programa
Ingeniero de datos en Python
40 h
Como he dicho antes, DuckDB funciona en tu portátil. Lo primero es conseguirlo.
Te mostraré los pasos de instalación para macOS, pero las instrucciones para Windows y Linux están bien explicadas y son fáciles de seguir.
Si tienes un Mac, la forma más sencilla de instalar DuckDB es con Homebrew. Ejecuta el siguiente comando shell:
brew install duckdbVerás el siguiente resultado en cuestión de segundos:
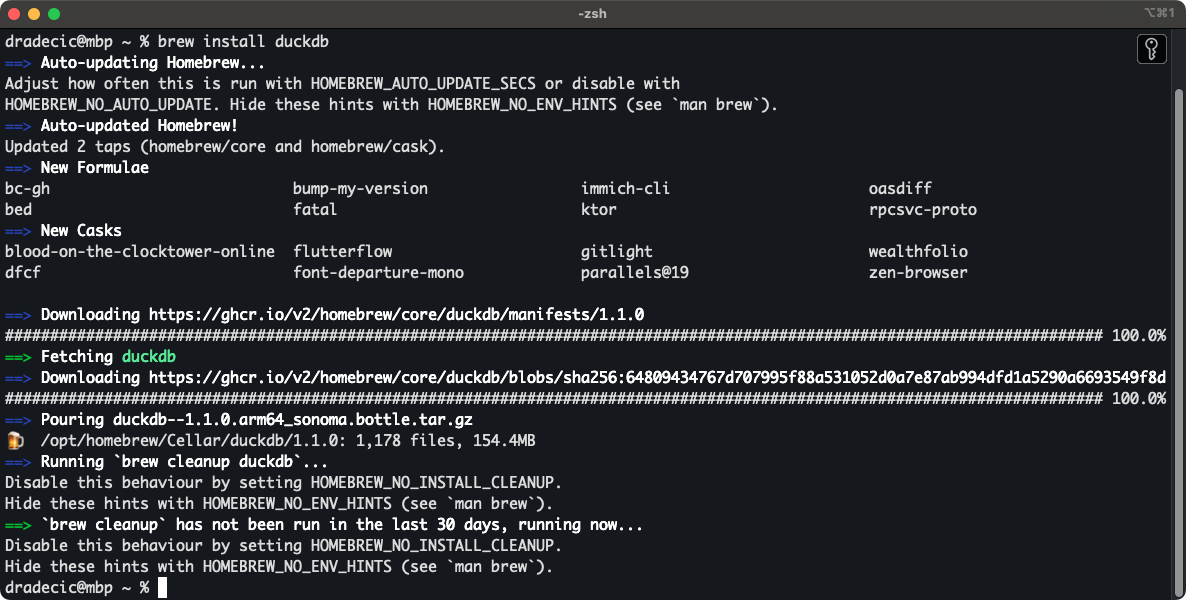
Instalar DuckDB con Homebrew
Una vez instalado, puedes entrar en el shell de DuckDB con el siguiente comando:
duckdb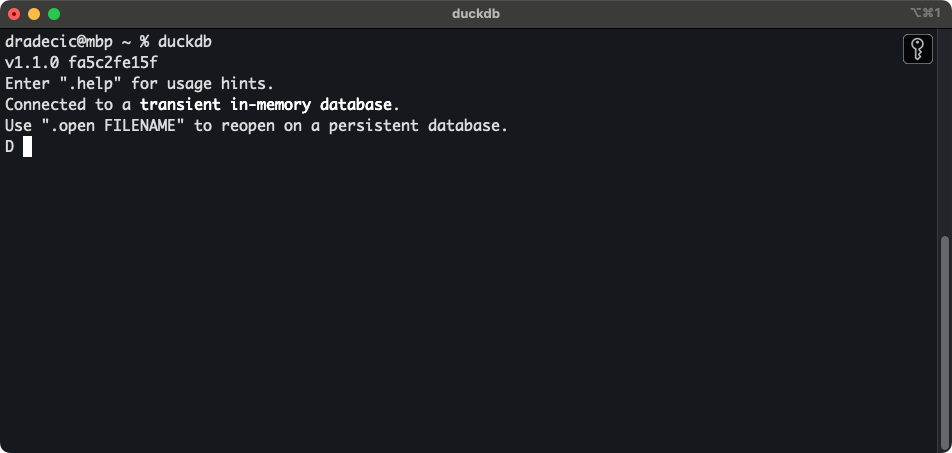
Shell DuckDB
A partir de aquí, ¡el mundo es tu ostra!
Puedes escribir y ejecutar consultas SQL directamente desde la consola. Por ejemplo, he descargado los datos de los 6 primeros meses de Taxis de NYC para 2024. Si has hecho lo mismo, utiliza el siguiente fragmento para mostrar el recuento de filas de un único archivo Parquet:
SELECT COUNT(*)
FROM PARQUET_SCAN("path-to-data.parquet");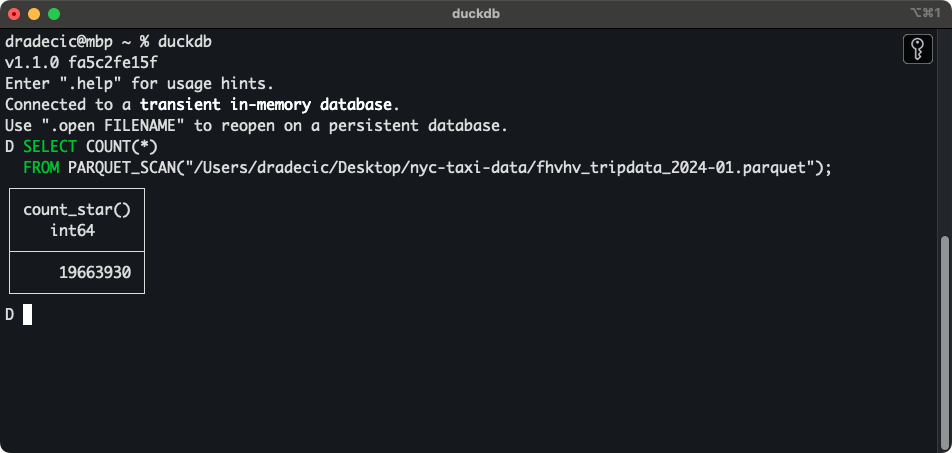
Recuento de filas de un único archivo Parquet
Sí, son casi 20 millones de filas de un solo archivo. He descargado 24 de ellos.
Probablemente no quieras ejecutar DuckDB desde el terminal, así que a continuación te guiaré por los pasos para conectar DuckDB con Python.
El objetivo de esta sección es mostrarte cómo configurar y ejecutar DuckDB en el lenguaje más popular de la ingeniería de datos: Pitón.
De hecho, DataCamp ofrece una carrera completa en ingeniería de datos en Python.
Python tiene una biblioteca DuckDB específica que debes instalar primero. Ejecuta lo siguiente desde el terminal, preferiblemente en un entorno virtual:
pip install duckdbAhora crea un nuevo archivo Python y pega el siguiente código:
import duckdb
# Function to get the count from a single file
def get_row_count_from_file(conn: duckdb.DuckDBPyConnection, file_path: str) -> int:
query = f"""
SELECT COUNT(*)
FROM PARQUET_SCAN("{file_path}")
"""
return conn.sql(query).fetchone()[0]
if __name__ == "__main__":
# In-memory database connection
conn = duckdb.connect()
# Path to a parquet file
file_path = "fhvhv_tripdata_2024-01.parquet"
# Get the row count
row_count = get_row_count_from_file(conn=conn, file_path=file_path)
print(row_count)Resumiendo, el fragmento de código tiene una función que obtiene el recuento de filas de un único archivo, dada una conexión DuckDB válida y una ruta de archivo.
Obtendrás el siguiente resultado casi instantáneamente después de ejecutar el script:
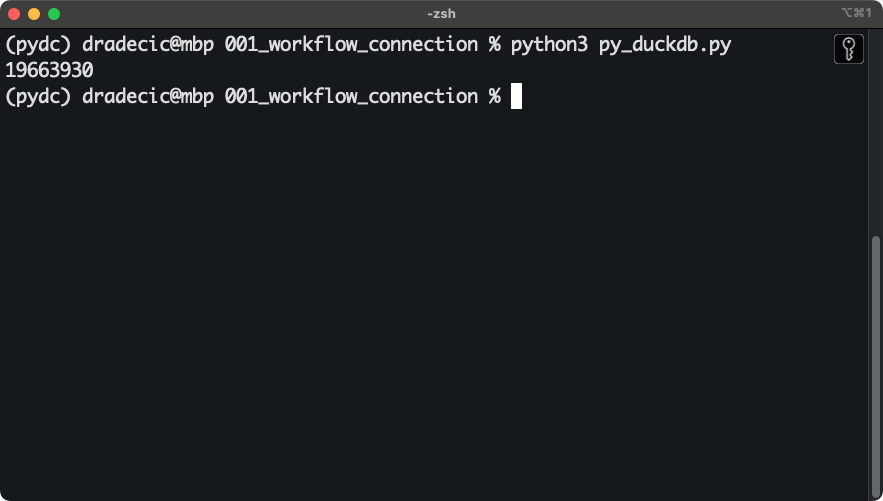
Conexión entre DuckDB y Python
Eso es.
A continuación, te mostraré cómo hacer cosas increíbles con Python y DuckDB ¡a toda velocidad!
Como referencia, ejecutaré el código en una parte de 2024 (enero-junio) del conjunto de datos de taxis de NYC , concretamente para los vehículos de alquiler de gran volumen. Esto es 6archivos Parquet, que ocupan aproximadamente 3GB de espacio en disco. En cuanto al hardware, estoy utilizando un MacBook Pro 16" M3 Pro con 12 núcleos de CPU y 36 GB de memoria unificada.
Tu kilometraje puede variar, pero aun así deberías acabar con cifras similares.
He convertido estos 6 archivos a dos formatos adicionales: CSV y JSON. Puedes ver cuánto espacio de disco ocupa cada una de ellas:
Comparación del tamaño del conjunto de datos
Total: 2,96 GB para Parquet, 19,31 GB para CSV y 66,04 GB para JSON.
¡La diferencia es enorme! Si no sacas nada más del artículo de hoy, al menos recuerda utilizar siempre el formato de archivo Parquet cuando se trate de archivos enormes. Te ahorrará tiempo de procesamiento y espacio en disco.
DuckDB dispone de prácticas funciones que pueden leer varios archivos del mismo formato a la vez (utilizando un patrón glob). Lo utilizaré para leer los seis y obtener el recuento de filas y comparar el tiempo de ejecución:
import duckdb
import pandas as pd
from datetime import datetime
def get_row_count_and_measure_time(file_format: str) -> str:
# Construct a DuckDB query based on the file_format
match file_format:
case "csv":
query = """
SELECT COUNT(*)
FROM READ_CSV("nyc-taxi-data-csv/*.csv")
"""
case "json":
query = """
SELECT COUNT(*)
FROM READ_JSON("nyc-taxi-data-json/*.json")
"""
case "parquet":
query = """
SELECT COUNT(*)
FROM READ_PARQUET("nyc-taxi-data/*.parquet")
"""
case _:
raise KeyError("Param file_format must be in [csv, json, parquet]")
# Open the database connection and measure the start time
time_start = datetime.now()
conn = duckdb.connect()
# Get the row count
row_count = conn.sql(query).fetchone()[0]
# Close the database connection and measure the finish time
conn.close()
time_end = datetime.now()
return {
"file_format": file_format,
"duration_seconds": (time_end - time_start).seconds + ((time_end - time_start).microseconds) / 1000000,
"row_count": row_count
}
# Run the function
file_format_results = []
for file_format in ["csv", "json", "parquet"]:
file_format_results.append(get_row_count_and_measure_time(file_format=file_format))
pd.DataFrame(file_format_results)Ya están los resultados: sólo hay un claro ganador:
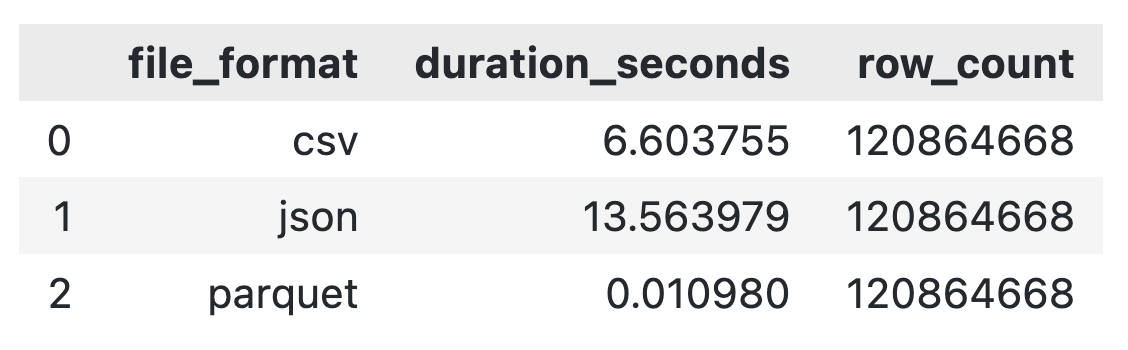
Comparación del tiempo de ejecución de la lectura de archivos
Gracias a DuckDB, los tres son rápidos y acaban en el mismo sitio, pero está claro que Parquet gana por un factor de 600 en comparación con CSV y por un factor de 1200 en comparación con JSON.
Por esta razón, sólo utilizaré Parquet durante el resto del artículo.
DuckDB te permite agregar datos mediante SQL.
Mi objetivo para esta sección es ampliar esa idea. Para ser más preciso, te mostraré cómo calcular estadísticas resumidas a nivel mensual que incluyan información sobre el número de viajes, el tiempo de viaje, la distancia recorrida, el coste del viaje y la remuneración del conductor, todo ello a partir de 120 millones de filas de datos.
Lo mejor: ¡Sólo te llevará dos segundos!
Este es el código que utilicé dentro de un script de Python para agregar datos e imprimir los resultados:
conn = duckdb.connect()
query = """
SELECT
ride_year || '-' || ride_month AS ride_period,
COUNT(*) AS num_rides,
ROUND(SUM(trip_time) / 86400, 2) AS ride_time_in_days,
ROUND(SUM(trip_miles), 2) AS total_miles,
ROUND(SUM(base_passenger_fare + tolls + bcf + sales_tax + congestion_surcharge + airport_fee + tips), 2) AS total_ride_cost,
ROUND(SUM(driver_pay), 2) AS total_rider_pay
FROM (
SELECT
DATE_PART('year', pickup_datetime) AS ride_year,
DATE_PART('month', pickup_datetime) AS ride_month,
trip_time,
trip_miles,
base_passenger_fare,
tolls,
bcf,
sales_tax,
congestion_surcharge,
airport_fee,
tips,
driver_pay
FROM PARQUET_SCAN("nyc-taxi-data/*.parquet")
WHERE
ride_year = 2024
AND ride_month >= 1
AND ride_month <= 6
)
GROUP BY ride_period
ORDER BY ride_period
"""
# Aggregate data, print it, and show the data type
results = conn.sql(query)
results.show()
print(type(results))La salida contiene los resultados de la agregación, el tipo de variable para results, y el tiempo total de ejecución:
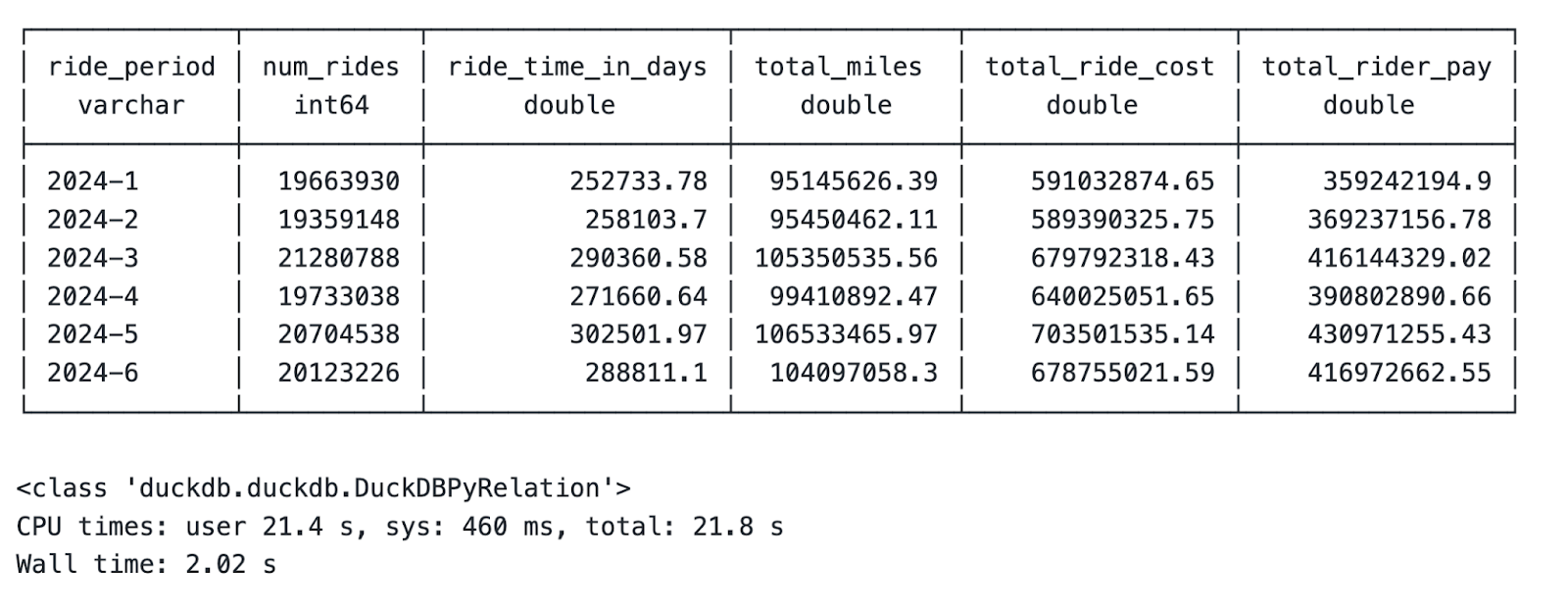
Agregación mensual de estadísticas resumidas
Deja que lo asimile: Eso son 3 GB de datos que abarcan más de 120 millones de filas, ¡todo agregado en 2 segundos en un ordenador portátil!
El único problema es que el tipo variable es algo inservible a largo plazo. Por suerte, hay una solución fácil.
La ventaja de utilizar DuckDB no es sólo que es rápido, sino que también se integra bien con tu biblioteca de marcos de datos favorita: pandas.
Si tienes un conjunto de resultados temporal similar al que he mostrado anteriormente, sólo tienes que llamar al método .df() sobre él para convertirlo en un pandas DataFrame:
# Convert to Pandas DataFrame
results_df = results.df()
# Print the type and contents
print(type(results_df))
results_df
Conversión de DuckDB a pandas
Del mismo modo, puedes utilizar DuckDB para realizar cálculos en DataFrames de pandas que ya se han cargado en memoria.
El truco consiste en hacer referencia al nombre de la variable después de la palabra clave FROM en una consulta SQL de DuckDB. He aquí un ejemplo:
# Pandas DataFrame
pandas_df = pd.read_parquet("nyc-taxi-data/fhvhv_tripdata_2024-01.parquet")
# Run SQL queries through DuckDB
duckdb_res = duckdb.sql("""
SELECT
pickup_datetime,
dropoff_datetime,
trip_miles,
trip_time,
driver_pay
FROM pandas_df
WHERE trip_miles >= 300
""").df()
duckdb_res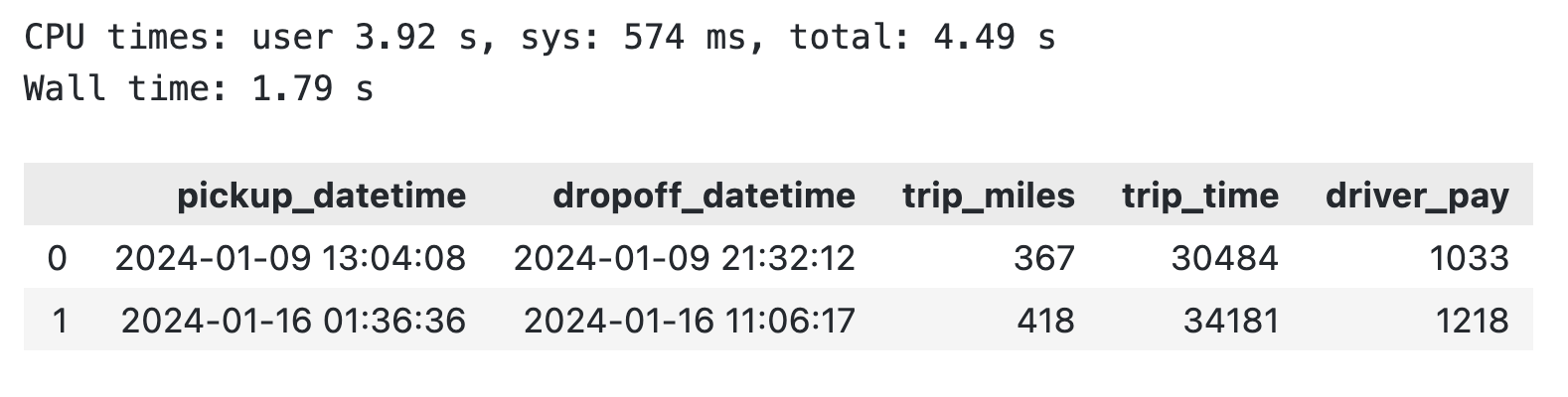
Consulta DuckDB sobre un DataFrame pandas existente
Para concluir, puedes evitar por completo pandas o realizar agregaciones más rápidamente en los DataFrames de pandas existentes.
A continuación, te mostraré un par de funciones avanzadas de DuckDB.
Hay mucho más DuckDB de lo que parece.
En esta sección, te guiaré a través de un par de funciones avanzadas de DuckDB que son esenciales para los ingenieros de datos.
DuckDB te permite ampliar su funcionalidad nativa mediante extensionesdel núcleo y de la comunidad. Utilizo extensiones todo el tiempo para conectarme a sistemas de almacenamiento en la nube y bases de datos y trabajar con formatos de archivo adicionales.
Puedes instalar extensiones a través de las consolas Python y DuckDB.
En el fragmento de código siguiente, te muestro cómo instalar la extensión httpfs, necesaria para conectar con AWS y leer datos de S3:
import duckdb
conn = duckdb.connect()
conn.execute("""
INSTALL httpfs;
LOAD httpfs;
""")No verás ninguna salida si no encadenas el método .df() a conn.execute(). Si lo haces, verás un mensaje de "Éxito" o de "Error".
Lo más frecuente es que tu empresa te conceda acceso a los datos que tienes que incluir en tus pipelines. Suelen almacenarse en plataformas escalables en la nube, como AWS S3.
DuckDB te permite conectar S3 (y otras plataformas) directamente.
Ya te he mostrado cómo instalar la extensión (httpfs), y lo único que queda por hacer es configurarla. AWS requiere que proporciones información sobre tu región, clave de acceso y clave de acceso secreta.
Suponiendo que tengas todo esto, ejecuta el siguiente comando a través de Python:
conn.execute(""" CREATE SECRET aws_s3_secret (
TYPE S3,
KEY_ID '<your-access-key>',
SECRET '<your-secret-key>',
REGION '<your-region>'
);
""")Mi bucket de S3 contiene dos de los archivos del conjunto de datos de Taxis de Nueva York:
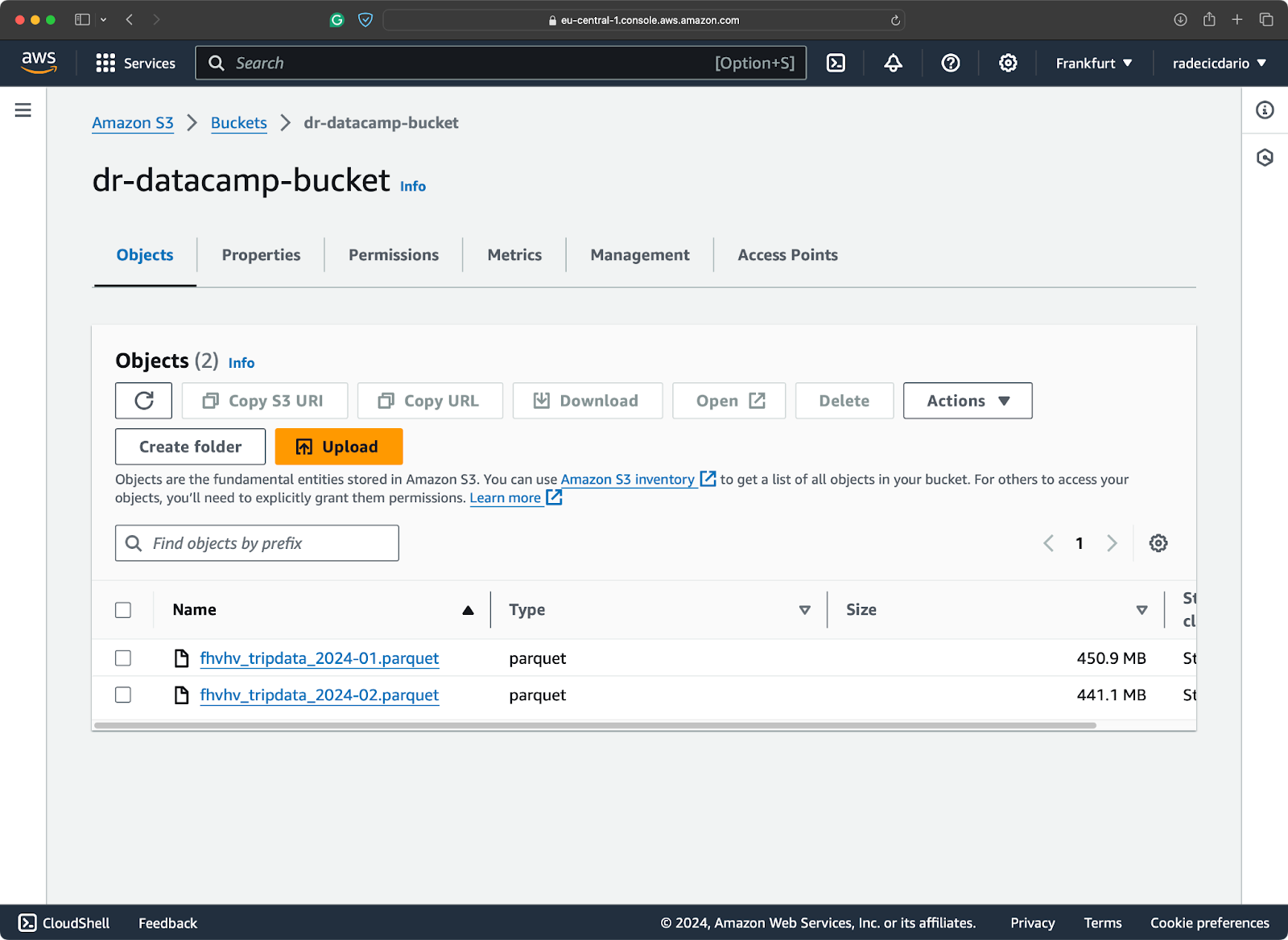
Contenido del cubo S3
No es necesario descargar los archivos, ya que puedes escanearlos directamente desde S3:
import duckdb
conn = duckdb.connect()
aws_count = conn.execute("""
SELECT COUNT(*)
FROM PARQUET_SCAN('s3://<your-bucket-name>/*.parquet');
""").df()
aws_count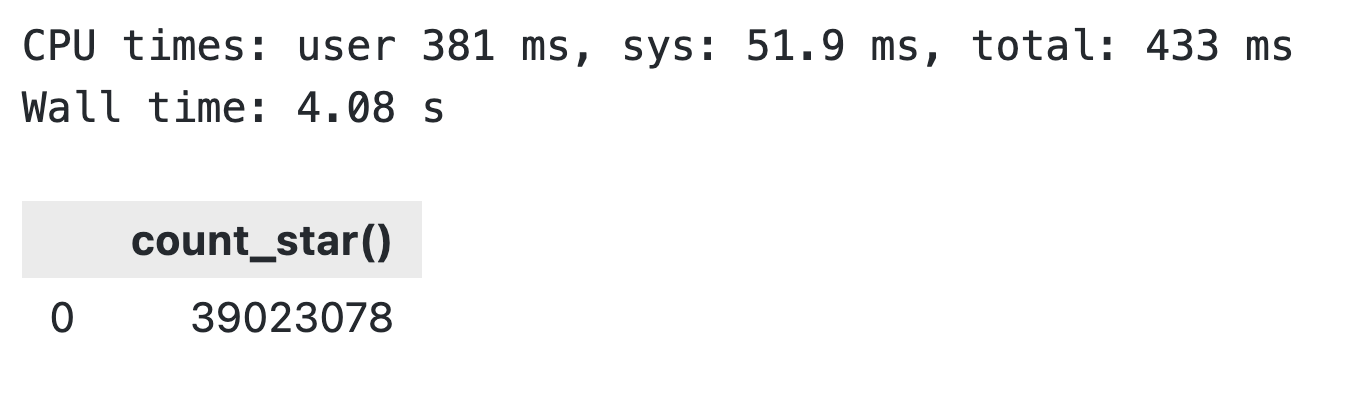
Resultados de la búsqueda en S3 de DuckDB
Estás leyendo bien: tardósólo 4 segundos en recorrer ~ 900 MB de datos almacenados en un bucket de S3.
En cuanto a la paralelización, DuckDB la implementa por defecto basándose en grupos de filas: particiones de datos horizontales que encontrarías típicamente en Parquet. Un único grupo de filas puede tener un máximo de 122.880 filas.
El paralelismo en DuckDB comienza cuando trabajas con más de 122.880 filas.
DuckDB lanzará automáticamente nuevos hilos cuando esto ocurra. Por defecto, el número de hilos es igual al número de núcleos de la CPU. Pero esto no te impide jugar manualmente con el número de hilos.
En esta sección, te mostraré cómo hacerlo y el impacto exacto que tiene un número diferente de hilos en una carga de trabajo idéntica.
Para ver el número actual de hilos, ejecuta lo siguiente:
SELECT current_setting('threads') AS threads;
El número actual de hilos utilizados por DuckDB
Puedes obtener los mismos resultados mediante Python.
Querrás ejecutar el comando SET threads = N para cambiar el número de hilos.
En el siguiente fragmento de código, te mostraré cómo implementar una función personalizada de Python que ejecute una consulta DuckDB en un número determinado de hilos, la convierta en un DataFrame de pandas y devuelva el tiempo de ejecución (entre otras cosas). El código que hay debajo de la función la ejecuta en un rango de [1, 12] hilos:
def thread_test(n_threads: int) -> dict:
# Open the database connection and measure the start time
time_start = datetime.now()
conn = duckdb.connect()
# Set the number of threads
conn.execute(f"SET threads = {n_threads};")
query = """
SELECT
ride_year || '-' || ride_month AS ride_period,
COUNT(*) AS num_rides,
ROUND(SUM(trip_time) / 86400, 2) AS ride_time_in_days,
ROUND(SUM(trip_miles), 2) AS total_miles,
ROUND(SUM(base_passenger_fare + tolls + bcf + sales_tax + congestion_surcharge + airport_fee + tips), 2) AS total_ride_cost,
ROUND(SUM(driver_pay), 2) AS total_rider_pay
FROM (
SELECT
DATE_PART('year', pickup_datetime) AS ride_year,
DATE_PART('month', pickup_datetime) AS ride_month,
trip_time,
trip_miles,
base_passenger_fare,
tolls,
bcf,
sales_tax,
congestion_surcharge,
airport_fee,
tips,
driver_pay
FROM PARQUET_SCAN("nyc-taxi-data/*.parquet")
WHERE
ride_year = 2024
AND ride_month >= 1
AND ride_month <= 6
)
GROUP BY ride_period
ORDER BY ride_period
"""
# Convert to DataFrame
res = conn.sql(query).df()
# Close the database connection and measure the finish time
conn.close()
time_end = datetime.now()
return {
"num_threads": n_threads,
"num_rows": len(res),
"duration_seconds": (time_end - time_start).seconds + ((time_end - time_start).microseconds) / 1000000
}
thread_results = []
for n_threads in range(1, 13):
thread_results.append(thread_test(n_threads=n_threads))
pd.DataFrame(thread_results)Deberías ver un resultado similar al mío:
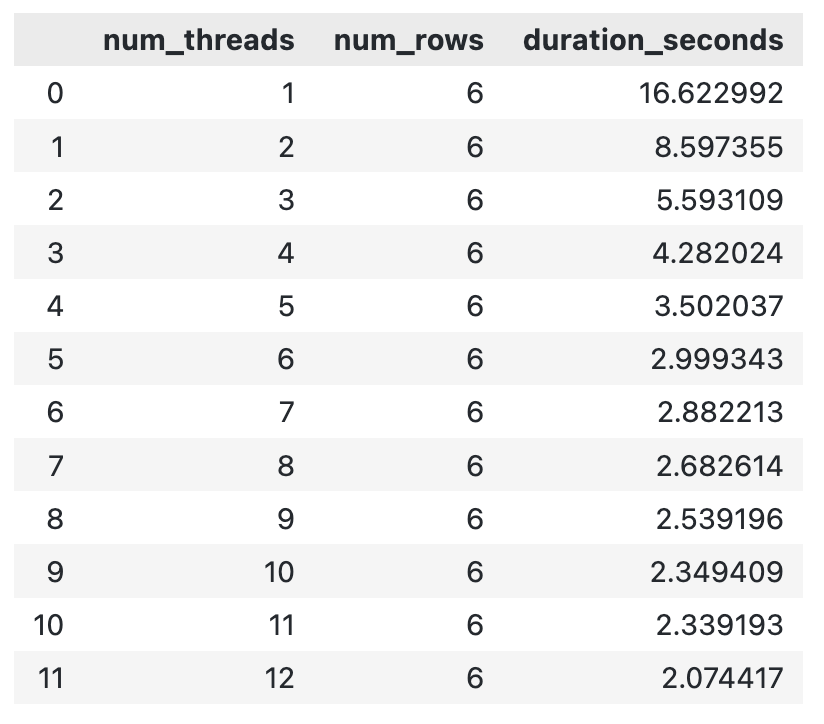
Tiempo de ejecución de DuckDB para diferente número de hilos
En general, cuantos más hilos lances a un cálculo, más rápido terminará. Puede haber un punto en el que lasobrecarga de al crear un nuevo hilo provoque un aumento del tiempo de ejecución total, pero no lo he encontrado en este rango.
En esta sección, te mostraré cómo escribir una canalización de datos desde cero. Será relativamente sencillo: leer datos del disco, realizar agregaciones y escribir los resultados. Mi objetivo es mostrar cuánto rendimiento puedes ganarcambiando de pandas a DuckDB. No sólo eso, sino que además tu código tendrá un aspecto más limpio.
No se trata de una introducción exhaustiva a los procesos ETL/ELT, sino de una visión general de alto nivel.
La canalización de datos que voy a mostrarte consigue lo siguiente:
Después de ejecutar el código, deberías obtener exactamente los mismos resultados de agregación para ambas implementaciones de canalización (sin tener en cuenta algunas diferencias de redondeo):
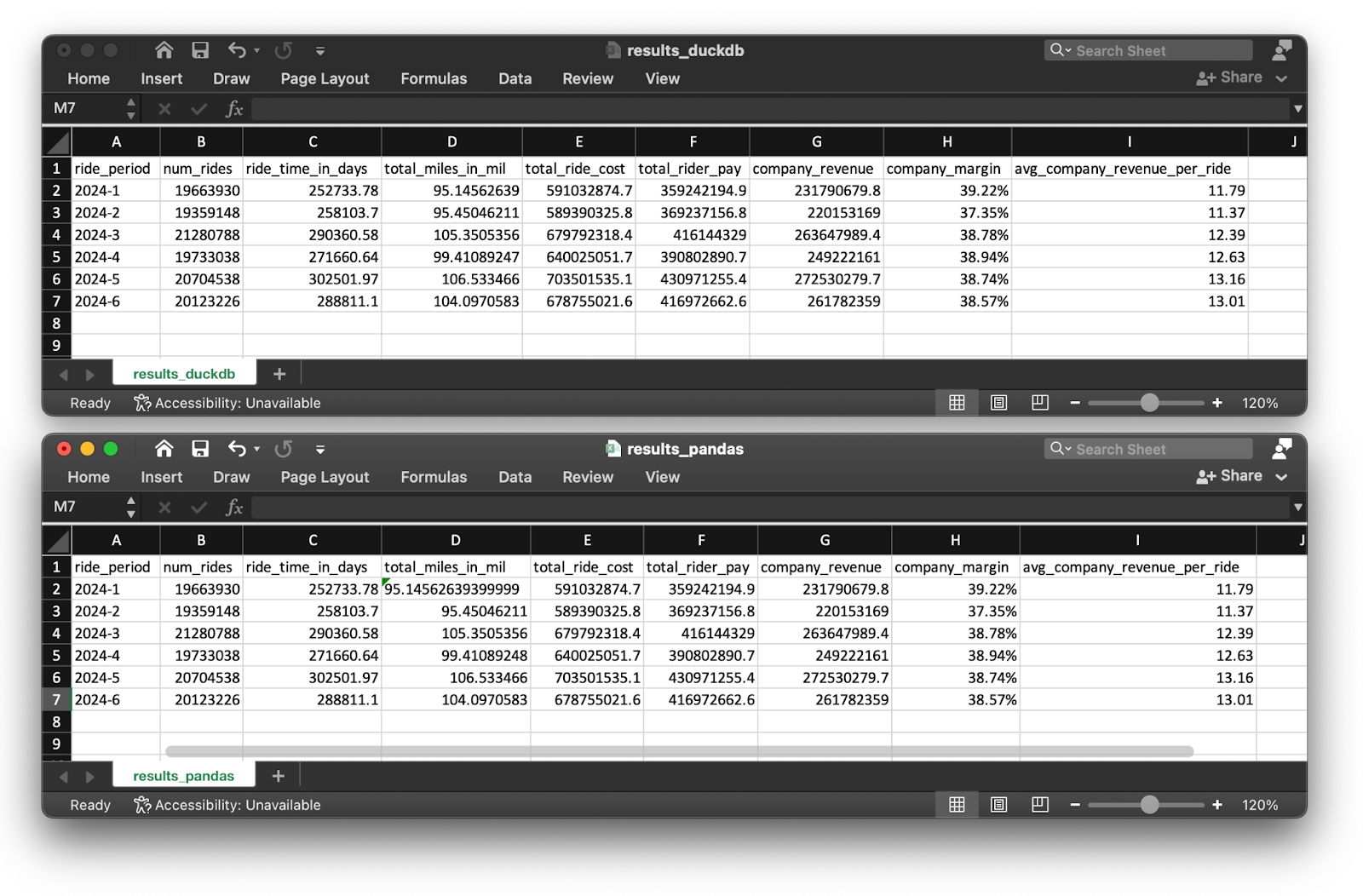
Resultados de la tubería para DuckDB y pandas
En primer lugar, vamos a repasar la implementación de la tubería en pandas.
No importa lo que haya intentado, no he podido procesar los 6 archivos Parquet a la vez. Los mensajes de advertencia del sistema como éste se mostraban en cuestión de segundos:
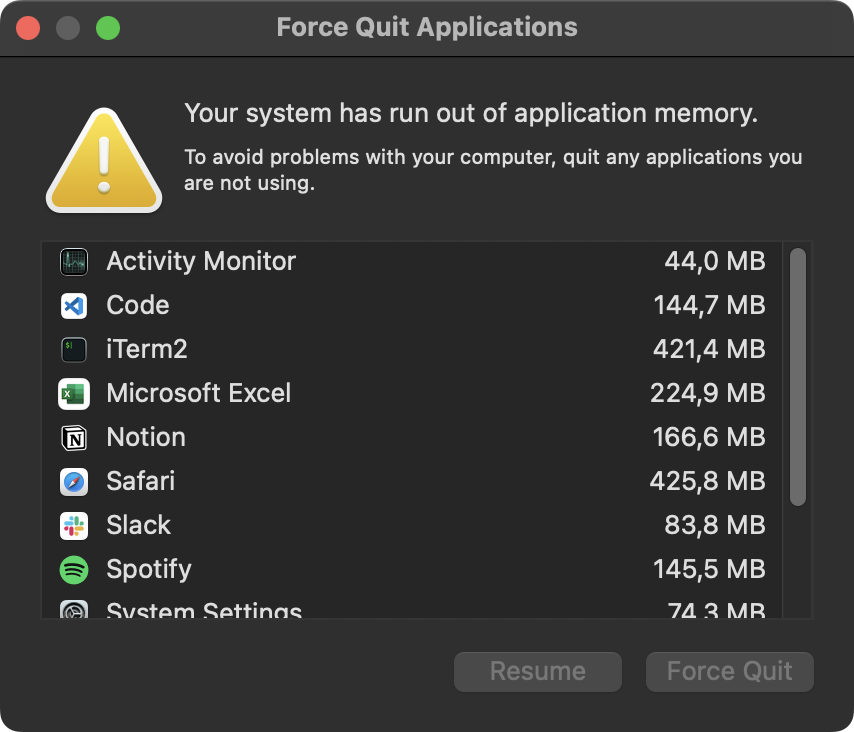
Error de memoria del sistema
Parece que 36 GB de memoria no son suficientes para procesar 120 millones de filas a la vez. Como resultado, el script Python fue eliminado:
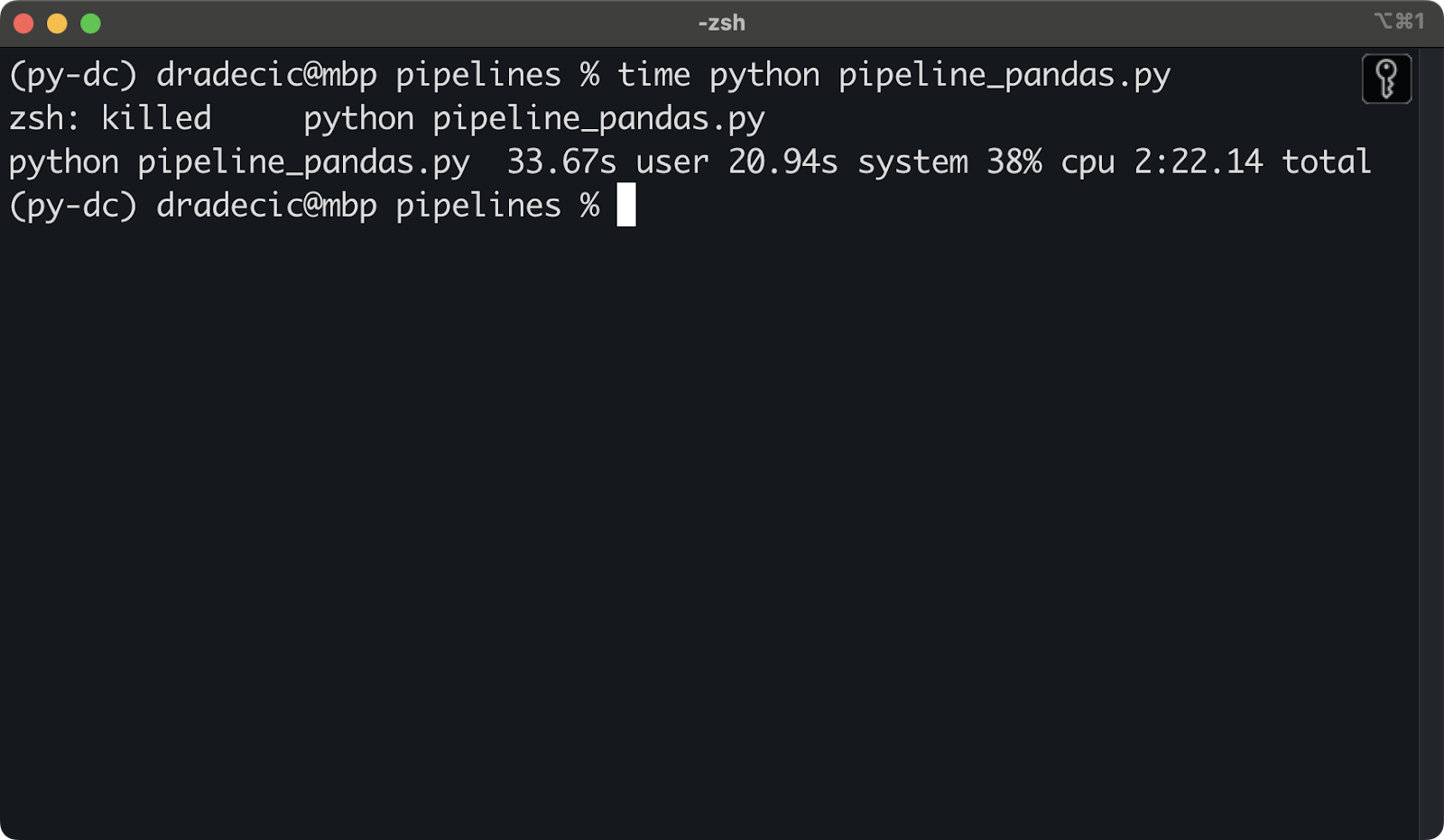
Matado script Python por memoria insuficiente
Para mitigarlo, tuve que procesar los archivos Parquet secuencialmente. Éste es el código que he utilizado para la canalización de datos:
import os
import pandas as pd
def calculate_monthly_stats_per_file(file_path: str) -> pd.DataFrame:
# Read a single Parquet file
df = pd.read_parquet(file_path)
# Extract ride year and month
df["ride_year"] = df["pickup_datetime"].dt.year
df["ride_month"] = df["pickup_datetime"].dt.month
# Remove data points that don"t fit in the time period
df = df[(df["ride_year"] == 2024) & (df["ride_month"] >= 1) & (df["ride_month"] <= 6)]
# Combine ride year and month
df["ride_period"] = df["ride_year"].astype(str) + "-" + df["ride_month"].astype(str)
# Calculate total ride cost
df["total_ride_cost"] = (
df["base_passenger_fare"] + df["tolls"] + df["bcf"] +
df["sales_tax"] + df["congestion_surcharge"] + df["airport_fee"] + df["tips"]
)
# Aggregations
summary = df.groupby("ride_period").agg(
num_rides=("pickup_datetime", "count"),
ride_time_in_days=("trip_time", lambda x: round(x.sum() / 86400, 2)),
total_miles=("trip_miles", "sum"),
total_ride_cost=("total_ride_cost", "sum"),
total_rider_pay=("driver_pay", "sum")
).reset_index()
# Additional attributes
summary["total_miles_in_mil"] = summary["total_miles"] / 1000000
summary["company_revenue"] = round(summary["total_ride_cost"] - summary["total_rider_pay"], 2)
summary["company_margin"] = round((1 - (summary["total_rider_pay"] / summary["total_ride_cost"])) * 100, 2).astype(str) + "%"
summary["avg_company_revenue_per_ride"] = round(summary["company_revenue"] / summary["num_rides"], 2)
# Remove columns that aren't needed anymore
summary.drop(["total_miles"], axis=1, inplace=True)
return summary
def calculate_monthly_stats(file_dir: str) -> pd.DataFrame:
# Read data from multiple Parquet files
files = [os.path.join(file_dir, f) for f in os.listdir(file_dir) if f.endswith(".parquet")]
df = pd.DataFrame()
for file in files:
print(file)
file_stats = calculate_monthly_stats_per_file(file_path=file)
# Check if df is empty
if df.empty:
df = file_stats
else:
# Concat row-wise
df = pd.concat([df, file_stats], axis=0)
# Sort the dataset
df = df.sort_values(by="ride_period")
# Change column order
cols = ["ride_period", "num_rides", "ride_time_in_days", "total_miles_in_mil", "total_ride_cost",
"total_rider_pay", "company_revenue", "company_margin", "avg_company_revenue_per_ride"]
return df[cols]
if __name__ == "__main__":
data_dir = "nyc-taxi-data"
output_dir = "pipeline_results"
output_file_name = "results_pandas.csv"
# Run the pipeline
monthly_stats = calculate_monthly_stats(file_dir=data_dir)
# Save to CSV
monthly_stats.to_csv(f"{output_dir}/{output_file_name}", index=False)Es de esperar que la implementación de la tubería en DuckDB termine sin problemas de memoria.
Ya conoces la mayor parte del código de DuckDB.
Lo único nuevo es la parte superior SELECT, ya que calcula un par de estadísticas adicionales. Dejé todo lo demás sin cambios:
import duckdb
import pandas as pd
def calculate_monthly_stats(file_dir: str) -> pd.DataFrame:
query = f"""
SELECT
ride_period,
num_rides,
ride_time_in_days,
total_miles / 1000000 AS total_miles_in_mil,
total_ride_cost,
total_rider_pay,
ROUND(total_ride_cost - total_rider_pay, 2) AS company_revenue,
ROUND((1 - total_rider_pay / total_ride_cost) * 100, 2) || '%' AS company_margin,
ROUND((total_ride_cost - total_rider_pay) / num_rides, 2) AS avg_company_revenue_per_ride
FROM (
SELECT
ride_year || '-' || ride_month AS ride_period,
COUNT(*) AS num_rides,
ROUND(SUM(trip_time) / 86400, 2) AS ride_time_in_days,
ROUND(SUM(trip_miles), 2) AS total_miles,
ROUND(SUM(base_passenger_fare + tolls + bcf + sales_tax + congestion_surcharge + airport_fee + tips), 2) AS total_ride_cost,
ROUND(SUM(driver_pay), 2) AS total_rider_pay
FROM (
SELECT
DATE_PART('year', pickup_datetime) AS ride_year,
DATE_PART('month', pickup_datetime) AS ride_month,
trip_time,
trip_miles,
base_passenger_fare,
tolls,
bcf,
sales_tax,
congestion_surcharge,
airport_fee,
tips,
driver_pay
FROM PARQUET_SCAN("{file_dir}/*.parquet")
WHERE
ride_year = 2024
AND ride_month >= 1
AND ride_month <= 6
)
GROUP BY ride_period
ORDER BY ride_period
)
"""
conn = duckdb.connect()
df = conn.sql(query).df()
conn.close()
return df
if __name__ == "__main__":
data_dir = "nyc-taxi-data"
output_dir = "pipeline_results"
output_file_name = "results_duckdb.csv"
# Run the pipeline
monthly_stats = calculate_monthly_stats(file_dir=data_dir)
# Save to CSV
monthly_stats.to_csv(f"{output_dir}/{output_file_name}", index=False)A continuación, te mostraré las diferencias en el tiempo de ejecución.
Después de ejecutar ambos pipelines 5 veces y promediar los resultados, estos son los tiempos de ejecución que obtuve:
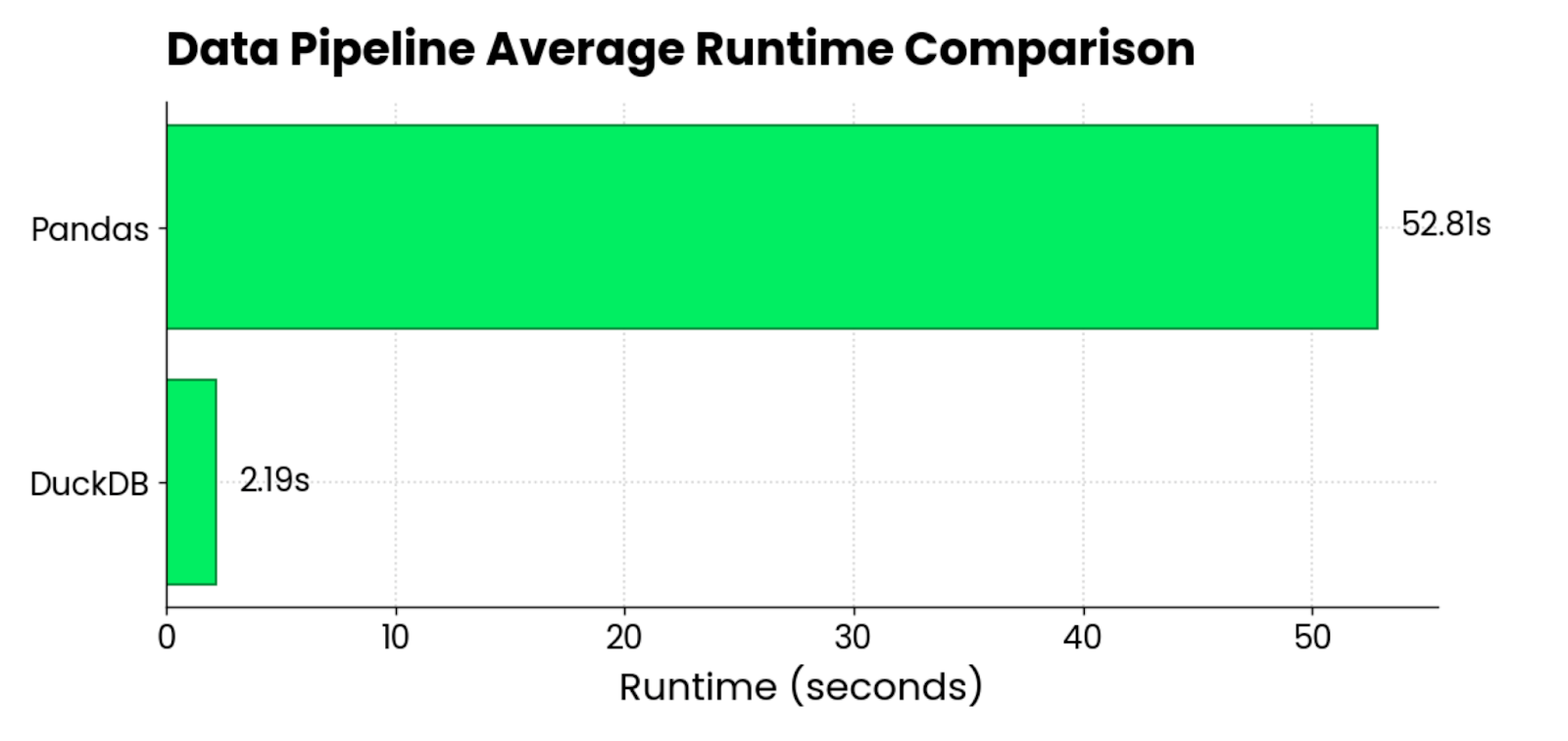
DuckDB vs. pandas runtime comparison chart
Por término medio, pandas era 24 veces más lento que DuckDB al cargar y procesar unos 120 millones de filas (~3GB), repartidas en 6 archivos Parquet.
La comparación no es del todo justa, ya que no pude procesar todos los archivos Parquet a la vez con pandas. Sin embargo, los resultados siguen siendo relevantes, ya que te encontrarás con las mismas dificultades en tu trabajo diario.
Si una biblioteca no puede hacer lo que necesitas, prueba con otra. Y el que probablemente termine más rápido la mayoría de las veces es DuckDB.
Antes de dejarte explorar DuckDB más a fondo por tu cuenta, quiero compartir un par de buenas prácticas genéricas y relacionadas con la ingeniería de datos:
SELECT. Debes evitar utilizarlo en flujos de trabajo que dependan de declaraciones frecuentes de INSERT y UPDATE. Si es así, utilizae SQLiteen su lugar.Para concluir, creo que deberías probar DuckDB si eres un ingeniero de datos encargado de construir y optimizar canalizaciones de datos.
No tienes nada que perder y todo que ganar. La cosa es casi garantiza ser más rápido que cualquier cosa que Python pueda ofrecer. Funciona rapidísimo en tu portátil y te permite recorrer conjuntos de datos que, de otro modo, darían lugar a errores de memoria. Incluso puede conectarse a plataformas de almacenamiento en la nube en caso de que no quieras o no te esté permitido almacenar datos localmente.
Dicho esto, DuckDB no debería ser la única optimización que pongas sobre la mesa. Siempre debes esforzarte por optimizar los datos que entran en tu sistema. Por ejemplo, abandonar CSV en favor de Parquet te ahorrará tiempo de cálculo y almacenamiento. Otra optimización que deberías tener en cuenta es implementar los principios de la arquitectura de datos moderna entus flujos de trabajo y pipelines.
DuckDB es sólo una herramienta. Pero muy potente.
Nuestros programas de certificación te ayudan a destacar y a demostrar que tus aptitudes están preparadas para el trabajo a posibles empleadores.

¡Aprende más sobre ingeniería de datos con estos cursos!
programa
programa
Curso
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Satyam Tripathi


