
Cursus
AWS Cloud Practitioner (CLF-C02)
10 h
De nombreuses entreprises choisissent de passer à AWS MSK pour éviter les problèmes opérationnels liés à la gestion des clusters Apache Kafka.
Dans ce tutoriel, nous allons explorer les caractéristiques, les avantages et les meilleures pratiques d'AWS MSK. Nous passerons également en revue les étapes de base pour configurer AWS MSK et nous verrons comment il se compare à d'autres services populaires tels que Kinesis et Confluent.
Tout d'abord, nous allons comprendre Apache Kafka et pourquoi il est si utile pour le streaming de données.
Apache Kafka est une plateforme de streaming distribuée en open-source qui gère des flux de données en temps réel et permet de créer des applications pilotées par les événements. Il peut ingérer et traiter des données en continu au fur et à mesure qu'elles se présentent.
Selon le site web de Kafka, plus de 80 % des entreprises du classement Fortune 100 font confiance à Kafka et l'utilisent.
Plus important encore, Kafka est évolutif et très rapide. Cela signifie qu'il peut traiter beaucoup plus de données que ce que pourrait contenir une seule machine, et ce avec une latence très faible.
Si vous souhaitez apprendre à créer, gérer et dépanner Kafka pour le streaming de données, envisagez de suivre le cours Introduction à Kafka.
Quel est le meilleur moment pour utiliser Apache Kafka ?
Cependant, la gestion des instances Kafka peut s'accompagner de nombreux maux de tête. C'est là qu'intervient AWS MSK.

Image par l'auteur
AWS MSK (Managed Streaming for Kafka) est un service entièrement géré qui prend en charge l'approvisionnement, la configuration, la mise à l'échelle et la maintenance des clusters Kafka. Vous pouvez l'utiliser pour créer des applications qui réagissent instantanément aux flux de données.
Kafka est souvent utilisé dans le cadre d'une installation de traitement de données plus importante, et AWS MSK facilite encore la création de pipelines de données en temps réel qui déplacent des données entre différents systèmes.
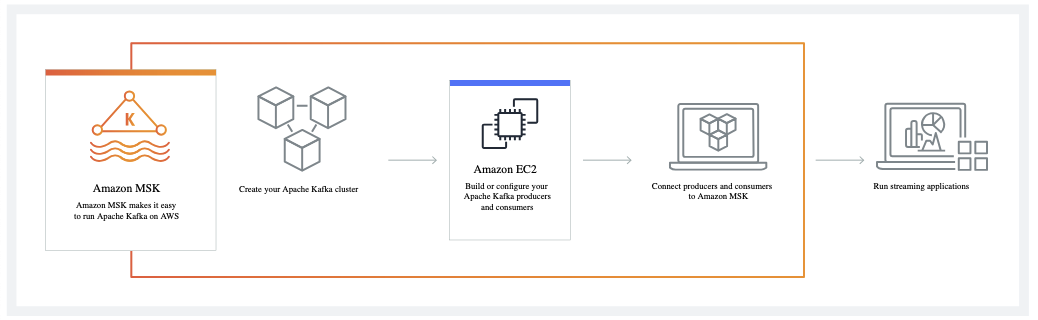
Comment fonctionne Amazon MSK. Source de l'imagee : AWS
Si vous ne connaissez pas encore AWS, vous pouvez suivre notre cours Introduction à AWS pour vous familiariser avec les principes de base. Lorsque vous serez prêt, vous pourrez passer à notre cours sur la technologie et les services cloud AWS pour explorer l'ensemble des services sur lesquels les entreprises s'appuient.
AWS MSK se distingue de la concurrence par le fait qu'il s'agit d'un service entièrement géré. Vous n'avez pas à vous préoccuper de la mise en place de serveurs ou des mises à jour.
Mais ce n'est pas tout. Ces cinq caractéristiques clés du système AWS MSK en font un investissement rentable :
Comme nous l'avons déjà vu, AWS MSK offre une valeur immédiate grâce à sa disponibilité, son évolutivité, sa sécurité et sa facilité d'intégration. Ces avantages fondamentaux en ont fait le choix privilégié des entreprises qui exécutent des charges de travail Kafka dans le cloud.
AWS MSK résout quatre problèmes critiques auxquels tout projet de flux de données est confronté :
Pour commencer avec AWS MSK, créez d'abord votre compte AWS. Si vous utilisez AWS pour la première fois, apprenez à configurer votre compte AWS grâce à notre tutoriel complet.
Connectez-vous à la console de gestion AWS et ouvrez la console MSK. Cliquez sur "Créer un cluster" pour lancer le processus d'installation.

Démarrer avec AWS MSK. Image source : AWS
Sélectionnez "Création rapide" pour les paramètres par défaut, puis entrez un nom de cluster descriptif.
À partir de là, vous pouvez sélectionner de nombreuses options supplémentaires, qui dépendent toutes de vos propres besoins pour votre cluster. Voici un bref aperçu des choix possibles :
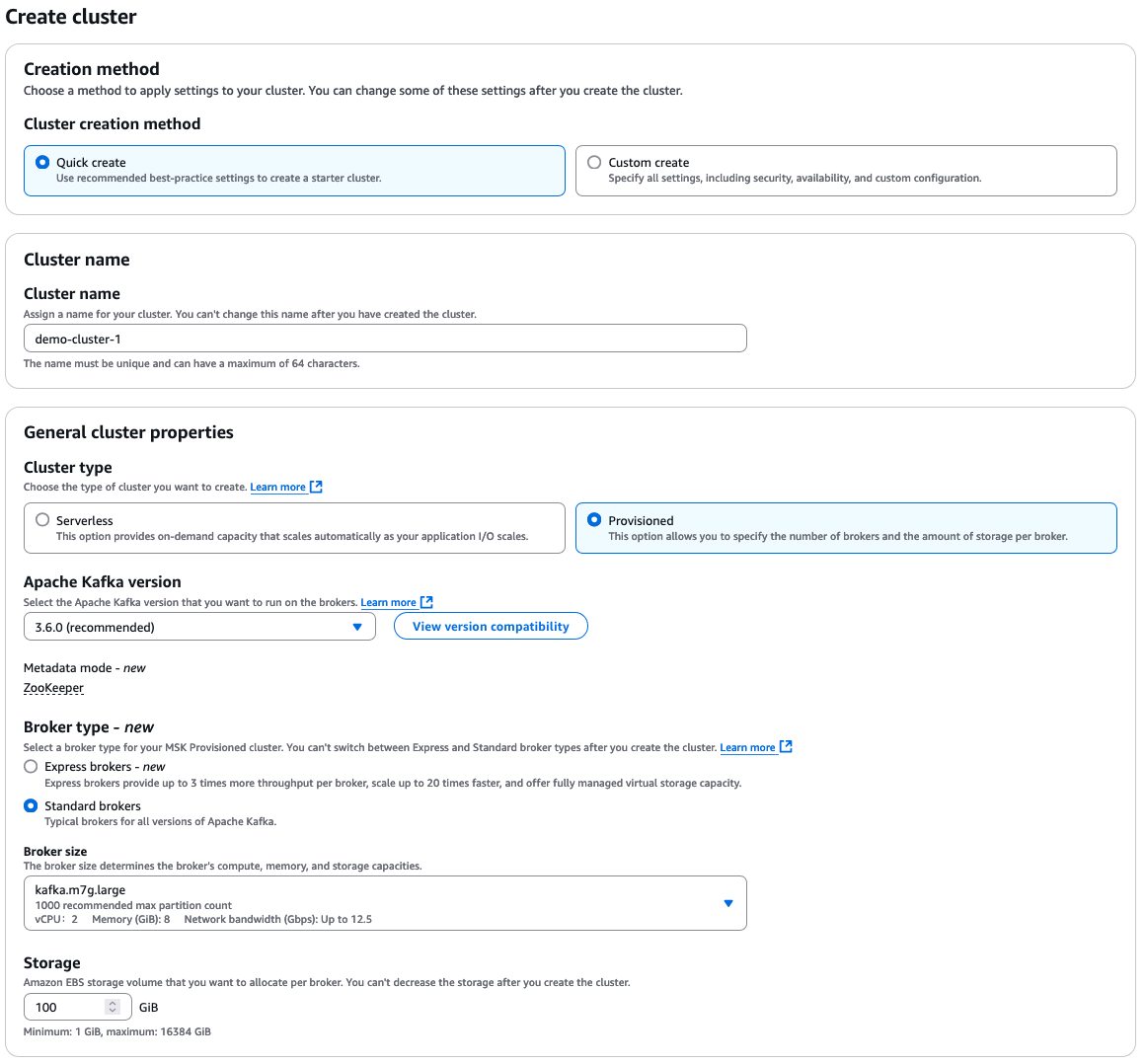
Options de configuration de l'AWS MSK
Le cluster est toujours créé au sein d'un Amazon VPC. Vous pouvez choisir d'utiliser le VPC par défaut ou de configurer et de spécifier un VPC personnalisé.
Il ne vous reste plus qu'à attendre que votre cluster soit activé, ce qui peut prendre de 15 à 30 minutes. Vous pouvez surveiller l'état de votre cluster à partir de la page de résumé du cluster, où vous verrez l'état passer de "Création" à "Actif".
Une fois que votre cluster MSK est installé, vous devez créer une machine cliente pour produire et consommer des données sur un ou plusieurs sujets. Étant donné qu'Apache Kafka s'intègre si bien à de nombreux producteurs de données (tels que les sites web, les appareils IoT, les instances Amazon EC2, etc.), MSK partage également cet avantage.
Apache Kafka organise les données dans des structures appelées "topics". Chaque thème se compose d'une ou de plusieurs partitions. Les partitions représentent le degré de parallélisme dans Apache Kafka. Les données sont réparties entre les courtiers à l'aide d'un partitionnement des données.
Termes clés à connaître lorsque vous travaillez avec des clusters Apache Kafka :
Lorsque vous construisez une architecture pilotée par les événements avec AWS MSK, vous devez configurer plusieurs couches, dont MSK est le principal composant d'ingestion de données. Voici un aperçu des couches qui peuvent être nécessaires :
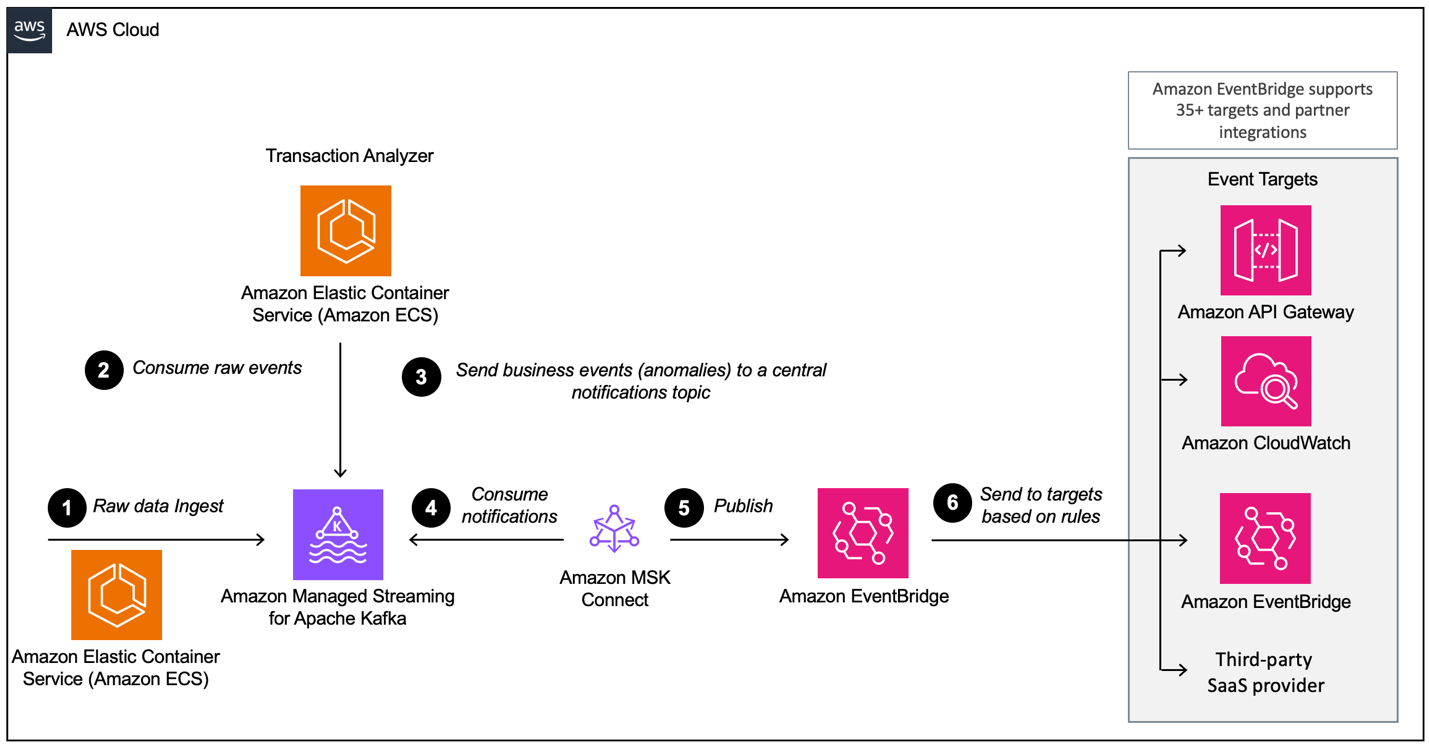
Exemple d'une architecture pilotée par les événements avec Amazon MSK et Amazon EventBridge. Source de l'image : AWS
Si vous souhaitez tirer parti de Python dans vos flux de travail de pipeline de données , consultez notre cours Introduction à AWS Bython en Python.
AWS MSK est relativement simple à mettre en place et à utiliser immédiatement. Cependant, certaines bonnes pratiques essentielles amélioreront les performances de vos clusters et vous feront gagner du temps par la suite.
Vous devrez choisir le bon nombre de partitions par courtier et le bon nombre de courtiers par grappe.
Un certain nombre de facteurs peuvent influencer vos décisions, mais AWS vous propose quelques recommandations et ressources pratiques pour vous guider dans ce processus.
En outre, AWS fournit une feuille de calcul facile à utiliser pour vous aider à estimer la taille de votre cluster et les coûts associés à l'utilisation d'AWS MSK par rapport à un cluster EC2 Kafka similaire autogéré.
AWS vous recommande de configurer vos clusters pour qu'ils soient hautement disponibles. Ceci est particulièrement important lors d'une mise à jour (comme la mise à jour de la version d'Apache Kafka) ou lorsqu'AWS remplace un courtier.
Pour garantir la haute disponibilité de vos grappes, vous devez procéder à trois opérations :
L'avantage d'AWS est qu'il s'engage à respecter des accords de niveau de service stricts pour les déploiements multi-zones, faute de quoi vous récupérez vos crédits.
L'utilisation du disque et de l'unité centrale sont deux paramètres clés à surveiller par le biais d'AWS CloudWatch. Cela vous permettra non seulement d'assurer le bon fonctionnement de votre système, mais aussi de réduire les coûts.
La meilleure façon de gérer l'utilisation des disques et les coûts de stockage associés est de mettre en place une alarme CloudWatch qui vous avertit lorsque l'utilisation des disques dépasse une certaine valeur, par exemple 85 %, et d'ajuster vos politiques de conservation. La définition d'une durée de conservation des messages dans votre journal peut grandement contribuer à libérer automatiquement de l'espace disque.
En outre, pour maintenir les performances de votre cluster et éviter les goulets d'étranglement, AWS vous recommande de maintenir l'utilisation totale du CPU pour vos courtiers à moins de 60 %. Vous pouvez surveiller ce phénomène à l'aide d'AWS CloudWatch et prendre des mesures correctives en mettant à jour la taille de votre courtier, par exemple.
Par défaut, AWS chiffre les données en transit entre les courtiers de votre cluster MSK. Vous pouvez désactiver cette fonction si votre système fait l'objet d'une utilisation élevée de l'unité centrale ou d'une latence importante. Toutefois, il est fortement recommandé de toujours activer le chiffrement en transit et de trouver d'autres moyens d'améliorer les performances si cela vous pose un problème.
Consultez notre cours sur la sécurité AWS et la gestion des coûts pour en savoir plus sur la façon de sécuriser et d'optimiser votre environnement cloud AWS et de gérer les coûts et les ressources dans AWS.
Lorsqu'il s'agit de choisir l'outil le mieux adapté à un projet, il est souvent nécessaire d'évaluer plusieurs options. Voici les alternatives les plus courantes à l'AWS MSK et leur comparaison.
Le principal compromis entre MSK et une option auto-hébergée utilisant EC2 est entre la commodité et le contrôle : MSK vous donne moins à gérer mais moins de flexibilité, tandis qu'EC2 vous donne un contrôle total mais nécessite plus de travail.
AWS MSK prend en charge toutes les tâches opérationnelles complexes, avec un provisionnement et une configuration automatiques. L'avantage est qu'il n'y a pas de coûts d'infrastructure initiaux. Il y a également une intégration transparente avec d'autres services AWS et des fonctions de sécurité robustes.
L'utilisation de Kafka sur EC2, en revanche, implique une installation et une configuration plus manuelles, et vous devez également vous charger vous-même de la maintenance et des mises à jour. Cette solution offre beaucoup plus de souplesse, mais peut s'accompagner d'une plus grande complexité et de coûts opérationnels plus élevés, et peut nécessiter des équipes plus qualifiées.
Utilisez Kinesis pour la simplicité et l'intégration AWS approfondie et MSK pour la compatibilité avec Kafka ou un meilleur contrôle de votre configuration de streaming.
Kinesis est une architecture entièrement sans serveur qui utilise les "shards" pour le flux de données. AWS gère tout pour vous. Toutefois, il existe des limites à la conservation des données dont il faut tenir compte. Kinesis est une excellente solution pour les besoins simples en matière de flux de données.
AWS MSK s'appuie sur le modèle de sujet et de partition de Kafka, avec une rétention de données virtuellement illimitée, en fonction de votre stockage. Il s'agit d'une solution plus flexible et personnalisable que vous pouvez migrer hors d'AWS si nécessaire.
Si vous ne connaissez pas Kinesis, nous avons un cours qui vous guide pour travailler avec des données en continu à l'aide d'AWS Kinesis et Lambda.
Choisissez Confluent si vous avez besoin de fonctionnalités et d'un support complets, et choisissez MSK si vous êtes fortement investi dans AWS et que vous disposez d'une expertise Kafka en interne.
Confluent dispose d'un ensemble de fonctionnalités riches avec de nombreux connecteurs intégrés. Il s'agit d'une option plus coûteuse dans l'ensemble, mais elle propose un niveau gratuit avec des fonctionnalités limitées. Confluent fonctionne bien pour les charges de travail irrégulières et son processus de déploiement est plus simple.
En comparaison, AWS est plus rationalisé et se concentre sur les fonctionnalités de base de Kafka. Pour accéder à un ensemble de fonctionnalités plus étendu, AWS MSK doit être intégré à d'autres services AWS. Heureusement, cette intégration est transparente. AWS MSK a un coût de base plus faible et peut être une bonne option pour les charges de travail régulières.
Le tableau suivant propose une comparaison entre le système AWS MSK et ses alternatives :
|
Fonctionnalité |
AWS MSK |
Apache Kafka sur EC2 |
Kinesis |
Confluent |
|
Déploiement |
Gestion complète |
Autogestion sur EC2 |
Gestion complète |
Entièrement géré ou autogéré |
|
Facilité d'utilisation |
Facile à mettre en place et à gérer |
Nécessite une configuration et une mise à l'échelle manuelles |
Configuration simple ; native AWS |
Interface utilisateur conviviale et outils avancés |
|
Évolutivité |
Mise à l'échelle automatique avec réglages manuels |
Mise à l'échelle manuelle |
Une mise à l'échelle sans faille |
Mise à l'échelle automatique avec flexibilité |
|
Temps de latence |
Faible latence |
Faible latence |
Temps de latence réduit pour les petites charges utiles |
Comparable à MSK |
|
Soutien au protocole |
Compatible avec l'API Kafka |
Compatible avec l'API Kafka |
Protocole propriétaire Kinesis |
API Kafka et protocoles additionnels |
|
Conservation des données |
Configurable (jusqu'à 7 jours par défaut) |
Configurable |
Configurable (max 365 jours) |
Hautement configurable |
|
Suivi et mesures |
Intégré à CloudWatch |
Nécessite une configuration personnalisée |
Intégré à CloudWatch |
Outils de surveillance avancés |
|
Coût |
Pay-as-you-go |
Basé sur la tarification des instances EC2 |
Pay-as-you-go |
Sur abonnement |
|
Sécurité |
Fonctions de sécurité AWS intégrées |
Doit configurer la sécurité manuellement |
Intégré à AWS IAM |
Fonctions de sécurité complètes |
|
Adéquation du cas d'utilisation |
Le meilleur pour les utilisateurs de Kafka dans l'écosystème AWS |
Flexible, mais exigeant beaucoup d'entretien |
Le meilleur pour les applications natives AWS |
Utilisateurs avancés de Kafka et entreprises |
Apache Kafka est le choix idéal pour les situations où vous avez besoin d'une solution fiable à grande échelle qui ne peut pas se permettre de perdre des données et qui nécessite de connecter plusieurs sources de données ou de construire des pipelines de données complexes. AWS MSK évite de nombreux maux de tête liés à la mise en place et à la configuration des clusters Kafka, ce qui permet aux développeurs de se concentrer sur la création et l'amélioration des applications plutôt que sur l'infrastructure.
L'obtention d'une certification AWS est un excellent moyen de démarrer votre carrière dans ce domaine. Vous pouvez développer vos compétences AWS en consultant notre catalogue de cours et en acquérant une expérience pratique par le biais de projets!
Apprenez-en plus sur AWS grâce à ces cours !
Cursus
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach