Curso
Aprendizaje profundo avanzado con Keras
4 h
34.9K

El aprendizaje profundo es un subcampo del aprendizaje automático que consiste en un conjunto de algoritmos inspirados en la estructura y función del cerebro.
TensorFlow es el segundo marco de aprendizaje automático que Google creó y utilizó para diseñar, construir y entrenar modelos de aprendizaje profundo. Puedes utilizar la biblioteca TensorFlow para realizar cálculos numéricos, lo que en sí mismo no parece demasiado especial, pero estos cálculos se realizan con gráficos de flujo de datos. En estos grafos, los nodos representan operaciones matemáticas, mientras que las aristas representan los datos, que suelen ser matrices de datos multidimensionales o tensores, que se comunican entre dichas aristas.
¿Lo ves? El nombre "TensorFlow" deriva de las operaciones que las redes neuronales realizan sobre matrices de datos multidimensionales o tensores. Es literalmente un flujo de tensores. Por ahora, esto es todo lo que necesitas saber sobre los tensores, ¡pero profundizarás en ello en las próximas secciones!
El tutorial de TensorFlow de hoy para principiantes te introducirá en la realización del aprendizaje profundo de forma interactiva:
Descarga el cuaderno de este tutorial aquí.
También podría interesarte un curso sobre Aprendizaje Profundo en Python, el tutorial Keras de DataCamp o el tutorial keras con R.
Para entender bien los tensores, es bueno tener algunos conocimientos prácticos de álgebra lineal y cálculo vectorial. Ya has leído en la introducción que los tensores se implementan en TensorFlow como matrices de datos multidimensionales, pero quizá sea necesaria alguna introducción más para comprender completamente los tensores y su uso en el aprendizaje automático.
Antes de entrar en los vectores planos, conviene repasar brevemente el concepto de "vectores"; los vectores son tipos especiales de matrices, que son matrices rectangulares de números. Como los vectores son colecciones ordenadas de números, a menudo se consideran matrices de columnas: tienen una sola columna y un número determinado de filas. En otros términos, también podrías considerar los vectores como magnitudes escalares a las que se ha dado una dirección.
Recuerda: un ejemplo de escalar es "5 metros" o "60 m/seg", mientras que un vector es, por ejemplo, "5 metros al Norte" o "60 m/seg al Este". La diferencia entre ambos es, obviamente, que el vector tiene una dirección. Sin embargo, estos ejemplos que has visto hasta ahora pueden parecer muy alejados de los vectores que puedes encontrarte cuando trabajes con problemas de aprendizaje automático. Esto es normal; la longitud de un vector matemático es un número puro: es absoluta. La dirección, en cambio, es relativa: se mide respecto a alguna dirección de referencia y tiene unidades de radianes o grados. Normalmente se supone que la dirección es positiva y en sentido contrario a las agujas del reloj respecto a la dirección de referencia.
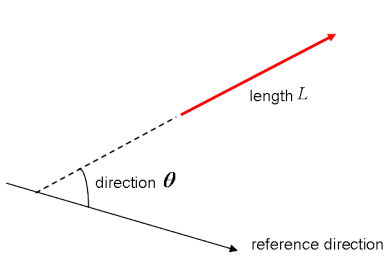
Visualmente, por supuesto, representas los vectores como flechas, como puedes ver en la imagen de arriba. Esto significa que puedes considerar los vectores también como flechas que tienen dirección y longitud. La dirección se indica con la cabeza de la flecha, mientras que la longitud se indica con la longitud de la flecha.
¿Qué pasa entonces con los vectores planos?
Los vectores planos son la configuración más sencilla de los tensores. Son muy parecidos a los vectores normales, como has visto antes, con la única diferencia de que se encuentran en un espacio vectorial. Para entenderlo mejor, empecemos con un ejemplo: tienes un vector que es 2 X 1. Esto significa que el vector pertenece al conjunto de números reales que vienen emparejados de dos en dos. O, dicho de otro modo, forman parte del biespacio. En estos casos, puedes representar los vectores en el plano de coordenadas (x,y) con flechas o rayos.
Trabajando desde este plano de coordenadas en una posición estándar en la que los vectores tienen su punto final en el origen (0,0), puedes deducir la coordenada x observando la primera fila del vector, mientras que encontrarás la coordenada y en la segunda fila. Por supuesto, no siempre es necesario mantener esta posición estándar: los vectores pueden moverse paralelos a sí mismos en el plano sin experimentar cambios.
Observa que, del mismo modo, para los vectores de tamaño 3 X 1, se habla del triespacio. Puedes representar el vector como una figura tridimensional con flechas que señalen posiciones en el paso de los vectores: se dibujan en los ejes x, y y z estándar.
Está bien tener estos vectores y representarlos en el plano de coordenadas, pero en esencia, tienes estos vectores para poder realizar operaciones con ellos y una cosa que puede ayudarte a hacerlo es expresar tus vectores como bases o vectores unitarios.
Los vectores unitarios son vectores de magnitud uno. A menudo reconocerás el vector unitario por una letra minúscula con un circunflejo, o "sombrero". Los vectores unitarios te resultarán útiles si quieres expresar un vector 2D o 3D como una suma de dos o tres componentes ortogonales, como los ejes x e y, o el eje z.
Y cuando hables de expresar un vector, por ejemplo, como suma de componentes, verás que estás hablando de vectores componentes, que son dos o más vectores cuya suma es ese vector dado.
Consejo: ¡mira este vídeo, que explica qué son los tensores con ayuda de sencillos objetos domésticos!
Junto a los vectores planos, también los covectores y los operadores lineales son otros dos casos que los tres juntos tienen una cosa en común: son casos específicos de tensores. Aún recuerdas cómo se caracterizó un vector en el apartado anterior como magnitudes escalares a las que se ha dado una dirección. Un tensor, por tanto, es la representación matemática de una entidad física que puede caracterizarse por su magnitud y múltiples direcciones.
Y, al igual que representas un escalar con un único número y un vector con una secuencia de tres números en un espacio de 3 dimensiones, por ejemplo, un tensor puede representarse mediante una matriz de 3R números en un espacio de 3 dimensiones.
La "R" de esta notación representa el rango del tensor: esto significa que en un espacio de 3 dimensiones, un tensor de segundo rango puede representarse por 3 a la potencia de 2 o 9 números. En un espacio de N dimensiones, los escalares seguirán necesitando un solo número, mientras que los vectores necesitarán N números y los tensores necesitarán N^R números. Esto explica por qué oyes a menudo que los escalares son tensores de rango 0: como no tienen dirección, puedes representarlos con un solo número.
Teniendo esto en cuenta, es relativamente fácil reconocer escalares, vectores y tensores y diferenciarlos: los escalares pueden representarse con un solo número, los vectores con un conjunto ordenado de números y los tensores con una matriz de números.
Lo que hace únicos a los tensores es la combinación de componentes y vectores base: los vectores base se transforman de una forma entre los sistemas de referencia y los componentes se transforman de tal forma que la combinación entre componentes y vectores base sigue siendo la misma.
Ahora que sabes más sobre TensorFlow, es hora de empezar e instalar la biblioteca. Aquí, es bueno saber que TensorFlow proporciona API para Python, C++, Haskell, Java, Go, Rust, y también hay un paquete de terceros para R llamado tensorflow.
Consejo: si quieres saber más sobre los paquetes de aprendizaje profundo en R, considera la posibilidad de consultar la página keras de DataCamp: Tutorial de Aprendizaje Profundo en R.
En este tutorial, descargarás una versión de TensorFlow que te permitirá escribir el código de tu proyecto de aprendizaje profundo en Python. En la página web de instalación de TensorFlow, verás algunas de las formas más comunes y las últimas instrucciones para instalar TensorFlow utilizando virtualenv, pip, Docker y, por último, también hay otras formas de instalar TensorFlow en tu ordenador personal.
Nota También puedes instalar TensorFlow con Conda si trabajas en Windows. Sin embargo, dado que la instalación de TensorFlow está respaldada por la comunidad, lo mejor es consultar las instrucciones de instalación oficiales.
Ahora que ya has pasado por el proceso de instalación, es hora de volver a comprobar que has instalado TensorFlow correctamente importándolo a tu espacio de trabajo con el alias tf:
import tensorflow as tfTen en cuenta que el alias que has utilizado en la línea de código anterior es una especie de convención: se utiliza para garantizar que mantienes la coherencia con otros desarrolladores que utilizan TensorFlow en proyectos de ciencia de datos, por un lado, y con proyectos TensorFlow de código abierto, por otro.
Generalmente escribirás programas TensorFlow, que ejecutarás como un chunk; Esto es a primera vista algo contradictorio cuando trabajas con Python. Sin embargo, si lo deseas, también puedes utilizar la Sesión Interactiva de TensorFlow, con la que puedes trabajar de forma más interactiva con la biblioteca. Esto es especialmente útil cuando estás acostumbrado a trabajar con IPython.
Para este tutorial, te centrarás en la segunda opción: te ayudará a iniciarte en el aprendizaje profundo con TensorFlow. Pero antes de seguir adelante con esto, vamos a probar algunas cosas menores antes de empezar con el trabajo pesado.
En primer lugar, importa la biblioteca tensorflow con el alias tf, como has visto en el apartado anterior. A continuación, inicializa dos variables que en realidad son constantes. Pasa una matriz de cuatro números a la función constant().
Ten en cuenta que también podrías pasar un número entero, pero que lo más habitual es que trabajes con matrices. Como has visto en la introducción, ¡los tensores tienen que ver con las matrices! Así que asegúrate de que pasas una matriz :) A continuación, puedes utilizar multiply() para multiplicar tus dos variables. Guarda el resultado en la variable result. Por último, imprime el result con ayuda de la función print().
Ten en cuenta que has definido constantes en el fragmento de código de DataCamp Light anterior. Sin embargo, hay otros dos tipos de valores que puedes utilizar potencialmente, a saber, los marcadores de posición, que son valores que no están asignados y que serán inicializados por la sesión cuando la ejecutes. Como el nombre ya delataba, es sólo un marcador de posición para un tensor que siempre se alimentará cuando se ejecute la sesión; También hay Variables, que son valores que pueden cambiar. Las constantes, como ya habrás deducido, son valores que no cambian.
El resultado de las líneas de código es un tensor abstracto en el gráfico de cálculo. Sin embargo, contrariamente a lo que cabría esperar, la result no se calcula realmente. Sólo definía el modelo, pero no se ejecutaba ningún proceso para calcular el resultado. Puedes verlo en la impresión: en realidad no hay un resultado que quieras ver (a saber, 30). ¡Esto significa que TensorFlow tiene una evaluación perezosa!
Sin embargo, si quieres ver el resultado, tienes que ejecutar este código en una sesión interactiva. Puedes hacerlo de varias maneras, como se demuestra en los trozos de código de DataCamp Light que aparecen a continuación:
Ten en cuenta que también puedes utilizar las siguientes líneas de código para iniciar una Sesión interactiva, ejecutar el result y volver a cerrar la Sesión automáticamente después de imprimir el output:
En los trozos de código anteriores acabas de definir una Sesión por defecto, pero también es bueno saber que puedes pasar opciones. Puedes, por ejemplo, especificar el argumento config y luego utilizar el búfer de protocolo ConfigProto para añadir opciones de configuración para tu sesión.
Por ejemplo, si añades
config=tf.ConfigProto(log_device_placement=True)a tu Sesión, asegúrate de que registras el dispositivo GPU o CPU que está asignado a una operación. A continuación, obtendrás información sobre qué dispositivos se utilizan en la sesión para cada operación. También podrías utilizar la siguiente sesión de configuración, por ejemplo, cuando utilices restricciones blandas para la colocación de dispositivos:
config=tf.ConfigProto(allow_soft_placement=True)Ahora que ya tienes TensorFlow instalado e importado en tu espacio de trabajo y has repasado los aspectos básicos del trabajo con este paquete, es hora de dejar esto a un lado por un momento y centrar tu atención en tus datos. Como siempre, primero te tomarás tu tiempo para explorar y comprender mejor tus datos antes de empezar a modelar tu red neuronal.
Aunque el tráfico es un tema generalmente conocido entre todos vosotros, no está de más repasar brevemente las observaciones que se incluyen en este conjunto de datos para ver si lo entiendes todo antes de empezar. En esencia, en esta sección te pondrás al día con los conocimientos de dominio que necesitas tener para avanzar en este tutorial.
Por supuesto, como soy belga, me aseguraré de que también tengas algunas anécdotas :)
Ahora que has reunido más información de fondo, es el momento de descargar el conjunto de datos aquí. Deberías obtener los dos archivos zip que aparecen junto a "BelgiumTS para Clasificación (imágenes recortadas), que se llaman "BelgiumTSC_Training" y "BelgiumTSC_Testing".
Consejo: si has descargado los archivos o vas a hacerlo después de completar este tutorial, ¡echa un vistazo a la estructura de carpetas de los datos que has descargado! Verás que las carpetas de datos de prueba, así como las de datos de entrenamiento, contienen 61 subcarpetas, que son los 62 tipos de señales de tráfico que utilizarás para la clasificación en este tutorial. Además, verás que los archivos tienen la extensión .ppm o Portable Pixmap Format. ¡Has descargado imágenes de las señales de tráfico!
Empecemos por importar los datos a tu espacio de trabajo. Empecemos con las líneas de código que aparecen debajo de la Función Definida por el Usuario (UDF) load_data():
ROOT_PATH. Esta ruta es aquella en la que has creado el directorio con tus datos de entrenamiento y de prueba.ROOT_PATH con ayuda de la función join(). Almacenas estas dos rutas específicas en train_data_directory y test_data_directory.load_data() y pasarle el train_data_directory.load_data() empieza reuniendo todos los subdirectorios que hay en train_data_directory; Lo hace con ayuda de la comprensión de listas, que es una forma bastante natural de construir listas - básicamente dice que, si encuentra algo en train_data_directory, comprobará si se trata de un directorio, y si lo es, lo añadirá a su lista. Recuerda que cada subdirectorio representa una etiqueta.labels y images. A continuación, reúne las rutas de los subdirectorios y los nombres de archivo de las imágenes que se almacenan en esos subdirectorios. Después, puedes reunir los datos de las dos listas con ayuda de la función append().def load_data(data_directory):
directories = [d for d in os.listdir(data_directory)
if os.path.isdir(os.path.join(data_directory, d))]
labels = []
images = []
for d in directories:
label_directory = os.path.join(data_directory, d)
file_names = [os.path.join(label_directory, f)
for f in os.listdir(label_directory)
if f.endswith(".ppm")]
for f in file_names:
images.append(skimage.data.imread(f))
labels.append(int(d))
return images, labels
ROOT_PATH = "/your/root/path"
train_data_directory = os.path.join(ROOT_PATH, "TrafficSigns/Training")
test_data_directory = os.path.join(ROOT_PATH, "TrafficSigns/Testing")
images, labels = load_data(train_data_directory)Observa que en el fragmento de código anterior, los datos de entrenamiento y de prueba se encuentran en carpetas llamadas "Entrenamiento" y "Pruebas", que son subdirectorios de otro directorio "Señales de tráfico". En una máquina local, podría ser algo así como "/Usuarios/Nombre/Descargas/SeñalesDeTráfico", con dos subcarpetas llamadas "Formación" y "Pruebas".
Consejo: repasa cómo escribir funciones en Python con el Tutorial de Funciones Python de DataCamp.
Una vez cargados los datos, ¡es hora de inspeccionarlos! Puedes empezar con un análisis bastante sencillo con ayuda de los atributos ndim y size de la matriz images:
Ten en cuenta que las variables images y labels son listas, por lo que puede que necesites utilizar np.array() para convertir las variables en una matriz en tu propio espacio de trabajo. ¡Aquí se ha hecho por ti!
Observa que el images[0] que imprimiste es, de hecho, ¡una sola imagen representada por matrices dentro de matrices! Esto puede parecer contraintuitivo al principio, pero es algo a lo que te acostumbrarás a medida que avances en el trabajo con imágenes en aplicaciones de aprendizaje automático o aprendizaje profundo.
A continuación, también puedes echar un pequeño vistazo a labels, pero no deberías ver demasiadas sorpresas en este punto:
Estas cifras ya te dan una idea del éxito de tu importación y del tamaño exacto de tus datos. A primera vista, todo se ha ejecutado como esperabas, y ves que el tamaño de la matriz es considerable si tienes en cuenta que estás tratando con matrices dentro de matrices.
Consejo Prueba a añadir los siguientes atributos a tus matrices para obtener más información sobre la disposición de la memoria, la longitud de un elemento de la matriz en bytes y el total de bytes consumidos por los elementos de la matriz con los atributos flags, itemsize y nbytes. ¡Puedes probarlo en la consola IPython en el trozo de DataCamp Light de arriba!
A continuación, también puedes echar un vistazo a la distribución de las señales de tráfico:
¡Un trabajo impresionante! ¡Ahora echemos un vistazo más de cerca al histograma que has hecho!
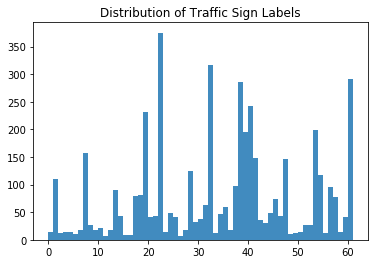
A primera vista, ves que hay etiquetas que están más presentes en el conjunto de datos que otras: las etiquetas 22, 32, 38 y 61 saltan definitivamente a la vista. Llegados a este punto, está bien tener esto en cuenta, ¡pero sin duda profundizarás en ello en la siguiente sección!
Los pequeños análisis o comprobaciones anteriores ya te han dado una idea de los datos con los que estás trabajando, pero cuando tus datos consisten principalmente en imágenes, el paso que debes dar para explorar tus datos es visualizarlos.
Veamos algunas señales de tráfico al azar:
pyplot del paquete matplotlib bajo el alias común plt.images que acabas de inspeccionar en la sección anterior. En este caso, eliges 300, 2250, 3650 y 4000.images que esté de acuerdo con el número del índice i. En el primer bucle, pasarás 300 a images[], en la segunda vuelta a 2250, y así sucesivamente. Por último, ajustarás las subparcelas para que haya suficiente anchura entre ellas.show()!Ahí lo tienes:
# Import the `pyplot` module of `matplotlib`
import matplotlib.pyplot as plt
# Determine the (random) indexes of the images that you want to see
traffic_signs = [300, 2250, 3650, 4000]
# Fill out the subplots with the random images that you defined
for i in range(len(traffic_signs)):
plt.subplot(1, 4, i+1)
plt.axis('off')
plt.imshow(images[traffic_signs[i]])
plt.subplots_adjust(wspace=0.5)
plt.show()Como habrás adivinado por las 62 etiquetas que se incluyen en este conjunto de datos, los signos son diferentes entre sí.
¿Pero qué más notas? Echa otro vistazo a las imágenes de abajo:

¡Estas cuatro imágenes no tienen el mismo tamaño!
Evidentemente, puedes juguetear con los números que figuran en la lista traffic_signs y profundizar en esta observación, pero sea como fuere, se trata de una observación importante que deberás tener en cuenta cuando empieces a trabajar más en la manipulación de tus datos para poder alimentar con ellos a la red neuronal.
Confirmemos la hipótesis de los diferentes tamaños imprimiendo la forma y los valores mínimo y máximo de las imágenes concretas que has incluido en las subparcelas.
El código siguiente se parece mucho al que utilizaste para crear el gráfico anterior, pero difiere en que aquí alternarás tamaños e imágenes en lugar de trazar sólo las imágenes una junto a otra:
# Import `matplotlib`
import matplotlib.pyplot as plt
# Determine the (random) indexes of the images
traffic_signs = [300, 2250, 3650, 4000]
# Fill out the subplots with the random images and add shape, min and max values
for i in range(len(traffic_signs)):
plt.subplot(1, 4, i+1)
plt.axis('off')
plt.imshow(images[traffic_signs[i]])
plt.subplots_adjust(wspace=0.5)
plt.show()
print("shape: {0}, min: {1}, max: {2}".format(images[traffic_signs[i]].shape,
images[traffic_signs[i]].min(),
images[traffic_signs[i]].max()))Observa cómo utilizas el método format() en la cadena "shape: {0}, min: {1}, max: {2}" para rellenar los argumentos {0}, {1} y {2} que has definido.

Ahora que has visto imágenes sueltas, puede que también quieras revisar el histograma que imprimiste en los primeros pasos de tu exploración de datos; puedes hacerlo fácilmente trazando un resumen de las 62 clases y una imagen que pertenezca a cada clase:
# Import the `pyplot` module as `plt`
import matplotlib.pyplot as plt
# Get the unique labels
unique_labels = set(labels)
# Initialize the figure
plt.figure(figsize=(15, 15))
# Set a counter
i = 1
# For each unique label,
for label in unique_labels:
# You pick the first image for each label
image = images[labels.index(label)]
# Define 64 subplots
plt.subplot(8, 8, i)
# Don't include axes
plt.axis('off')
# Add a title to each subplot
plt.title("Label {0} ({1})".format(label, labels.count(label)))
# Add 1 to the counter
i += 1
# And you plot this first image
plt.imshow(image)
# Show the plot
plt.show()Ten en cuenta que, aunque definas 64 subparcelas, no todas mostrarán imágenes (¡ya que sólo hay 62 etiquetas!). Observa también que, de nuevo, no incluyes ningún eje para asegurarte de que la atención de los lectores no se aleja del tema principal: ¡las señales de tráfico!

Como casi has adivinado en el histograma anterior, hay bastantes más señales de tráfico con las etiquetas 22, 32, 38 y 61. Esta hipótesis se confirma ahora en este gráfico: ves que hay 375 casos con la etiqueta 22, 316 casos con la etiqueta 32, 285 casos con la etiqueta 38 y, por último, 282 casos con la etiqueta 61.
Una de las preguntas más interesantes que podrías hacerte ahora es si existe una conexión entre todos estos casos, ¿quizás todos ellos sean signos designativos?
Veámoslo más de cerca: ves que las etiquetas 22 y 32 son señales prohibitorias, pero que las etiquetas 38 y 61 son señales designatorias y a priori, respectivamente. Esto significa que no hay una conexión inmediata entre estas cuatro, salvo por el hecho de que la mitad de las señales que tienen una presencia sustancial en el conjunto de datos es de tipo prohibitivo.

Ahora que has explorado a fondo tus datos, ¡es hora de ensuciarse las manos! Recapitulemos brevemente lo que has descubierto para asegurarnos de que no olvidas ningún paso en la manipulación:
Ahora que tienes una idea clara de lo que necesitas mejorar, puedes empezar a manipular tus datos de forma que estén listos para alimentar a la red neuronal o al modelo que quieras alimentar. Empecemos primero con la extracción de algunas características: reescalarás las imágenes y convertirás a escala de grises las imágenes contenidas en la matriz images. Harás esta conversión de color principalmente porque el color importa menos en preguntas de clasificación como la que intentas responder ahora. Para la detección, sin embargo, ¡el color juega un papel importante! Así que en esos casos, ¡no es necesario hacer esa conversión!
Para hacer frente a los diferentes tamaños de las imágenes, vas a reescalarlas; puedes hacerlo fácilmente con ayuda de la biblioteca skimage o Scikit-Image, que es una colección de algoritmos para el tratamiento de imágenes.
En este caso, el módulo transform te resultará útil, ya que te ofrece una función resize(); verás que utilizas la comprensión de listas (¡otra vez!) para cambiar el tamaño de cada imagen a 28 por 28 píxeles. Una vez más, verás que la forma en que realmente se forma la lista: por cada imagen que encuentres en la matriz images, realizarás la operación de transformación que tomes prestada de la biblioteca skimage. Por último, almacena el resultado en la variable images28:
# Import the `transform` module from `skimage`
from skimage import transform
# Rescale the images in the `images` array
images28 = [transform.resize(image, (28, 28)) for image in images]Ha sido bastante fácil, ¿verdad?
Observa que las imágenes tienen ahora cuatro dimensiones: si conviertes images28 en una matriz y le concatenas el atributo shape, verás que la impresión te dice que las dimensiones de images28son (4575, 28, 28, 3). Las imágenes tienen 784 dimensiones (porque tus imágenes tienen 28 por 28 píxeles).
Puedes comprobar el resultado de la operación de reescalado reutilizando el código que utilizaste anteriormente para trazar las 4 imágenes aleatorias con ayuda de la variable traffic_signs. No olvides cambiar todas las referencias a images por images28.
Comprueba el resultado aquí:

Fíjate en que, como has reescalado, tus valores min y max también han cambiado; ahora parecen estar todos en los mismos rangos, ¡lo cual es estupendo porque así no tienes que normalizar necesariamente tus datos!
Como se dijo en la introducción a esta sección del tutorial, el color de las imágenes importa menos cuando intentas responder a una pregunta de clasificación. Por eso también te tomarás la molestia de convertir las imágenes a escala de grises.
Sin embargo, ten en cuenta que también puedes probar por tu cuenta qué ocurriría con los resultados finales de tu modelo si no siguieras este paso específico.
Al igual que con el reescalado, puedes contar de nuevo con la ayuda de la biblioteca Scikit-Image; en este caso, es el módulo color con su función rgb2gray() el que tienes que utilizar para llegar a donde necesitas.
¡Eso va a ser muy fácil!
Sin embargo, no olvides volver a convertir la variable images28 en una matriz, ya que la función rgb2gray() espera una matriz como argumento.
# Import `rgb2gray` from `skimage.color`
from skimage.color import rgb2gray
# Convert `images28` to an array
images28 = np.array(images28)
# Convert `images28` to grayscale
images28 = rgb2gray(images28)Vuelve a comprobar el resultado de tu conversión a escala de grises trazando algunas de las imágenes; Aquí, puedes volver a reutilizar y adaptar ligeramente parte del código para mostrar las imágenes ajustadas:
import matplotlib.pyplot as plt
traffic_signs = [300, 2250, 3650, 4000]
for i in range(len(traffic_signs)):
plt.subplot(1, 4, i+1)
plt.axis('off')
plt.imshow(images28[traffic_signs[i]], cmap="gray")
plt.subplots_adjust(wspace=0.5)
# Show the plot
plt.show()Ten en cuenta que, efectivamente, tienes que especificar el mapa de color o cmap y configurarlo en "gray" para trazar las imágenes en escala de grises. Esto se debe a que imshow() utiliza, por defecto, un mapa de colores similar a un mapa de calor. Lee más aquí.

Consejo: ya que has estado reutilizando esta función bastante en este tutorial, podrías mirar cómo puedes convertirla en una función :)
Estos dos pasos son muy básicos; otras operaciones que podrías haber probado con tus datos incluyen el aumento de datos (rotar, desenfocar, desplazar, cambiar el brillo,...). Si quieres, también puedes configurar toda una cadena de operaciones de manipulación de datos a través de la cual envíes tus imágenes.
Ahora que ya has explorado y manipulado tus datos, ¡es hora de construir tu arquitectura de red neuronal con la ayuda del paquete TensorFlow!
Igual que has hecho con Keras, es hora de construir tu red neuronal, capa por capa.
Si aún no lo has hecho, importa tensorflow a tu espacio de trabajo con el alias convencional tf. A continuación, puedes inicializar el Gráfico con ayuda de Graph(). Utiliza esta función para definir el cálculo. Ten en cuenta que con el Gráfico no calculas nada, porque no contiene ningún valor. Sólo define las operaciones que quieres que se ejecuten más tarde.
En este caso, configuras un contexto por defecto con la ayuda de as_default(), que devuelve un gestor de contexto que hace que este Gráfico concreto sea el gráfico por defecto. Utiliza este método si quieres crear varios gráficos en el mismo proceso: con esta función, tienes un gráfico global por defecto al que se añadirán todas las operaciones si no creas explícitamente un nuevo gráfico.
A continuación, estás preparado para añadir operaciones a tu gráfico. Como recordarás de tu trabajo con Keras, construyes tu modelo y luego, al compilarlo, defines una función de pérdida, un optimizador y una métrica. Ahora todo esto ocurre en un solo paso cuando trabajas con TensorFlow:
run()!flatten(), que te dará una matriz de forma [None, 784] en lugar de la [None, 28, 28], que es la forma de tus imágenes en escala de grises.[None, 62]. Logits es la función que opera sobre la salida sin escalar de las capas anteriores, y que utiliza la escala relativa para entender que las unidades son lineales.sparse_softmax_cross_entropy_with_logits()reduce_mean(), que calcula la media de los elementos a través de las dimensiones de un tensor.0.001.# Import `tensorflow`
import tensorflow as tf
# Initialize placeholders
x = tf.placeholder(dtype = tf.float32, shape = [None, 28, 28])
y = tf.placeholder(dtype = tf.int32, shape = [None])
# Flatten the input data
images_flat = tf.contrib.layers.flatten(x)
# Fully connected layer
logits = tf.contrib.layers.fully_connected(images_flat, 62, tf.nn.relu)
# Define a loss function
loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(labels = y,
logits = logits))
# Define an optimizer
train_op = tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss)
# Convert logits to label indexes
correct_pred = tf.argmax(logits, 1)
# Define an accuracy metric
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))¡Ya has creado con éxito tu primera red neuronal con TensorFlow!
Si quieres, también puedes imprimir los valores de (la mayoría de) las variables para obtener una rápida recapitulación o comprobación de lo que acabas de codificar:
print("images_flat: ", images_flat)
print("logits: ", logits)
print("loss: ", loss)
print("predicted_labels: ", correct_pred)Consejo: si ves un error como "module 'pandas' has no attribute 'computation'", considera la posibilidad de actualizar los paquetes dask ejecutando pip install --upgrade dask en tu línea de comandos. Consulta este post de StackOverflow para obtener más información.
Ahora que has construido tu modelo capa por capa, ¡es hora de ejecutarlo! Para ello, primero tienes que inicializar una sesión con la ayuda de Session() a la que puedes pasar tu graph que definiste en el apartado anterior. A continuación, puedes ejecutar la sesión con run(), a la que pasarás las operaciones inicializadas en forma de la variable init que también definiste en el apartado anterior.
A continuación, puedes utilizar esta sesión inicializada para iniciar épocas o bucles de entrenamiento. En este caso, eliges 201 porque quieres poder registrar el último loss_value; En el bucle, ejecutas la sesión con el optimizador de entrenamiento y la métrica de pérdida (o precisión) que definiste en la sección anterior. También pasas un argumento feed_dict, con el que introduces datos en el modelo. Después de cada 10 épocas, obtendrás un registro que te dará más información sobre la pérdida o el coste del modelo.
Como has visto en la sección sobre los fundamentos de TensorFlow, no es necesario cerrar la sesión manualmente; esto se hace por ti. Sin embargo, si quieres probar una configuración diferente, probablemente tendrás que hacerlo con sess.close() si has definido tu sesión como sess, como en el trozo de código siguiente:
tf.set_random_seed(1234)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
for i in range(201):
print('EPOCH', i)
_, accuracy_val = sess.run([train_op, accuracy], feed_dict={x: images28, y: labels})
if i % 10 == 0:
print("Loss: ", loss)
print('DONE WITH EPOCH')Recuerda que también puedes ejecutar el siguiente trozo de código, pero ése cerrará inmediatamente la sesión después, tal y como viste en la introducción de este tutorial:
tf.set_random_seed(1234)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(201):
_, loss_value = sess.run([train_op, loss], feed_dict={x: images28, y: labels})
if i % 10 == 0:
print("Loss: ", loss)Ten en cuenta que utilizas global_variables_initializer() porque la función initialize_all_variables() está obsoleta.
¡Ya has entrenado con éxito a tu modelo! No ha sido tan difícil, ¿verdad?
Aún no has llegado del todo; todavía tienes que evaluar tu red neuronal. En este caso, ya puedes intentar hacerte una idea de lo bien que funciona tu modelo eligiendo 10 imágenes al azar y comparando las etiquetas predichas con las etiquetas reales.
Primero puedes imprimirlas, pero ¿por qué no utilizar matplotlib para trazar las propias señales de tráfico y hacer una comparación visual?
# Import `matplotlib`
import matplotlib.pyplot as plt
import random
# Pick 10 random images
sample_indexes = random.sample(range(len(images28)), 10)
sample_images = [images28[i] for i in sample_indexes]
sample_labels = [labels[i] for i in sample_indexes]
# Run the "correct_pred" operation
predicted = sess.run([correct_pred], feed_dict={x: sample_images})[0]
# Print the real and predicted labels
print(sample_labels)
print(predicted)
# Display the predictions and the ground truth visually.
fig = plt.figure(figsize=(10, 10))
for i in range(len(sample_images)):
truth = sample_labels[i]
prediction = predicted[i]
plt.subplot(5, 2,1+i)
plt.axis('off')
color='green' if truth == prediction else 'red'
plt.text(40, 10, "Truth: {0}\nPrediction: {1}".format(truth, prediction),
fontsize=12, color=color)
plt.imshow(sample_images[i], cmap="gray")
plt.show()
Sin embargo, mirar sólo imágenes aleatorias no te da muchas pistas sobre el rendimiento real de tu modelo. Por eso cargarás los datos de prueba.
Ten en cuenta que utilizas la función load_data(), que definiste al principio de este tutorial.
# Import `skimage`
from skimage import transform
# Load the test data
test_images, test_labels = load_data(test_data_directory)
# Transform the images to 28 by 28 pixels
test_images28 = [transform.resize(image, (28, 28)) for image in test_images]
# Convert to grayscale
from skimage.color import rgb2gray
test_images28 = rgb2gray(np.array(test_images28))
# Run predictions against the full test set.
predicted = sess.run([correct_pred], feed_dict={x: test_images28})[0]
# Calculate correct matches
match_count = sum([int(y == y_) for y, y_ in zip(test_labels, predicted)])
# Calculate the accuracy
accuracy = match_count / len(test_labels)
# Print the accuracy
print("Accuracy: {:.3f}".format(accuracy))Recuerda cerrar la sesión con sess.close() en caso de que no hayas utilizado with tf.Session() as sess: para iniciar tu sesión TensorFlow.
Si quieres seguir trabajando con este conjunto de datos y el modelo que has elaborado en este tutorial, prueba lo siguiente:
No dejes de consultar el libro Aprendizaje automático con TensorFlow, escrito por Nishant Shukla.
Consejo: consulta también el TensorFlow Playground y el TensorBoard.
Si quieres seguir trabajando con imágenes, echa un vistazo al tutorial scikit-learn de DataCamp, que aborda el conjunto de datos MNIST con la ayuda de PCA, K-Means y Support Vector Machines (SVM). O echa un vistazo a otros tutoriales, como éste que utiliza el conjunto de datos de señales de tráfico belgas.
Más información sobre Python y el Aprendizaje Profundo
Curso
Curso
Curso
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Bex Tuychiev
Tutorial
Bharath K

