
Cours
Machine learning avec des modèles arborescents en Python
5 h
116.4K
Les méthodes d'ensemble sont des techniques puissantes d'apprentissage automatique qui combinent plusieurs modèles pour améliorer la précision globale de la prédiction et la stabilité du modèle. L'agrégation Bootstrap, mieux connue sous le nom de Bagging, est une méthode d'ensemble populaire et largement mise en œuvre.
Dans ce tutoriel, nous allons nous intéresser de plus près à l'ensachage, à son fonctionnement et à ses avantages. Nous la comparerons à une autre méthode d'ensemble (Boosting) et étudierons un exemple de bagging en Python. À la fin, vous aurez une solide compréhension de l'ensachage, y compris des meilleures pratiques.
La modélisation d'ensemble est une technique qui combine plusieurs modèles d'apprentissage automatique afin d'améliorer les performances prédictives globales. L'idée de base est qu'un groupe d'apprenants faibles peut se réunir pour former un apprenant fort.
Un modèle d'ensemble se compose généralement de deux étapes :
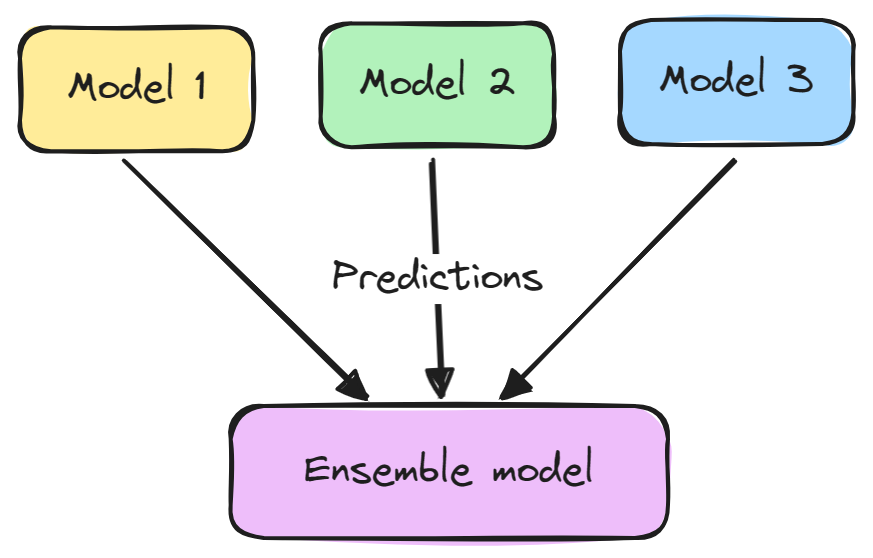
Les ensembles ont tendance à donner de meilleurs résultats parce que les différents modèles se complètent et surmontent leurs faiblesses individuelles. Ils réduisent également la variance et empêchent l'ajustement excessif.
Les méthodes d'ensemble les plus répandues sont l'ensachage, l'augmentation et l'empilage. L'apprentissage d'ensemble est largement utilisé dans les tâches d'apprentissage automatique telles que la classification, la régression et le regroupement afin d'améliorer la précision et la robustesse.
L'agrégation (bootstrap) est une méthode d'ensemble qui consiste à former plusieurs modèles indépendamment sur des sous-ensembles aléatoires de données et à agréger leurs prédictions par le biais d'un vote ou d'un calcul de moyenne.
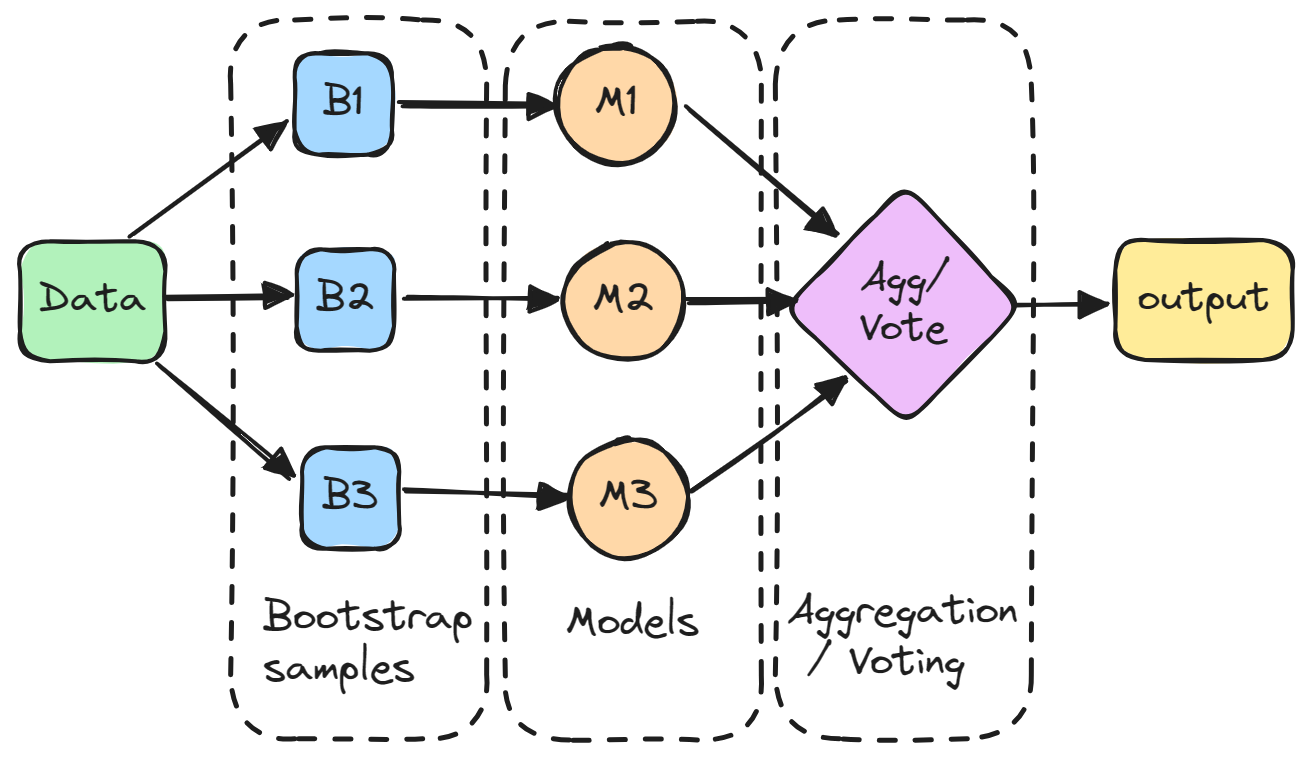
En détail, chaque modèle est formé sur un sous-ensemble aléatoire de données échantillonnées avec remplacement, ce qui signifie que les points de données individuels peuvent être choisis plus d'une fois. Ce sous-ensemble aléatoire est appelé échantillon bootstrap. En entraînant les modèles sur différents bootstraps, le bagging réduit la variance des modèles individuels. Il évite également le surajustement en exposant les modèles constitutifs à différentes parties de l'ensemble de données.
Les prédictions de tous les modèles échantillonnés sont ensuite combinées par une simple moyenne pour obtenir la prédiction globale. De cette manière, le modèle agrégé intègre les points forts des modèles individuels et annule leurs erreurs.
Le bagging est particulièrement efficace pour réduire la variance et le surajustement, ce qui rend le modèle plus robuste et plus précis, en particulier dans les cas où les modèles individuels sont sujets à une forte variabilité.
La méthode Boosting est une autre méthode d'ensemble populaire qui est souvent comparée à la méthode Bagging. La principale différence réside dans la manière dont les modèles constitutifs sont formés.
Dans le cas du bagging, les modèles sont formés indépendamment en parallèle sur différents sous-ensembles aléatoires des données. Alors que dans le cas du boosting, les modèles sont formés de manière séquentielle, chaque modèle apprenant à partir des erreurs du modèle précédent. En outre, le bagging implique généralement une simple moyenne des modèles, tandis que le boosting attribue des poids en fonction de la précision.
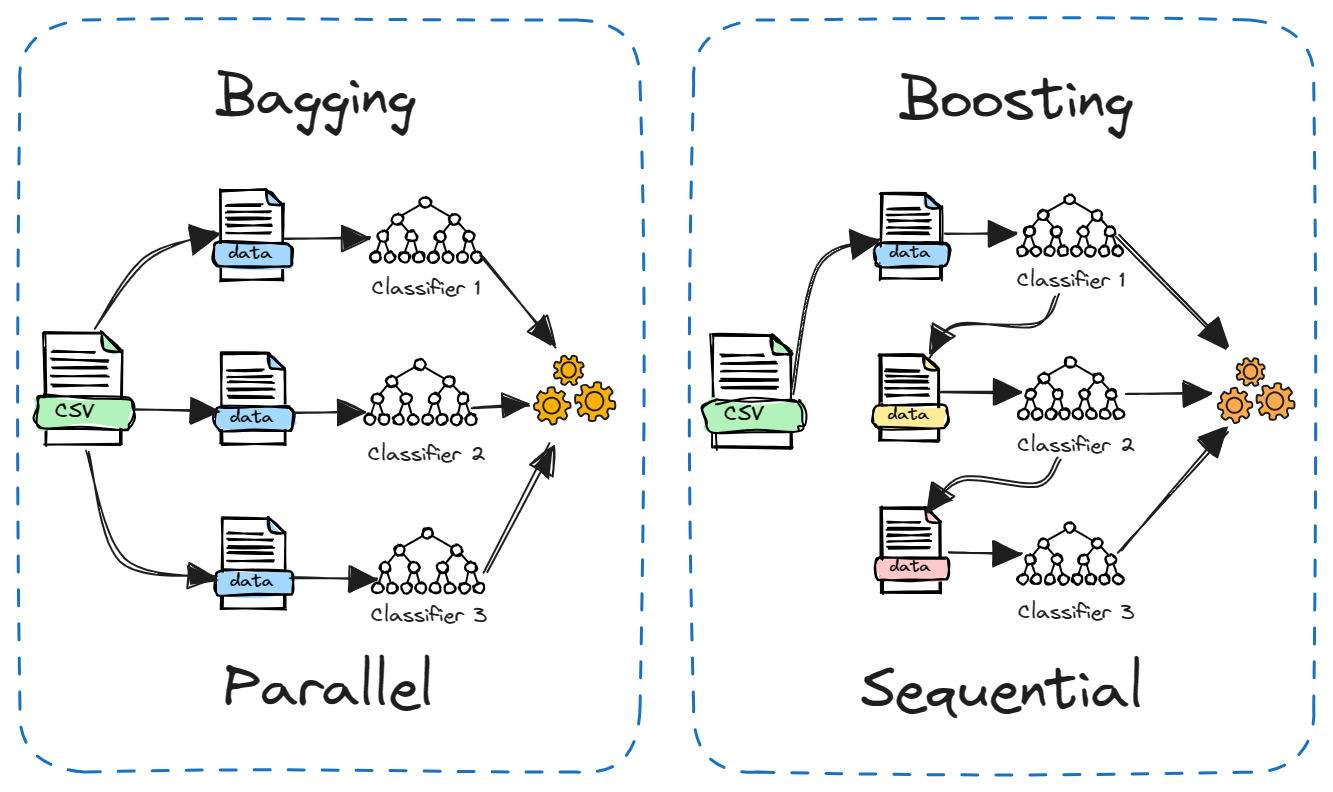
Le bagging réduit la variance tandis que le boosting réduit le biais. Le bagging peut être utilisé avec des modèles instables tels que les arbres de décision, tandis que le boosting fonctionne mieux avec des modèles stables tels que la régression linéaire.
Les deux méthodes ont leurs forces et leurs faiblesses. Le bagging est plus simple à exécuter en parallèle, tandis que le boosting peut être plus puissant et plus précis. Dans la pratique, il est utile de tester les deux sur un nouveau problème pour voir lequel est le plus performant.
Voici les principaux avantages de l'ensachage :
Dans ce tutoriel Python, nous allons entraîner un modèle de classification par arbre de décision sur un ensemble de données de désabonnement des clients des télécommunications et utiliser la méthode d'ensemble de bagging pour améliorer les performances. Nous utiliserons DataLab pour obtenir l'ensemble de données et exécuter notre code. Le code est également disponible dans ce classeur DataLab, que vous pouvez copier pour l'exécuter dans votre navigateur sans rien installer.
L'ensemble de données sur le renouvellement des clients des télécommunications provient d'une entreprise de télécommunications iranienne. Chaque ligne de l'ensemble de données correspond à l'activité d'un client au cours d'une année, y compris des informations sur les échecs d'appel, la durée de l'abonnement et une étiquette de désabonnement qui indique si le client a quitté le service.
Tout d'abord, nous allons charger l'ensemble de données et afficher les 5 premières lignes.
import pandas as pd
customer = pd.read_csv("data/customer_churn.csv")
customer.head()
Ensuite, nous créerons des variables indépendantes (X) et dépendantes (y). Ensuite, nous divisons l'ensemble de données en sous-ensembles de formation et de test.
X = customer.drop("Churn", axis=1)
y = customer.Churn
# Split into train and test
from sklearn.model_selection import train_test_split, cross_val_score
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)Nous allons créer un pipeline d'apprentissage automatique simple et y intégrer un ensemble de données d'entraînement. Le pipeline normalise les données avant d'alimenter le classificateur à arbre de décision.
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
pipeline = Pipeline([
('scaler', StandardScaler()),
('classifier', DecisionTreeClassifier(random_state=42))
])
pipeline.fit(X_train, y_train)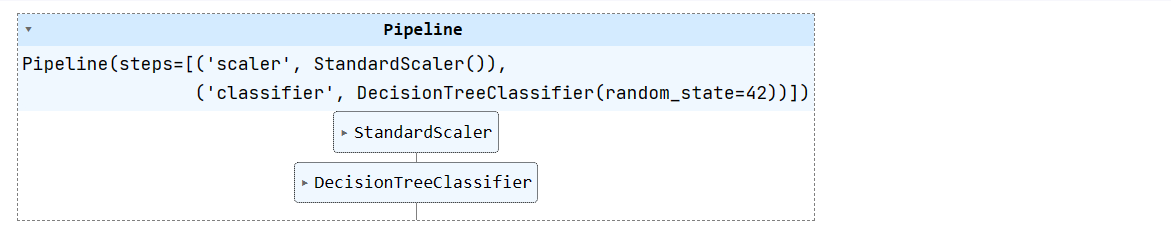
Suivez le cours Machine Learning with Tree-Based Models in Python pour apprendre à utiliser des modèles arborescents et des ensembles pour la régression et la classification avec scikit-learn.
Nous évaluerons un modèle d'arbre de décision afin de le comparer au modèle d'ensemble.
Nous produirons des rapports de classification en faisant des prédictions sur une feuille de données de test.
from sklearn.metrics import classification_report
# Make prediction on the testing data
y_pred = pipeline.predict(X_test)
# Classification Report
print(classification_report(y_pred, y_test))Notre modèle a obtenu une précision de 96 % et un rappel de 97 % pour la classe majoritaire "0", mais ses performances ont été médiocres pour la classe minoritaire "1".
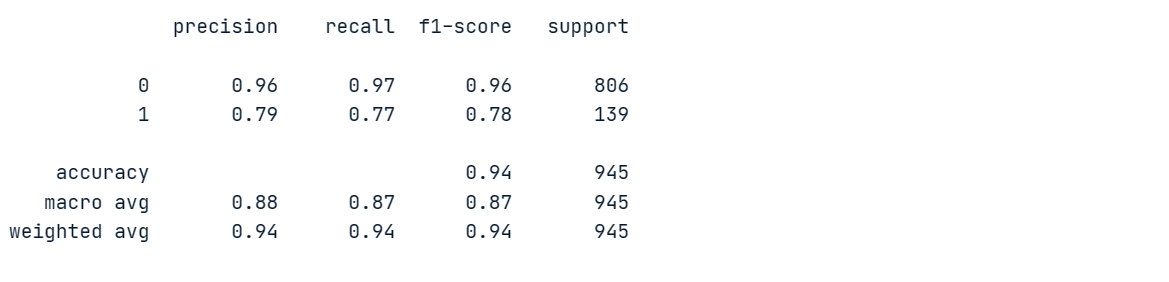
Afin de mieux comprendre les performances du modèle, nous procéderons à une validation croisée et calculerons les scores correspondants.
# Evaluate the classifier using cross-validation
cv_scores = cross_val_score(pipeline, X, y, cv=5)
print(f"Cross-validation scores: {cv_scores}")
print(f"Mean CV accuracy: {np.mean(cv_scores):.2f}")Les scores varient fortement, avec des maxima de 95 % et des minima de 92 %.
Cross-validation scores: [0.95079365 0.94126984 0.93492063 0.94285714 0.92222222]
Mean CV accuracy: 0.94Maintenant, créons un classificateur de bagging en utilisant un estimateur de base comme notre pipeline (scalaire + classificateur d'arbre de décision) et entraînons-le sur un ensemble de données d'entraînement.
Nous pouvons améliorer la performance du modèle en augmentant n_estimators, mais 50 est suffisant pour les résultats de base.
from sklearn.ensemble import BaggingClassifier
# Create a bagging classifier with the decision tree pipeline
bagging_classifier = BaggingClassifier(base_estimator=pipeline, n_estimators=50, random_state=42)
# Train the bagging classifier on the training data
bagging_classifier.fit(X_train, y_train)
Nous allons évaluer les résultats du modèle d'ensemble et les comparer aux performances du modèle unique. Pour cela, nous allons générer des rapports de classification sur un ensemble de données de test.
# Make prediction on the testing data
y_pred = bagging_classifier.predict(X_test)
# Classification Report
print(classification_report(y_pred, y_test))Comme vous pouvez le constater, nous avons comparativement amélioré la performance du modèle. La précision et le rappel pour la classe minoritaire sont passés respectivement de 79 % à 80 % et de 77 % à 82 %. Cela représente une amélioration significative.
Calculons maintenant le score de validation croisée.
# Evaluate the classifier using cross-validation
cv_scores = cross_val_score(bagging_classifier, X, y, cv=5)
print(f"Cross-validation scores: {cv_scores}")
print(f"Mean CV accuracy: {np.mean(cv_scores):.2f}")Nos scores de validation croisée présentent une faible variance, comprise entre 94 % et 96 %. La précision globale du modèle est également passée de 94 % à 95 %.
Cross-validation scores: [0.95396825 0.95714286 0.94126984 0.96190476 0.95714286]
Mean CV accuracy: 0.95La technique du bagging est un outil utile dans les applications d'apprentissage automatique pour améliorer la précision et la stabilité des modèles.
Apprenez les techniques d'ensemble telles que le bagging, le boosting et le stacking pour construire des modèles d'apprentissage automatique avancés et efficaces en Python avec le cours Méthodes d'ensemble en Python.
Lorsque vous utilisez le bagging dans l'apprentissage automatique, vous pouvez maximiser son efficacité en suivant les meilleures pratiques et les conseils :
n_estimators (100-200 par exemple) lors de l'ensachage afin d'en tirer le meilleur parti.n_jobs. Mettez-le en œuvre sur plusieurs unités centrales/machines pour une formation plus rapide.GridSearchCV. Une bonne performance des modèles individuels se traduit généralement par une meilleure performance de l'ensemble.Lisez les meilleures pratiques MLOps (Machine Learning Operations) pour apprendre les pratiques MLOps réussies pour un déploiement fiable et évolutif des systèmes d'apprentissage automatique.
Dans ce tutoriel, nous avons exploré le bagging, une puissante technique d'apprentissage automatique d'ensemble. L'agrégation de plusieurs modèles permet d'améliorer les performances prédictives globales. Nous l'avons comparée au boosting et avons découvert ses avantages par rapport à l'utilisation d'un modèle unique.
Au final, nous avons mis en œuvre un classificateur de bagging en Python sur un jeu de données de churn de télécoms. L'ensemble d'arbres de décision a amélioré la précision et la performance des classes minoritaires par rapport à un seul arbre de décision. En outre, nous avons appris de précieux conseils et astuces pour maximiser l'efficacité du bagging dans l'apprentissage automatique.
Si vous souhaitez poursuivre une carrière en tant qu'ingénieur professionnel en apprentissage automatique, commencez par vous inscrire au cursus Machine Learning Scientist with Python. Vous apprendrez à former des modèles supervisés, non supervisés et d'apprentissage profond à l'aide du langage de programmation Python.
Commencez dès aujourd'hui votre voyage dans le domaine de l'apprentissage automatique !
Cours
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach