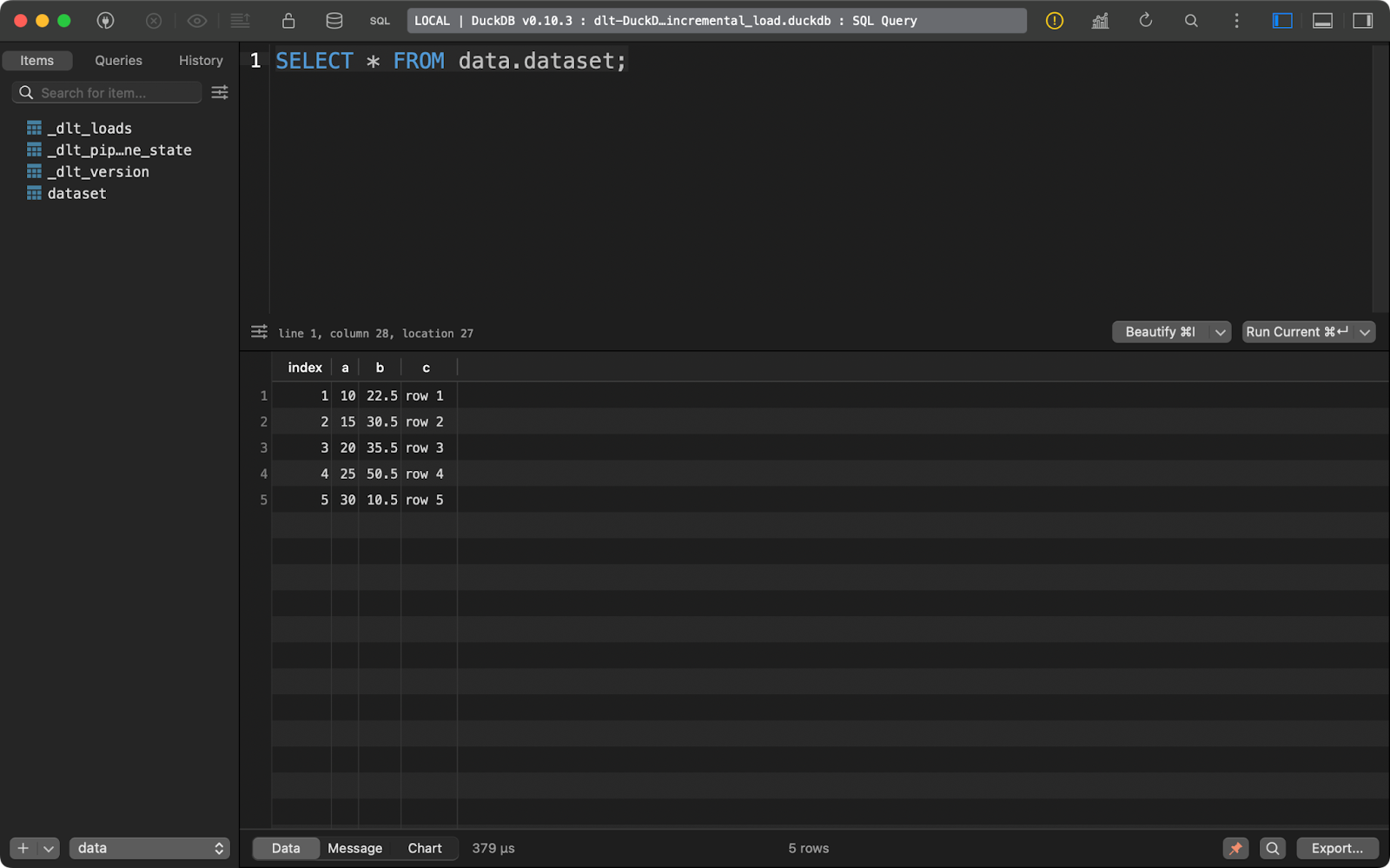
dataset Inhalt der Tabelle
Kurz gesagt, dieser Ansatz wird immer die vorhandenen Daten ersetzen.
Was aber, wenn du eine Mischung aus neuen und aktualisierten Daten hast? Hier kommt die upsert Operation ins Spiel. Sie wird durch die merge Schreibdisposition in dlt implementiert.
Als Referenz habe ich die Pipeline noch einmal mit den Daten aus dem vorherigen Abschnitt ausgeführt, um sicherzustellen, dass 5 Zeilen vorhanden sind.
Dann habe ich die Daten aktualisiert, um eine weitere Zeile hinzuzufügen und die Werte für einige Datensätze mit den bestehenden index Werten zu ändern.
Das dlt Paket schaut sich die primary_key Spalte an, die du angegeben hast, und vergleicht sie mit den Daten auf dem Zielsystem. Datensätze mit der bestehenden Primärschlüsselspalte werden aktualisiert und die neuen werden eingefügt:
import dlt
import pandas as pd
@dlt.resource(primary_key="index")
def data():
data = pd.DataFrame({
"index": [1, 2, 3, 4, 5, 6],
"a": [10, 15, 200000, 25, -3000, 50],
"b": [22.5, 30.5, 3555555.5, 50.5, -100.5, 15.5],
"c": ["row 1", "row 2", "row 3 updated", "row 4", "row 5 updated", "row 6 new"]
})
yield data
def load_local_data() -> None:
pipeline = dlt.pipeline(
pipeline_name="pipeline_incremental_load",
destination="duckdb",
dataset_name="data"
)
load_info = pipeline.run(data=data(), table_name="dataset", write_disposition="merge")
print(load_info)
if __name__ == "__main__":
load_local_data()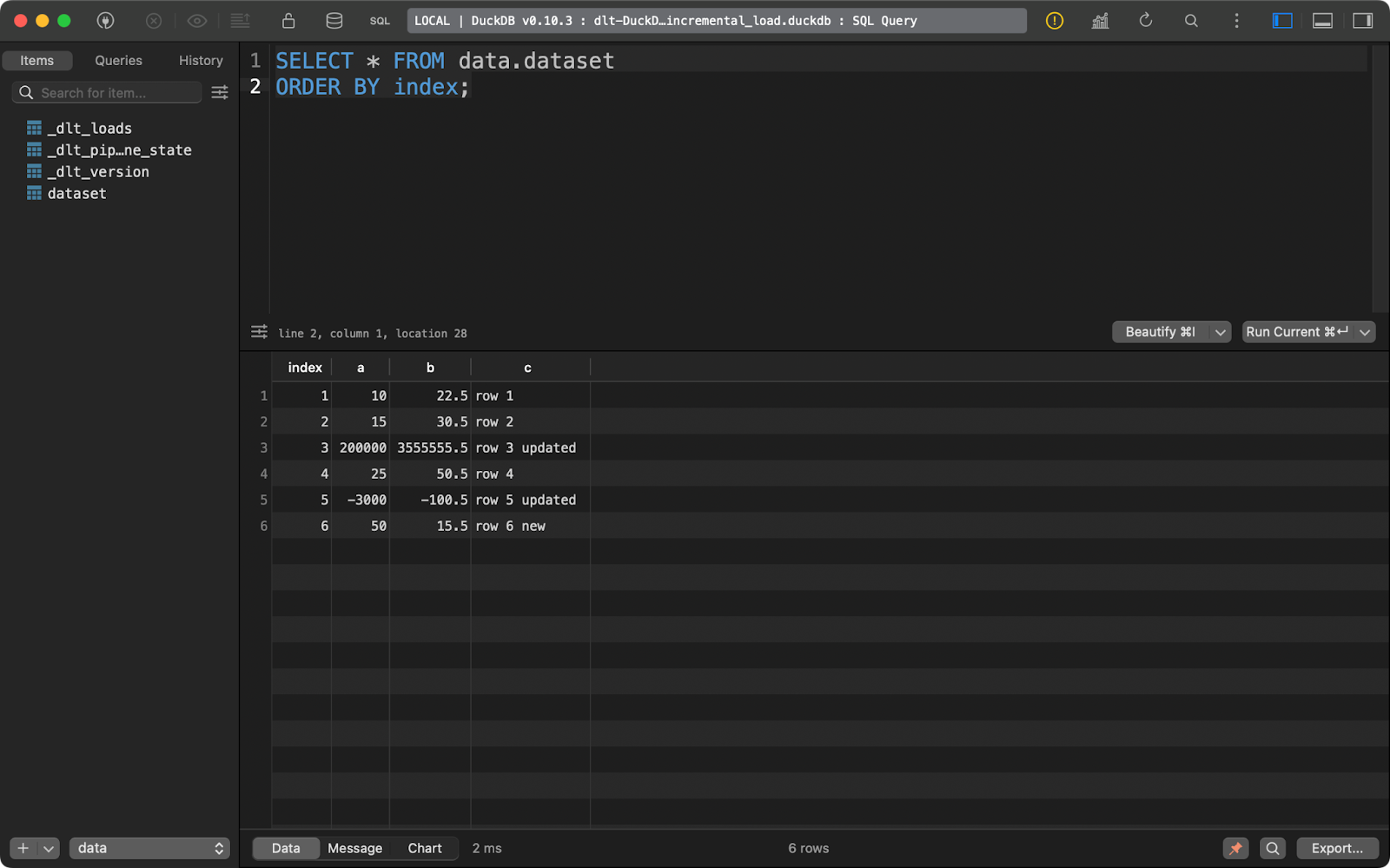
Datensatz nach dem Upsert-Vorgang
Am Ende hast du also eine neue und zwei aktualisierte Zeilen.
Das ist wahrscheinlich das Verhalten, das du dir für die meisten deiner Pipelines wünschst, vor allem, wenn du Datendopplungen vermeiden willst.
Zusammenfassend lässt sich sagen, dass hinter Data Engineering mehr steckt, als man denkt. Die Datenbewegung ist nur ein Teil davon. Nichtsdestotrotz ist es ein wichtiger Teil und die meisten anderen Aspekte der Datentechnik drehen sich um ihn.
Wenn du dich bereits mit Python auskennst, willst du wahrscheinlich kein GUI-Tool für die Datenübertragung von Grund auf lernen oder zu einer völlig neuen Sprache wechseln. Du möchtest in einer vertrauten Umgebung bleiben. Die Python-Bibliothek dlt ist alles, was du und dein Team brauchen, um Altsysteme zu modernisieren und dieoud-Kosten zu senken. Es hat sich bei vielen großen Unternehmen wie Hugging Face, Taktile, Untitled Data Company und Harness bewährt, also glaube ich, dass es auch für deine Bedürfnisse geeignet ist.
Allerdings ist dlt wahrscheinlich nicht das einzige Tool, das du brauchst, um effiziente Datenpipelines zu implementieren. Du wirst zusätzliche Datentools wie dbt lernen wollen, um die Datenverarbeitung auf die nächste Stufe zu bringen.
Wenn du eine Karriere als Datentechniker/in anstrebst, ist unser 3-moduliger Kurs der perfekte Einstieg für dich.
Unsere Zertifizierungsprogramme helfen dir, dich von anderen abzuheben und potenziellen Arbeitgebern zu beweisen, dass deine Fähigkeiten für den Job geeignet sind.

Lerne mehr über Data Engineering mit diesen Kursen!
Lernpfad
Kurs
Kurs