Programa
Engenheiro de dados Em Python
40 h
Uma prática recomendada ao configurar um novo projeto Python é fazê-lo em um ambiente virtual. Mostrarei a você como fazer isso com conda e venv.
Estou usando o Anaconda para gerenciar ambientes e dependências. Se você também o fizer, execute o seguinte snippet para criar um novo ambiente virtual chamado dlt_env com base no Python 3.12:
conda create --name dlt_env python=3.12 -y
conda activate dlt_envVocê deverá ver uma saída semelhante a esta no terminal:
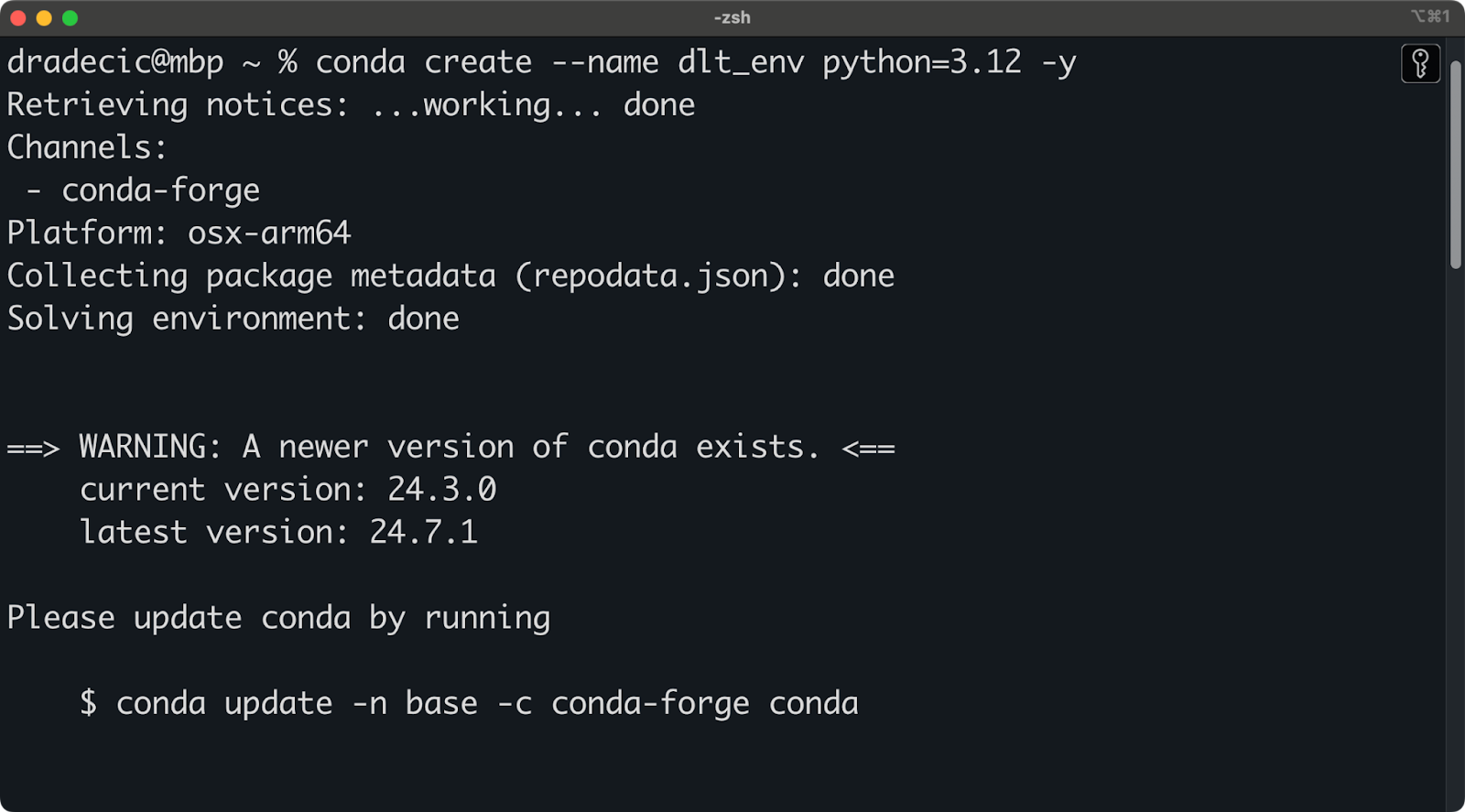
Configuração do ambiente Conda
Por outro lado, se você não estiver usando o Anaconda, execute o seguinte comando para criar e ativar um novo ambiente Python:
python -m venv ./env
source ./env/bin/activateAgora você está pronto para instalar o dlt.
Antes de continuar, você deve ter um ambiente virtual criado e ativado
Para instalar o dlt, execute o seguinte dentro do ambiente:
pip install dlt
dlt version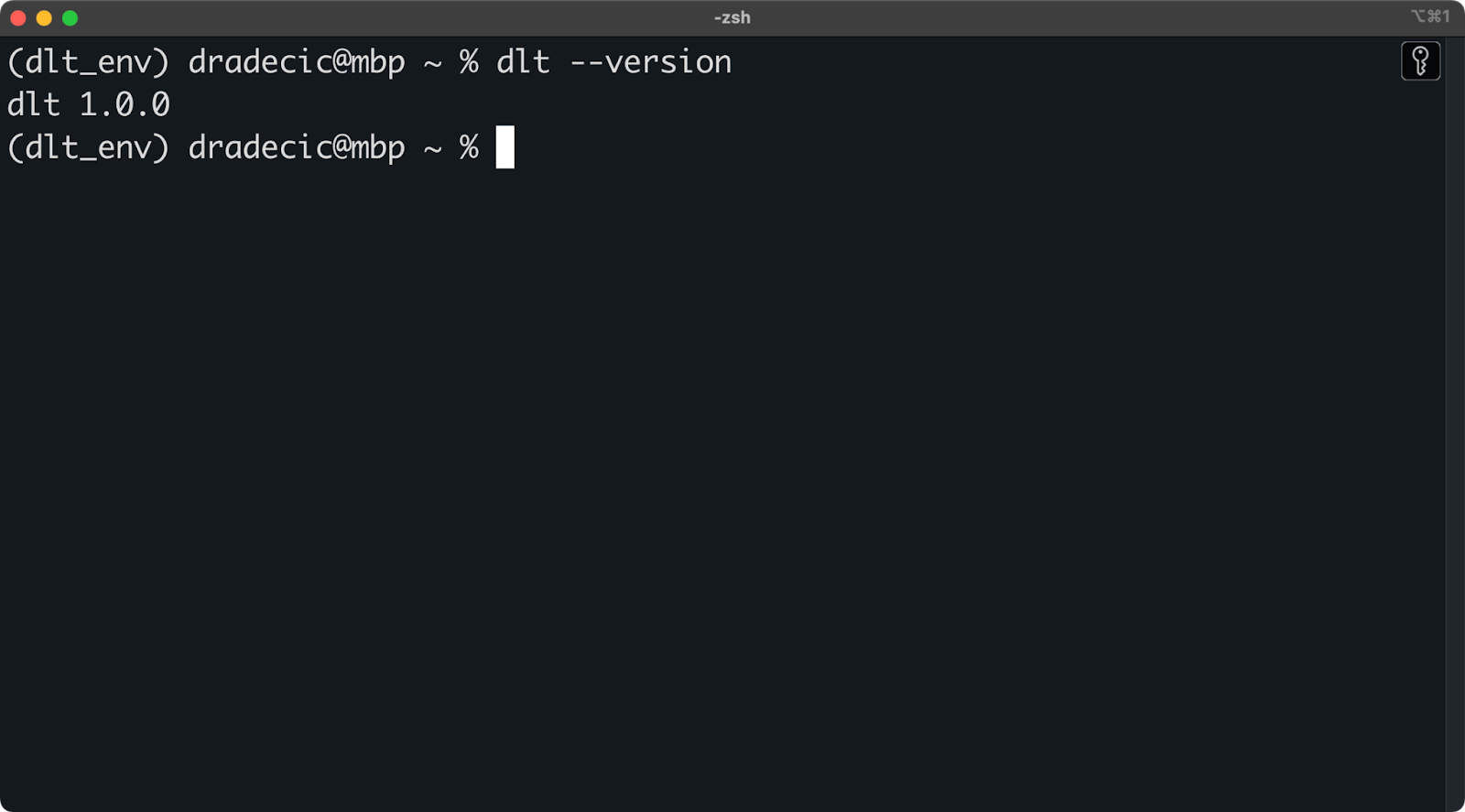
Versão instalada do dlt
Contanto que você não receba uma mensagem de erro ou uma mensagem mostrando que dlt não é reconhecido, você está pronto para começar!
Agora você pode usar a interface de linha de comando dlt para criar novos projetos a partir de um modelo.
Isso é feito por meio do comando dlt init . No snippet a seguir, mostro a você como criar um pipeline que usa uma API REST como fonte de dados e o DuckDB como destino (target):
dlt init rest_api_test duckdb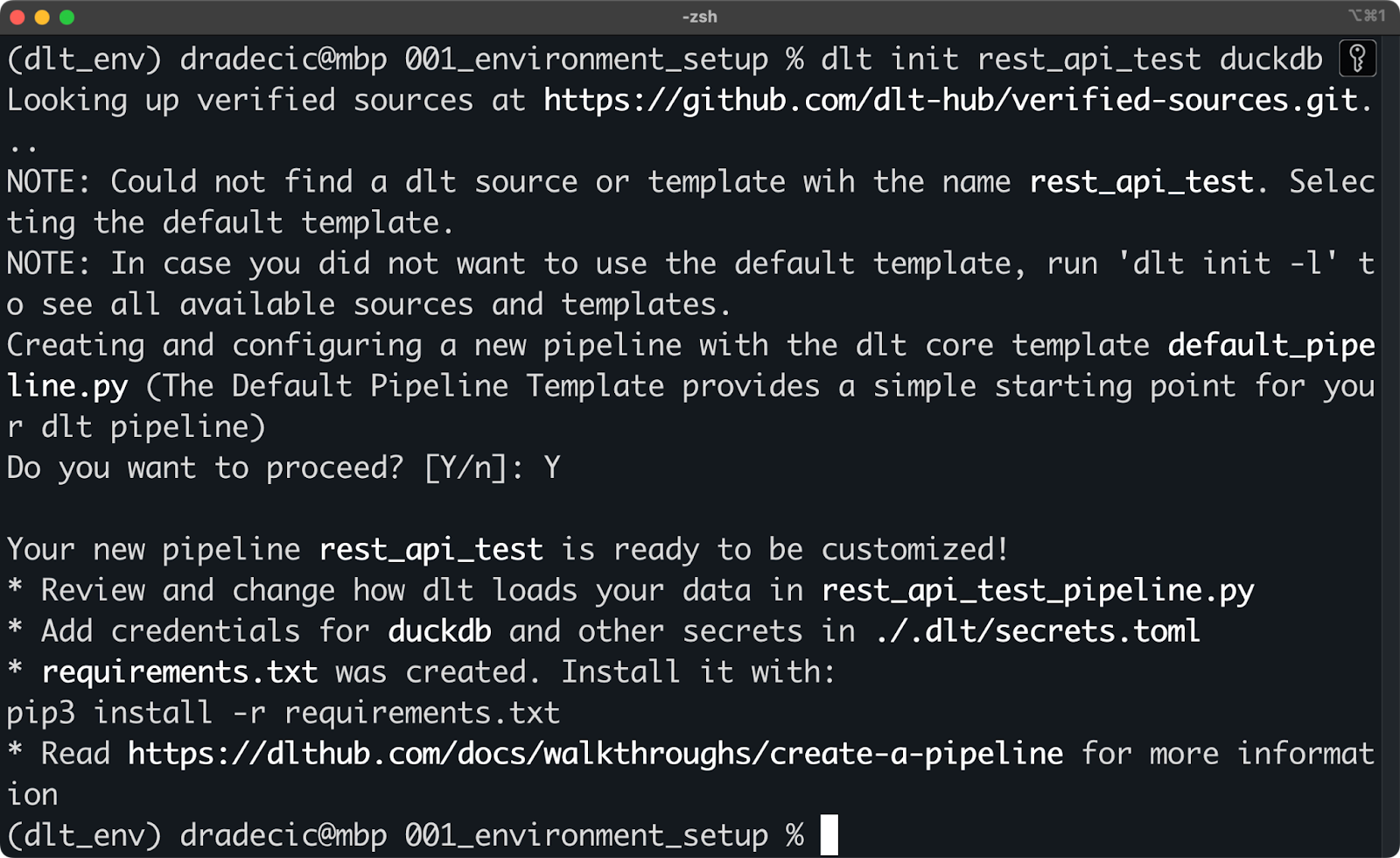
Inicialização de um novo projeto dlt com o DuckDB
Não há nada que impeça você de criar os arquivos manualmente, apenas certifique-se de que a estrutura de pastas seja semelhante à criada pelo dlt CLI. Por exemplo, isso é o que o comando do shell anterior criou em meu sistema:
.
├── requirements.txt
├── rest_api_test_pipeline.py
├── .dlt
│ ├── config.toml
│ ├── secrets.tomlA mágica acontece na pasta .dlt. Ele contém dois arquivos que abrangem tudo o que diz respeito àconfiguração do pipeline e às fontes e destinos de dados, como chaves de API e credenciais de banco de dados.
O rest_api_test_pipeline.py é um arquivo Python gerado automaticamente que mostra a você algumas maneiras de conectar uma API REST ao DuckDB.
Para começar, você deverá instalar tudo o que está listado em requirements.txt. Para isso, execute o seguinte comando:
pip install -r requirements.txtDepois de instalado, você está pronto para executar seu primeiro pipeline dlt!
Aqui está o conteúdo do arquivo rest_api_test_pipeline.py:
"""The Default Pipeline Template provides a simple starting point for your dlt pipeline"""
# mypy: disable-error-code="no-untyped-def,arg-type"
import dlt
from dlt.common import Decimal
@dlt.resource(name="customers", primary_key="id")
def rest_api_test_customers():
"""Load customer data from a simple python list."""
yield [
{"id": 1, "name": "simon", "city": "berlin"},
{"id": 2, "name": "violet", "city": "london"},
{"id": 3, "name": "tammo", "city": "new york"},
]
@dlt.resource(name="inventory", primary_key="id")
def rest_api_test_inventory():
"""Load inventory data from a simple python list."""
yield [
{"id": 1, "name": "apple", "price": Decimal("1.50")},
{"id": 2, "name": "banana", "price": Decimal("1.70")},
{"id": 3, "name": "pear", "price": Decimal("2.50")},
]
@dlt.source(name="my_fruitshop")
def rest_api_test_source():
"""A source function groups all resources into one schema."""
return rest_api_test_customers(), rest_api_test_inventory()
def load_stuff() -> None:
# specify the pipeline name, destination and dataset name when configuring pipeline,
# otherwise the defaults will be used that are derived from the current script name
p = dlt.pipeline(
pipeline_name='rest_api_test',
destination='duckdb',
dataset_name='rest_api_test_data',
)
load_info = p.run(rest_api_test_source())
# pretty print the information on data that was loaded
print(load_info) # noqa: T201
if __name__ == "__main__":
load_stuff()Deixe-me explicar os decoradores primeiro, pois você certamente nunca os viu antes:
@dlt.resource: Usado para criar um recurso genérico, por exemplo, uma tabela de banco de dados com um nome e um nome de coluna de chave primária. Você desejará acessar yield um conjunto de dados (por exemplo, uma lista do Python, um DataFrame do pandas) em vez de retorná-lo.@dlt.source: Usado para agrupar vários recursos, por exemplo, várias tabelas em um único esquema de banco de dados. A função deve retornar chamadas de função para seus recursos.As funções Python nesse arquivo são bastante simples, mas deixe-me explicar a lógica:
rest_api_test_customers(): Gera dados aleatórios sobre o nome e a cidade do cliente.rest_api_test_inventory(): Gera dados aleatórios sobre o nome e o preço do produto.rest_api_test_source(): Agrupa os dois recursos anteriores em um único esquema.load_stuff(): Cria e executa um pipeline que move dados fictícios do Python para um banco de dados DuckDB.Observe que os dados não são realmente obtidos de uma API REST, mas sua estrutura se parece exatamente com o JSON que qualquer API REST retornaria. Mais adiante neste artigo, mostrarei a você como trabalhar com APIs reais.
Por enquanto, execute o pipeline com o seguinte comando do shell:
python rest_api_test_pipeline.py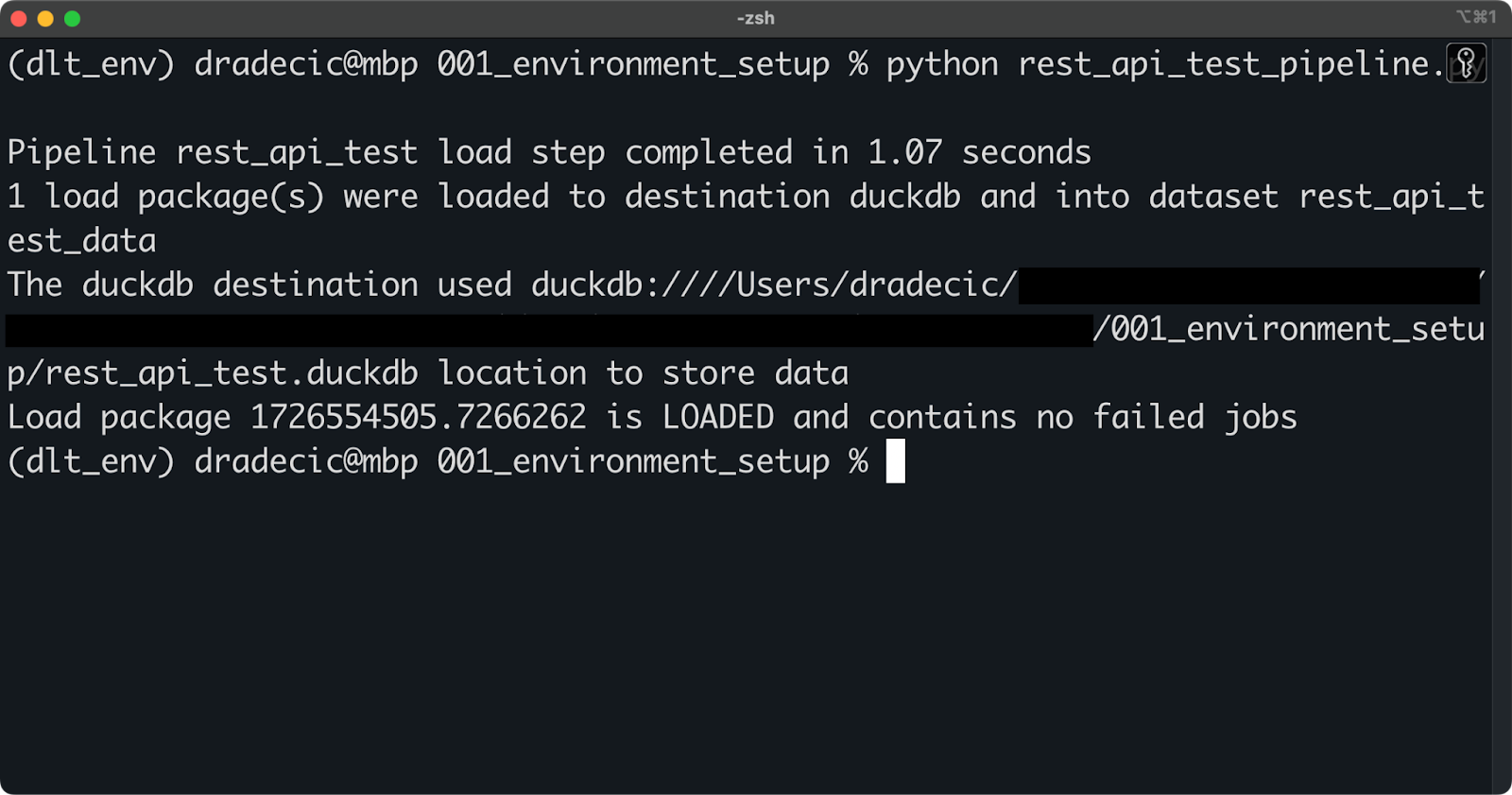
Executando o pipeline
Se você vir uma mensagem semelhante à mensagem acima, a execução do pipeline foi bem-sucedida.
Você pode se conectar ao arquivo DuckDB local por meio de qualquer ferramenta de banco de dados (estou usando o TablePlus). Uma vez lá, seus dados estarão dentro de um esquema especificado no parâmetro dataset_name em dlt.pipeline().
A tabela customers mostra os dados gerados com o Python, com a adição de duas colunas de linhagem de dados:
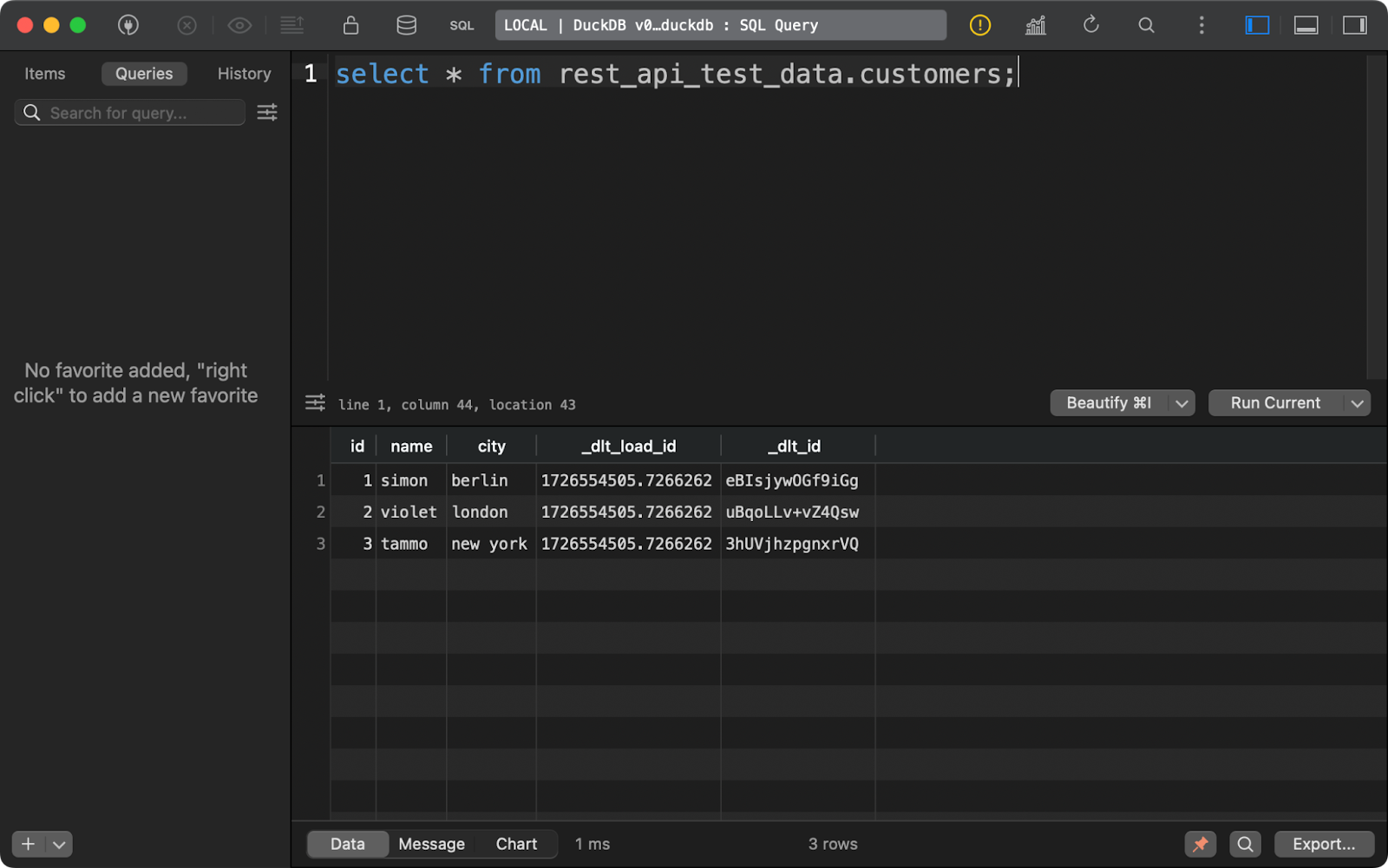
Conteúdo da tabela de clientes
O mesmo se aplica à tabela inventory. Observe que a coluna price contém NULLs. É provável que haja um problema com o tipo de dados Decimal que o dlt usou por padrão neste exemplo:
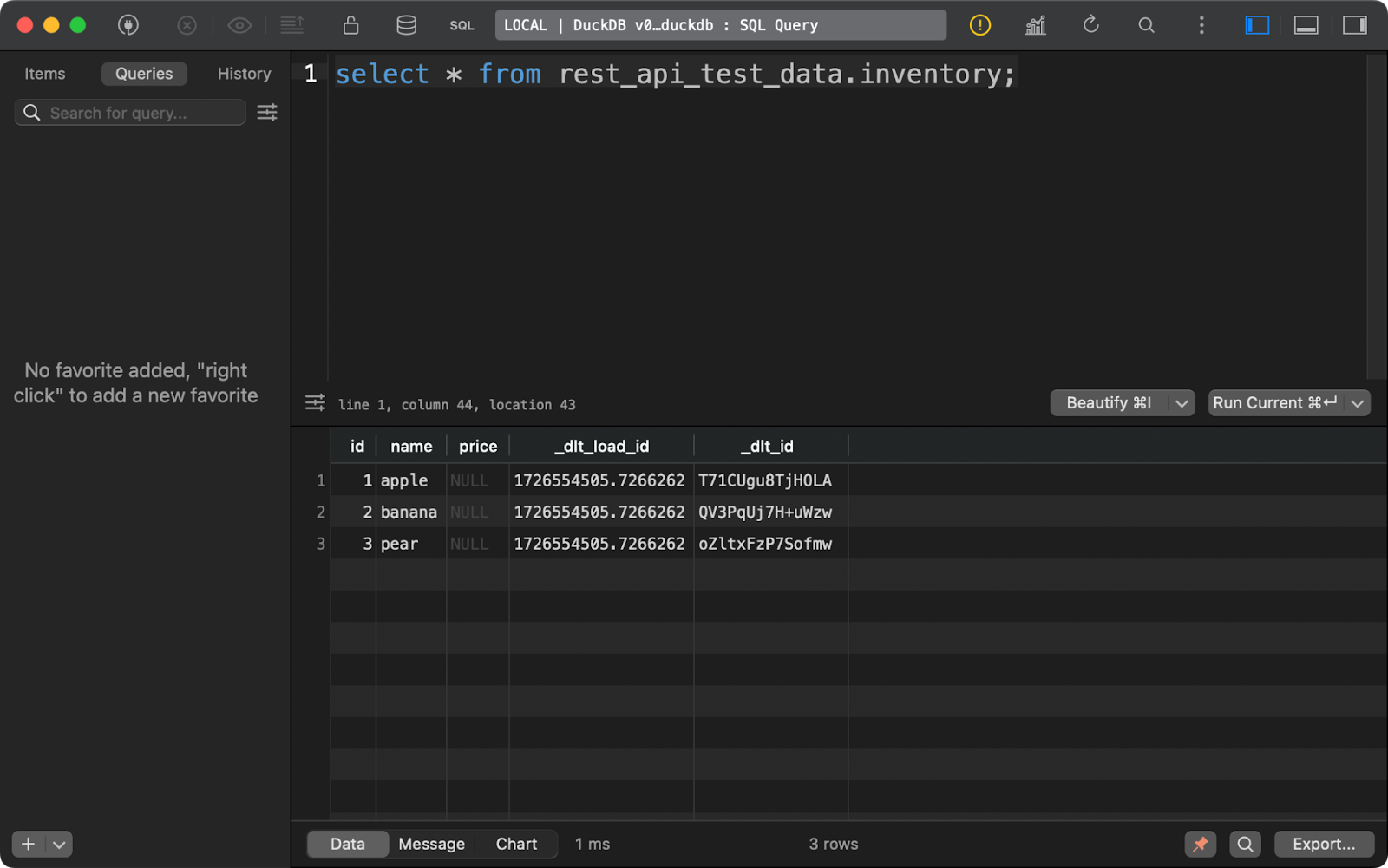
Conteúdo da tabela de inventário
Sempre que você executar um pipeline, o site dlt criará (ou anexará) três tabelas de metadados.
O primeiro, _dlt_loads, rastreia o histórico de cargas de dados realizadas pelo pipeline. Ele mostra o nome do esquema, o status do carregamento e a hora do carregamento, entre outras coisas:
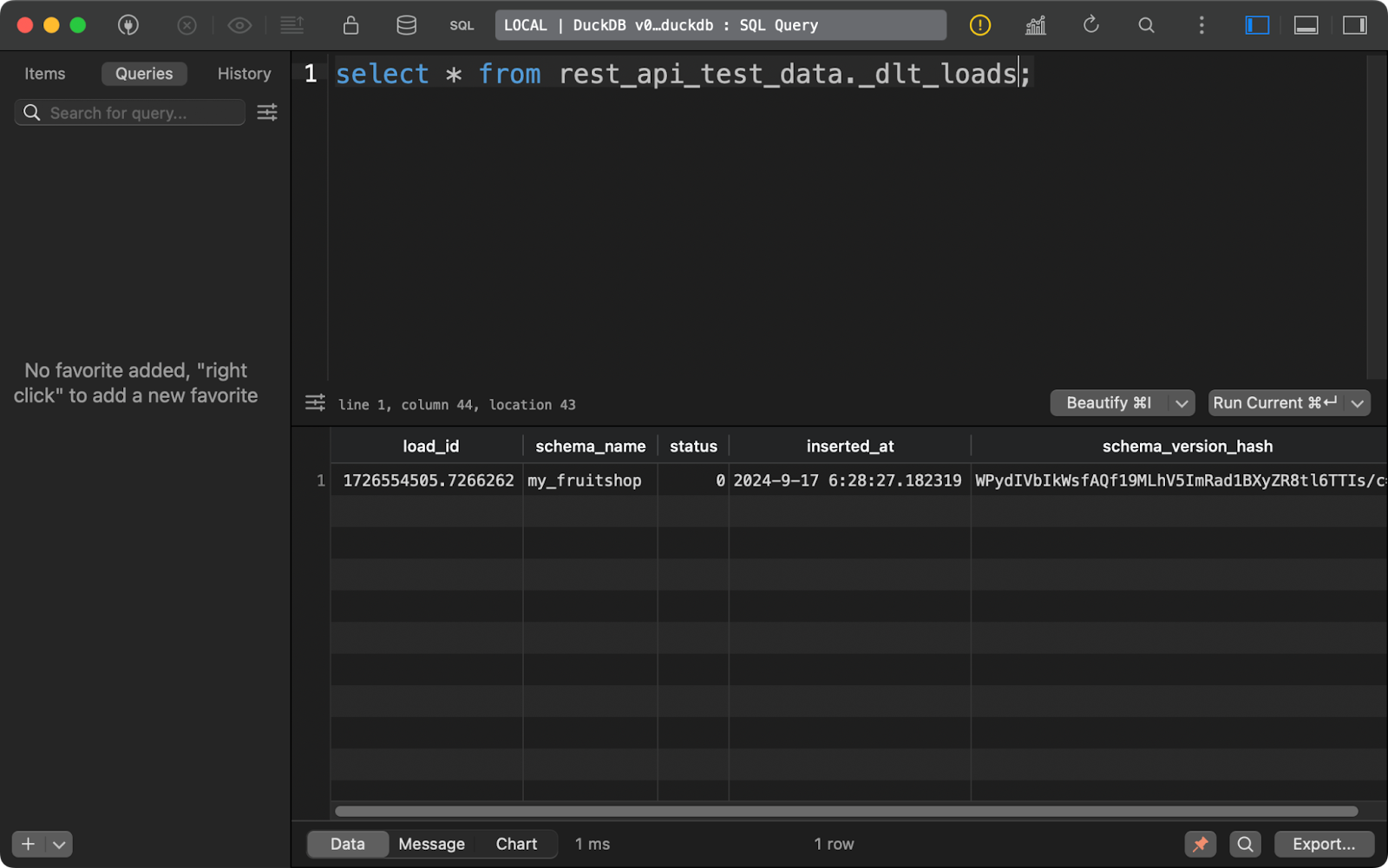
Histórico de cargas de dados
A tabela _dlt_pipeline_state mostra detalhes sobre a configuração, os pontos de verificação e o progresso do pipeline. Também é útil nos casos em que o pipeline é interrompido por qualquer motivo, pois os dados dessa tabela podem retomá-lo de onde parou:
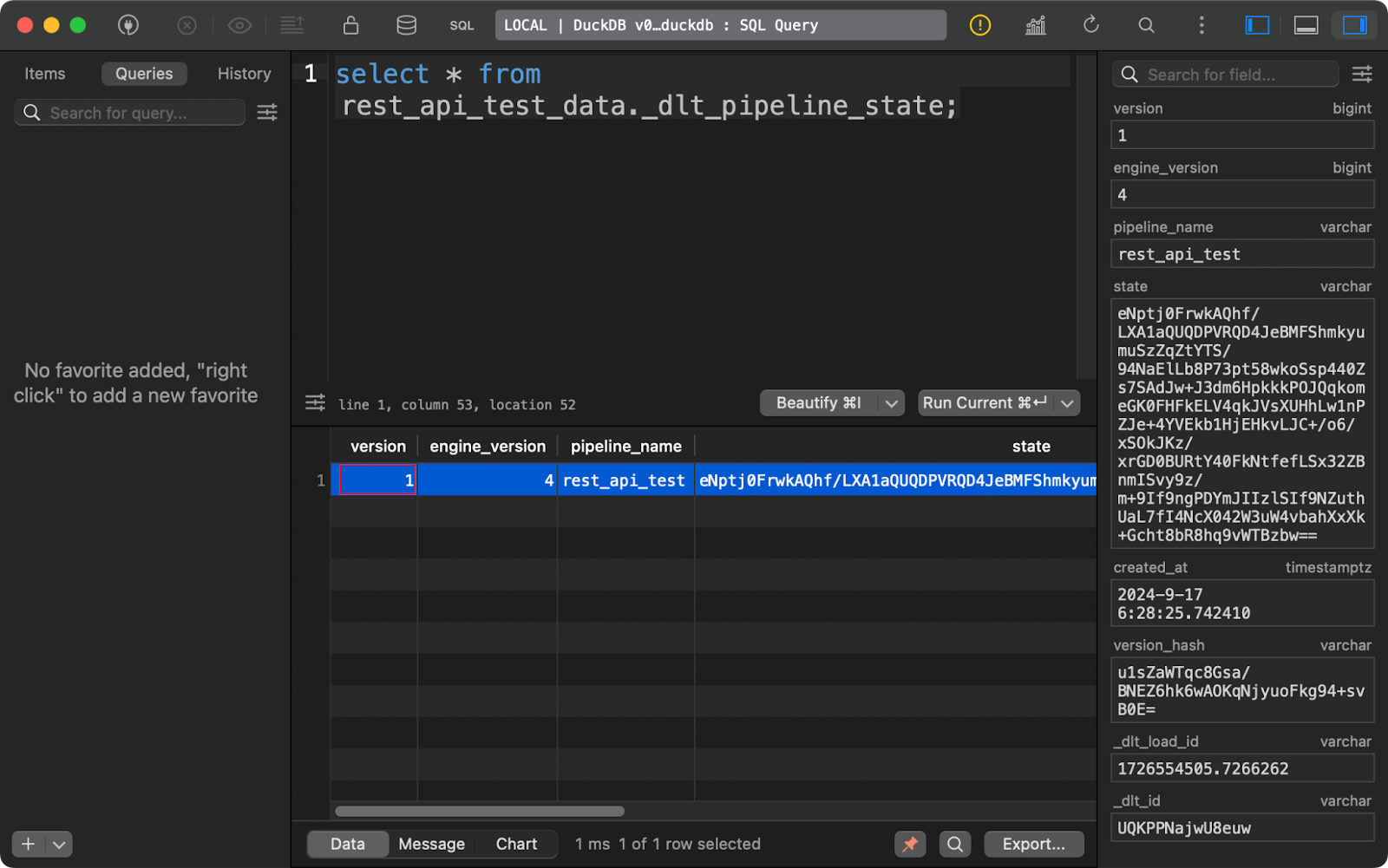
Tabela de estado do pipeline
Por fim, a tabela _dlt_version armazena informações sobre a própria biblioteca para garantir a compatibilidade:
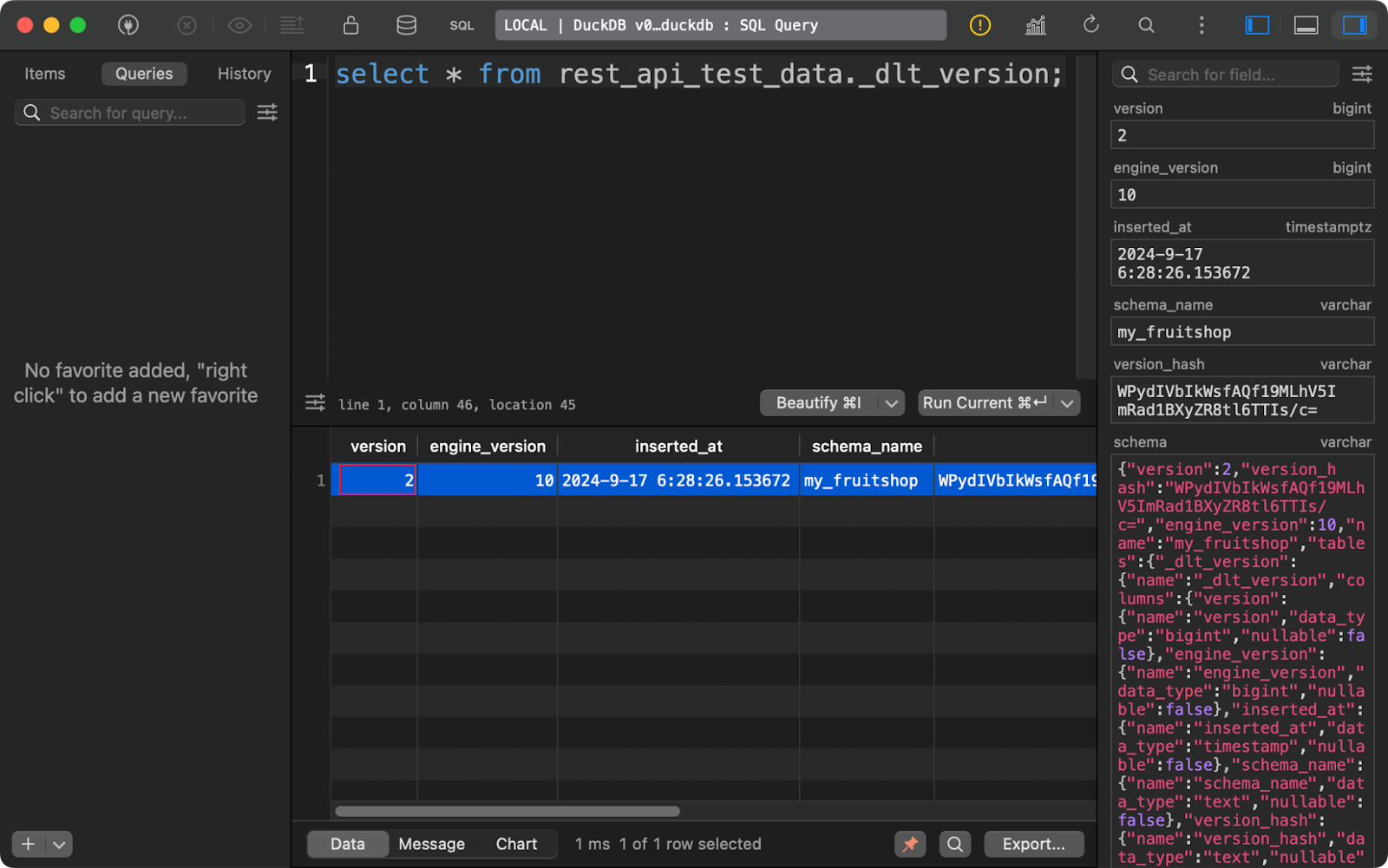
Tabela de versões do dlt
Quando combinadas, essas três tabelas de metadados fornecem todos os detalhes que você deseja acompanhar ao longo do tempo para gerenciar seus pipelines de dados com eficiência.
Agora você tem uma visão geral de alto nível de como funciona o dlt. A seguir, mostrarei a você como extrair dados de diferentes fontes.
Nesta seção, abordarei quatro tipos de fontes de dados: APIs REST, bancos de dados, armazenamento em nuvem e sistema de arquivos local.
As APIs REST estão no centro quando se trata de fontes para pipelines de dados. A biblioteca dlt faz com que você trabalhe com eles sem esforço.
Para demonstração, usarei a API JSONPlaceholder que tem pontos de extremidade para buscar publicações, comentários e usuários, entre outras coisas. Quanto ao destino dos dados, optarei pelo DuckDB, pois ele não exige nenhuma configuração.
Para se conectar a uma API REST, use a função rest_api_source(). Você pode passar um dicionário que forneça o URL da API básica e as regras de paginação. Você pode adicionar outras propriedades, por exemplo, paraautenticação , mas a API que escolhi é acessível publicamente, portanto, não é necessária.
A parte interessante vem da propriedade resources. Aqui, você fornecerá uma lista de pontos de extremidade dos quais o dlt deve buscar os dados. Por exemplo, o recurso posts se conectará a https://jsonplaceholder.typicode.com/posts. Você pode ajustar os recursos individuais com muito mais profundidade, mas deixarei isso a seu critério.
O restante desse arquivo Python permanece mais ou menos inalterado:
import dlt
from dlt.sources.rest_api import rest_api_source
def load_rest_api_data() -> None:
data_source = rest_api_source({
"client": {
"base_url": "https://jsonplaceholder.typicode.com/",
"paginator": {
"type": "json_response",
"next_url_path": "paging.next"
}
},
"resources": [
"posts",
"comments",
"users"
]
})
pipeline = dlt.pipeline(
pipeline_name="rest_api_jsonplaceholder",
destination="duckdb",
dataset_name="jsonplaceholder"
)
load_info = pipeline.run(data_source)
print(load_info)
if __name__ == "__main__":
load_rest_api_data()Depois de executar o pipeline, você verá três tabelas de dados, uma para cada recurso especificado.
A primeira mostra postagens fictícias:
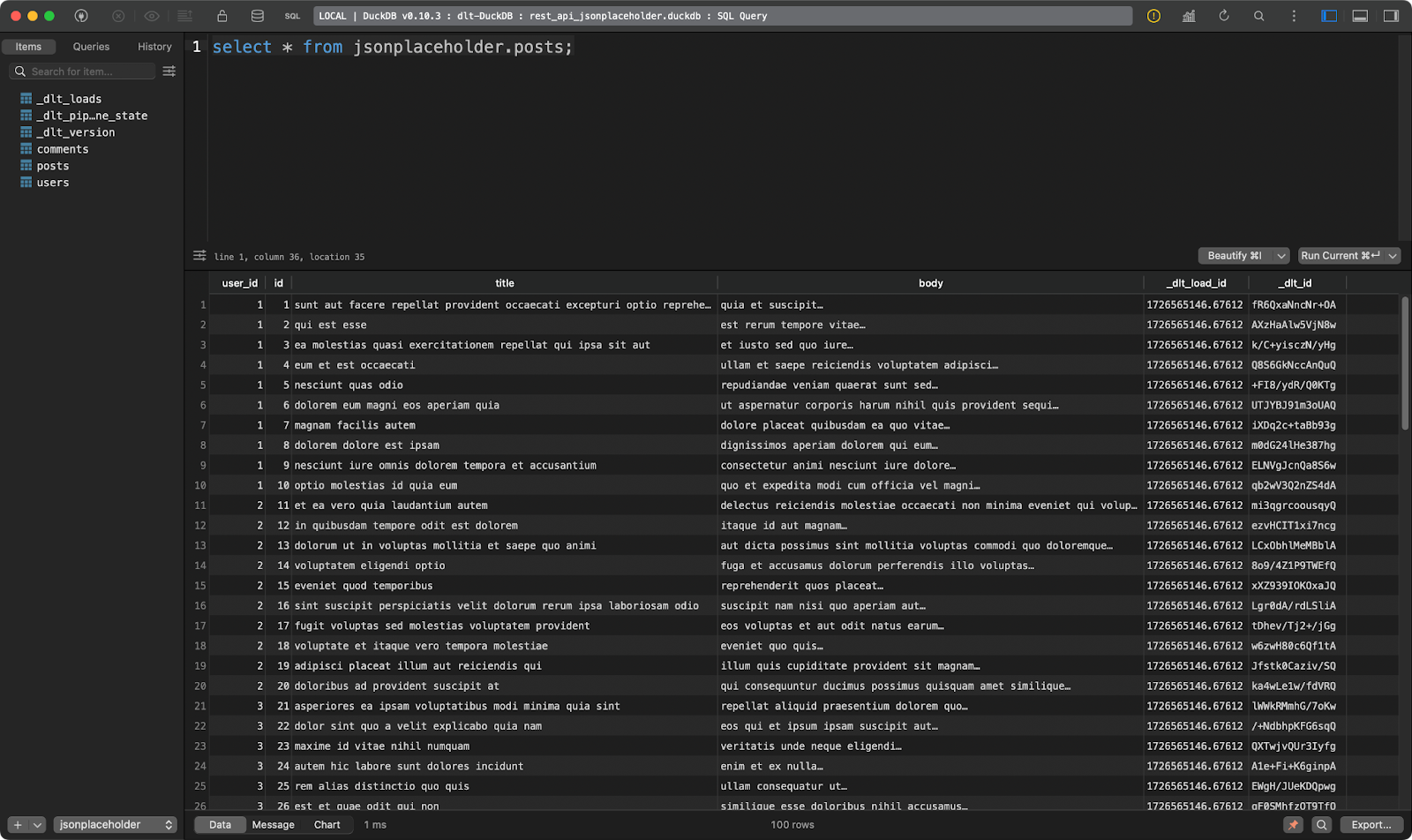
Mesa de postagens
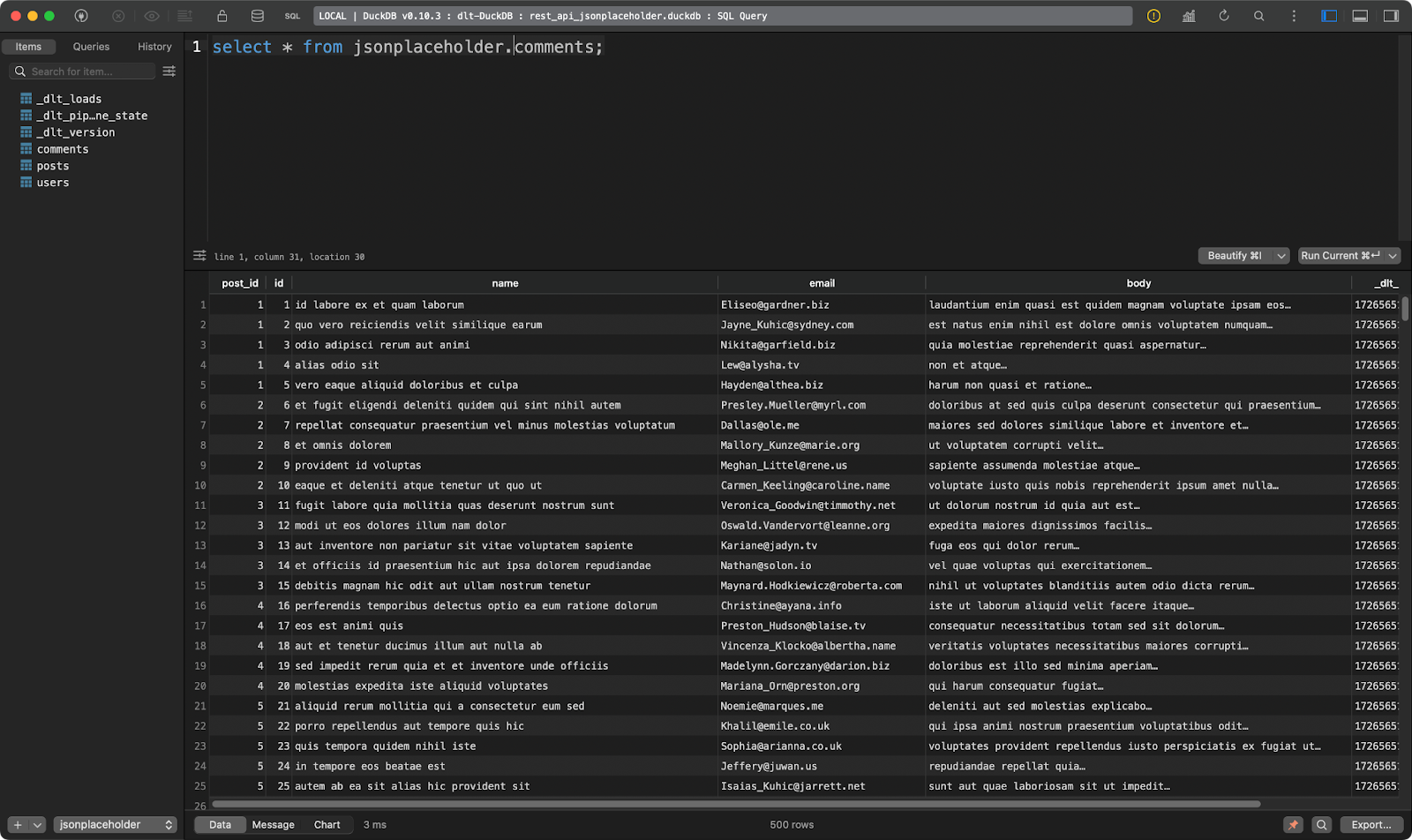
A segunda mostra os comentários das postagens:
Tabela de comentários
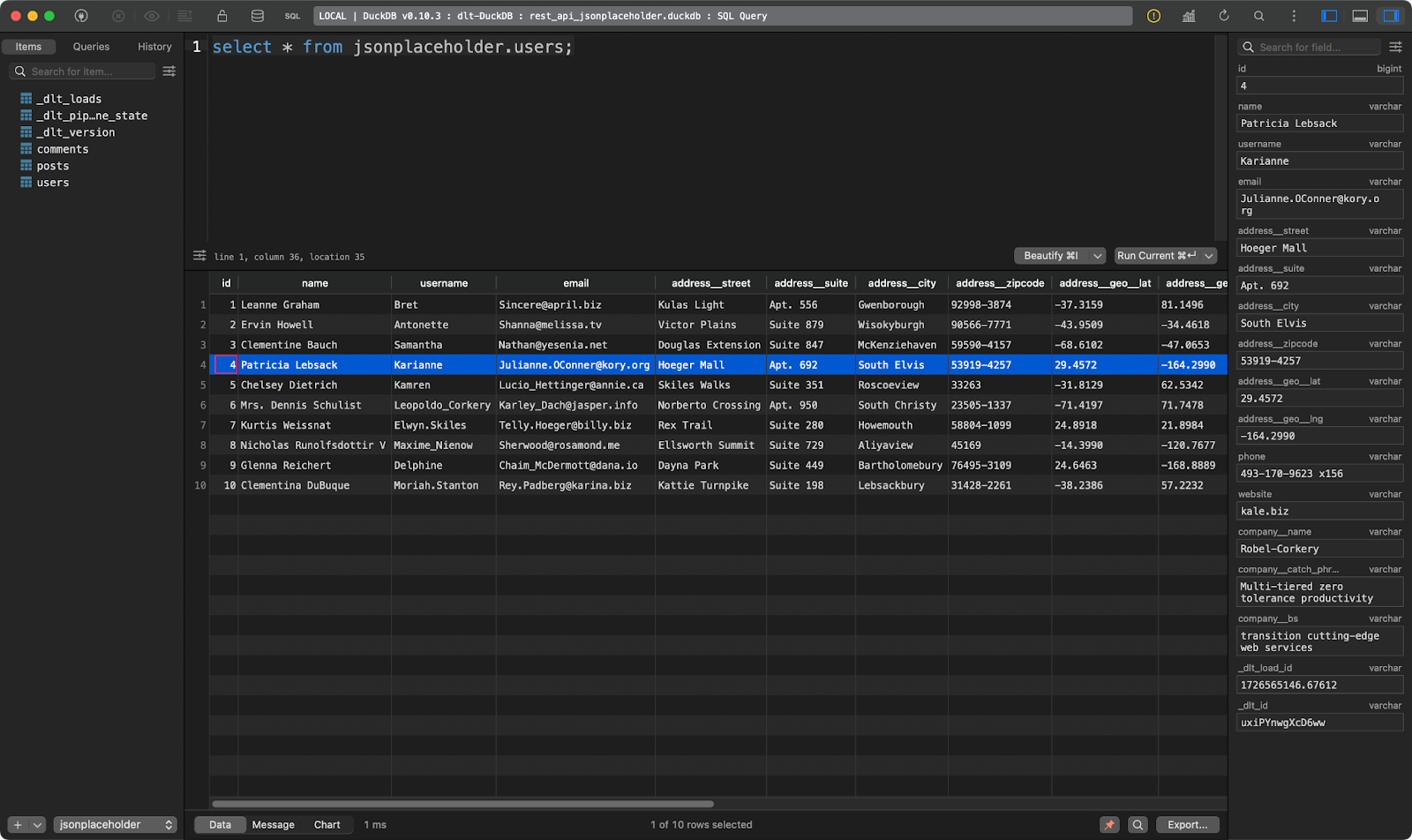
E a terceira mostra os usuários. Este é interessante porque contém dados JSON aninhados. A biblioteca dlt a nivelou, de modo que ela pode ser armazenada sem problemas em uma única tabela:
users tabela
Legal, não é? Você não precisa mais analisar o JSON manualmente.
Se há uma fonte de dados mais comumente usada do que as APIs REST, ela deve ser um banco de dados relacional.
Para fins de demonstração, provisionei um banco de dados Postgres de camada livre no AWS:
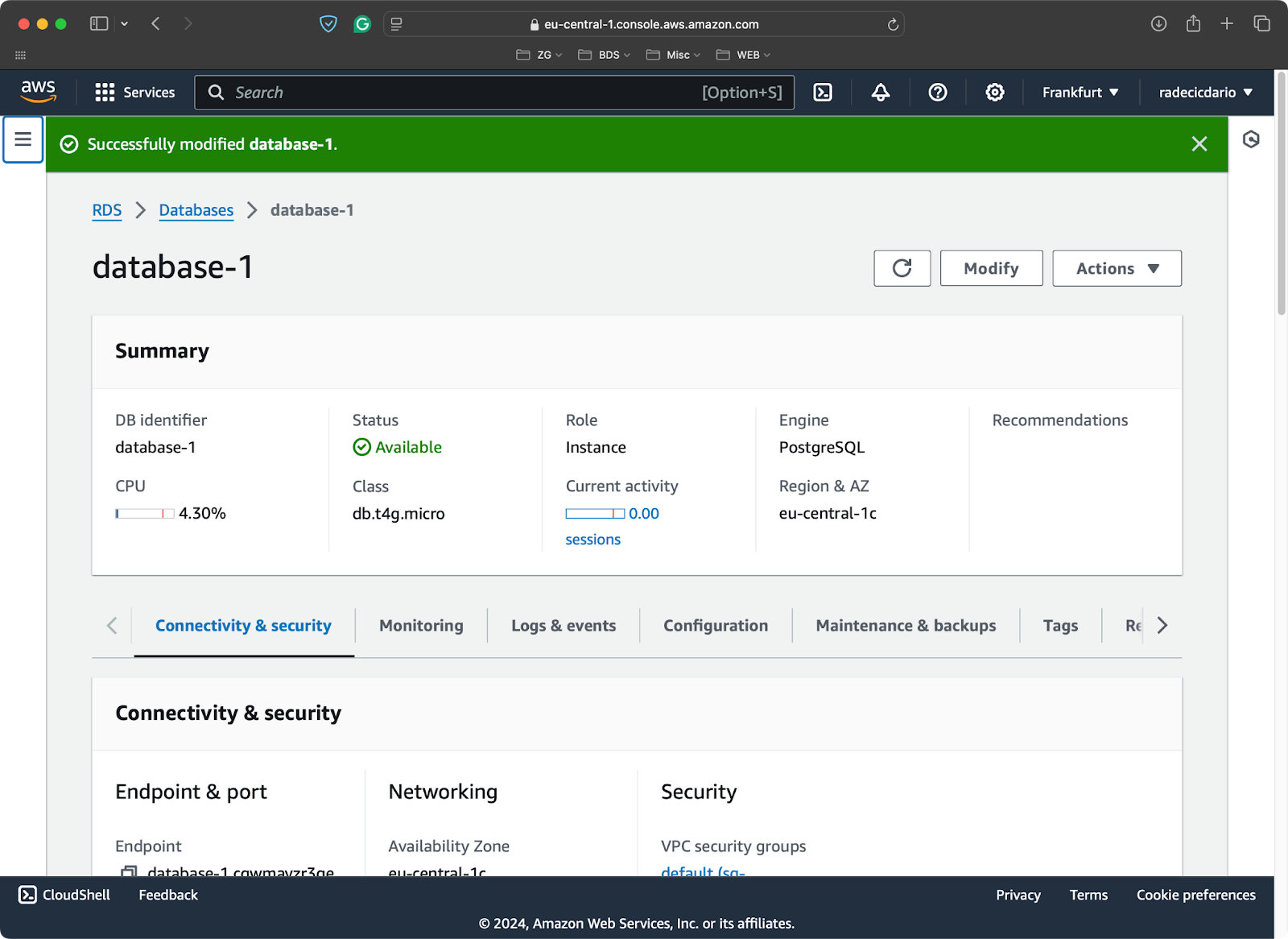
Banco de dados PostgreSQL no AWS
E carregou o conhecido conjunto de dados Iris como uma tabela:
Dados no banco de dados Postgres
Agora, mostrarei a você como se conectar a uma fonte Postgres em dlt. É um processo mais complexo do que você pode pensar inicialmente.
Primeiro, comece instalando um submódulo para trabalhar com bancos de dados SQL:
pip install "dlt[sql_database]"Em seguida, inicialize um pipeline que use um banco de dados SQL genérico como origem e o DuckDB como destino:
dlt init sql_database duckdbEsta é a primeira vez que você vai brincar com os arquivos da pasta .dtl. Em config.toml, especifique o nome da tabela de origem da qual você deseja extrair os dados:
[sources.sql_database]
table = "table" # please set me up!
[runtime]
dlthub_telemetry = trueSubstitua ”table” por “iris” e você estará pronto para começar.
Em secrets.toml, você deverá especificar os parâmetros de conexão para se conectar ao banco de dados de origem. Observe que você deve absolutamente adicionar o nome [sources.sql_database.credentials] antes de especificar os parâmetros de conexão. Caso contrário, o site dlt não saberá a que eles se referem:
[sources.sql_database.credentials]
drivername = "drivername" # please set me up!
database = "database" # please set me up!
password = "password" # please set me up!
username = "username" # please set me up!
host = "host" # please set me up!
port = 0 # please set me up!E isso é tudo em relação à configuração. Agora você pode alternar para o arquivo de pipeline do Python.
Em resumo, você só precisa chamar a função sql_database() para se conectar ao banco de dados e extrair os dados de origem. Cada detalhe de configuração é especificado nos arquivos TOML, portanto, você pode chamar essa função sem nenhum parâmetro.
O restante do roteiro não apresenta nada de novo:
import dlt
from dlt.sources.sql_database import sql_database
def load_database_data() -> None:
source = sql_database()
pipeline = dlt.pipeline(
pipeline_name="postgres_to_duckdb_pipeline",
destination="duckdb",
dataset_name="iris_from_postgres"
)
load_info = pipeline.run(source)
print(load_info)
if __name__ == "__main__":
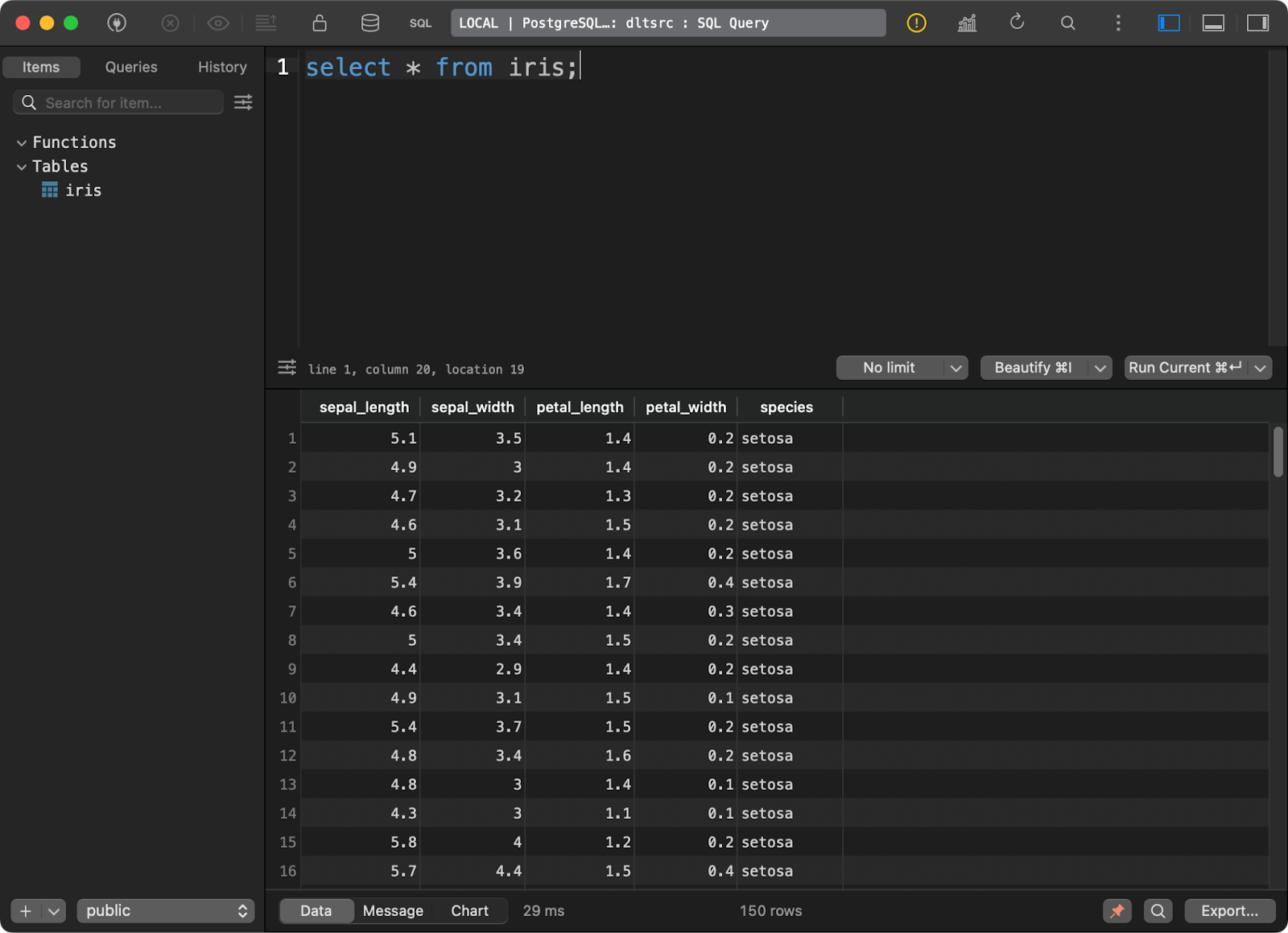
load_database_data()
Mesa Iris
A tabela de destino no DuckDB tem todos os dados da Iris com as duas colunas adicionais de linhagem de dados.
Na maioria das vezes, você desejará que seus pipelines se conectem ao armazenamento em nuvem, como os buckets do AWS S3.
Criei um bucket do S3 para este artigo e fiz upload de um único arquivo Parquet com conjuntos de dados do projeto viagens de táxi em Nova York:
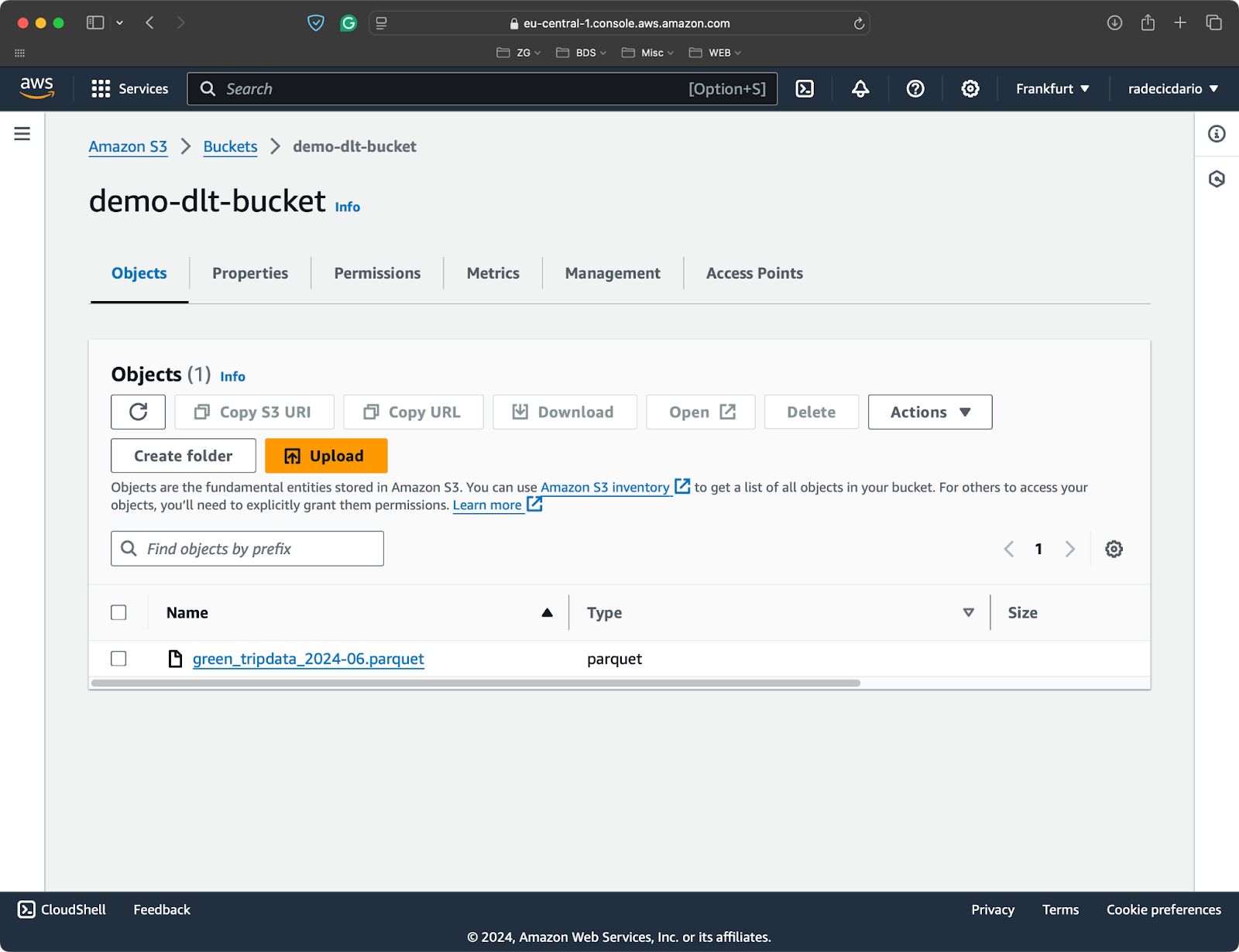
Balde S3 com um único arquivo Parquet
Para conectar um sistema de arquivos local ou remoto a dlt, você precisará instalar um submódulo adicional:
pip install "dlt[filesystem]"Agora você pode inicializar um novo pipeline que usa um sistema de arquivos como origem e o DuckDB como destino:
dlt init filesystem duckdbA primeira ordem do dia é preencher os arquivos de configuração. O arquivo config.toml precisa do URL completo do seu bucket S3:
[sources.filesystem]
bucket_url = "bucket_url" # please set me up!
[runtime]
dlthub_telemetry = trueE o arquivo secrets.toml precisa de informações sobre sua função de IAM (chave de acesso e chave de acesso secreta), juntamente com a região em que seu bucket está provisionado:
[sources.filesystem.credentials]
aws_access_key_id = "aws_access_key_id" # please set me up!
aws_secret_access_key = "aws_secret_access_key" # please set me up!
region_name = "region_name" # please set me up!Para o código do pipeline.
Use a função readers() para ler dados de sua fonte configurada. O parâmetro file_glob controla quais arquivos devem ser lidos. Eu o configurei de forma a retornar todos os arquivos Parquet. Em seguida, basta encadear a função read_parquet() para ler os dados:
import dlt
from dlt.sources.filesystem import readers, read_parquet
def load_s3_data() -> None:
source = readers(file_glob="*.parquet").read_parquet()
pipeline = dlt.pipeline(
pipeline_name="s3_to_duckdb_pipeline",
destination="duckdb",
dataset_name="nyc_data_from_s3"
)
load_info = pipeline.run(source.with_name("nyc_taxi_data"))
print(load_info)
if __name__ == "__main__":
load_s3_data()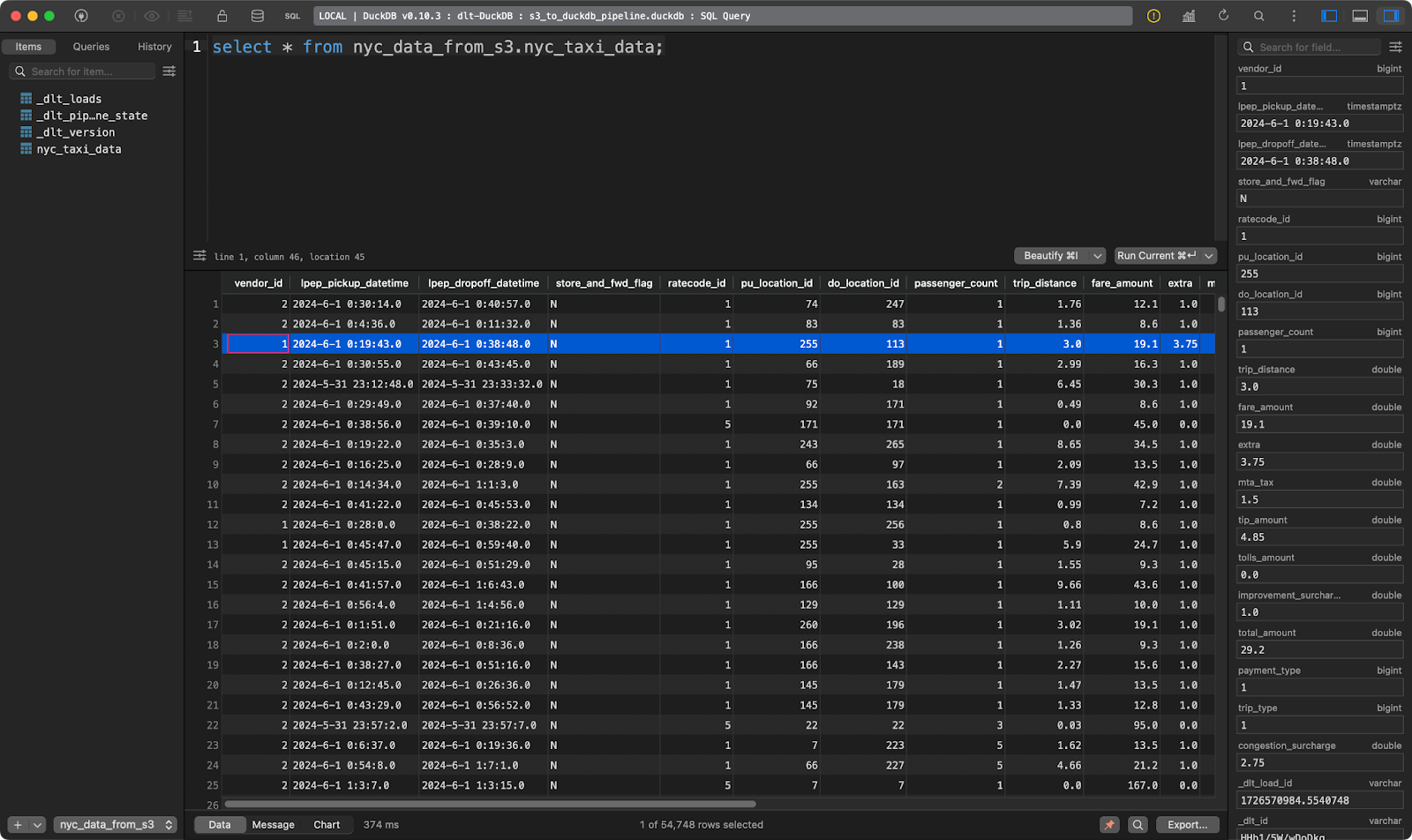
Tabela de viagens de táxi em Nova York
E aí está, dezenas de milhares de registros carregados em segundos!
A leitura de dados de um sistema de arquivos local é quase idêntica à leitura de dados do S3.
Desta vez, estou usando o conjunto de dados conjunto de dados mtcars salvo localmente em uma pasta localbucket:
Arquivo em um sistema local
Agora, no arquivo config.toml, forneça um caminho absoluto para a pasta local. É importante que você prefixe o caminho com file:///. São três cortes:
[sources.filesystem]
bucket_url = "file:///absolute/path/to/local/folder"
[runtime]
dlthub_telemetry = trueComo você não está mais se conectando ao S3, pode excluir o conteúdo de secrets.toml.
O código real do pipeline será quase idêntico ao da seção anterior. A única mudança é que em file_glob você agora está fornecendo um nome de arquivo e usando uma função diferente para ler os dados (formato CSV):
import dlt
from dlt.sources.filesystem import filesystem, read_csv_duckdb
def load_local_data() -> None:
source = filesystem(file_glob="mtcars.csv") | read_csv_duckdb()
pipeline = dlt.pipeline(
pipeline_name="local_filesystem_to_duckdb_pipeline",
destination="duckdb",
dataset_name="mtcars_data_from_local_disk"
)
load_info = pipeline.run(source.with_name("mtcars"))
print(load_info)
if __name__ == "__main__":
load_local_data()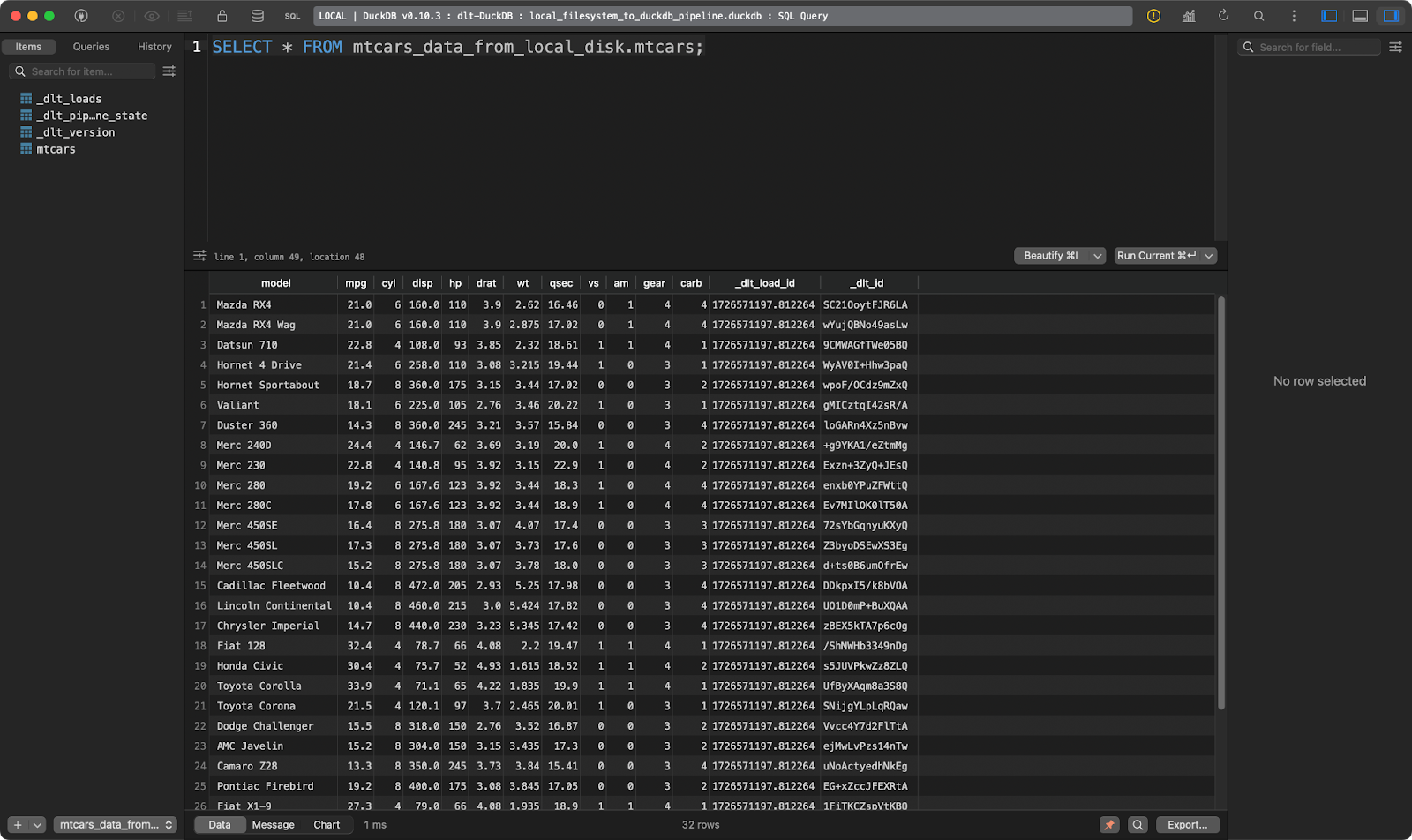
A tabela mtcars
Funciona muito bem!
Isso é tudo o que eu quero mostrar em relação às fontes de dados. Você pode encontrar muitas outras para atender às suas necessidades específicas emna página de documentação do dlt para fontes de dados.
Não adianta apenas mover os dados do ponto A para o ponto B. Normalmente, você deseja aplicar a transformação antes de gravar os dados no destino (ETL) ou depois (ELT).
Se os acrônimos ETL e ELT não lhe parecerem familiares, recomendamos que você façanosso curso de pipeline de dados com Python.
Nesta seção, mostrarei a você como aplicar transformações aos seus dados com SQL e Python.
Os engenheiros de dados vivem e respiram SQL. Nesta seção, mostrarei a você como carregar um arquivo local em um banco de dados Postgres, transformá-lo e gravá-lo novamente em outra tabela (ELT).
Comece ajustando o arquivo secrets.toml para incluir os detalhes da conexão do banco de dados para a origem e o destino. Os valores serão idênticos, você só precisa especificá-los duas vezes:
[sources.sql_database.credentials]
drivername = "drivername" # please set me up!
database = "database" # please set me up!
password = "password" # please set me up!
username = "username" # please set me up!
host = "host" # please set me up!
port = 0 # please set me up!
[destinations.sql_database.credentials]
drivername = "drivername" # please set me up!
database = "database" # please set me up!
password = "password" # please set me up!
username = "username" # please set me up!
host = "host" # please set me up!
port = 0 # please set me up!Dentro de config.toml, escreva um caminho absoluto para uma pasta localizada em seu sistema de arquivos:
[sources.filesystem]
bucket_url = "file:///absolute/path/to/local/folder"
[runtime]
dlthub_telemetry = trueO arquivo do pipeline Python terá duas funções:
load_source_data(): Ele carrega um arquivo CSV local e o salva em uma tabela em um banco de dados Postgres.transform_data(): Ele extrai dados de uma tabela do Postgres e cria uma nova tabela com base na tabela original. Acrescentarei apenas algumas colunas para provar um ponto. A tabela de destino é excluída primeiro, se existir.Você deverá chamar as funções uma após a outra:
import dlt
from dlt.sources.filesystem import filesystem, read_csv
def load_source_data() -> None:
source = filesystem(file_glob="iris.csv") | read_csv()
pipeline = dlt.pipeline(
pipeline_name="load_source_data",
destination="postgres",
dataset_name="data"
)
load_info = pipeline.run(source.with_name("iris_src"), write_disposition="replace")
print(load_info)
def transform_data() -> None:
pipeline = dlt.pipeline(
pipeline_name="transform_data",
destination="postgres",
dataset_name="data"
)
try:
with pipeline.sql_client() as client:
client.execute_sql("""
DROP TABLE iris_tgt;
""")
print(f"Table iris_tgt deleted!")
except Exception as e:
print(f"Table iris_tgt does not exists, proceeding!")
try:
with pipeline.sql_client() as client:
client.execute_sql("""
CREATE TABLE iris_tgt AS (
SELECT
sepal_length,
sepal_width,
petal_length,
petal_width,
sepal_length + sepal_width AS total_sepal,
petal_length + petal_width AS total_petal,
UPPER(species) AS species_upper
FROM iris_src
);
""")
print(f"Table iris_tgt created and filled!")
except Exception as e:
print(f"Unable to transform data! Error: {str(e)}")
if __name__ == "__main__":
load_source_data()
transform_data()A tabela de origem contém o conjunto de dados Iris com duas colunas adicionais de linhagem de dados:
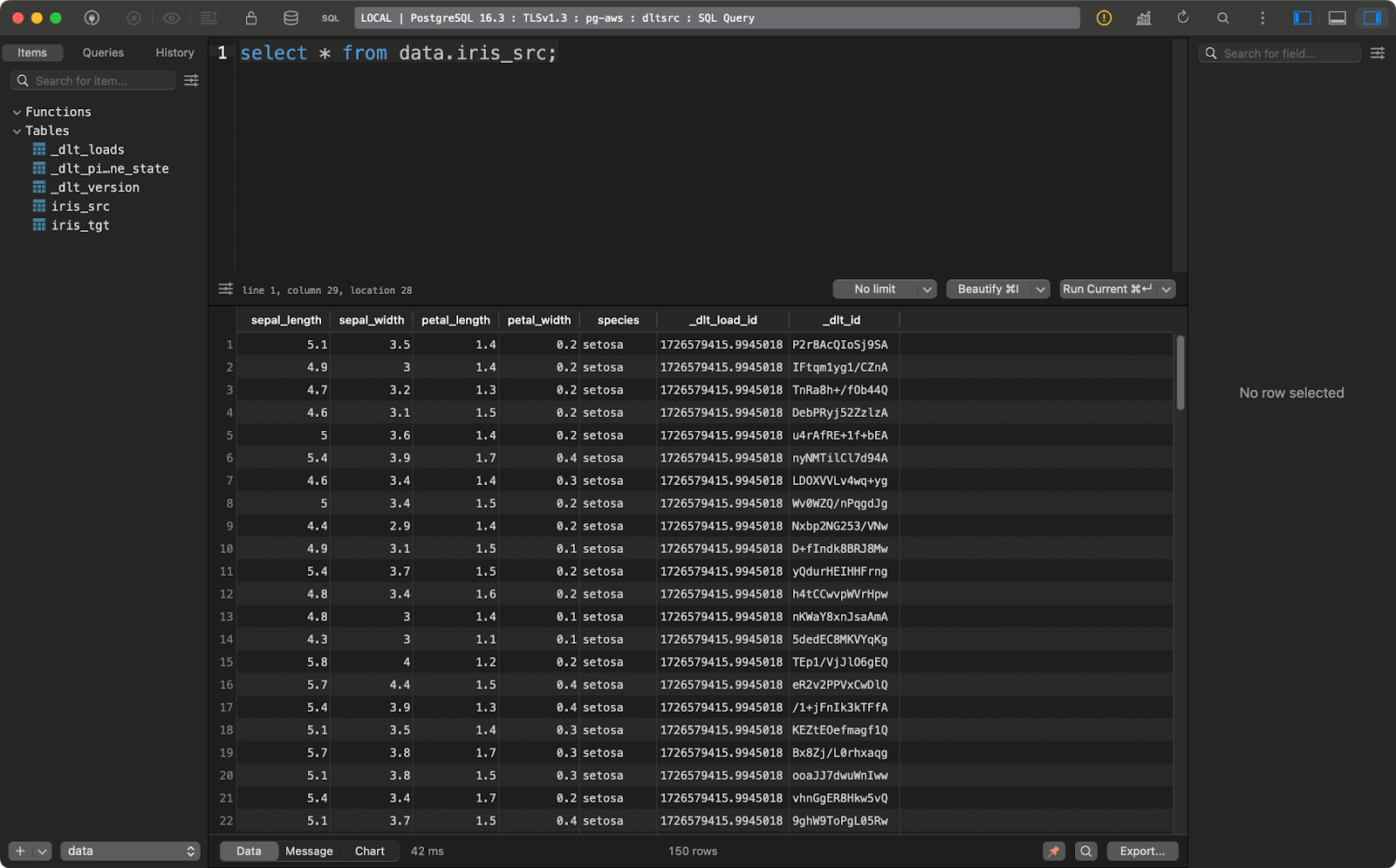
Tabela de origem da Iris
E a tabela de destino contém a versão transformada do conjunto de dados Iris:
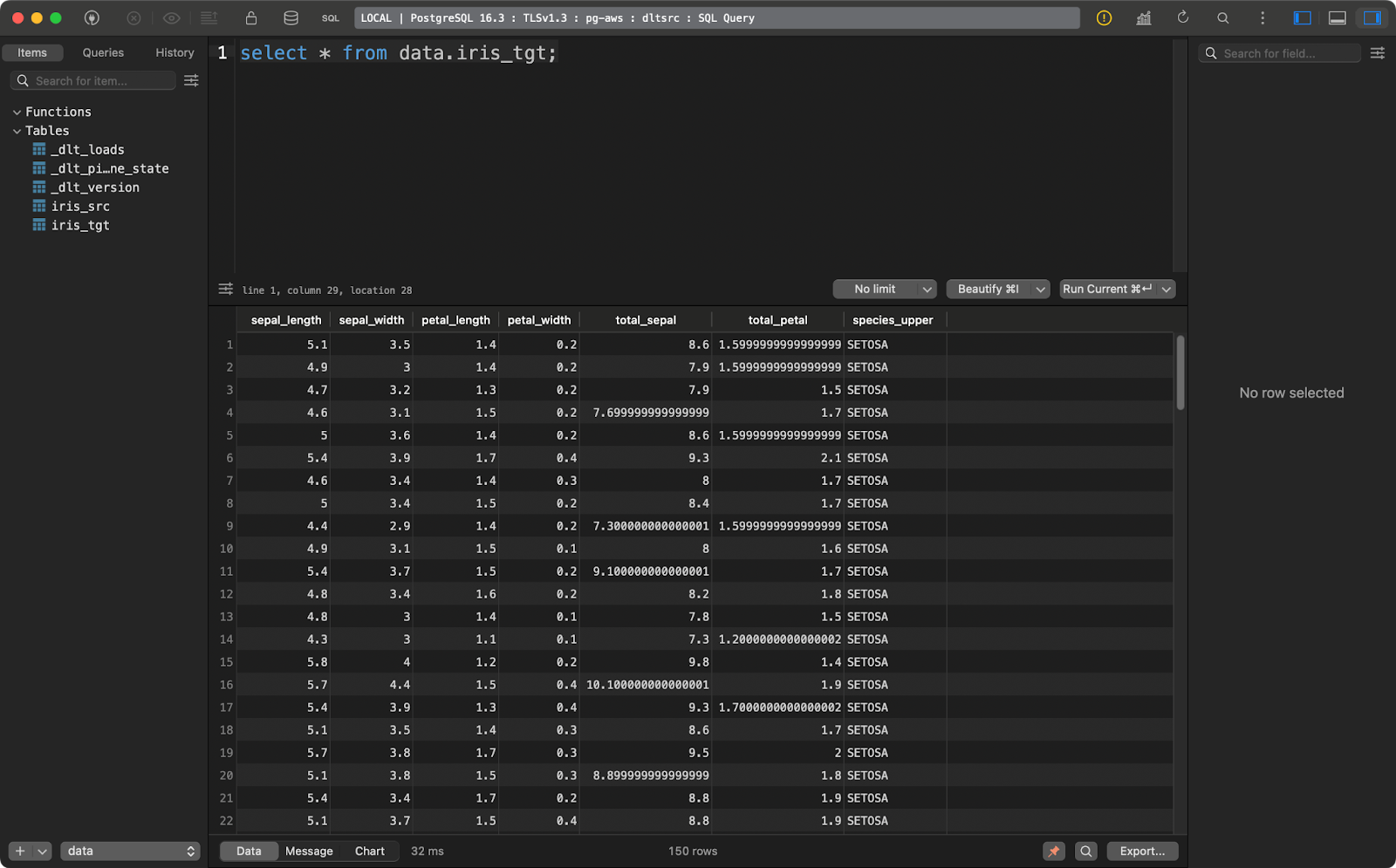
Tabela de destino da íris
Esse exemplo de transformação é bastante básico, mas explica como transformar seus dados quando eles já estão carregados no destino.
E se você quiser transformar os dados antes de gravá-los no banco de dados? Em outras palavras, se você não quiser salvar dados brutos e transformados? Essa é basicamente uma descrição de um pipeline de ETL. Mostrarei a você como implementar um com pandas.
Seus arquivos TOML permanecem inalterados.
No código do pipeline, agora você precisará implementar algumas funções adicionais:
extract_data(): Usa o site pandas para ler um arquivo CSV local.transform_data(): Aplica transformações de dados usando pandas em vez de SQL.data(): Uma função decorada com @dlt.resource que produz o conjunto de dados transformado.load_data(): Carrega o endereço dlt.resource na tabela iris_tgt.O código desse pipeline parecerá familiar se você tiver experiência com o pandas:
import dlt
import pandas as pd
def extract_data() -> pd.DataFrame:
return pd.read_csv("iris.csv")
def transform_data(df: pd.DataFrame) -> pd.DataFrame:
df["sepal_sum"] = df["sepal_length"] + df["sepal_width"]
df["petal_sum"] = df["petal_length"] + df["petal_width"]
df = df.drop(["sepal_length", "sepal_width", "petal_length", "petal_width"], axis=1)
return df
@dlt.resource
def data():
yield transform_data(df=extract_data())
def load_data() -> None:
pipeline = dlt.pipeline(
pipeline_name="pandas_etl_pipeline",
destination="duckdb",
dataset_name="data"
)
load_info = pipeline.run(data(), table_name="iris_tgt")
print(load_info)
if __name__ == "__main__":
load_data()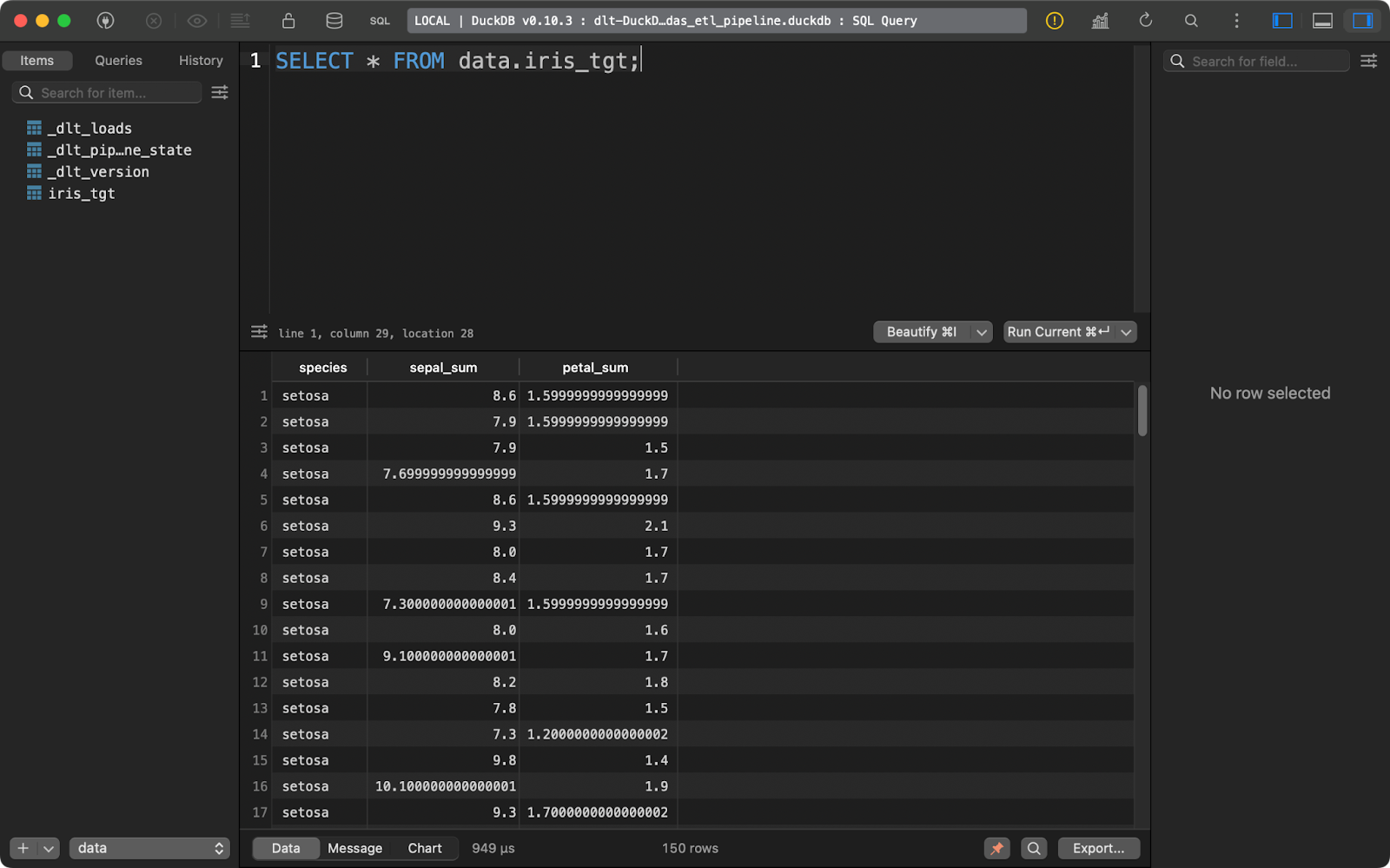
Tabela de destino da íris
Mais uma vez, o site dlt foi projetado com o ELT em mente, mas os fluxos de trabalho de ETL não exigem muitas alterações no código.
Tanto o SQL quanto o pandas são maneiras fáceis de transformar dados antes e depois do carregamento no destino.
Os autores do site dlt recomendam que você use o dbt ido Python. É uma opção muito melhor e mais versátil, mas é uma ferramenta complexa demais para ser abordada em um único artigo. Se você ou sua equipe já estiverem usando o dbt, usá-lo nos pipelines do dlt parecerá uma extensão natural.
Se você quiser saber mais sobre dbt em Python, temos um curso completo de curso completo de 4 módulos disponível.
Por outro lado, se você for um iniciante com conhecimentos básicos de SQL e pandas, as duas abordagens de transformação que mostrei são suficientes para você começar.
Até o momento, usei o DuckDB como destino de escolha porque ele é simples e não requer configuração. Nesta seção, mostrarei a você como trabalhar com alguns dosmais destinos,inclusive um sistema de arquivos local, armazenamento em nuvem e bancos de dados.
Às vezes, você deseja salvar o resultado de um pipeline de dados no disco. Agora, o dlt não é o candidato perfeito para o trabalho, pois também armazena muitos metadados, mas você pode usá-lo se for absolutamente necessário.
Comece ajustando o arquivo config.toml. Forneça caminhos para as pastas de origem e destino em seu sistema local:
[sources.filesystem]
bucket_url = "file:///path/to/source/folder"
[destination.filesystem]
bucket_url = "file:///path/to/target/folder"
[runtime]
dlthub_telemetry = trueAgora, no arquivo Python, basta carregar o arquivo de origem de um sistema de arquivos e executá-lo no pipeline. Por uma questão de simplicidade, não apliquei nenhuma transformação de dados:
import dlt
from dlt.sources.filesystem import filesystem, read_csv
def load_local_data() -> None:
source = filesystem(file_glob="iris.csv") | read_csv()
pipeline = dlt.pipeline(
pipeline_name="local_to_local",
destination="filesystem",
dataset_name="data"
)
load_info = pipeline.run(source.with_name("iris"), loader_file_format="csv")
print(load_info)
if __name__ == "__main__":
load_local_data()Esse é o conteúdo da pasta de destino:
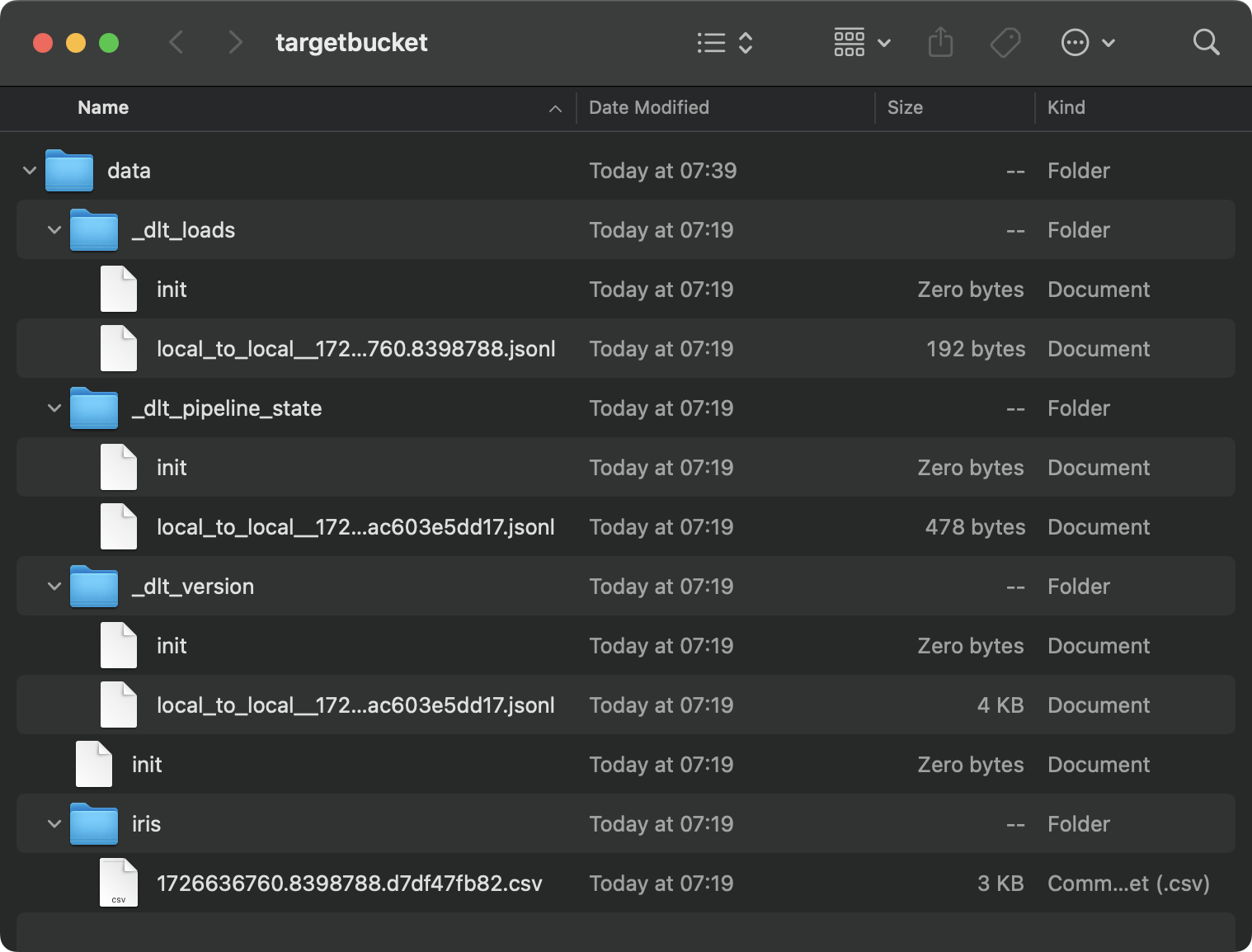
Conteúdo da pasta local
É uma bagunça, e isso é apenas o resultado de um único pipeline. Imagine que você tivesse dezenas deles.
Os bancos de dados são locais mais naturais para armazenar essas informações.
Estou usando um banco de dados Postgres provisionado no AWS, mas você não precisa fazer isso. Você pode usar qualquer outro banco de dados e fornecedor de nuvem.
Em config.toml, você deverá fornecer um caminho para a pasta no sistema de arquivos local:
[sources.filesystem]
bucket_url = "file:///your-local-bucket"
[runtime]
dlthub_telemetry = trueE em secrets.toml, escreva os detalhes da conexão com o banco de dados:
[destination.postgres.credentials]
drivername = "drivername" # please set me up!
database = "database" # please set me up!
password = "password" # please set me up!
username = "username" # please set me up!
host = "host" # please set me up!
port = 0 # please set me up!O carregamento de dados de origem no banco de dados agora se resume a alterar o valor do parâmetro destination em dlt.pipeline(). A função with_name() chamada na fonte de dados controla como a tabela do banco de dados será nomeada:
import dlt
from dlt.sources.filesystem import filesystem, read_csv
def load_to_database() -> None:
source = filesystem(file_glob="iris.csv") | read_csv()
pipeline = dlt.pipeline(
pipeline_name="local_to_db",
destination="postgres",
dataset_name="local_load"
)
load_info = pipeline.run(source.with_name("iris_from_local"))
print(load_info)
if __name__ == "__main__":
load_to_database()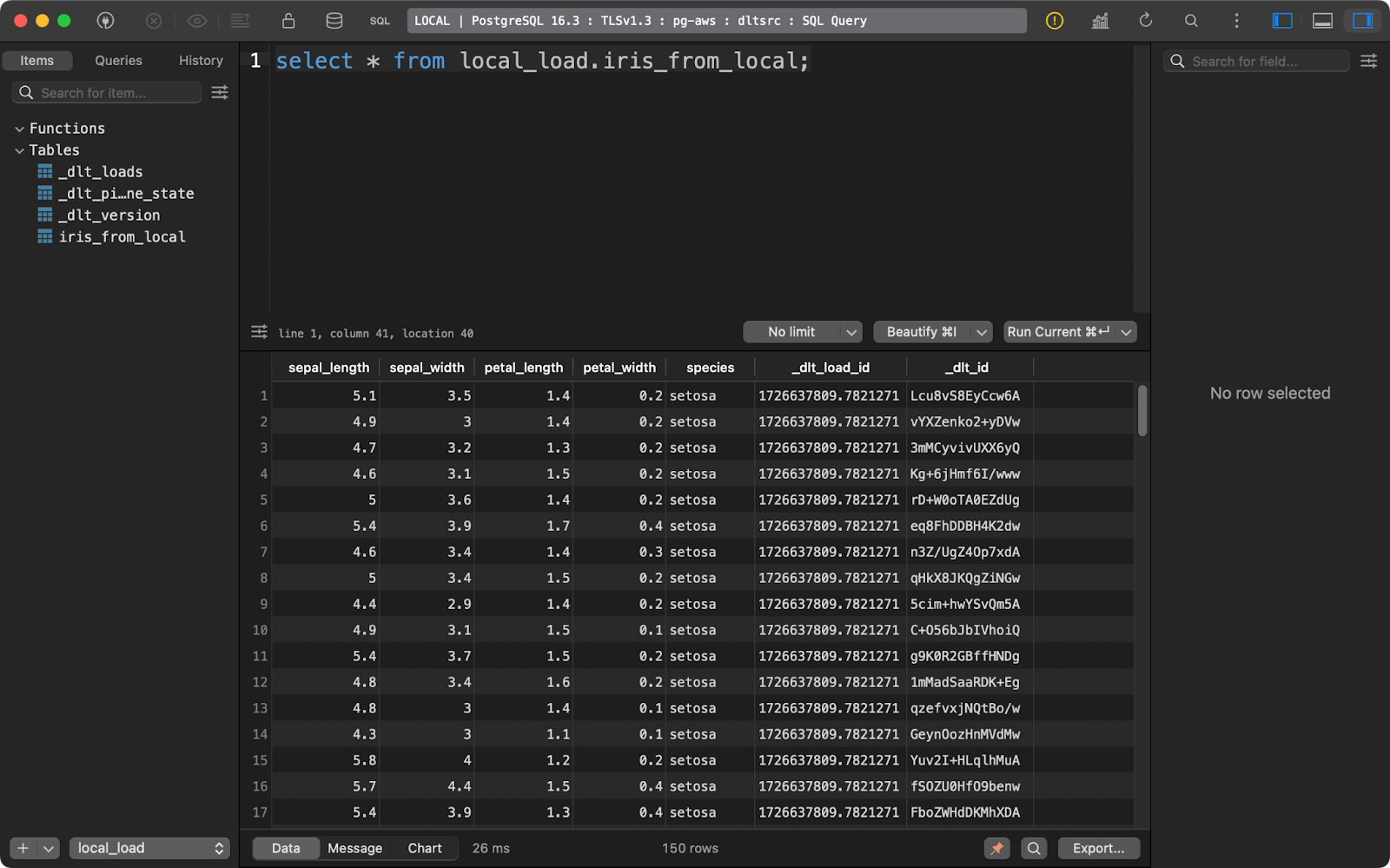
Dados da íris carregados
Vamos explorar mais uma opção de destino antes de falarmos de assuntos mais avançados do dlt.
Assim como no seu sistema de arquivos local, o armazenamento em nuvem (por exemplo, S3) também armazenará metadados em arquivos e pastas separados.
Se você quiser experimentar, comece ajustando o arquivo config.toml para incluir caminhos para uma pasta local e o bucket S3:
[sources.filesystem]
bucket_url = "file:///path/to/local/folder"
[destination.filesystem]
bucket_url = "s3://bucket-name"
[runtime]
dlthub_telemetry = trueEm secrets.toml, insira suas credenciais de IAM e o nome da região do bucket S3:
[destination.filesystem.credentials]
aws_access_key_id = "aws_access_key_id" # please set me up!
aws_secret_access_key = "aws_secret_access_key" # please set me up!
region_name = "region_name" # please set me up!A execução do pipeline transferirá o arquivo CSV local para o S3 e o armazenará no formato JSONL (linhas JSON):
import dlt
from dlt.sources.filesystem import filesystem, read_csv
def load_to_s3() -> None:
source = filesystem(file_glob="iris.csv") | read_csv()
pipeline = dlt.pipeline(
pipeline_name="local_to_db",
destination="filesystem",
dataset_name="iris_data"
)
load_info = pipeline.run(source.with_name("iris"))
print(load_info)
if __name__ == "__main__":
load_to_s3()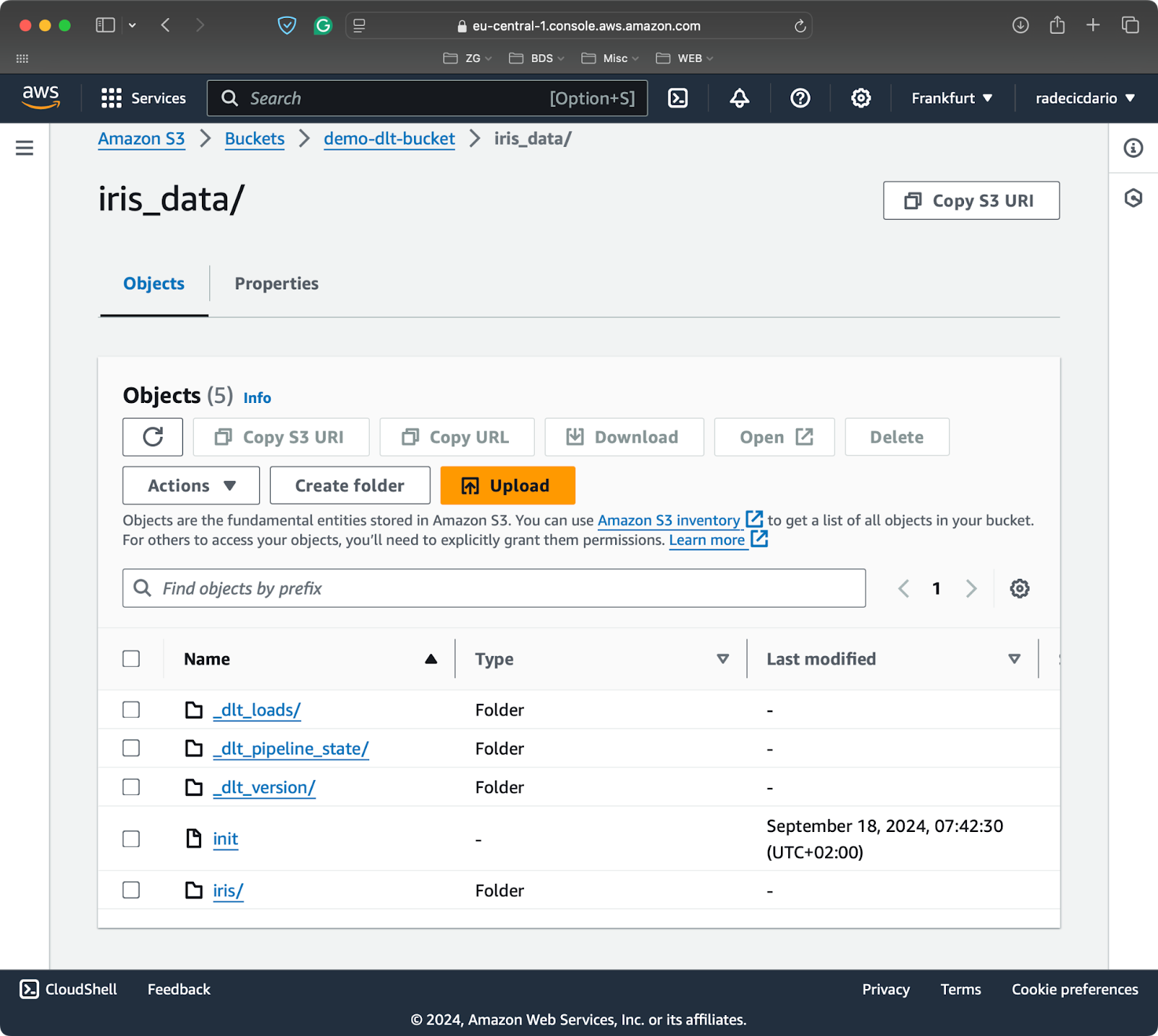
Conteúdo do bucket S3
Agora você conhece os conceitos básicos de movimentação de dados e sua transformação ao longo do caminho. Mas o que acontece quando você executa o pipeline várias vezes? É sobre isso que falarei a seguir.
Você quase nunca executará o pipeline apenas uma vez. É mais comum você programar execuções de pipeline, por exemplo, para serem executadas uma vez por dia ou uma vez por semana.
Se esse for o caso, você provavelmente desejará ter mais controle sobre como os novos dados são inseridos e como os dados existentes são atualizados.
Sempre que você executar o pipeline, novos dados serão anexados à tabela de sua escolha.
Vou demonstrar isso escrevendo um pipeline simples que insere um DataFrame do pandas fictício em uma tabela do DuckDB:
import dlt
import pandas as pd
@dlt.resource(primary_key="index")
def data():
data = pd.DataFrame({
"index": [1, 2, 3, 4, 5],
"a": [10, 15, 20, 25, 30],
"b": [22.5, 30.5, 35.5, 50.5, 10.5],
"c": ["row 1", "row 2", "row 3", "row 4", "row 5"]
})
yield data
def load_local_data() -> None:
pipeline = dlt.pipeline(
pipeline_name="pipeline_incremental_load",
destination="duckdb",
dataset_name="data"
)
load_info = pipeline.run(data=data(), table_name="dataset")
print(load_info)
if __name__ == "__main__":
load_local_data()Ao executar o pipeline uma vez, você inserirá cinco linhas de dados:
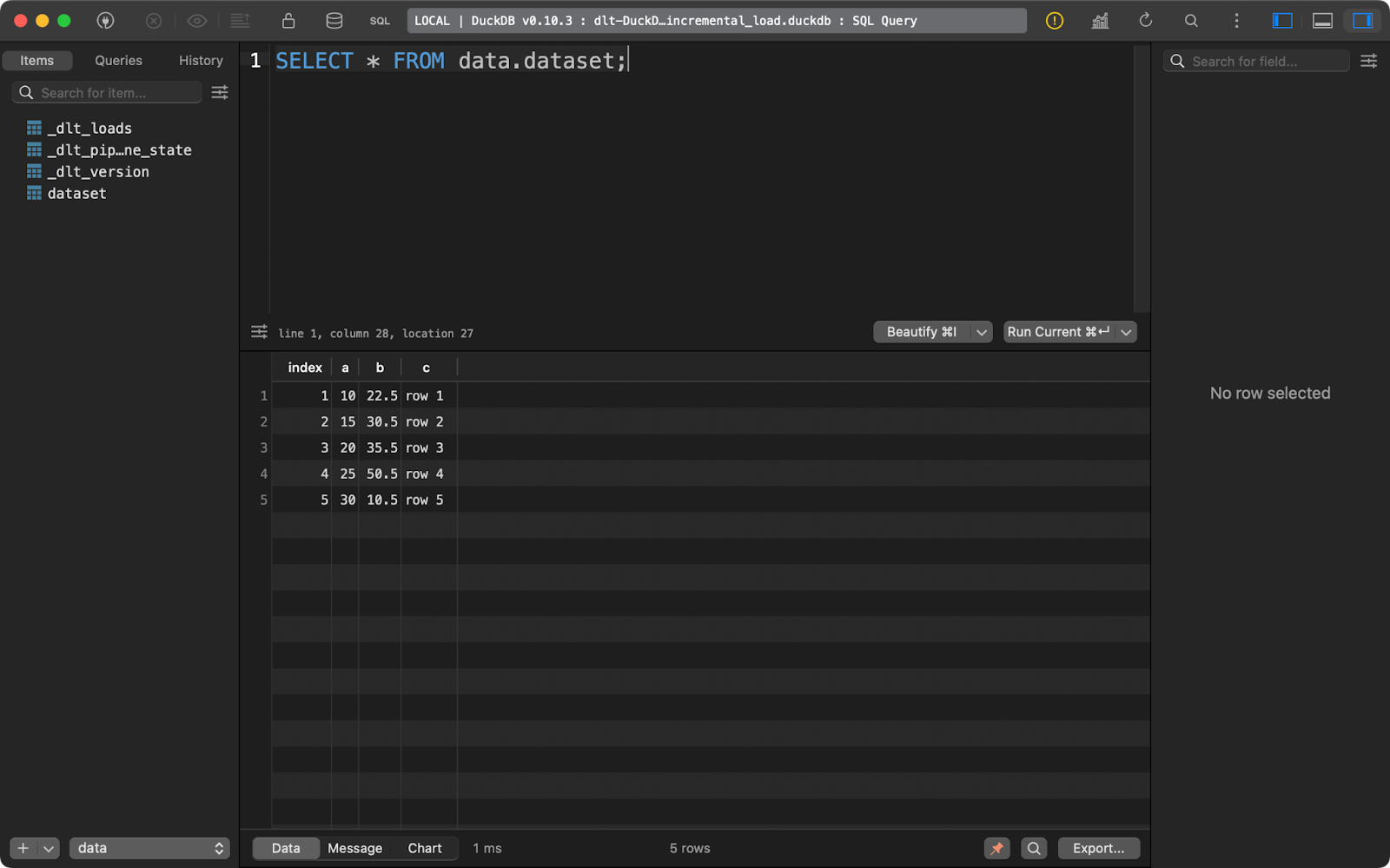
Primeira execução de anexação
E executá-lo novamente insere as mesmas cinco linhas:
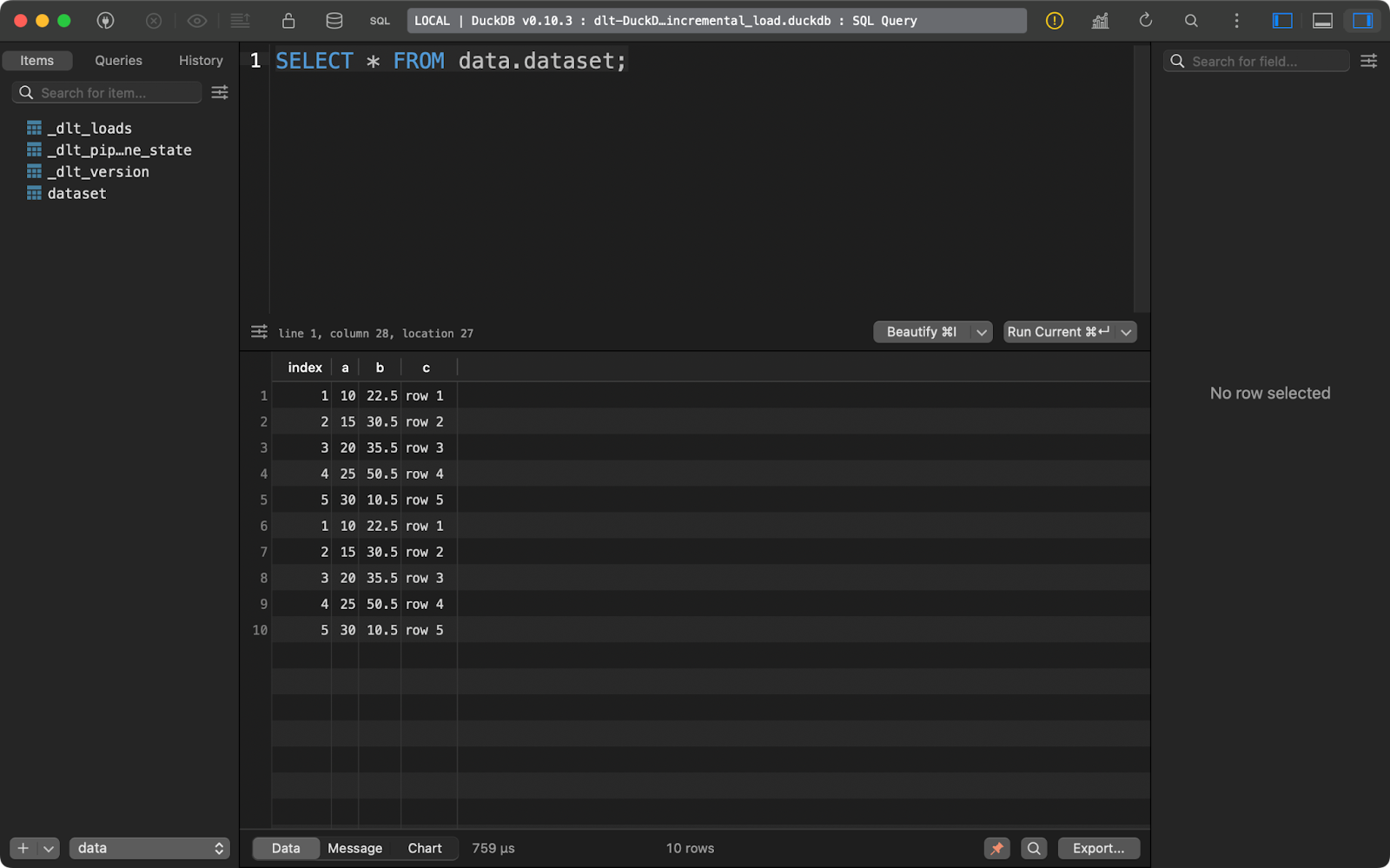
Segunda execução de anexação
Com esse tipo de dados, é fácil concluir uma coisa: ele é duplicado. Deixe-me mostrar o que você pode fazer a respeito.
Se você quiser excluir os registros existentes e substituí-los por novos, adicione write_disposition=”replace” a pipeline.run():
load_info = pipeline.run(data=data(), table_name="dataset", write_disposition="replace")Depois de fazer isso, executei o pipeline quatro vezes, como você pode ver na tabela de metadados _dlt_loads:
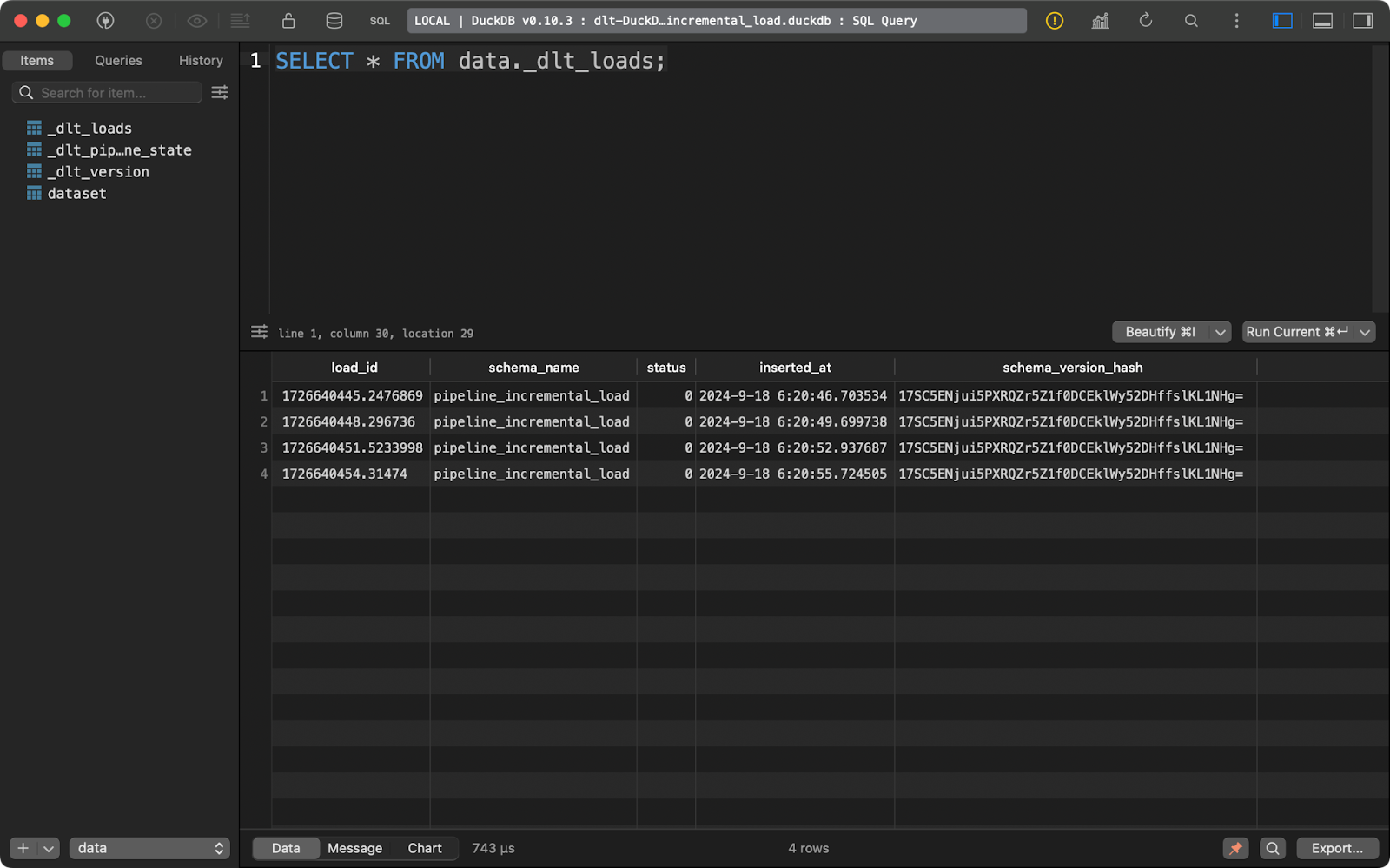
Executar o pipeline várias vezes
E a tabela dataset contém apenas 5 registros:
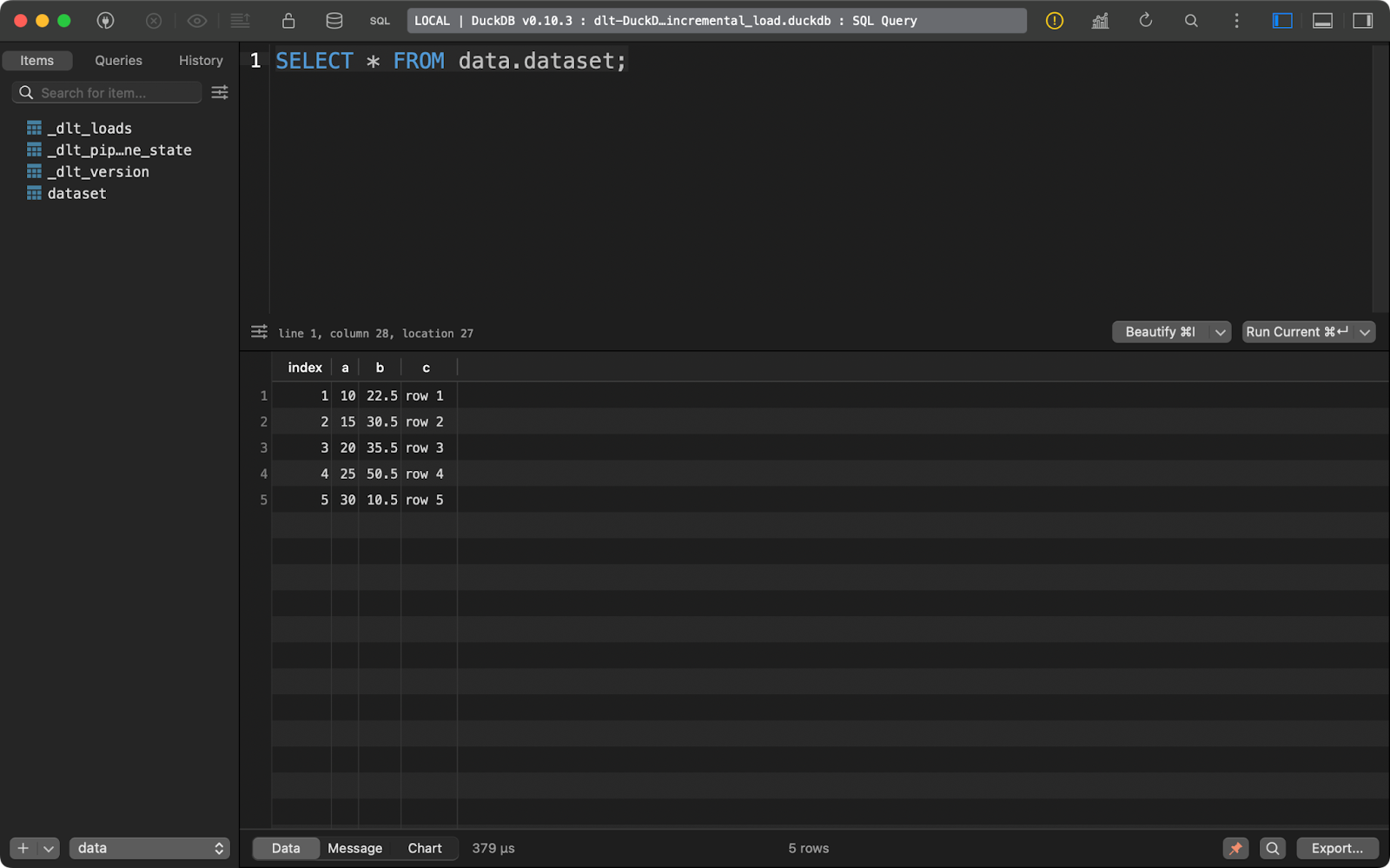
dataset conteúdo da tabela
Em resumo, essa abordagem sempre substituirá os dados existentes.
Mas e se você tiver uma combinação de dados novos e atualizados? É aí que entra a operação upsert. Ele é implementado por meio da disposição de gravação merge em dlt.
Para referência, executei o pipeline mais uma vez com os dados da seção anterior para garantir que haja 5 linhas presentes.
Em seguida, atualizei os dados para adicionar mais uma linha e alterar os valores de alguns registros com os valores existentes em index.
O pacote dlt examinará a coluna primary_key que você especificou e a comparará com os dados presentes no sistema de destino. Os registros com a coluna de chave primária existente serão atualizados e os novos serão inseridos:
import dlt
import pandas as pd
@dlt.resource(primary_key="index")
def data():
data = pd.DataFrame({
"index": [1, 2, 3, 4, 5, 6],
"a": [10, 15, 200000, 25, -3000, 50],
"b": [22.5, 30.5, 3555555.5, 50.5, -100.5, 15.5],
"c": ["row 1", "row 2", "row 3 updated", "row 4", "row 5 updated", "row 6 new"]
})
yield data
def load_local_data() -> None:
pipeline = dlt.pipeline(
pipeline_name="pipeline_incremental_load",
destination="duckdb",
dataset_name="data"
)
load_info = pipeline.run(data=data(), table_name="dataset", write_disposition="merge")
print(load_info)
if __name__ == "__main__":
load_local_data()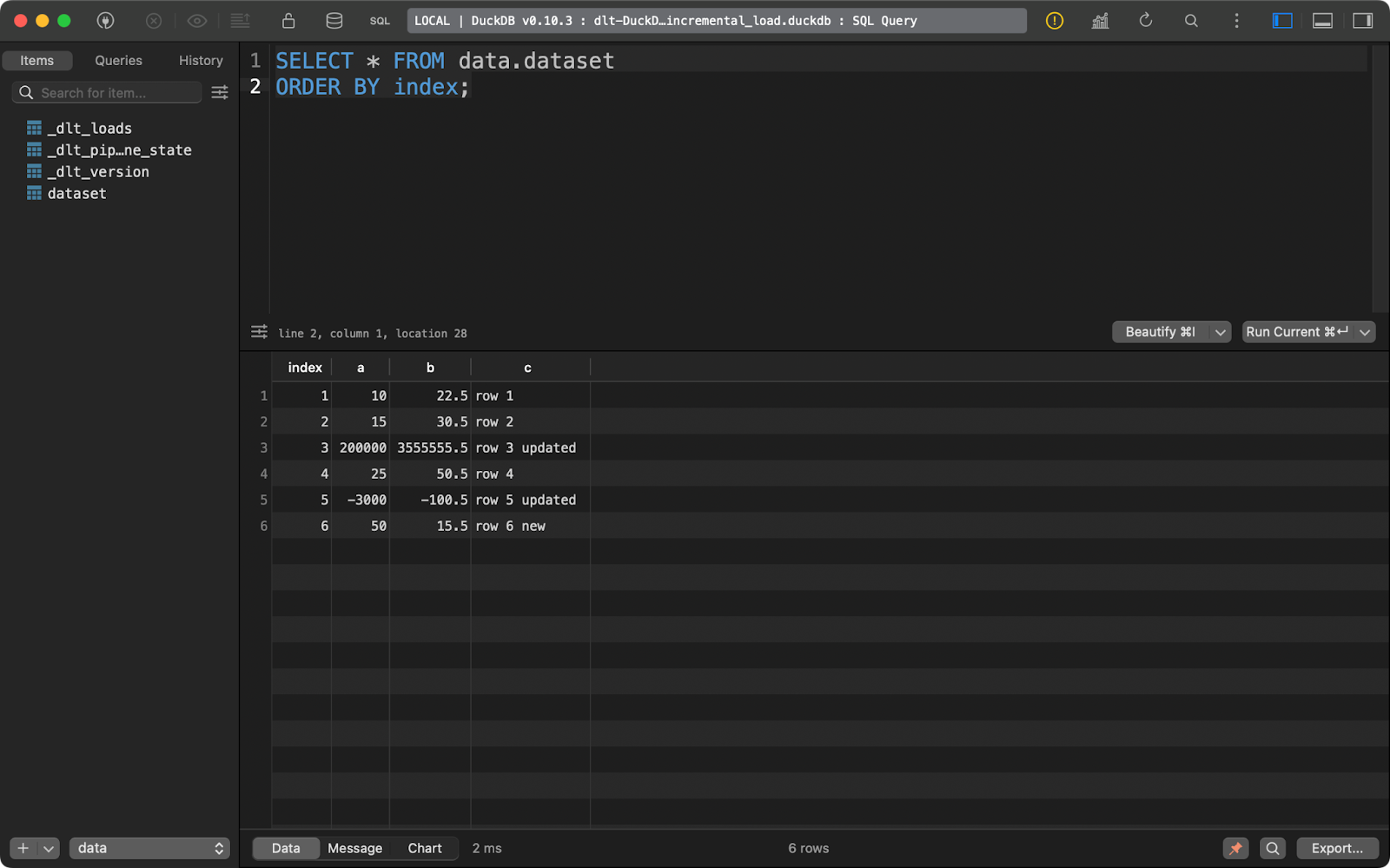
Conjunto de dados após a operação de upsert
Em resumo, você acaba com uma nova linha e duas atualizadas.
Esse é provavelmente o comportamento que você deseja para a maioria dos pipelines, especialmente quando deseja evitar a duplicação de dados.
Para concluir, a engenharia de dados é mais do que você imagina. A movimentação de dados é apenas uma parte. No entanto, é uma parte vital e a maioria dos outros aspectos da engenharia de dados gira em torno dela.
Se você já está familiarizado com Python, provavelmente não está procurando aprender do zero uma ferramenta GUI para movimentação de dados ou migrar para uma linguagem totalmente nova. Você quer se ater a um ambiente familiar. A biblioteca dlt do Python é tudo o que você e sua equipe precisam para modernizar os sistemas legados e reduzir os custos de nuvem. Ele foi experimentado e testado por muitos grandes players, como Hugging Face, Taktile, Untitled Data Company e Harness, portanto, acredito que ele também atenderá às suas necessidades.
Dito isso, o dlt provavelmente não é a única ferramenta de que você precisa para implementar pipelines de dados eficientes. Você desejará aprender ferramentas de dados adicionais, como o dbt, para levar o processamento de dados ao próximo nível.
Se você deseja iniciar uma carreira como engenheiro de dados, nosso curso de três módulos é a maneira perfeita de começar.
Nossos programas de certificação ajudam você a se destacar e a provar que suas habilidades estão prontas para o trabalho para possíveis empregadores.

Saiba mais sobre engenharia de dados com estes cursos!
Programa
Curso
Curso
blog
Kurtis Pykes
7 min
Tutorial
Joleen Bothma
Tutorial
Nadia mhadhbi
Tutorial
Abid Ali Awan
Tutorial
Natassha Selvaraj
