Course
Data Manipulation in SQL
4 hr
324.1K
We will use the Unicorn Companies Database, which is available on DataLab, DataCamp's AI-enabled data notebook. These companies are called Unicorns because they are startup companies with a valuation of over a billion dollars. For simplicity, we’ll focus on three tables: companies, sales, and product_emissions. To run all the example code in this tutorial yourself, you can create a DataLab workbook for free with the database and all code samples pre-loaded for you.
GROUP BY is a SQL command commonly used to aggregate the data to get insights from it. There are three phases when you group data:
We can begin by showing a simple example of GROUP BY. Suppose we want to find the top ten countries with the highest number of Unicorn companies.
SELECT *
FROM companies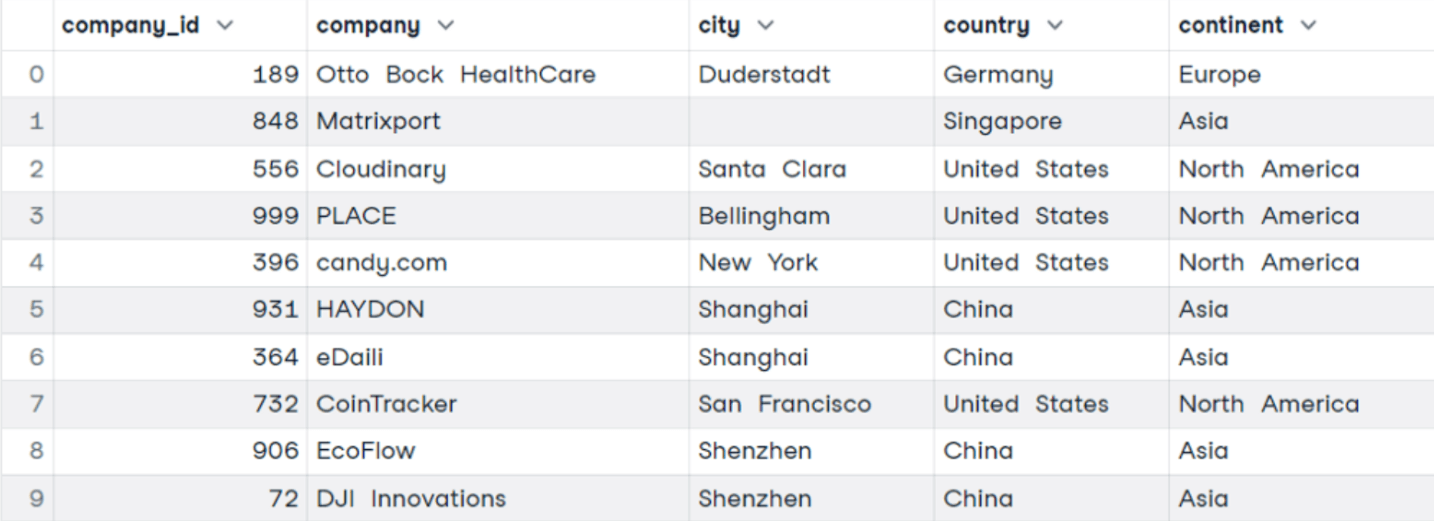
It also would be nice to order the results in decreasing order based on the number of companies
SELECT country, COUNT(*) AS n_companies
FROM companies
GROUP BY country
ORDER BY n_companies DESC
LIMIT 10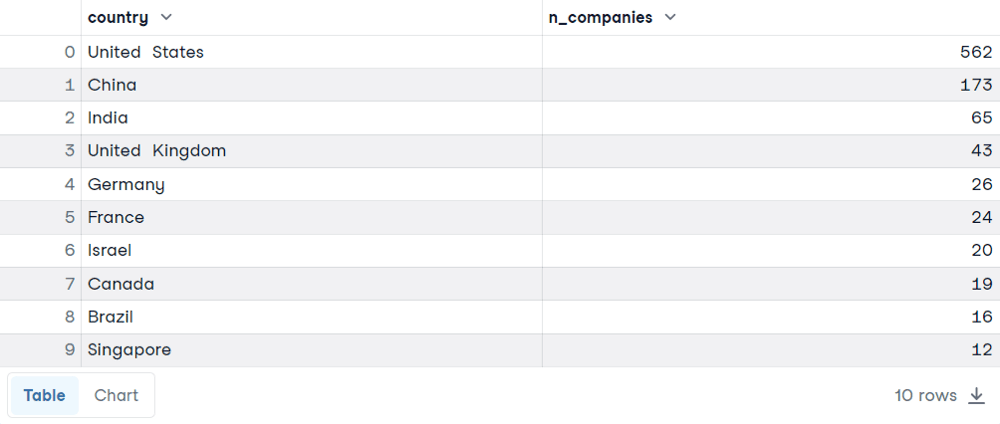
Here we have the results. You will probably not be surprised to find the US, China, and India in the ranking. Let’s explain the decision behind this query:
First, notice that we used COUNT(*) to count the rows for each group, which corresponds to the country. In addition, we also used the SQL alias to rename the column into a more explainable name. This is possible by using the keyword AS, followed by the new name. COUNT is covered in more depth in the COUNT() SQL FUNCTION tutorial.
The fields were selected from the table companies, where each row corresponds to a Unicorn company.
After, we need to specify the column name after GROUP BY to aggregate the data based on the country.
ORDER BY is required to visualize the countries in the right order, from the highest number to the lower number of companies.
We limit the results to 10 using LIMIT, which is followed by the number of rows you want in the results.
Now, we will analyze the table with the sales. For each order number, we have the type of client, the product line, the quantity, the unit price, the total, etc.
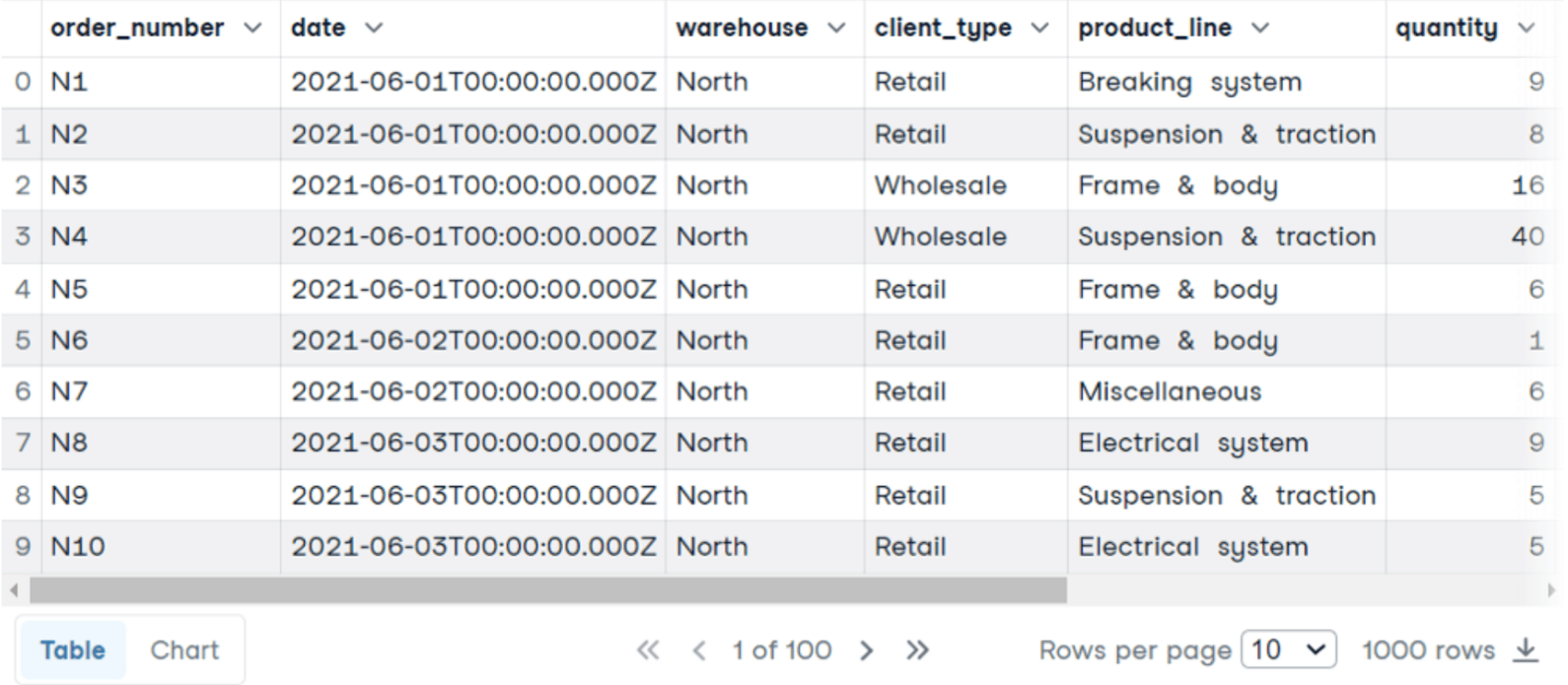
This time, we are interested in finding the average price per unit, the total number of orders, and the total gain for each product line:
SELECT
product_line,
AVG(unit_price) AS avg_price,
SUM(quantity) AS tot_pieces,
SUM(total) AS total_gain
FROM sales
GROUP BY product_line
ORDER BY total_gain DESC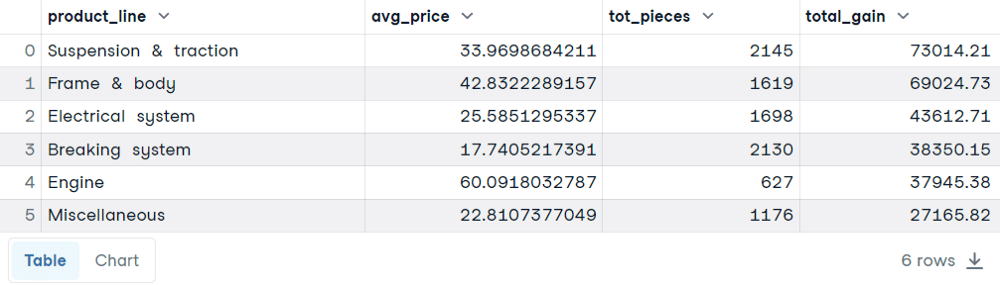
Instead of counting the number of rows, we have the AVG() function to obtain the average price and the SUM() function to calculate the total number of orders and the total gain for each product line.
As before, we specify the column initially dividing the dataset into chunks. Then the aggregation functions will allow us to obtain a row per each modality of the product line.
This time, ORDER BY is optional. It was included to highlight how the higher total gains are not always proportional to higher average prices or total pieces.
Let’s take the previous example again. Now, we want to put a condition to the query: we only want to filter for the total number of orders higher than 40,000. Let's try the WHERE clause:
SELECT
product_line,
AVG(unit_price) AS avg_price,
SUM(quantity) AS tot_pieces,
SUM(total) AS total_gain
FROM sales
WHERE SUM(total) > 40000
GROUP BY product_line
ORDER BY total_gain DESCThis query will return the following error:

This error’s not possible to pass aggregated functions in the WHERE clause. We need a new command to solve this issue.
Like WHERE, the HAVING clause filters the rows of a table. Whereas WHERE tried to filter the whole table, HAVING filters rows within each of the groups defined by GROUP BY
Here's the previous example again, replacing the word WHERE with HAVING.
SELECT
product_line,
AVG(unit_price) AS avg_price,
SUM(quantity) AS tot_pieces,
SUM(total) AS total_gain
FROM sales
GROUP BY product_line
HAVING SUM(total) > 40000
ORDER BY total_gain DESC
This time it will produce three rows. The other product lines didn’t match the criterion, so we passed from six results to three.
What else do you notice from the query? We didn’t pass the column alias to HAVING, but the aggregation of the original field. Are you asking yourself why? You’ll unravel the mystery in the next example.
As the last example, we will use the table called product_emissions, which contains the emission of the products provided by the companies.
This time, we are interested in showing the average product carbon footprint (pcf) for each company that belongs to the industry group “Technology Hardware & Equipment.” Moreover, it would be helpful to see the number of products for each company to understand if there is some relationship between the number of products and the carbon footprint. We also again use HAVING to extract companies with an average carbon footprint of over 100.
SELECT pe.company, count(product_name) AS n_products, avg(carbon_footprint_pcf) AS avg_carbon_footprint_pcf
FROM product_emissions AS pe
WHERE industry_group = 'Technology Hardware & Equipment'
GROUP BY pe.company, industry_group
having avg_carbon_footprint_pcf>100
ORDER BY n_products
An error appeared after trying to use the alias. For the HAVING clause, the new column’s name doesn’t exist, so it won’t be able to filter the query. Let’s correct the request:
SELECT pe.company, count(product_name) AS n_products, avg(carbon_footprint_pcf) AS avg_carbon_footprint_pcf
FROM product_emissions AS pe
WHERE industry_group = 'Technology Hardware & Equipment'
GROUP BY pe.company, industry_group
having avg(carbon_footprint_pcf)>100
ORDER BY n_products
This time, the condition worked, and we can visualize the results from the table. We just learned that column aliases can’t be used in HAVING because this condition is applied before the SELECT. For this reason, it cannot recognize the fields from the new names.
This is the order of the commands while writing the query:
SELECT
FROM
WHERE
GROUP BY
HAVING
ORDER BYBut there is a question you need to ask yourself. In what order do SQL commands execute? As humans, we often take for granted that the computer reads and interprets SQL from top to down. But the reality is different from what it might look like. This is the right order of execution:
FROM
WHERE
GROUP BY
HAVING
SELECT
ORDER BY
LIMITSo, the query processor doesn’t start from SELECT, but it begins by selecting which tables to include, and SELECT is executed after HAVING. This explains why HAVING doesn’t allow the use of ALIAS, while ORDER BY doesn’t have problems with it. In addition to this aspect, this order of execution clarifies the reason why HAVING is used together with GROUP BY to apply conditions on aggregated data, while WHERE cannot.
I would read our tutorial, SQL Order of Execution: Understanding How Queries Run, which gives good detail, if you want to learn more.
After reading this tutorial, you should have a clear idea of the difference between GROUP BY and HAVING. You can practice on DataLab to master these concepts.
If you want to move to the next level of the SQL learning path, you can take our Intermediate SQL course. If you still need to strengthen your foundations of SQL, you can go back to the Introduction to SQL course to learn about the fundamentals of the language.
SQL Courses
Course
Course
Tutorial
Islam Salahuddin
Tutorial
Allan Ouko
Tutorial
Sayak Paul
Tutorial
Allan Ouko
Tutorial
Bekhruz Tuychiev
code-along
Kelsey McNeillie