Curso
Introducción al aprendizaje profundo con PyTorch
4 h
85.7K
A medida que la tecnología del aprendizaje automático avanza a un ritmo sin precedentes, los Autocodificadores Variacionales (VAE) están revolucionando nuestra forma de procesar y generar datos. Al fusionar una potente codificación de datos con innovadoras capacidades generativas, las VAE ofrecen soluciones transformadoras a complejos retos sobre el terreno.
En este artículo, exploraremos paso a paso los conceptos básicos de las VAE, sus aplicaciones y cómo pueden implementarse eficazmente utilizando PyTorch.
Los autocodificadores son un tipo de red neuronal diseñada para aprender representaciones eficientes de los datos, principalmente con fines de reducción de la dimensionalidad o aprendizaje de características.
Los autocodificadores constan de dos partes principales:
El objetivo principal de los autocodificadores es minimizar la diferencia entre la entrada y la salida reconstruida, aprendiendo así una representación compacta de los datos.
Aparecen los Autocodificadores Variacionales (VAE), que amplían las capacidades del marco tradicional de los autocodificadores incorporando elementos probabilísticos al proceso de codificación.
Mientras que los autocodificadores estándar asignan entradas a representaciones latentes fijas, los VAE introducen un enfoque probabilístico en el que el codificador emite una distribución sobre el espacio latente, típicamente modelada como una gaussiana multivariante. Esto permite a las VAE tomar muestras de esta distribución durante el proceso de descodificación, lo que conduce a la generación de nuevas instancias de datos.
La innovación clave de las VAE reside en su capacidad para generar nuevos datos de alta calidad mediante el aprendizaje de un espacio latente estructurado y continuo. Esto es especialmente importante para el modelado generativo, donde el objetivo no es sólo comprimir datos, sino crear nuevas muestras de datos que se parezcan al conjunto de datos original.
Las VAE han demostrado una eficacia significativa en tareas como la síntesis de imágenes, la eliminación de ruido de los datos y la detección de anomalías, lo que las convierte en herramientas relevantes para hacer avanzar las capacidades de los modelos y aplicaciones de aprendizaje automático.
En esta sección, presentaremos los fundamentos teóricos y la mecánica operativa de las VAE, proporcionándote una base sólida para explorar sus aplicaciones en secciones posteriores.
Empecemos por los codificadores. El codificador es una red neuronal encargada de asignar los datos de entrada a un espacio latente. A diferencia de los autocodificadores tradicionales, que producen un punto fijo en el espacio latente, el codificador de una VAE produce los parámetros de una distribución de probabilidad, normalmente la media y la varianza de una distribución gaussiana. Esto permite a la VAE modelizar eficazmente la incertidumbre y la variabilidad de los datos.
Otra red neuronal llamada decodificador se utiliza para reconstruir los datos originales a partir de la representación del espacio latente. Dada una muestra de la distribución del espacio latente, el descodificador pretende generar una salida que se parezca mucho a los datos de entrada originales. Este proceso permite a la VAE crear nuevas instancias de datos tomando muestras de la distribución aprendida.
El espacio latente es un espacio continuo de dimensiones inferiores en el que se codifican los datos de entrada.
Visualización del papel del codificador, el descodificador y el espacio latente. Fuente de la imagen.
El enfoque variacional es una técnica utilizada para aproximar distribuciones de probabilidad complejas. En el contexto de las VAE, implica aproximar la verdadera distribución posterior de las variables latentes dados los datos, lo que suele ser intratable.
La VAE aprende una distribución posterior aproximada. El objetivo es que esta aproximación sea lo más cercana posible a la verdadera posterior.
La inferencia bayesiana es un método de actualización de la estimación de la probabilidad de una hipótesis a medida que se dispone de más pruebas o información. En las VAE, se utiliza la inferencia bayesiana para estimar la distribución de las variables latentes.
Al integrar el conocimiento previo (distribución previa) con los datos observados (verosimilitud), las VAE ajustan la representación del espacio latente mediante la distribución posterior aprendida.
Inferencia bayesiana con una distribución a priori, una distribución a posteriori y una función de verosimilitud. Fuente de la imagen.
Así es como se ve el flujo del proceso:
Examinemos las diferencias y ventajas de los VAE sobre los autocodificadores tradicionales.
Como hemos visto antes, los autocodificadores tradicionales consisten en una red codificadora que mapea los datos de entrada x a una representación fija de espacio latente de dimensión inferior z. Este proceso es determinista, lo que significa que cada entrada se codifica en un punto concreto del espacio latente.
A continuación, la red decodificadora reconstruye los datos originales a partir de esta representación latente fija, con el objetivo de minimizar la diferencia entre la entrada y su reconstrucción.
El espacio latente de los autocodificadores tradicionales es una representación comprimida de los datos de entrada sin ningún modelado probabilístico, lo que limita su capacidad para generar datos nuevos y diversos, ya que carecen de un mecanismo para manejar la incertidumbre.
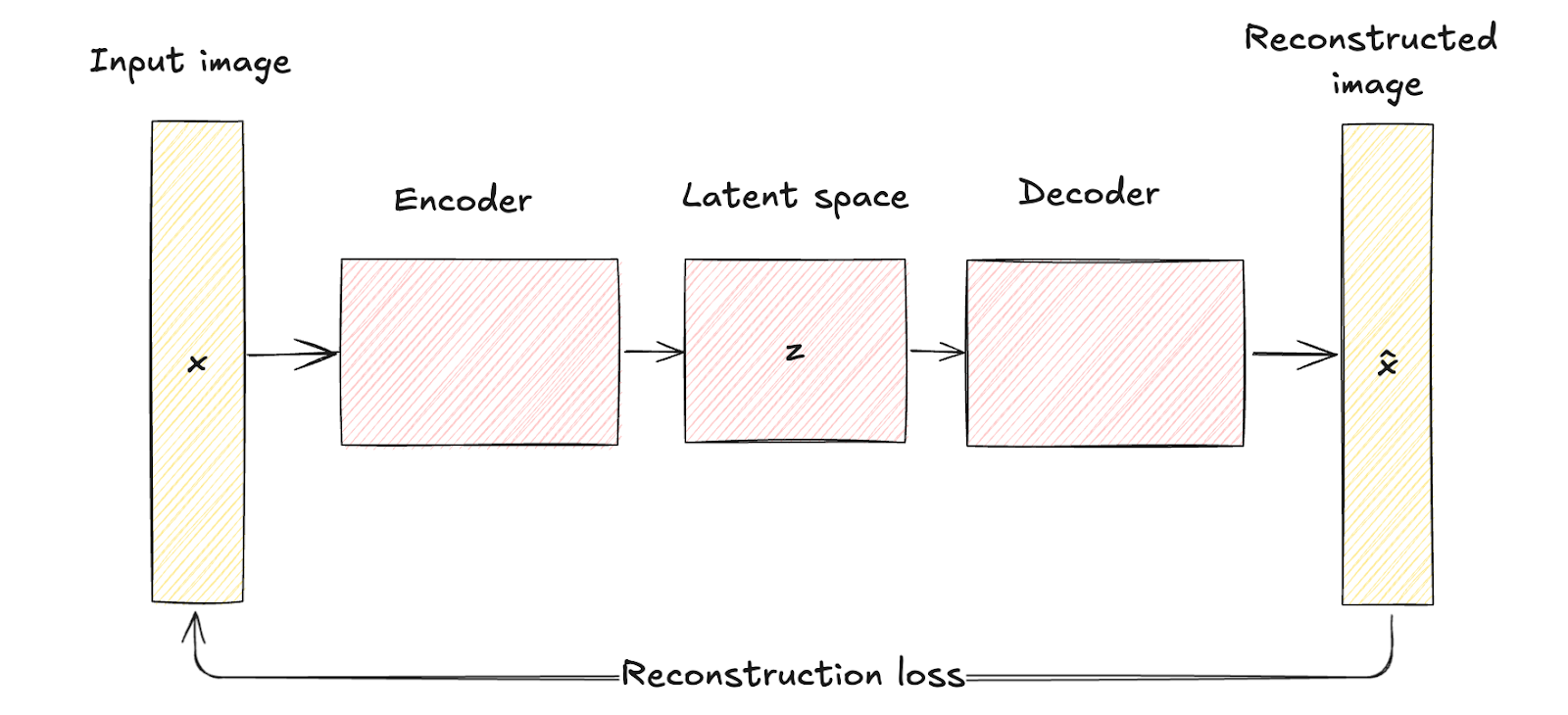
Arquitectura del autocodificador. Imagen del autor
Las VAE introducen un elemento probabilístico en el proceso de codificación. Es decir, el codificador de una VAE asigna los datos de entrada a una distribución de probabilidad sobre las variables latentes, modelada típicamente como una distribución gaussiana con media μ y varianza σ2.
Este enfoque codifica cada entrada en una distribución en lugar de en un único punto, lo que añade una capa de variabilidad e incertidumbre.
Las diferencias arquitectónicas se representan visualmente por el mapeo determinista de los autocodificadores tradicionales frente a la codificación probabilística y el muestreo de los VAE.
Esta diferencia estructural pone de relieve cómo las VAE incorporan la regularización mediante un término conocido como divergencia KL, dando forma al espacio latente para que sea continuo y bien estructurado.
La regularización introducida mejora significativamente la calidad y la coherencia de las muestras generadas, superando las capacidades de los autocodificadores tradicionales.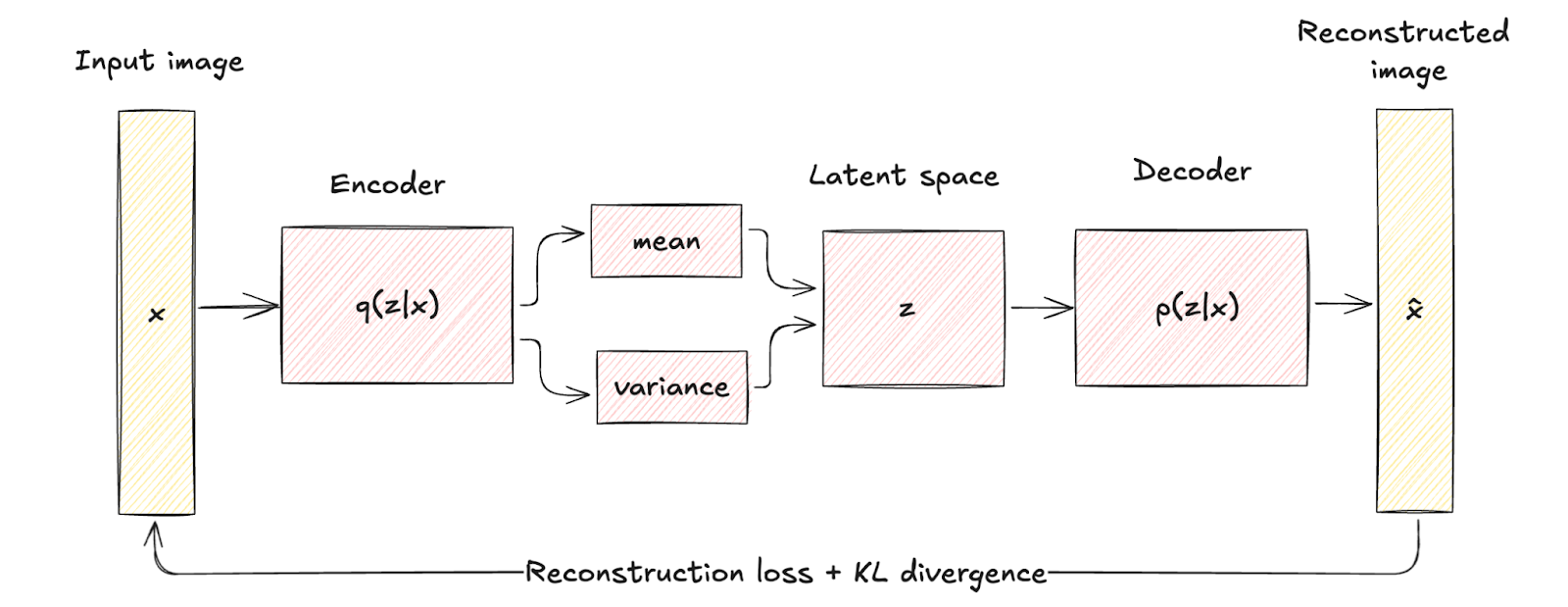
Arquitectura del autoencoder variacional. Imagen del autor
La naturaleza probabilística de los VAE amplía significativamente su campo de aplicaciones en comparación con el de los autocodificadores tradicionales. En cambio, los autocodificadores tradicionales son muy eficaces en aplicaciones en las que basta con una representación determinista de los datos.
Veamos algunas aplicaciones de cada uno de ellos para entender mejor este punto.
Las VAE han evolucionado hacia diversas formas especializadas para abordar diferentes retos y aplicaciones en el aprendizaje automático. En esta sección, examinaremos los tipos más destacados, resaltando casos de uso, ventajas y limitaciones.
Los Autocodificadores Variacionales Condicionales (VAE) son una forma especializada de VAE que mejoran el proceso generativo condicionándolo a información adicional.
Una VAE se convierte en condicional al incorporar información adicional, denotada como c, tanto en la red del codificador como en la del descodificador. Esta información condicionante puede ser cualquier dato relevante, como etiquetas de clase, atributos u otros datos contextuales.
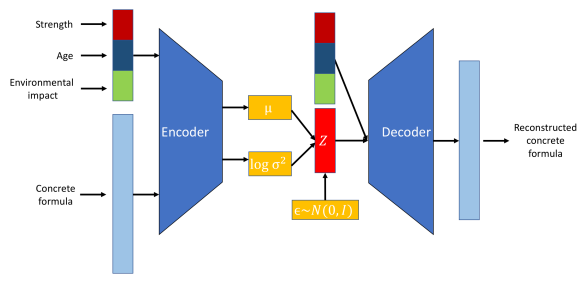
Estructura del modelo CVAE. Fuente de la imagen.
Los casos de uso de los CVAE incluyen
Los pros y los contras son:
Los Autocodificadores Variacionales Desenmarañados, a menudo llamados Beta-VAE, son otro tipo de VAE especializados. Su objetivo es aprender representaciones latentes en las que cada dimensión capte un factor de variación distinto e interpretable de los datos. Esto se consigue modificando el objetivo VAE original con un hiperparámetro β que equilibra la pérdida de reconstrucción y el término de divergencia KL.
Pros y contras de los Beta-VAE:
Otra variante de los VAE son los autocodificadores adversariales (AAEs). Los AAE combinan el marco VAE con los principios de entrenamiento adversarial de las Redes Adversariales Generativas (GAN). Una red discriminante adicional garantiza que las representaciones latentes coincidan con una distribución a priori, mejorando la capacidad generativa del modelo.
Pros y contras de los AAE:
Ahora veremos otras dos extensiones de los Autocodificadores Variacionales.
El primero son los Autocodificadores Recurrentes Variacionales (VRAE). Los VRAE amplían el marco VAE a los datos secuenciales incorporando redes neuronales recurrentes (RNN) en las redes codificadoras y decodificadoras. Esto permite a los VRAE captar las dependencias temporales y modelar patrones secuenciales.
Pros y contras de las VRAE:
La última variante que examinaremos es Autocodificadores (HVAE). Los HVAE introducen múltiples capas de variables latentes dispuestas en una estructura jerárquica, lo que permite al modelo captar dependencias y abstracciones más complejas en los datos.
Pros y contras de los EAVH:
En esta sección, implementaremos un sencillo Autoencoder Variacional (VAE) utilizando PyTorch.
Para poner en marcha una VAE, necesitamos configurar nuestro entorno Python con las bibliotecas y herramientas necesarias. Las bibliotecas que utilizaremos son
Aquí tienes el código para instalar estas bibliotecas:
pip install torch torchvision matplotlib numpyRecorramos paso a paso la puesta en marcha de una VAE. En primer lugar, debemos importar las bibliotecas:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as npA continuación, debemos definir el codificador, el descodificador y la VAE. Aquí tienes el código:
class Encoder(nn.Module):
def __init__(self, input_dim, hidden_dim, latent_dim):
super(Encoder, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc_mu = nn.Linear(hidden_dim, latent_dim)
self.fc_logvar = nn.Linear(hidden_dim, latent_dim)
def forward(self, x):
h = torch.relu(self.fc1(x))
mu = self.fc_mu(h)
logvar = self.fc_logvar(h)
return mu, logvar
class Decoder(nn.Module):
def __init__(self, latent_dim, hidden_dim, output_dim):
super(Decoder, self).__init__()
self.fc1 = nn.Linear(latent_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, z):
h = torch.relu(self.fc1(z))
x_hat = torch.sigmoid(self.fc2(h))
return x_hat
class VAE(nn.Module):
def __init__(self, input_dim, hidden_dim, latent_dim):
super(VAE, self).__init__()
self.encoder = Encoder(input_dim, hidden_dim, latent_dim)
self.decoder = Decoder(latent_dim, hidden_dim, input_dim)
def forward(self, x):
mu, logvar = self.encoder(x)
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
z = mu + eps * std
x_hat = self.decoder(z)
return x_hat, mu, logvarTambién tenemos que definir la función de pérdida. La función de pérdida de las VAE consiste en una pérdida de reconstrucción y una pérdida de divergencia KL. Así es como se ve en PyTorch:
def loss_function(x, x_hat, mu, logvar):
BCE = nn.functional.binary_cross_entropy(x_hat, x, reduction='sum')
KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
return BCE + KLDPara entrenar la VAE, cargaremos el conjunto de datos MNIST, definiremos el optimizador y entrenaremos el modelo.
# Hyperparameters
input_dim = 784
hidden_dim = 400
latent_dim = 20
lr = 1e-3
batch_size = 128
epochs = 10
# Data loader
transform = transforms.Compose([transforms.ToTensor(), transforms.Lambda(lambda x: x.view(-1))])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# Model, optimizer
vae = VAE(input_dim, hidden_dim, latent_dim)
optimizer = optim.Adam(vae.parameters(), lr=lr)
# Training loop
vae.train()
for epoch in range(epochs):
train_loss = 0
for x, _ in train_loader:
x = x.view(-1, input_dim)
optimizer.zero_grad()
x_hat, mu, logvar = vae(x)
loss = loss_function(x, x_hat, mu, logvar)
loss.backward()
train_loss += loss.item()
optimizer.step()
print(f"Epoch {epoch + 1}, Loss: {train_loss / len(train_loader.dataset)}")Tras el entrenamiento, podemos evaluar la VAE visualizando las salidas reconstruidas y las muestras generadas.
Este es el código:
# visualizing reconstructed outputs
vae.eval()
with torch.no_grad():
x, _ = next(iter(train_loader))
x = x.view(-1, input_dim)
x_hat, _, _ = vae(x)
x = x.view(-1, 28, 28)
x_hat = x_hat.view(-1, 28, 28)
fig, axs = plt.subplots(2, 10, figsize=(15, 3))
for i in range(10):
axs[0, i].imshow(x[i].cpu().numpy(), cmap='gray')
axs[1, i].imshow(x_hat[i].cpu().numpy(), cmap='gray')
axs[0, i].axis('off')
axs[1, i].axis('off')
plt.show()
#visualizing generated samples
with torch.no_grad():
z = torch.randn(10, latent_dim)
sample = vae.decoder(z)
sample = sample.view(-1, 28, 28)
fig, axs = plt.subplots(1, 10, figsize=(15, 3))
for i in range(10):
axs[i].imshow(sample[i].cpu().numpy(), cmap='gray')
axs[i].axis('off')
plt.show()
Visualización de los resultados. La fila superior son los datos MNIST originales, la fila central son los resultados reconstruidos, y la última fila son las muestras-imagen generadas por el autor.
Aunque los Autocodificadores Variacionales (VAE) son potentes herramientas para el modelado generativo, presentan varios retos y limitaciones que pueden afectar a su rendimiento. Analicemos algunas de ellas y ofrezcamos estrategias de mitigación.
Se trata de un fenómeno en el que la VAE no consigue captar toda la diversidad de la distribución de los datos. El resultado son muestras generadas que representan sólo unos pocos modos (regiones distintas) de la distribución de los datos, ignorando otros. Esto conduce a una falta de variedad en los resultados generados.
Colapso del modo causado por:
El colapso del modo puede mitigarse utilizando:
En algunos casos, el espacio latente aprendido por una VAE puede resultar poco informativo, cuando el modelo no utiliza eficazmente las variables latentes para captar características significativas de los datos de entrada. Esto puede dar lugar a una mala calidad de las muestras y reconstrucciones generadas.
Esto suele ocurrir por las siguientes razones:
Los espacios latentes poco informativos pueden arreglarse aprovechando la estrategia de calentamiento, que consiste en aumentar gradualmente el peso de la divergencia KL durante el entrenamiento o modificando directamente el peso del término de divergencia KL en la función de pérdida.
Las VAE de entrenamiento a veces pueden ser inestables, con la función de pérdida oscilando o divergiendo. Esto puede dificultar la convergencia y la obtención de un modelo bien entrenado.
Esto ocurre porque
Los pasos para mitigar la inestabilidad de la formación implican utilizar:
Entrenar VAEs, especialmente con conjuntos de datos grandes y complejos, puede ser costoso desde el punto de vista informático. Esto se debe a la necesidad de muestreo y retropropagación a través de capas estocásticas.
Las causas de los elevados costes computacionales incluyen:
Estas son algunas acciones de mitigación:
Los autocodificadores variacionales (VAE) han demostrado ser un avance revolucionario en el ámbito del aprendizaje automático y la generación de datos.
Al introducir elementos probabilísticos en el marco del autoencoder tradicional, los VAE permiten generar nuevos datos de alta calidad y proporcionan un espacio latente más estructurado y continuo. Esta capacidad única ha abierto un amplio abanico de aplicaciones, desde el modelado generativo y la detección de anomalías hasta la imputación de datos y el aprendizaje semisupervisado.
En este artículo, hemos cubierto los fundamentos de los Autocodificadores Variacionales, los diferentes tipos, cómo implementar VAEs en PyTorch, así como los retos y soluciones cuando se trabaja con VAEs.
Consulta estos recursos para continuar tu aprendizaje:
Aprende más sobre IA con estos cursos
Curso
Curso
Curso
blog
Abid Ali Awan
11 min
blog
Abid Ali Awan
10 min
blog
Arun Nanda
15 min
Tutorial
Arjun Sarkar
Tutorial
Bex Tuychiev
Tutorial
Moez Ali


