
Lernpfad
AWS Cloud Practitioner (CLF-C02)
10 Std.
Viele Unternehmen entscheiden sich für den Wechsel zu AWS MSK, um die mit der Verwaltung von Apache Kafka-Clustern verbundenen betrieblichen Probleme zu vermeiden.
In diesem Lernprogramm werden wir die Funktionen, Vorteile und bewährten Verfahren von AWS MSK kennenlernen. Wir werden auch die grundlegenden Schritte zur Einrichtung von AWS MSK durchgehen und sehen, wie es im Vergleich zu anderen beliebten Diensten wie Kinesis und Confluent abschneidet.
Zuerst wollen wir Apache Kafka verstehen und warum es so nützlich für das Datenstreaming ist.
Apache Kafka ist eine Open-Source-Plattform für verteiltes Streaming, die Datenströme in Echtzeit verarbeiten und ereignisgesteuerte Anwendungen erstellen kann. Es kann Streaming-Daten aufnehmen und verarbeiten, während sie entstehen.
Laut der Kafka-Website vertrauen über 80 % der Fortune-100-Unternehmen auf Kafka und nutzen es.
Am wichtigsten ist, dass Kafka skalierbar und sehr schnell ist. Das bedeutet, dass sie viel mehr Daten verarbeiten kann, als auf eine einzige Maschine passen würden, und das bei extrem niedriger Latenz.
Wenn du lernen möchtest, wie du Kafka für das Datenstreaming erstellst, verwaltest und Fehler behebst, solltest du den Kurs Einführung in Kafka besuchen.
Wann ist der beste Zeitpunkt, um Apache Kafka zu nutzen?
Die Verwaltung von Kafka-Instanzen kann jedoch eine Menge Kopfschmerzen bereiten. An dieser Stelle kommt AWS MSK ins Spiel.

Bild vom Autor
AWS MSK (Managed Streaming for Kafka) ist ein vollständig verwalteter Service, der die Bereitstellung, Konfiguration, Skalierung und Wartung von Kafka-Clustern übernimmt. Du kannst damit Apps entwickeln, die sofort auf Datenströme reagieren.
Kafka wird oft als Teil eines größeren Datenverarbeitungssystems verwendet, und AWS MSK macht es noch einfacher, Echtzeit-Datenpipelines zu erstellen, die Daten zwischen verschiedenen Systemen übertragen.
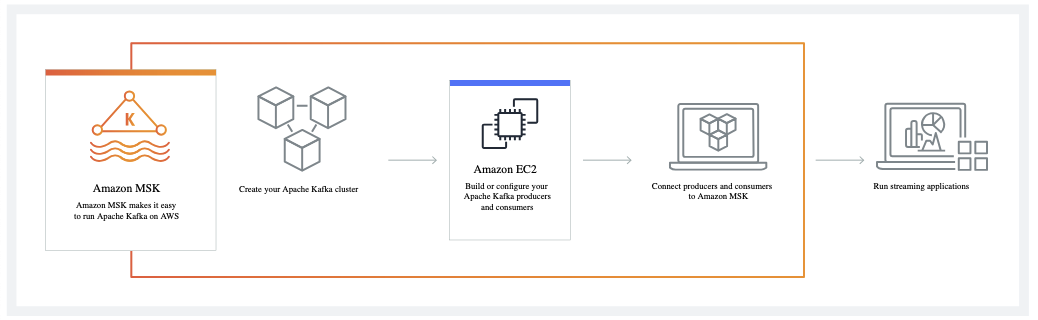
Wie Amazon MSK funktioniert. Bildquellee: AWS
Wenn du neu bei AWS bist, solltest du unseren Kurs Einführung in AWS besuchen, um dich mit den Grundlagen vertraut zu machen. Wenn du bereit bist, kannst du mit unserem Kurs AWS Cloud-Technologie und -Services weitermachen, um die gesamte Palette an Services kennenzulernen, auf die sich Unternehmen verlassen.
AWS MSK hebt sich von der Konkurrenz ab, weil es ein vollständig verwalteter Dienst ist. Du musst dich nicht um die Einrichtung von Servern oder um Updates kümmern.
Aber das ist noch nicht alles. Diese fünf Hauptmerkmale von AWS MSK machen es zu einer lohnenden Investition:
Wie wir bereits gesehen haben, bietet AWS MSK aufgrund seiner Verfügbarkeit, Skalierbarkeit, Sicherheit und einfachen Integration einen unmittelbaren Mehrwert. Diese Kernvorteile haben es zur ersten Wahl für Unternehmen gemacht, die Kafka-Workloads in der Cloud betreiben.
AWS MSK löst vier entscheidende Herausforderungen, mit denen jedes Datenstreaming-Projekt konfrontiert ist:
Um mit AWS MSK loszulegen, musst du zunächst dein AWS-Konto erstellen. Wenn du AWS zum ersten Mal nutzt, erfährst du in unserem umfassenden Tutorial , wie du dein AWS-Konto einrichtest und konfigurierst.
Melde dich bei der AWS Management Console an und öffne die MSK-Konsole. Klicke auf "Cluster erstellen", um den Einrichtungsprozess zu starten.

Erste Schritte mit AWS MSK. Bild sauerce: AWS
Wähle "Schnell erstellen" für die Standardeinstellungen und gib dann einen beschreibenden Clusternamen ein.
Von dort aus hast du viele weitere Optionen zur Auswahl, die alle von deinen eigenen Anforderungen an deinen Cluster abhängen. Hier ist ein kurzer Überblick über die Auswahlmöglichkeiten:
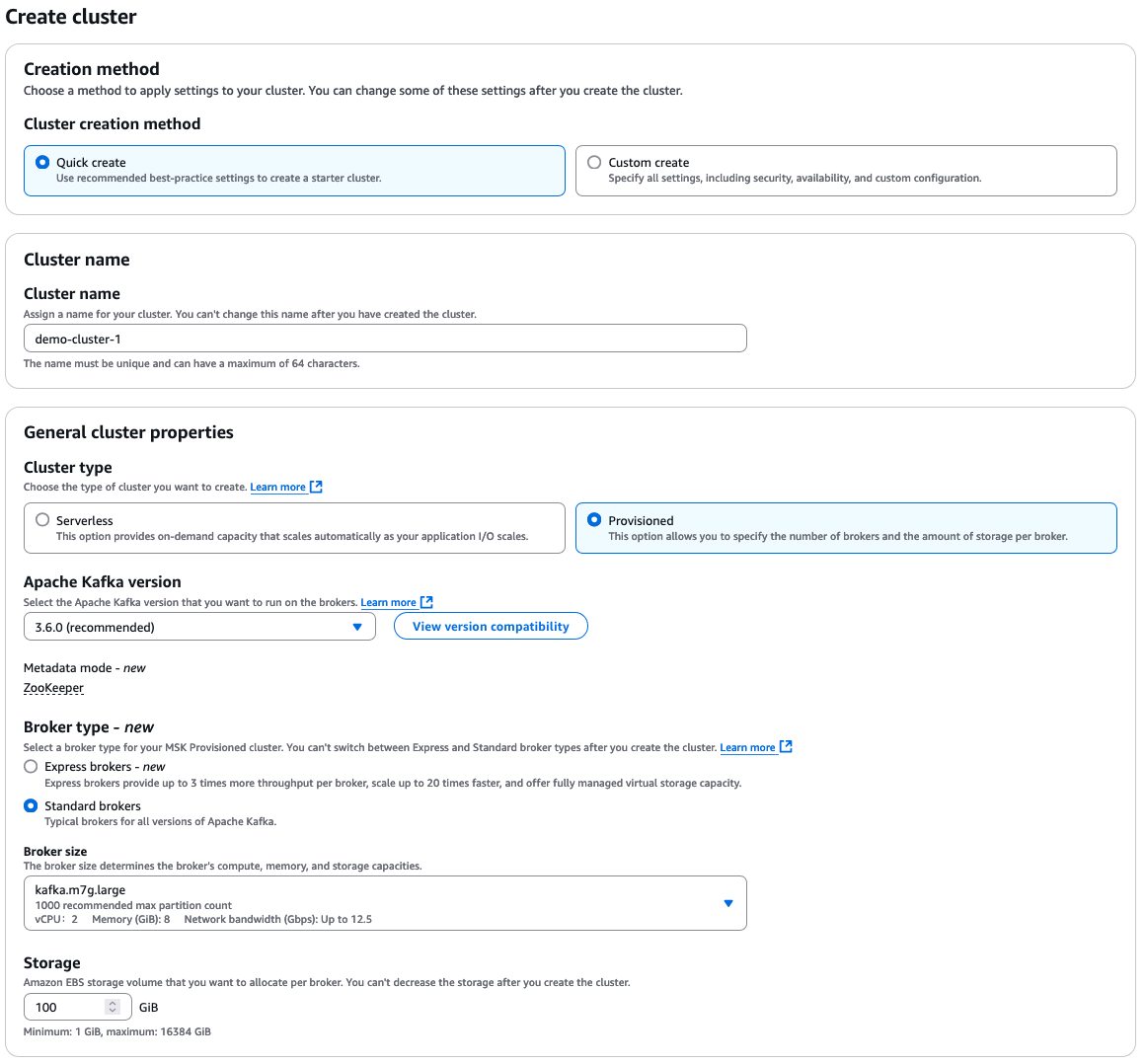
AWS MSK Konfigurationsoptionen
Der Cluster wird immer innerhalb einer Amazon VPC erstellt. Du kannst entweder die Standard-VPC verwenden oder eine eigene VPC konfigurieren und angeben.
Jetzt musst du nur noch darauf warten, dass dein Cluster aktiviert wird. Das kann 15 bis 30 Minuten dauern. Du kannst den Status deines Clusters auf der Übersichtsseite des Clusters überwachen, wo du siehst, dass der Status von "Erstellen" auf "Aktiv" wechselt.
Sobald dein MSK-Cluster eingerichtet ist, musst du einen Client-Rechner erstellen, der Daten für ein oder mehrere Themen produziert und konsumiert. Da sich Apache Kafka so gut in viele Datenproduzenten (wie Websites, IoT-Geräte, Amazon EC2-Instanzen usw.) integrieren lässt, teilt auch MSK diesen Vorteil.
Apache Kafka organisiert die Daten in Strukturen, die Topics genannt werden. Jedes Thema besteht aus einzelnen oder mehreren Fächern. Partitionen sind der Grad der Parallelität in Apache Kafka. Die Daten werden mithilfe der Datenpartitionierung auf die Broker verteilt.
Wichtige Begriffe, die du im Umgang mit Apache Kafka-Clustern kennen solltest:
Wenn du eine ereignisgesteuerte Architektur mit AWS MSK aufbaust, musst du mehrere Ebenen konfigurieren, von denen MSK die wichtigste Komponente für die Datenaufnahme ist. Hier ist ein Überblick über die Schichten, die erforderlich sein können:
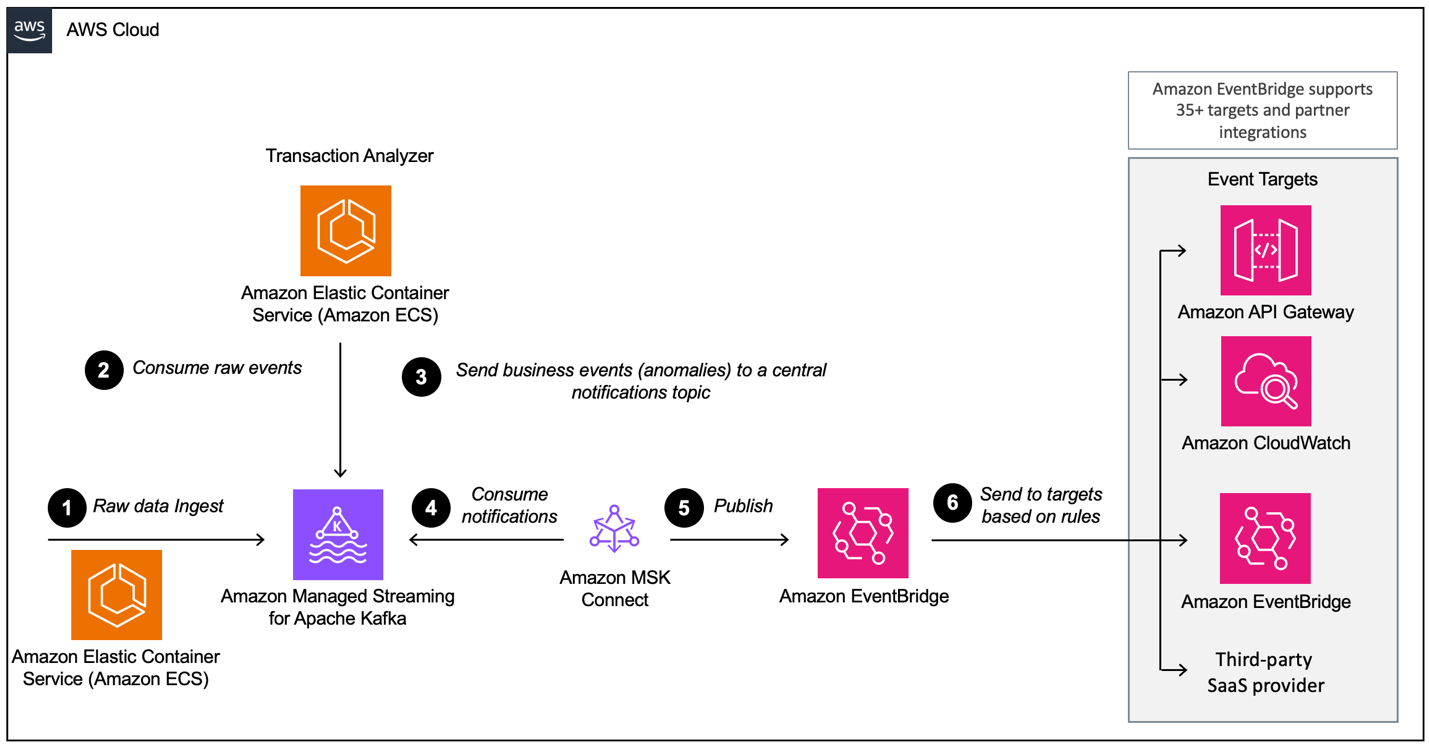
Beispiel für eine ereignisgesteuerte Architektur mit Amazon MSK und Amazon EventBridge. Bildquelle: AWS
Wenn du daran interessiert bist, Python für deine Datenpipeline-Workflows zu nutzen , schau dir unseren Kurs Einführung in AWS Boto in Python an.
AWS MSK ist relativ einfach einzurichten und kann sofort verwendet werden. Einige wichtige Best Practices werden jedoch die Leistung deiner Cluster verbessern und dir später Zeit sparen.
Du musst die richtige Anzahl von Partitionen pro Broker und die richtige Anzahl von Brokern pro Cluster wählen.
Es gibt eine Reihe von Faktoren, die deine Entscheidungen beeinflussen können; AWS hat jedoch einige praktische Empfehlungen und Ressourcen bereitgestellt, die dich durch diesen Prozess führen.
Darüber hinaus bietet AWS eine benutzerfreundliche Tabelle zur Größenbestimmung und Preisgestaltung, mit der du die richtige Größe deines Clusters und die damit verbundenen Kosten für die Nutzung von AWS MSK im Vergleich zu einem ähnlichen selbstverwalteten EC2 Kafka-Cluster abschätzen kannst.
AWS empfiehlt, dass du deine Cluster so einrichtest, dass sie hochverfügbar sind. Das ist besonders wichtig, wenn du ein Update durchführst (z. B. die Apache Kafka-Version aktualisieren) oder wenn AWS einen Broker austauscht.
Um sicherzustellen, dass deine Cluster hochverfügbar sind, musst du drei Dinge tun:
Das Tolle an AWS ist, dass sie sich an strenge SLAs für Multi-AZ-Einsätze halten, sonst bekommst du dein Guthaben zurück.
Zwei wichtige Metriken, die du mit AWS CloudWatch überwachen kannst, sind die Festplatten- und CPU-Auslastung. So stellst du nicht nur sicher, dass dein System reibungslos funktioniert, sondern kannst auch die Kosten niedrig halten.
Der beste Weg, die Festplattennutzung und die damit verbundenen Speicherkosten zu verwalten, ist, einen CloudWatch-Alarm einzurichten, der dich warnt, wenn die Festplattennutzung einen bestimmten Wert, z. B. 85 %, überschreitet, und deine Aufbewahrungsrichtlinien anzupassen. Das Festlegen einer Aufbewahrungszeit für Meldungen in deinem Protokoll kann viel dazu beitragen, dass du automatisch Speicherplatz freimachst.
Um die Leistung deines Clusters aufrechtzuerhalten und Engpässe zu vermeiden, empfiehlt AWS außerdem, dass du die Gesamt-CPU-Auslastung für deine Broker unter 60 % hältst. Du kannst dies mit AWS CloudWatch überwachen und dann Korrekturmaßnahmen ergreifen, indem du z. B. deine Brokergröße aktualisierst.
Standardmäßig verschlüsselt AWS die Daten bei der Übertragung zwischen den Brokern in deinem MSK-Cluster. Du kannst diese Funktion deaktivieren, wenn dein System eine hohe CPU-Auslastung oder Latenz aufweist. Es wird jedoch dringend empfohlen, die In-Transit-Verschlüsselung immer aktiviert zu lassen und andere Wege zu finden, um die Leistung zu verbessern, wenn das für dich ein Problem ist.
In unserem Kurs AWS-Sicherheit und Kostenmanagement erfährst du mehr darüber, wie du deine AWS-Cloud-Umgebung sichern und optimieren sowie Kosten und Ressourcen in AWS verwalten kannst.
Bei der Entscheidung, welches Werkzeug für ein Projekt am besten geeignet ist, müssen wir oft mehrere Optionen abwägen. Hier sind die gängigsten Alternativen zu AWS MSK und wie sie im Vergleich abschneiden.
Der wichtigste Kompromiss zwischen MSK und einer selbst gehosteten Option mit EC2 ist der zwischen Komfort und Kontrolle: Mit MSK hast du weniger zu verwalten, aber auch weniger Flexibilität, während EC2 dir die volle Kontrolle gibt, aber mehr Arbeit erfordert.
AWS MSK übernimmt alle komplexen Betriebsaufgaben mit automatischer Bereitstellung und Konfiguration. Der Vorteil dabei ist, dass keine Infrastrukturkosten anfallen. Außerdem gibt es eine nahtlose Integration mit anderen AWS-Diensten und robuste Sicherheitsfunktionen.
Die Verwendung von Kafka auf EC2 hingegen erfordert mehr manuelle Einstellungen und Konfigurationen, und du musst dich auch selbst um alle Wartungsarbeiten und Updates kümmern. Das bietet viel mehr Flexibilität, kann aber auch mit mehr Komplexität und Betriebskosten verbunden sein und erfordert möglicherweise hochqualifizierte Teams.
Verwende Kinesis für Einfachheit und tiefe AWS-Integration und MSK für Kafka-Kompatibilität oder mehr Kontrolle über dein Streaming-Setup.
Kinesis ist eine komplett serverlose Architektur, die Shards für das Daten-Streaming verwendet. AWS verwaltet alles für dich. Allerdings gibt es Grenzen für die Datenspeicherung, die du beachten musst. Kinesis ist eine großartige Lösung für einfache Anforderungen an das Datenstreaming.
AWS MSK basiert auf dem Topic- und Partitionsmodell von Kafka und bietet eine praktisch unbegrenzte Datenspeicherung, abhängig von deinem Speicherplatz. Es ist eine flexiblere und anpassbare Lösung, die du bei Bedarf von AWS weg migrieren kannst.
Wenn du mit Kinesis nicht vertraut bist, haben wir einen Kurs, der dich durch die Arbeit mit Streaming-Daten mit AWS Kinesis und Lambda führt.
Entscheide dich für Confluent, wenn du umfassende Funktionen und Unterstützung brauchst, und für MSK, wenn du stark in AWS investiert bist und Kafka-Know-how im Haus hast.
Confluent verfügt über ein umfangreiches Funktionsspektrum mit vielen integrierten Konnektoren. Es ist insgesamt eine teurere Option, bietet aber eine kostenlose Stufe mit eingeschränkten Funktionen. Confluent eignet sich gut für sporadische Workloads und hat einen einfacheren Bereitstellungsprozess.
Im Vergleich dazu ist AWS schlanker und konzentriert sich auf die Kernfunktionen von Kafka. Um Zugang zu einem erweiterten Funktionsumfang zu erhalten, muss AWS MSK mit anderen AWS-Diensten integriert werden. Zum Glück ist diese Integration nahtlos. AWS MSK hat niedrigere Grundkosten und kann eine gute Option für konstante Arbeitslasten sein.
Die folgende Tabelle bietet einen Vergleich von AWS MSK und seinen Alternativen:
|
Feature |
AWS MSK |
Apache Kafka on EC2 |
Kinesis |
Konfluent |
|
Einsatz |
Vollständig verwaltet |
Selbstverwaltet auf EC2 |
Vollständig verwaltet |
Vollständig verwaltet oder selbst verwaltet |
|
Einfachheit der Nutzung |
Einfach einzurichten und zu verwalten |
Erfordert manuelle Einrichtung und Skalierung |
Einfache Einrichtung; AWS-nativ |
Benutzerfreundliche UI und fortschrittliche Tools |
|
Skalierbarkeit |
Automatische Skalierung mit manuellen Einstellungen |
Manuelle Skalierung |
Nahtlose Skalierung |
Automatische Skalierung mit Flexibilität |
|
Latenz |
Geringe Latenz |
Geringe Latenz |
Geringere Latenzzeit für kleine Nutzlasten |
Vergleichbar mit MSK |
|
Protokoll Unterstützung |
Kafka API kompatibel |
Kafka API kompatibel |
Proprietäres Kinesis-Protokoll |
Kafka API und zusätzliche Protokolle |
|
Vorratsdatenspeicherung |
Konfigurierbar (bis zu 7 Tage Standard) |
Konfigurierbar |
Konfigurierbar (max. 365 Tage) |
Hochgradig konfigurierbar |
|
Überwachung und Metriken |
Integriert mit CloudWatch |
Erfordert eine benutzerdefinierte Einrichtung |
Integriert mit CloudWatch |
Erweiterte Überwachungstools |
|
Kosten |
Pay-as-you-go |
Basierend auf den EC2-Instanzpreisen |
Pay-as-you-go |
Abonnement-basiert |
|
Sicherheit |
Integrierte AWS-Sicherheitsfunktionen |
Muss die Sicherheit manuell konfigurieren |
Integriert mit AWS IAM |
Umfassende Sicherheitsfunktionen |
|
Eignung des Anwendungsfalls |
Am besten für Kafka-Benutzer im AWS-Ökosystem |
Flexibel, aber wartungsintensiv |
Am besten für AWS-native Anwendungen |
Fortgeschrittene Kafka-Nutzer und Unternehmen |
Apache Kafka ist die erste Wahl für Situationen, in denen du eine groß angelegte, zuverlässige Lösung brauchst, die sich keinen Datenverlust leisten kann und die Verbindung mehrerer Datenquellen oder den Aufbau komplexer Datenpipelines erfordert. AWS MSK erspart viele der Kopfschmerzen, die mit dem Einrichten und Konfigurieren von Kafka-Clustern verbunden sind, sodass sich die Entwickler mehr auf die Entwicklung und Verbesserung von Anwendungen als auf die Infrastruktur konzentrieren können.
Eine AWS-Zertifizierung ist ein hervorragender Start für deine AWS-Karriere. Du kannst deine AWS-Kenntnisse ausbauen, indem du dir unseren Kurskatalog ansiehst und anhand von Projekten praktische Erfahrungen sammelst!
Lerne mehr über AWS mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
