
Curso
Aprendizado de máquina com modelos baseados em árvores em Python
5 h
116.4K
Os métodos de conjunto são técnicas poderosas de aprendizado de máquina que combinam vários modelos para melhorar a precisão geral da previsão e a estabilidade do modelo. O Bootstrap Aggregating, mais conhecido como Bagging, destaca-se como um método de conjunto popular e amplamente implementado.
Neste tutorial, vamos nos aprofundar no uso de sacos, como ele funciona e onde ele se destaca. Vamos compará-lo com outro método de conjunto (Boosting) e analisar um exemplo de ensacamento em Python. Ao final, você terá uma sólida compreensão do ensacamento, inclusive das práticas recomendadas.
A modelagem de conjunto é uma técnica que combina vários modelos de aprendizado de máquina para melhorar o desempenho preditivo geral. A ideia básica é que um grupo de alunos fracos pode se unir para formar um aluno forte.
Em geral, um modelo de conjunto consiste em duas etapas:
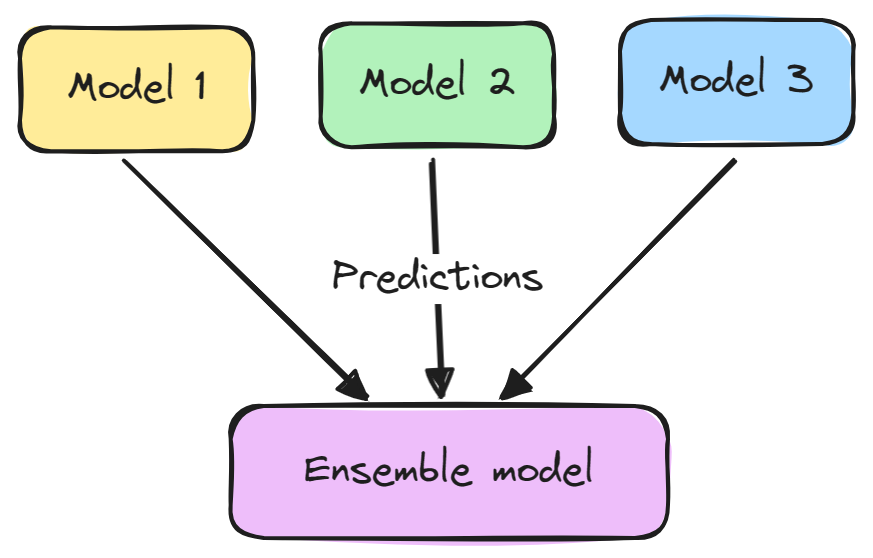
Os conjuntos tendem a produzir melhores resultados porque os diferentes modelos se complementam e superam seus pontos fracos individuais. Eles também reduzem a variação e evitam o ajuste excessivo.
Alguns métodos de conjunto populares são ensacamento, aumento e empilhamento. O aprendizado em conjunto é amplamente usado em tarefas de aprendizado de máquina, como classificação, regressão e agrupamento, para aumentar a precisão e a robustez.
Bagging (agregação bootstrap) é um método de conjunto que envolve o treinamento de vários modelos independentemente em subconjuntos aleatórios dos dados e a agregação de suas previsões por meio de votação ou média.
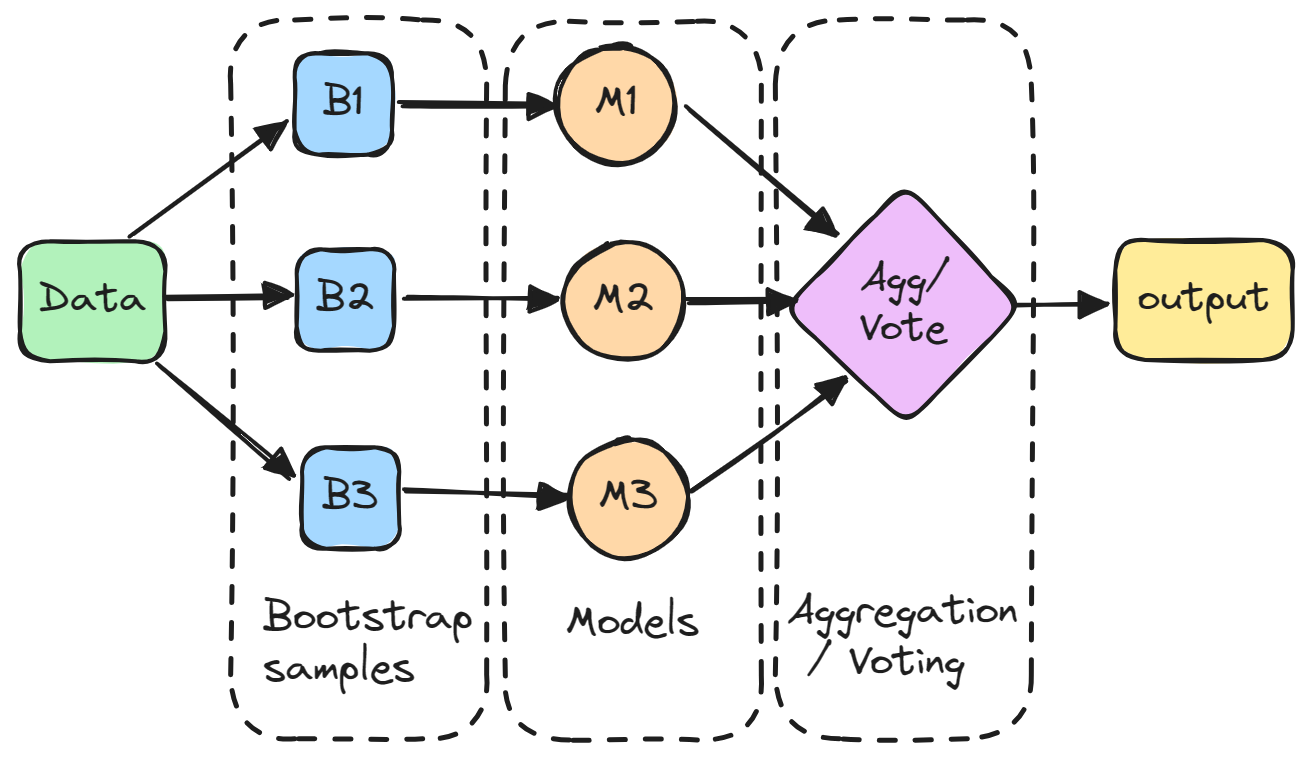
Em detalhes, cada modelo é treinado em um subconjunto aleatório dos dados amostrados com substituição, o que significa que os pontos de dados individuais podem ser escolhidos mais de uma vez. Esse subconjunto aleatório é conhecido como amostra bootstrap. Ao treinar modelos em diferentes bootstraps, o bagging reduz a variação dos modelos individuais. Ele também evita o ajuste excessivo, expondo os modelos constituintes a diferentes partes do conjunto de dados.
As previsões de todos os modelos amostrados são então combinadas por meio de uma média simples para fazer a previsão geral. Dessa forma, o modelo agregado incorpora os pontos fortes dos modelos individuais e cancela seus erros.
O ensacamento é particularmente eficaz para reduzir a variação e o excesso de ajuste, tornando o modelo mais robusto e preciso, especialmente nos casos em que os modelos individuais são propensos a alta variabilidade.
O Boosting é outro método de conjunto popular que é frequentemente comparado ao Bagging. A principal diferença está em como os modelos constituintes são treinados.
No bagging, os modelos são treinados de forma independente e paralela em diferentes subconjuntos aleatórios dos dados. Já no boosting, os modelos são treinados sequencialmente, com cada modelo aprendendo com os erros do modelo anterior. Além disso, o ensacamento normalmente envolve a média simples de modelos, enquanto o aumento atribui pesos com base na precisão.
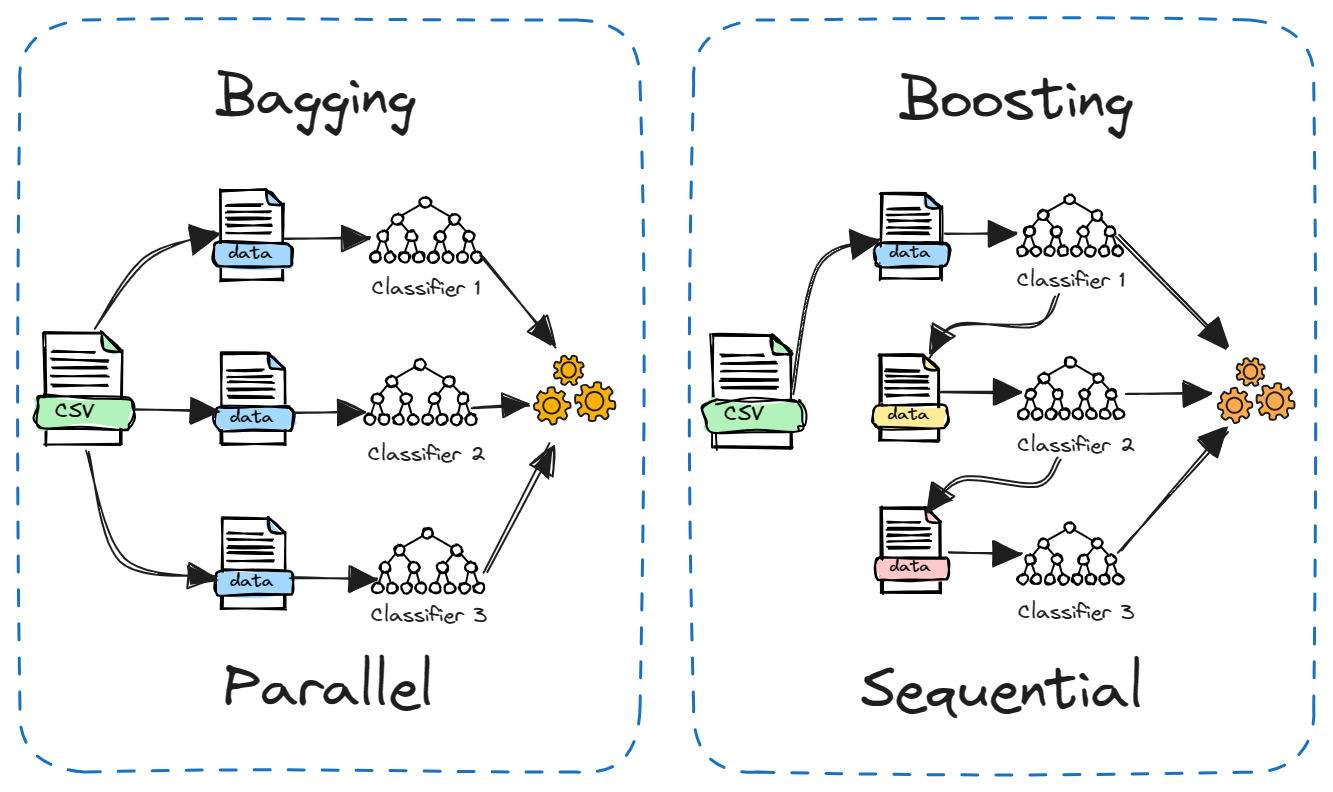
O bagging reduz a variação, enquanto o boosting reduz a tendência. O Bagging pode ser usado com modelos instáveis, como árvores de decisão, enquanto o boosting funciona melhor com modelos estáveis, como regressão linear.
Ambos os métodos têm seus pontos fortes e fracos. O bagging é mais simples de ser executado em paralelo, enquanto o boosting pode ser mais eficiente e preciso. Na prática, é útil testar ambos em um novo problema para ver qual apresenta melhor desempenho.
Aqui estão algumas das principais vantagens do ensacamento:
Neste tutorial em Python, treinaremos um modelo de classificação de árvore de decisão no conjunto de dados de rotatividade de clientes de telecomunicações e usaremos o método de ensemble de ensemble para melhorar o desempenho. Usaremos o DataLab para obter o conjunto de dados e executar nosso código. O código também está disponível nesta pasta de trabalho do DataLab, que você pode copiar para executar no navegador sem instalar nada.
O conjunto de dados sobre a rotatividade de clientes de telecomunicações vem de uma empresa de telecomunicações iraniana. Cada linha do conjunto de dados corresponde à atividade de um cliente ao longo de um ano, incluindo informações sobre falhas de chamadas, duração da assinatura e um rótulo de rotatividade que indica se o cliente abandonou o serviço.
Primeiro, carregaremos o conjunto de dados e visualizaremos as 5 primeiras linhas.
import pandas as pd
customer = pd.read_csv("data/customer_churn.csv")
customer.head()
Depois disso, criaremos variáveis independentes (X) e dependentes (y). Em seguida, dividiremos o conjunto de dados em subconjuntos de treinamento e de teste.
X = customer.drop("Churn", axis=1)
y = customer.Churn
# Split into train and test
from sklearn.model_selection import train_test_split, cross_val_score
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)Criaremos um pipeline simples de aprendizado de máquina e ajustaremos um conjunto de dados de treinamento a ele. O pipeline normalizará os dados antes de alimentar as entradas do classificador de árvore de decisão.
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
pipeline = Pipeline([
('scaler', StandardScaler()),
('classifier', DecisionTreeClassifier(random_state=42))
])
pipeline.fit(X_train, y_train)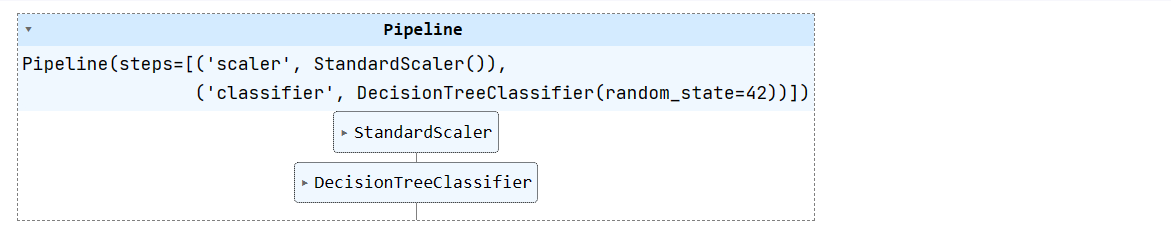
Faça o curso Aprendizado de máquina com modelos baseados em árvores em Python para saber como usar modelos baseados em árvores e conjuntos para regressão e classificação com o scikit-learn.
Avaliaremos um modelo de árvore de decisão para que possamos compará-lo com o modelo de conjunto.
Geraremos relatórios de classificação fazendo previsões em uma planilha de dados de teste.
from sklearn.metrics import classification_report
# Make prediction on the testing data
y_pred = pipeline.predict(X_test)
# Classification Report
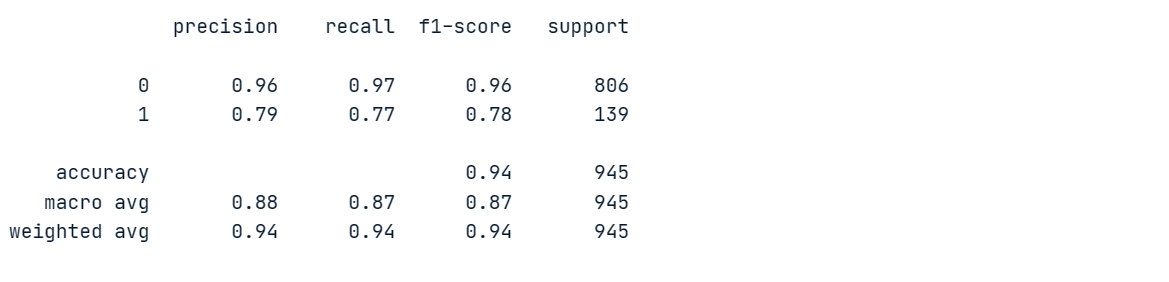
print(classification_report(y_pred, y_test))Nosso modelo alcançou 96% de precisão e 97% de recuperação na classe majoritária "0", mas teve um desempenho ruim na classe minoritária "1".
Para entender melhor o desempenho do modelo, faremos uma validação cruzada e calcularemos as pontuações correspondentes.
# Evaluate the classifier using cross-validation
cv_scores = cross_val_score(pipeline, X, y, cv=5)
print(f"Cross-validation scores: {cv_scores}")
print(f"Mean CV accuracy: {np.mean(cv_scores):.2f}")Há uma grande variação nas pontuações, com máximas de 95% e mínimas de 92%.
Cross-validation scores: [0.95079365 0.94126984 0.93492063 0.94285714 0.92222222]
Mean CV accuracy: 0.94Agora, vamos criar um classificador de ensacamento usando um estimador de base como nosso pipeline (escalar + classificador de árvore de decisão) e treiná-lo em um conjunto de dados de treinamento.
Podemos melhorar o desempenho do modelo aumentando n_estimators, mas 50 é suficiente para os resultados da linha de base.
from sklearn.ensemble import BaggingClassifier
# Create a bagging classifier with the decision tree pipeline
bagging_classifier = BaggingClassifier(base_estimator=pipeline, n_estimators=50, random_state=42)
# Train the bagging classifier on the training data
bagging_classifier.fit(X_train, y_train)
Vamos avaliar os resultados do modelo de conjunto e compará-los com o desempenho do modelo único. Para isso, geraremos relatórios de classificação em um conjunto de dados de teste.
# Make prediction on the testing data
y_pred = bagging_classifier.predict(X_test)
# Classification Report
print(classification_report(y_pred, y_test))Como você pode ver, melhoramos comparativamente o desempenho do modelo. A precisão e a recuperação da classe minoritária aumentaram de 79% para 80% e de 77% para 82%, respectivamente. Isso representa uma melhoria significativa.
Vamos agora calcular a pontuação da validação cruzada.
# Evaluate the classifier using cross-validation
cv_scores = cross_val_score(bagging_classifier, X, y, cv=5)
print(f"Cross-validation scores: {cv_scores}")
print(f"Mean CV accuracy: {np.mean(cv_scores):.2f}")Nossas pontuações de validação cruzada têm baixa variação, variando de 94% a 96%. A precisão geral do modelo também aumentou de 94% para 95%.
Cross-validation scores: [0.95396825 0.95714286 0.94126984 0.96190476 0.95714286]
Mean CV accuracy: 0.95A técnica de ensacamento é uma ferramenta útil em aplicativos de aprendizado de máquina para melhorar a precisão e a estabilidade do modelo.
Aprenda técnicas de conjunto, como bagging, boosting e stacking, para criar modelos avançados e eficazes de aprendizado de máquina em Python com o curso Ensemble Methods in Python.
Ao usar o bagging no aprendizado de máquina, seguir as práticas recomendadas e as dicas pode maximizar sua eficácia:
n_estimators mais alto , como 100-200, ao ensacar para obter o máximo benefício.n_jobs. Implemente-o em várias CPUs/máquinas para um treinamento mais rápido.GridSearchCV. O bom desempenho dos modelos individuais geralmente se traduz em um melhor desempenho do conjunto.Leia as práticas recomendadas de MLOps (operações de aprendizado de máquina) para conhecer as práticas bem-sucedidas de MLOps para uma implantação confiável e dimensionável de sistemas de aprendizado de máquina.
Neste tutorial, exploramos o bagging, uma técnica avançada de aprendizado de máquina de conjunto. O ensacamento agrega vários modelos para melhorar o desempenho preditivo geral. Nós o comparamos com o boosting e aprendemos sobre suas vantagens em relação ao uso de um único modelo.
No final, implementamos um classificador de ensacamento em Python em um conjunto de dados de rotatividade de telecomunicações. O conjunto de árvores de decisão ensacadas melhorou a precisão e o desempenho da classe minoritária em relação a uma única árvore de decisão. Além disso, aprendemos dicas e truques valiosos para maximizar a eficácia do bagging no aprendizado de máquina.
Se você deseja seguir uma carreira como engenheiro de aprendizado de máquina profissional, comece inscrevendo-se no curso de carreira de Cientista de Aprendizado de Máquina com Python. Você aprenderá a treinar modelos supervisionados, não supervisionados e de aprendizagem profunda usando a linguagem de programação Python.
Comece sua jornada de aprendizado de máquina hoje mesmo!
Curso
Curso
Curso
blog
Moez Ali
15 min
blog
Natassha Selvaraj
15 min
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
Tutorial
Amberle McKee

