
Cursus
AWS Cloud Practitioner (CLF-C02)
10 h
Avant de transférer des données, vous devez configurer correctement AWS DataSync. Cette section présente les conditions préalables et les étapes de configuration, notamment l'installation de l'agent, les rôles IAM et la configuration du stockage.
Nous utiliserons AWS CloudFormation pour automatiser le processus de provisionnement et nous nous concentrerons sur la migration des données. Nous allons créer les ressources suivantes :

Figure 1 - Sélection de la région AWS dans la console de gestion AWS
Figure 2 - Création d'une paire de clés pour un accès sécurisé dans AWS EC2
datasync.pem.Dans cette étape, vous utiliserez un modèle CloudFormation pour configurer l'infrastructure AWS nécessaire à AWS DataSync, qui a été mentionnée précédemment.
Figure 3 - Téléchargement d'un modèle CloudFormation pour créer une nouvelle pile.
datasync-onprem.yaml, et cliquez sur Next.
Figure 4 - Examen de l'état de création d'une ressource dans AWS CloudFormation
Dans ce tutoriel, nous répliquons un environnement sur site dans AWS afin d'émuler des scénarios de transfert de données réels à l'aide d'AWS DataSync.
Au lieu d'utiliser une véritable infrastructure sur site, nous avons lancé un serveur NFS sur une instance Amazon EC2, qui sera le système de stockage source. Cela nous permet de tester et de configurer AWS DataSync comme si nous déplacions des données à partir d'un emplacement sur site.
Nous avons lancé les agents AWS DataSync sur des instances EC2 dans le même environnement pour permettre le mouvement des données. Ces agents sont chargés de relier le serveur NFS à AWS DataSync, ce qui permet de transférer des données vers des services de stockage dans le cloud tels qu'Amazon S3.
Cette architecture nous permet d'imiter, de configurer et de valider les tâches AWS DataSync pour obtenir un flux de travail transparent avant de les mettre en œuvre dans un environnement réel sur site. Dans ce tutoriel, nous utiliserons cet environnement pour enregistrer l'agent, créer les tâches DataSync et déplacer les données de manière efficace.
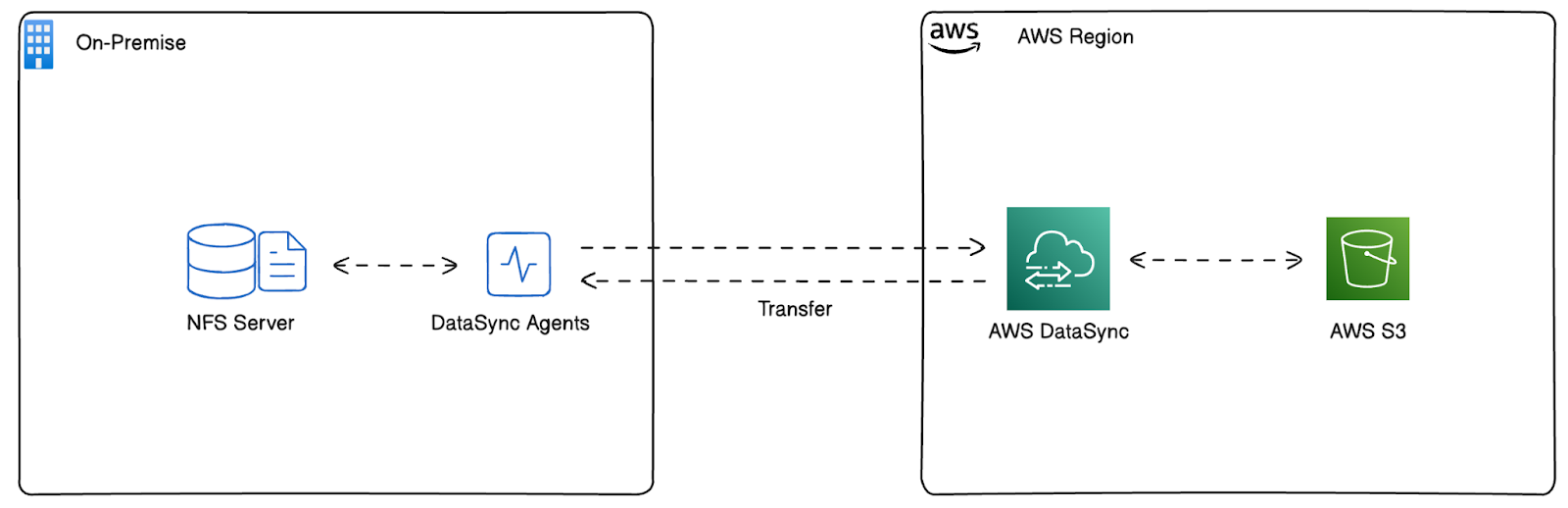
Figure 5 - Architecture déployée par AWS CloudFormation
Avant de configurer AWS DataSync, il est essentiel de comprendre les données que vous allez transférer et leur organisation. Dans cette section, nous allons configurer un serveur NFS déployé dans notre environnement AWS pour qu'il agisse comme un système de stockage sur site. Cette configuration nous permettra de simuler la migration des données vers les services AWS.
Connectez-vous d'abord au serveur NFS :
Parcourez ensuite les systèmes de fichiers. Le serveur NFS contient trois volumes EBS de 200 GiB, chacun formaté avec le système de fichiers XFS et pré-rempli avec des échantillons de données.
mount | grep /mnt
Figure 6 - Résultats attendus de la commande mount
df -h | grep /mnt
Figure 7 - Résultats attendus de la commande df
Comme vous pouvez le voir, fs1 et fs2 contiennent 12 GiB de données, et fs3 contient 22 GiB de données.
Configurons maintenant les exportations NFS. Pour permettre aux agents AWS DataSync d'accéder au serveur NFS, configurez le fichier /etc/exports:
/etc/exports en tant que root à l'aide d'un éditeur de texte :sudo nano /etc/exports/mnt/fs1 10.12.14.243(ro,no_root_squash) 10.12.14.249(ro,no_root_squash)
/mnt/fs2 10.12.14.243(ro,no_root_squash) 10.12.14.249(ro,no_root_squash)
/mnt/fs3 10.12.14.243(ro,no_root_squash) 10.12.14.249(ro,no_root_squash)Remplacez 10.12.14.243 et 10.12.14.249 par les IP privées de vos instances EC2 de l'agent DataSync à partir des sorties de CloudFormation.
sudo systemctl restart nfsshowmount -e
Figure 8 - Résultats attendus de la commande showmount
Une fois le serveur NFS configuré, l'étape suivante consiste à activer la journalisation AWS CloudWatch pour DataSync et à activer les agents DataSync dans l'espace "N". Région "Californie". Ainsi, tous les transferts de fichiers sont enregistrés, ce qui permet de connaître les erreurs ou les défaillances.
Avant qu'AWS DataSync puisse envoyer des journaux à CloudWatch, nous devons créer une politique de ressources qui accorde à DataSync les autorisations nécessaires.
datasync-policy.json sur votre machine locale :{
"Statement": [
{
"Sid": "DataSyncLogsToCloudWatchLogs",
"Effect": "Allow",
"Action": [
"logs:PutLogEvents",
"logs:CreateLogStream"
],
"Principal": {
"Service": "datasync.amazonaws.com"
},
"Resource": "*"
}
],
"Version": "2012-10-17"
}aws logs put-resource-policy --region us-west-1 --policy-name trustDataSync --policy-document file://datasync-policy.jsonLa commande ci-dessus permet à AWS DataSync d'écrire des journaux dans CloudWatch, ce qui permet de surveiller et de déboguer les problèmes de transfert.
Maintenant, activons les agents DataSync. Bien que les instances EC2 de l'agent DataSync aient été créées dans l'environnement "N. Californie", ils doivent être activés dans cette région avant d'être utilisés.
Note : Si vous devez installer l'agent DataSync dans VMware ou dans un autre environnement sur site, reportez-vous au guide officiel AWS. Toutefois, comme nous simulons une configuration sur site à l'aide d'instances EC2, les agents DataSync de ce tutoriel sont déployés en suivant les meilleures pratiques AWS pour les installations basées sur le cloud.
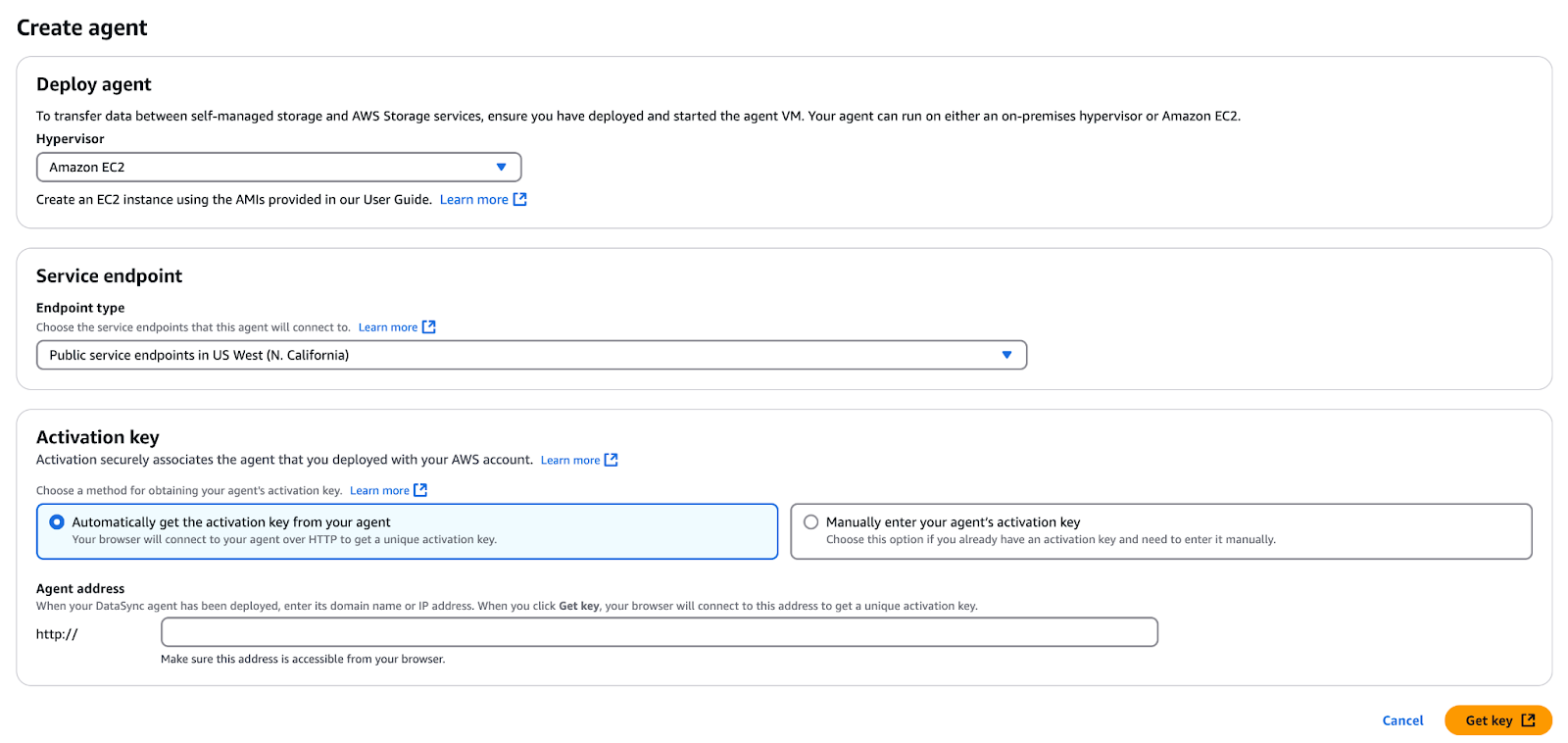
Figure 8 - Créer et activer l'agent DataSync
Créons enfin une tâche DataSync ! Procédez comme suit :
/mnt/fs1/d0001 (copie uniquement le répertoire d0001 ).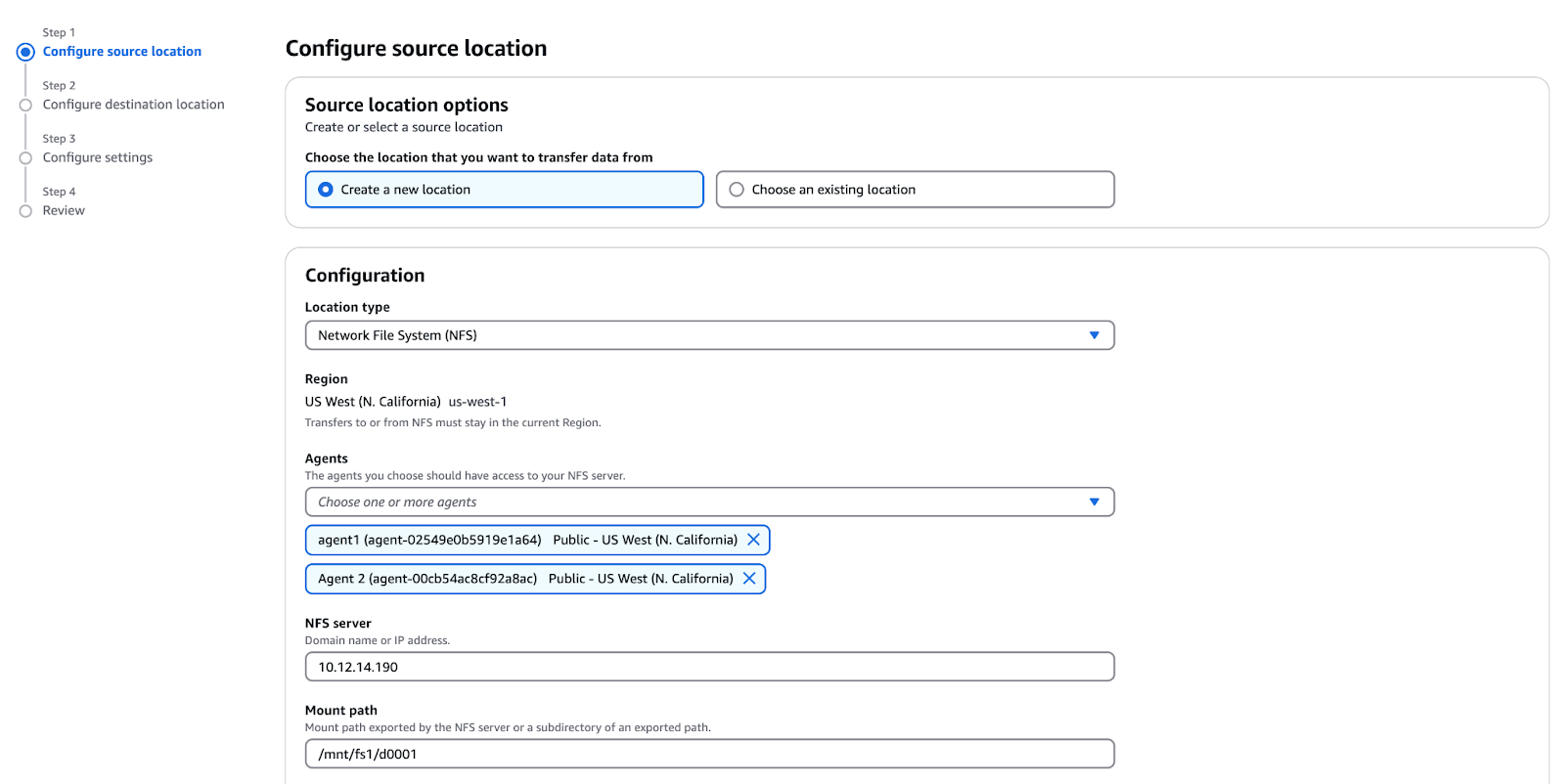
Figure 10 - Configuration de l'emplacement de la source pour AWS DataSync
Une fois AWS DataSync configuré, l'étape suivante consiste à configurer les tâches de transfert de données. Ces tâches définissent comment, quand et où les données seront transférées. AWS DataSync prend en charge diverses options d'optimisation des transferts, notamment le filtrage des fichiers, la planification et la surveillance.
*/.htaccess et */index.htmlDataSyncLogs-datasync-incloud.Après avoir configuré une tâche DataSync, vous devez exécuter le transfert et surveiller sa progression. Cette section explique comment démarrer un transfert manuellement ou par l'intermédiaire de l'interface de commande, comment en suivre l'état et comment résoudre les problèmes les plus courants.

Figure 11 - Liste des tâches AWS DataSync affichant les options de démarrage, de modification ou de suppression de la tâche
Cliquez sur le bouton Tâche l'historique et sélectionnez l'objet d'exécution pour consulter les statistiques de transfert dans la tâche.
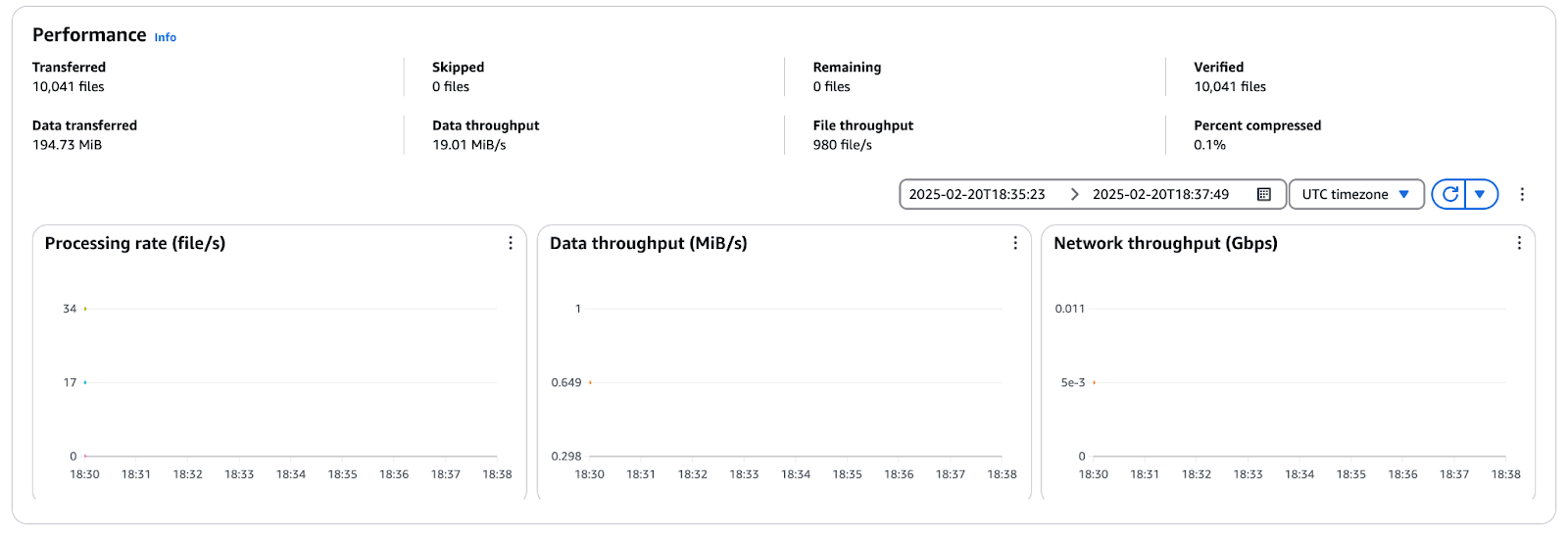
Figure 12 - Mesures de performance d'AWS DataSync indiquant le débit des fichiers, le débit des données et l'utilisation du réseau
Lors des transferts AWS DataSync, des problèmes courants tels que des défaillances de connectivité, des erreurs d'autorisation ou des vitesses de transfert lentes peuvent survenir. Pour résoudre le problème :
Une fois le transfert de données terminé, il est important de vérifier l'intégrité des fichiers transférés et de mettre en place une synchronisation continue si nécessaire. Cette section explique comment vérifier l'exactitude des données, planifier des synchronisations incrémentielles et nettoyer les ressources inutilisées afin d'optimiser les coûts.
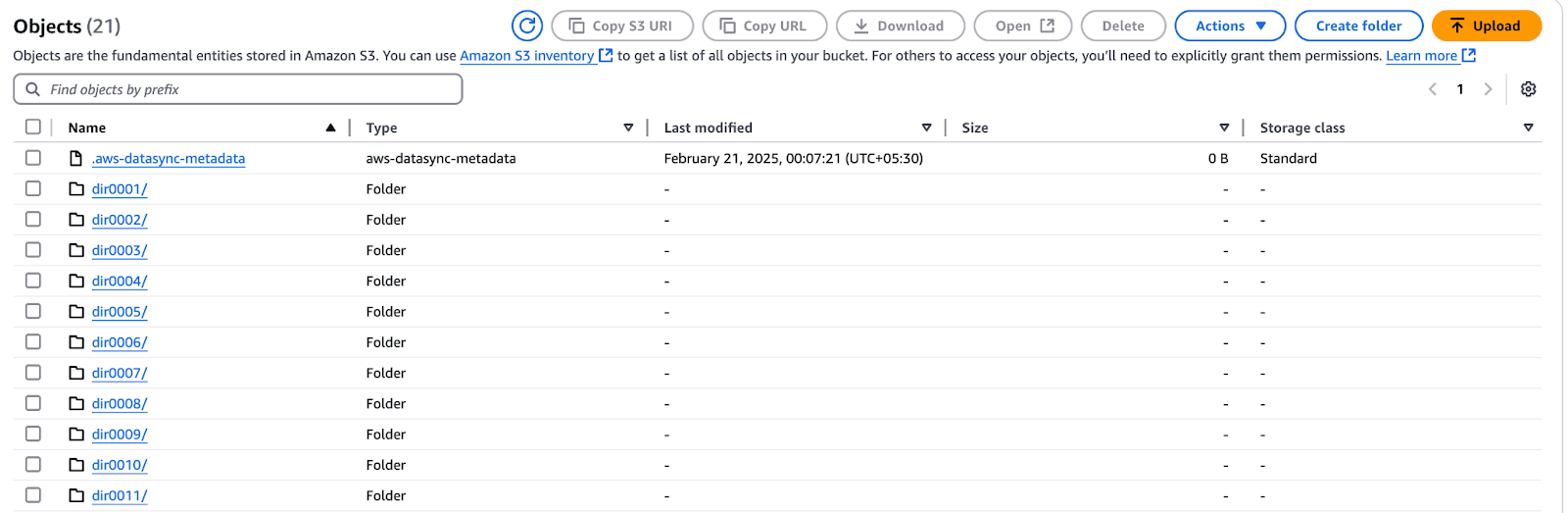
Figure 13 - Seau AWS S3 montrant les fichiers transférés via AWS DataSync
.htaccess et index.html n'ont pas été copiés.Vous pouvez également vérifier les détails de l'exécution de la tâche via la CLI AWS :
aws datasync list-task-executions --region us-west-1 | grep exec-aws datasync describe-task-execution --region us-west-1 --task-execution-arn <task-execution-arn>
Figure 14 - Détails de l'exécution de la tâche AWS DataSync
EstimatedFilesToTransfer BytesTransferred , vitesse de transfert et durée.Dans le monde réel, les fichiers continuent d'être ajoutés et modifiés après le transfert initial. AWS DataSync prend en charge les transferts incrémentiels, ce qui garantit que seuls les fichiers nouveaux ou modifiés sont copiés vers la destination. Dans cette section, nous allons modifier les données sur fs2, exécuter un transfert incrémentiel et optimiser le processus à l'aide de filtres.
Commençons par modifier les fichiers sur fs2.
ssh ec2-user@<NFS-Server-IP>cd /mnt/fs2/d0001/dir0001
dd if=/dev/urandom of=newfile1 bs=1M count=1
echo "newfile1" >> manifest.lstCette opération ajoute un nouveau fichier (newfile1) et modifie manifest.lst.
Ensuite, réexécutez la tâche pour synchroniser les modifications :
newfile1, mise à jour manifest.lst, et mise à jour du dossier).
Figure 15 - Mesures de performance d'AWS DataSync montrant un transfert incrémentiel
newfile1.manifest.lst pour obtenir un horodatage mis à jour.Dans les environnements où les données changent fréquemment, la programmation de synchronisations périodiques garantit que la destination reste à jour avec une intervention manuelle minimale. AWS DataSync vous permet de configurer des tâches à intervalles réguliers (par exemple, toutes les heures, tous les jours ou toutes les semaines), ce qui réduit la charge opérationnelle.
En établissant un calendrier récurrent, DataSync détectera et transférera automatiquement uniquement les fichiers nouveaux et modifiés, optimisant ainsi l'utilisation de la bande passante et l'efficacité du transfert.
Pour planifier une tâche :
Une fois le transfert de données terminé, il est essentiel de nettoyer les ressources inutilisées afin d'éviter les coûts inutiles. Procédez comme suit :
Figure 15 - Confirmation de la suppression de la pile dans AWS
Pour minimiser les dépenses liées au transfert de données, tenez compte des meilleures pratiques suivantes :
En nettoyant correctement les ressources et en optimisant les stratégies de transfert, vous pouvez réduire considérablement les coûts AWS tout en maintenant une synchronisation efficace des données.
Au-delà des transferts de base, AWS DataSync offre des fonctionnalités puissantes qui améliorent les performances, la rentabilité et la sécurité. Cette section explore les principaux cas d'utilisation avancés, notamment l'intégration de S3 et la migration de NFS vers EFS.
AWS DataSync est un outil puissant pour déplacer de grandes quantités de données vers et depuis S3 et est idéal pour les tâches de sauvegarde, d'archivage et de migration vers le cloud. Il améliore les performances grâce aux téléchargements en plusieurs parties, qui divisent les fichiers volumineux en parties plus petites et les transfèrent ensuite en parallèle. En outre, l'intégration de DataSync avec les classes de stockage S3 permet aux utilisateurs de réaliser des économies en migrant les données moins actives vers S3 Glacier ou S3 Intelligent-Tiering.
Dans ce tutoriel, nous avons expliqué comment configurer une tâche DataSync, mettre en place une source NFS et déplacer des fichiers vers un panier S3, tout en excluant les fichiers indésirables. Vous pouvez utiliser ces étapes pour planifier des déplacements de données importants avec peu ou pas d'impact opérationnel.
Pour les entreprises qui doivent migrer des partages NFS sur site vers Amazon EFS, la solution est automatisée, sécurisée et évolutive : AWS DataSync. Le problème est que S3 est un système de stockage d'objets. Parallèlement, Amazon EFS (Elastic File System) est un service de stockage de fichiers entièrement géré et conforme à la norme POSIX, ce qui en fait un bon choix pour les applications nécessitant un accès partagé et une faible latence.
Voici comment DataSync vous aide à migrer de NFS à EFS :
Bien que ce tutoriel soit basé sur la migration de NFS vers S3, les mêmes principes de DataSync peuvent être utilisés lors de la migration vers Amazon EFS. La principale variation consiste à choisir EFS comme cible afin que le mouvement des données soit bien exécuté pour les applications qui ont besoin d'un système de fichiers avec une mise à l'échelle dynamique dans AWS.
Pour tirer le meilleur parti d'AWS DataSync, il est essentiel de suivre les meilleures pratiques qui améliorent la vitesse, la sécurité et la rentabilité. Cette section présente des stratégies clés pour optimiser les transferts de données, garantir la sécurité des données et gérer efficacement le contrôle.
Pour les migrations de données à grande échelle, AWS Direct Connect (DX) est une connexion deréseau privé dédié qui évite l'internet public et permet des transferts plus rapides, plus sûrs et avec une latence plus faible. Si DX n'est pas disponible, d'autres solutions, comme lesconnexions VPN ou le peering VPC, peuvent améliorer les vitesses de transfert tout en maintenant la sécurité.
De plus, AWS DataSync intègre lacompression qui réduit la quantité de données déplacées sur le réseau, augmentant ainsi les vitesses et minimisant les coûts de la bande passante. Cependant, comme la compression utilise des ressources de l'unité centrale, il est essentiel de comparer les avantages en termes de performances avec les éventuels frais généraux du système.
En outre, la planification des tâches et la configuration peuvent être optimisées pour améliorer encore les performances de DataSync. La reprogrammation des transferts aux heures creuses permet d'éviter le trafic sur le réseau et de garantir la disponibilité de la bande passante, en particulier lors du transfert de fichiers volumineux. Le réglage fin de la taille de la mémoire tampon et de plusieurs flux de transfert parallèles en fonction de la capacité du réseau et du stockage améliore considérablement le débit.
Pour les flux de fichiers de petite taille, l'augmentation du niveau de parallélisme réduit le temps nécessaire au transfert des données. En revanche, une gestion efficace de la mémoire tampon améliore les performances et la fiabilité des fichiers volumineux.
Toutes les données transférées par AWS DataSync sont cryptées en transit via TLS pour garantir un transfert réseau sécurisé. Le chiffrement des services de stockage de destination, notamment Amazon S3, Amazon EFS et Amazon FSx, doit également être activé. Pour augmenter le niveau de protection lors de l'utilisation de S3, active égalementle chiffrement côté serveur.
Lorsque vous attribuez des rôles IAM pour les tâches DataSync, suivez le principe du moindre privilège. Pour minimiser les risques de sécurité, n'accordez que les autorisations nécessaires aux agents DataSync et aux rôles d'exécution des tâches. Évitez d'utiliser des clés de politique basées sur des balises et utilisez plutôt des politiques basées sur les ressources afin d'éviter les altérations imprévues des données.
Pour les transferts de données intra-VPC, activez les points d'extrémité VPC pour qu'ils participent au trafic DataSync au sein du réseau AWS sans passer par l'Internet public. Cela permet de réduire les risques de sécurité et d'améliorer les performances lors du transfert de données entre différents services AWS.
L'agent DataSync doit être exécuté en toute sécurité, conformément aux nouvelles recommandations relatives à la sécurité du système d'exploitation et à la segmentation du réseau. Il doit également être misà jour à l'adresse et les politiques de sécurité du groupe AWS doivent être appliquées pour interdire tout accès non autorisé.
Une surveillance efficace permet de garantir la réussite et l'optimisation des transferts de données dans AWS DataSync. Ce cursus a également montré comment s'intégrer à CloudWatch pour assurer un suivi en temps réel de l'exécution des tâches, des vitesses de transfert, des taux d'erreur et du débit. L'examen des journaux des tâches permet d'identifier les problèmes, de vérifier l'intégrité des fichiers et de résoudre les échecs de transfert.
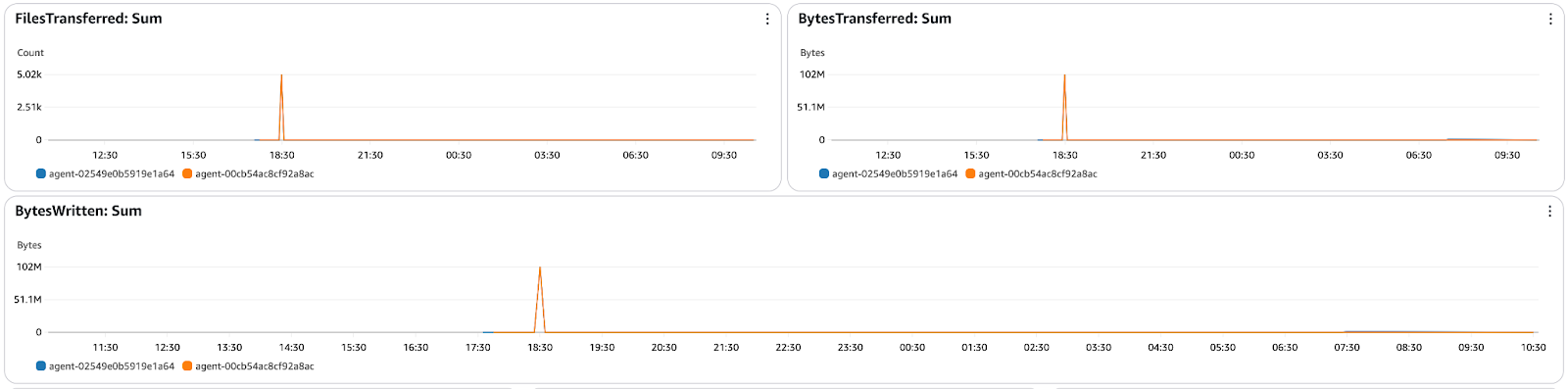
Figure 16 - Tableau de bord de surveillance AWS DataSync CloudWatch indiquant les fichiers et les octets transférés
En outre,les alarmes de CloudWatchsignalent les échecs de transfert ou les problèmes de performance, qui peuvent survenir avant qu'ils ne soient censés se produire et peuvent être traités avant qu'ils ne deviennent un problème plus important.
Bien qu'AWS DataSync automatise les transferts de données, vous pouvez rencontrer des problèmes de connectivité, des erreurs de permission ou des incohérences dans les données. Cette section fournit des solutions aux problèmes courants, explique comment déboguer à l'aide des journaux et assure une synchronisation fluide des données.
Les utilisateurs d'AWS DataSync peuvent rencontrer des délais d'attente, des problèmes d'autorisation ou des erreurs d'intégrité des données pendant les transferts. Voici quelques problèmes courants et leurs solutions :
Pour dépanner efficacement les tâches AWS DataSync, les journaux fournissent des informations précieuses sur les échecs de transfert, les fichiers ignorés et les erreurs de réseau. Ce tutoriel a montré l'intégration de CloudWatch pour la surveillance et le débogage des exécutions de DataSync.
Voici comment vérifier les journaux des tâches DataSync :

Figure 17 - Flux de journaux AWS CloudWatch pour l'exécution de la tâche DataSync
Ensuite, configurez les alarmes CloudWatch pour les défaillances :
AWS DataSync simplifie les transferts de données automatisés, sécurisés et efficaces entre les environnements sur site et les services de stockage AWS tels que Amazon S3, EFS et FSx. Ce tutoriel propose une approche pratique de la configuration de DataSync, de la mise en place de NFS en tant que source et du transfert de données tout en garantissant la sécurité et les performances.
Nous avons étudié les transferts incrémentiels, la planification des tâches et la surveillance par CloudWatch afin d'optimiser DataSync en termes de coût, de vitesse et de fiabilité. En outre, les étapes de dépannage et les techniques d'analyse des journaux permettent de diagnostiquer et de résoudre efficacement les problèmes de transfert.
Si vous ne connaissez pas encore AWS ou si vous souhaitez approfondir votre compréhension des concepts et des services cloud, je vous recommande de consulter ces ressources d'apprentissage connexes :
Ces cours sont un excellent moyen d'acquérir des connaissances fondamentales et de se préparer à des scénarios de cloud réels utilisant AWS !
Apprenez-en plus sur AWS grâce à ces cours !
Cursus
Cours
Cours