
Cursus
Développer des applications d'IA
21 h
La série Qwen2.5-Coder (anciennement connue sous le nom de CodeQwen1.5), développée par l'équipe de recherche Qwen d'Alibaba, est dédiée à l'avancement des Open CodeLLM. La série comprend des modèles tels que le Qwen 2.5-32B-Instruct, qui est devenu le modèle de code open-source de pointe, rivalisant avec les capacités de codage de géants propriétaires tels que GPT-4o et Gemini.
Ces modèles sont présentés comme suit :
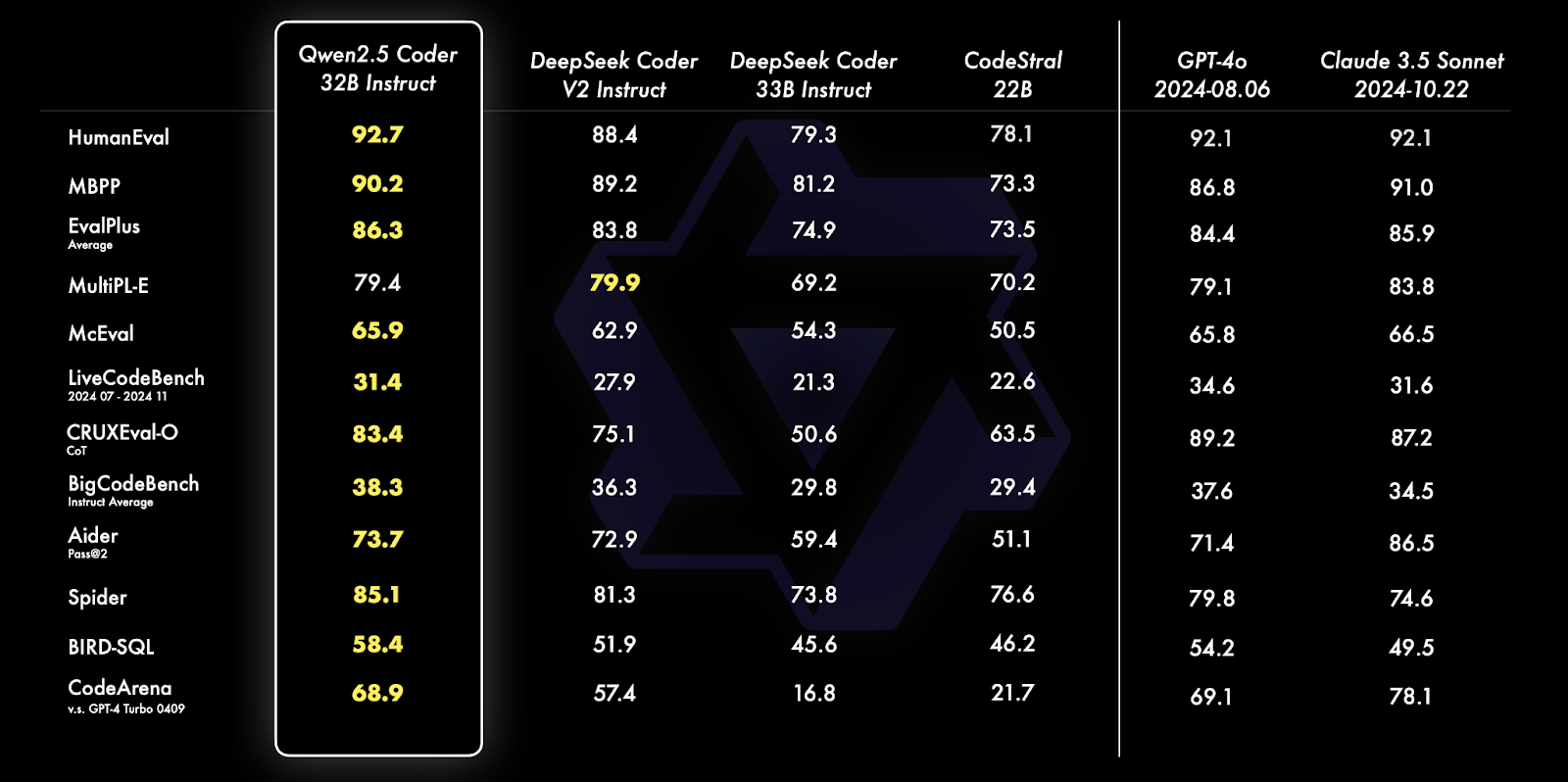
Source : Blog officiel de Qwen
Qwen 2.5 Coder 32B Instruct surpasse ses homologues sur de nombreux benchmarks, y compris HumanEval, MBPP et Spider, démontrant des capacités exceptionnelles de codage et de résolution de problèmes. Il excelle dans diverses tâches telles que la génération de requêtes SQL, l'évaluation de code et les défis de programmation du monde réel, surpassant des modèles tels que GPT-4o et Claude 3.5 Sonnet.
Pour en savoir plus sur les capacités et les comparaisons de ces modèles, lisez l'article d'annonce de la série Qwen2.5-Coder article d'annonce.
Dans cette section, nous allons nous plonger dans l'implémentation du code de notre assistant de revue de code en utilisant Gradio.
Nous commencerons par mettre en place les conditions préalables nécessaires, puis nous initialiserons le modèle avec des configurations optimisées.
Ensuite, nous définirons les fonctionnalités de base, en utilisant les capacités d'instruction du modèle, et enfin nous intégrerons ces composants dans une interface Gradio conviviale, permettant une interaction facile avec l'assistant.
Avant de plonger dans la mise en œuvre, assurons-nous que les outils et bibliothèques suivants sont installés :
Exécutez les commandes suivantes pour installer les dépendances nécessaires :
!pip install torch transformers gradio bitsandbytes -qUne fois les dépendances ci-dessus installées, exécutez les commandes d'importation suivantes :
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
import torch
Import gradio as grNote : L'exécution du modèle Qwen2.5-Coder-32B-Instruct sur Google Colab nécessite un GPU A100 avec beaucoup de RAM. Si les ressources sont limitées, envisagez d'utiliser des modèles à paramètres plus faibles tels que 0,5B, 3B, 7B ou 14B.
La bibliothèque de transformateurs Hugging Face simplifie le chargement des grands modèles. Nous commençons par initialiser le Qwen2.5-Coder-32B-Instruct de HuggingFace avec quantification pour de meilleures performances :
# Define quantization configuration for optimized performance
bnb_config = BitsAndBytesConfig(load_in_8bit=True)
# Load the model and tokenizer
model_name = "Qwen/Qwen2.5-Coder-32B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto",
quantization_config=bnb_config
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
if tokenizer.pad_token_id is None:
tokenizer.pad_token_id = tokenizer.eos_token_idL'extrait de code ci-dessus nous permet de charger le modèle Qwen2.5-Coder-32B-Instruct avec une quantification sur 8 bits, réduisant ainsi l'utilisation de la mémoire pour une exécution efficace sur des appareils aux ressources limitées.
Il utilise BitsAndBytesConfig pour activer la quantification, torch.float16 pour optimiser le calcul sur les GPU pris en charge et device_map="auto" pour l'allocation automatique du matériel. Le tokenizer de la bibliothèque transformers de HuggingFace assure un traitement facile du texte, en attribuant un pad_token_id s'il n'est pas déjà défini. Cette configuration permet d'exécuter efficacement de grands modèles sur du matériel grand public.
Une fois le modèle chargé avec le tokenizer, nous configurons une fonction pour générer une réponse à partir du modèle à l'aide de la méthode apply_chat_template.
def generate_response(messages):
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=200,
temperature=0.7,
repetition_penalty=1.2
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
return responseLa fonction ci-dessus sert d'utilitaire pour interagir avec le modèle Qwen2.5-Coder-32B-Instruct afin de générer des réponses tenant compte du contexte. Il prend en entrée une liste de messages de type "chat" (avec des rôles tels que "système" et "utilisateur") et exécute les étapes suivantes :
apply_chat_template, les préparant ainsi à la compréhension du modèle basée sur le chat.max_new_tokens=200Ce paramètre limite la longueur de la réponse à 200 jetons.temperature=0.7Cela permet de contrôler le caractère aléatoire de la réponse et d'équilibrer ainsi la créativité et la cohérence.repetition_penalty=1.2Ce paramètre décourage les phrases répétitives dans la sortie.4. Post-traitement : Cette étape supprime l'invite d'entrée de la sortie générée en découpant et en décodant la réponse en une chaîne lisible par l'homme à l'aide de la fonction batch_decode. La fonction fait abstraction de la complexité de la préparation, de la génération et du décodage des réponses, ce qui la rend réutilisable pour diverses tâches telles que le débogage, l'analyse du code et la génération d'un retour d'information exploitable.
Ensuite, nous configurons le code des fonctions principales de notre application, à savoir l'analyseur de code, l'améliorateur de code et le vérificateur de normes de codage. Comme nous utilisons un modèle d'instruction, nous pouvons utiliser des rôles tels que "système" et "utilisateur" et les transmettre au modèle dans l'invite pour générer une réponse.
Voici les trois fonctions principales de notre application : détecteur de problèmes, expert en qualité de code et expert en normes de codage.
Cet assistant identifie les erreurs de syntaxe, les bogues logiques et les vulnérabilités potentielles dans le code fourni. Les instructions spécifiques pour le modèle sont les suivantes :
def analyze_code_issues(code):
messages = [
{"role": "system", "content": "You are Qwen, a helpful coding assistant. Your job is to analyze and debug code."},
{"role": "user", "content": f"""Review this code:
{code}
List all syntax errors, logical bugs, and potential runtime issues. Format as:
- Error/Bug: [description]
- Impact: [potential consequences]
- Fix: [suggested solution]"""}
]
return generate_response(messages)Le code ci-dessus consiste en des messages contenant des rôles et du contenu, ainsi qu'une invite initiale pour que le modèle agisse comme un assistant de codage utile. Ce message est ensuite transmis à la fonction generate_response qui renvoie une réponse appropriée.
Cet assistant aide à améliorer la lisibilité, l'efficacité et la maintenabilité du code, en générant des suggestions sur les optimisations et la qualité du code.
def suggest_code_improvements(code):
messages = [
{"role": "system", "content": "You are Qwen, an expert in code optimization. Help improve code quality."},
{"role": "user", "content": f"""Review this code:
{code}
Provide specific optimization suggestions:
1. Performance improvements
2. Better variable names
3. Simpler logic
4. Memory efficiency
Include code examples where relevant."""}
]
return generate_response(messages)Cet assistant vérifie si le code fourni respecte les normes de codage idéales et fournit des suggestions en conséquence.
messages = [
{"role": "system", "content": "You are Qwen, a coding standards expert. Your task is to evaluate code adherence to best practices."},
{"role": "user", "content": f"""Evaluate this code:
{code}
Check against these standards:
1. PEP 8 compliance
2. Function/variable naming
3. Documentation completeness
4. Error handling
5. Code organization
List violations with specific examples and corrections."""}
]
return generate_response(messages)La fonction ci-dessus permet au modèle d'agir en tant qu'expert des normes de codage, en évaluant le code fourni pour s'assurer qu'il respecte les lignes directrices telles que la conformité PEP 8, le nommage correct des fonctions, la gestion robuste des erreurs, etc.
Gradio simplifie le déploiement de l'assistant, permettant aux utilisateurs de saisir du code et de visualiser les résultats de manière interactive. Les réponses du modèle obtenues dans les sections précédentes sont intégrées de manière transparente dans une interface Gradio.
def review_code(code):
issues = analyze_code_issues(code)
improvements = suggest_code_improvements(code)
standards = check_coding_standards(code)
return issues, improvements, standards
interface = gr.Interface(
fn=review_code,
inputs="textbox",
outputs=["text", "text", "text"],
title="AI Code Review Assistant",
description="Analyze code for issues, suggest improvements, and check adherence to coding standards."
)
interface.launch(debug=True)La fonction review_code intègre trois composants : analyze_code_issues, suggest_code_improvements, et check_coding_standards. Ces fonctions permettent d'identifier les erreurs de syntaxe, les bogues, les optimisations et le respect des normes de codage. L'interface Gradio saisit les données de l'utilisateur dans une zone de texte et affiche les résultats dans trois champs de texte. Il offre aux développeurs une interface web facile à utiliser pour analyser et améliorer leur code. Une fois que nous avons exécuté cette dernière cellule, nous obtenons une interface d'application Gradio en cours d'exécution, comme celle illustrée ci-dessous.
L'interface de l'assistant de revue de code construit avec Gradio
Si un utilisateur ne souhaite pas exécuter une application Gradio, il peut tester l'assistant en exécutant le code suivant. Voici un exemple de la manière dont l'assistant analyse une fonction Python boguée :
code = """
def add_numbers(a, b):
return a + b
"""
issues, suggestions, standards = review_code(code)
print("Issues:", issues)
print("Suggestions:", suggestions)
print("Adherence to coding standards:", standards)Issues:
Here's the review of your provided Python code:
```python
.
.
- **Fix:** Implement input validation or use exception handling to manage unexpected data types gracefully.
Suggestions:
Certainly! Let's review the provided function and suggest optimizations based on your criteria:
1. **Proper Indentation**
.
.
2. **Better Variable Names**
In this simple case, `a` and `b` could be considered generic enough as they represent arbitrary operands. However, more descriptive names can help when functions become complex.
Adherence to coding standards:
Certainly! Let's go through the provided Python function `add_numbers` according to the specified standards.
.
.
2. **Function/Variable Naming**
- The names `add_numbers`, `a`, and `b` follow good conventions for simplicity and clarity in their context (function name clearly indicates addition; variable names indicate they're operands). However, if you want more descriptive variable names (especially useful in larger functions), consider using something like `operand_one` or `num1`.
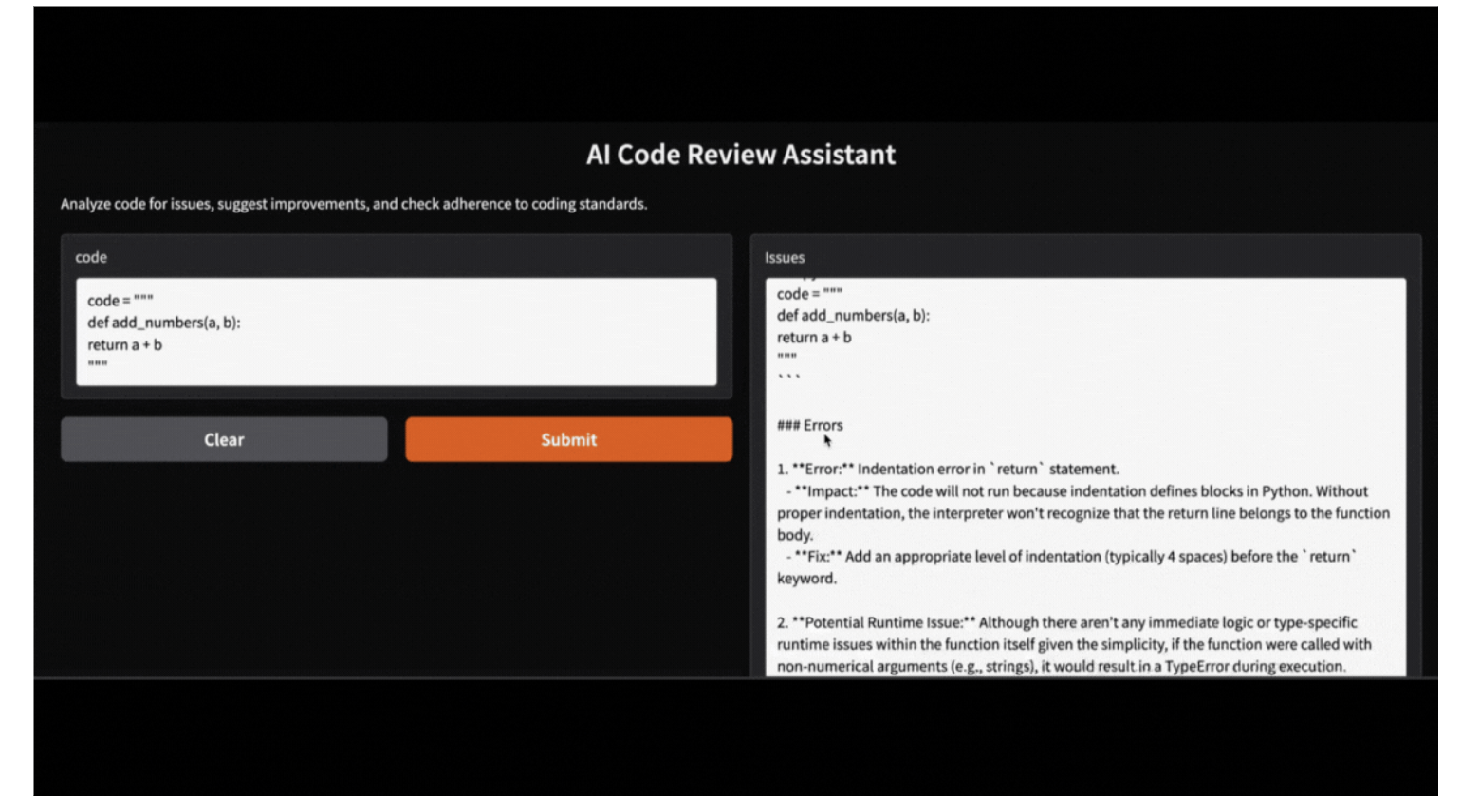
Cette application Gradio peut également être exécutée localement avec le code fourni, en utilisant le modèle Qwen-2.5 accessible via Ollama. Remplacez simplement le modèle de bibliothèque HF par le modèle de bibliothèque locale Ollama, et votre application sera opérationnelle en toute transparence.
Dans cet article, nous avons appris à utiliser Qwen 2.5-Coder-32B-Instruct en combinaison avec Gradio pour créer un assistant de revue de code IA. Cet outil analyse le code à la recherche d'erreurs de syntaxe, suggère des optimisations et applique des normes de codage, rationalisant ainsi le processus de développement logiciel.
Maintenant que vous savez comment configurer Qwen 2.5, je vous encourage à construire votre propre projet !
Apprenez l'IA avec ces cours !
Cursus
Cours
Cours