
Cours
Introduction à AWS Boto en Python
4 h
18.4K
Avant de vous plonger dans la commande aws s3 cp, vous devez avoir installé et configuré correctement la CLI AWS sur votre système. Ne vous inquiétez pas si vous n'avez jamais travaillé avec AWS : le processus d'installation est simple et devrait prendre moins de 10 minutes.
Je vais décomposer cette opération en trois phases simples : installation de l'outil AWS CLI, configuration de vos informations d'identification et création de votre premier godet S3 pour le stockage.
La procédure d'installation diffère légèrement selon le système d'exploitation que vous utilisez.
Pour les systèmes Windows :
Pour les systèmes Linux :
Exécutez les trois commandes suivantes dans le terminal :
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
unzip awscliv2.zip
sudo ./aws/installPour les systèmes macOS :
En supposant que vous ayez installé Homebrew, exécutez cette ligne depuis le Terminal :
brew install awscliSi vous n'avez pas Homebrew, utilisez ces deux commandes à la place :
curl "https://awscli.amazonaws.com/AWSCLIV2.pkg" -o "AWSCLIV2.pkg"
sudo installer -pkg AWSCLIV2.pkg -target /Pour confirmer la réussite de l'installation, lancez aws --version dans votre terminal. Vous devriez voir quelque chose comme ceci :
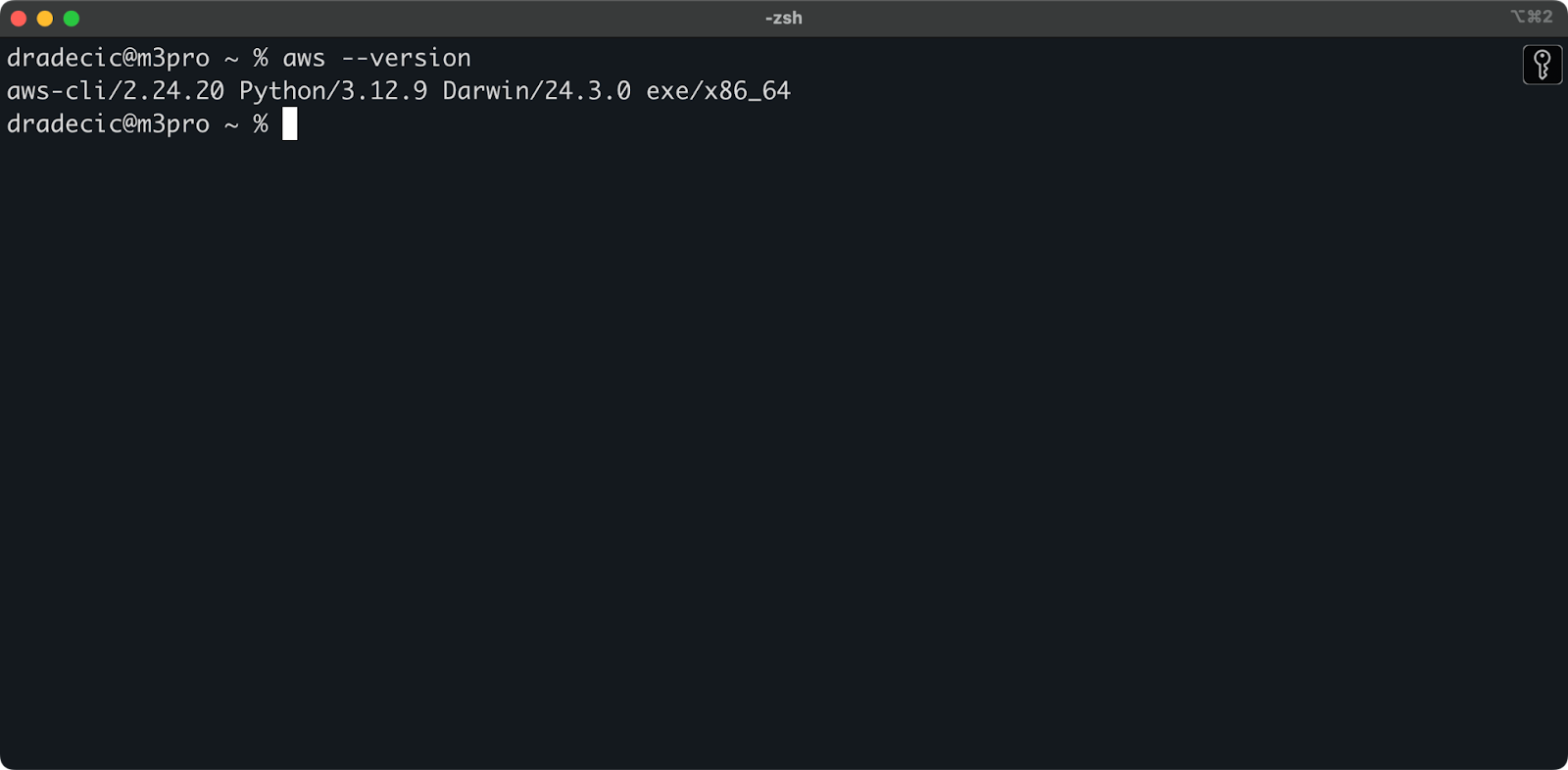
Image 1 - Version CLI d'AWS
Une fois le CLI installé, il est temps de configurer vos informations d'identification AWS pour l'authentification.
Tout d'abord, accédez à votre compte AWS et naviguez jusqu'au tableau de bord du service IAM. Créez un nouvel utilisateur avec un accès programmatique et attachez la politique de permissions S3 appropriée :
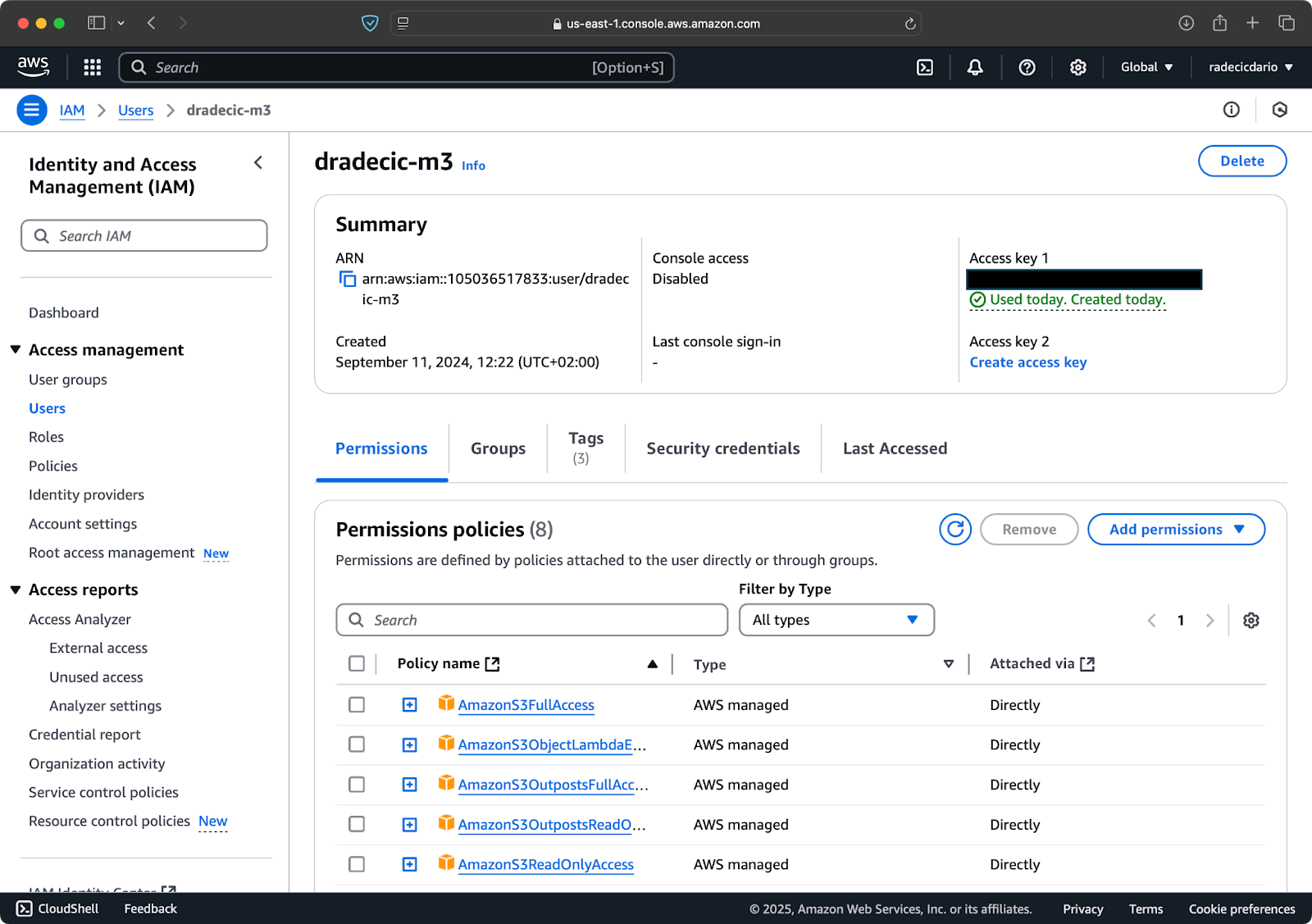
Image 2 - Utilisateur AWS IAM
Ensuite, visitez l'onglet "Security credentials" et générez une nouvelle paire de clés d'accès. Veillez à enregistrer l'ID de la clé d'accès et la clé d'accès secrète dans un endroit sûr - Amazon ne vous montrera plus la clé secrète après cet écran :
Image 3 - Informations d'identification de l'utilisateur AWS IAM
Ouvrez maintenant votre terminal et exécutez la commande aws configure. Quatre informations vous seront demandées : votre ID de clé d'accès, votre clé d'accès secrète, votre région par défaut (j'utilise eu-central-1) et votre format de sortie préféré (généralement json) :
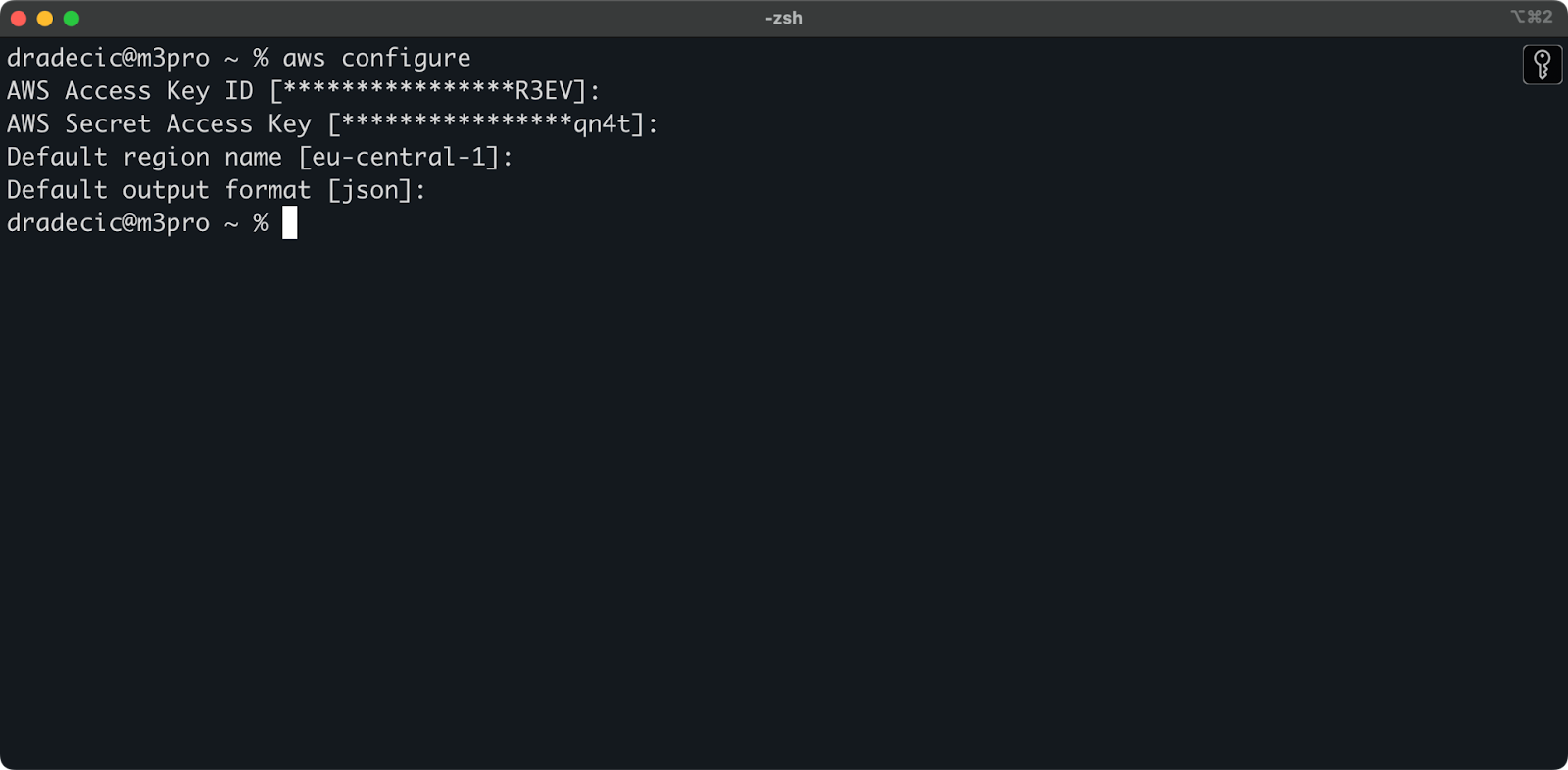
Image 4 - Configuration de la CLI AWS
Pour vous assurer que tout est bien connecté, vérifiez votre identité à l'aide de la commande suivante :
aws sts get-caller-identitySi la configuration est correcte, vous verrez les détails de votre compte :
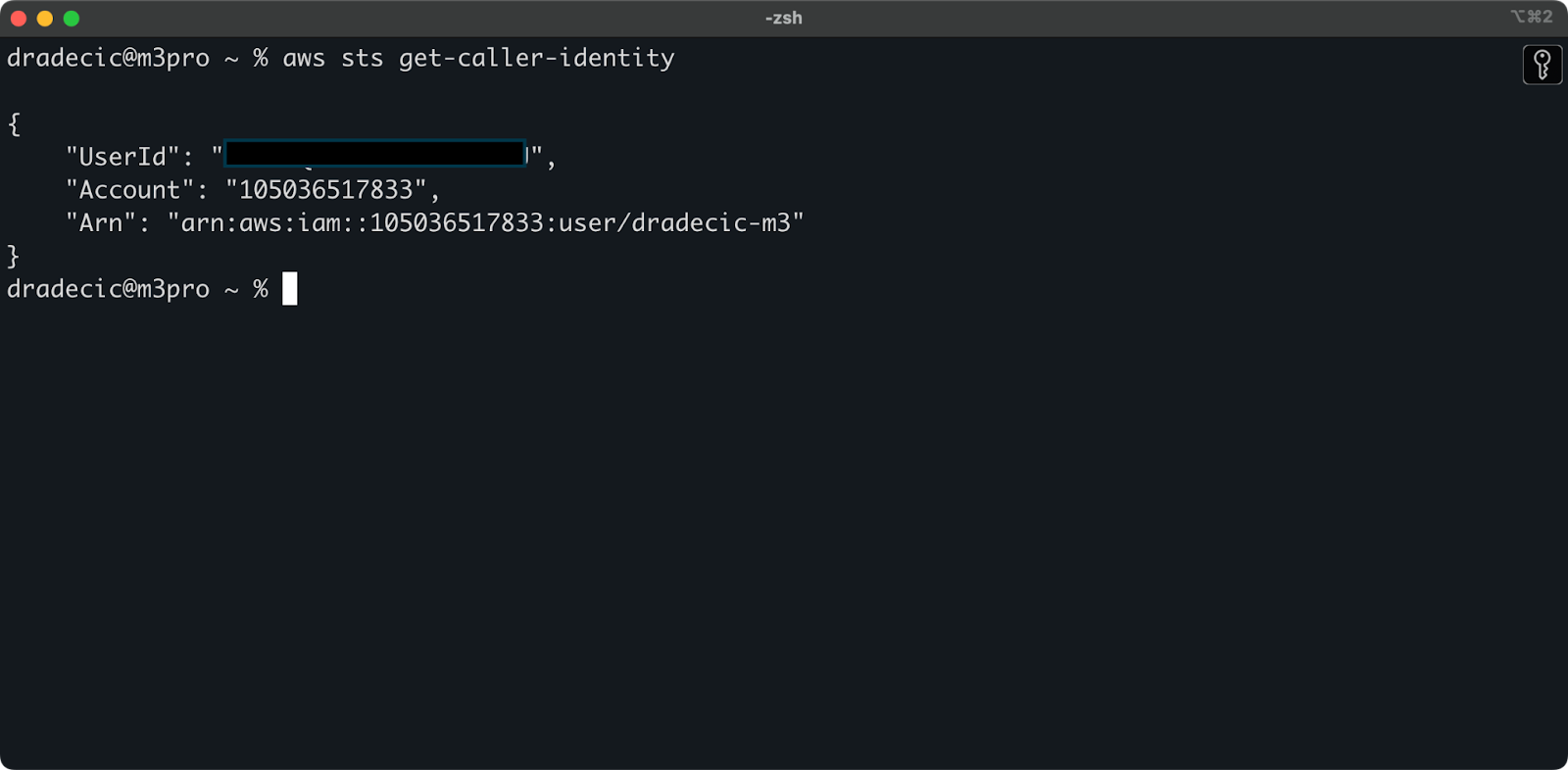
Image 5 - Commande de test de connexion de la CLI AWS
Enfin, vous devez créer un panier S3 pour stocker les fichiers que vous copierez.
Rendez-vous dans la section du service S3 de votre console AWS et cliquez sur "Create bucket" (Créer un seau). N'oubliez pas que les noms des godets doivent être uniques dans l'ensemble d'AWS. Choisissez un nom distinctif, laissez les paramètres par défaut pour l'instant et cliquez sur "Créer" :
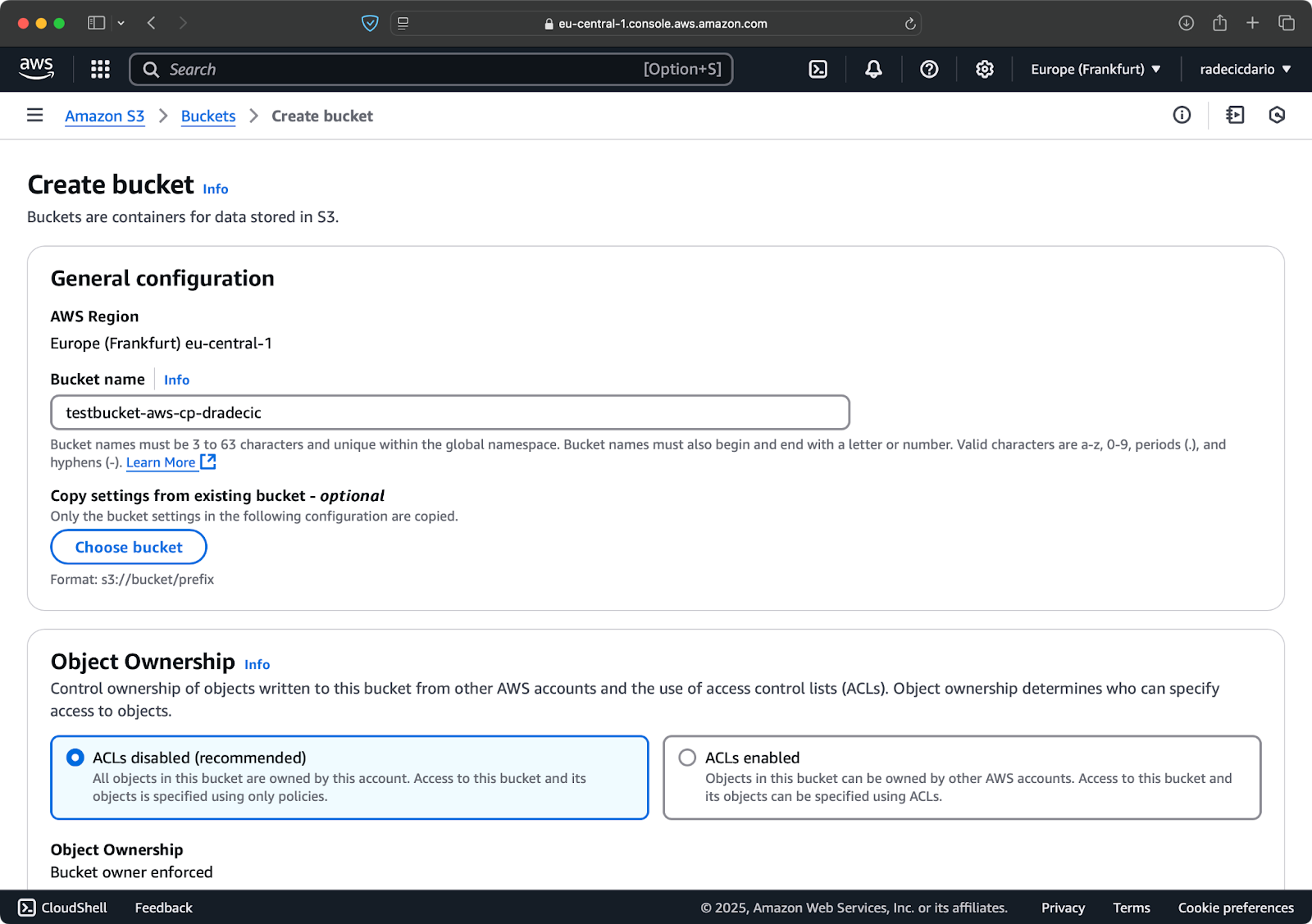
Image 6 - Création d'un seau AWS
Une fois créé, votre nouveau seau apparaîtra dans la console. Vous pouvez également confirmer son existence à l'aide de la ligne de commande :
aws s3 ls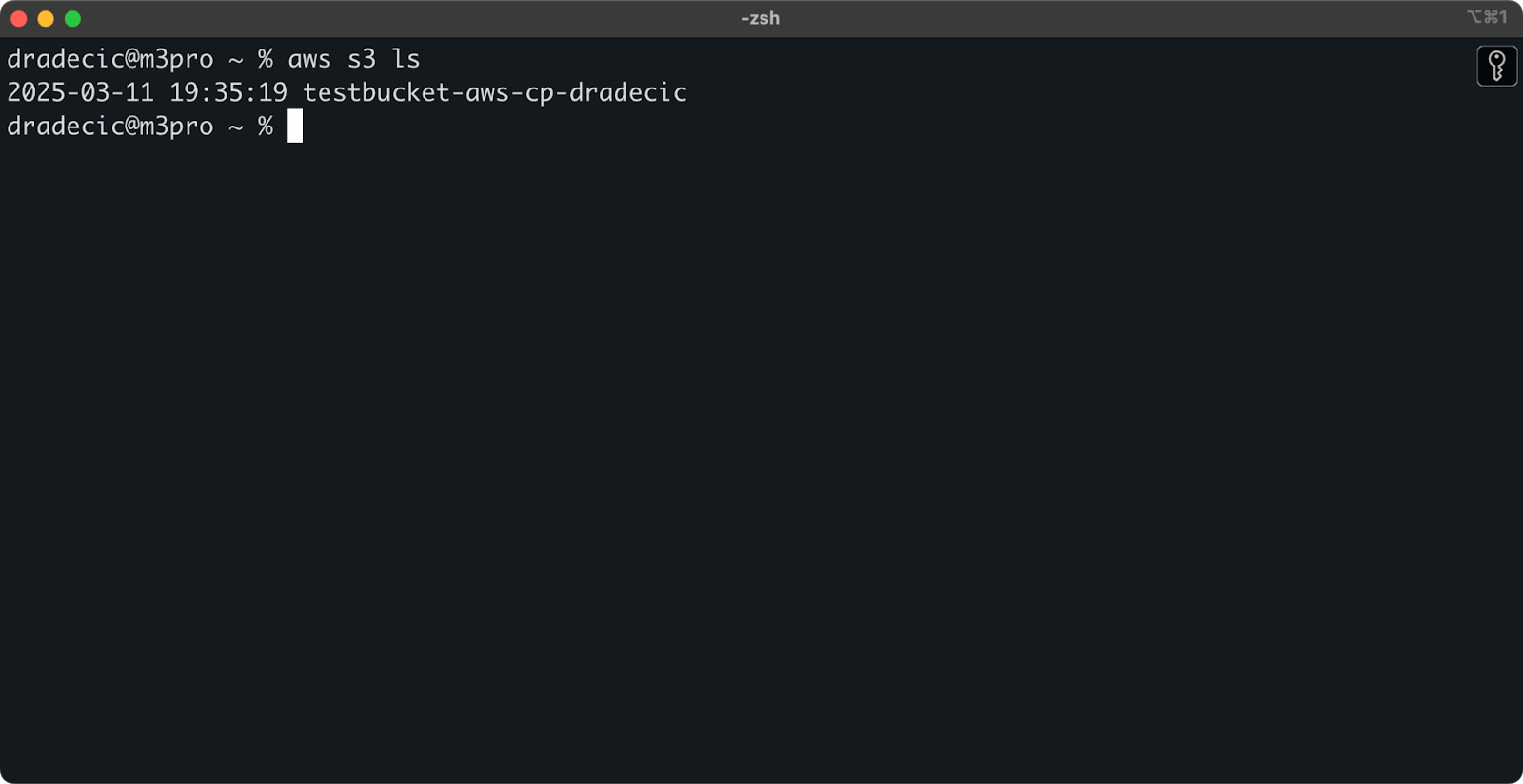
Image 7 - Tous les buckets S3 disponibles
Tous les buckets S3 sont configurés comme privés par défaut, gardez cela à l'esprit. Si vous avez l'intention d'utiliser ce seau pour des fichiers accessibles au public, vous devrez modifier les règles du seau en conséquence.
Vous êtes maintenant prêt à utiliser la commande aws s3 cp pour transférer des fichiers. Commençons par les bases.
Maintenant que tout est configuré, nous allons nous plonger dans l'utilisation de base de la commande aws s3 cp. Comme toujours avec AWS, la beauté réside dans la simplicité, même si la commande peut gérer différents scénarios de transfert de fichiers.
Dans sa forme la plus élémentaire, la commande aws s3 cp suit la syntaxe suivante :
aws s3 cp <source> <destination> [options]Où peuvent être des chemins d'accès à des fichiers locaux ou des URI S3 (qui commencent par s3://). Examinons les trois cas d'utilisation les plus courants.
Pour copier un fichier de votre système local vers un panier S3, la source sera un chemin local et la destination sera une URI S3 :
aws s3 cp /Users/dradecic/Desktop/test_file.txt s3://testbucket-aws-cp-dradecic/test_file.txtCette commande télécharge le fichier test_file.txt du répertoire fourni vers le panier S3 spécifié. Si l'opération est réussie, vous verrez apparaître une sortie de console comme celle-ci :
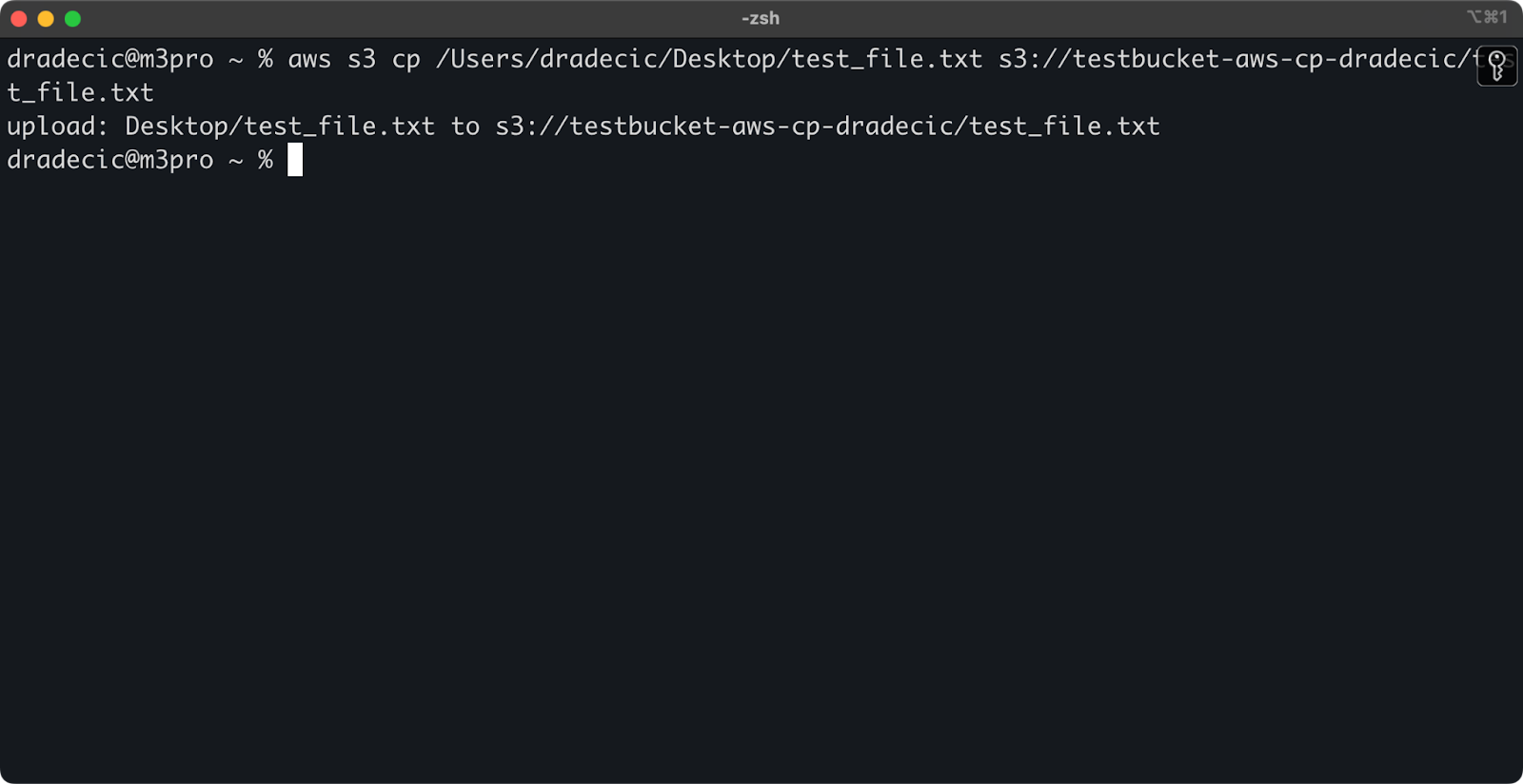
Image 8 - Sortie de la console après la copie du fichier local
Dans la console de gestion AWS, vous verrez votre fichier téléchargé :
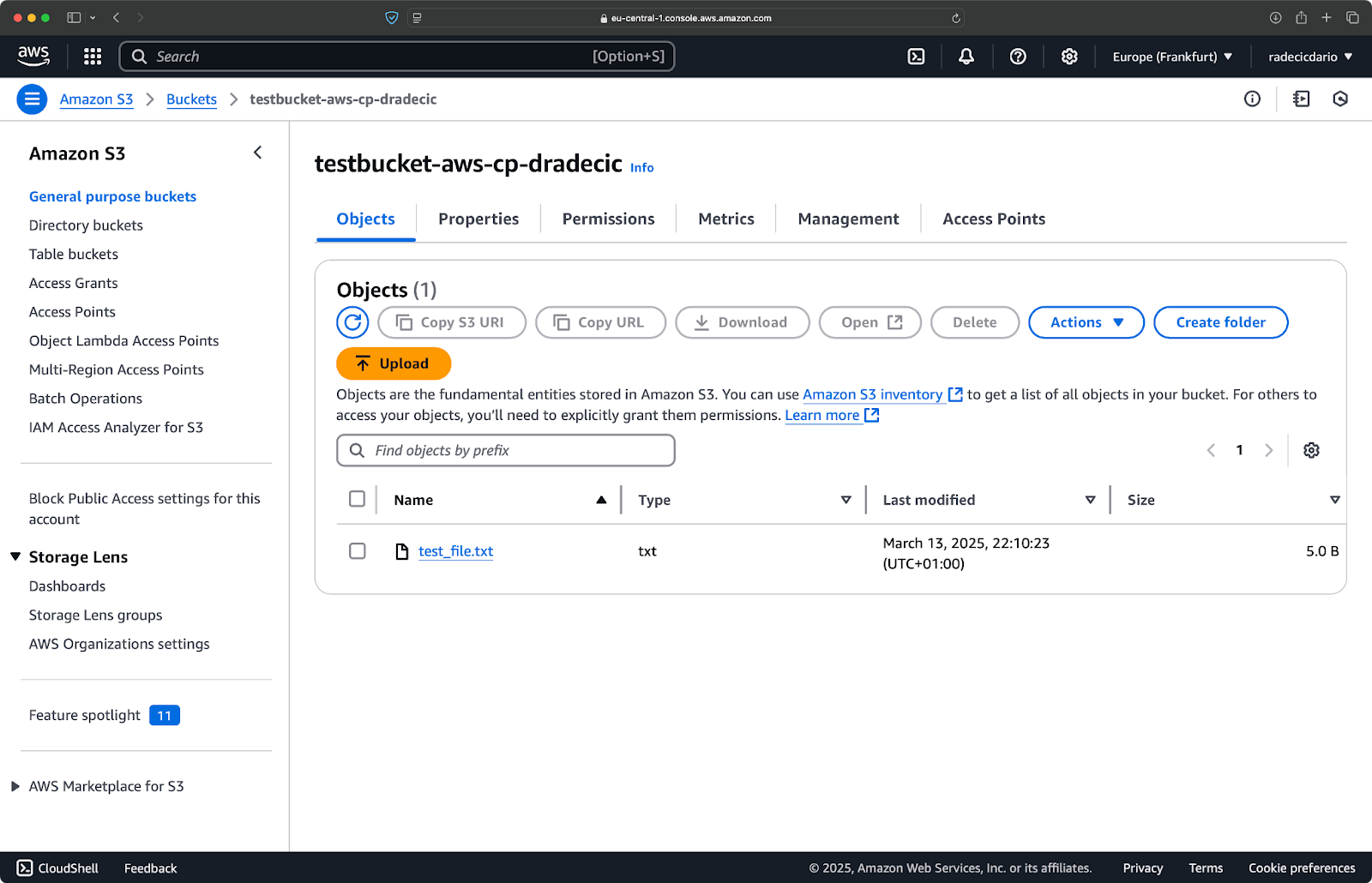
Image 9 - Contenu du seau S3
De même, si vous souhaitez copier un dossier local dans votre panier S3 et le placer, disons, dans un autre dossier imbriqué, exécutez une commande similaire à celle-ci :
aws s3 cp /Users/dradecic/Desktop/test_folder s3://testbucket-aws-cp-dradecic/my-desired-folder/test_folder/ --recursive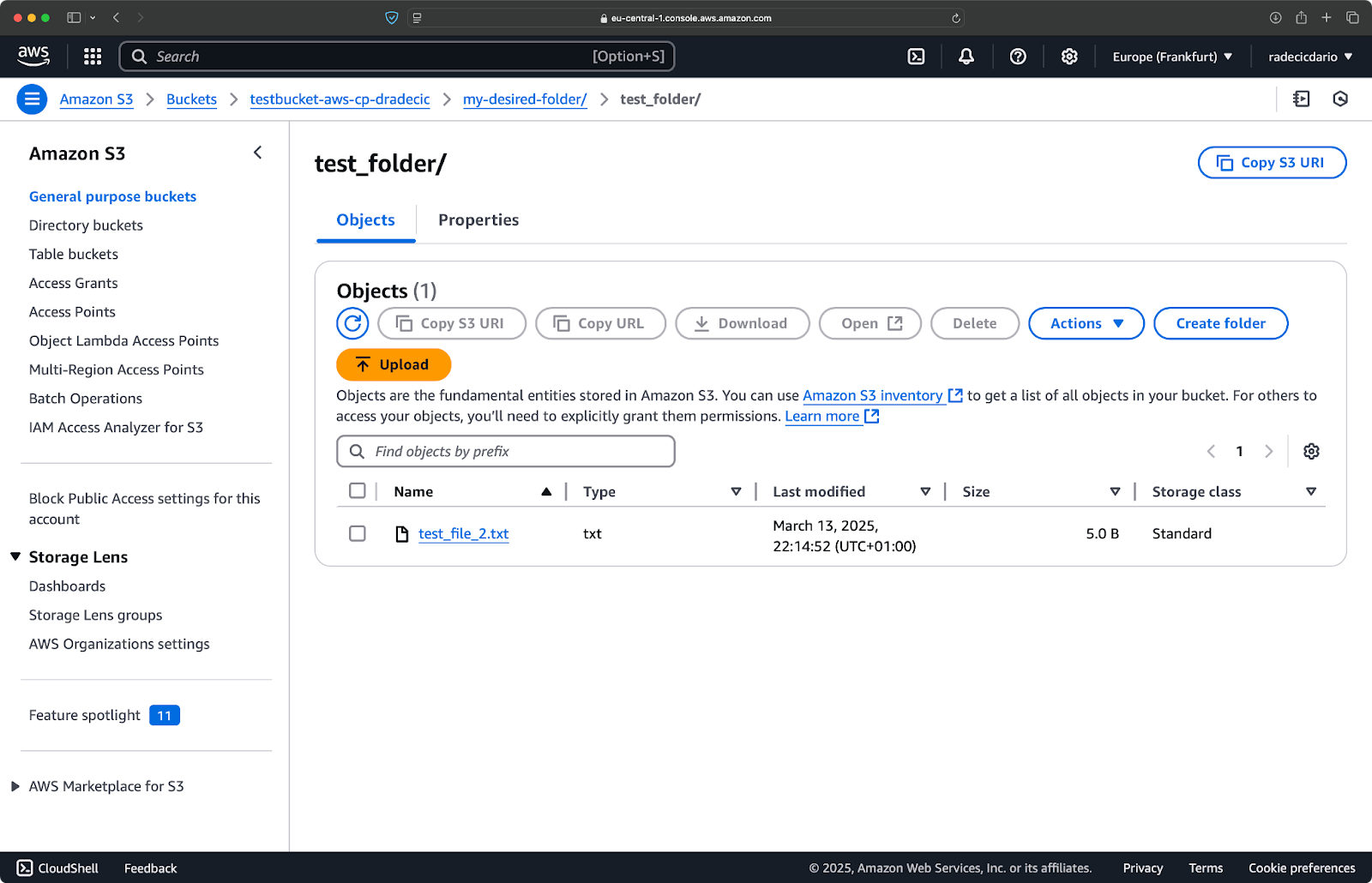
Image 10 - Contenu du panier S3 après le téléchargement d'un dossier
L'option --recursive permet de s'assurer que tous les fichiers et sous-dossiers du dossier sont copiés.
Gardez à l'esprit que S3 n'a pas réellement de dossiers - la structure du chemin fait partie de la clé de l'objet, mais elle fonctionne conceptuellement comme des dossiers.
Pour copier un fichier de S3 vers votre système local, il suffit d'inverser l'ordre : la source devient l'URI S3 et la destination est votre chemin d'accès local :
aws s3 cp s3://testbucket-aws-cp-dradecic/test_file.txt /Users/dradecic/Documents/s3-data/downloaded_test_file.txtCette commande télécharge test_file.txt depuis votre panier S3 et l'enregistre sous downloaded_test_file.txt dans le répertoire fourni. Vous le verrez immédiatement sur votre système local :
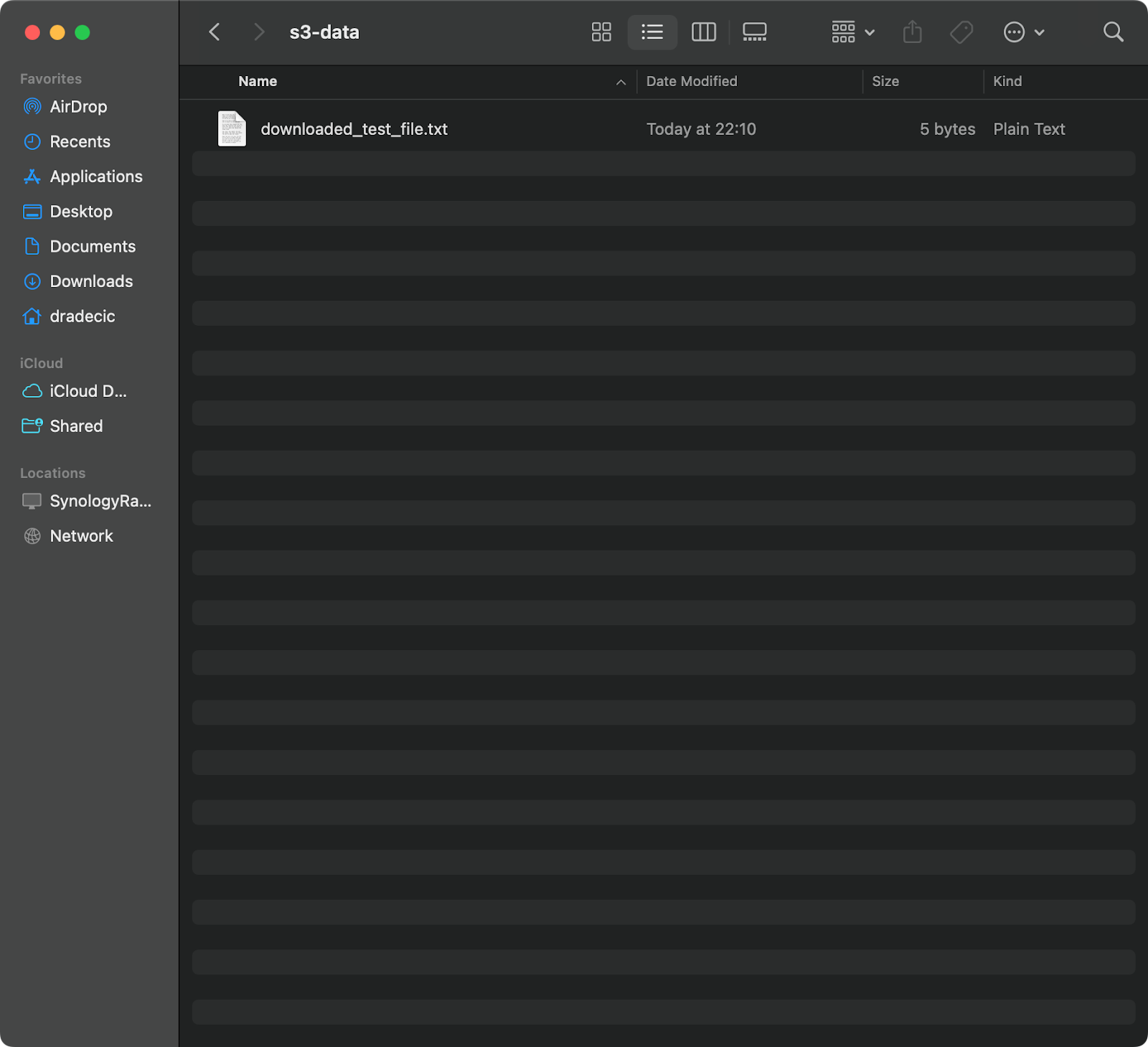
Image 11 - Téléchargement d'un seul fichier depuis S3
Si vous omettez le nom du fichier de destination, la commande utilisera le nom du fichier d'origine :
aws s3 cp s3://testbucket-aws-cp-dradecic/test_file.txt .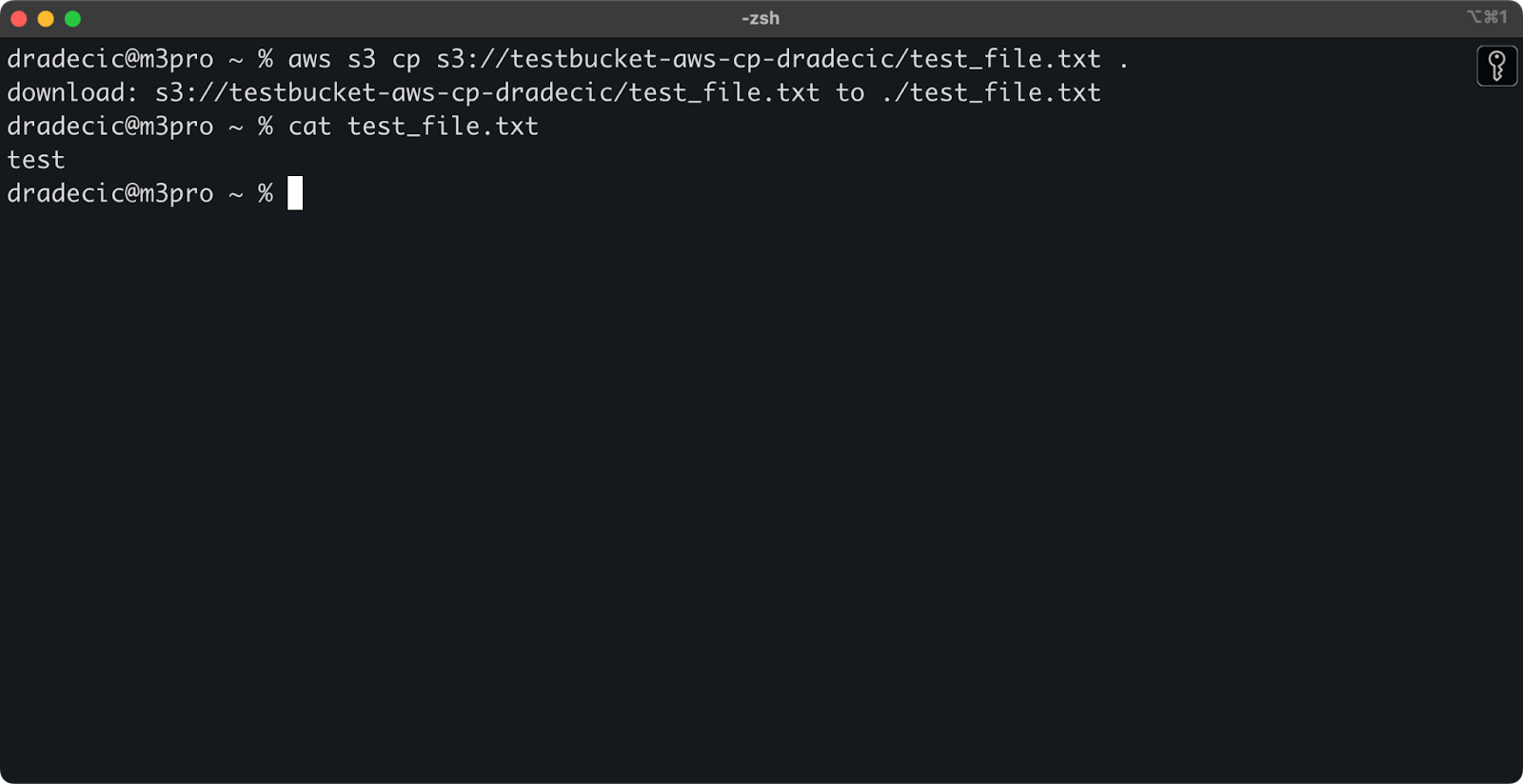
Image 12 - Contenu du fichier téléchargé
Le point (.) représente votre répertoire actuel, ce qui permet de télécharger test_file.txt à votre emplacement actuel.
Enfin, pour télécharger un répertoire entier, vous pouvez utiliser une commande similaire à celle-ci :
aws s3 cp s3://testbucket-aws-cp-dradecic/my-desired-folder/test_folder /Users/dradecic/Documents/test_folder --recursive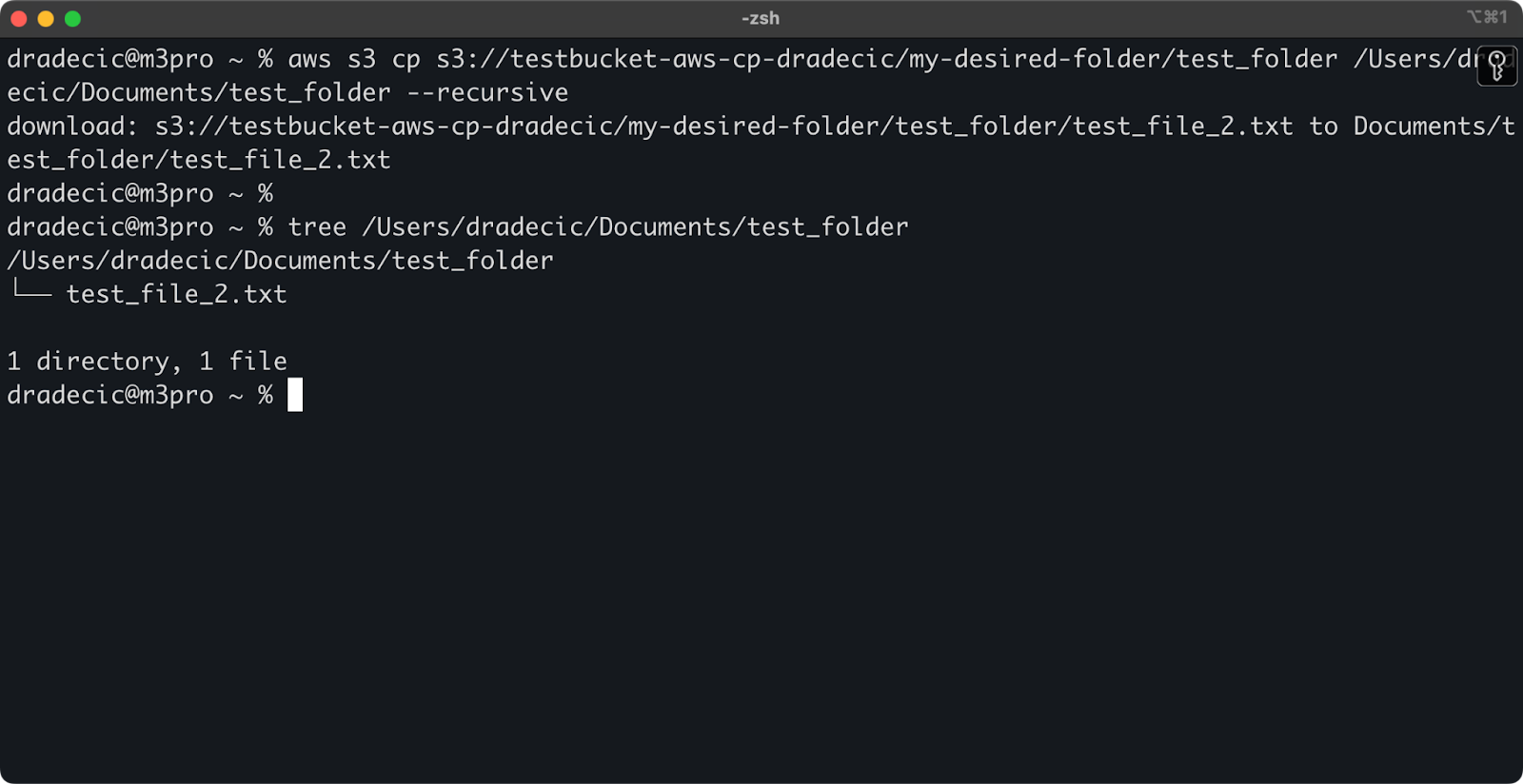
Image 13 - Contenu du dossier téléchargé
Gardez à l'esprit que le drapeau --recursive est essentiel lorsque vous travaillez avec plusieurs fichiers - sans lui, la commande échouera si la source est un répertoire.
Avec ces commandes de base, vous pouvez déjà accomplir la plupart des tâches de transfert de fichiers dont vous aurez besoin. Mais dans la section suivante, vous découvrirez des options plus avancées qui vous permettront de mieux contrôler le processus de copie.
AWS propose quelques options avancées qui vous permettent d'optimiser les opérations de copie de fichiers. Dans cette section, je vous présenterai quelques-uns des drapeaux et paramètres les plus utiles qui vous aideront dans vos tâches quotidiennes.
Il arrive que vous ne souhaitiez copier que certains fichiers correspondant à des modèles spécifiques. Les drapeaux --exclude et --include vous permettent de filtrer les fichiers en fonction de modèles et de contrôler précisément ce qui est copié.
Pour commencer, voici la structure de répertoire avec laquelle je travaille :
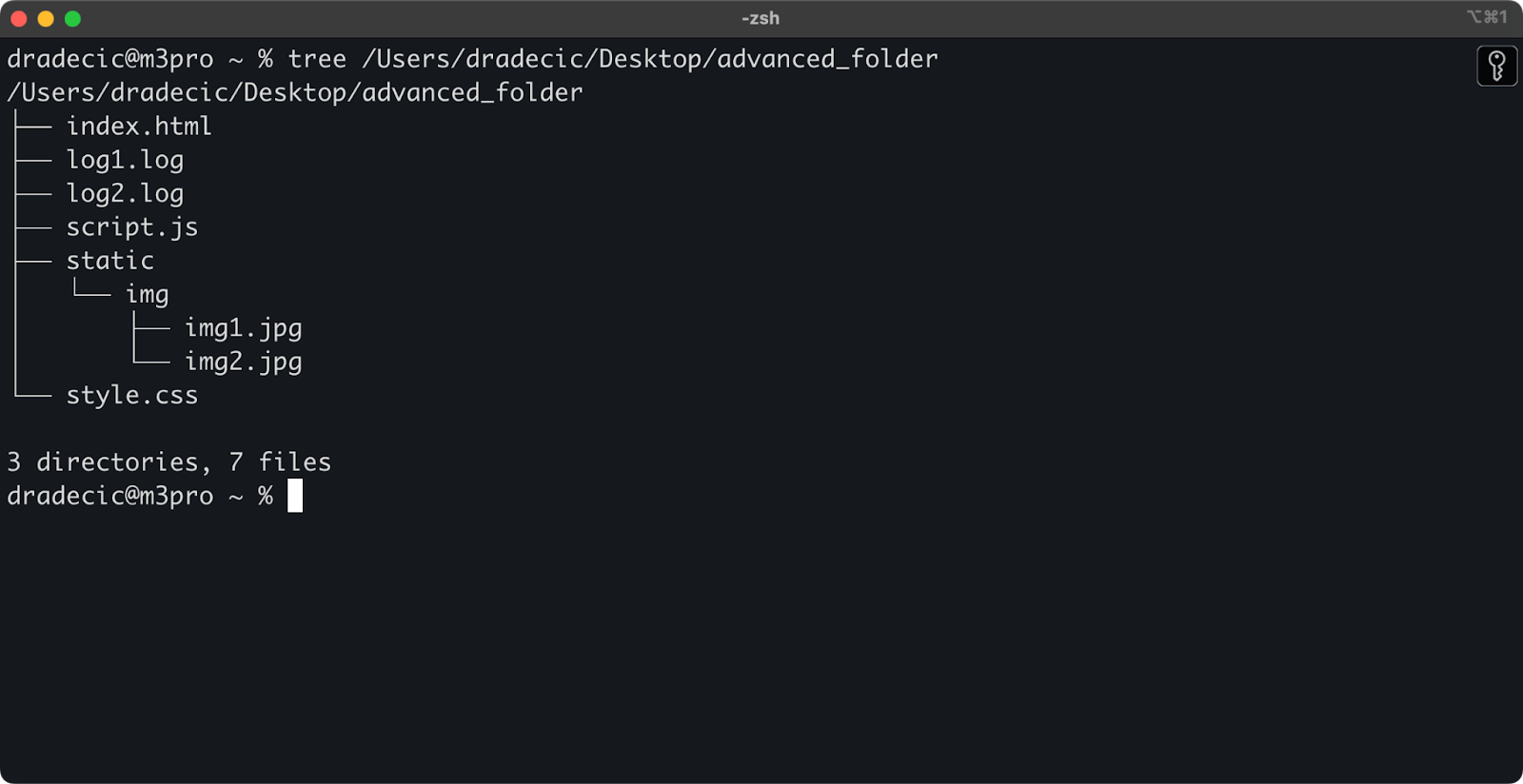
Image 14 - Structure du répertoire
Supposons maintenant que vous souhaitiez copier tous les fichiers du répertoire, à l'exception des fichiers .log:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --exclude "*.log"Cette commande copiera tous les fichiers du répertoire advanced_folder vers S3, à l'exclusion de tout fichier portant l'extension .log:
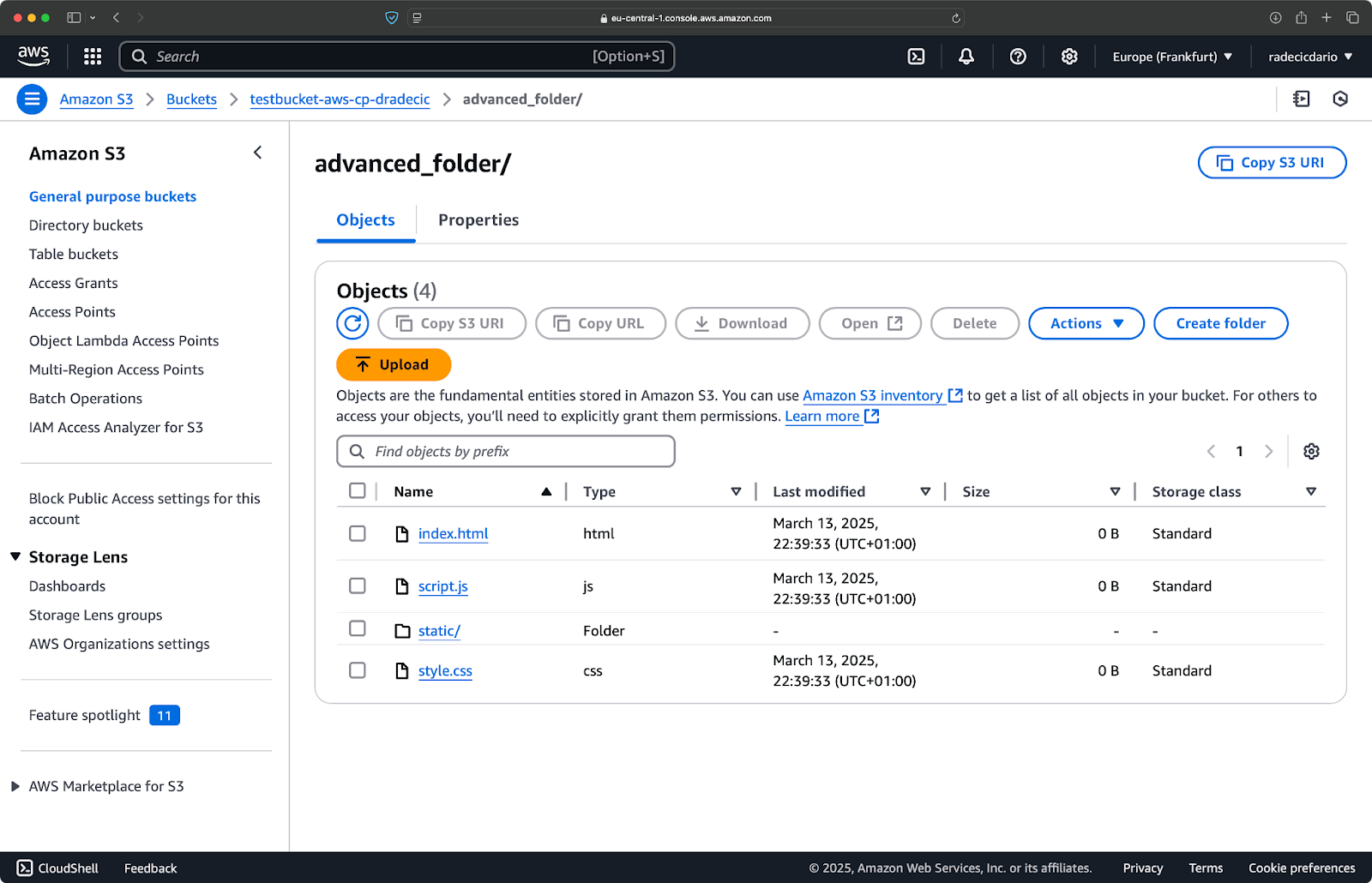
Image 15 - Résultats de la copie de dossier
Vous pouvez également combiner plusieurs motifs. Supposons que vous souhaitiez copier uniquement les fichiers HTML et CSS du dossier du projet :
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --exclude "*" --include "*.html" --include "*.css"Cette commande exclut d'abord tout (--exclude "*"), puis n'inclut que les fichiers portant les extensions .html et .css. Le résultat est le suivant :
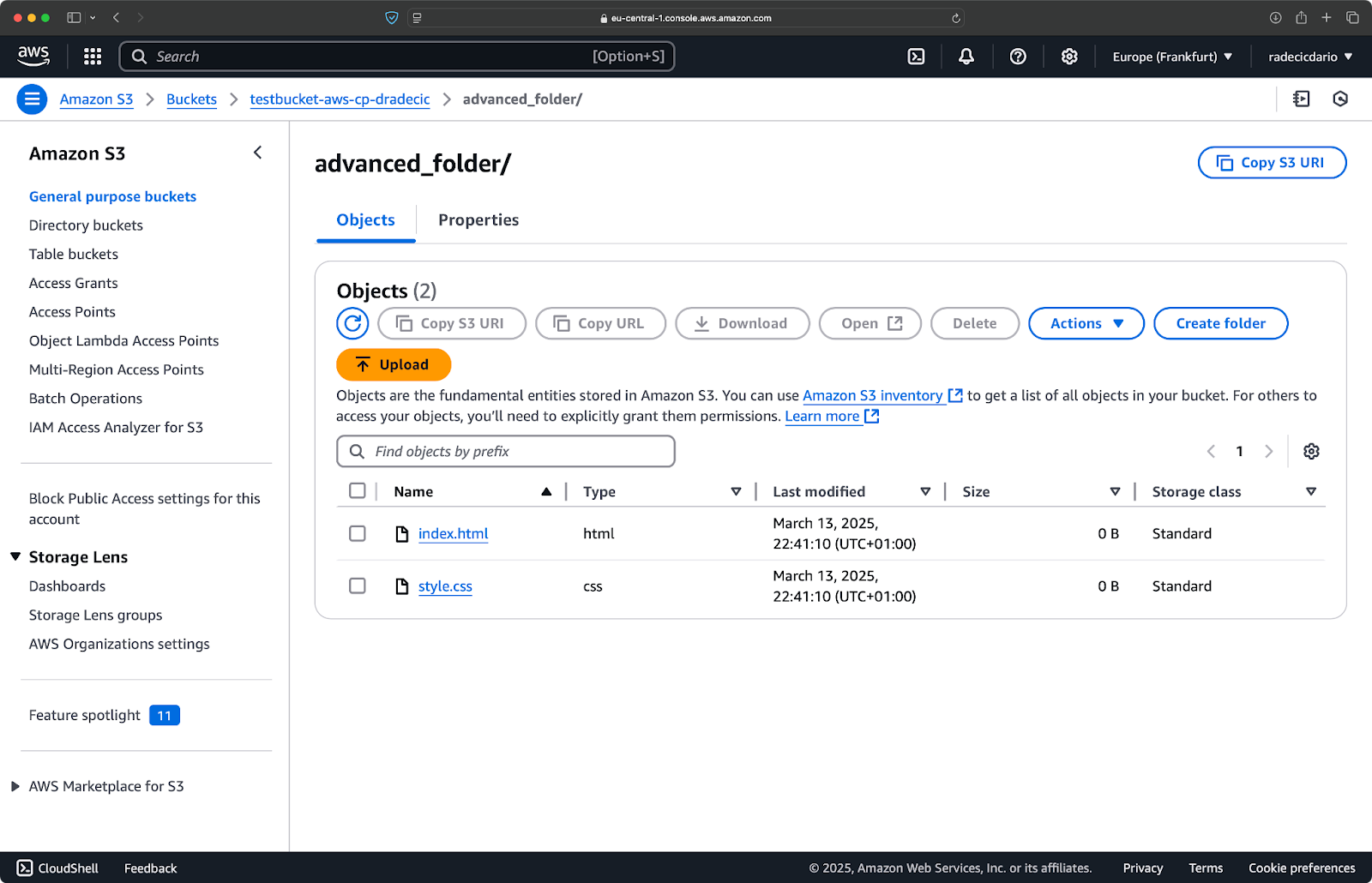
Image 16 - Résultats de la copie de dossier (2)
Gardez à l'esprit que l'ordre des drapeaux a de l'importance - AWS CLI traite ces drapeaux de manière séquentielle, donc si vous mettez --include avant --exclude, vous obtiendrez des résultats différents :
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --include "*.html" --include "*.css" --exclude "*"Cette fois, rien n'a été copié dans le seau :
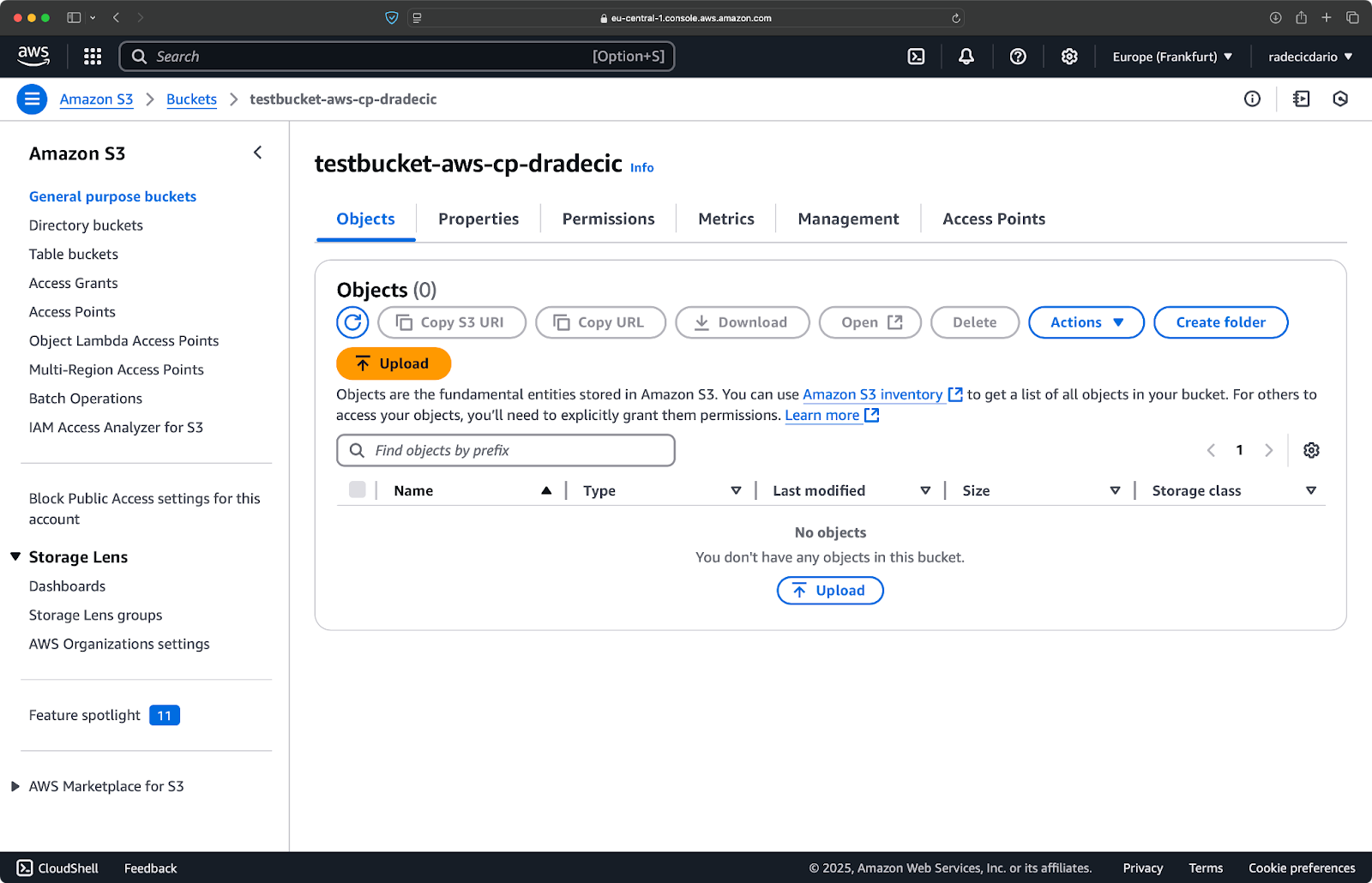
Image 17 - Résultats de la copie de dossiers (3)
Amazon S3 propose différentes classes de stockage, chacune ayant des coûts et des caractéristiques de recherche différents. Par défaut, aws s3 cp télécharge les fichiers dans la classe de stockage Standard, mais vous pouvez spécifier une classe différente à l'aide de l'option --storage-class:
aws s3 cp /Users/dradecic/Desktop/large-archive.zip s3://testbucket-aws-cp-dradecic/archives/ --storage-class GLACIERCette commande télécharge large-archive.zip vers la classe de stockage Glacier, qui est nettement moins chère, mais dont les coûts et les délais de récupération sont plus élevés :
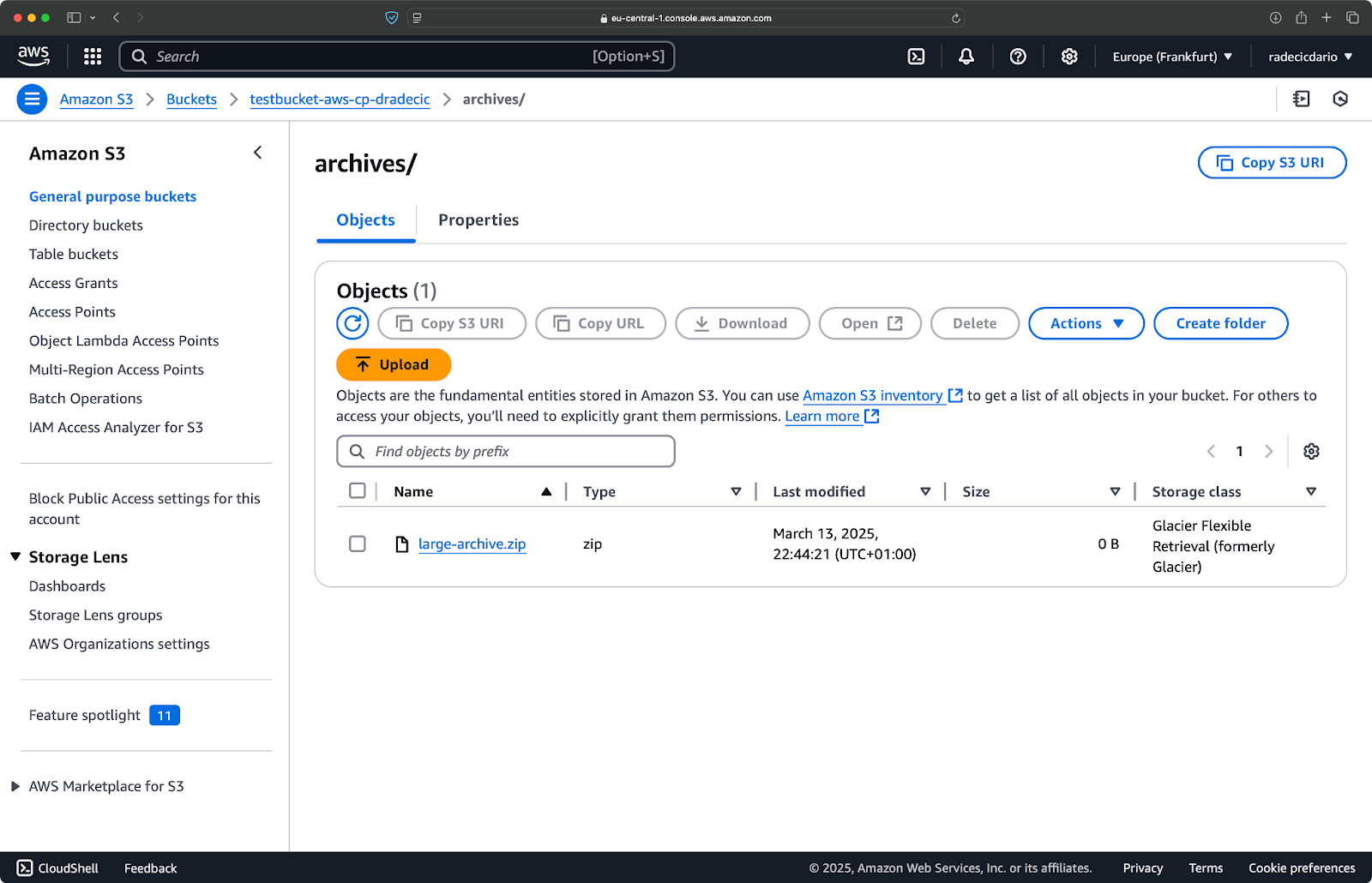
Image 18 - Copier des fichiers sur S3 avec différentes classes de stockage
Les classes de stockage disponibles sont les suivantes :
STANDARD (par défaut) : Stockage polyvalent avec une durabilité et une disponibilité élevées.REDUCED_REDUNDANCY (qui n'est plus recommandé) : Durabilité moindre, option économique, aujourd'hui obsolète.STANDARD_IA (Accès peu fréquent) : Stockage moins coûteux pour les données auxquelles on accède moins fréquemment.ONEZONE_IA (Single Zone Infrequent Access) : Stockage à moindre coût, avec accès peu fréquent, dans une seule zone de disponibilité AWS.INTELLIGENT_TIERING: Déplace automatiquement les données entre les différents niveaux de stockage en fonction des schémas d'accès.GLACIER: Stockage d'archives à faible coût pour une conservation à long terme, récupération en quelques minutes ou quelques heures.DEEP_ARCHIVE: Stockage d'archives le moins cher, récupération en quelques heures, idéal pour la sauvegarde à long terme.Si vous sauvegardez des fichiers auxquels vous n'avez pas besoin d'accéder immédiatement, l'utilisation de GLACIER ou DEEP_ARCHIVE peut vous faire économiser des coûts de stockage importants.
Lorsque vous mettez à jour des fichiers déjà existants dans S3, il se peut que vous ne souhaitiez copier que les fichiers modifiés. L'option --exact-timestamps permet de comparer les dates entre la source et la destination.
En voici un exemple :
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --exact-timestampsAvec cette option, la commande ne copiera que les fichiers dont l'horodatage diffère de celui des fichiers déjà présents dans S3. Cela permet de réduire le temps de transfert et l'utilisation de la bande passante lorsque vous mettez régulièrement à jour un grand nombre de fichiers.
En quoi cela est-il utile ? Imaginez des scénarios de déploiement dans lesquels vous souhaitez mettre à jour vos fichiers d'application sans transférer inutilement des actifs inchangés.
Bien que --exact-timestamps soit utile pour effectuer une sorte de synchronisation, si vous avez besoin d'une solution plus sophistiquée, envisagez d'utiliser aws s3 sync au lieu de aws s3 cp. La commande sync a été spécialement conçue pour assurer la synchronisation des répertoires et dispose de fonctionnalités supplémentaires à cet effet. J'ai tout écrit sur la commande sync dans le tutoriel AWS S3 Sync.
Grâce à ces options avancées, vous disposez désormais d'un contrôle beaucoup plus fin sur vos opérations de fichiers S3. Vous pouvez cibler des fichiers spécifiques, optimiser les coûts de stockage et mettre à jour efficacement vos fichiers. Dans la section suivante, vous apprendrez à automatiser ces opérations à l'aide de scripts et de tâches planifiées.
Jusqu'à présent, vous avez appris à copier manuellement des fichiers depuis et vers S3 à l'aide de la ligne de commande. L'un des principaux avantages de l'utilisation de aws s3 cp est que vous pouvez facilement automatiser ces transferts, ce qui vous fera gagner beaucoup de temps.
Voyons comment vous pouvez intégrer la commande aws s3 cp dans des scripts et des tâches planifiées pour des transferts de fichiers sans intervention.
Voici un exemple de script bash simple qui sauvegarde un répertoire sur S3, ajoute un horodatage à la sauvegarde, et implémente la gestion des erreurs et la journalisation dans un fichier :
#!/bin/bash
# Set variables
SOURCE_DIR="/Users/dradecic/Desktop/advanced_folder"
BUCKET="s3://testbucket-aws-cp-dradecic/backups"
DATE=$(date +%Y-%m-%d-%H-%M)
BACKUP_NAME="backup-$DATE"
LOG_FILE="/Users/dradecic/logs/s3-backup-$DATE.log"
# Ensure the logs directory exists
mkdir -p "$(dirname "$LOG_FILE")"
# Create the backup and log the output
echo "Starting backup of $SOURCE_DIR to $BUCKET/$BACKUP_NAME" | tee -a $LOG_FILE
aws s3 cp $SOURCE_DIR $BUCKET/$BACKUP_NAME --recursive 2>&1 | tee -a $LOG_FILE
# Check if the backup was successful
if [ $? -eq 0 ]; then
echo "Backup completed successfully on $DATE" | tee -a $LOG_FILE
else
echo "Backup failed on $DATE" | tee -a $LOG_FILE
fiSauvegardez-le sous backup.sh, rendez-le exécutable avec chmod +x backup.sh, et vous avez un script de sauvegarde réutilisable !
Vous pouvez ensuite l'exécuter à l'aide de la commande suivante :
./backup.sh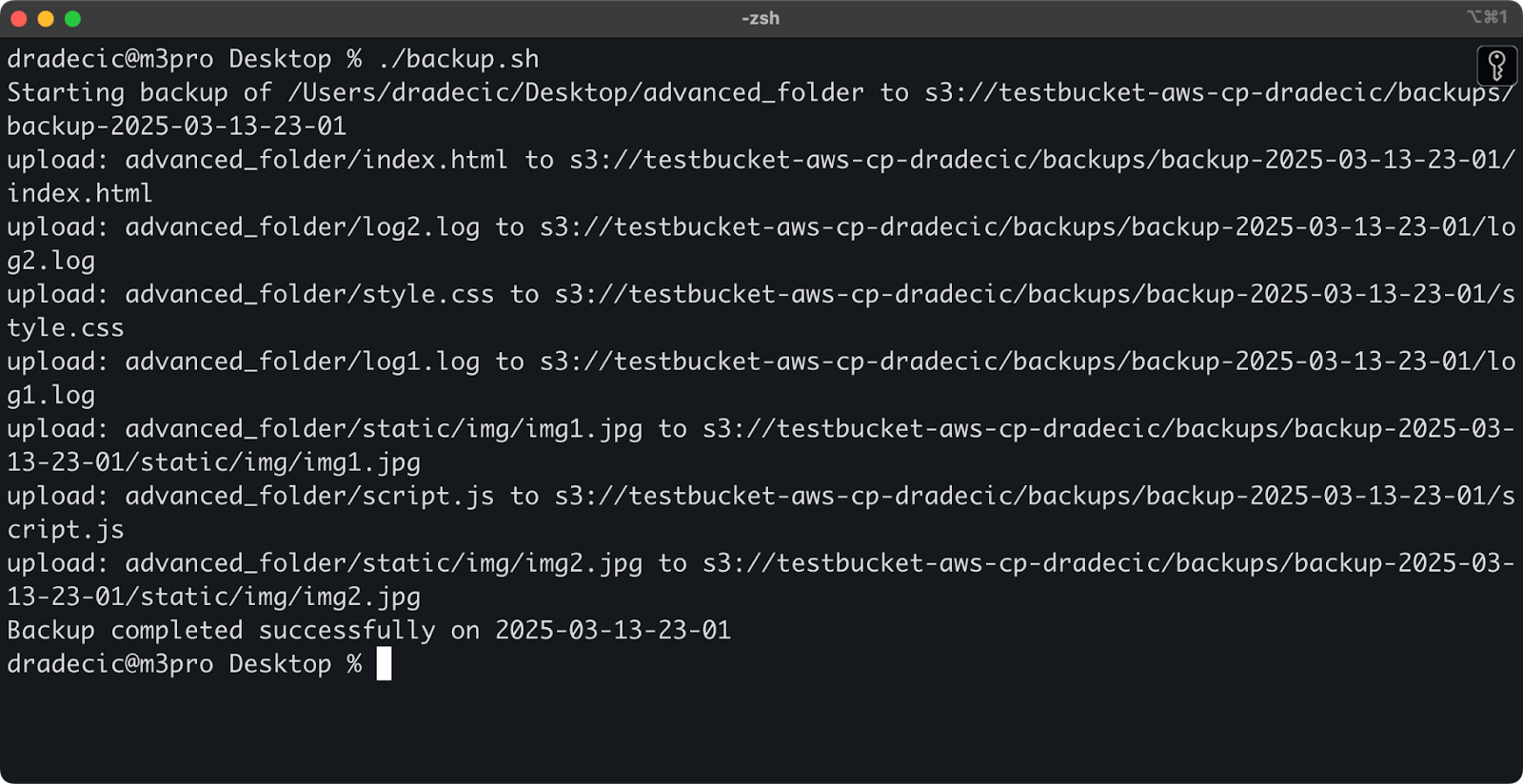
Image 19 - Script exécuté dans le terminal
Immédiatement après, le dossier backups du seau sera rempli :
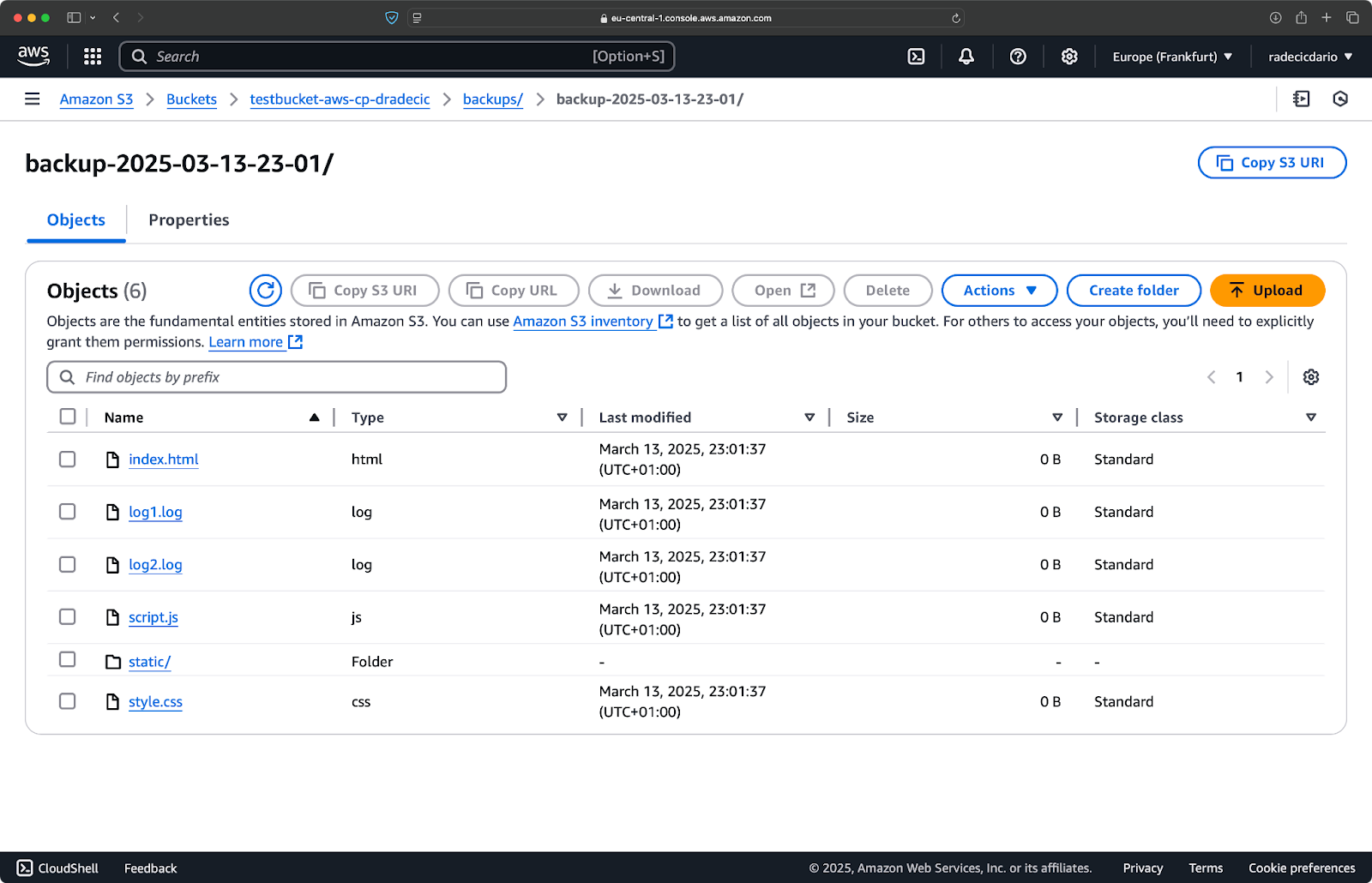
Image 20 - Sauvegarde stockée sur un panier S3
Passons à l'étape suivante en exécutant le script selon un calendrier.
Maintenant que vous disposez d'un script, l'étape suivante consiste à le programmer pour qu'il s'exécute automatiquement à des heures précises.
Si vous utilisez Linux ou macOS, vous pouvez utiliser cron pour planifier vos sauvegardes. Voici comment mettre en place une tâche cron pour exécuter votre script de sauvegarde tous les jours à minuit :
1. Ouvrez votre crontab pour l'éditer :
crontab -e2. Ajoutez la ligne suivante pour exécuter votre script tous les jours à minuit :
0 0 * * * /path/to/your/backup.sh
Image 21 - Tâche Cron pour l'exécution quotidienne du script
Le format des tâches cron est minute hour day-of-month month day-of-week command. Voici quelques exemples supplémentaires :
0 * * * * /path/to/your/backup.sh0 9 * * 1 /path/to/your/backup.sh0 0 1 * * /path/to/your/backup.shEt c'est tout ! Le script backup.sh s'exécutera désormais à l'intervalle programmé.
L'automatisation de vos transferts de fichiers S3 est une bonne solution. Il est particulièrement utile pour des scénarios tels que :
Ces techniques d'automatisation vous aideront à mettre en place un système fiable qui gère les transferts de fichiers sans intervention manuelle. Il suffit de l'écrire une fois, puis de l'oublier.
Dans la section suivante, j'aborderai quelques bonnes pratiques pour rendre vos opérations sur aws s3 cp plus sûres et plus efficaces.
Bien que la commande aws s3 cp soit facile à utiliser, les choses peuvent mal tourner.
Si vous suivez les meilleures pratiques, vous éviterez les pièges les plus courants, vous optimiserez les performances et vous assurerez la sécurité de vos données. Examinons ces pratiques pour rendre vos opérations de transfert de fichiers plus efficaces.
Lorsque vous travaillez avec S3, l'organisation logique de vos fichiers vous permettra de gagner du temps et de vous épargner des maux de tête.
Tout d'abord, établissez une convention de dénomination cohérente des seaux et des préfixes. Par exemple, vous pouvez séparer vos données par environnement, application ou date :
s3://company-backups/production/database/2023-03-13/
s3://company-backups/staging/uploads/2023-03/Ce type d'organisation facilite la tâche :
Autre conseil : Lorsque vous transférez de grands ensembles de fichiers, envisagez de regrouper d'abord les petits fichiers (à l'aide de zip ou de tar) avant de les télécharger. Cela permet de réduire le nombre d'appels d'API vers S3, ce qui peut réduire les coûts et accélérer les transferts.
# Instead of copying thousands of small log files
# tar them first, then upload
tar -czf example-logs-2025-03.tar.gz /var/log/application/
aws s3 cp example-logs-2025-03.tar.gz s3://testbucket-aws-cp-dradecic/logs/2025/03/Lorsque vous copiez des fichiers volumineux ou plusieurs fichiers à la fois, il existe quelques techniques pour rendre le processus plus fiable et plus efficace.
Vous pouvez utiliser l'option --quiet pour réduire la production lors de l'exécution de scripts :
aws s3 cp large-directory/ s3://testbucket-aws-cp-dradecic/backups/ --recursive --quietCela supprime les informations de progression pour chaque fichier, ce qui rend les journaux plus faciles à gérer. Il améliore aussi légèrement les performances.
Pour les fichiers très volumineux, envisagez d'utiliser téléchargements en plusieurs parties avec l'option --multipart-threshold:
aws s3 cp huge-file.iso s3://testbucket-aws-cp-dradecic/backups/ --multipart-threshold 100MBLe paramètre ci-dessus indique à AWS CLI de diviser les fichiers de plus de 100 Mo en plusieurs parties pour le téléchargement. Cette démarche présente plusieurs avantages :
Lorsque transfert de données entre régionsenvisagez d'utiliser l'accélération de transfert S3 pour des téléchargements plus rapides :
aws s3 cp large-file.zip s3://testbucket-aws-cp-dradecic/backups/ --endpoint-url https://s3-accelerate.amazonaws.comL'option ci-dessus fait passer votre transfert par le réseau périphérique d'Amazon, ce qui permet d'accélérer considérablement les transferts entre régions.
La sécurité doit toujours être une priorité absolue lorsque vous travaillez avec vos données dans le cloud.
Tout d'abord, assurez-vous que vos autorisations IAM respectent le principe du moindre privilège. N'accordez que les autorisations spécifiques nécessaires à chaque tâche.
Voici un exemple de politique que vous pouvez attribuer à l'utilisateur :
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject"
],
"Resource": "arn:aws:s3:::testbucket-aws-cp-dradecic/backups/*"
}
]
}Cette politique permet de copier des fichiers depuis et vers le préfixe "backups" de "my-bucket".
Un autre moyen d'accroître la sécurité consiste à activer le cryptage pour les données sensibles. Vous pouvez spécifier le cryptage côté serveur lors du téléchargement :
aws s3 cp confidential.docx s3://testbucket-aws-cp-dradecic/ --sse AES256Ou, pour plus de sécurité, utilisez AWS Key Management Service (KMS) :
aws s3 cp secret-data.json s3://testbucket-aws-cp-dradecic/ --sse aws:kms --sse-kms-key-id myKMSKeyIdToutefois, pour les opérations très sensibles, envisagez d'utiliser des points d'extrémité VPC pour S3. Cela permet de maintenir votre trafic au sein du réseau AWS et d'éviter complètement l'internet public.
Dans la section suivante, vous apprendrez à résoudre les problèmes courants que vous pouvez rencontrer lorsque vous utilisez cette commande.
Une chose est sûre : vous rencontrerez parfois des problèmes lorsque vous travaillerez avec aws s3 cp. Mais en comprenant les erreurs courantes et leurs solutions, vous économiserez du temps et de la frustration lorsque les choses ne se déroulent pas comme prévu.
Dans cette section, je vous montrerai les problèmes les plus fréquents et comment les résoudre.
C'est probablement l'erreur la plus fréquente que vous rencontrerez :
upload failed: ./myfile.txt to s3://testbucket-aws-cp-dradecic/myfile.txt An error occurred (AccessDenied) when calling the PutObject operation: Access DeniedCela signifie généralement l'une des trois choses suivantes :
Pour résoudre le problème :
s3:PutObject (pour les téléchargements) ou s3:GetObject (pour les téléchargements).aws configure pour mettre à jour vos informations d'identification si elles ont expiré.Cette erreur se produit lorsque le fichier local ou le répertoire que vous essayez de copier n'existe pas :
upload failed: ./missing-file.txt to s3://testbucket-aws-cp-dradecic/missing-file.txt An error occurred (404) when calling the PutObject operation: Not FoundLa solution est simple : vérifiez soigneusement les chemins d'accès à vos fichiers. Les chemins d'accès sont sensibles à la casse, gardez cela à l'esprit. Assurez-vous également que vous êtes dans le bon répertoire lorsque vous utilisez des chemins relatifs.
Si vous voyez cette erreur :
upload failed: ./myfile.txt to s3://testbucket-aws-cp-dradecic/myfile.txt An error occurred (NoSuchBucket) when calling the PutObject operation: The specified bucket does not existVérifier pour :
Vous pouvez lister tous vos buckets avec aws s3 ls pour confirmer le nom correct.
Des problèmes de réseau peuvent entraîner des dépassements de délai de connexion :
upload failed: ./largefile.zip to s3://testbucket-aws-cp-dradecic/largefile.zip An error occurred (RequestTimeout) when calling the PutObject operation: Request timeoutPour résoudre ce problème :
Les erreurs sont beaucoup plus susceptibles de se produire lors du transfert de fichiers volumineux. Lorsque c'est le cas, essayez de gérer les échecs avec élégance.
Par exemple, vous pouvez utiliser l'indicateur --only-show-errors pour faciliter le diagnostic des erreurs dans les scripts :
aws s3 cp large-directory/ s3://testbucket-aws-cp-dradecic/ --recursive --only-show-errorsCette option supprime les messages de transfert réussis et n'affiche que les erreurs, ce qui facilite grandement le dépannage des transferts importants.
Pour gérer les transferts interrompus, la commande --recursive ignore automatiquement les fichiers de même taille qui existent déjà dans la destination. Cependant, pour être plus complet, vous pouvez utiliser les tentatives intégrées de la CLI AWS pour les problèmes de réseau en définissant ces variables d'environnement :
export AWS_RETRY_MODE=standard
export AWS_MAX_ATTEMPTS=5
aws s3 cp large-file.zip s3://testbucket-aws-cp-dradecic/Cette option permet à l'interface de programmation AWS de réessayer automatiquement les opérations qui ont échoué, jusqu'à 5 fois.
Mais pour les très grands ensembles de données, envisagez d'utiliser aws s3 sync au lieu de cp, car il est conçu pour mieux gérer les interruptions :
aws s3 sync large-directory/ s3://testbucket-aws-cp-dradecic/large-directory/La commande sync ne transfère que les fichiers différents de ceux qui se trouvent déjà dans la destination, ce qui est idéal pour reprendre des transferts importants interrompus.
Si vous comprenez ces erreurs courantes et que vous mettez en œuvre une gestion appropriée des erreurs dans vos scripts, vous rendrez vos opérations de copie S3 beaucoup plus robustes et fiables.
En conclusion, la commande aws s3 cp est un moyen unique de copier des fichiers locaux sur S3 et vice-versa.
Vous avez tout appris à ce sujet dans cet article. Vous avez commencé par les principes de base et la configuration de l'environnement, et vous avez fini par écrire des scripts programmés et automatisés pour copier des fichiers. Vous avez également appris à résoudre certaines erreurs et difficultés courantes lors du déplacement de fichiers, en particulier de fichiers volumineux.
Si vous êtes un développeur, un professionnel des données ou un administrateur système, je pense que cette commande vous sera utile. La meilleure façon de s'y habituer est de l'utiliser régulièrement. Assurez-vous de bien comprendre les principes fondamentaux, puis passez du temps à automatiser les tâches fastidieuses de votre travail.
Pour en savoir plus sur AWS, suivez ces formations proposées par DataCamp :
Vous pouvez même utiliser DataCamp pour vous préparer aux examens de certification AWS - AWS Cloud Practitioner (CLF-C02).
Apprenez-en plus sur AWS grâce à ces cours !
Cours
Cours
Cours