Kurs
Datenbearbeitung in SQL
4 Std.
324.1K
Wir werden die Unicorn Companies Database verwenden, die auf DataLab, dem KI-fähigen Daten-Notebook von DataCamp, verfügbar ist. Diese Unternehmen werden "Einhorn" genannt, weil sie Startup-Unternehmen mit einer Bewertung von über einer Milliarde Dollar sind. Diese Datenbank enthält also die Daten dieser Einhorn-Unternehmen und besteht aus sieben Tabellen. Der Einfachheit halber werden wir uns auf drei Tabellen konzentrieren: companies, sales, und product_emissions.
GROUP BYGROUP BY ist ein SQL-Befehl, der häufig verwendet wird, um die Daten zu aggregieren und daraus Erkenntnisse zu gewinnen. Wenn du Daten gruppierst, gibt es drei Phasen:
GROUP BY Beispiel 1Wir können damit beginnen, ein einfaches Beispiel für GROUP BY zu zeigen. Angenommen, wir wollen die zehn Länder mit der höchsten Anzahl an Einhorn-Unternehmen finden.
SELECT *
FROM companies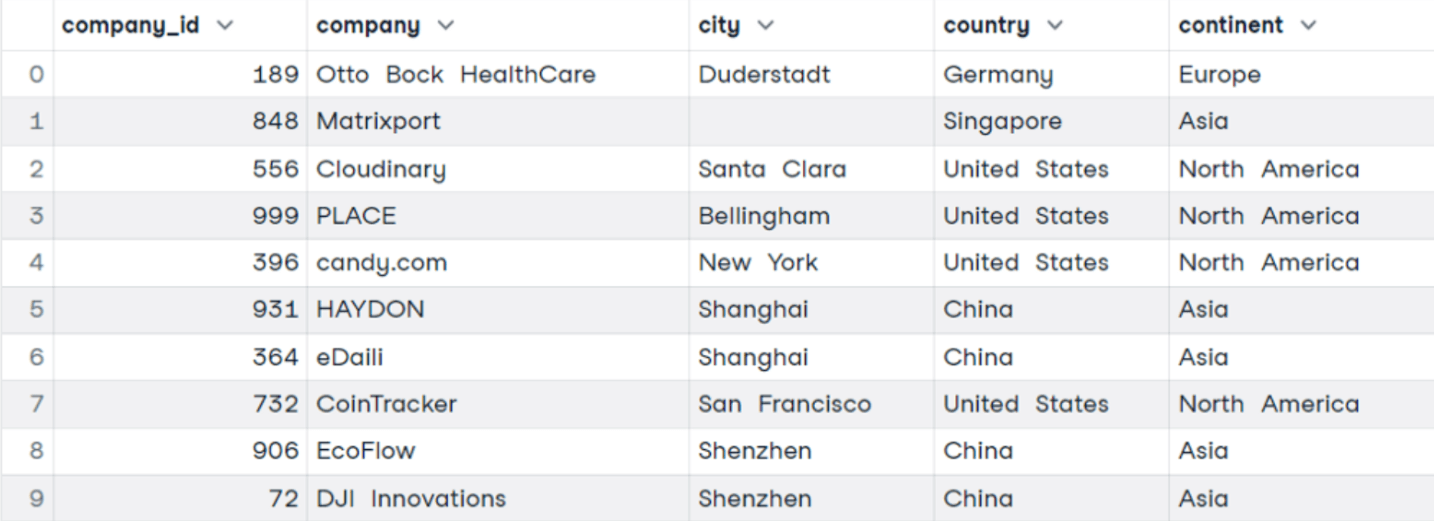
Es wäre auch schön, die Ergebnisse in absteigender Reihenfolge nach der Anzahl der Unternehmen zu sortieren.
SELECT country, COUNT(*) AS n_companies
FROM companies
GROUP BY country
ORDER BY n_companies DESC
LIMIT 10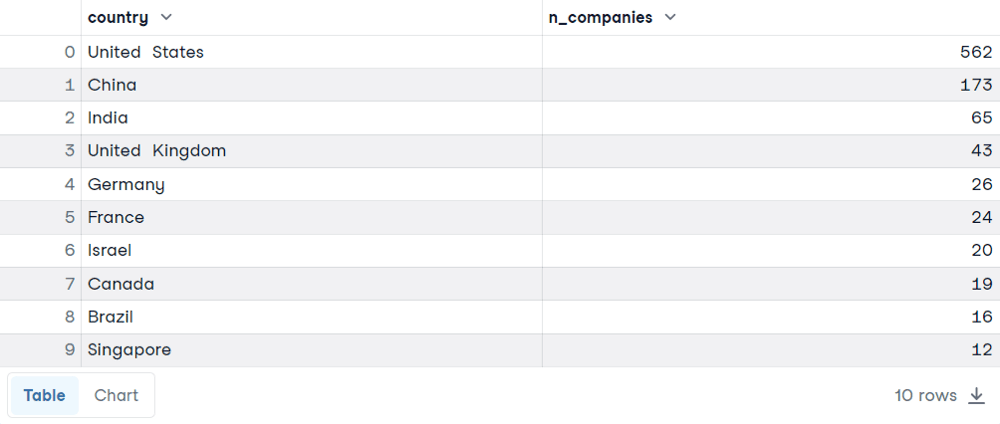
Hier haben wir die Ergebnisse. Es wird dich wahrscheinlich nicht überraschen, dass die USA, China und Indien auf der Rangliste stehen. Lass uns die Entscheidung hinter dieser Abfrage erklären:
COUNT(*) verwendet haben, um die Zeilen für jede Gruppe, die dem Land entspricht, zu zählen. Außerdem haben wir den SQL-Alias verwendet, um die Spalte in einen besser verständlichen Namen umzubenennen. Dies ist möglich, indem du das Schlüsselwort AS verwendest, gefolgt von dem neuen Namen. COUNT wird im Tutorial COUNT() SQL FUNCTION ausführlicher behandelt.GROUP BY angeben, um die Daten nach dem Land zu aggregieren. ORDER BY ist erforderlich, um die Länder in der richtigen Reihenfolge darzustellen, von der höchsten Anzahl an Unternehmen bis zur geringeren Anzahl an Unternehmen. LIMIT, gefolgt von der Anzahl der Zeilen, die du in den Ergebnissen haben möchtest.GROUP BY Beispiel 2 Jetzt werden wir die Tabelle mit den Verkäufen analysieren. Für jede Bestellnummer haben wir die Art des Kunden, die Produktlinie, die Menge, den Stückpreis, den Gesamtbetrag usw.
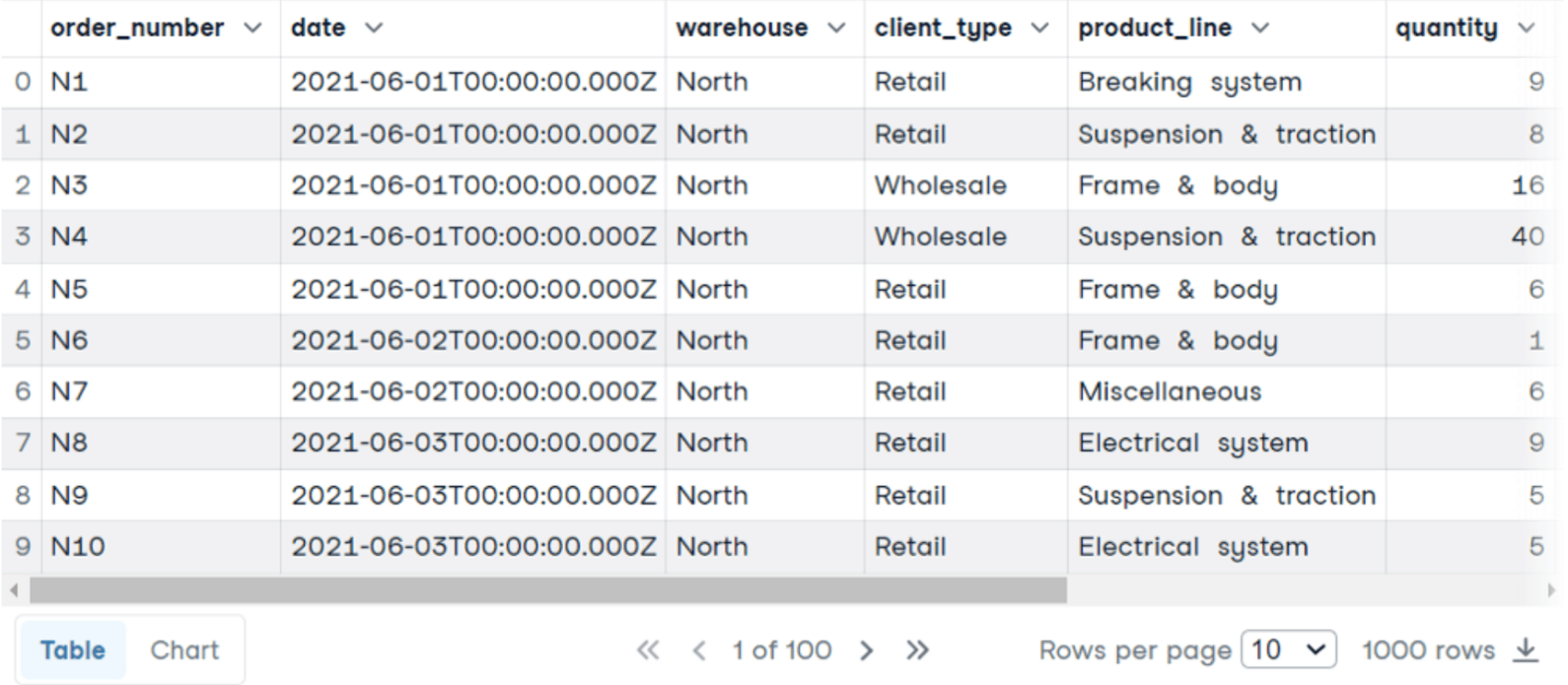
Diesmal interessieren wir uns für den Durchschnittspreis pro Einheit, die Gesamtzahl der Bestellungen und den Gesamtgewinn für jede Produktlinie:
SELECT
product_line,
AVG(unit_price) AS avg_price,
SUM(quantity) AS tot_pieces,
SUM(total) AS total_gain
FROM sales
GROUP BY product_line
ORDER BY total_gain DESC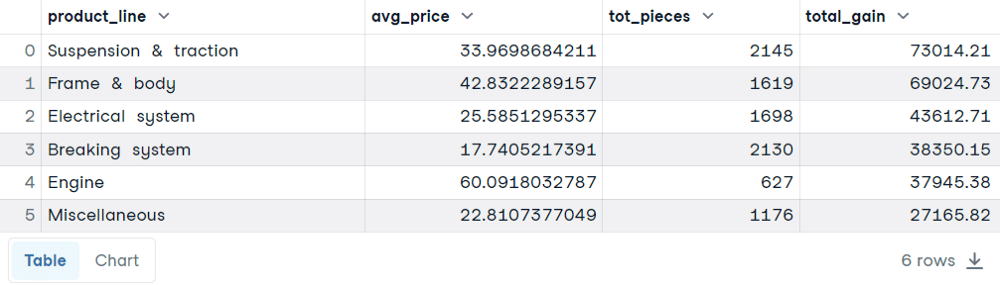
AVG(), um den Durchschnittspreis zu erhalten, und die Funktion SUM(), um die Gesamtzahl der Bestellungen und den Gesamtgewinn für jede Produktlinie zu berechnen. ORDER BY optional. Er wurde aufgenommen, um zu verdeutlichen, dass die höheren Gesamtgewinne nicht immer proportional zu den höheren Durchschnittspreisen oder der Gesamtstückzahl sind. WHERENehmen wir noch einmal das vorherige Beispiel. Jetzt wollen wir die Abfrage mit einer Bedingung versehen: Wir wollen nur nach der Gesamtzahl der Bestellungen über 40.000 filtern. Versuchen wir es mit der WHERE Klausel:
SELECT
product_line,
AVG(unit_price) AS avg_price,
SUM(quantity) AS tot_pieces,
SUM(total) AS total_gain
FROM sales
WHERE SUM(total) > 40000
GROUP BY product_line
ORDER BY total_gain DESCDiese Abfrage wird den folgenden Fehler zurückgeben:

Dieser Fehler ist nicht möglich, wenn du aggregierte Funktionen in der WHERE Klausel übergibst. Wir brauchen einen neuen Befehl, um dieses Problem zu lösen.
Wie WHERE filtert auch die HAVING Klausel die Zeilen einer Tabelle. Während WHERE versucht, die gesamte Tabelle zu filtern, filtert HAVING die Zeilen innerhalb jeder der Gruppen, die durch GROUP BY
Hier ist das vorherige Beispiel noch einmal, wobei das Wort WHERE durch HAVING ersetzt wurde.
SELECT
product_line,
AVG(unit_price) AS avg_price,
SUM(quantity) AS tot_pieces,
SUM(total) AS total_gain
FROM sales
GROUP BY product_line
HAVING SUM(total) > 40000
ORDER BY total_gain DESC
Dieses Mal werden drei Reihen erzeugt. Die anderen Produktlinien erfüllten das Kriterium nicht, sodass wir von sechs Ergebnissen auf drei kamen.
Was fällt dir bei der Abfrage noch auf? Wir haben nicht den Spaltenalias an HAVING übergeben, sondern die Aggregation des ursprünglichen Feldes. Fragst du dich, warum? Du wirst das Geheimnis im nächsten Beispiel lüften.
Als letztes Beispiel verwenden wir die Tabelle product_emissions, die die Emissionen der von den Unternehmen angebotenen Produkte enthält.
Dieses Mal interessieren wir uns für den durchschnittlichen Product Carbon Footprint (pcf) für jedes Unternehmen, das zur Industriegruppe "Technology Hardware & Equipment" gehört. Außerdem wäre es hilfreich, die Anzahl der Produkte für jedes Unternehmen zu sehen, um zu verstehen, ob es einen Zusammenhang zwischen der Anzahl der Produkte und dem Carbon Footprint gibt. Wir verwenden auch wieder HAVING, um Unternehmen mit einem durchschnittlichen Carbon Footprint von über 100 herauszufiltern.
SELECT pe.company, count(product_name) AS n_products, avg(carbon_footprint_pcf) AS avg_carbon_footprint_pcf
FROM product_emissions AS pe
WHERE industry_group = 'Technology Hardware & Equipment'
GROUP BY pe.company, industry_group
having avg_carbon_footprint_pcf>100
ORDER BY n_products
Beim Versuch, den Alias zu verwenden, trat ein Fehler auf. Für die HAVING Klausel existiert der Name der neuen Spalte nicht, sodass sie die Abfrage nicht filtern kann. Lass uns die Anfrage korrigieren:
SELECT pe.company, count(product_name) AS n_products, avg(carbon_footprint_pcf) AS avg_carbon_footprint_pcf
FROM product_emissions AS pe
WHERE industry_group = 'Technology Hardware & Equipment'
GROUP BY pe.company, industry_group
having avg(carbon_footprint_pcf)>100
ORDER BY n_products
Dieses Mal hat die Bedingung funktioniert, und wir können die Ergebnisse in der Tabelle sehen. Wir haben gerade gelernt, dass Spaltenaliase nicht in HAVING verwendet werden können, weil diese Bedingung vor der SELECT angewendet wird. Aus diesem Grund kann es die Felder nicht anhand der neuen Namen erkennen.
Das ist die Reihenfolge der Befehle beim Schreiben der Abfrage:
SELECT
FROM
WHERE
GROUP BY
HAVING
ORDER BYAber es gibt eine Frage, die du dir stellen musst. In welcher Reihenfolge werden die SQL-Befehle ausgeführt? Als Menschen gehen wir oft davon aus, dass der Computer SQL von oben nach unten liest und interpretiert. Aber die Realität sieht anders aus, als es vielleicht den Anschein hat. Das ist die richtige Reihenfolge der Ausführung:
FROM
WHERE
GROUP BY
HAVING
SELECT
ORDER BY
LIMIT Der Abfrageprozessor beginnt also nicht mit SELECT, sondern mit der Auswahl der einzubeziehenden Tabellen, und SELECT wird nach HAVING ausgeführt. Das erklärt, warum HAVING die Verwendung von ALIAS nicht zulässt, während ORDER BY keine Probleme damit hat. Zusätzlich zu diesem Aspekt verdeutlicht diese Reihenfolge der Ausführung den Grund, warum HAVING zusammen mit GROUP BY verwendet wird, um Bedingungen auf aggregierte Daten anzuwenden, während WHERE dies nicht kann.
Nach der Lektüre dieses Tutorials solltest du eine klare Vorstellung vom Unterschied zwischen GROUP BY und HAVING haben. Du kannst im DataLab üben, um diese Konzepte zu beherrschen.
Wenn du auf die nächste Stufe des SQL-Lernpfads wechseln möchtest, kannst du unseren SQL-Kurs für Fortgeschrittene besuchen. Wenn du deine SQL-Grundlagen noch vertiefen musst, kannst du zum Kurs Einführung in SQL zurückkehren, um die Grundlagen der Sprache zu lernen.
SQL-Kurse
Kurs
Kurs
Tutorial
Sejal Jaiswal
Tutorial
Laiba Siddiqui
Tutorial
Matt Crabtree
Tutorial
Allan Ouko
Tutorial
Sejal Jaiswal
Tutorial
Mark Pedigo

