Cours
Introduction à R
4 h
3M
Les réseaux neuronaux ou réseaux neuronaux simulés sont un sous-ensemble de l'apprentissage automatique qui s'inspire du cerveau humain. Ils imitent la façon dont les neurones biologiques communiquent entre eux pour prendre une décision.
Un réseau neuronal se compose d'une couche d'entrée, d'une couche cachée et d'une couche de sortie. La première couche reçoit des données brutes, elles sont traitées par plusieurs couches cachées et la dernière couche produit le résultat.
Dans l'exemple ci-dessous, nous avons simulé le processus d'apprentissage des réseaux neuronaux pour classer des données tabulaires. Nous avons les paramètres X1 et X2 qui passent par 2 couches cachées de 4 et 2 neurones pour produire la sortie. Au fil des itérations, le modèle parvient à mieux classer les cibles.
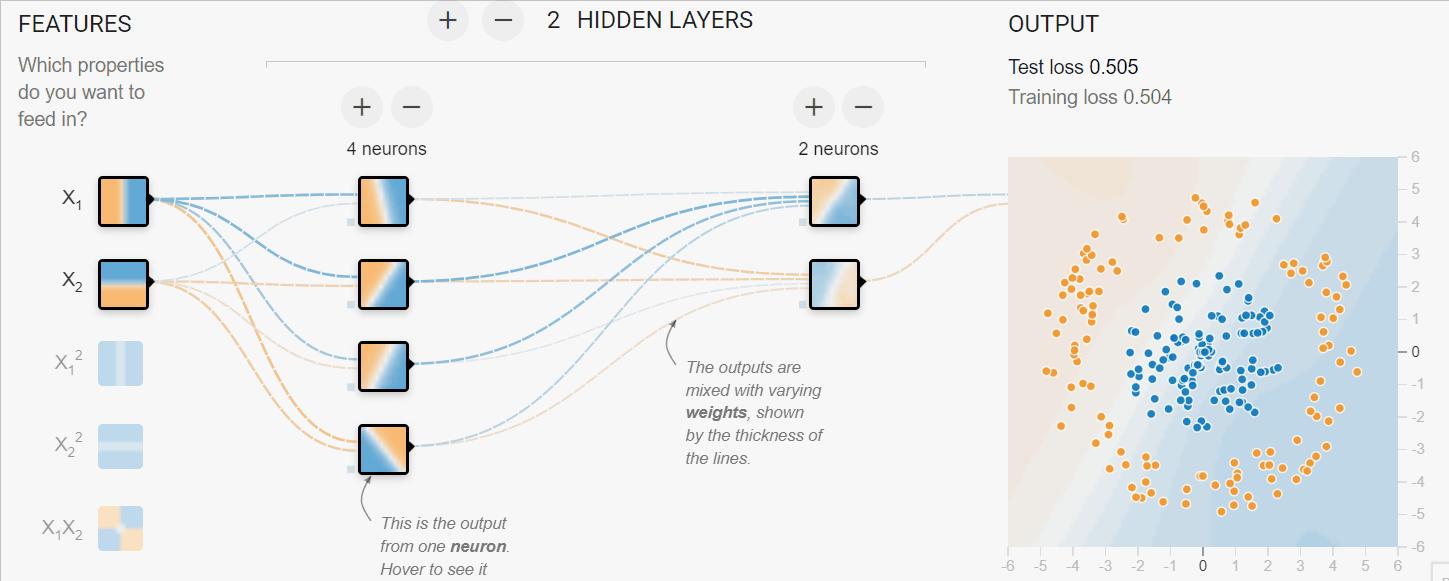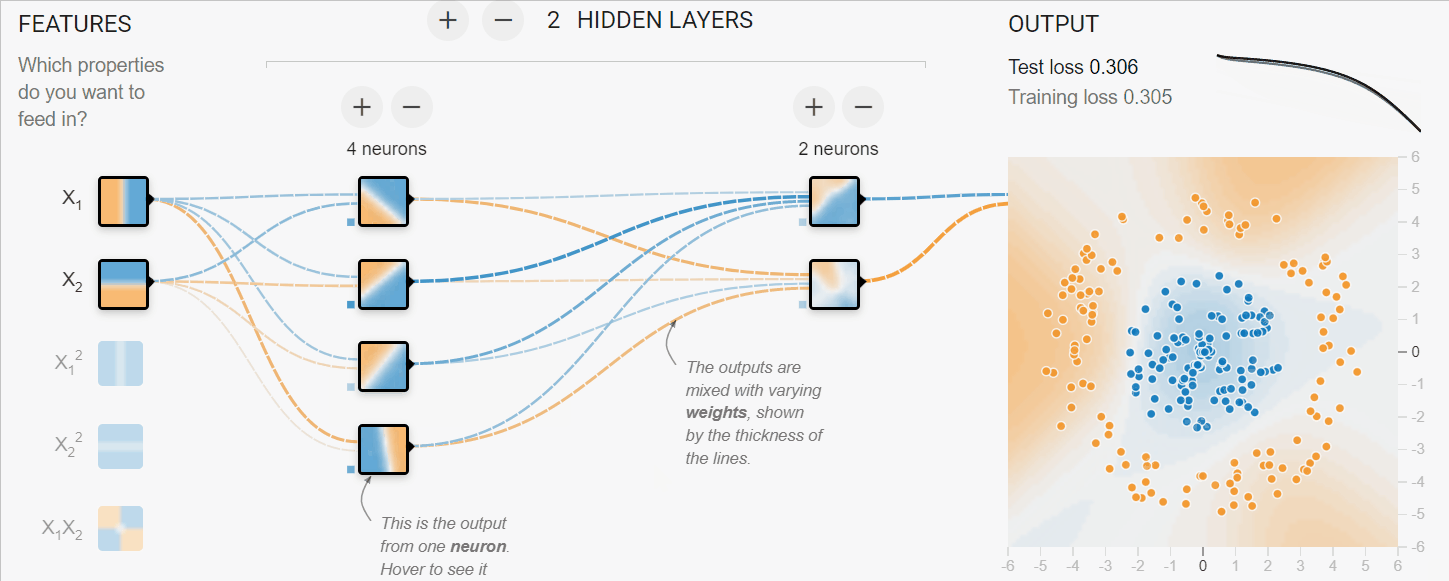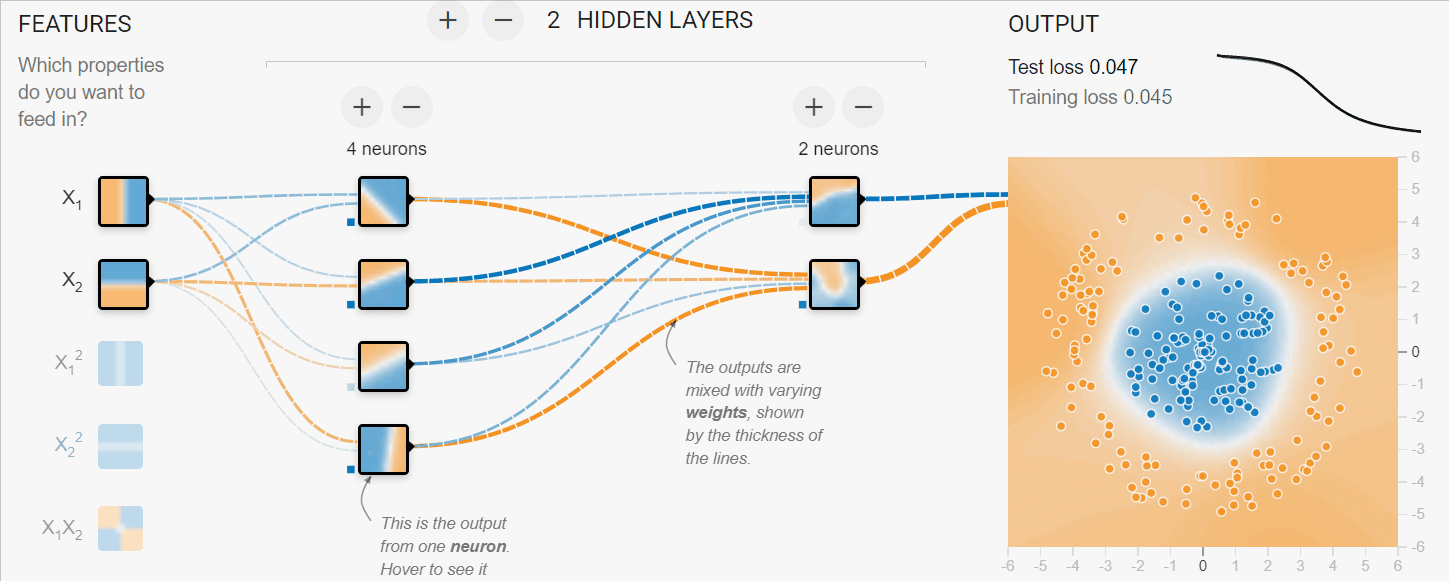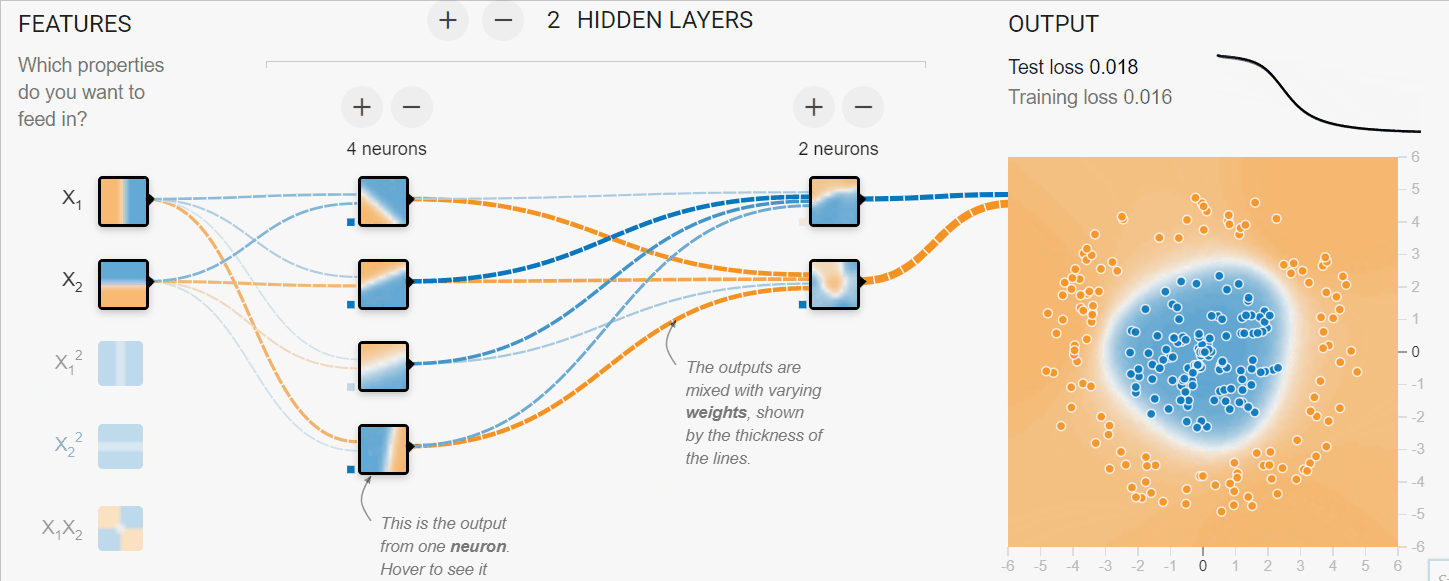
Image créée avec TF Playground
Les algorithmes d'apprentissage profond ou les réseaux neuronaux profonds se composent de plusieurs couches et nœuds cachés. Le terme "deep" désigne la profondeur des réseaux neuronaux. Ils sont généralement utilisés pour résoudre des problèmes complexes tels que la classification d'images, la reconnaissance vocale et la génération de textes.
Pour en savoir plus sur les réseaux neuronaux, consultez notre didacticiel sur l'apprentissage profond. Vous apprendrez comment la fonction d'activation, la fonction de perte et la rétropropagation fonctionnent pour produire des résultats précis.
Plusieurs types de réseaux neuronaux sont utilisés pour des applications avancées d'apprentissage automatique. Nous ne disposons pas d'un modèle d'architecture unique qui convienne à tous. Le plus ancien type de réseau neuronal est connu sous le nom de Perceptron, créé par Frank Rosenblatt en 1958.
Dans cette section, nous aborderons les cinq types de réseaux neuronaux les plus utilisés dans l'industrie technologique.
Les réseaux neuronaux feedforward se composent d'une couche d'entrée, de couches cachées et d'une couche de sortie. Il est appelé "feedforward" parce que les données circulent dans le sens de la marche et qu'il n'y a pas de rétropropagation. Il est principalement utilisé dans les domaines de la classification, de la reconnaissance vocale, de la reconnaissance des visages et de la reconnaissance des formes.
Les perceptrons multicouches (MLP) permettent de résoudre les problèmes du réseau neuronal feedforward, à savoir l'impossibilité d'apprendre par rétropropagation. Il est bidirectionnel et se compose de plusieurs couches cachées et de fonctions d'activation. Les MLP utilisent la propagation vers l'avant pour les entrées et la rétropropagation pour la mise à jour des poids. Il s'agit de réseaux neuronaux de base qui ont jeté les bases de la vision par ordinateur, de la technologie du langage et d'autres réseaux neuronaux.
Note: Les MLP sont constitués de neurones sigmoïdes, et non de perceptrons, car les problèmes du monde réel ne sont pas des lignes.
Les réseaux neuronaux à convolution (CNN) sont généralement utilisés dans les domaines de la vision artificielle, de la reconnaissance d'images et de la reconnaissance de formes. Il est utilisé pour extraire les caractéristiques importantes de l'image à l'aide de plusieurs couches convolutives. La couche convolutive du CNN utilise une matrice personnalisée (filtre) pour convoluer sur les images et créer une carte.
En règle générale, les réseaux neuronaux à convolution se composent d'une couche d'entrée, d'une couche de convolution, d'une couche de mise en commun, d'une couche entièrement connectée et d'une couche de sortie. Lisez notre tutoriel sur les réseaux neuronaux convolutifs (CNN) en Python avec TensorFlow pour en savoir plus sur le fonctionnement des CNN.
Les réseaux neuronaux récurrents (RNN) sont couramment utilisés pour les données séquentielles telles que les textes, les séquences d'images et les séries temporelles. Ils sont similaires aux réseaux de type "feed-forward", sauf qu'ils obtiennent des entrées à partir de séquences précédentes à l'aide d'une boucle de rétroaction. Les RNN sont utilisés dans la PNL, les prévisions de vente et les prévisions météorologiques.
Les RNN sont confrontés à des problèmes de gradient de disparition, qui sont résolus par des versions avancées des RNN appelées réseaux de mémoire à court terme (LSTM) et réseaux d'unités récurrentes gérées (GRU). Lisez le didacticiel sur les réseaux neuronaux récurrents (RNN) pour en savoir plus sur les LSTM et les GRU.
Nous apprendrons à créer des réseaux neuronaux à l'aide des packages R populaires neuralnet et Keras.
Dans le premier exemple, nous créerons un réseau neuronal simple avec un minimum d'efforts, et dans le second, nous nous attaquerons à un problème plus avancé à l'aide du paquet Keras.
Configurons l'environnement R en téléchargeant les bibliothèques et dépendances essentielles.
install.packages(c('neuralnet','keras','tensorflow'),dependencies = T)Dans ce premier exemple, nous utiliserons les données R intégrées iris et nous résoudrons des problèmes de multi-classification à l'aide d'un simple réseau neuronal.
Nous commencerons par importer les paquets R essentiels à la manipulation des données et à l'apprentissage des modèles.
library(tidyverse)
library(neuralnet)Vous pouvez accéder aux données en tapant `iris` et en l'exécutant dans la console R. Avant d'entraîner les données, nous devons convertir les types de colonnes de caractères en facteurs.
Remarque: nous utilisons l'espace de travail R de DataCamp pour exécuter les exemples.
iris <- iris %>% mutate_if(is.character, as.factor)La fonction `summary` est utilisée pour l'analyse statistique et la distribution des données.
summary(iris)Comme nous pouvons le constater, nous disposons de données équilibrées. Les trois classes cibles comptent 50 échantillons.
Sepal.Length Sepal.Width Petal.Length Petal.Width
Min. :4.300 Min. :2.000 Min. :1.000 Min. :0.100
1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300
Median :5.800 Median :3.000 Median :4.350 Median :1.300
Mean :5.843 Mean :3.057 Mean :3.758 Mean :1.199
3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 3rd Qu.:1.800
Max. :7.900 Max. :4.400 Max. :6.900 Max. :2.500
Species
setosa :50
versicolor:50
virginica :50 Nous fixerons des semences pour la reproductibilité et diviserons les données en ensembles de données de formation et de test pour la formation et l'évaluation des modèles. Nous allons le diviser en 80:20.
set.seed(245)
data_rows <- floor(0.80 * nrow(iris))
train_indices <- sample(c(1:nrow(iris)), data_rows)
train_data <- iris[train_indices,]
test_data <- iris[-train_indices,]Le package neuralnet est obsolète, mais il est toujours populaire au sein de la communauté R.
La fonction `neuralnet` est simple. Il ne nous donne pas la liberté de créer des modèles d'architecture entièrement personnalisables.
Dans notre cas, nous lui fournissons une formule d'apprentissage automatique et des données, tout comme le GLM. La formule se compose de variables cibles et de caractéristiques.
Ensuite, nous créons deux couches cachées, la première couche avec quatre neurones et la seconde avec deux neurones.
model = neuralnet(
Species~Sepal.Length+Sepal.Width+Petal.Length+Petal.Width,
data=train_data,
hidden=c(4,2),
linear.output = FALSE
)Pour visualiser l'architecture de notre modèle, nous utiliserons la fonction `plot`. Elle nécessite un objet modèle et l'argument `rep`.
plot(model,rep = "best")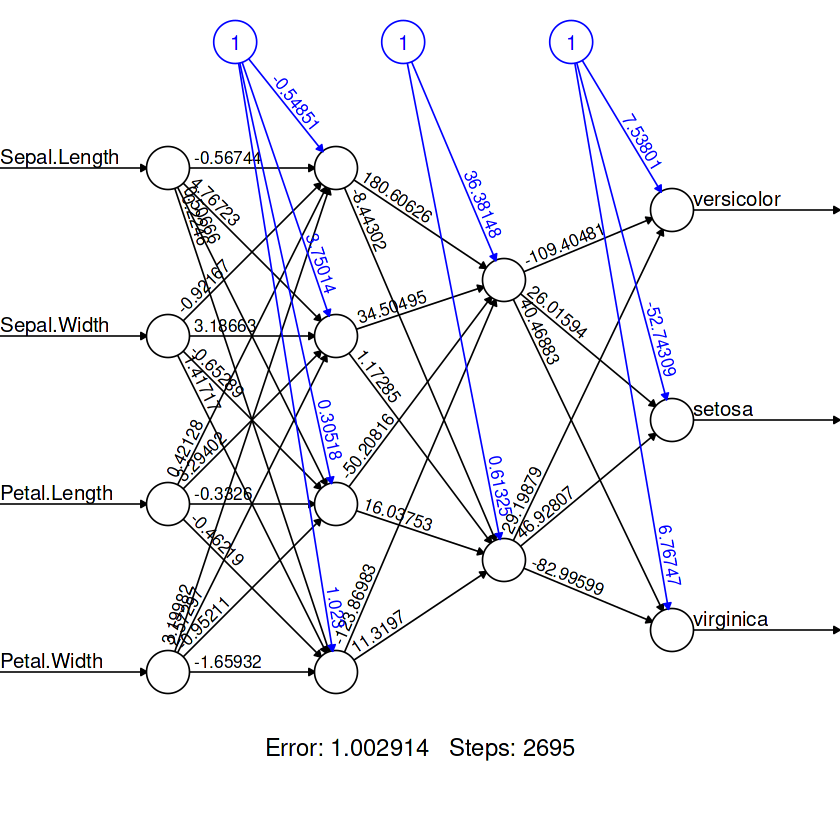
Pour la matrice de confusion :
pred <- predict(model, test_data)
labels <- c("setosa", "versicolor", "virginca")
prediction_label <- data.frame(max.col(pred)) %>%
mutate(pred=labels[max.col.pred.]) %>%
select(2) %>%
unlist()
table(test_data$Species, prediction_label)Nous avons obtenu des résultats presque parfaits. Il semble que notre modèle ait prédit à tort trois échantillons. Nous pouvons améliorer le résultat en ajoutant plus de neurones dans chaque couche.
prediction_label
setosa versicolor virginica
setosa 8 0 0
versicolor 0 13 0
virginica 0 3 6 Pour vérifier la précision, nous devons d'abord convertir les valeurs catégorielles réelles en valeurs numériques et les comparer aux valeurs prédites. En conséquence, nous recevrons une liste de valeurs booléennes.
Nous pouvons utiliser la fonction `sum` pour trouver le nombre de valeurs `VRAIES` et le diviser par le nombre total d'échantillons pour obtenir la précision.
check = as.numeric(test_data$Species) == max.col(pred)
accuracy = (sum(check)/nrow(test_data))*100
print(accuracy)Le modèle a prédit des valeurs avec une précision de 90 %.
90Remarque: le code source de cet exemple est disponible sur l'espace de travail R : Construire des modèles de réseaux neuronaux (NN) en R.
Dans cet exemple, nous utiliserons Keras et TensorFlow pour construire et entraîner un modèle de réseau neuronal convolutif pour la tâche de classification d'images. Pour ce faire, nous utiliserons l'ensemble de données d'images cifar10 composé de 60 000 images couleur 32x32 étiquetées sur dix catégories.

Image de CIFAR-10
Importez les paquets R essentiels.
library(keras)
library(tensorflow)Nous importerons l'ensemble de données intégré de Keras et le diviserons en ensembles de formation et de test.
c(c(x_train, y_train), c(x_test, y_test)) %<-% dataset_cifar10()Divisez les caractéristiques de formation et de test par 255 pour normaliser les données.
x_train <- x_train / 255
x_test <- x_test / 255L'API Keras nous offre la flexibilité nécessaire pour construire une architecture de réseau neuronal complexe entièrement personnalisable.
Dans notre cas, nous créerons plusieurs couches de convolution, suivies de la couche de mise en commun maximale, de la couche d'élimination, de la couche dense et de la couche de sortie.
Nous utilisons "Leaky ReLU" comme fonction d'activation pour toutes les couches, à l'exception de la couche de sortie. Pour ce faire, nous utilisons la méthode "softmax".
Nous devons définir la forme d'entrée de la première couche convolutive 2D sur la forme de l'image (32,32,3) de l'ensemble de données d'apprentissage.
model <- keras_model_sequential()%>%
# Start with a hidden 2D convolutional layer
layer_conv_2d(
filter = 16, kernel_size = c(3,3), padding = "same",
input_shape = c(32, 32, 3), activation = 'leaky_relu'
) %>%
# 2nd hidden layer
layer_conv_2d(filter = 32, kernel_size = c(3,3), activation = 'leaky_relu') %>%
# Use max pooling
layer_max_pooling_2d(pool_size = c(2,2)) %>%
layer_dropout(0.25) %>%
# 3rd and 4th hidden 2D convolutional layers
layer_conv_2d(filter = 32, kernel_size = c(3,3), padding = "same", activation = 'leaky_relu') %>%
layer_conv_2d(filter = 64, kernel_size = c(3,3), activation = 'leaky_relu') %>%
# Use max pooling
layer_max_pooling_2d(pool_size = c(2,2)) %>%
layer_dropout(0.25) %>%
# Flatten max filtered output into feature vector
# and feed into dense layer
layer_flatten() %>%
layer_dense(256, activation = 'leaky_relu') %>%
layer_dropout(0.5) %>%
# Outputs from dense layer
layer_dense(10, activation = 'softmax')Pour visualiser l'architecture du modèle, nous utiliserons la fonction `summary`.
summary(model)Nous disposons de deux couches convolutives suivies d'une couche de mise en commun maximale, de deux autres couches convolutives, d'une couche de mise en commun maximale, d'une couche aplatie pour filtrer au maximum la sortie en vecteurs, puis de deux couches denses.
Model: "sequential"
________________________________________________________________________________
Layer (type) Output Shape Param #
================================================================================
conv2d_3 (Conv2D) (None, 32, 32, 16) 448
________________________________________________________________________________
conv2d_2 (Conv2D) (None, 30, 30, 32) 4640
________________________________________________________________________________
max_pooling2d_1 (MaxPooling2D) (None, 15, 15, 32) 0
________________________________________________________________________________
dropout_2 (Dropout) (None, 15, 15, 32) 0
________________________________________________________________________________
conv2d_1 (Conv2D) (None, 15, 15, 32) 9248
________________________________________________________________________________
conv2d (Conv2D) (None, 13, 13, 64) 18496
________________________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 6, 6, 64) 0
________________________________________________________________________________
dropout_1 (Dropout) (None, 6, 6, 64) 0
________________________________________________________________________________
flatten (Flatten) (None, 2304) 0
________________________________________________________________________________
dense_1 (Dense) (None, 256) 590080
________________________________________________________________________________
dropout (Dropout) (None, 256) 0
________________________________________________________________________________
dense (Dense) (None, 10) 2570
================================================================================
Total params: 625,482
Trainable params: 625,482
Non-trainable params: 0
________________________________________________________________________________learning_rate <- learning_rate_schedule_exponential_decay(
initial_learning_rate = 5e-3,
decay_rate = 0.96,
decay_steps = 1500,
staircase = TRUE
)
opt <- optimizer_adamax(learning_rate = learning_rate)
loss <- loss_sparse_categorical_crossentropy(from_logits = TRUE)
model %>% compile(
loss = loss,
optimizer = opt,
metrics = "accuracy"
)Nous allons ajuster notre modèle et stocker la métrique d'évaluation dans `history`.
history <- model %>% fit(
x_train, y_train,
batch_size = 32,
epochs = 10,
validation_data = list(x_test, y_test),
shuffle = TRUE
)Vous pouvez évaluer le modèle sur un ensemble de données de test en utilisant la fonction `evaluate`, qui renverra la perte finale et la précision.
model %>% evaluate(x_test, y_test)Le recyclage du modèle sur 50 époques améliorera la précision du modèle.
Loss 0.648191571235657 Accuracy 0.776799976825714Pour tracer les courbes de perte et de précision pour chaque époque, nous utiliserons la fonction `plot`.
plot(history)En regardant le graphique, nous pouvons observer que la ligne ne s'est pas encore aplatie. Cela signifie qu'avec un plus grand nombre d'époques, nous pouvons améliorer les métriques du modèle.
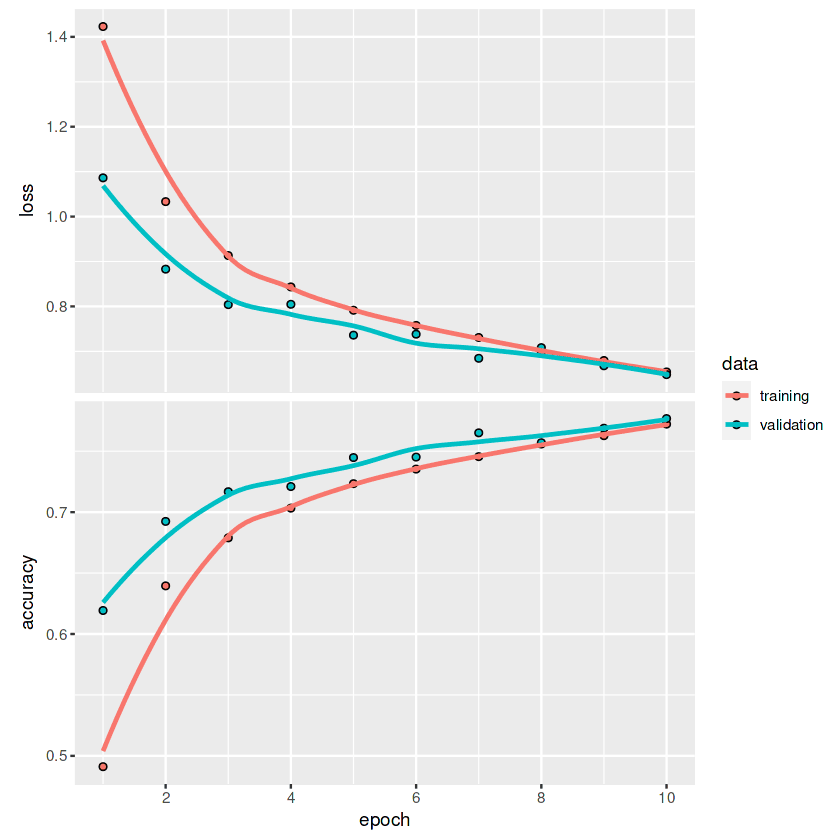
Si vous souhaitez en savoir plus sur l'API Keras et sur la manière dont vous pouvez l'utiliser pour créer des réseaux neuronaux profonds, consultez le site keras : Tutoriel sur l'apprentissage profond dans R.
On trouve des exemples concrets de réseaux neuronaux partout, des applications mobiles à l'ingénierie. En raison du récent essor du langage et des grands modèles visuels, de plus en plus d'entreprises s'intéressent à la mise en œuvre de réseaux neuronaux profonds afin d'accroître leurs bénéfices et la satisfaction de leurs clients.
Dans cette section, nous allons découvrir les 10 principales applications des réseaux neuronaux qui façonnent le monde moderne.
Les réseaux neuronaux simples sont très efficaces pour les données tabulaires de grande taille. Nous pouvons les utiliser pour les problèmes de classification, de regroupement et de régression.
De nombreuses entreprises utilisent les LSTM, GRU et RNN pour les prévisions financières. Cela leur permet de prendre de meilleures décisions.
La détection du cancer du sein, la détection des anomalies et la segmentation des images sont quelques-unes des applications des réseaux neuronaux convolutionnels. Grâce aux transformateurs préformés, nous avons pu observer des progrès dans la recherche sur la prévention des maladies et la détection précoce des maladies mortelles.
Les recommandations de produits, les expériences personnalisées et les chatbots sont quelques-unes des applications des réseaux neuronaux utilisées dans le commerce électronique. Ces modèles sont principalement utilisés pour le regroupement, le traitement du langage naturel et la vision par ordinateur afin d'améliorer l'expérience des clients sur la plateforme.
Grâce à la popularité de DALL-E 2 et à une diffusion stable, cet espace est devenu courant. Des sociétés telles que Canva et Adobe ont déjà mis en place une capacité de génération d'images afin d'augmenter le nombre d'utilisateurs. Au-delà du battage médiatique, les images génératives sont utilisées dans tous les secteurs d'activité pour créer des données synthétiques afin d'améliorer les performances, la stabilité et les biais du modèle.
ChatGPT, GPT-3 et GPT-NEO sont les modèles de réseaux neuronaux profonds qui dominent l'espace. Ces modèles sont utilisés pour l'assistance à la programmation, les chatbots, la traduction, les questions/réponses, etc. Il est partout et les entreprises l'intègrent facilement dans leurs systèmes actuels.
DailoGPT et Blenderbot sont des modèles conversationnels populaires qui améliorent votre expérience de chatbot. Ils sont adaptatifs et peuvent être réglés avec précision pour un objectif spécifique. À l'avenir, nous ne verrons plus de longs temps d'attente ; ces chatbots seront capables de comprendre vos problèmes et d'y apporter des solutions en temps réel.
Les modèles de réseaux neuronaux d'apprentissage par renforcement et de vision par ordinateur jouent un rôle majeur dans les industries de transfert. Par exemple, la gestion des entrepôts, les usines et l'expérience d'achat sont entièrement automatisées.
Les modèles de réseaux neuronaux de reconnaissance de la parole, de synthèse vocale et de détection de l'activité audio sont utilisés pour l'assistance vocale, la transcription automatique et les applications de communication améliorée.
La conversion de texte en image (DALLE-2), le texte d'image, la réponse à des questions visuelles et l'extraction de caractéristiques sont quelques-unes des applications utilisées dans les réseaux neuronaux multimodaux. À l'avenir, vous verrez des textes-vidéos accompagnés d'audio. Vous pourrez créer un film complet en fournissant le script.
Les packages Keras et TensorFlow R nous fournissent une gamme complète d'outils pour créer une architecture de modèle complexe pour des tâches spécifiques. Vous pouvez charger l'ensemble de données, effectuer un prétraitement, construire et optimiser le modèle, et évaluer le modèle en utilisant quelques lignes de code. De plus, avec Tensorflow, vous pouvez contrôler vos expériences, configurer les GPU et déployer le modèle en production.
Dans ce tutoriel, nous avons appris les bases des réseaux neuronaux, le type d'architecture du modèle et l'application. De plus, nous avons appris à former un réseau neuronal simple à l'aide de `neuralnet` et un réseau neuronal convolutif à l'aide de `keras`. Le tutoriel couvre la construction du modèle, la compilation, la formation et l'évaluation.
Apprenez-en plus sur l'API Tensorflow et Keras en suivant le cours Introduction à TensorFlow dans R. Vous apprendrez à connaître tensorboard et d'autres API TensorFlow, à construire des réseaux neuronaux profonds et à améliorer les performances des modèles à l'aide de la régularisation, de l'abandon et de l'optimisation des hyperparamètres.
R Cours
Cours
Cours
Cours
blog
Nathaniel Taylor-Leach
8 min
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach