
Lernpfad
Entwicklung von KI-Anwendungen
21 Std.
Die Qwen 2.5 Coder-Serie (früher bekannt als CodeQwen1.5), die vom Qwen-Forschungsteam von Alibaba entwickelt wurde, widmet sich der Förderung von Open CodeLLMs. Die Serie umfasst Modelle wie den Qwen 2.5-32B-Instruct, der sich zum modernsten Open-Source-Code-Modell entwickelt hat und mit den Codierfähigkeiten proprietärer Giganten wie GPT-4o und Gemini konkurriert.
Diese Modelle werden wie folgt vorgestellt:
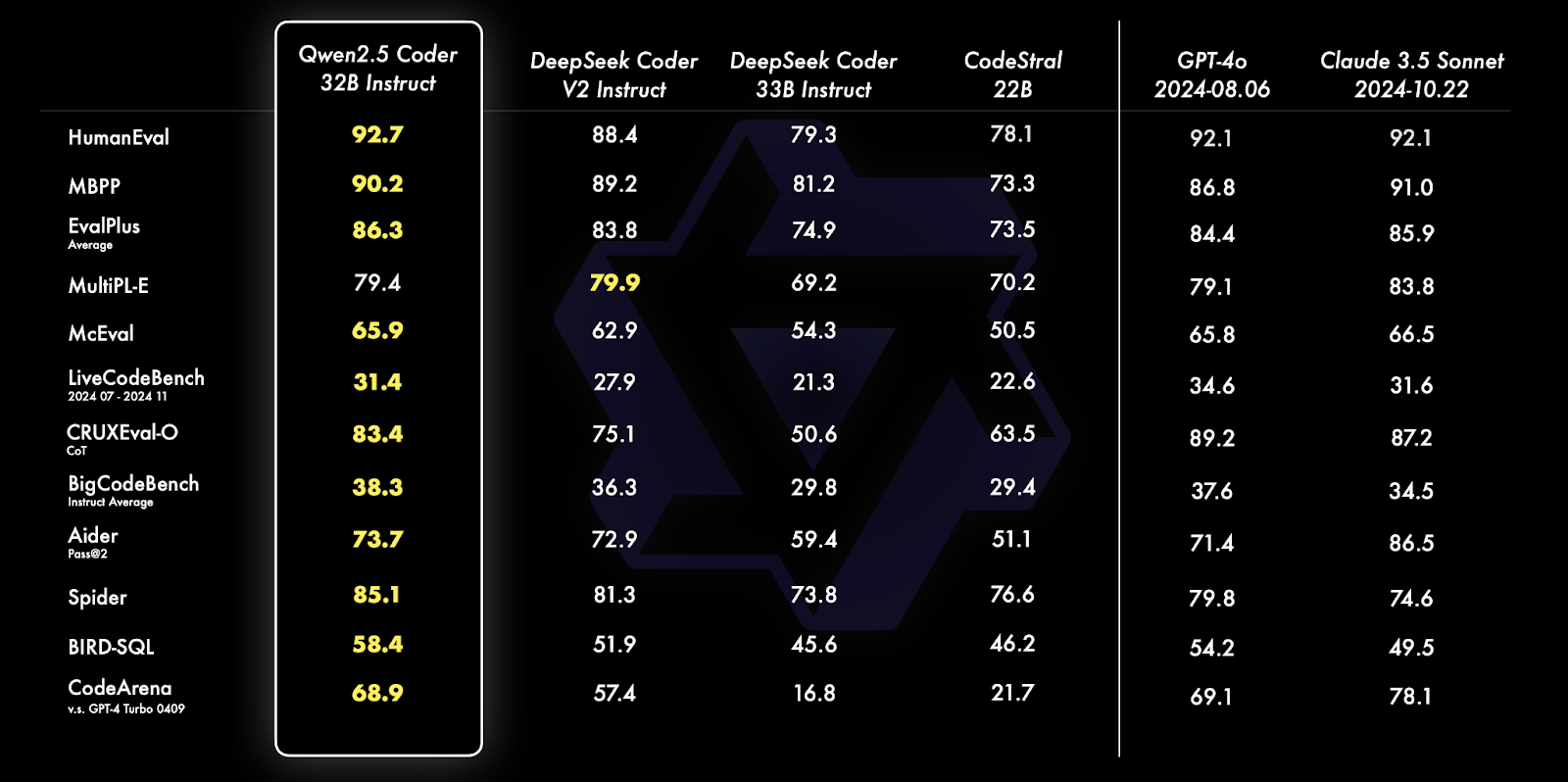
Quelle: Qwens offizieller Blog
Qwen 2.5 Coder 32B Instruct übertrifft seine Konkurrenten in mehreren Benchmarks, darunter HumanEval, MBPP und Spider, und zeigt dabei außergewöhnliche Programmier- und Problemlösungsfähigkeiten. Er übertrifft bei verschiedenen Aufgaben wie SQL-Abfragegenerierung, Code-Evaluierung und realen Programmierherausforderungen Modelle wie GPT-4o und Claude 3.5 Sonnet.
Um mehr über die Fähigkeiten und Vergleiche dieser Modelle zu erfahren, lies den Qwen2.5-Coder Series Ankündigungsartikel.
In diesem Abschnitt werden wir uns mit der Code-Implementierung unseres Code-Review-Assistenten mit Gradio beschäftigen.
Wir beginnen damit, die notwendigen Voraussetzungen zu schaffen, um dann das Modell mit optimierten Konfigurationen zu initialisieren.
Als Nächstes werden wir Kernfunktionen definieren, die die Fähigkeiten des Modells nutzen und schließlich diese Komponenten in eine benutzerfreundliche Gradio-Oberfläche integrieren, die eine einfache Interaktion mit dem Assistenten ermöglicht.
Bevor wir mit der Implementierung beginnen, müssen wir sicherstellen, dass wir die folgenden Tools und Bibliotheken installiert haben:
Führe die folgenden Befehle aus, um die notwendigen Abhängigkeiten zu installieren:
!pip install torch transformers gradio bitsandbytes -qSobald die oben genannten Abhängigkeiten installiert sind, führst du die folgenden Importbefehle aus:
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
import torch
Import gradio as grHinweis: Die Ausführung des Qwen2.5-Coder-32B-Instruct-Modells auf Google Colab erfordert einen A100-Grafikprozessor mit viel RAM. Wenn die Ressourcen begrenzt sind, solltest du Modelle mit niedrigeren Parametern wie 0,5B, 3B, 7B oder 14B verwenden.
Die Hugging Face Transformers-Bibliothek vereinfacht das Laden großer Modelle. Wir beginnen mit der Initialisierung der Qwen2.5-Coder-32B-Instruct Modell von HuggingFace mit Quantisierung für eine bessere Leistung:
# Define quantization configuration for optimized performance
bnb_config = BitsAndBytesConfig(load_in_8bit=True)
# Load the model and tokenizer
model_name = "Qwen/Qwen2.5-Coder-32B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto",
quantization_config=bnb_config
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
if tokenizer.pad_token_id is None:
tokenizer.pad_token_id = tokenizer.eos_token_idMit dem obigen Codeschnipsel können wir das Qwen2.5-Coder-32B-Instruct-Modell mit einer 8-Bit-Quantisierung laden, was den Speicherverbrauch reduziert und eine effiziente Ausführung auf Geräten mit begrenzten Ressourcen ermöglicht.
Es verwendet BitsAndBytesConfig, um die Quantisierung zu aktivieren, torch.float16 für optimierte Berechnungen auf unterstützten GPUs und device_map="auto" für die automatische Hardwarezuweisung. Der Tokenizer aus der Bibliothek transformers von HuggingFace sorgt für eine einfache Textverarbeitung, indem er ein pad_token_id zuweist, wenn es nicht bereits gesetzt ist. Diese Konfiguration macht es einfach, große Modelle effizient auf Consumer-Grade-Hardware auszuführen.
Nachdem wir das Modell zusammen mit dem Tokenizer geladen haben, richten wir eine Funktion ein, die mit der Methode apply_chat_template eine Antwort aus dem Modell erzeugt.
def generate_response(messages):
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=200,
temperature=0.7,
repetition_penalty=1.2
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
return responseDie obige Funktion dient als Hilfsmittel, um mit dem Qwen2.5-Coder-32B-Instruct-Modell zu interagieren und kontextabhängige Antworten zu erzeugen. Er nimmt eine Liste von chatähnlichen Nachrichten (mit Rollen wie "System" und "Benutzer") als Eingabe und führt die folgenden Schritte durch:
apply_chat_template und bereitet sie für das chatbasierte Verständnis des Modells vor.max_new_tokens=200Dieser Parameter begrenzt die Länge der Antwort auf 200 Token.temperature=0.7Das hilft, die Zufälligkeit der Antwort zu kontrollieren und so ein Gleichgewicht zwischen Kreativität und Beständigkeit herzustellen.repetition_penalty=1.2Dieser Parameter verhindert, dass sich Phrasen in der Ausgabe wiederholen.4. Nachbearbeiten: In diesem Schritt wird die Eingabeaufforderung aus der generierten Ausgabe entfernt, indem die Antwort mit der Funktion batch_decode in eine für Menschen lesbare Zeichenfolge zerlegt und dekodiert wird. Die Funktion abstrahiert die Komplexität der Vorbereitung, Generierung und Dekodierung von Antworten und ist somit für verschiedene Aufgaben wie Debugging, Codeanalyse und die Generierung von umsetzbarem Feedback wiederverwendbar.
Als Nächstes richten wir den Code für die Kernfunktionen unserer Anwendung ein, nämlich den Code Analyzer, den Code Improver und den Coding Standards Checker. Da wir ein Anweisungsmodell verwenden, können wir Rollen wie "System" und "Benutzer" verwenden und sie innerhalb der Eingabeaufforderung an das Modell übergeben, um eine Antwort zu erzeugen.
Hier sind die drei Hauptfunktionen unserer App: Fehlerdetektor, Codequalitätsexperte und Experte für Codierungsstandards.
Dieser Assistent identifiziert Syntaxfehler, logische Bugs und potenzielle Schwachstellen in dem bereitgestellten Code. Die spezifischen Anweisungen für das Modell lauten:
def analyze_code_issues(code):
messages = [
{"role": "system", "content": "You are Qwen, a helpful coding assistant. Your job is to analyze and debug code."},
{"role": "user", "content": f"""Review this code:
{code}
List all syntax errors, logical bugs, and potential runtime issues. Format as:
- Error/Bug: [description]
- Impact: [potential consequences]
- Fix: [suggested solution]"""}
]
return generate_response(messages)Der obige Code besteht aus Nachrichten mit Rollen und Inhalten sowie einer ersten Aufforderung an das Modell, wie ein hilfreicher Kodierassistent zu handeln. Diese Nachricht wird dann an die Funktion generate_response weitergegeben, um eine passende Antwort zurückzugeben.
Dieser Assistent hilft dabei, die Lesbarkeit, Effizienz und Wartbarkeit des Codes zu verbessern, indem er Vorschläge zu Optimierungen und zur Codequalität macht.
def suggest_code_improvements(code):
messages = [
{"role": "system", "content": "You are Qwen, an expert in code optimization. Help improve code quality."},
{"role": "user", "content": f"""Review this code:
{code}
Provide specific optimization suggestions:
1. Performance improvements
2. Better variable names
3. Simpler logic
4. Memory efficiency
Include code examples where relevant."""}
]
return generate_response(messages)Dieser Assistent prüft, ob der bereitgestellte Code den idealen Kodierungsstandards entspricht und macht entsprechende Vorschläge.
messages = [
{"role": "system", "content": "You are Qwen, a coding standards expert. Your task is to evaluate code adherence to best practices."},
{"role": "user", "content": f"""Evaluate this code:
{code}
Check against these standards:
1. PEP 8 compliance
2. Function/variable naming
3. Documentation completeness
4. Error handling
5. Code organization
List violations with specific examples and corrections."""}
]
return generate_response(messages)Mit der oben genannten Funktion kann das Modell als Experte für Codierungsstandards fungieren und den bereitgestellten Code auf die Einhaltung von Richtlinien wie PEP 8, korrekte Funktionsbenennung, robuste Fehlerbehandlung und mehr überprüfen.
Gradio vereinfacht den Einsatz des Assistenten, indem es den Nutzern ermöglicht, Code einzugeben und die Ergebnisse interaktiv anzuzeigen. Die Antworten des Modells aus den vorherigen Abschnitten werden nahtlos in eine Gradio-Oberfläche integriert.
def review_code(code):
issues = analyze_code_issues(code)
improvements = suggest_code_improvements(code)
standards = check_coding_standards(code)
return issues, improvements, standards
interface = gr.Interface(
fn=review_code,
inputs="textbox",
outputs=["text", "text", "text"],
title="AI Code Review Assistant",
description="Analyze code for issues, suggest improvements, and check adherence to coding standards."
)
interface.launch(debug=True)Die Funktion review_code besteht aus drei Komponenten: analyze_code_issues, suggest_code_improvements, und check_coding_standards. Diese Funktionen identifizieren Syntaxfehler, Bugs, Optimierungen und die Einhaltung von Codierungsstandards. Die Gradio-Schnittstelle nimmt Benutzereingaben über ein Textfeld entgegen und gibt die Ergebnisse in drei Textfeldern aus. Es bietet eine einfach zu bedienende Weboberfläche für Entwickler, um ihren Code zu analysieren und zu verbessern. Wenn wir diese letzte Zelle ausführen, erhalten wir eine Gradio-App-Oberfläche, wie sie unten abgebildet ist.
Der KI-Code-Review-Assistent, der mit Gradio entwickelt wurde
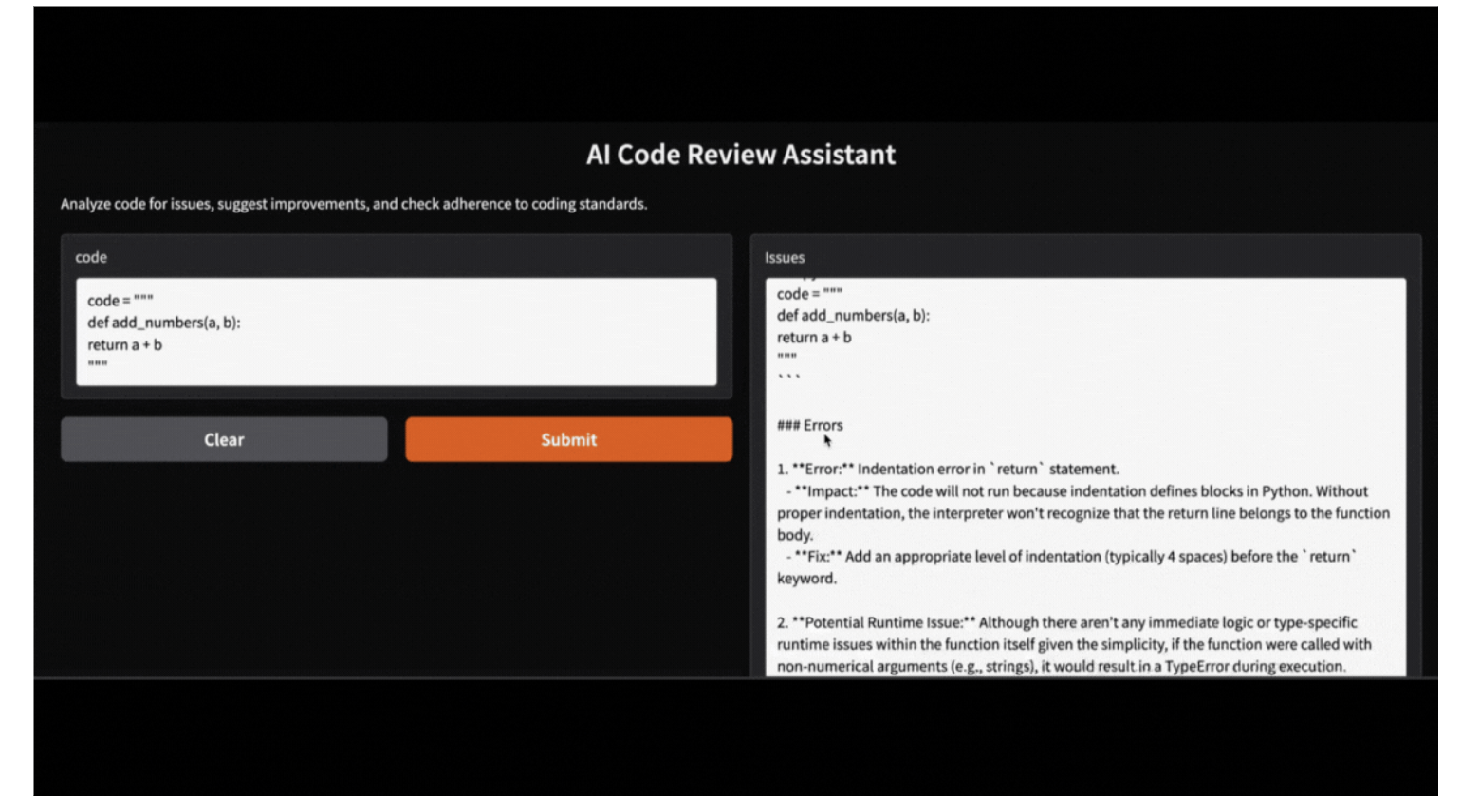
Falls ein Nutzer keine Gradio-App ausführen möchte, kann er den Assistenten testen, indem er den folgenden Code ausführt. Hier ist ein Beispiel dafür, wie der Assistent eine fehlerhafte Python-Funktion analysiert:
code = """
def add_numbers(a, b):
return a + b
"""
issues, suggestions, standards = review_code(code)
print("Issues:", issues)
print("Suggestions:", suggestions)
print("Adherence to coding standards:", standards)Issues:
Here's the review of your provided Python code:
```python
.
.
- **Fix:** Implement input validation or use exception handling to manage unexpected data types gracefully.
Suggestions:
Certainly! Let's review the provided function and suggest optimizations based on your criteria:
1. **Proper Indentation**
.
.
2. **Better Variable Names**
In this simple case, `a` and `b` could be considered generic enough as they represent arbitrary operands. However, more descriptive names can help when functions become complex.
Adherence to coding standards:
Certainly! Let's go through the provided Python function `add_numbers` according to the specified standards.
.
.
2. **Function/Variable Naming**
- The names `add_numbers`, `a`, and `b` follow good conventions for simplicity and clarity in their context (function name clearly indicates addition; variable names indicate they're operands). However, if you want more descriptive variable names (especially useful in larger functions), consider using something like `operand_one` or `num1`.
Diese Gradio-App kann auch lokal mit dem bereitgestellten Code ausgeführt werden, wobei das Qwen-2.5-Modell verwendet wird, das über Ollama. Ersetze einfach das HF-Bibliotheksmodell durch das lokale Ollama-Bibliotheksmodell, und deine App wird nahtlos in Betrieb genommen.
In diesem Artikel haben wir gelernt, wie man Qwen 2.5-Coder-32B-Instruct in Kombination mit Gradio verwendet , um einen KI-Code-Review-Assistenten zu bauen. Dieses Tool analysiert den Code auf Syntaxfehler, schlägt Optimierungen vor und setzt Codierungsstandards durch, um den Softwareentwicklungsprozess zu rationalisieren.
Jetzt, wo du weißt, wie du Qwen 2.5 einrichten kannst, möchte ich dich ermutigen, dein eigenes Projekt zu bauen!
Lerne KI mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.