
Kurs
Introduction to AWS Boto in Python
4 Std.
18.4K
Bevor du den Befehl aws s3 cp ausführst, musst du AWS CLI auf deinem System installiert und richtig konfiguriert haben. Keine Sorge, wenn du noch nie mit AWS gearbeitet hast - der Einrichtungsprozess ist einfach und sollte weniger als 10 Minuten dauern.
Ich werde dies in drei einfache Phasen unterteilen: die Installation des AWS CLI-Tools, die Konfiguration deiner Anmeldedaten und die Erstellung deines ersten S3-Buckets für die Speicherung.
Je nachdem, welches Betriebssystem du verwendest, unterscheidet sich der Installationsprozess leicht.
Für Windows-Systeme:
Für Linux-Systeme:
Führe die folgenden drei Befehle über das Terminal aus:
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
unzip awscliv2.zip
sudo ./aws/installFür macOS-Systeme:
Angenommen, du hast Homebrew installiert, dann führe diese eine Zeile im Terminal aus:
brew install awscliWenn du kein Homebrew hast, kannst du stattdessen diese beiden Befehle verwenden:
curl "https://awscli.amazonaws.com/AWSCLIV2.pkg" -o "AWSCLIV2.pkg"
sudo installer -pkg AWSCLIV2.pkg -target /Um die erfolgreiche Installation zu bestätigen, führe aws --version in deinem Terminal aus. Du solltest so etwas wie das hier sehen:
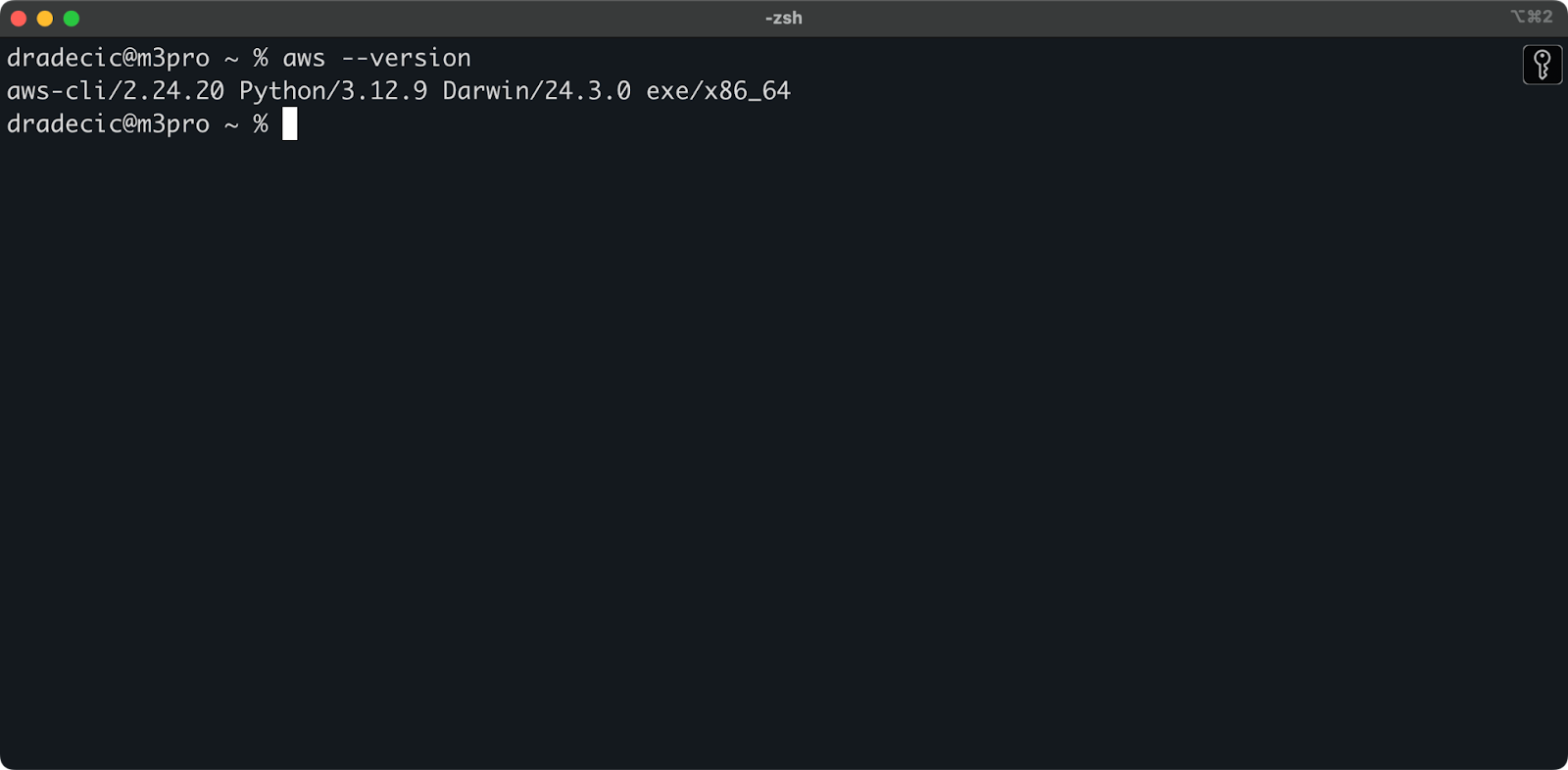
Abbildung 1 - AWS CLI-Version
Nachdem du die CLI installiert hast, musst du deine AWS-Anmeldedaten für die Authentifizierung einrichten.
Greife zunächst auf dein AWS-Konto zu und navigiere zum IAM-Service-Dashboard. Erstelle einen neuen Benutzer mit programmatischem Zugriff und füge die entsprechende S3-Berechtigungsrichtlinie hinzu:
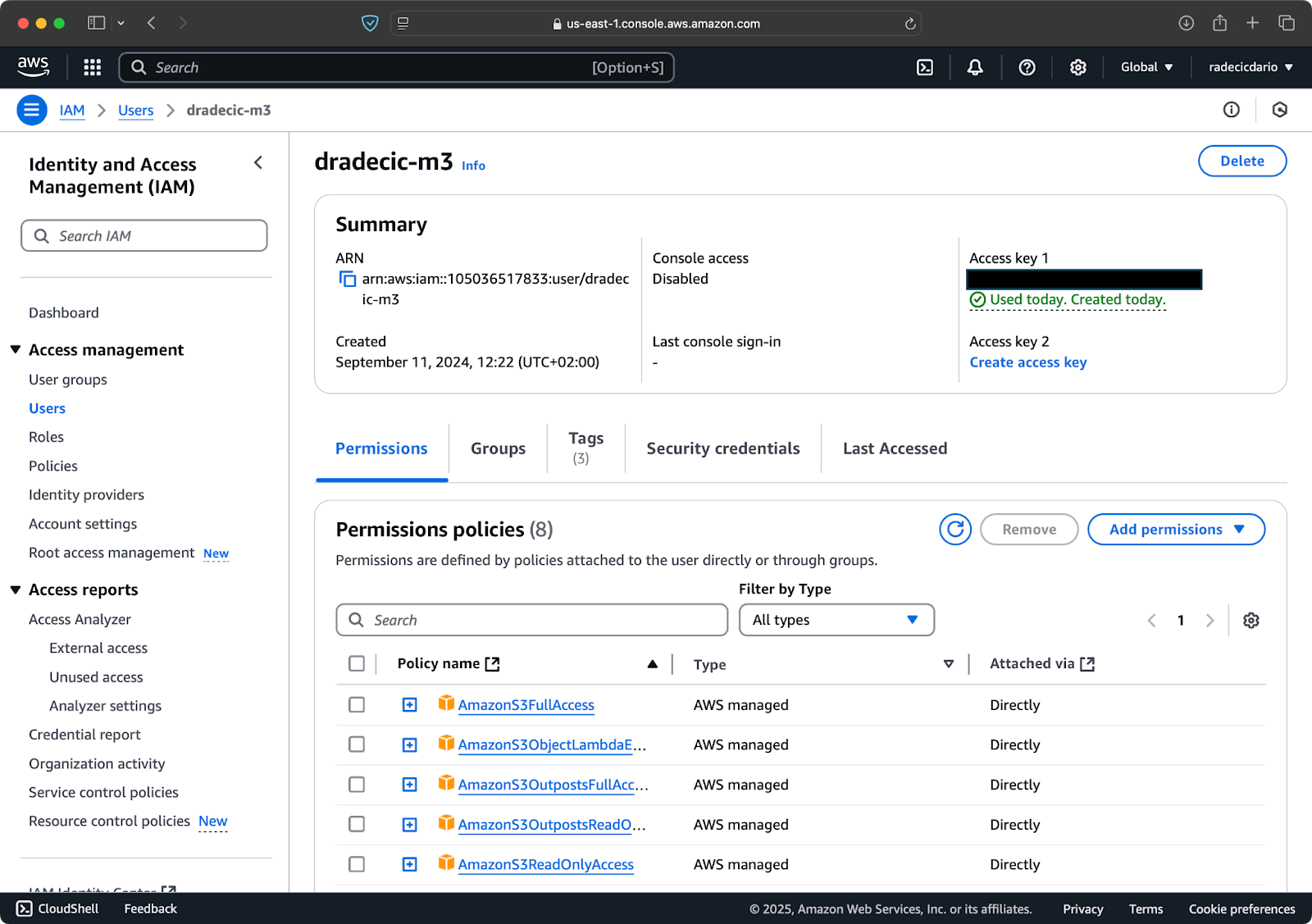
Abbildung 2 - AWS IAM-Benutzer
Als Nächstes besuchst du die Registerkarte "Sicherheitszugangsdaten" und erstellst ein neues Schlüsselpaar. Achte darauf, dass du sowohl die Zugangsschlüssel-ID als auch den geheimen Zugangsschlüssel an einem sicheren Ort speicherst - Amazon wird dir den geheimen Schlüssel nach diesem Bildschirm nicht mehr anzeigen:
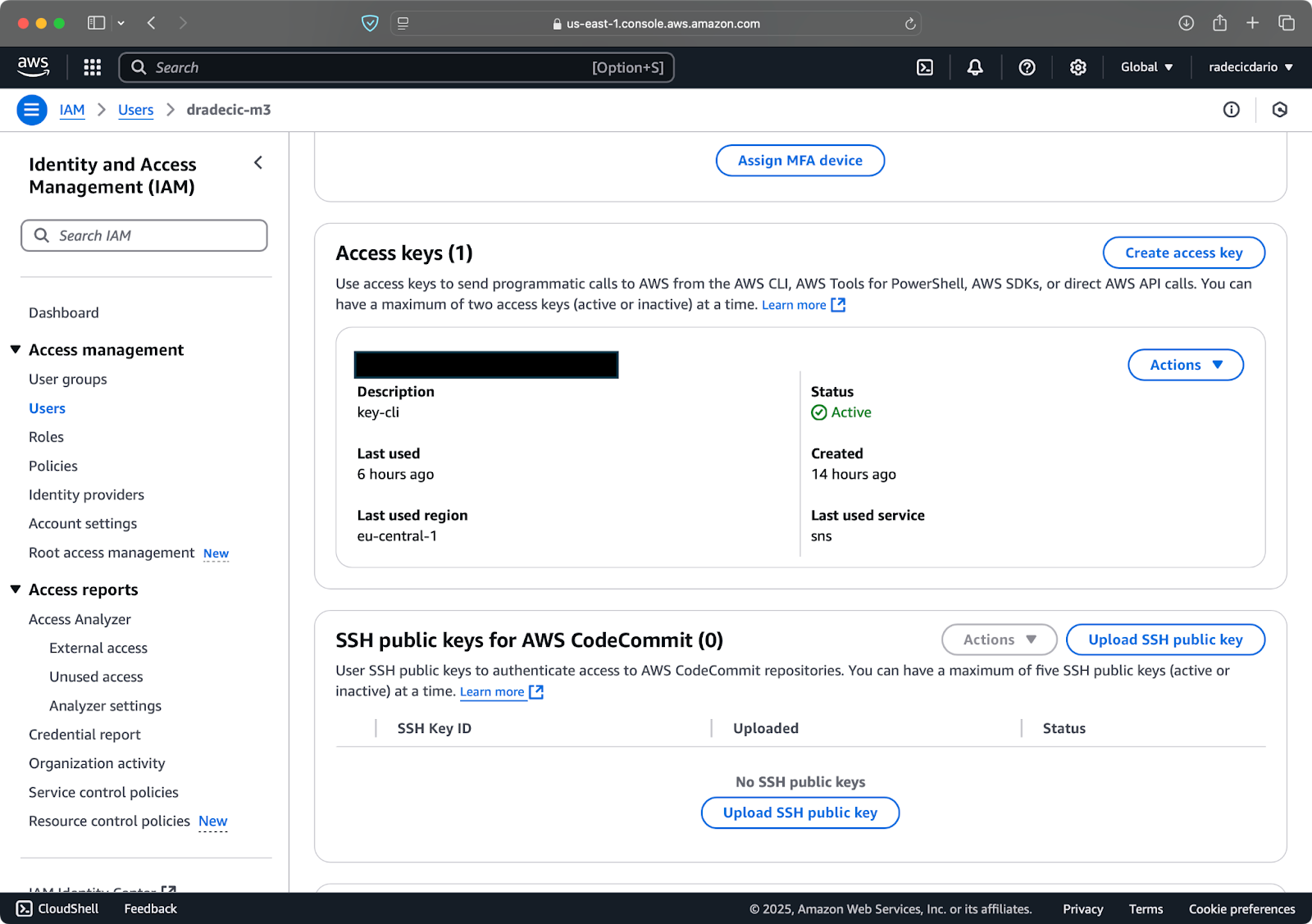
Abbildung 3 - AWS IAM-Benutzeranmeldeinformationen
Öffne nun dein Terminal und führe den Befehl aws configure aus. Du wirst nach vier Informationen gefragt: deine Zugangsschlüssel-ID, dein geheimer Zugangsschlüssel, deine Standardregion (ich verwende eu-central-1) und dein bevorzugtes Ausgabeformat (normalerweise json):
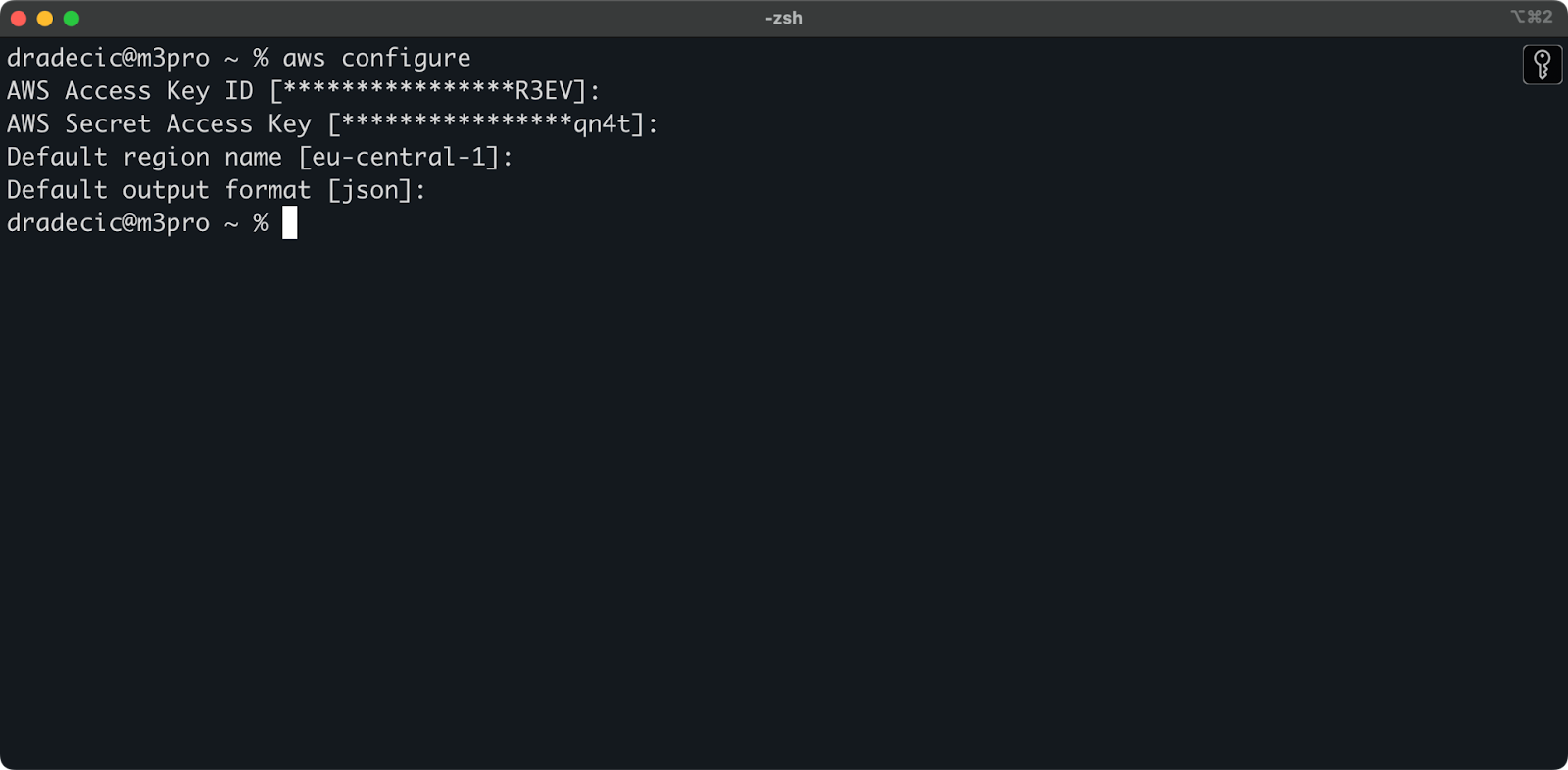
Abbildung 4 - AWS CLI-Konfiguration
Um sicherzustellen, dass alles richtig angeschlossen ist, überprüfe deine Identität mit dem folgenden Befehl:
aws sts get-caller-identityWenn du richtig konfiguriert bist, siehst du deine Kontodaten:
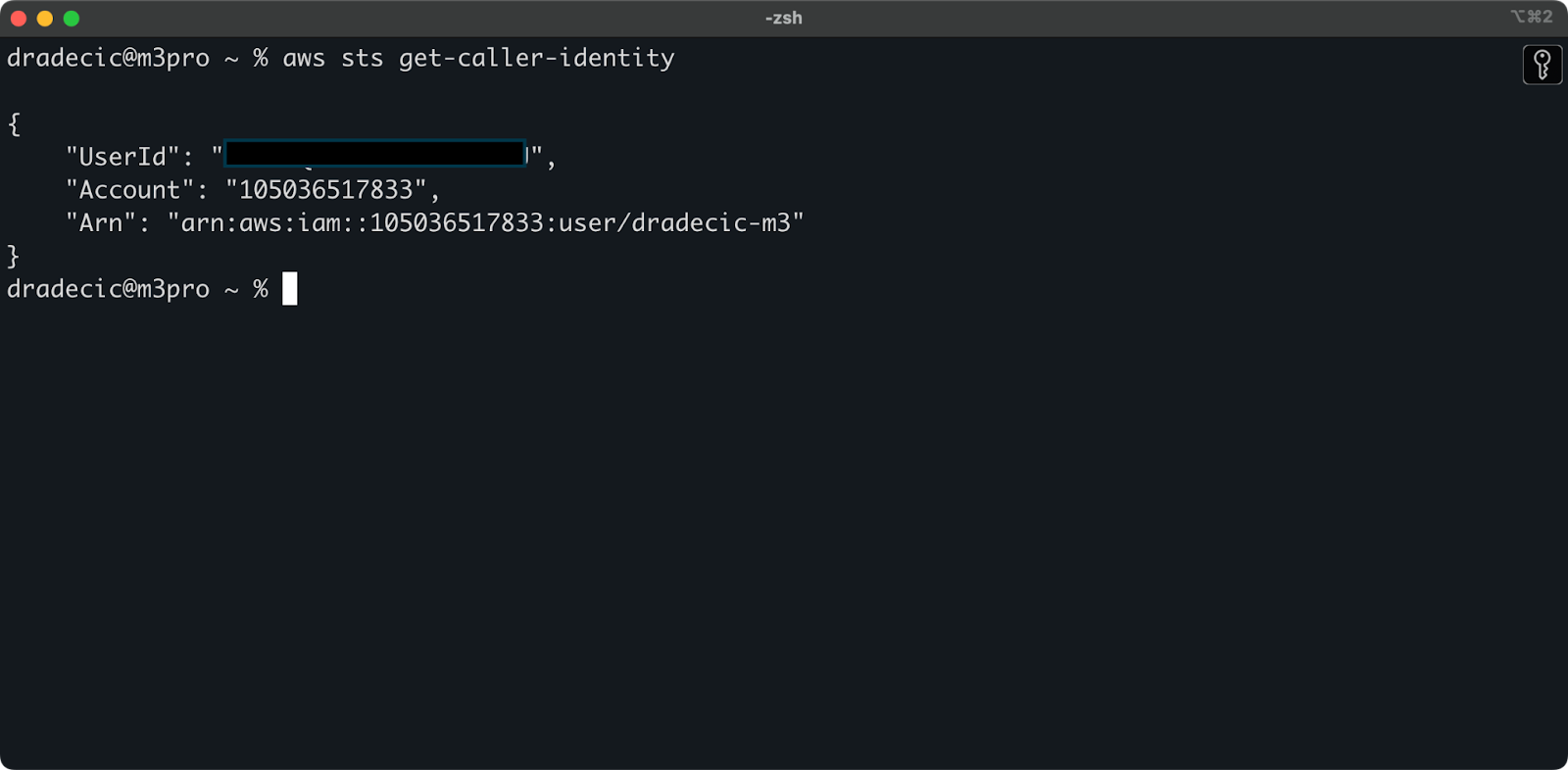
Abbildung 5 - AWS CLI-Befehl zum Testen der Verbindung
Schließlich musst du einen S3-Bucket erstellen, um die zu kopierenden Dateien zu speichern.
Gehe in deiner AWS-Konsole in den Bereich S3-Service und klicke auf "Bucket erstellen". Denke daran, dass Bucket-Namen in ganz AWS global eindeutig sein müssen. Wähle einen aussagekräftigen Namen, lass die Standardeinstellungen vorerst stehen und klicke auf "Erstellen":
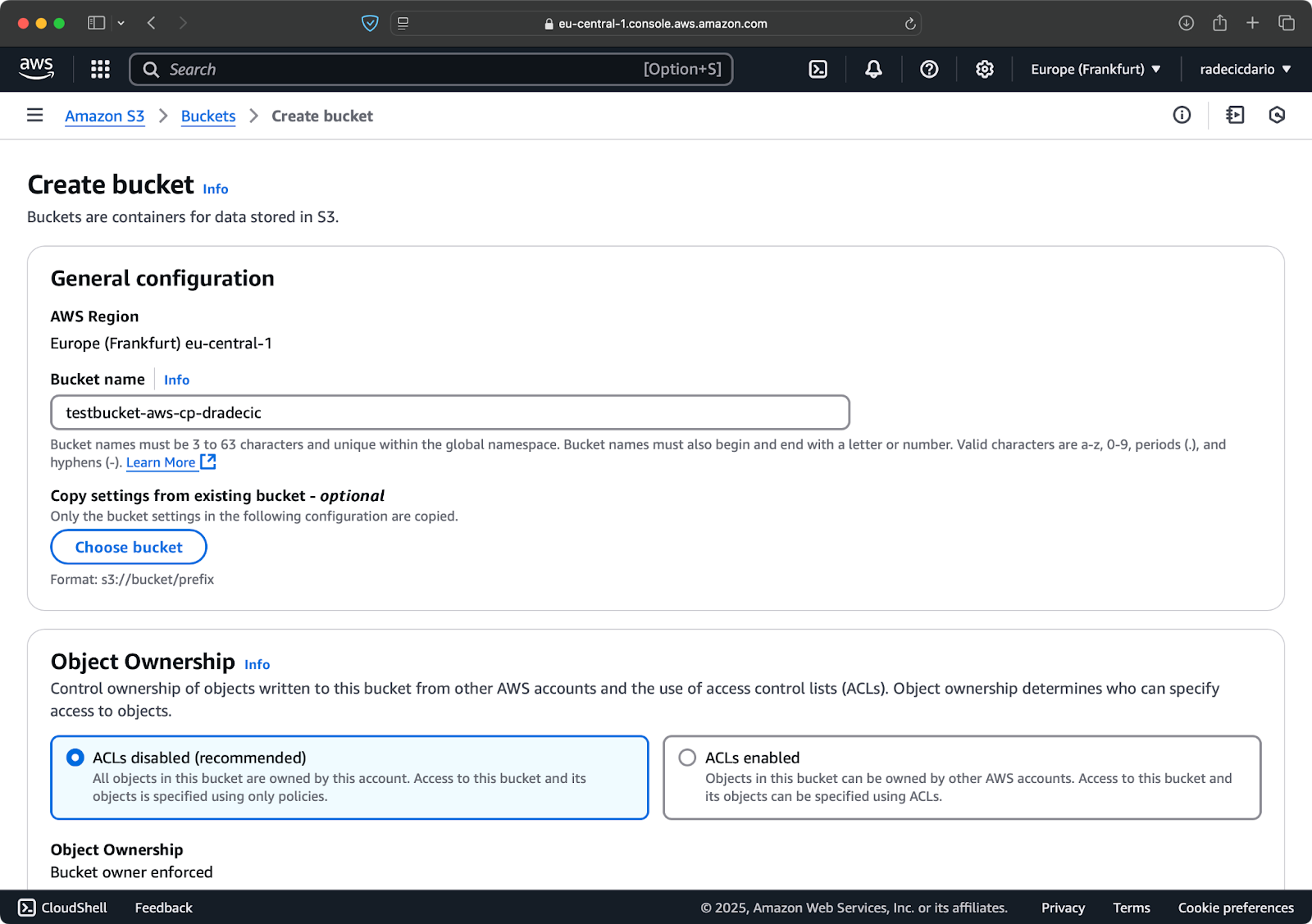
Abbildung 6 - Erstellung eines AWS Buckets
Sobald er erstellt ist, erscheint dein neuer Bucket in der Konsole. Du kannst seine Existenz auch über die Kommandozeile bestätigen:
aws s3 ls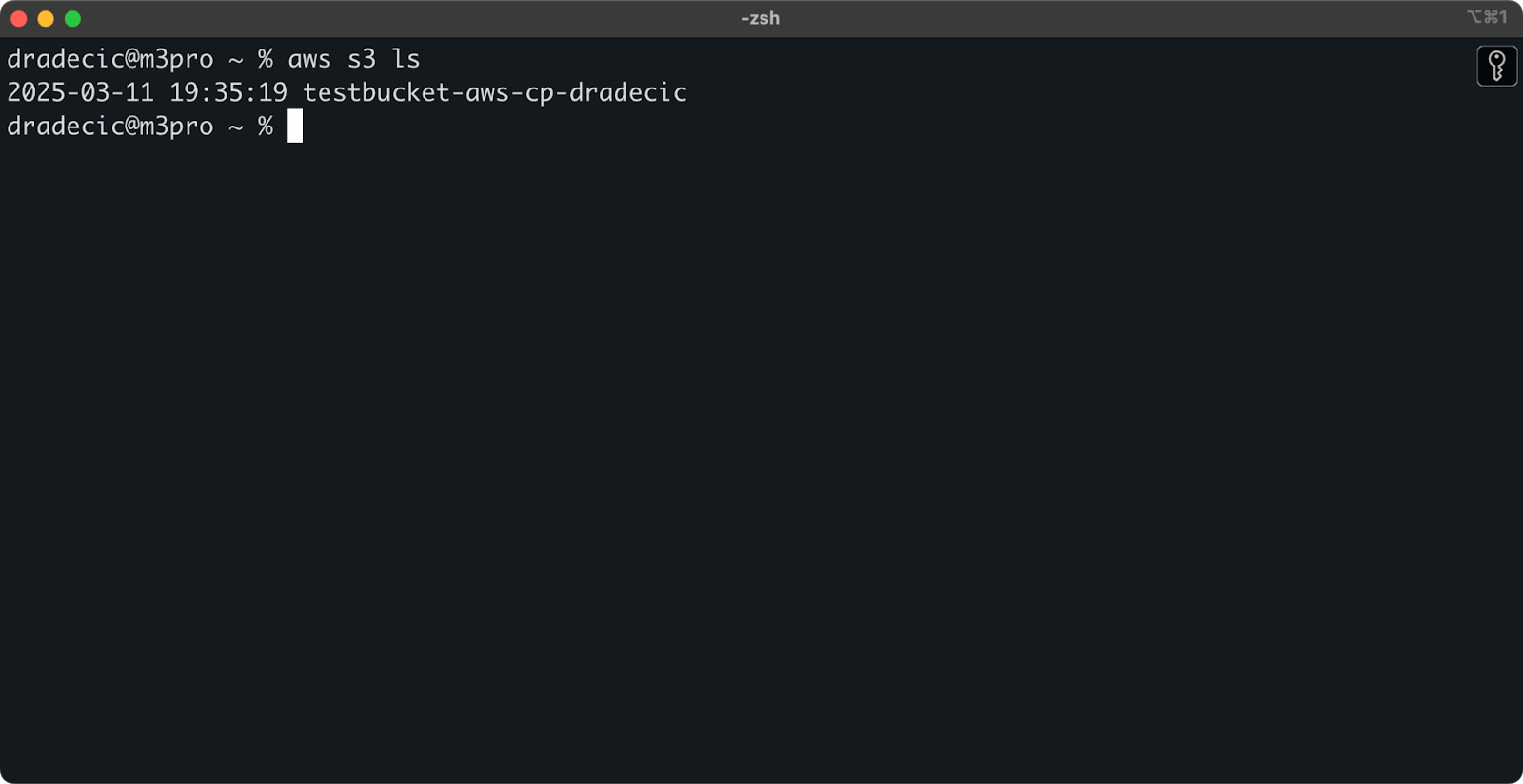
Abbildung 7 - Alle verfügbaren S3-Buckets
Alle S3-Buckets sind standardmäßig als privat konfiguriert, also beachte dies. Wenn du diesen Bucket für öffentlich zugängliche Dateien nutzen willst, musst du die Bucket-Richtlinien entsprechend anpassen.
Jetzt bist du bestens gerüstet, um den Befehl aws s3 cp zum Übertragen von Dateien zu verwenden. Beginnen wir als Nächstes mit den Grundlagen.
Nachdem du nun alles konfiguriert hast, können wir uns mit der grundlegenden Verwendung des aws s3 cp Befehls beschäftigen. Wie bei AWS üblich, liegt die Schönheit in der Einfachheit, auch wenn der Befehl verschiedene Dateiübertragungsszenarien verarbeiten kann.
In seiner einfachsten Form folgt der Befehl aws s3 cp dieser Syntax:
aws s3 cp <source> <destination> [options]Dabei können lokale Dateipfade oder S3 URIs (die mit s3:// beginnen) sein. Schauen wir uns die drei häufigsten Anwendungsfälle an.
Um eine Datei von deinem lokalen System in einen S3-Bucket zu kopieren, ist die Quelle ein lokaler Pfad und das Ziel ein S3-URI:
aws s3 cp /Users/dradecic/Desktop/test_file.txt s3://testbucket-aws-cp-dradecic/test_file.txtMit diesem Befehl wird die Datei test_file.txt aus dem angegebenen Verzeichnis in den angegebenen S3-Bucket hochgeladen. Wenn der Vorgang erfolgreich ist, siehst du eine Konsolenausgabe wie diese:
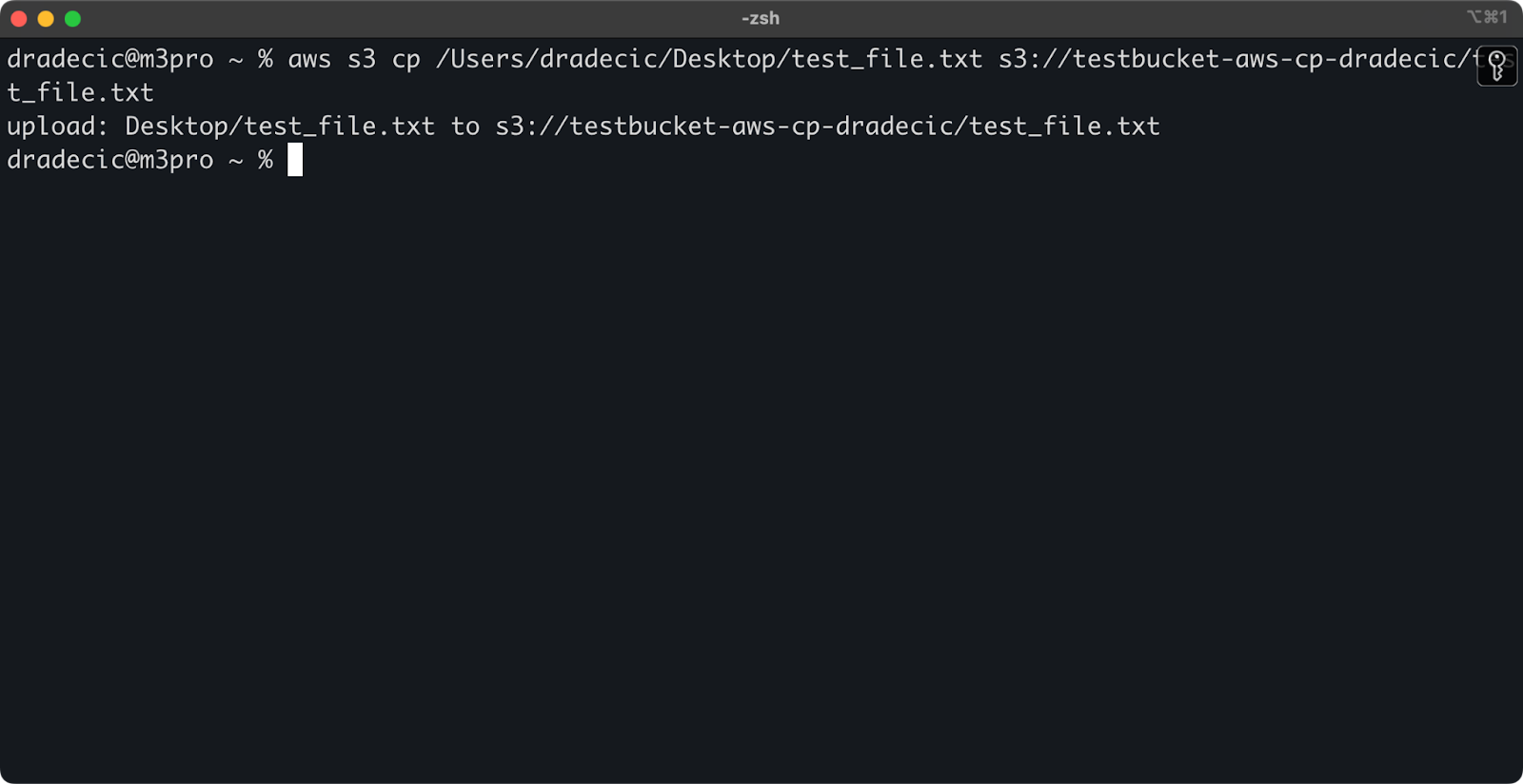
Abbildung 8 - Konsolenausgabe nach dem Kopieren der lokalen Datei
In der AWS-Verwaltungskonsole siehst du dann, dass deine Datei hochgeladen wurde:
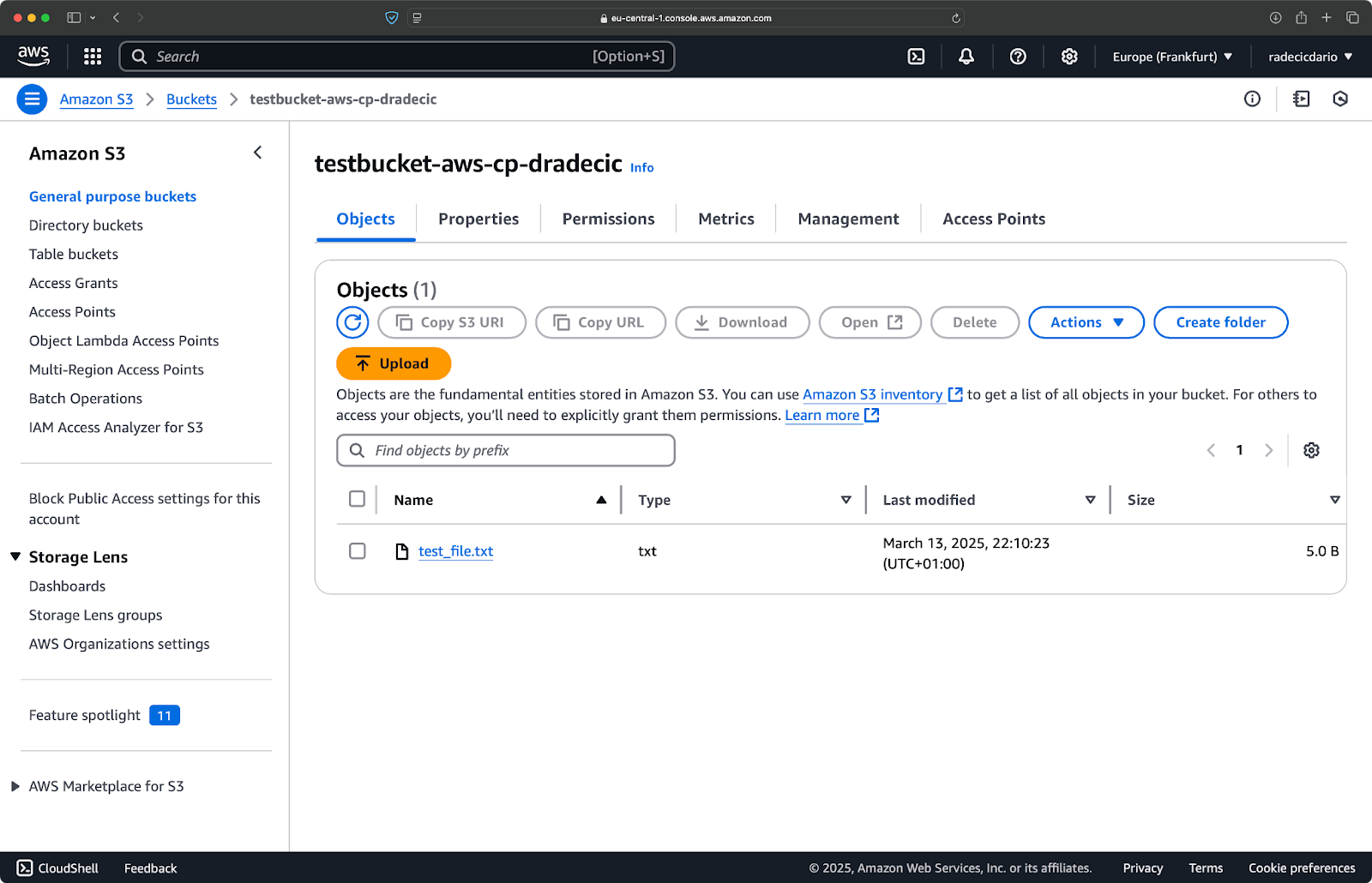
Abbildung 9 - Inhalt des S3-Buckets
Wenn du einen lokalen Ordner in deinen S3-Bucket kopieren und ihn, sagen wir, in einen anderen verschachtelten Ordner legen willst, führst du einen ähnlichen Befehl wie diesen aus:
aws s3 cp /Users/dradecic/Desktop/test_folder s3://testbucket-aws-cp-dradecic/my-desired-folder/test_folder/ --recursive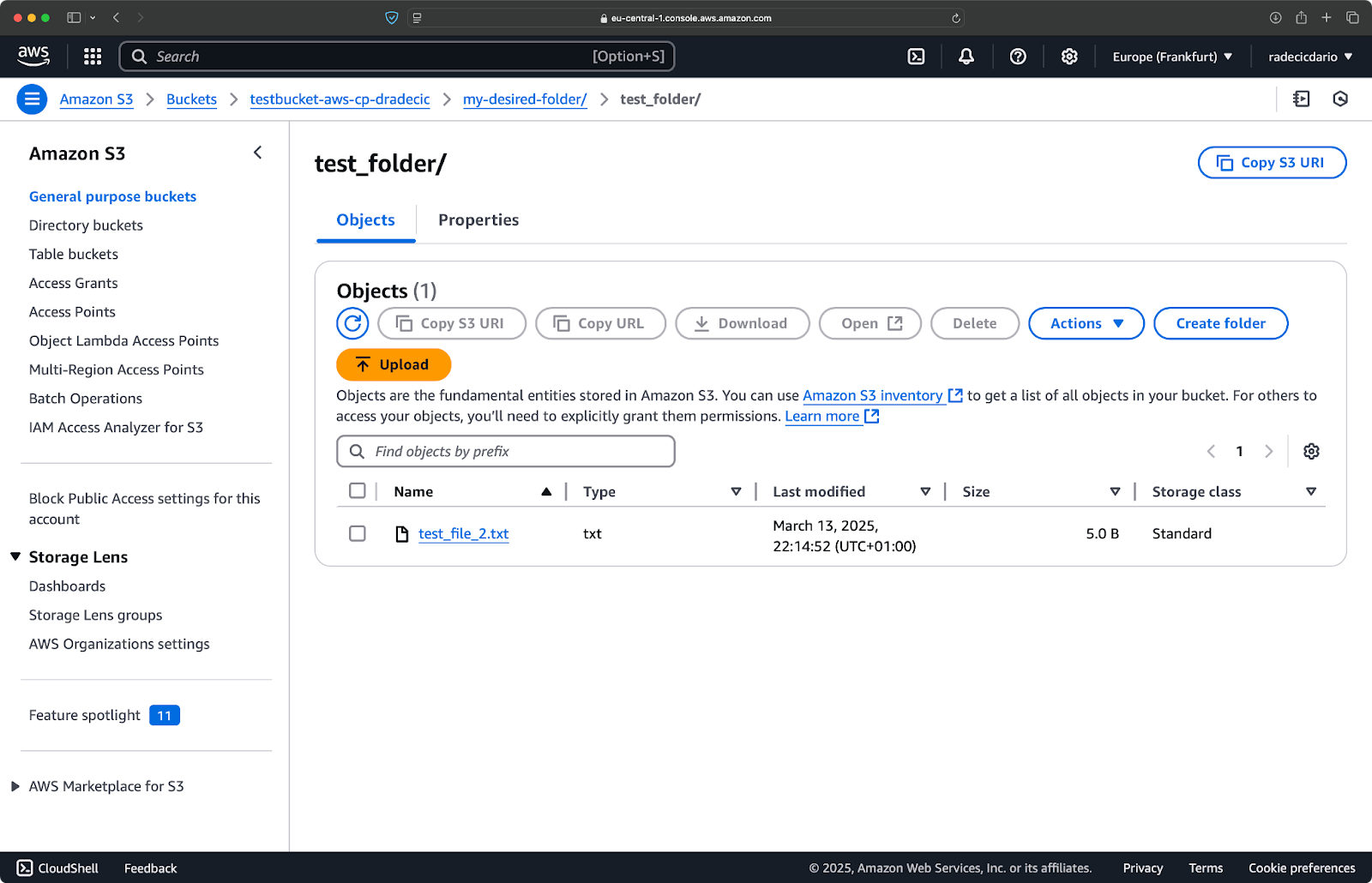
Abbildung 10 - Inhalt des S3-Buckets nach dem Hochladen eines Ordners
Das --recursive Flag sorgt dafür, dass alle Dateien und Unterordner innerhalb des Ordners kopiert werden.
Vergiss nicht, dass S3 eigentlich keine Ordner hat - die Pfadstruktur ist nur ein Teil des Objektschlüssels, aber sie funktioniert konzeptionell wie Ordner.
Um eine Datei von S3 auf dein lokales System zu kopieren, kehrst du einfach die Reihenfolge um - die Quelle wird zur S3 URI und das Ziel ist dein lokaler Pfad:
aws s3 cp s3://testbucket-aws-cp-dradecic/test_file.txt /Users/dradecic/Documents/s3-data/downloaded_test_file.txtDieser Befehl lädt test_file.txt von deinem S3-Bucket herunter und speichert es als downloaded_test_file.txt in dem angegebenen Verzeichnis. Du wirst es sofort auf deinem lokalen System sehen:
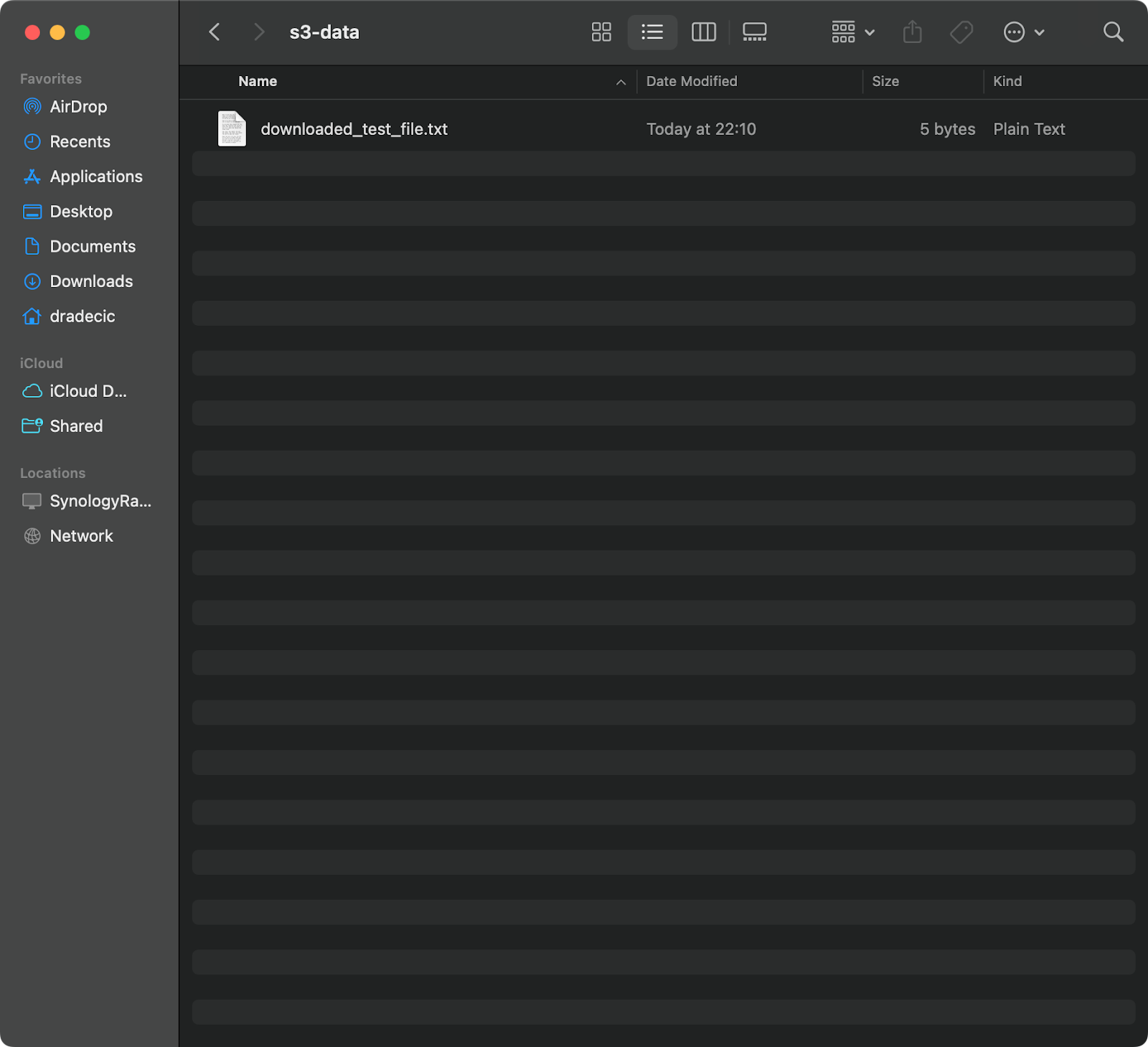
Abbildung 11 - Herunterladen einer einzelnen Datei von S3
Wenn du den Zieldateinamen nicht angibst, verwendet der Befehl den ursprünglichen Dateinamen:
aws s3 cp s3://testbucket-aws-cp-dradecic/test_file.txt .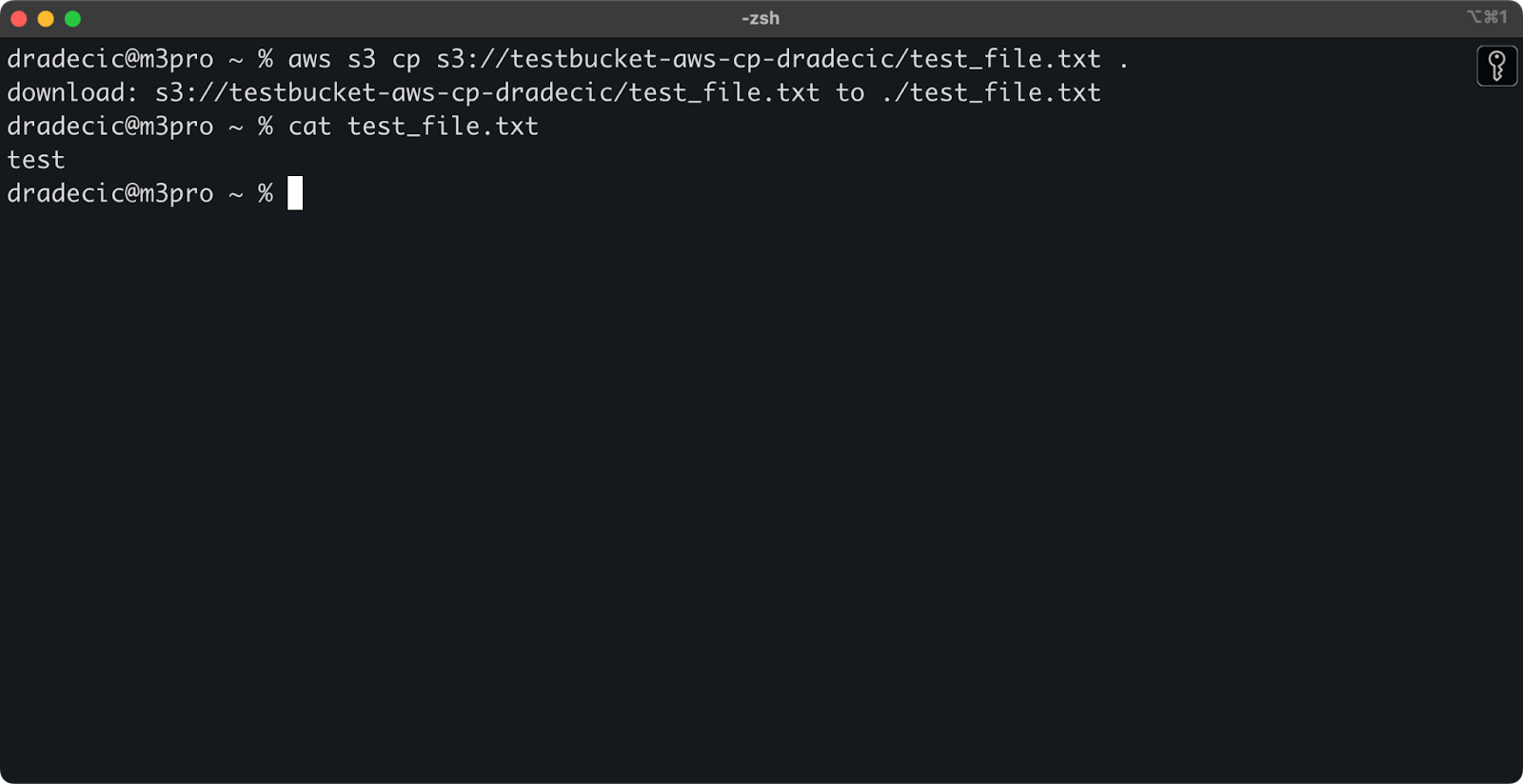
Abbildung 12 - Inhalt der heruntergeladenen Datei
Der Punkt (.) steht für dein aktuelles Verzeichnis, d.h. test_file.txt wird in dein aktuelles Verzeichnis heruntergeladen.
Und um ein ganzes Verzeichnis herunterzuladen, kannst du einen ähnlichen Befehl wie diesen verwenden:
aws s3 cp s3://testbucket-aws-cp-dradecic/my-desired-folder/test_folder /Users/dradecic/Documents/test_folder --recursive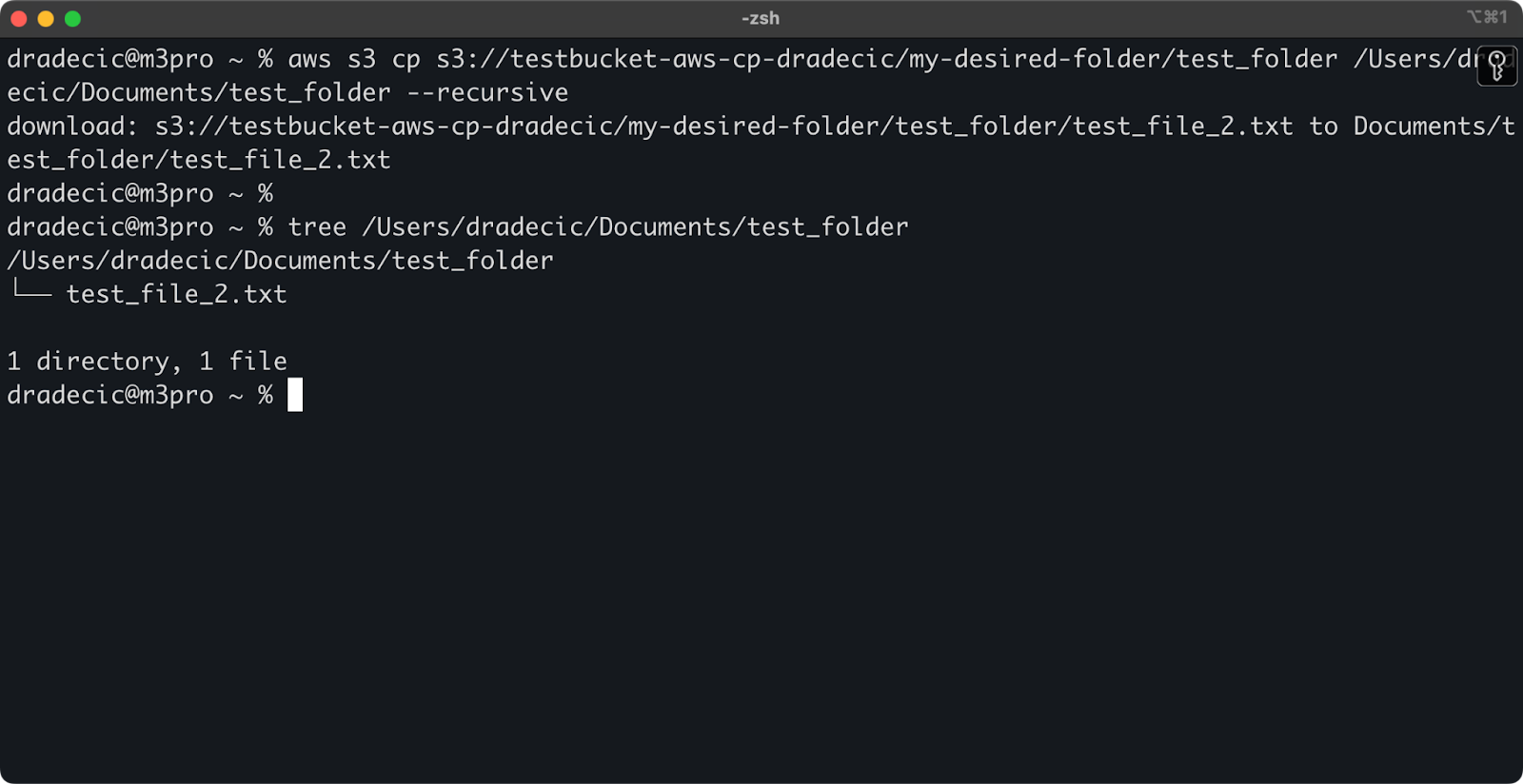
Abbildung 13 - Inhalt des heruntergeladenen Ordners
Denke daran, dass das --recursive Flag wichtig ist, wenn du mit mehreren Dateien arbeitest - ohne es schlägt der Befehl fehl, wenn die Quelle ein Verzeichnis ist.
Mit diesen grundlegenden Befehlen kannst du bereits die meisten der benötigten Dateiübertragungsaufgaben erledigen. Im nächsten Abschnitt lernst du erweiterte Optionen kennen, die dir eine bessere Kontrolle über den Kopiervorgang geben.
AWS bietet eine Reihe erweiterter Optionen, mit denen du das Kopieren von Dateien optimieren kannst. In diesem Abschnitt zeige ich dir einige der nützlichsten Flaggen und Parameter, die dir bei deinen täglichen Aufgaben helfen.
Manchmal möchtest du nur bestimmte Dateien kopieren, die bestimmten Mustern entsprechen. Mit den Flags --exclude und --include kannst du Dateien anhand von Mustern filtern und genau kontrollieren, was kopiert wird.
Das ist die Verzeichnisstruktur, mit der ich arbeite:
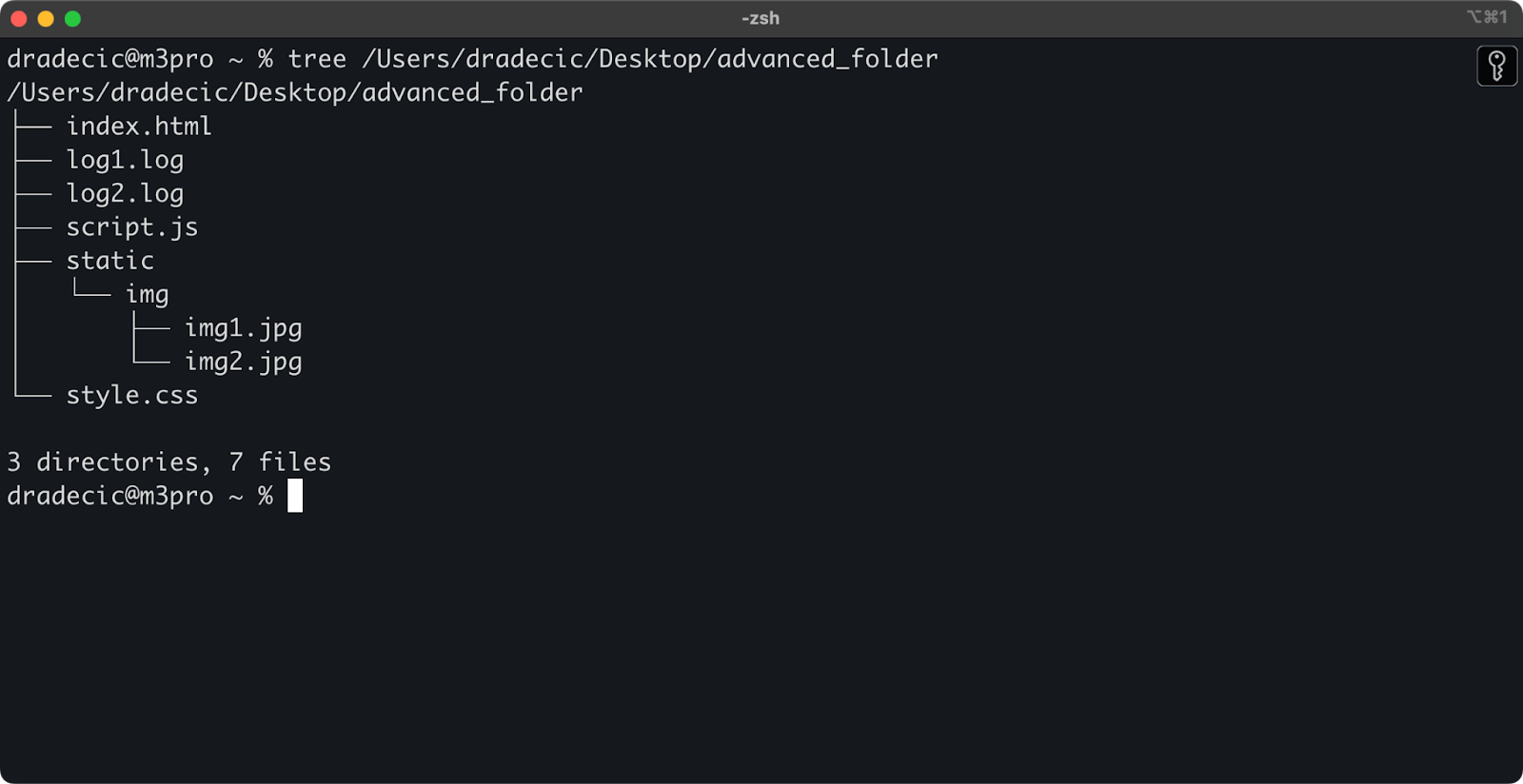
Abbildung 14 - Verzeichnisstruktur
Nehmen wir an, du willst alle Dateien aus dem Verzeichnis kopieren, außer den .log Dateien:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --exclude "*.log"Mit diesem Befehl werden alle Dateien aus dem Verzeichnis advanced_folder nach S3 kopiert, mit Ausnahme aller Dateien mit der Erweiterung .log:
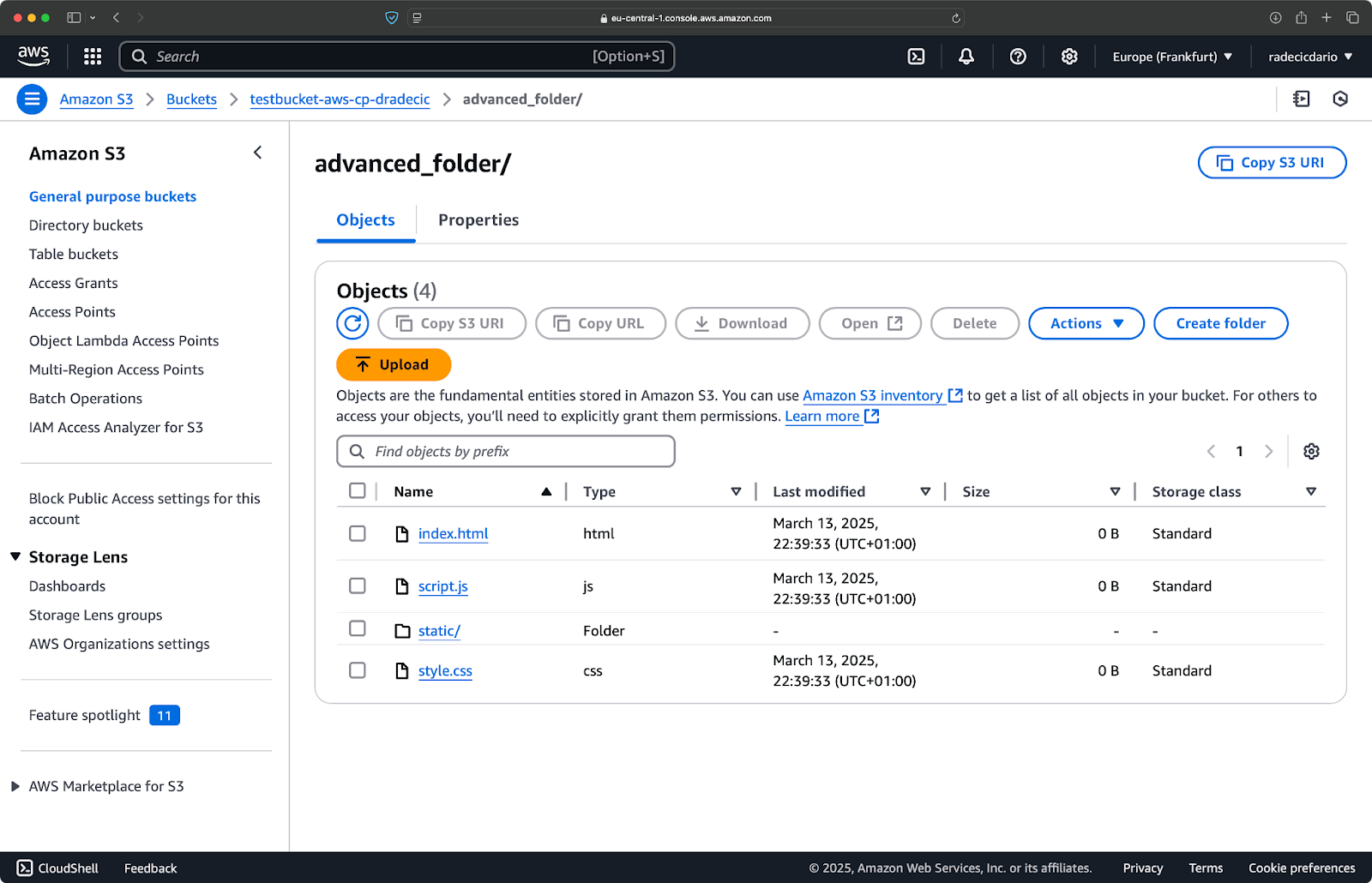
Abbildung 15 - Ergebnisse beim Kopieren von Ordnern
Du kannst auch mehrere Muster kombinieren. Nehmen wir an, du willst nur die HTML- und CSS-Dateien aus dem Projektordner kopieren:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --exclude "*" --include "*.html" --include "*.css"Dieser Befehl schließt zunächst alles aus (--exclude "*") und schließt dann nur Dateien mit den Erweiterungen .html und .css ein. Das Ergebnis sieht so aus:
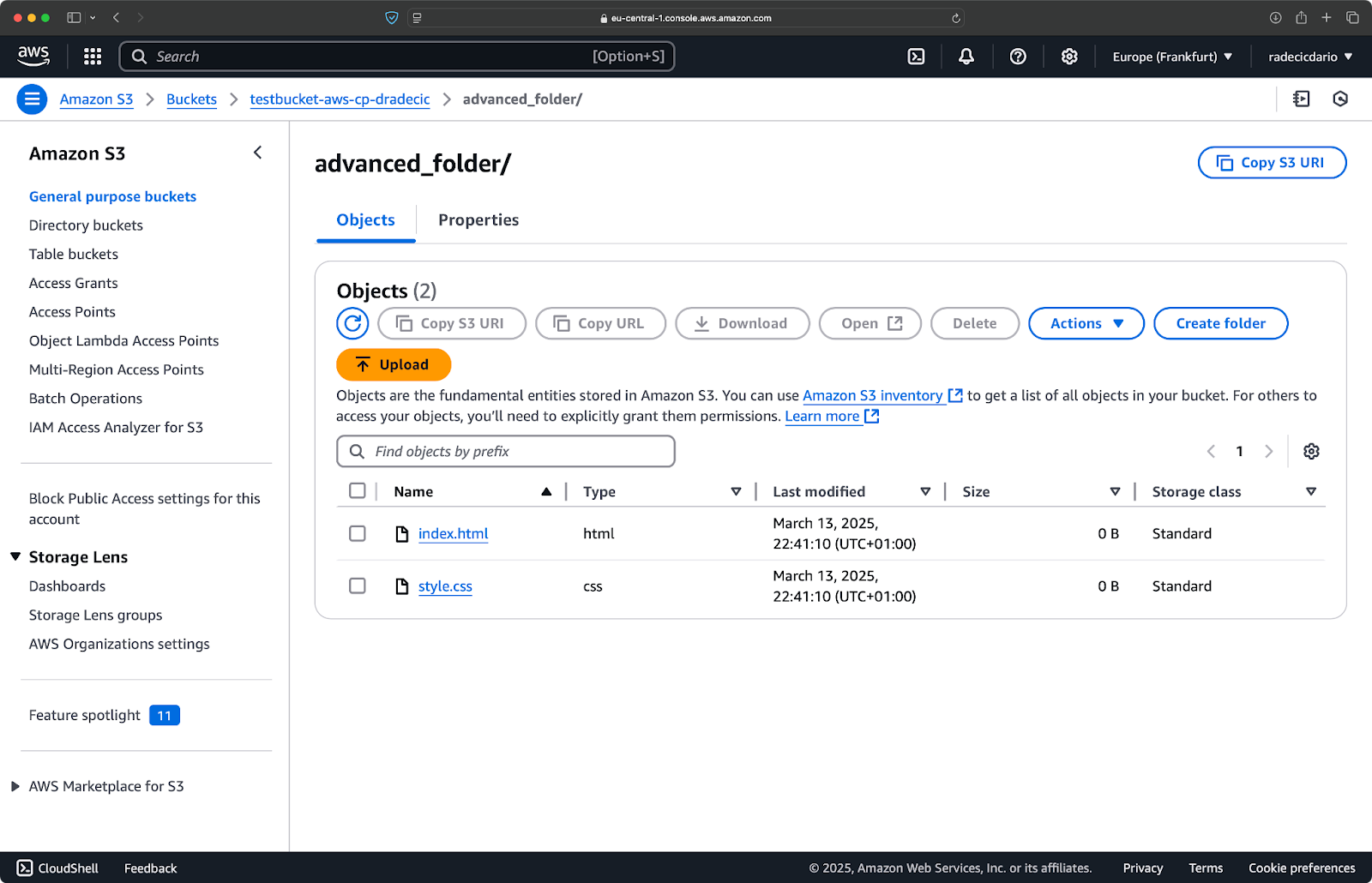
Abbildung 16 - Ergebnisse der Ordnungskopie (2)
Beachte, dass die Reihenfolge der Flags wichtig ist - AWS CLI verarbeitet diese Flags der Reihe nach. Wenn du also --include vor --exclude einträgst, erhältst du andere Ergebnisse:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --include "*.html" --include "*.css" --exclude "*"Dieses Mal wurde nichts in den Eimer kopiert:
Abbildung 17 - Ergebnisse beim Kopieren von Ordnern (3)
Amazon S3 bietet verschiedene Speicherklassen an, die jeweils unterschiedliche Kosten und Abrufeigenschaften haben. Standardmäßig lädt aws s3 cp Dateien in die Speicherklasse Standard hoch, aber du kannst mit dem Flag --storage-class eine andere Klasse angeben:
aws s3 cp /Users/dradecic/Desktop/large-archive.zip s3://testbucket-aws-cp-dradecic/archives/ --storage-class GLACIERMit diesem Befehl wird large-archive.zip in die Speicherklasse Glacier hochgeladen, die deutlich günstiger ist, aber höhere Abrufkosten und längere Abrufzeiten hat:
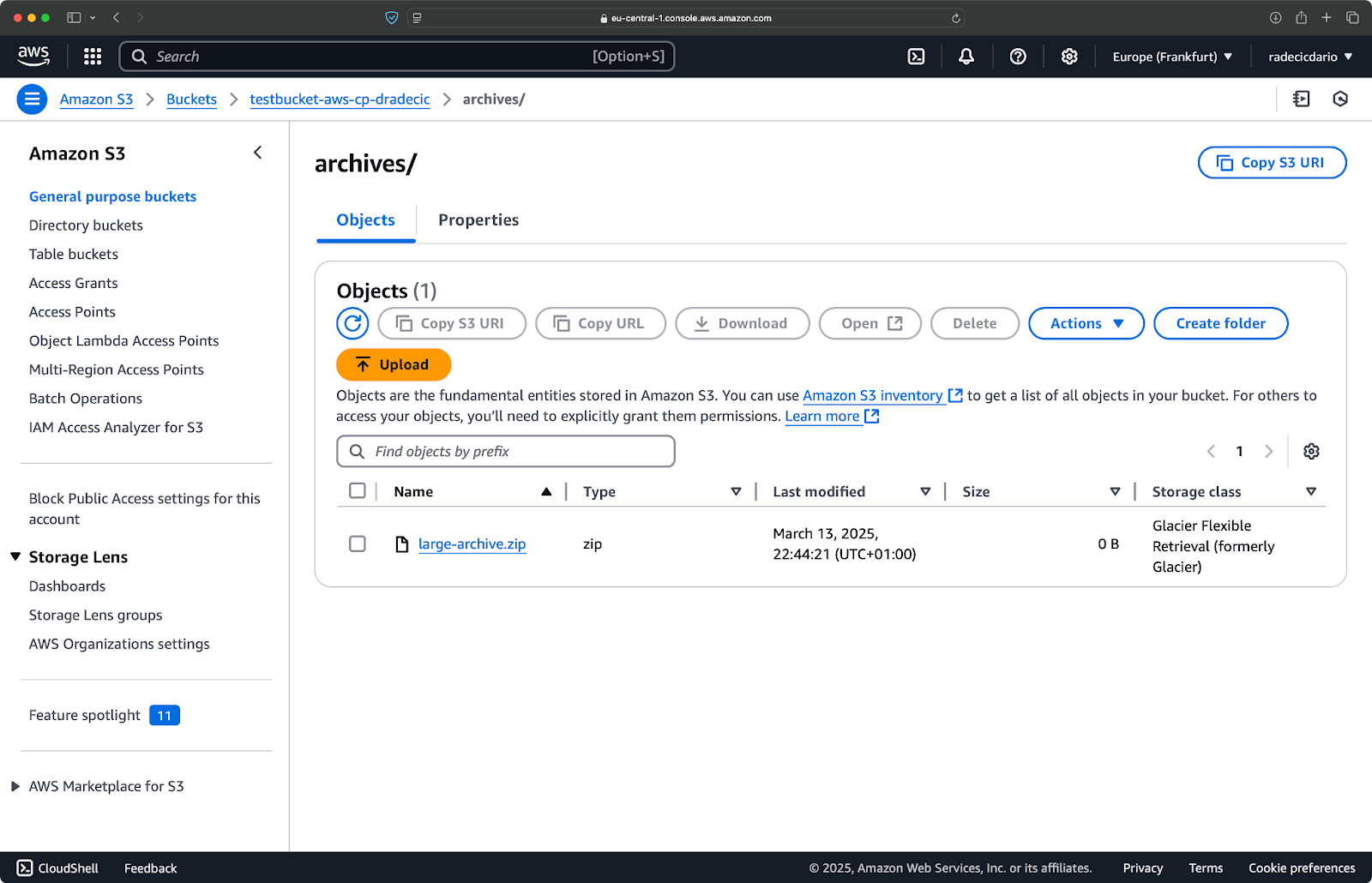
Abbildung 18 - Kopieren von Dateien in S3 mit verschiedenen Speicherklassen
Zu den verfügbaren Speicherklassen gehören:
STANDARD (Standard): Universell einsetzbarer Speicher mit hoher Haltbarkeit und Verfügbarkeit.REDUCED_REDUNDANCY (nicht mehr empfohlen): Geringere Haltbarkeit, kostensparende Option, jetzt veraltet.STANDARD_IA (Infrequent Access): Kostengünstigerer Speicher für Daten, auf die weniger häufig zugegriffen wird.ONEZONE_IA (Single Zone Infrequent Access): Kostengünstiger Speicher mit seltenem Zugriff in einer einzigen AWS Availability Zone.INTELLIGENT_TIERING: Verschiebt Daten auf der Grundlage von Zugriffsmustern automatisch zwischen den Speicherschichten.GLACIER: Kostengünstige Archivierung für langfristige Aufbewahrung, Abruf innerhalb von Minuten bis Stunden.DEEP_ARCHIVE: Günstigster Archivierungsspeicher, Abruf innerhalb von Stunden, ideal für die Langzeitsicherung.Wenn du Dateien sicherst, auf die du nicht sofort zugreifen musst, kannst du mit GLACIER oder DEEP_ARCHIVE erhebliche Speicherkosten sparen.
Wenn du Dateien in S3 aktualisierst, die bereits existieren, möchtest du vielleicht nur die Dateien kopieren, die sich geändert haben. Das --exact-timestamps Flag hilft dabei, indem es Zeitstempel zwischen Quelle und Ziel vergleicht.
Hier ist ein Beispiel:
aws s3 cp /Users/dradecic/Desktop/advanced_folder s3://testbucket-aws-cp-dradecic/advanced_folder/ --recursive --exact-timestampsMit diesem Flag kopiert der Befehl nur Dateien, deren Zeitstempel sich von den Dateien unterscheiden, die sich bereits in S3 befinden. Das kann die Übertragungszeit und die Bandbreitennutzung reduzieren, wenn du regelmäßig eine große Anzahl von Dateien aktualisierst.
Warum ist das also nützlich? Stell dir Verteilungsszenarien vor, in denen du deine Anwendungsdateien aktualisieren möchtest, ohne unnötigerweise unveränderte Assets zu übertragen.
Während --exact-timestamps nützlich ist, um eine Art von Synchronisation durchzuführen, solltest du, wenn du eine anspruchsvollere Lösung brauchst, aws s3 sync statt aws s3 cp verwenden. Der Befehl sync wurde speziell dafür entwickelt, Verzeichnisse synchron zu halten und verfügt über zusätzliche Funktionen für diesen Zweck. Ich habe alles über den Sync-Befehl im AWS S3 Sync-Tutorial geschrieben.
Mit diesen erweiterten Optionen hast du jetzt eine viel feinere Kontrolle über deine S3-Dateivorgänge. Du kannst bestimmte Dateien anvisieren, die Speicherkosten optimieren und deine Dateien effizient aktualisieren. Im nächsten Abschnitt erfährst du, wie du diese Vorgänge mithilfe von Skripten und geplanten Aufgaben automatisieren kannst.
Bis jetzt hast du gelernt, wie du Dateien manuell über die Kommandozeile in und aus S3 kopierst. Einer der größten Vorteile von aws s3 cp ist, dass du diese Überweisungen ganz einfach automatisieren kannst, was dir eine Menge Zeit spart.
Im Folgenden erfahren wir, wie du den Befehl aws s3 cp in Skripte und geplante Aufträge integrieren kannst, um Dateien ohne großen Aufwand zu übertragen.
Hier ist ein einfaches Beispiel für ein Bash-Skript, das ein Verzeichnis in S3 sichert, dem Backup einen Zeitstempel hinzufügt und die Fehlerbehandlung und Protokollierung in einer Datei implementiert:
#!/bin/bash
# Set variables
SOURCE_DIR="/Users/dradecic/Desktop/advanced_folder"
BUCKET="s3://testbucket-aws-cp-dradecic/backups"
DATE=$(date +%Y-%m-%d-%H-%M)
BACKUP_NAME="backup-$DATE"
LOG_FILE="/Users/dradecic/logs/s3-backup-$DATE.log"
# Ensure the logs directory exists
mkdir -p "$(dirname "$LOG_FILE")"
# Create the backup and log the output
echo "Starting backup of $SOURCE_DIR to $BUCKET/$BACKUP_NAME" | tee -a $LOG_FILE
aws s3 cp $SOURCE_DIR $BUCKET/$BACKUP_NAME --recursive 2>&1 | tee -a $LOG_FILE
# Check if the backup was successful
if [ $? -eq 0 ]; then
echo "Backup completed successfully on $DATE" | tee -a $LOG_FILE
else
echo "Backup failed on $DATE" | tee -a $LOG_FILE
fiSpeichere es unter backup.sh, mach es mit chmod +x backup.sh ausführbar und schon hast du ein wiederverwendbares Backup-Skript!
Du kannst es dann mit dem folgenden Befehl ausführen:
./backup.sh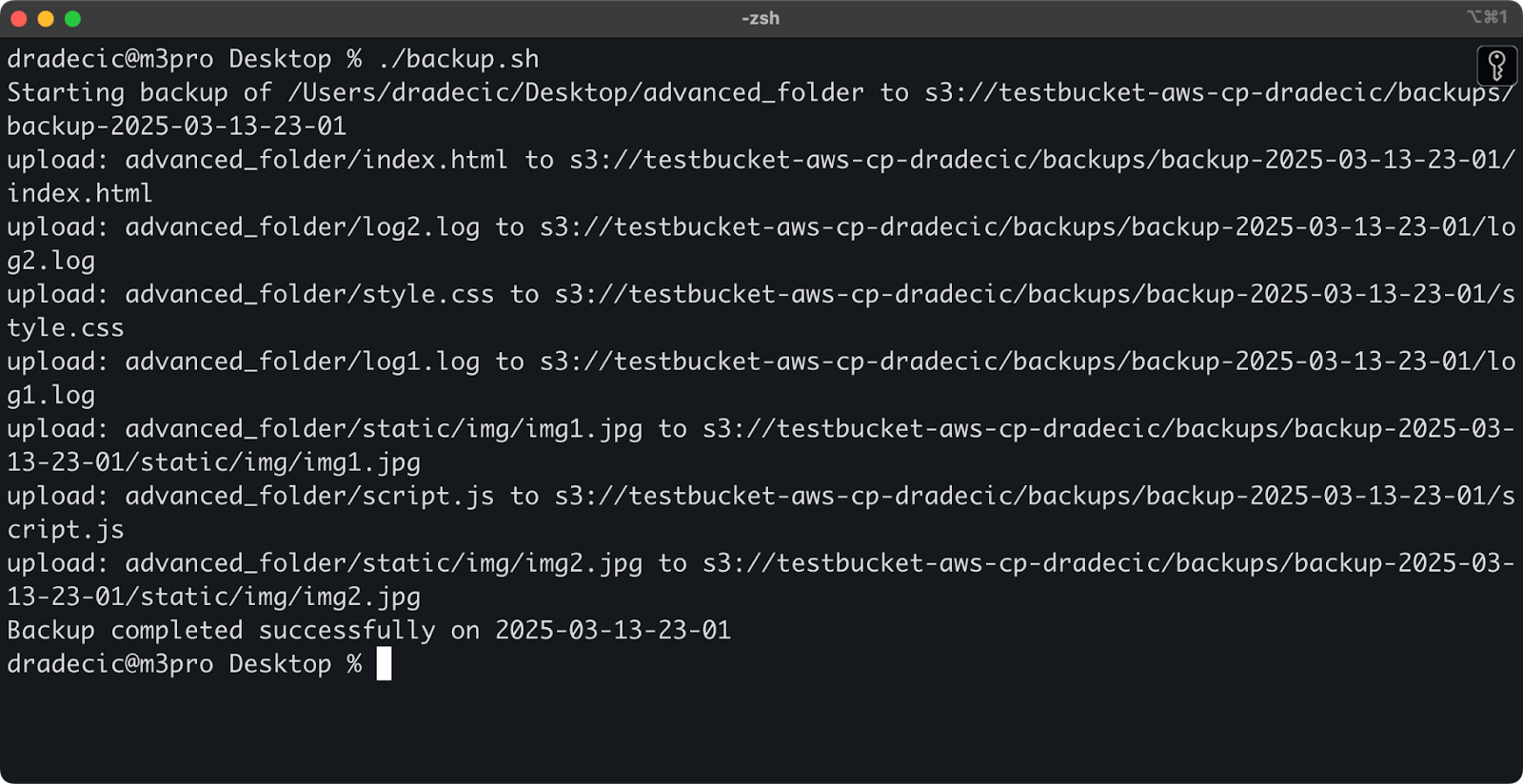
Abbildung 19 - Skript läuft im Terminal
Unmittelbar danach wird der Ordner backups auf dem Bucket gefüllt:
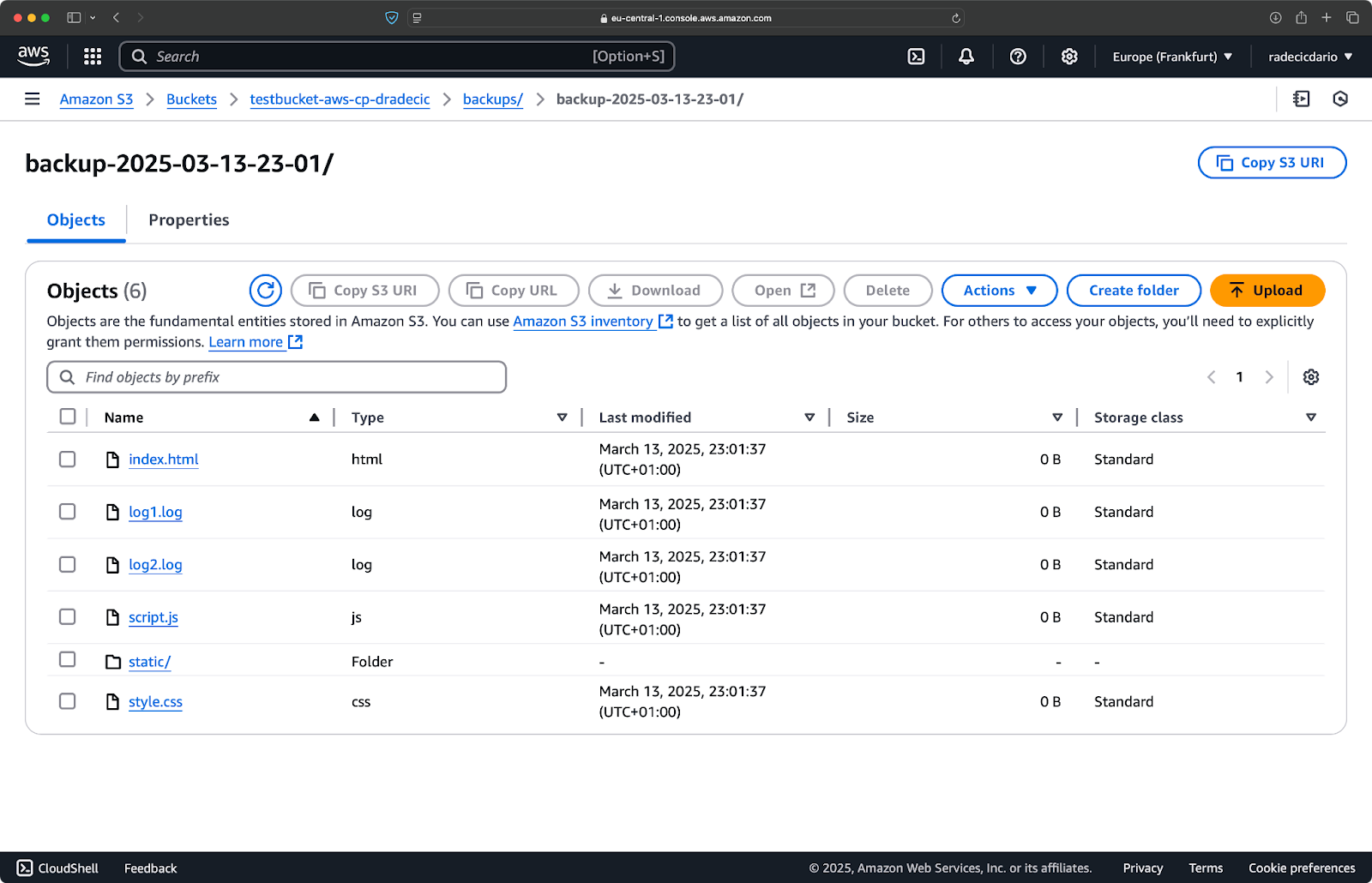
Abbildung 20 - Backup im S3-Bucket gespeichert
Wir gehen noch einen Schritt weiter und lassen das Skript nach einem Zeitplan laufen.
Nachdem du nun ein Skript erstellt hast, musst du es zu bestimmten Zeiten automatisch ausführen lassen.
Wenn du mit Linux oder macOS arbeitest, kannst du cron verwenden, um deine Backups zu planen. Hier erfährst du, wie du einen Cronjob einrichtest, der dein Backup-Skript jeden Tag um Mitternacht ausführt:
1. Öffne deine crontab zur Bearbeitung:
crontab -e2. Füge die folgende Zeile hinzu, um dein Skript täglich um Mitternacht auszuführen:
0 0 * * * /path/to/your/backup.sh
Abbildung 21 - Cron-Job für die tägliche Ausführung des Skripts
Das Format für Cron-Jobs ist minute hour day-of-month month day-of-week command. Hier sind ein paar weitere Beispiele:
0 * * * * /path/to/your/backup.sh0 9 * * 1 /path/to/your/backup.sh0 0 1 * * /path/to/your/backup.shUnd das war's! Das Skript backup.sh wird nun in dem geplanten Intervall ausgeführt.
Die Automatisierung deiner S3-Dateiübertragungen ist ein guter Weg. Es ist besonders nützlich für Szenarien wie:
Automatisierungstechniken wie diese helfen dir, ein zuverlässiges System einzurichten, das Dateiübertragungen ohne manuelle Eingriffe abwickelt. Du musst es nur einmal schreiben und dann kannst du es vergessen.
Im nächsten Abschnitt gehe ich auf einige Best Practices ein, die deinen aws s3 cp Betrieb sicherer und effizienter machen.
Der Befehl aws s3 cp ist zwar einfach zu bedienen, aber es kann auch etwas schiefgehen.
Wenn du die Best Practices befolgst, vermeidest du häufige Fallstricke, optimierst die Leistung und sorgst für die Sicherheit deiner Daten. Lass uns diese Praktiken erkunden, um deine Dateiübertragungsvorgänge effizienter zu machen.
Wenn du mit S3 arbeitest, sparst du Zeit und Kopfschmerzen, wenn du deine Dateien logisch organisierst.
Legezunächst eine einheitliche Namenskonvention für Eimer und Präfixe fest:. Du kannst deine Daten zum Beispiel nach Umgebung, Anwendung oder Datum trennen:
s3://company-backups/production/database/2023-03-13/
s3://company-backups/staging/uploads/2023-03/Diese Art der Organisation macht es einfacher,..:
Noch ein Tipp: Wenn du große Mengen an Dateien übermittelst, solltest du kleine Dateien vor dem Hochladen in Gruppen zusammenfassen (mit zip oder tar). Dadurch wird die Anzahl der API-Aufrufe an S3 reduziert, was die Kosten senken und die Übertragung beschleunigen kann.
# Instead of copying thousands of small log files
# tar them first, then upload
tar -czf example-logs-2025-03.tar.gz /var/log/application/
aws s3 cp example-logs-2025-03.tar.gz s3://testbucket-aws-cp-dradecic/logs/2025/03/Wenn du große Dateien oder viele Dateien auf einmal kopierst, gibt es ein paar Techniken, die den Prozess zuverlässiger und effizienter machen.
Du kannst das --quiet Flag verwenden, um Ausgabe zu reduzieren bei der Ausführung in Skripten:
aws s3 cp large-directory/ s3://testbucket-aws-cp-dradecic/backups/ --recursive --quietDadurch werden die Fortschrittsinformationen für jede Datei unterdrückt, was die Logs übersichtlicher macht. Außerdem wird dadurch die Leistung leicht verbessert.
Für sehr große Dateien solltest du die Verwendung von mehrteilige Uploads mit dem --multipart-threshold Flag:
aws s3 cp huge-file.iso s3://testbucket-aws-cp-dradecic/backups/ --multipart-threshold 100MBMit der obigen Einstellung wird AWS CLI angewiesen, Dateien, die größer als 100 MB sind, für den Upload in mehrere Teileaufzuteilen. Das hat einige Vorteile:
Wenn Übertragung von Daten zwischen Regionenerwäge, S3 Transfer Acceleration für schnellere Uploads zu nutzen:
aws s3 cp large-file.zip s3://testbucket-aws-cp-dradecic/backups/ --endpoint-url https://s3-accelerate.amazonaws.comDie oben beschriebene Methode leitet deinen Transfer durch das Amazon-Edge-Netzwerk, was regionsübergreifende Transfers erheblich beschleunigen kann.
Bei der Arbeit mit deinen Daten in der Cloud sollte die Sicherheit immer an erster Stelle stehen.
Stelle zunächst sicher, dass deine IAM-Berechtigungen dem Prinzip der geringsten Berechtigung folgen. Gewähre nur die spezifischen Berechtigungen, die für jede Aufgabe benötigt werden.
Hier ist ein Beispiel für eine Richtlinie, die du dem Benutzer zuweisen kannst:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject"
],
"Resource": "arn:aws:s3:::testbucket-aws-cp-dradecic/backups/*"
}
]
}Diese Richtlinie erlaubt nur das Kopieren von Dateien in und aus dem Präfix "backups" in "my-bucket".
Eine weitere Möglichkeit, die Sicherheit zu erhöhen, ist die Aktivierung der Verschlüsselung für sensible Daten. Du kannst beim Hochladen eine serverseitige Verschlüsselung angeben:
aws s3 cp confidential.docx s3://testbucket-aws-cp-dradecic/ --sse AES256Für mehr Sicherheit kannst du auch den AWS Key Management Service (KMS) verwenden:
aws s3 cp secret-data.json s3://testbucket-aws-cp-dradecic/ --sse aws:kms --sse-kms-key-id myKMSKeyIdFür hochsensible Vorgänge solltest du jedoch die Verwendung von VPC-Endpunkten für S3 in Betracht ziehen . Dadurch bleibt dein Datenverkehr innerhalb des AWS-Netzwerks und vermeidet das öffentliche Internet vollständig.
Im nächsten Abschnitt erfährst du, wie du häufige Probleme, die bei der Arbeit mit diesem Befehl auftreten können, beheben kannst.
Eines ist sicher - bei der Arbeit mit aws s3 cp wirst du gelegentlich auf Probleme stoßen. Aber wenn du die häufigsten Fehler und ihre Lösungen kennst, sparst du dir Zeit und Frustration, wenn die Dinge nicht so laufen wie geplant.
In diesem Abschnitt zeige ich dir die häufigsten Probleme und wie du sie beheben kannst.
Das ist wahrscheinlich der häufigste Fehler, dem du begegnen wirst:
upload failed: ./myfile.txt to s3://testbucket-aws-cp-dradecic/myfile.txt An error occurred (AccessDenied) when calling the PutObject operation: Access DeniedDas bedeutet normalerweise eines von drei Dingen:
So behebst du Probleme:
s3:PutObject (für Uploads) oder s3:GetObject (für Downloads) Berechtigungen hast.aws configure aus, um deine Anmeldedaten zu aktualisieren, wenn sie abgelaufen sind.Dieser Fehler tritt auf, wenn die lokale Datei oder das Verzeichnis, das du zu kopieren versuchst, nicht existiert:
upload failed: ./missing-file.txt to s3://testbucket-aws-cp-dradecic/missing-file.txt An error occurred (404) when calling the PutObject operation: Not FoundDie Lösung ist einfach - überprüfe deine Dateipfade sorgfältig. Bei Pfaden wird zwischen Groß- und Kleinschreibung unterschieden, behalte das also im Hinterkopf. Achte außerdem darauf, dass du dich im richtigen Verzeichnis befindest, wenn du relative Pfade verwendest.
Wenn du diesen Fehler siehst:
upload failed: ./myfile.txt to s3://testbucket-aws-cp-dradecic/myfile.txt An error occurred (NoSuchBucket) when calling the PutObject operation: The specified bucket does not existPrüfe auf:
Du kannst alle deine Buckets mit aws s3 ls auflisten, um den richtigen Namen zu bestätigen.
Netzwerkprobleme können Timeouts bei der Verbindung verursachen:
upload failed: ./largefile.zip to s3://testbucket-aws-cp-dradecic/largefile.zip An error occurred (RequestTimeout) when calling the PutObject operation: Request timeoutUm dies zu lösen:
Bei der Übertragung großer Dateien ist die Wahrscheinlichkeit von Fehlern viel größer. Wenn das der Fall ist, versuche, Misserfolge anständig zu behandeln.
Du kannst zum Beispiel das --only-show-errors Flag verwenden, um die Fehlerdiagnose in Skripten zu erleichtern:
aws s3 cp large-directory/ s3://testbucket-aws-cp-dradecic/ --recursive --only-show-errorsDadurch werden Meldungen über erfolgreiche Übertragungen unterdrückt und nur Fehler angezeigt, was die Fehlersuche bei großen Übertragungen erheblich erleichtert.
Um unterbrochene Übertragungen zu behandeln, überspringt der Befehl --recursive automatisch Dateien, die im Ziel bereits mit derselben Größe vorhanden sind. Um gründlicher zu sein, kannst du jedoch die in der AWS CLI integrierten Wiederholungsversuche für Netzwerkproblemeverwenden, indem du diese Umgebungsvariablen setzt:
export AWS_RETRY_MODE=standard
export AWS_MAX_ATTEMPTS=5
aws s3 cp large-file.zip s3://testbucket-aws-cp-dradecic/Damit wird die AWS CLI angewiesen, fehlgeschlagene Operationen bis zu 5 Mal automatisch zu wiederholen.
Für sehr große Datenmengen solltest du jedoch aws s3 sync statt cp verwenden, da es besser mit Unterbrechungen umgehen kann:
aws s3 sync large-directory/ s3://testbucket-aws-cp-dradecic/large-directory/Der Befehl sync überträgt nur Dateien, die sich von denen unterscheiden, die sich bereits im Ziel befinden, und eignet sich daher perfekt für die Wiederaufnahme unterbrochener großer Übertragungen.
Wenn du diese häufigen Fehler verstehst und eine angemessene Fehlerbehandlung in deinen Skripten implementierst, werden deine S3-Kopiervorgänge viel robuster und zuverlässiger.
Zusammenfassend lässt sich sagen, dass der Befehl aws s3 cp eine zentrale Anlaufstelle für das Kopieren von lokalen Dateien nach S3 und umgekehrt ist.
In diesem Artikel erfährst du alles darüber. Du hast mit den Grundlagen und der Umgebungskonfiguration begonnen und schließlich geplante und automatisierte Skripte zum Kopieren von Dateien geschrieben. Du hast auch gelernt, wie du einige häufige Fehler und Herausforderungen beim Verschieben von Dateien, insbesondere von großen Dateien, meistern kannst.
Wenn du also ein Entwickler, ein Datenexperte oder ein Systemadministrator bist, wirst du diesen Befehl sicher nützlich finden. Am besten gewöhnst du dich daran, indem du es regelmäßig benutzt. Vergewissere dich, dass du die Grundlagen verstehst, und verbringe dann einige Zeit damit, lästige Teile deiner Arbeit zu automatisieren.
Um mehr über AWS zu erfahren, besuche diese Kurse von DataCamp:
Du kannst dich mit DataCamp sogar auf die AWS-Zertifizierungsprüfungen vorbereiten - AWS Cloud Practitioner (CLF-C02).
Lerne mehr über AWS mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
