
Course
Machine Learning with Tree-Based Models in Python
5 hr
116.3K
Ensemble methods are powerful techniques in machine learning that combine multiple models to improve overall prediction accuracy and model stability. Bootstrap Aggregating, better known as Bagging, stands out as a popular and widely implemented ensemble method.
In this tutorial, we will dive deeper into bagging, how it works, and where it shines. We will compare it to another ensemble method (Boosting) and look at a bagging example in Python. By the end, you'll have a solid understanding of bagging, including best practices.
Ensemble Modeling is a technique that combines multiple machine learning models to improve overall predictive performance. The basic idea is that a group of weak learners can come together to form one strong learner.
An ensemble model typically consists of two steps:
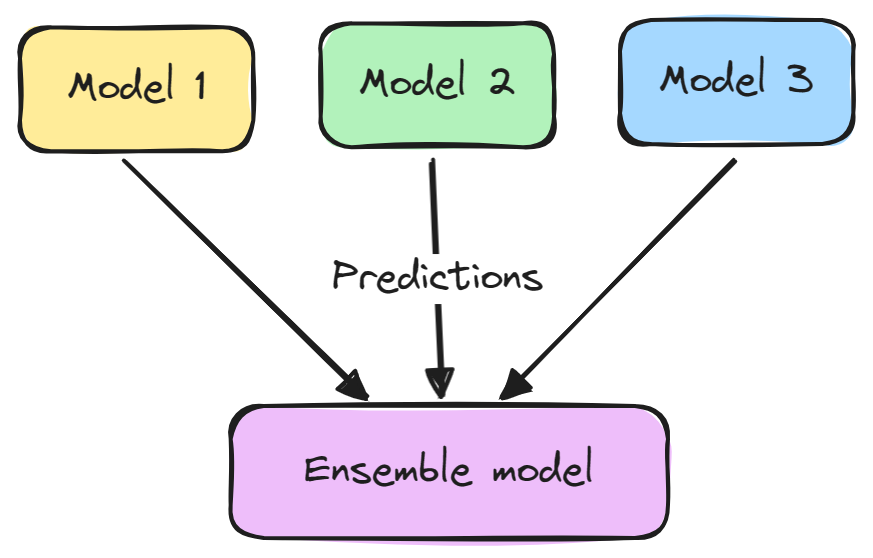
Ensembles tend to yield better results because the different models complement each other and overcome their individual weaknesses. They also reduce variance and prevent overfitting.
Some popular ensemble methods are bagging, boosting, and stacking. Ensemble learning is used extensively across machine learning tasks like classification, regression, and clustering to enhance accuracy and robustness.
Bagging (bootstrap aggregating) is an ensemble method that involves training multiple models independently on random subsets of the data, and aggregating their predictions through voting or averaging.
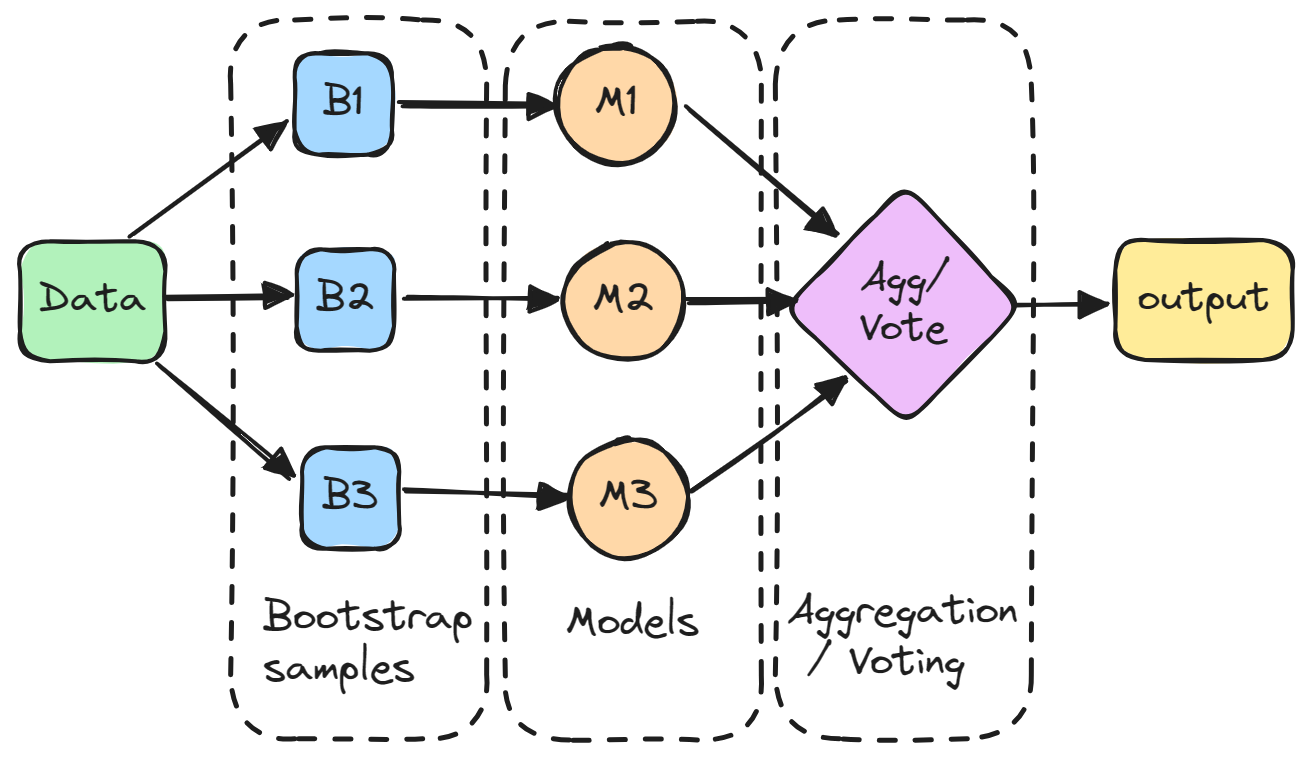
In detail, each model is trained on a random subset of the data sampled with replacement, meaning that the individual data points can be chosen more than once. This random subset is known as a bootstrap sample. By training models on different bootstraps, bagging reduces the variance of the individual models. It also avoids overfitting by exposing the constituent models to different parts of the dataset.
The predictions from all the sampled models are then combined through a simple averaging to make the overall prediction. This way, the aggregated model incorporates the strengths of the individual ones and cancels out their errors.
Bagging is particularly effective in reducing variance and overfitting, making the model more robust and accurate, especially in cases where the individual models are prone to high variability.
Boosting is another popular ensemble method that is often compared to Bagging. The main difference lies in how the constituent models are trained.
In bagging, models are trained independently in parallel on different random subsets of the data. Whereas in boosting, models are trained sequentially, with each model learning from the errors of the previous one. Additionally, bagging typically involves simple averaging of models, while boosting assigns weights based on accuracy.
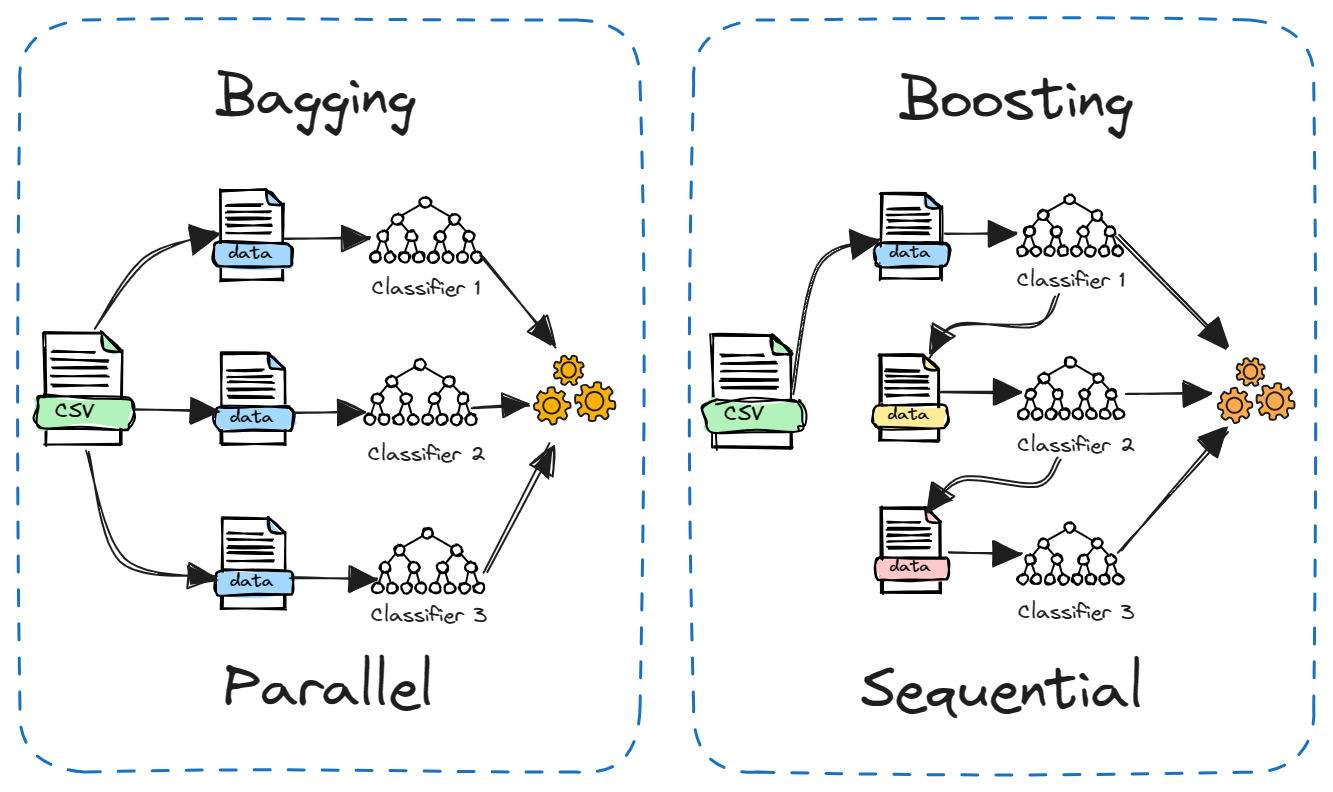
Bagging reduces variance while boosting reduces bias. Bagging can be used with unstable models like decision trees while boosting works better for stable models like linear regression.
Both methods have their strengths and weaknesses. Bagging is simpler to run parallelly while boosting can be more powerful and accurate. In practice, it helps to test both on a new problem to see which performs better.
Here are some key advantages of bagging:
In this Python tutorial, we will train a decision tree classification model on telecom customer churn dataset and use the bagging ensemble method to improve the performance. We will use DataLab to get the dataset and run our code. The code is also available in this DataLab workbook, that you can copy to run in your browser without installing anything.
The dataset on telecom customer churn comes from an Iranian telecom company. Each row in the dataset corresponds to a customer's activity over the course of a year, including information on call failures, subscription length, and a churn label that indicates whether the customer has left the service.
First, we will load the dataset and view the top 5 rows.
import pandas as pd
customer = pd.read_csv("data/customer_churn.csv")
customer.head()
After that, we will create independent (X) and dependent (y) variables. Then, we will split the dataset into training and test subsets.
X = customer.drop("Churn", axis=1)
y = customer.Churn
# Split into train and test
from sklearn.model_selection import train_test_split, cross_val_score
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)We will create a simple machine learning pipeline and fit a training dataset on it. The pipeline will normalize the data before feeding the inputs to the decision tree classifier.
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
pipeline = Pipeline([
('scaler', StandardScaler()),
('classifier', DecisionTreeClassifier(random_state=42))
])
pipeline.fit(X_train, y_train)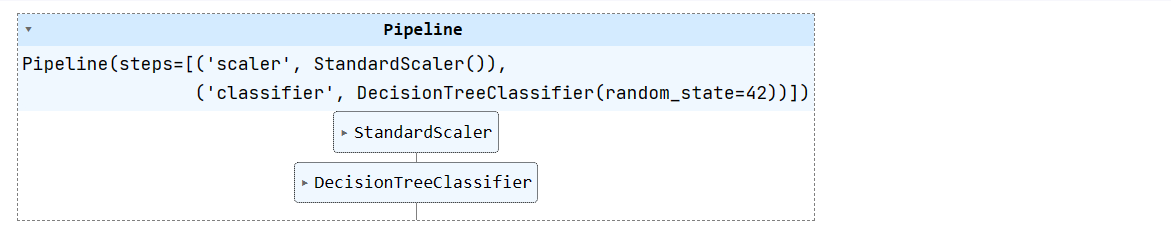
Take the Machine Learning with Tree-Based Models in Python course to learn how to use tree-based models and ensembles for regression and classification with scikit-learn.
We will evaluate a decision tree model so that we can compare it with the ensemble model.
We will generate classification reports by making predictions on a testing datasheet.
from sklearn.metrics import classification_report
# Make prediction on the testing data
y_pred = pipeline.predict(X_test)
# Classification Report
print(classification_report(y_pred, y_test))Our model achieved 96% precision and 97% recall on majority class “0”, but performed poorly on minority class “1”.
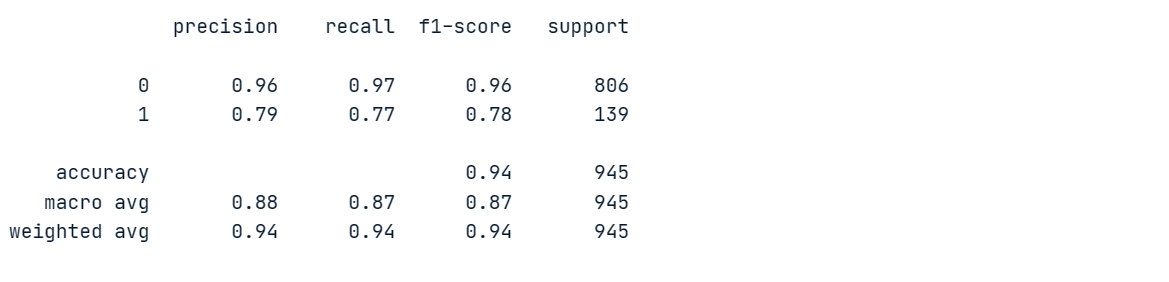
In order to gain a better understanding of the performance of the model, we will conduct cross-validation and calculate the corresponding scores.
# Evaluate the classifier using cross-validation
cv_scores = cross_val_score(pipeline, X, y, cv=5)
print(f"Cross-validation scores: {cv_scores}")
print(f"Mean CV accuracy: {np.mean(cv_scores):.2f}")There is high variation in scores, with highs at 95% and lows at 92%.
Cross-validation scores: [0.95079365 0.94126984 0.93492063 0.94285714 0.92222222]
Mean CV accuracy: 0.94Now, let's create a bagging classifier using a base estimator as our pipeline (scalar + decision tree classifier) and train it on a training dataset.
We can improve the model performance by increasing n_estimators, but 50 is enough for baseline results.
from sklearn.ensemble import BaggingClassifier
# Create a bagging classifier with the decision tree pipeline
bagging_classifier = BaggingClassifier(base_estimator=pipeline, n_estimators=50, random_state=42)
# Train the bagging classifier on the training data
bagging_classifier.fit(X_train, y_train)
Let’s evaluate the ensemble model results and compare them with the single model performance. For that, we will generate classification reports on a testing dataset.
# Make prediction on the testing data
y_pred = bagging_classifier.predict(X_test)
# Classification Report
print(classification_report(y_pred, y_test))As you can see, we have comparatively improved model performance. The precision and recall for the minority class have both increased from 79% to 80% and from 77% to 82%, respectively. This represents a significant improvement.
Let’s now calculate the cross-validation score.
# Evaluate the classifier using cross-validation
cv_scores = cross_val_score(bagging_classifier, X, y, cv=5)
print(f"Cross-validation scores: {cv_scores}")
print(f"Mean CV accuracy: {np.mean(cv_scores):.2f}")Our cross-validation scores have low variance, ranging from 94% to 96%. The overall accuracy of the model has also increased from 94% to 95%.
Cross-validation scores: [0.95396825 0.95714286 0.94126984 0.96190476 0.95714286]
Mean CV accuracy: 0.95The bagging technique is a useful tool in machine learning applications to improve model accuracy and stability.
Learn ensemble techniques such as bagging, boosting, and stacking to build advanced and effective machine learning models in Python with the Ensemble Methods in Python course.
When using bagging in machine learning, following best practices and tips can maximize its effectiveness:
n_estimators value like 100-200 when bagging to obtain maximum benefit.n_jobs. Implement it across multiple CPUs/machines for faster training.GridSearchCV. Good performance of individual models usually translates to better performance of the ensemble.Read MLOps (Machine Learning Operations) Best Practices to learn successful MLOps practices for reliable and scalable deployment of machine learning systems.
In this tutorial, we explored bagging, a powerful ensemble machine learning technique. Bagging aggregates multiple models to improve overall predictive performance. We have compared it with boosting and learned about its advantages over using a single model.
In the end, we have implemented a bagging classifier in Python on a telecom churn dataset. The bagged ensemble of decision trees improved accuracy and minority class performance over a single decision tree. Moreover, we learned valuable tips and tricks to maximize the effectiveness of bagging in machine learning.
If you want to pursue a career as a professional machine learning engineer, start by enrolling in the Machine Learning Scientist with Python career track. You'll learn how to train supervised, unsupervised, and deep learning models using the Python programming language.
Start Your Machine Learning Journey Today!
Course
Course
Course
cheat-sheet
Karlijn Willems
Tutorial
Zoumana Keita
Tutorial
Derrick Mwiti
Tutorial
Bekhruz Tuychiev
Tutorial
Avinash Navlani
Tutorial
Hugo Bowne-Anderson

