
Kurs
Maschinelles Lernen mit baumbasierten Modellen in Python
5 Std.
116.4K
Ensemble-Methoden sind leistungsstarke Techniken des maschinellen Lernens, die mehrere Modelle kombinieren, um die Vorhersagegenauigkeit und die Stabilität der Modelle zu verbessern. Bootstrap Aggregating, besser bekannt als Bagging, ist eine beliebte und weit verbreitete Ensemble-Methode.
In diesem Tutorial tauchen wir tiefer in das Bagging ein, wie es funktioniert und wo es seine Stärken hat. Wir werden sie mit einer anderen Ensemble-Methode (Boosting) vergleichen und uns ein Bagging-Beispiel in Python ansehen. Am Ende des Kurses wirst du ein solides Verständnis für das Bagging haben, einschließlich der besten Praktiken.
Die Ensemble-Modellierung ist eine Technik, die mehrere maschinelle Lernmodelle kombiniert, um die Gesamtvorhersageleistung zu verbessern. Die Grundidee ist, dass sich eine Gruppe schwacher Lernender zu einer Gruppe starker Lernender zusammenschließen kann.
Ein Ensemble-Modell besteht in der Regel aus zwei Schritten:
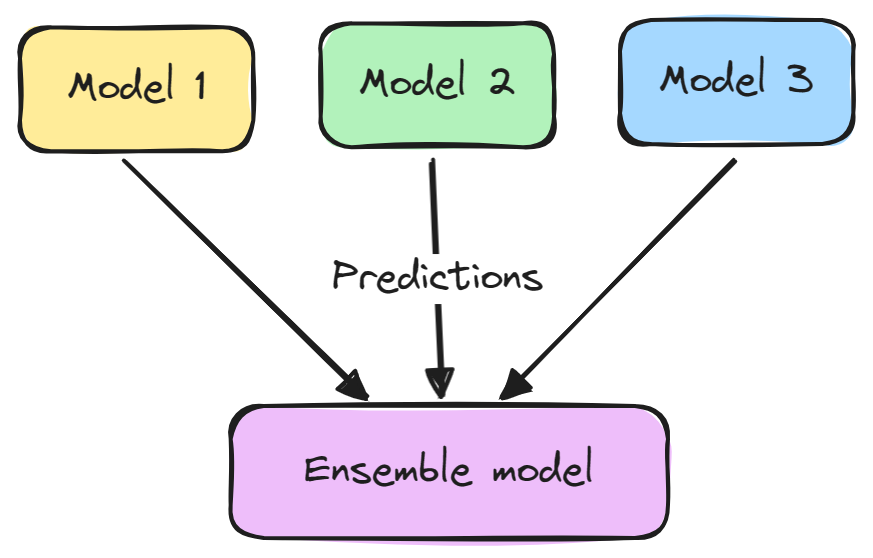
Ensembles führen in der Regel zu besseren Ergebnissen, weil sich die verschiedenen Modelle gegenseitig ergänzen und ihre individuellen Schwächen überwinden. Außerdem verringern sie die Varianz und verhindern eine Überanpassung.
Einige beliebte Ensemble-Methoden sind Bagging, Boosting und Stacking. Ensemble-Lernen wird häufig bei maschinellen Lernaufgaben wie Klassifizierung, Regression und Clustering eingesetzt, um die Genauigkeit und Robustheit zu verbessern.
Bagging (Bootstrap-Aggregation) ist eine Ensemble-Methode, bei der mehrere Modelle unabhängig voneinander auf zufälligen Teilmengen der Daten trainiert und ihre Vorhersagen durch Abstimmung oder Mittelwertbildung aggregiert werden.
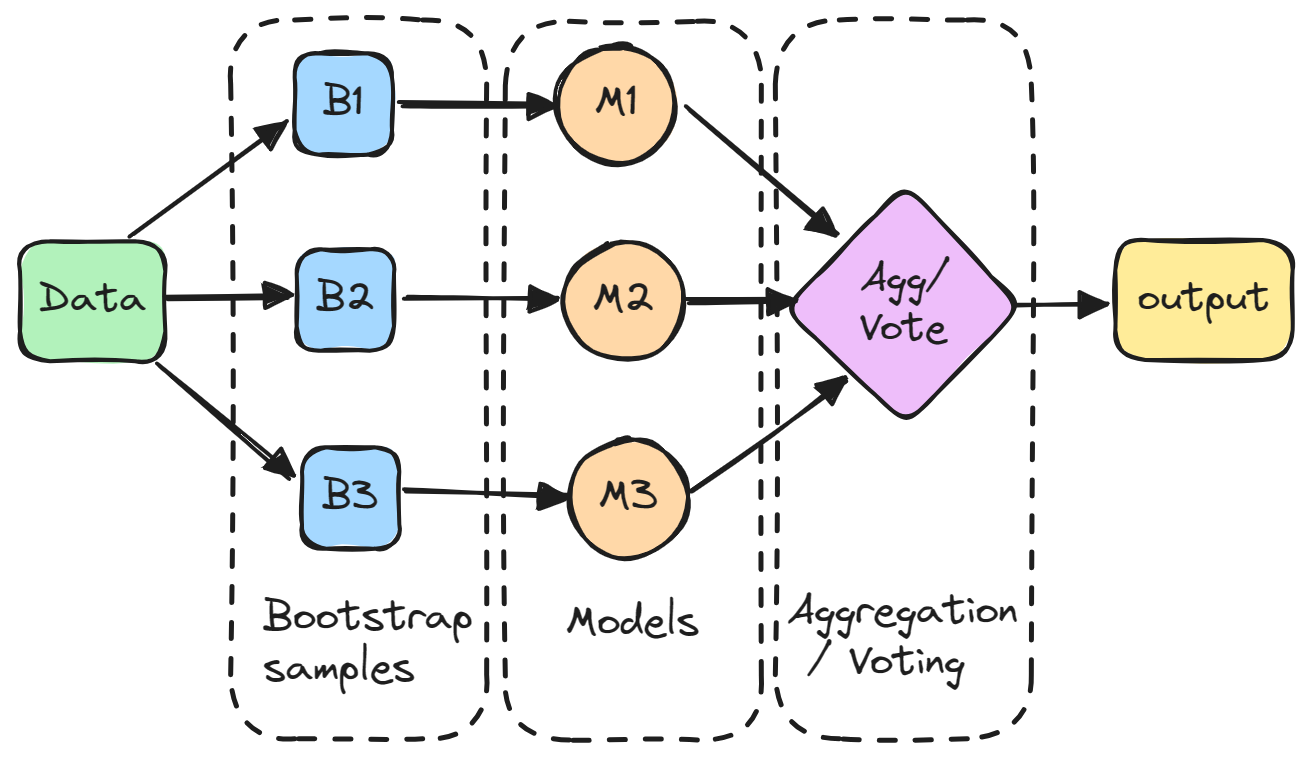
Im Einzelnen wird jedes Modell auf einer zufälligen Teilmenge der Daten trainiert, die mit Ersetzung ausgewählt wird, was bedeutet, dass die einzelnen Datenpunkte mehr als einmal ausgewählt werden können. Diese zufällige Teilmenge wird als Bootstrap-Stichprobe bezeichnet. Durch das Trainieren von Modellen auf verschiedenen Bootstraps wird beim Bagging die Varianz der einzelnen Modelle reduziert. Außerdem wird eine Überanpassung vermieden, indem die einzelnen Modelle auf verschiedene Teile des Datensatzes angewendet werden.
Die Vorhersagen aller Stichprobenmodelle werden dann durch eine einfache Mittelwertbildung kombiniert, um die Gesamtvorhersage zu erstellen. Auf diese Weise berücksichtigt das aggregierte Modell die Stärken der einzelnen Modelle und gleicht deren Fehler aus.
Bagging ist besonders effektiv, um die Varianz und die Überanpassung zu reduzieren und das Modell robuster und genauer zu machen, vor allem in Fällen, in denen die einzelnen Modelle für eine hohe Variabilität anfällig sind.
Boosting ist eine weitere beliebte Ensemble-Methode, die oft mit Bagging verglichen wird. Der Hauptunterschied liegt darin, wie die einzelnen Modelle trainiert werden.
Beim Bagging werden die Modelle unabhängig voneinander und parallel auf verschiedenen zufälligen Teilmengen der Daten trainiert. Beim Boosting hingegen werden die Modelle nacheinander trainiert, wobei jedes Modell aus den Fehlern des vorherigen Modells lernt. Außerdem wird beim Bagging in der Regel einfach der Durchschnitt der Modelle gebildet, während beim Boosting die Gewichtung auf der Grundlage der Genauigkeit erfolgt.
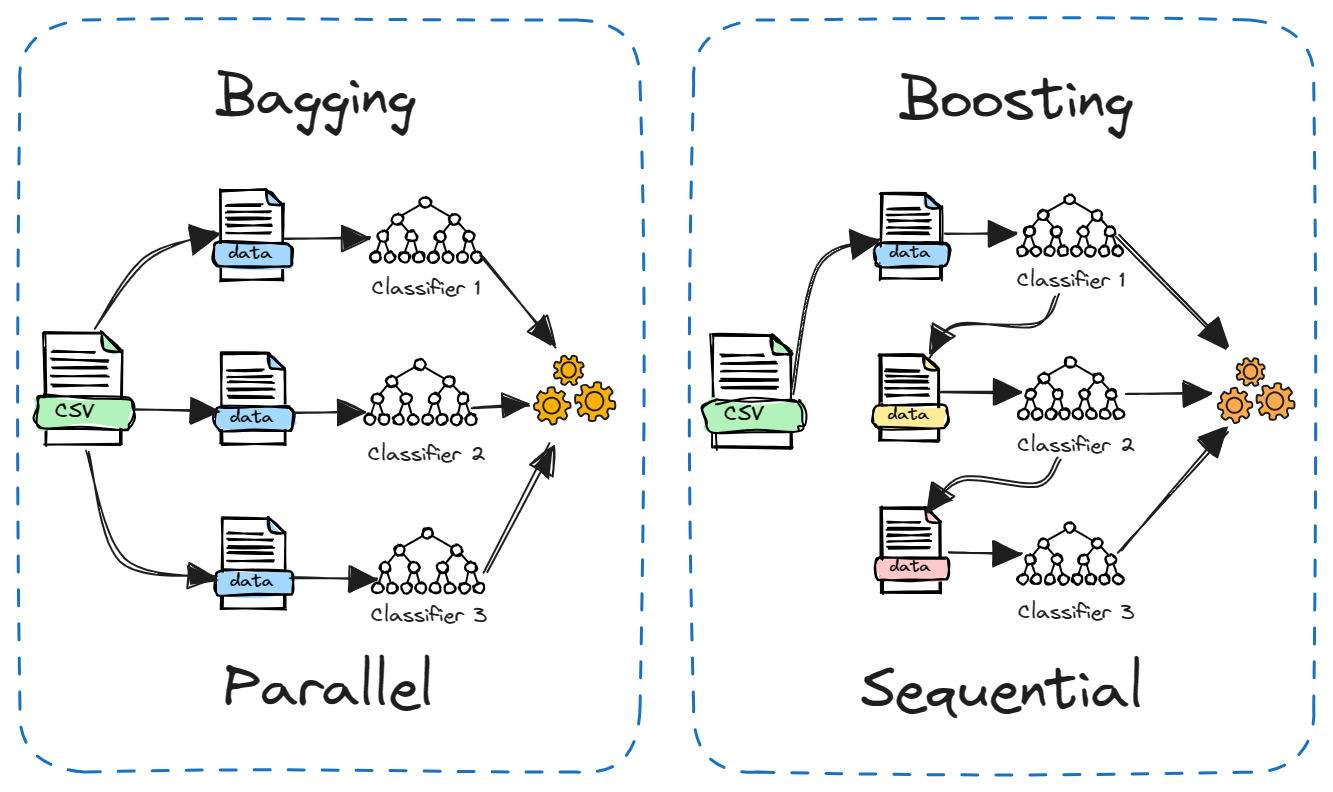
Bagging reduziert die Varianz, während Boosting die Verzerrung reduziert. Bagging kann für instabile Modelle wie Entscheidungsbäume verwendet werden, während Boosting besser für stabile Modelle wie die lineare Regression geeignet ist.
Beide Methoden haben ihre Stärken und Schwächen. Bagging ist einfacher parallel zu betreiben, während Boosting leistungsfähiger und genauer sein kann. In der Praxis hilft es, beide an einem neuen Problem zu testen, um zu sehen, was besser funktioniert.
Hier sind einige wichtige Vorteile des Absackens:
In diesem Python-Tutorial trainieren wir ein Entscheidungsbaum-Klassifizierungsmodell für den Datensatz zur Kundenabwanderung bei der Telekom und verwenden die Bagging-Ensemble-Methode, um die Leistung zu verbessern. Wir werden DataLab verwenden, um den Datensatz zu erhalten und unseren Code auszuführen. Der Code ist auch in dieser DataLab-Arbeitsmappe verfügbar, die du kopieren kannst, um sie in deinem Browser auszuführen, ohne etwas zu installieren.
Der Datensatz zur Abwanderung von Telekommunikationskunden stammt von einem iranischen Telekommunikationsunternehmen. Jede Zeile im Datensatz entspricht der Aktivität eines Kunden im Laufe eines Jahres, einschließlich Informationen über Anrufausfälle, die Dauer des Abonnements und eine Abwanderungskennzeichnung, die angibt, ob der Kunde den Dienst verlassen hat.
Zuerst laden wir den Datensatz und sehen uns die obersten 5 Zeilen an.
import pandas as pd
customer = pd.read_csv("data/customer_churn.csv")
customer.head()
Danach werden wir unabhängige (X) und abhängige (y) Variablen erstellen. Dann teilen wir den Datensatz in eine Trainings- und eine Testgruppe auf.
X = customer.drop("Churn", axis=1)
y = customer.Churn
# Split into train and test
from sklearn.model_selection import train_test_split, cross_val_score
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)Wir werden eine einfache Pipeline für maschinelles Lernen erstellen und sie mit einem Trainingsdatensatz versehen. Die Pipeline normalisiert die Daten, bevor sie die Eingaben an den Entscheidungsbaum-Klassifikator weiterleitet.
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
pipeline = Pipeline([
('scaler', StandardScaler()),
('classifier', DecisionTreeClassifier(random_state=42))
])
pipeline.fit(X_train, y_train)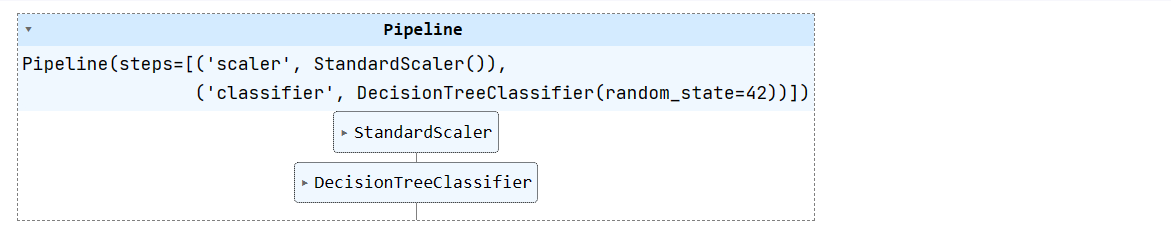
Im Kurs Maschinelles Lernen mit baumbasierten Modellen in Python lernst du, wie du baumbasierte Modelle und Ensembles für Regression und Klassifizierung mit scikit-learn einsetzt.
Wir werden ein Entscheidungsbaummodell auswerten, damit wir es mit dem Ensemble-Modell vergleichen können.
Wir werden Klassifizierungsberichte erstellen, indem wir Vorhersagen auf einem Testdatenblatt machen.
from sklearn.metrics import classification_report
# Make prediction on the testing data
y_pred = pipeline.predict(X_test)
# Classification Report
print(classification_report(y_pred, y_test))Unser Modell erreichte bei der Mehrheitsklasse "0" eine Genauigkeit von 96 % und eine Wiedererkennung von 97 %, schnitt aber bei der Minderheitenklasse "1" schlecht ab.
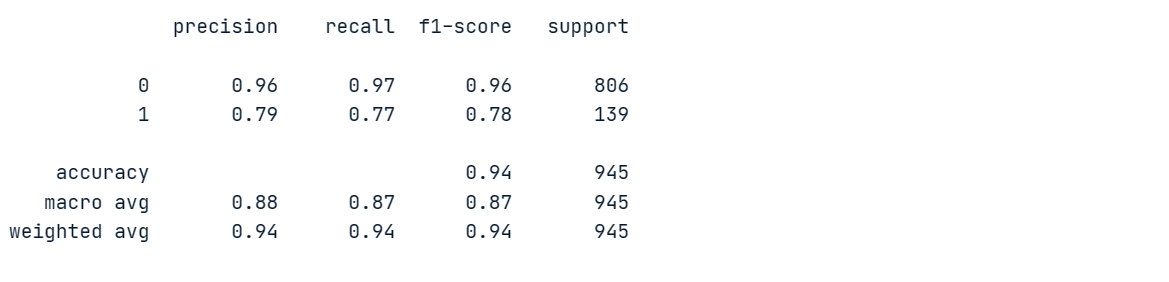
Um ein besseres Verständnis für die Leistung des Modells zu bekommen, führen wir eine Kreuzvalidierung durch und berechnen die entsprechenden Punktzahlen.
# Evaluate the classifier using cross-validation
cv_scores = cross_val_score(pipeline, X, y, cv=5)
print(f"Cross-validation scores: {cv_scores}")
print(f"Mean CV accuracy: {np.mean(cv_scores):.2f}")Es gibt große Unterschiede in den Ergebnissen, mit Höchstwerten von 95% und Tiefstwerten von 92%.
Cross-validation scores: [0.95079365 0.94126984 0.93492063 0.94285714 0.92222222]
Mean CV accuracy: 0.94Erstellen wir nun einen Bagging-Klassifikator mit einem Basisschätzer als Pipeline (skalarer + Entscheidungsbaum-Klassifikator) und trainieren ihn mit einem Trainingsdatensatz.
Wir können die Leistung des Modells verbessern, indem wir n_estimators erhöhen, aber 50 ist genug für die Basisergebnisse.
from sklearn.ensemble import BaggingClassifier
# Create a bagging classifier with the decision tree pipeline
bagging_classifier = BaggingClassifier(base_estimator=pipeline, n_estimators=50, random_state=42)
# Train the bagging classifier on the training data
bagging_classifier.fit(X_train, y_train)
Lass uns die Ergebnisse des Ensemble-Modells auswerten und sie mit der Leistung des Einzelmodells vergleichen. Dazu erstellen wir Klassifizierungsberichte für einen Testdatensatz.
# Make prediction on the testing data
y_pred = bagging_classifier.predict(X_test)
# Classification Report
print(classification_report(y_pred, y_test))Wie du sehen kannst, haben wir die Leistung des Modells vergleichsweise verbessert. Die Genauigkeit und der Wiedererkennungswert für die Minderheitenklasse sind beide von 79% auf 80% bzw. von 77% auf 82% gestiegen. Das ist eine deutliche Verbesserung.
Berechnen wir nun den Kreuzvalidierungswert.
# Evaluate the classifier using cross-validation
cv_scores = cross_val_score(bagging_classifier, X, y, cv=5)
print(f"Cross-validation scores: {cv_scores}")
print(f"Mean CV accuracy: {np.mean(cv_scores):.2f}")Unsere Ergebnisse der Kreuzvalidierung haben eine geringe Streuung und liegen zwischen 94% und 96%. Auch die Gesamtgenauigkeit des Modells ist von 94% auf 95% gestiegen.
Cross-validation scores: [0.95396825 0.95714286 0.94126984 0.96190476 0.95714286]
Mean CV accuracy: 0.95Die Bagging-Technik ist ein nützliches Hilfsmittel bei Anwendungen des maschinellen Lernens, um die Genauigkeit und Stabilität der Modelle zu verbessern.
Im Kurs Ensemble Methods in Python lernst du Ensemble-Techniken wie Bagging, Boosting und Stacking kennen, um fortgeschrittene und effektive Machine Learning-Modelle in Python zu erstellen.
Wenn du Bagging beim maschinellen Lernen einsetzt, kannst du seine Effektivität maximieren, indem du die besten Methoden und Tipps befolgst:
n_estimators Wert wie 100-200 ein , um den maximalen Nutzen zu erzielen.n_jobsleicht parallelisieren. Implementiere sie auf mehreren CPUs/Maschinen, um schneller zu lernen.GridSearchCV, bevor du sie zusammenfasst. Eine gute Leistung der einzelnen Modelle bedeutet in der Regel auch eine bessere Leistung des Ensembles.Lies MLOps (Machine Learning Operations) Best Practices, um erfolgreiche MLOps-Praktiken für den zuverlässigen und skalierbaren Einsatz von maschinellen Lernsystemen zu lernen.
In diesem Tutorium haben wir uns mit Bagging beschäftigt, einer leistungsstarken Methode des maschinellen Lernens. Beim Bagging werden mehrere Modelle zusammengefasst, um die Vorhersageleistung insgesamt zu verbessern. Wir haben es mit Boosting verglichen und seine Vorteile gegenüber der Verwendung eines einzelnen Modells kennengelernt.
Schließlich haben wir einen Bagging-Klassifikator in Python für einen Datensatz von Telekommunikationsabwanderungen implementiert. Das Ensemble von Entscheidungsbäumen verbesserte die Genauigkeit und die Leistung der Minderheitsklassen gegenüber einem einzelnen Entscheidungsbaum. Außerdem lernten wir wertvolle Tipps und Tricks, um die Effektivität des Baggings beim maschinellen Lernen zu maximieren.
Wenn du eine Karriere als professioneller Ingenieur für maschinelles Lernen anstrebst, solltest du dich für den Lernpfad Machine Learning Scientist with Python anmelden. Du lernst, wie du mit der Programmiersprache Python überwachte, unüberwachte und Deep-Learning-Modelle trainieren kannst.
Beginne deine Reise zum maschinellen Lernen noch heute!
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach
