
Curso
Machine learning con modelos basados en árboles en Python
5 h
116.5K
Los métodos de conjunto son potentes técnicas de aprendizaje automático que combinan varios modelos para mejorar la precisión general de la predicción y la estabilidad del modelo. La Agregación de Bootstrap, más conocida como Bagging, destaca como un método de conjunto popular y ampliamente implementado.
En este tutorial, profundizaremos en el embolsado, cómo funciona y dónde brilla. Lo compararemos con otro método ensemble (Boosting) y veremos un ejemplo de bagging en Python. Al final, tendrás una sólida comprensión del embolsado, incluidas las mejores prácticas.
El modelado conjunto es una técnica que combina múltiples modelos de aprendizaje automático para mejorar el rendimiento predictivo global. La idea básica es que un grupo de alumnos débiles puede unirse para formar un alumno fuerte.
Un modelo de conjunto suele constar de dos pasos:
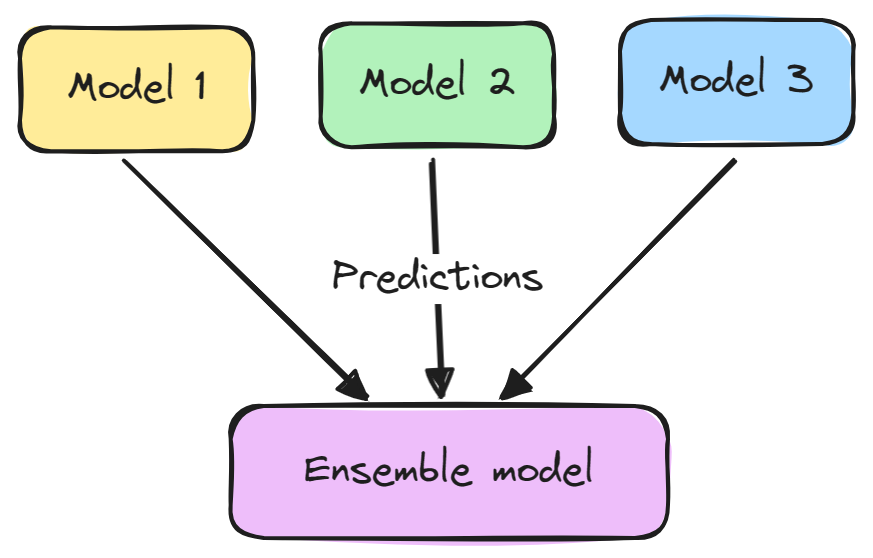
Los conjuntos suelen dar mejores resultados porque los distintos modelos se complementan entre sí y superan sus debilidades individuales. También reducen la varianza y evitan el sobreajuste.
Algunos métodos populares de ensamblaje son el ensacado, el refuerzo y el apilamiento. El aprendizaje conjunto se utiliza ampliamente en tareas de aprendizaje automático como la clasificación, la regresión y la agrupación para mejorar la precisión y la solidez.
El ensamblaje (agregación bootstrap) es un método de conjunto que consiste en entrenar varios modelos de forma independiente en subconjuntos aleatorios de los datos, y agregar sus predicciones mediante votación o promediación.
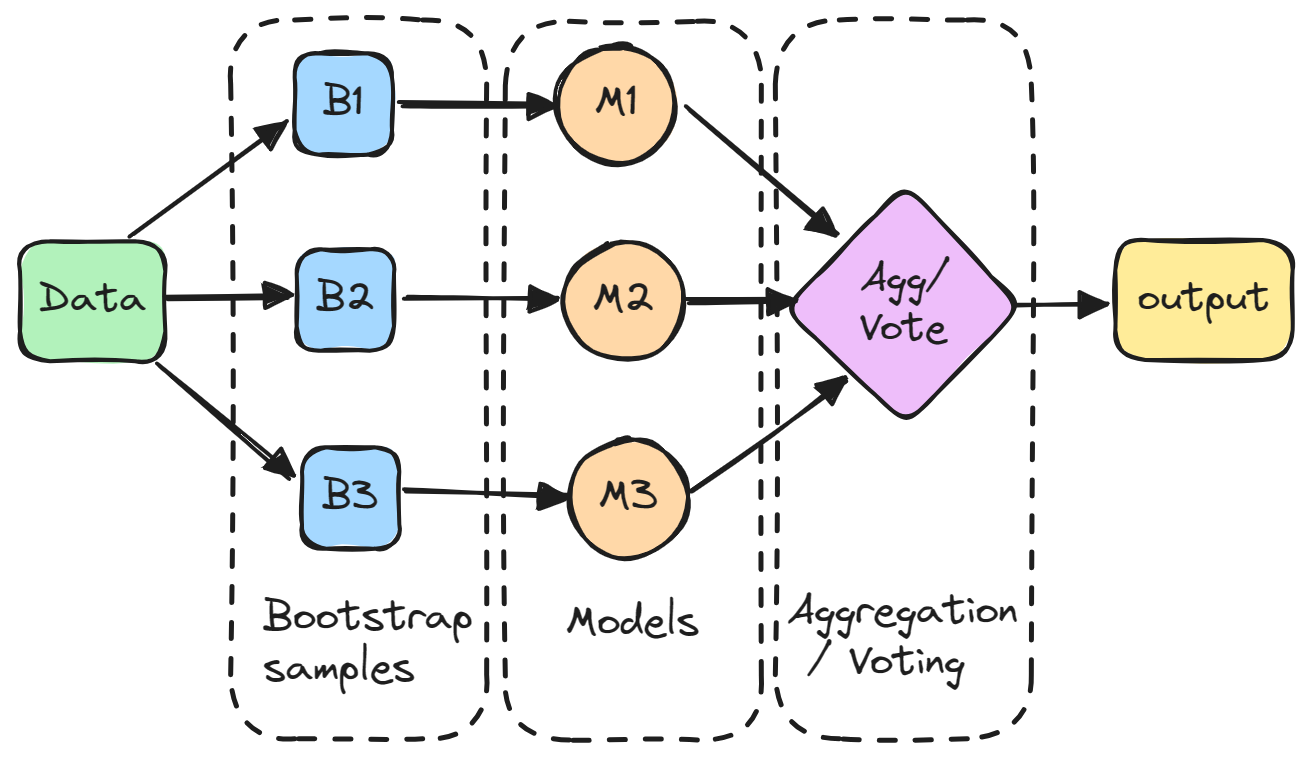
En detalle, cada modelo se entrena en un subconjunto aleatorio de los datos muestreados con reemplazo, lo que significa que los puntos de datos individuales pueden elegirse más de una vez. Este subconjunto aleatorio se conoce como muestra bootstrap. Al entrenar los modelos en diferentes bootstraps, el bagging reduce la varianza de los modelos individuales. También evita el sobreajuste exponiendo los modelos constituyentes a diferentes partes del conjunto de datos.
A continuación, las predicciones de todos los modelos muestreados se combinan mediante un simple promedio para hacer la predicción global. De este modo, el modelo agregado incorpora los puntos fuertes de los individuales y anula sus errores.
El ensacado es especialmente eficaz para reducir la varianza y el sobreajuste, haciendo que el modelo sea más robusto y preciso, sobre todo en los casos en que los modelos individuales son propensos a una gran variabilidad.
El Boosting es otro método de conjunto popular que a menudo se compara con el Bagging. La principal diferencia radica en cómo se entrenan los modelos constituyentes.
En el bagging, los modelos se entrenan independientemente en paralelo en diferentes subconjuntos aleatorios de los datos. Mientras que en el boosting, los modelos se entrenan secuencialmente, y cada modelo aprende de los errores del anterior. Además, el ensacado suele implicar un simple promedio de modelos, mientras que el refuerzo asigna pesos en función de la precisión.
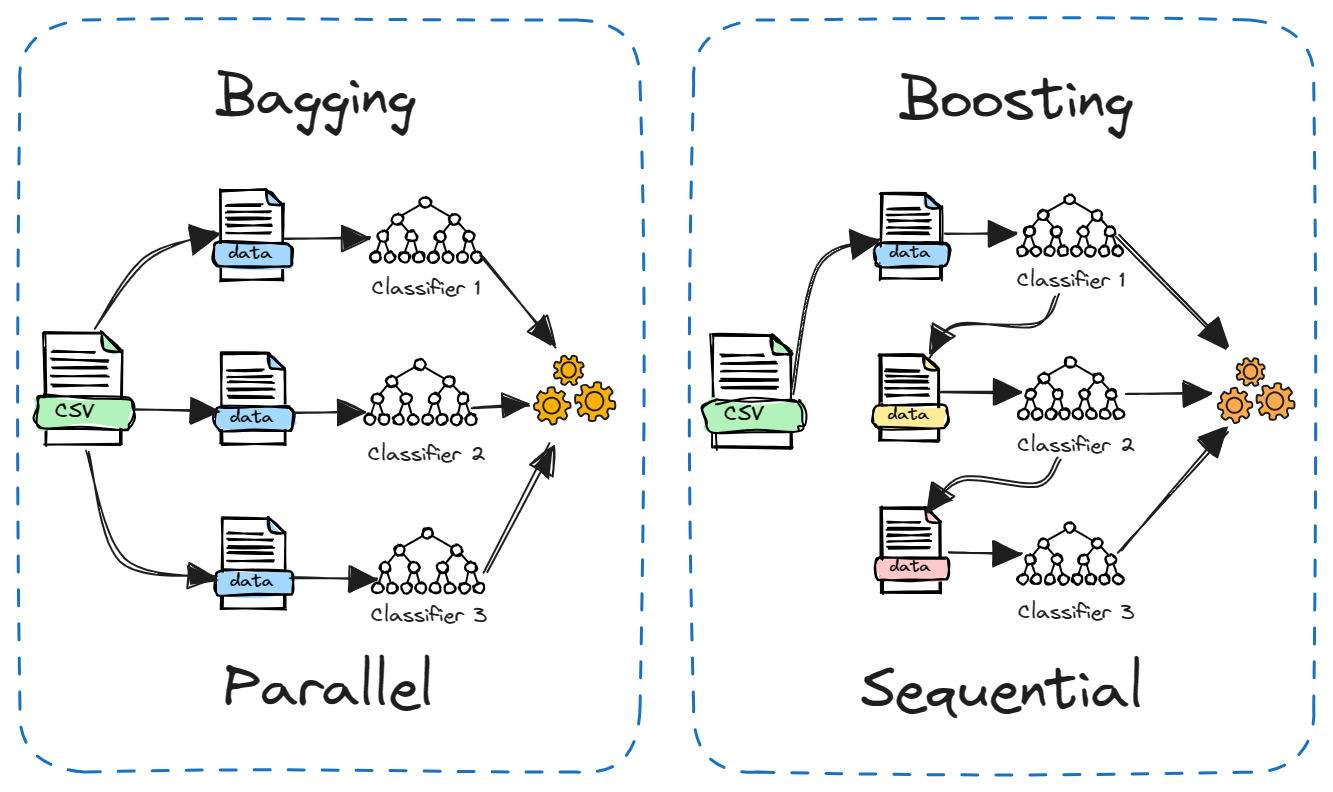
El ensacado reduce la varianza, mientras que el refuerzo reduce el sesgo. El ensacado puede utilizarse con modelos inestables como los árboles de decisión, mientras que el reforzamiento funciona mejor con modelos estables como la regresión lineal.
Ambos métodos tienen sus puntos fuertes y débiles. El ensacado es más sencillo de ejecutar en paralelo, mientras que el refuerzo puede ser más potente y preciso. En la práctica, ayuda probar ambos en un problema nuevo para ver cuál funciona mejor.
He aquí algunas ventajas clave del ensacado:
En este tutorial de Python, entrenaremos un modelo de clasificación de árbol de decisión en un conjunto de datos de rotación de clientes de telecomunicaciones y utilizaremos el método de ensamblaje de bolsas para mejorar el rendimiento. Utilizaremos DataLab para obtener el conjunto de datos y ejecutar nuestro código. El código también está disponible en este libro de trabajo de DataLab, que puedes copiar para ejecutarlo en tu navegador sin instalar nada.
El conjunto de datos sobre la rotación de clientes de telecomunicaciones procede de una empresa de telecomunicaciones iraní. Cada fila del conjunto de datos corresponde a la actividad de un cliente a lo largo de un año, e incluye información sobre fallos en las llamadas, duración de la suscripción y una etiqueta de abandono que indica si el cliente ha dejado el servicio.
En primer lugar, cargaremos el conjunto de datos y veremos las 5 filas superiores.
import pandas as pd
customer = pd.read_csv("data/customer_churn.csv")
customer.head()
Después, crearemos variables independientes (X) y dependientes (y). A continuación, dividiremos el conjunto de datos en subconjuntos de entrenamiento y de prueba.
X = customer.drop("Churn", axis=1)
y = customer.Churn
# Split into train and test
from sklearn.model_selection import train_test_split, cross_val_score
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)Crearemos una cadena sencilla de aprendizaje automático y le aplicaremos un conjunto de datos de entrenamiento. La tubería normalizará los datos antes de alimentar las entradas al clasificador del árbol de decisión.
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
pipeline = Pipeline([
('scaler', StandardScaler()),
('classifier', DecisionTreeClassifier(random_state=42))
])
pipeline.fit(X_train, y_train)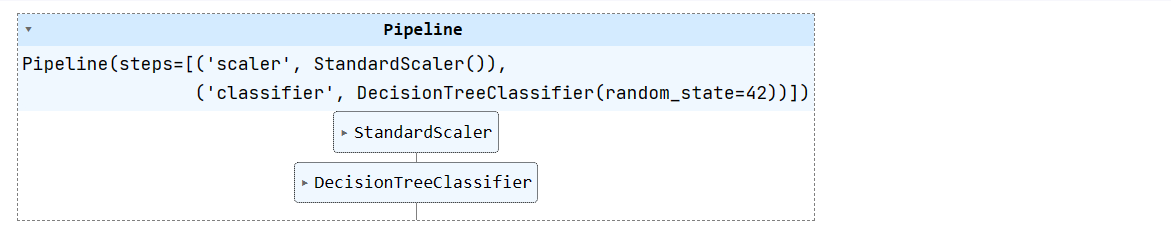
Realiza el curso Aprendizaje automático con modelos basados en árboles en Python para aprender a utilizar modelos basados en árboles y conjuntos para regresión y clasificación con scikit-learn.
Evaluaremos un modelo de árbol de decisión para poder compararlo con el modelo de conjunto.
Generaremos informes de clasificación haciendo predicciones en una hoja de datos de pruebas.
from sklearn.metrics import classification_report
# Make prediction on the testing data
y_pred = pipeline.predict(X_test)
# Classification Report
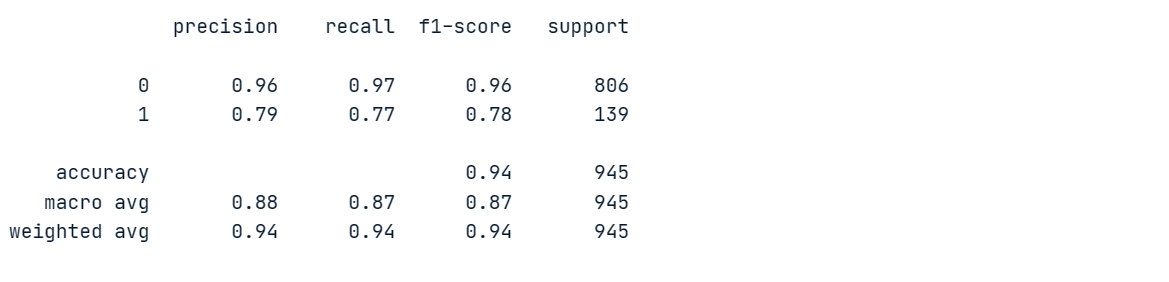
print(classification_report(y_pred, y_test))Nuestro modelo alcanzó un 96% de precisión y un 97% de recuperación en la clase mayoritaria "0", pero obtuvo malos resultados en la clase minoritaria "1".
Para conocer mejor el rendimiento del modelo, realizaremos una validación cruzada y calcularemos las puntuaciones correspondientes.
# Evaluate the classifier using cross-validation
cv_scores = cross_val_score(pipeline, X, y, cv=5)
print(f"Cross-validation scores: {cv_scores}")
print(f"Mean CV accuracy: {np.mean(cv_scores):.2f}")Hay una gran variación en las puntuaciones, con máximos del 95% y mínimos del 92%.
Cross-validation scores: [0.95079365 0.94126984 0.93492063 0.94285714 0.92222222]
Mean CV accuracy: 0.94Ahora, vamos a crear un clasificador bagging utilizando un estimador base como nuestro pipeline (clasificador escalar + árbol de decisión) y entrenarlo en un conjunto de datos de entrenamiento.
Podemos mejorar el rendimiento del modelo aumentando n_estimators, pero 50 es suficiente para los resultados de referencia.
from sklearn.ensemble import BaggingClassifier
# Create a bagging classifier with the decision tree pipeline
bagging_classifier = BaggingClassifier(base_estimator=pipeline, n_estimators=50, random_state=42)
# Train the bagging classifier on the training data
bagging_classifier.fit(X_train, y_train)
Evaluemos los resultados del modelo conjunto y comparémoslos con el rendimiento del modelo único. Para ello, generaremos informes de clasificación sobre un conjunto de datos de prueba.
# Make prediction on the testing data
y_pred = bagging_classifier.predict(X_test)
# Classification Report
print(classification_report(y_pred, y_test))Como puedes ver, hemos mejorado comparativamente el rendimiento del modelo. La precisión y el recuerdo de la clase minoritaria han aumentado del 79% al 80% y del 77% al 82%, respectivamente. Esto representa una mejora significativa.
Calculemos ahora la puntuación de validación cruzada.
# Evaluate the classifier using cross-validation
cv_scores = cross_val_score(bagging_classifier, X, y, cv=5)
print(f"Cross-validation scores: {cv_scores}")
print(f"Mean CV accuracy: {np.mean(cv_scores):.2f}")Nuestras puntuaciones de validación cruzada tienen una varianza baja, que oscila entre el 94% y el 96%. La precisión global del modelo también ha aumentado del 94% al 95%.
Cross-validation scores: [0.95396825 0.95714286 0.94126984 0.96190476 0.95714286]
Mean CV accuracy: 0.95La técnica del ensacado es una herramienta útil en aplicaciones de aprendizaje automático para mejorar la precisión y la estabilidad del modelo.
Aprende técnicas de ensamblaje como bagging, boosting y stacking para construir modelos de aprendizaje automático avanzados y eficaces en Python con el curso Métodos de Ensamblaje en Python.
Al utilizar el ensacado en el aprendizaje automático, seguir las mejores prácticas y consejos puede maximizar su eficacia:
n_estimators más alto , como 100-200, al embolsar para obtener el máximo beneficio.n_jobs. Impleméntalo en varias CPU/máquinas para un entrenamiento más rápido.GridSearchCV. Un buen rendimiento de los modelos individuales suele traducirse en un mejor rendimiento del conjunto.Lee las Mejores Prácticas MLOps (Machine Learning Operations) para aprender prácticas MLOps de éxito para un despliegue fiable y escalable de sistemas de aprendizaje automático.
En este tutorial, exploramos el bagging, una potente técnica de aprendizaje automático por conjuntos. El ensacado agrega múltiples modelos para mejorar el rendimiento predictivo global. Lo hemos comparado con el boosting y hemos conocido sus ventajas sobre el uso de un único modelo.
Al final, hemos implementado un clasificador bagging en Python sobre un conjunto de datos de churn de telecomunicaciones. El conjunto empaquetado de árboles de decisión mejoró la precisión y el rendimiento de las clases minoritarias respecto a un único árbol de decisión. Además, aprendimos valiosos consejos y trucos para maximizar la eficacia del ensacado en el aprendizaje automático.
Si quieres dedicarte profesionalmente al aprendizaje automático, empieza por matricularte en la carrera de Científico de Aprendizaje Automático con Python. Aprenderás a entrenar modelos supervisados, no supervisados y de aprendizaje profundo utilizando el lenguaje de programación Python.
¡Empieza hoy tu viaje de aprendizaje automático!
Curso
Curso
Curso