
Programa
Desenvolvimento de aplicativos de IA
21 h
A série Qwen 2.5 Coder (anteriormente conhecida como CodeQwen1.5), desenvolvida pela equipe de pesquisa Qwen da Alibaba, é dedicada ao avanço dos Open CodeLLMs. A série inclui modelos como o Qwen 2.5-32B-Instruct, que se tornou o modelo de código aberto de última geração, rivalizando com os recursos de codificação de gigantes proprietários como o GPT-4o e o Gemini.
Esses modelos são apresentados como sendo:
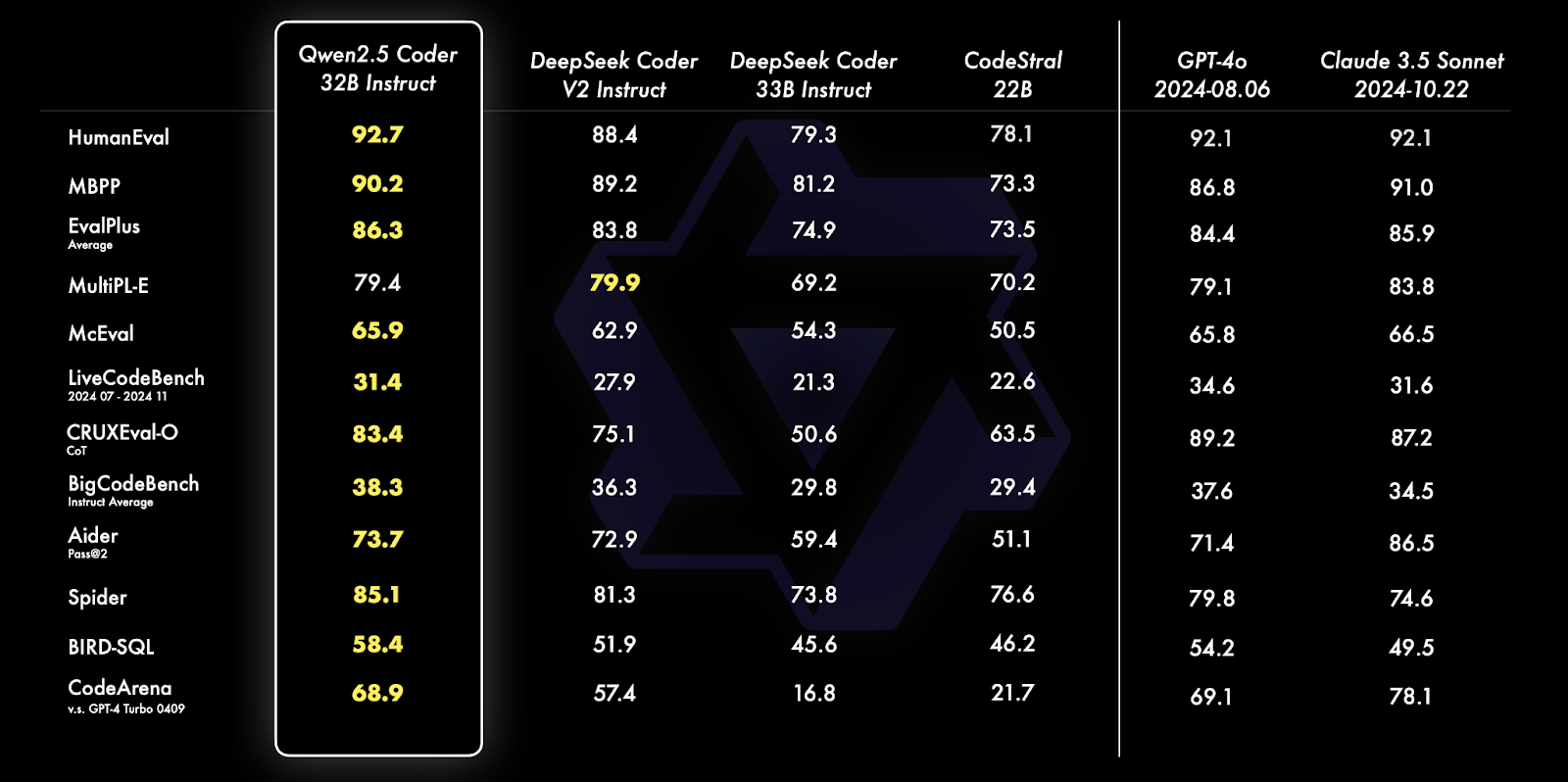
Fonte: Blog oficial de Qwen
O Qwen 2.5 Coder 32B Instruct supera seus equivalentes em vários benchmarks, incluindo HumanEval, MBPP e Spider, demonstrando recursos excepcionais de codificação e solução de problemas. Ele se destaca em diversas tarefas, como geração de consultas SQL, avaliação de código e desafios de programação do mundo real, superando modelos como o GPT-4o e Claude 3.5 Sonnet.
Para saber mais sobre os recursos e as comparações desses modelos, leia o artigo de anúncio da série Qwen2.5-Coder artigo de anúncio.
Nesta seção, vamos nos aprofundar na implementação do código do nosso assistente de revisão de código usando o Gradio.
Começaremos definindo os pré-requisitos necessários e, em seguida, inicializaremos o modelo com configurações otimizadas.
Em seguida, definiremos as principais funcionalidades, usando os recursos de instrução do modelo e, por fim, integrando esses componentes em uma interface Gradio amigável, permitindo uma interação fácil com o assistente.
Antes de mergulhar na implementação, vamos garantir que você tenha as seguintes ferramentas e bibliotecas instaladas:
Execute os seguintes comandos para instalar as dependências necessárias:
!pip install torch transformers gradio bitsandbytes -qQuando as dependências acima estiverem instaladas, execute os seguintes comandos de importação:
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
import torch
Import gradio as grObservação: Para executar o modelo Qwen2.5-Coder-32B-Instruct no Google Colab, você precisa de uma GPU A100 com muita RAM. Se os recursos forem limitados, considere o uso de modelos com parâmetros mais baixos, como 0,5B, 3B, 7B ou 14B.
A biblioteca Hugging Face Transformers simplifica o carregamento de modelos grandes. Começamos inicializando o Qwen2.5-Coder-32B-Instruct do HuggingFace com quantização para melhorar o desempenho:
# Define quantization configuration for optimized performance
bnb_config = BitsAndBytesConfig(load_in_8bit=True)
# Load the model and tokenizer
model_name = "Qwen/Qwen2.5-Coder-32B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto",
quantization_config=bnb_config
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
if tokenizer.pad_token_id is None:
tokenizer.pad_token_id = tokenizer.eos_token_idO trecho de código acima nos permite carregar o modelo Qwen2.5-Coder-32B-Instruct com quantização de 8 bits, reduzindo o uso da memória para uma execução eficiente em dispositivos com recursos limitados.
Ele usa BitsAndBytesConfig para ativar a quantização, torch.float16 para computação otimizada em GPUs compatíveis e device_map="auto" para alocação automática de hardware. O tokenizador da biblioteca transformers da HuggingFace garante um processamento de texto fácil, atribuindo um pad_token_id se você ainda não tiver definido. Essa configuração facilita a execução eficiente de modelos grandes em hardware de nível de consumidor.
Depois de carregar o modelo junto com o tokenizador, configuramos uma função para gerar uma resposta do modelo usando o método apply_chat_template.
def generate_response(messages):
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=200,
temperature=0.7,
repetition_penalty=1.2
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
return responseA função acima serve como um utilitário para interagir com o modelo Qwen2.5-Coder-32B-Instruct para gerar respostas com reconhecimento de contexto. Ele recebe uma lista de mensagens do tipo chat (com funções como "sistema" e "usuário") como entrada e executa as seguintes etapas:
apply_chat_template, preparando-as para o entendimento baseado em bate-papo do modelo.max_new_tokens=200Esse parâmetro limita o comprimento da resposta a 200 tokens.temperature=0.7Isso ajuda a controlar a aleatoriedade da resposta, equilibrando assim a criatividade e a consistência.repetition_penalty=1.2Esse parâmetro não incentiva frases repetitivas na saída.4. Pós-processamento: Essa etapa remove o prompt de entrada da saída gerada, dividindo e decodificando a resposta em uma string legível por humanos usando a função batch_decode. A função abstrai a complexidade da preparação, geração e decodificação de respostas, tornando-a reutilizável para várias tarefas, como depuração, análise de código e geração de feedback acionável.
Em seguida, configuramos o código para os principais recursos do nosso aplicativo, ou seja, o analisador de código, o melhorador de código e o verificador de padrões de codificação. Como estamos usando um modelo de instrução, podemos usar funções como "sistema" e "usuário" e passá-las para o modelo dentro do prompt para gerar uma resposta.
Aqui estão os três principais recursos do nosso aplicativo: detector de problemas, especialista em qualidade de código e especialista em padrões de codificação.
Esse assistente identifica erros de sintaxe, bugs lógicos e possíveis vulnerabilidades no código fornecido. As instruções específicas para o modelo são:
def analyze_code_issues(code):
messages = [
{"role": "system", "content": "You are Qwen, a helpful coding assistant. Your job is to analyze and debug code."},
{"role": "user", "content": f"""Review this code:
{code}
List all syntax errors, logical bugs, and potential runtime issues. Format as:
- Error/Bug: [description]
- Impact: [potential consequences]
- Fix: [suggested solution]"""}
]
return generate_response(messages)O código acima consiste em mensagens que contêm funções e conteúdo, juntamente com um prompt inicial para que o modelo atue como um assistente de codificação útil. Essa mensagem é então passada para a função generate_response para retornar uma resposta adequada.
Esse assistente ajuda a melhorar a legibilidade, a eficiência e a manutenção do código, gerando sugestões sobre otimizações e qualidade do código.
def suggest_code_improvements(code):
messages = [
{"role": "system", "content": "You are Qwen, an expert in code optimization. Help improve code quality."},
{"role": "user", "content": f"""Review this code:
{code}
Provide specific optimization suggestions:
1. Performance improvements
2. Better variable names
3. Simpler logic
4. Memory efficiency
Include code examples where relevant."""}
]
return generate_response(messages)Esse assistente verifica se o código fornecido segue os padrões ideais de codificação e fornece sugestões adequadas.
messages = [
{"role": "system", "content": "You are Qwen, a coding standards expert. Your task is to evaluate code adherence to best practices."},
{"role": "user", "content": f"""Evaluate this code:
{code}
Check against these standards:
1. PEP 8 compliance
2. Function/variable naming
3. Documentation completeness
4. Error handling
5. Code organization
List violations with specific examples and corrections."""}
]
return generate_response(messages)A função acima permite que o modelo atue como um especialista em padrões de codificação, avaliando o código fornecido quanto à adesão às diretrizes, como conformidade com o PEP 8, nomeação adequada de funções, tratamento robusto de erros e muito mais.
O Gradio simplifica a implantação do assistente, permitindo que os usuários insiram códigos e visualizem os resultados de forma interativa. As respostas do modelo das seções anteriores são perfeitamente integradas em uma interface Gradio.
def review_code(code):
issues = analyze_code_issues(code)
improvements = suggest_code_improvements(code)
standards = check_coding_standards(code)
return issues, improvements, standards
interface = gr.Interface(
fn=review_code,
inputs="textbox",
outputs=["text", "text", "text"],
title="AI Code Review Assistant",
description="Analyze code for issues, suggest improvements, and check adherence to coding standards."
)
interface.launch(debug=True)A função review_code integra três componentes: analyze_code_issues, suggest_code_improvements, e check_coding_standards. Essas funções identificam erros de sintaxe, bugs, otimizações e aderência aos padrões de codificação. A interface do Gradio recebe a entrada do usuário por meio de uma caixa de texto e exibe os resultados como três campos de texto. Ele oferece uma interface da Web fácil de usar para que os desenvolvedores analisem e aprimorem seus códigos. Quando executamos essa célula final, obtemos uma interface de aplicativo Gradio em execução, como a mostrada abaixo.
A interface do assistente de revisão de código de IA criada com o Gradio
Caso um usuário não queira executar um aplicativo Gradio, ele pode testar o assistente executando o seguinte código. Aqui está um exemplo de como o assistente analisa uma função Python com erros:
code = """
def add_numbers(a, b):
return a + b
"""
issues, suggestions, standards = review_code(code)
print("Issues:", issues)
print("Suggestions:", suggestions)
print("Adherence to coding standards:", standards)Issues:
Here's the review of your provided Python code:
```python
.
.
- **Fix:** Implement input validation or use exception handling to manage unexpected data types gracefully.
Suggestions:
Certainly! Let's review the provided function and suggest optimizations based on your criteria:
1. **Proper Indentation**
.
.
2. **Better Variable Names**
In this simple case, `a` and `b` could be considered generic enough as they represent arbitrary operands. However, more descriptive names can help when functions become complex.
Adherence to coding standards:
Certainly! Let's go through the provided Python function `add_numbers` according to the specified standards.
.
.
2. **Function/Variable Naming**
- The names `add_numbers`, `a`, and `b` follow good conventions for simplicity and clarity in their context (function name clearly indicates addition; variable names indicate they're operands). However, if you want more descriptive variable names (especially useful in larger functions), consider using something like `operand_one` or `num1`.
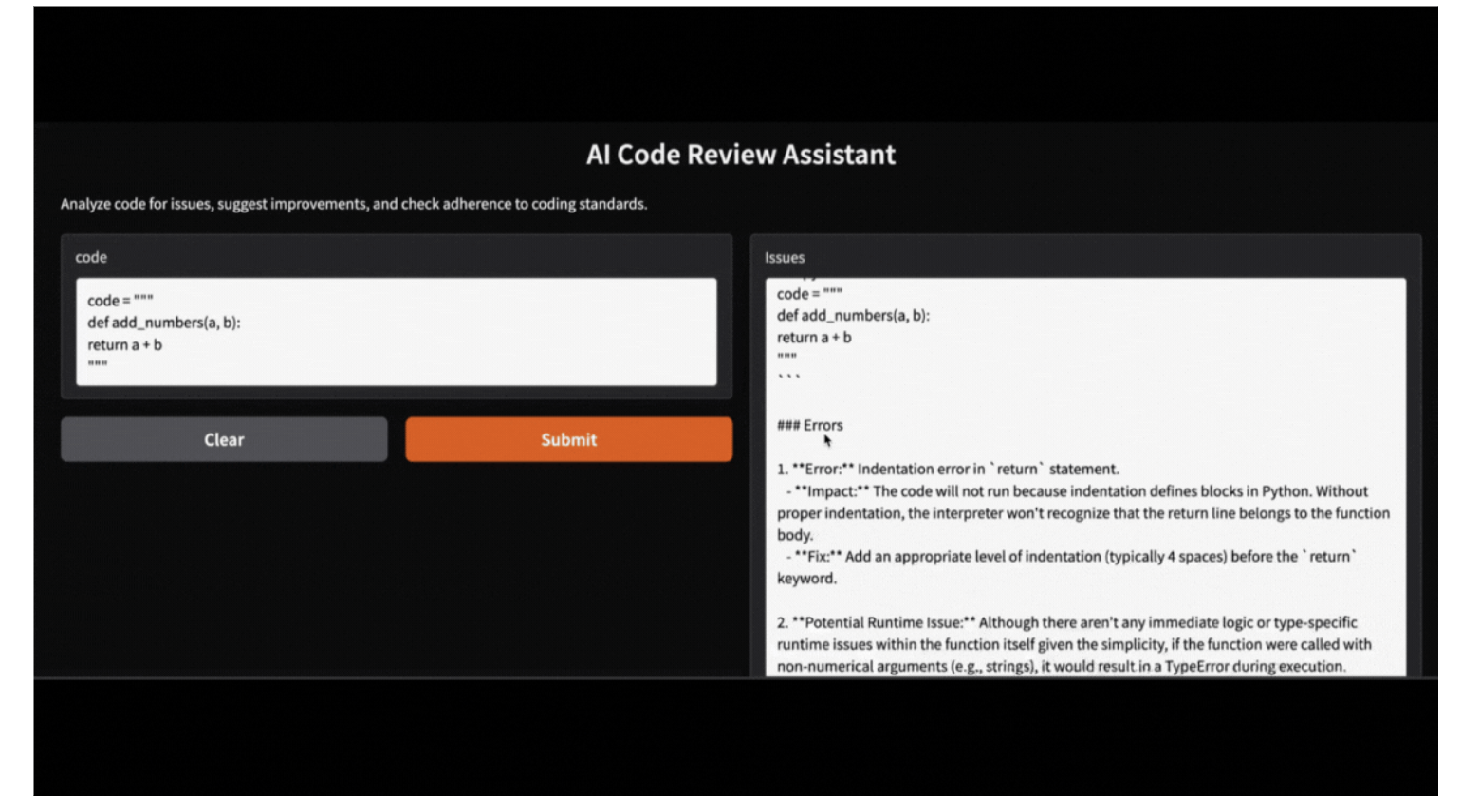
Esse aplicativo Gradio também pode ser executado localmente com o código fornecido, utilizando o modelo Qwen-2.5 acessível via Ollama. Basta substituir o modelo de biblioteca HF pelo modelo de biblioteca Ollama local e seu aplicativo estará pronto e funcionando sem problemas.
Neste artigo, aprendemos a usar o Qwen 2.5-Coder-32B-Instruct em combinação com o Gradio para criar um assistente de revisão de código de IA. Essa ferramenta analisa o código em busca de erros de sintaxe, sugere otimizações e aplica padrões de codificação, simplificando o processo de desenvolvimento de software.
Agora que você sabe como configurar o Qwen 2.5, incentivo-o a criar seu próprio projeto!
Aprenda IA com estes cursos!
Programa
Curso
Curso
blog
DataCamp Team
4 min
blog
Abid Ali Awan
9 min
Tutorial
Dimitri Didmanidze
Tutorial
Kurtis Pykes

