
programa
Desarrollo de aplicaciones de IA
21 h
La serie Qwen 2.5 Coder (antes conocida como CodeQwen1.5), desarrollada por el equipo de investigación Qwen de Alibaba, se dedica a hacer avanzar los Open CodeLLM. La serie incluye modelos como el Qwen 2.5-32B-Instruct, que se ha convertido en el modelo de código abierto más avanzado, rivalizando con las capacidades de codificación de gigantes propietarios como GPT-4o y Gemini.
Estos modelos se presentan como
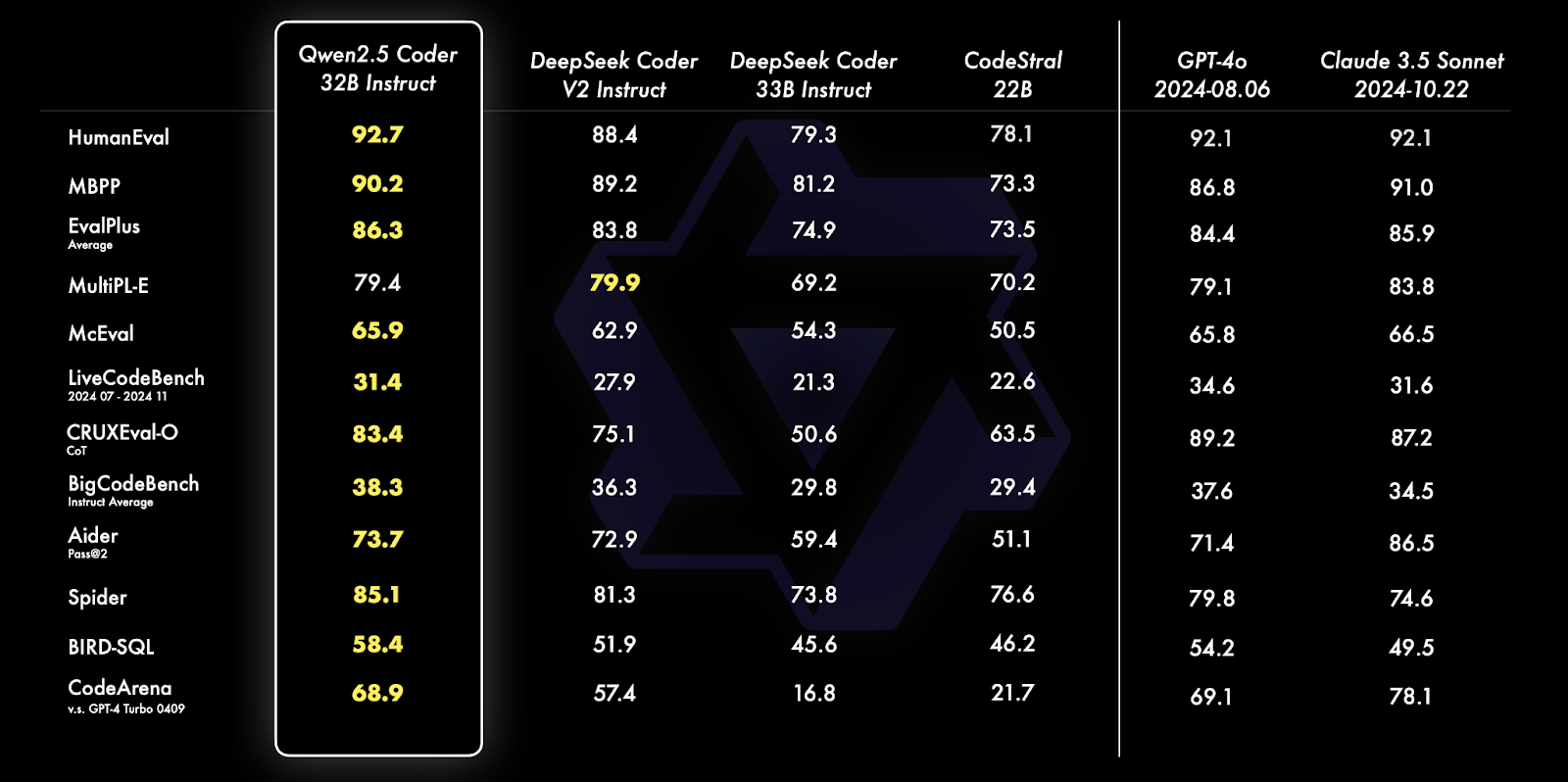
Fuente: Blog oficial de Qwen
Qwen 2.5 Coder 32B Instruct supera a sus homólogos en múltiples pruebas comparativas, como HumanEval, MBPP y Spider, demostrando unas capacidades excepcionales de codificación y resolución de problemas. Sobresale en diversas tareas como la generación de consultas SQL, la evaluación de código y los retos de programación del mundo real, superando a modelos como GPT-4o y Claude 3.5 Sonnet.
Para saber más sobre las capacidades y comparaciones de estos modelos, lee el artículo de anuncio de la serie de codificadores Qwen2.5 artículo de anuncio.
En esta sección, nos sumergiremos en la implementación del código de nuestro asistente de revisión de código utilizando Gradio.
Empezaremos por establecer los requisitos previos necesarios, seguidos de la inicialización del modelo con configuraciones optimizadas.
A continuación, definiremos las funcionalidades básicas, utilizando las capacidades de instrucción del modelo y, por último, integraremos estos componentes en una interfaz de Gradio fácil de usar, que permita una interacción sencilla con el asistente.
Antes de sumergirnos en la implementación, asegurémonos de que tenemos instaladas las siguientes herramientas y bibliotecas:
Ejecuta los siguientes comandos para instalar las dependencias necesarias:
!pip install torch transformers gradio bitsandbytes -qUna vez instaladas las dependencias anteriores, ejecuta los siguientes comandos de importación:
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
import torch
Import gradio as grNota: Ejecutar el modelo Qwen2.5-Coder-32B-Instruct en Google Colab requiere una GPU A100 con mucha RAM. Si los recursos son limitados, considera la posibilidad de utilizar modelos con parámetros más bajos, como 0,5B, 3B, 7B o 14B.
La biblioteca Transformadores de Cara Abrazada simplifica la carga de modelos grandes. Comenzamos inicializando la Qwen2.5-Codificador-32B-Instructor de HuggingFace con cuantificación para mejorar el rendimiento:
# Define quantization configuration for optimized performance
bnb_config = BitsAndBytesConfig(load_in_8bit=True)
# Load the model and tokenizer
model_name = "Qwen/Qwen2.5-Coder-32B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto",
quantization_config=bnb_config
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
if tokenizer.pad_token_id is None:
tokenizer.pad_token_id = tokenizer.eos_token_idEl fragmento de código anterior nos permite cargar el modelo Qwen2.5-Coder-32B-Instruct con una cuantización de 8 bits, reduciendo el uso de memoria para una ejecución eficiente en dispositivos con recursos limitados.
Utiliza BitsAndBytesConfig para activar la cuantización, torch.float16 para el cálculo optimizado en las GPU compatibles y device_map="auto" para la asignación automática de hardware. El tokenizador de la biblioteca transformers de HuggingFace garantiza un procesamiento sencillo del texto, asignando un pad_token_id si no está ya configurado. Esta configuración facilita la ejecución eficiente de grandes modelos en hardware de consumo.
Una vez cargado el modelo junto con el tokenizador, configuramos una función para generar una respuesta a partir del modelo utilizando el método apply_chat_template.
def generate_response(messages):
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=200,
temperature=0.7,
repetition_penalty=1.2
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
return responseLa función anterior sirve como utilidad para interactuar con el modelo Qwen2.5-Coder-32B-Instruct para generar respuestas conscientes del contexto. Toma una lista de mensajes tipo chat (con roles como "sistema" y "usuario") como entrada y realiza los siguientes pasos:
apply_chat_template, preparándolos para la comprensión basada en el chat del modelo.max_new_tokens=200; Este parámetro limita la longitud de la respuesta a 200 tokens.temperature=0.7Esto ayuda a controlar la aleatoriedad de la respuesta, equilibrando así la creatividad y la coherencia.repetition_penalty=1.2; Este parámetro desalienta las frases repetitivas en la salida.4. Post-procesamiento: Este paso elimina la solicitud de entrada de la salida generada cortando y descodificando la respuesta en una cadena legible por humanos mediante la función batch_decode. La función abstrae la complejidad de preparar, generar y descodificar respuestas, lo que la hace reutilizable para diversas tareas, como la depuración, el análisis de código y la generación de información procesable.
A continuación, configuramos el código de las funciones principales de nuestra aplicación, es decir, el analizador de código, el mejorador de código y el comprobador de normas de codificación. Como estamos utilizando un modelo de instrucción, podemos utilizar roles como "sistema" y "usuario" y pasarlos al modelo dentro de la instrucción para generar una respuesta.
Estas son las tres funciones principales de nuestra aplicación: detector de problemas, experto en calidad del código y experto en normas de codificación.
Este asistente identifica errores de sintaxis, fallos lógicos y vulnerabilidades potenciales en el código proporcionado. Las instrucciones específicas para el modelo son
def analyze_code_issues(code):
messages = [
{"role": "system", "content": "You are Qwen, a helpful coding assistant. Your job is to analyze and debug code."},
{"role": "user", "content": f"""Review this code:
{code}
List all syntax errors, logical bugs, and potential runtime issues. Format as:
- Error/Bug: [description]
- Impact: [potential consequences]
- Fix: [suggested solution]"""}
]
return generate_response(messages)El código anterior consta de mensajes que contienen funciones y contenido, junto con una indicación inicial para que el modelo actúe como un útil asistente de codificación. Este mensaje se pasa a la función generate_response para que devuelva una respuesta adecuada.
Este asistente ayuda a mejorar la legibilidad, la eficacia y el mantenimiento del código, generando sugerencias sobre optimizaciones y calidad del código.
def suggest_code_improvements(code):
messages = [
{"role": "system", "content": "You are Qwen, an expert in code optimization. Help improve code quality."},
{"role": "user", "content": f"""Review this code:
{code}
Provide specific optimization suggestions:
1. Performance improvements
2. Better variable names
3. Simpler logic
4. Memory efficiency
Include code examples where relevant."""}
]
return generate_response(messages)Este asistente comprueba si el código proporcionado sigue las normas de codificación ideales y proporciona sugerencias en consecuencia.
messages = [
{"role": "system", "content": "You are Qwen, a coding standards expert. Your task is to evaluate code adherence to best practices."},
{"role": "user", "content": f"""Evaluate this code:
{code}
Check against these standards:
1. PEP 8 compliance
2. Function/variable naming
3. Documentation completeness
4. Error handling
5. Code organization
List violations with specific examples and corrections."""}
]
return generate_response(messages)La función anterior permite que el modelo actúe como un experto en normas de codificación, evaluando el código proporcionado para comprobar si se ajusta a directrices como el cumplimiento de PEP 8, la denominación adecuada de las funciones, el tratamiento robusto de los errores, etc.
Gradio simplifica el despliegue del asistente, permitiendo a los usuarios introducir código y ver los resultados de forma interactiva. Las respuestas del modelo de las secciones anteriores se integran perfectamente en una interfaz de Gradio.
def review_code(code):
issues = analyze_code_issues(code)
improvements = suggest_code_improvements(code)
standards = check_coding_standards(code)
return issues, improvements, standards
interface = gr.Interface(
fn=review_code,
inputs="textbox",
outputs=["text", "text", "text"],
title="AI Code Review Assistant",
description="Analyze code for issues, suggest improvements, and check adherence to coding standards."
)
interface.launch(debug=True)La función review_code integra tres componentes: analyze_code_issues, suggest_code_improvements, y check_coding_standards. Estas funciones identifican errores de sintaxis, fallos, optimizaciones y cumplimiento de las normas de codificación. La interfaz de Gradio toma la entrada del usuario a través de un cuadro de texto y muestra los resultados en tres campos de texto. Proporciona una interfaz web fácil de usar para que los desarrolladores analicen y mejoren su código. Una vez que ejecutemos esta última celda, obtendremos una interfaz de aplicación Gradio en ejecución como la que se muestra a continuación.
La interfaz AI del asistente de revisión de código construida con Gradio
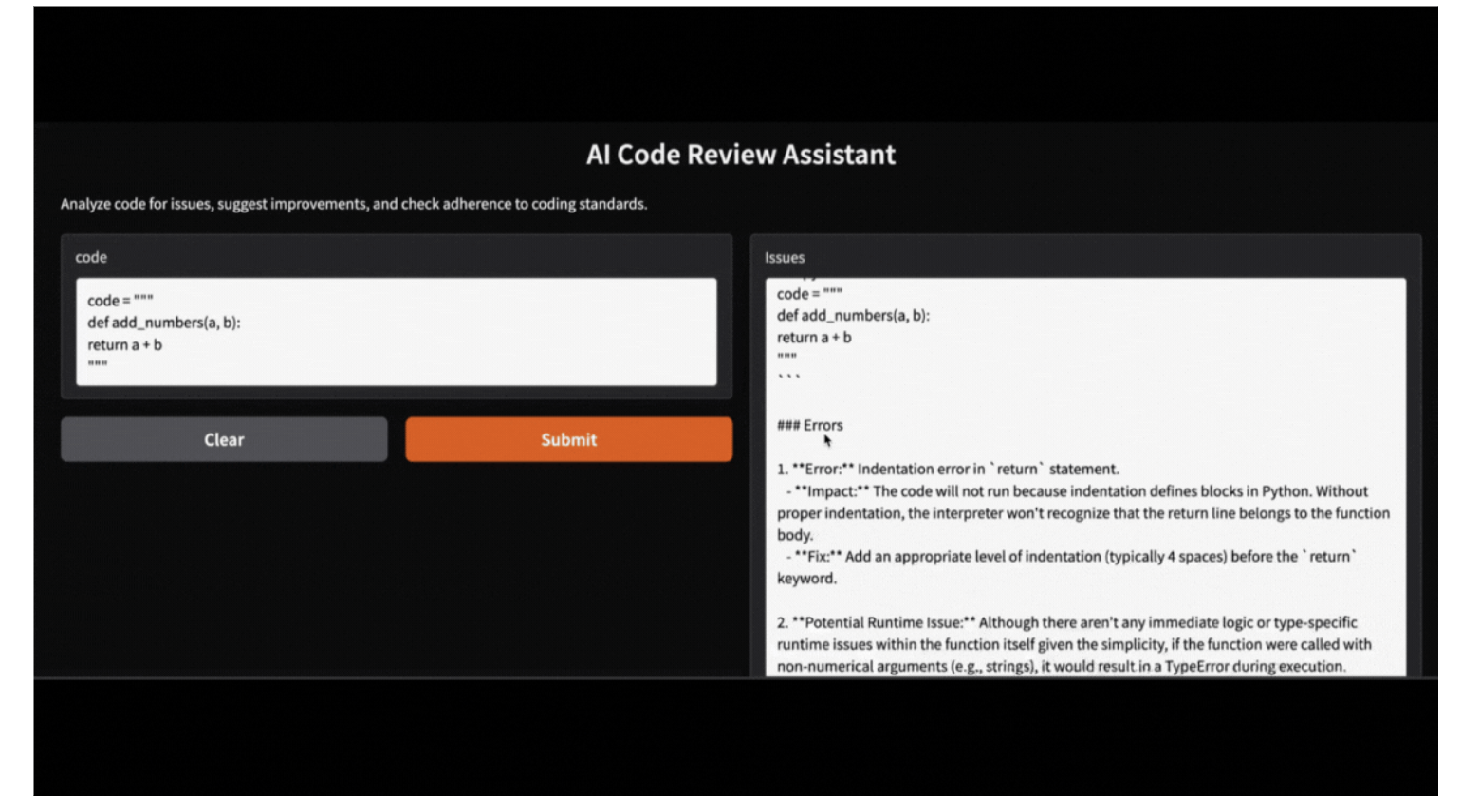
En caso de que un usuario no quiera ejecutar una aplicación Gradio, puede probar el asistente ejecutando el siguiente código. He aquí un ejemplo de cómo el asistente analiza una función Python con errores:
code = """
def add_numbers(a, b):
return a + b
"""
issues, suggestions, standards = review_code(code)
print("Issues:", issues)
print("Suggestions:", suggestions)
print("Adherence to coding standards:", standards)Issues:
Here's the review of your provided Python code:
```python
.
.
- **Fix:** Implement input validation or use exception handling to manage unexpected data types gracefully.
Suggestions:
Certainly! Let's review the provided function and suggest optimizations based on your criteria:
1. **Proper Indentation**
.
.
2. **Better Variable Names**
In this simple case, `a` and `b` could be considered generic enough as they represent arbitrary operands. However, more descriptive names can help when functions become complex.
Adherence to coding standards:
Certainly! Let's go through the provided Python function `add_numbers` according to the specified standards.
.
.
2. **Function/Variable Naming**
- The names `add_numbers`, `a`, and `b` follow good conventions for simplicity and clarity in their context (function name clearly indicates addition; variable names indicate they're operands). However, if you want more descriptive variable names (especially useful in larger functions), consider using something like `operand_one` or `num1`.
Esta aplicación Gradio también puede ejecutarse localmente con el código proporcionado, utilizando el modelo Qwen-2.5 accesible a través de Ollama. Sólo tienes que sustituir el modelo de biblioteca HF por el modelo de biblioteca local Ollama, y tu aplicación estará funcionando sin problemas.
En este artículo, aprendimos a utilizar Qwen 2.5-Coder-32B-Instruct en combinación con Gradio para construir un asistente de revisión de código de IA. Esta herramienta analiza el código en busca de errores de sintaxis, sugiere optimizaciones y aplica normas de codificación, agilizando el proceso de desarrollo de software.
Ahora que ya sabes cómo configurar Qwen 2.5, ¡te animo a que construyas tu propio proyecto!
Aprende IA con estos cursos
programa
Curso
Curso
blog
Abid Ali Awan
10 min
Tutorial
Dimitri Didmanidze
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Kurtis Pykes


