programa
Keras Fundamentals
16 h
Las redes neuronales profundas han cambiado el panorama de la inteligencia artificial en la era moderna. En los últimos tiempos, se han producido varios avances en la investigación, tanto en el aprendizaje profundo como en las redes neuronales, que aumentan drásticamente la calidad de los proyectos relacionados con la inteligencia artificial.
Estas redes neuronales profundas ayudan a los desarrolladores a conseguir resultados más sostenibles y de mayor calidad. De ahí que incluso estén sustituyendo a varias técnicas convencionales de machine learning.
Pero ¿qué son exactamente las redes neuronales profundas y por qué son la opción óptima para una amplia gama de tareas? ¿Y cuáles son las distintas bibliotecas y herramientas para iniciarse en las redes neuronales profundas?
Este artículo explicará las redes neuronales profundas, sus requisitos de biblioteca y cómo construir una arquitectura básica de red neuronal profunda desde cero.
El objetivo de una red neuronal artificial (ANN) o una red neuronal tradicional sencilla es resolver tareas triviales con un esquema de red sencillo. Una red neuronal artificial se inspira libremente en las redes neuronales biológicas. Es un conjunto de capas para realizar una tarea específica. Cada capa está formada por un conjunto de nodos que funcionan juntos.
Estas redes suelen constar de una capa de entrada, una o dos capas ocultas y una capa de salida. Aunque es posible resolver cuestiones matemáticas fáciles y problemas informáticos, incluidas estructuras básicas de puerta con sus respectivas tablas de verdad, es difícil que estas redes resuelvan tareas complicadas de procesamiento de imágenes, visión artificial y procesamiento de lenguaje natural.
Para estos problemas, utilizamos redes neuronales profundas, que suelen tener una estructura compleja de capas ocultas con una gran variedad de capas diferentes, como una capa convolucional, una capa de max-pooling, una capa densa y otras capas únicas. Estas capas adicionales ayudan al modelo a comprender mejor los problemas y a proporcionar soluciones óptimas a proyectos complejos. Una red neuronal profunda tiene más capas (más profundidad) que una ANN y cada capa añade complejidad al modelo, al mismo tiempo que permite a dicho modelo procesar las entradas de forma concisa para proporcionar la solución ideal.
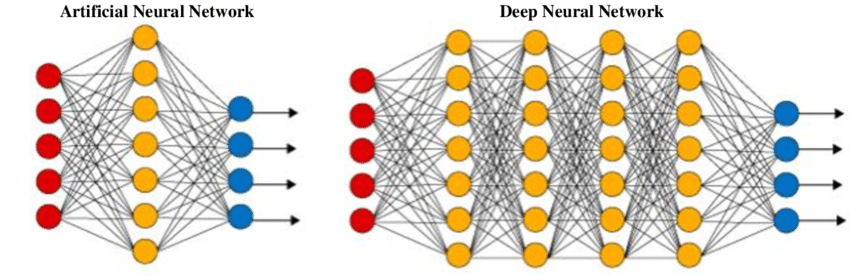
ANN frente a DNN - Fuente de la imagen
Las redes neuronales profundas han conseguido mucho terreno debido a su gran eficiencia en la consecución de numerosas variedades de proyectos de aprendizaje profundo. Explora las diferencias entre machine learning y aprendizaje profundo en otro artículo.
Tras entrenar una red neuronal profunda bien construida, puede conseguir los resultados deseados con altas puntuaciones de exactitud. Son populares en todos los aspectos del aprendizaje profundo, lo que incluye la visión artificial, el procesamiento de lenguaje natural y el aprendizaje por transferencia.
Los principales ejemplos del protagonismo de las redes neuronales profundas son su utilidad en la detección de objetos con modelos como YOLO (You Only Look Once), tareas de traducción de idiomas con modelos BERT (Bidirectional Encoder Representations from Transformers), modelos de aprendizaje por transferencia, como VGG-19, RESNET-50, EfficientNet y otras redes similares para proyectos de procesamiento de imágenes.
Para comprender estos conceptos de aprendizaje profundo de la inteligencia artificial de forma más intuitiva, te recomiendo que eches un vistazo al curso Aprendizaje profundo en Python de DataCamp.
Construir redes neuronales desde cero ayuda a los programadores a comprender conceptos y resolver tareas triviales manipulando estas redes. Sin embargo, construir estas redes desde cero lleva mucho tiempo y requiere un enorme esfuerzo. Para simplificar el aprendizaje profundo, tenemos varias herramientas y bibliotecas a nuestra disposición para producir un modelo eficaz de red neuronal profunda capaz de resolver problemas complejos con unas cuantas líneas de código.
Las bibliotecas y herramientas de aprendizaje profundo más populares utilizadas para construir redes neuronales profundas son TensorFlow, Keras y PyTorch. Las bibliotecas Keras y TensorFlow se han integrado desde el inicio de TensorFlow 2.0. Esta integración permite a los usuarios desarrollar redes neuronales complejas con estructuras de código generales utilizando Keras en la red TensorFlow.
La biblioteca PyTorch es otro marco de machine learning muy popular que permite a los usuarios desarrollar proyectos de investigación generales.
Aunque cojea ligeramente en visualización, PyTorch lo compensa con su rendimiento compacto y rápido, con instalaciones de GPU relativamente más rápidas y sencillas para construir modelos de redes neuronales profundas.
El curso Introducción a PyTorch en Python de DataCamp es el mejor punto de partida para aprender más sobre PyTorch.
El marco TensorFlow ofrece a sus desarrolladores una amplia gama de fantásticas opciones de herramientas de visualización para tareas de aprendizaje profundo. El panel gráfico tensorboard presenta una opción excepcional para visualizar, analizar e interpretar adecuadamente los datos y resultados de un proyecto.
La integración de la biblioteca Keras permite una construcción más rápida de proyectos con estructuras de código sencillas, por lo que es una opción popular para proyectos de desarrollo a largo plazo. Introducción a TensorFlow en Python es un gran lugar para que los principiantes se inicien en TensorFlow.
En esta sección, comprenderemos algunos conceptos fundamentales de las redes neuronales profundas y cómo construir una red de este tipo desde cero.
El primer paso es elegir tu biblioteca preferida para la aplicación requerida. Utilizaremos los marcos de aprendizaje profundo TensorFlow y Keras para construir la red neuronal profunda.
# Importing the necessary functionality
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Input, Dense, Conv2D
from tensorflow.keras.layers import Flatten, MaxPooling2DUna vez que terminemos de importar las bibliotecas deseadas para esta tarea, utilizaremos el modelo de tipo secuencial para construir el modelo de aprendizaje profundo. El modelo secuencial es una sencilla pila de capas con un valor de entrada y salida. Las otras opciones disponibles son la clase de API funcional o la construcción de un modelo personalizado. Sin embargo, la clase secuencial proporciona un enfoque sencillo para construir la arquitectura de la red neuronal.
# Creating the model
DNN_Model = Sequential()
Añadiremos una forma de entrada, normalmente equivalente al tamaño del tipo de imagen que utilices en tu proyecto. El tamaño contiene la anchura, la altura y la codificación de color de la imagen. En el código de ejemplo siguiente, la altura y la anchura de la imagen son 256 con un esquema de color RGB, representado por 3 (se utiliza 1 para las imágenes en escala de grises). A continuación, construiremos las capas ocultas necesarias con capas convolucionales y de max-pooling con distintos tamaños de filtro. Por último, utilizaremos una capa aplanada para aplanar las salidas y utilizaremos una capa densa como capa de salida final.
Las capas ocultas aumentan la complejidad de la red neuronal. Una capa convolucional realiza una operación de convolución sobre las imágenes visuales para filtrar la información. Cada tamaño de filtro de una capa convolucional ayuda a extraer características específicas de la entrada. Una capa de max-pooling ayuda a reducir el número de características considerando los valores máximos de las características extraídas.
Una capa aplanada reduce las dimensiones espaciales a una sola dimensión para una computación más rápida. Una capa densa es la capa más sencilla que recibe una salida de las capas anteriores y suele utilizarse como capa de salida. La convolución 2D aplica un producto de Hadamard sobre una entrada 2D. La función de activación de unidad lineal rectificada (ReLU) proporciona no linealidad al modelo para mejorar el rendimiento de la computación. Utilizaremos el mismo relleno para mantener las formas de entrada y salida de las capas convolucionales.
# Inputting the shape to the model
DNN_Model.add(Input(shape = (256, 256, 3)))
# Creating the deep neural network
DNN_Model.add(Conv2D(256, (3, 3), activation='relu', padding = "same"))
DNN_Model.add(MaxPooling2D(2, 2))
DNN_Model.add(Conv2D(128, (3, 3), activation='relu', padding = "same"))
DNN_Model.add(MaxPooling2D(2, 2))
DNN_Model.add(Conv2D(64, (3, 3), activation='relu', padding = "same"))
DNN_Model.add(MaxPooling2D(2, 2))
# Creating the output layers
DNN_Model.add(Flatten())
DNN_Model.add(Dense(64, activation='relu'))
DNN_Model.add(Dense(10))A continuación se presentan la estructura del modelo y el gráfico de la red neuronal profunda construida.
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_5 (Conv2D) (None, 256, 256, 256) 7168
max_pooling2d_5 (MaxPooling (None, 128, 128, 256) 0
2D)
conv2d_6 (Conv2D) (None, 128, 128, 128) 295040
max_pooling2d_6 (MaxPooling (None, 64, 64, 128) 0
2D)
conv2d_7 (Conv2D) (None, 64, 64, 64) 73792
max_pooling2d_7 (MaxPooling (None, 32, 32, 64) 0
2D)
flatten_2 (Flatten) (None, 65536) 0
dense_4 (Dense) (None, 64) 4194368
dense_5 (Dense) (None, 10) 650
=================================================================
Total params: 4,571,018
Trainable params: 4,571,018
Non-trainable params: 0
_________________________________________________________________El gráfico es el siguiente:
tf.keras.utils.plot_model(DNN_Model, to_file='model_big.png', show_shapes=True)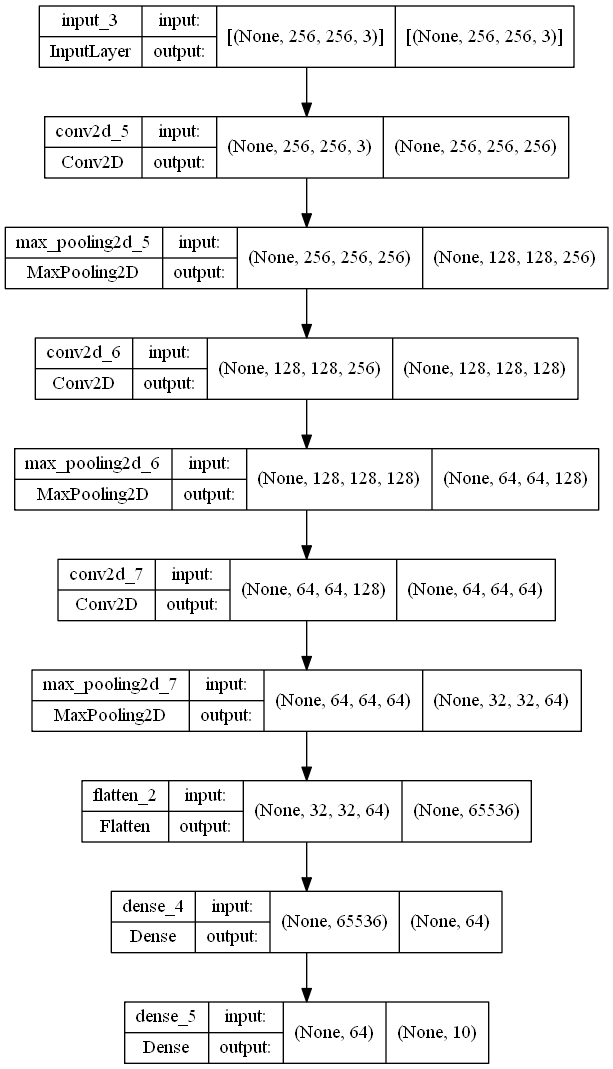
Flujo de trabajo de machine learning - Fuente de la imagen
Una vez construido el modelo, hay que compilarlo para configurarlo. Durante la compilación del modelo, las operaciones significativas en los modelos de aprendizaje profundo son la propagación hacia delante y la propagación hacia atrás. En la propagación hacia delante, toda la información esencial pasa por los distintos nodos hasta la capa de salida. En la capa de salida, para las tareas de clasificación, se computan los valores previstos y los valores verdaderos según corresponda.
En la etapa de entrenamiento o ajuste, se produce el proceso de propagación hacia atrás. Los pesos se reajustan en cada capa fijando los pesos hasta que los valores previstos y los valores verdaderos se aproximen entre sí para conseguir los resultados deseados. Para una explicación en profundidad de este tema, recomiendo consultar la siguiente guía sobre propagación hacia atrás del curso Introducción al aprendizaje profundo en Python.
Explorar el aprendizaje profundo tiene muchas complejidades. Recomiendo encarecidamente consultar el curso Aprendizaje profundo con Keras para comprender mejor cómo construir redes neuronales profundas.
La computación de cualquier tarea concreta de machine learning requiere una red neuronal profunda específica para realizar las acciones necesarias. Dos modelos de aprendizaje profundo utilizados principalmente son las redes neuronales convolucionales (CNN) y las redes neuronales recurrentes (RNN). Las redes neuronales convolucionales tienen enorme utilidad en proyectos de procesamiento de imágenes y visión artificial.
En estas redes neuronales profundas, en lugar de realizar una operación matricial típica en las capas ocultas, realizamos una operación de convolución. Permite que la red tenga un enfoque más escalable que produzca una mayor eficiencia y unos resultados exactos. En las tareas de clasificación de imágenes y detección de objetos, hay muchos datos e imágenes que el modelo debe computar. Estas redes neuronales convolucionales ayudan a combatir estos problemas con éxito.
En proyectos de procesamiento de lenguaje natural y semánticos, a menudo se utilizan redes neuronales recurrentes para optimizar los resultados. Una variante popular de estas RNN, la memoria larga a corto plazo (LSTM), se suele utilizar para realizar diversas tareas de traducción automática, clasificación de textos, reconocimiento del habla y otras tareas similares.
Estas redes transportan la información esencial de cada una de las celdas anteriores y la transmiten a la siguiente, al mismo tiempo que almacenan la información crucial para optimizar el rendimiento del modelo. Redes neuronales convolucionales para el procesamiento de imágenes es una guía fantástica para profundizar en las CNN, y Aprendizaje profundo en Python permite comprender perfectamente el aprendizaje profundo.
Tenemos un somero conocimiento de las redes neuronales profundas y de su construcción con el marco de aprendizaje profundo TensorFlow. Sin embargo, hay ciertos retos que todo desarrollador debe tener en cuenta antes de desarrollar una red neuronal para un proyecto concreto. Veamos algunos de estos retos.
Uno de los principales requisitos del aprendizaje profundo son los datos. Los datos son el componente más crítico para construir un modelo de gran exactitud. En varios casos, las redes neuronales profundas suelen necesitar grandes cantidades de datos para impedir el sobreajuste y obtener buenos resultados. Los requisitos de datos para las tareas de detección de objetos pueden requerir más datos para que un modelo detecte distintos objetos con gran exactitud.
Aunque las técnicas de aumento de datos son útiles como solución rápida a algunos de estos problemas, los requisitos de datos son algo que hay que tener en cuenta en todo proyecto de aprendizaje profundo.
Además de la gran cantidad de datos, también hay que tener en cuenta el elevado coste computacional de la red neuronal profunda. Modelos como Generative Pre-trained Transformer 3 (GPT-3) tienen 175 000 millones de parámetros, por ejemplo.
La compilación y el entrenamiento de modelos para tareas complejas requerirá una GPU con recursos. A menudo, los modelos pueden entrenarse de forma más eficiente en GPU o TPU que en CPU. Para tareas extremadamente complejas, los requisitos del sistema son más elevados, lo que requiere más recursos para una tarea concreta.
Durante el entrenamiento, el modelo también puede encontrarse con problemas como el subajuste o el sobreajuste. El subajuste suele producirse debido a una falta de datos, mientras que el sobreajuste es un problema más importante que se produce debido a que los datos de entrenamiento mejoran constantemente y los datos de prueba permanecen constantes. Por tanto, la exactitud del entrenamiento es alta, pero la exactitud de validación es baja, lo que da lugar a un modelo muy inestable que no da los mejores resultados.
En este artículo, hemos explorado las redes neuronales profundas y comprendido sus conceptos básicos. Hemos comprendido la diferencia entre estas redes neuronales y una red tradicional y hemos comprendido los diferentes tipos de marcos de aprendizaje profundo para la computación de proyectos de aprendizaje profundo. A continuación, hemos utilizado las bibliotecas TensorFlow y Keras para demostrar la construcción de una red neuronal profunda. Por último, hemos tenido en cuenta algunos de los retos críticos del aprendizaje profundo y algunos métodos para superarlos.
Las redes neuronales profundas son un recurso fantástico para la mayoría de los proyectos y aplicaciones comunes de inteligencia artificial. Nos permiten resolver tareas de procesamiento de imágenes y de procesamiento de lenguaje natural con gran exactitud.
Es importante que todos los desarrolladores cualificados se mantengan al día de las tendencias emergentes, ya que un modelo que es popular hoy puede no serlo tanto o no ser la mejor opción en un futuro próximo.
Por tanto, es esencial seguir aprendiendo y adquiriendo conocimientos, ya que el mundo de la inteligencia artificial es una aventura llena de emoción y nuevos avances tecnológicos. Una de las mejores formas de estar al día es consultar el programa de competencias Aprendizaje profundo en Python de DataCamp, que trata temas como TensorFlow y Keras, y Aprendizaje profundo en PyTorch, para aprender más sobre PyTorch. También puedes consultar los cursos Fundamentos de la IA para una introducción más suave. El primero ayuda a liberar el enorme potencial de los proyectos de aprendizaje profundo, mientras que el último ayuda a estabilizar los cimientos.
¡Aprende sobre los temas mencionados en este tutorial!
programa
Curso
Curso
Tutorial
Zoumana Keita
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan


