R est un outil puissant pour la mise en œuvre de la classification KNN, et il est généralement utilisé par les scientifiques des données et les statisticiens pour diverses applications d'apprentissage automatique.
Dans ce tutoriel, nous allons découvrir les K-voisins les plus proches, comment ils fonctionnent, et passer en revue certains avantages et inconvénients. En outre, nous utiliserons les paquets R "class" et "caret" pour mettre en œuvre facilement le modèle de classification KNN.
Qu'est-ce que les K-voisins les plus proches ?
K-Nearest Neighbors (KNN) est un modèle d'apprentissage automatique supervisé qui peut être utilisé pour des tâches de régression et de classification. L'algorithme est non paramétrique, ce qui signifie qu'il ne fait aucune hypothèse sur la distribution sous-jacente des données.
L'algorithme KNN prédit les étiquettes de l'ensemble de données de test en examinant les étiquettes de ses voisins les plus proches dans l'espace des caractéristiques de l'ensemble de données d'apprentissage. Le "K" est l'hyperparamètre le plus important qui peut être réglé pour optimiser les performances du modèle.
KNN est un algorithme simple et intuitif qui donne de bons résultats pour un large éventail de problèmes de classification. Il est facile à mettre en œuvre et à comprendre, et il s'applique aussi bien aux petits qu'aux grands ensembles de données. Cependant, elle présente également quelques inconvénients, dont le principal est qu'elle peut s'avérer coûteuse en termes de calcul pour les grands ensembles de données ou les espaces de caractéristiques à haute dimension.
L'algorithme KNN est utilisé dans les moteurs de recommandation pour le commerce électronique, la reconnaissance d'images, la détection de fraudes, la classification de textes, la détection d'anomalies, etc. Dans ce tutoriel, nous utiliserons l'algorithme KNN pour un système d'approbation de prêt.
Si vous êtes confus et ne savez pas comment commencer votre voyage dans la science des données, prenez le cursus professionnel Data Scientist Professional with R et préparez-vous à une carrière réussie dans la science des données. Le cursus de compétences vous aidera à maîtriser la programmation R, l'ingestion de données, le nettoyage de données, la manipulation de données, la visualisation de données, l'apprentissage automatique, les tests d'hypothèses, les plans d'expérience, SQL et Git.
Comment fonctionne la classification par K-voisins les plus proches ?
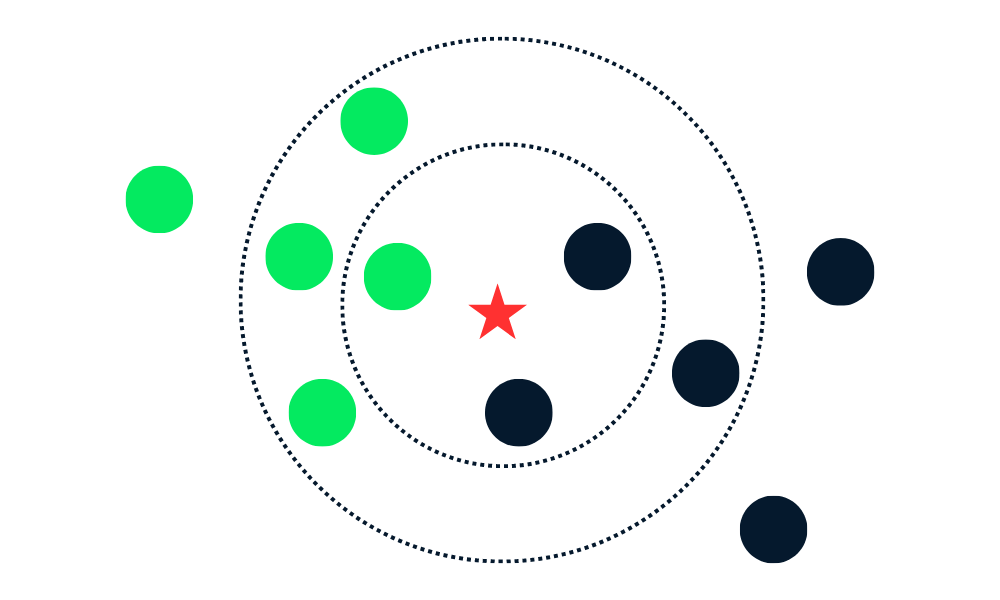
L'algorithme de classification KNN consiste à trouver les K voisins (points de données les plus proches) d'un nouveau point de données dans l'ensemble de données d'apprentissage. Il attribue ensuite aux nouveaux points de données l'étiquette de la classe majoritaire parmi les voisins.
Décomposons les algorithmes en plusieurs parties.
Tout d'abord, il calcule la distance entre les nouveaux points de données et tous les autres points de données de l'ensemble d'apprentissage et sélectionne les K points les plus proches. La métrique utilisée pour calculer la distance peut varier en fonction des problèmes. La métrique la plus utilisée est la distance euclidienne.
Après avoir identifié les K voisins les plus proches, l'algorithme attribue au nouveau point de données l'étiquette de la classe majoritaire parmi ces voisins. Par exemple, si les deux étiquettes sont "bleues" et l'une "rouge", l'algorithme attribuera l'étiquette "bleue" à un nouveau point de données.
Gif de eunsukim.me
Résumé :
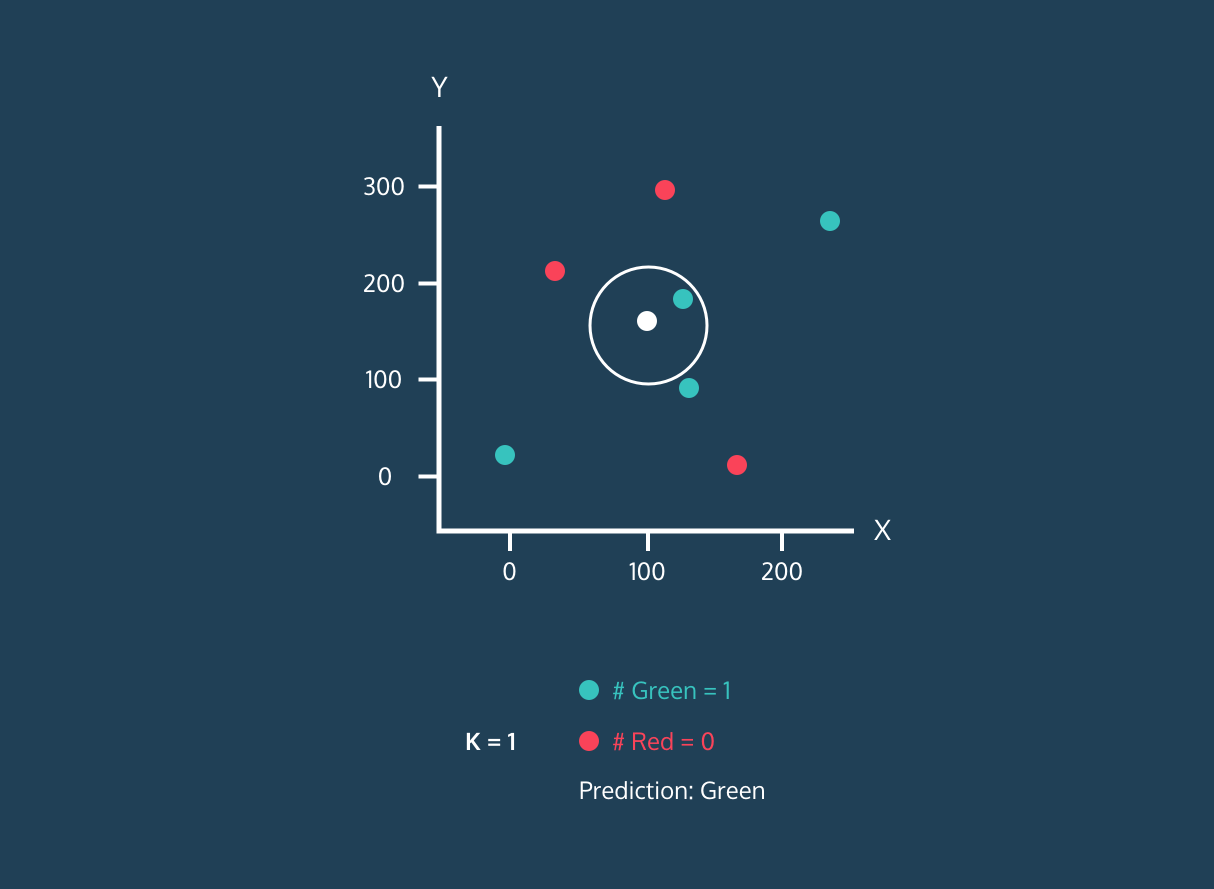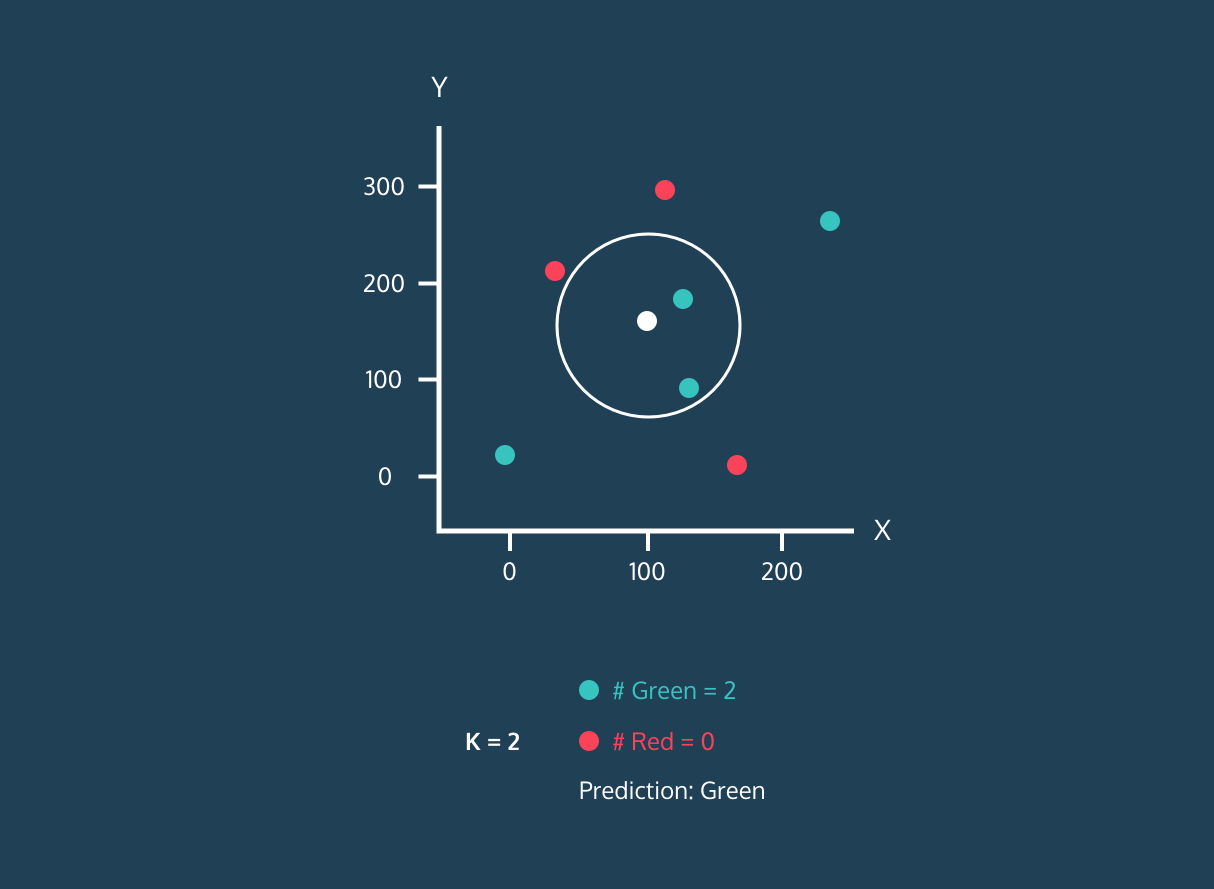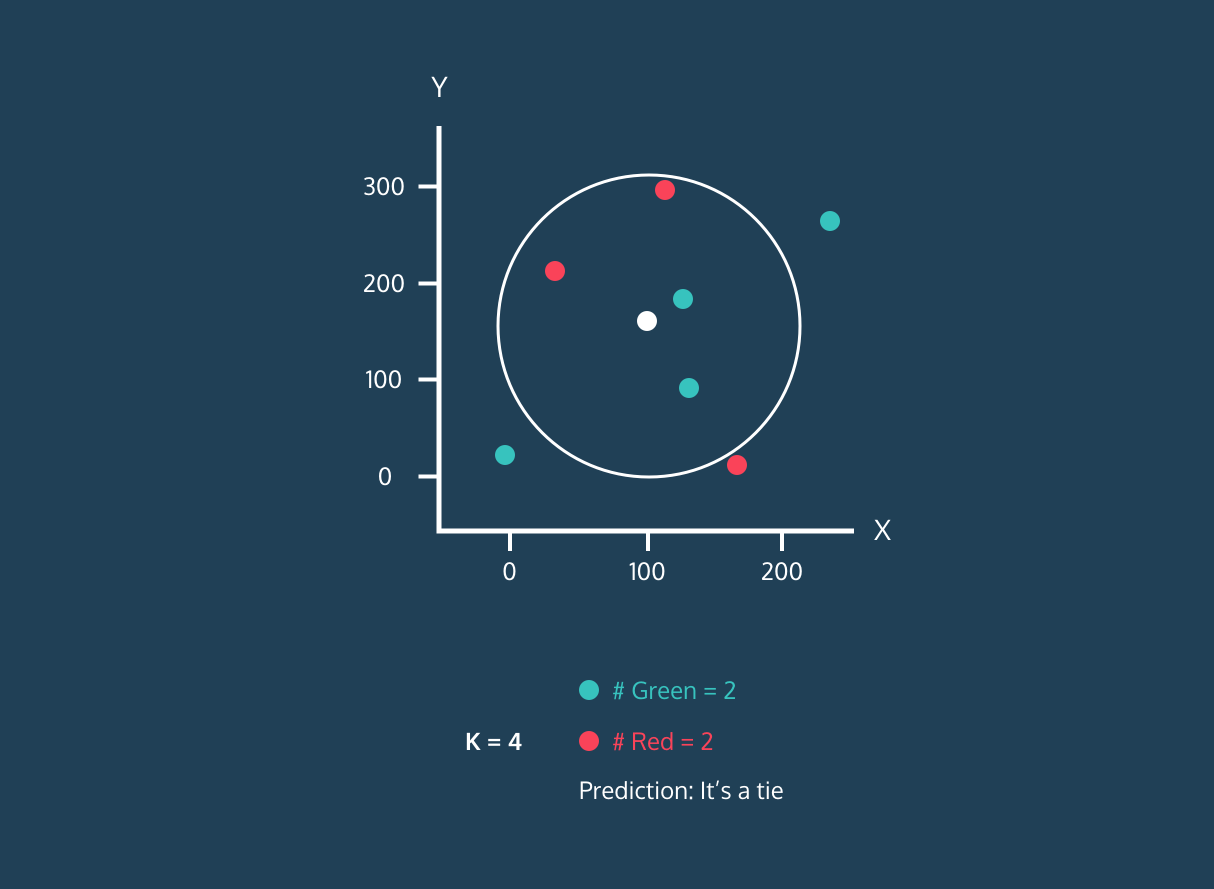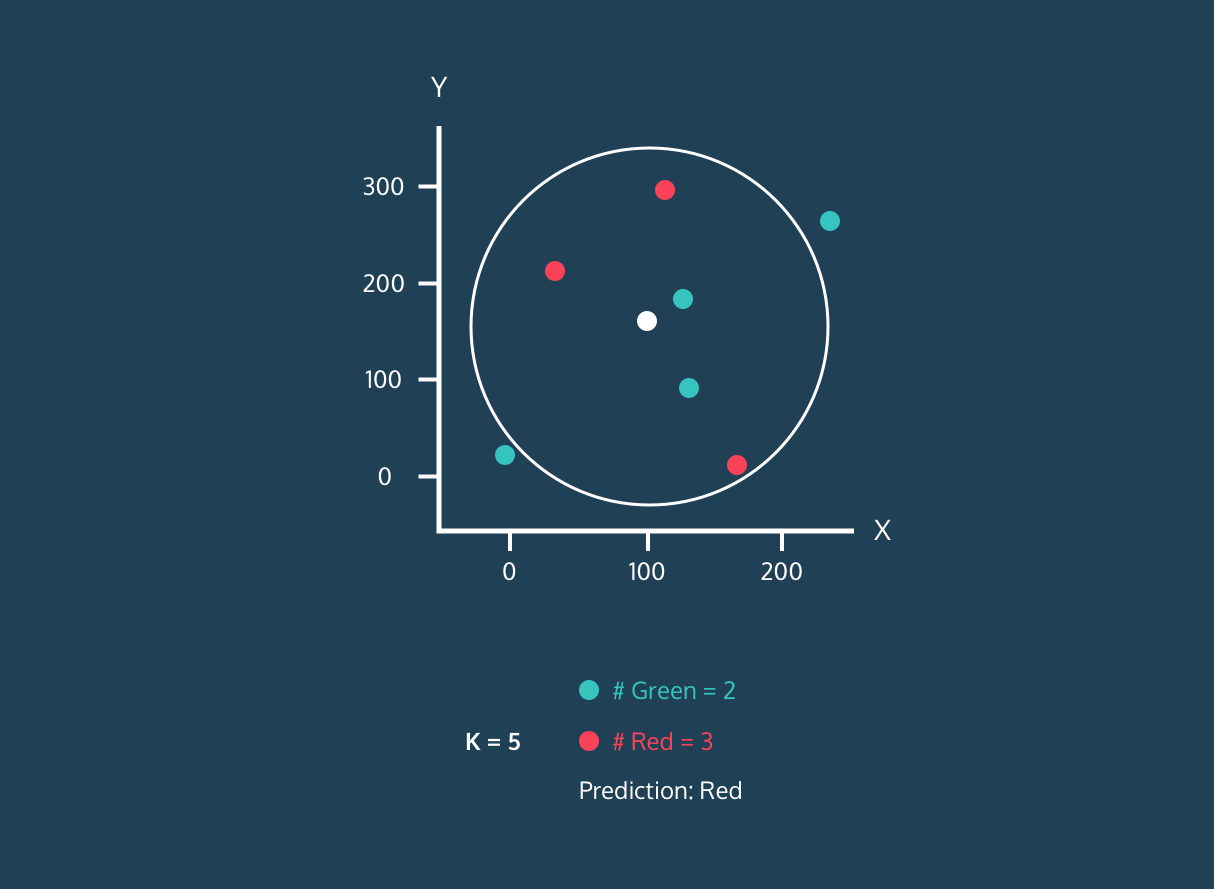
- Nous choisirons la valeur de K, qui est le nombre de voisins les plus proches qui seront utilisés pour faire la prédiction.
- Calculez la distance entre ce point et tous les points de l'ensemble d'apprentissage.
- Sélectionnez les K plus proches voisins en fonction des distances calculées.
- Attribuez l'étiquette de la classe majoritaire au nouveau point de données.
- Répétez les étapes 2 à 4 pour tous les points de données de l'ensemble de test.
- Évaluez la précision de l'algorithme.
La valeur de "K" est fournie par l'utilisateur et peut être utilisée pour optimiser les performances de l'algorithme. Des valeurs K plus petites peuvent conduire à un surajustement, et des valeurs plus grandes à un sous-ajustement. Il est donc essentiel de trouver les valeurs optimales qui assurent la stabilité et la meilleure adéquation.
Mise en œuvre de KNN en R
Dans cette section, nous utiliserons des données de prêt et nous entraînerons la classification KNN à l'aide du logiciel class. L'ensemble de données se compose de 10 000 prêts, et nous déterminerons si un prêt sera remboursé sur la base des données du client.
Chargement des données
Nous importerons la bibliothèque tidyverse afin d'accéder aux packages R essentiels pour le chargement, la manipulation et la visualisation des données. Le site suppressPackageStartupMessages supprimera les avertissements et vous obtiendrez un résultat propre.
Ensuite, nous utiliserons read_csv pour charger l'ensemble de données, supprimer la colonne "purpose" du dataframe à l'aide de la fonction subset et afficher les 3 premiers échantillons.
suppressPackageStartupMessages(library(tidyverse))
data <- read_csv('data/loans.csv.gz', show_col_types = FALSE)
data <- subset(data, select = -c(purpose))
head(data,3)
Entraînez-vous et testez le fractionnement
Nous pouvons diviser l'ensemble de données manuellement, mais l'utilisation de la bibliothèque caTools est beaucoup plus propre.
- Créer des conditions propices à la reproductibilité.
- Utilisez
sample.splitpour créer un index pour les ensembles de données de formation et de test dans un rapport de 75:25. - Utilisez
subsetpour créer un ensemble de données de formation et de test, comme indiqué ci-dessous.
library(caTools)
set.seed(255)
split = sample.split(data$not_fully_paid,
SplitRatio = 0.75)
train = subset(data,
split == TRUE)
test = subset(data,
split == FALSE)Mise à l'échelle des caractéristiques
Nous allons maintenant mettre à l'échelle l'ensemble de formation et l'ensemble de test. Au niveau du back-end, la fonction utilise (x - mean(x)) / sd(x). Nous ne faisons que redimensionner les caractéristiques et supprimer les étiquettes cibles des ensembles de test et d'apprentissage.
train_scaled = scale(train[-13])
test_scaled = scale(test[-13])Formation du classificateur KNN et prédiction
La bibliothèque class est très populaire pour l'apprentissage de la classification KNN. C'est simple et rapide. Nous vous fournirons un ensemble de données de formation et de test mis à l'échelle, une colonne cible et un hyperparamètre "k".
library(class)
test_pred <- knn(
train = train_scaled,
test = test_scaled,
cl = train$not_fully_paid,
k=10
)Évaluation du modèle
Pour évaluer les résultats du modèle, nous afficherons une matrice de confusion à l'aide de la fonction table. Nous avons fourni des étiquettes réelles (cible de test) et prédites à la fonction table, et comme nous pouvons le voir, nous obtenons d'assez bons résultats pour la classe majoritaire.
L'algorithme KNN n'est pas très performant dans le cas de données déséquilibrées, et c'est la raison pour laquelle nous constatons de faibles performances dans les classes minoritaires.
actual <- test$not_fully_paid
cm <- table(actual,test_pred)
cm test_pred
actual 0 1
0 1988 23
1 373 10Nous pouvons calculer la précision en additionnant les valeurs des vrais positifs de la matrice de confusion et en les divisant par la longueur totale des colonnes cibles.
Comme nous pouvons le constater, nous avons une bonne précision sur un modèle vanille. Nous pouvons améliorer cette précision en ajustant l'hyperparamètre "K" et en équilibrant l'ensemble des données.
accuracy <- sum(diag(cm))/length(actual)
sprintf("Accuracy: %.2f%%", accuracy*100)'Accuracy: 83.46%'Classification KNN en R avec caret
Dans cette section, nous utiliserons caret pour tout. caret est un paquetage R pour la construction et l'évaluation de modèles d'apprentissage automatique. Il fournit une interface pour les principaux algorithmes d'apprentissage automatique.
Nous l'utiliserons pour diviser et prétraiter l'ensemble de données, effectuer le réglage des hyperparamètres, et entraîner et évaluer les modèles.
Entraînez-vous et testez le fractionnement
Nous allons importer le paquet caret et préparer le terrain pour la reproductibilité. Ensuite, nous convertirons la variable cible d'un entier à un facteur. Enfin, nous utiliserons createDataPartition pour diviser l'ensemble de données en ensembles de données de formation et de test selon un rapport de 80:20.
suppressPackageStartupMessages(library(caret))
set.seed(255)
data$not_fully_paid <- factor(data$not_fully_paid, levels = c(0, 1))
trainIndex <- createDataPartition(data$not_fully_paid,
times=1,
p = .8,
list = FALSE)
train <- data[trainIndex, ]
test <- data[-trainIndex, ]Prétraitement des données
Nous mettrons ensuite à l'échelle l'ensemble de formation et l'ensemble de test à l'aide de la fonction preProcess.
preProcValues <- preProcess(train, method = c("center", "scale"))
trainTransformed <- predict(preProcValues, train)
testTransformed <- predict(preProcValues, test)Modèle Tuning
Avant d'entraîner notre modèle KNN, nous devons trouver la valeur optimale de "K" à l'aide de la fonction d'entraînement. La fonction train nécessite une formule, un ensemble de données d'entraînement mis à l'échelle, le nom du modèle, la méthode de contrôle de l'entraînement (validation croisée) et une liste d'hyperparamètres. Nous allons vérifier la performance du modèle lorsque "K" est égal à 3, 5 et 7.
knnModel <- train(
not_fully_paid ~ .,
data = trainTransformed,
method = "knn",
trControl = trainControl(method = "cv"),
tuneGrid = data.frame(k = c(3,5,7))
)Formation du modèle le plus performant
Après avoir trouvé la meilleure valeur de "K", nous entraînerons le modèle de classification KNN à l'aide d'un ensemble de données d'entraînement mis à l'échelle.
best_model<- knn3(
not_fully_paid ~ .,
data = trainTransformed,
k = knnModel$bestTune$k
)Évaluation du modèle
caret fournit une fonction d'évaluation de modèle simple et puissante. Pour afficher les résultats des performances du modèle, nous devons d'abord prédire les étiquettes pour l'ensemble de données de test inédites. Ensuite, nous utiliserons les valeurs prédites et réelles pour évaluer la performance du modèle à l'aide de la fonction confusionMatrix .
predictions <- predict(best_model, testTransformed,type = "class")
# Calculate confusion matrix
cm <- confusionMatrix(predictions, testTransformed$not_fully_paid)
cmNous obtenons ainsi la matrice de confusion, la précision du modèle, la valeur P, la sensibilité du modèle et d'autres paramètres importants qui nous aideront à déterminer la stabilité et la performance du modèle.
Comme nous pouvons le constater, le modèle a obtenu des résultats assez médiocres dans la classe "Neg Pred Value", qui est une classe minoritaire, et notre précision équilibrée est de 51 %. Nous pouvons obtenir un résultat similaire avec le jeu de la pièce de monnaie.
Nous pouvons améliorer le résultat en équilibrant les classes à l'aide de méthodes de suréchantillonnage et de sous-échantillonnage. Nous pouvons également procéder à l'ingénierie des caractéristiques, créer de nouvelles caractéristiques et supprimer les caractéristiques fortement corrélées.
Confusion Matrix and Statistics
Reference
Prediction 0 1
0 1570 288
1 39 18
Accuracy : 0.8292
95% CI : (0.8116, 0.8458)
No Information Rate : 0.8402
P-Value [Acc > NIR] : 0.9091
Kappa : 0.0516
Mcnemar's Test P-Value : <2e-16
Sensitivity : 0.97576
Specificity : 0.05882
Pos Pred Value : 0.84499
Neg Pred Value : 0.31579
Prevalence : 0.84021
Detection Rate : 0.81984
Detection Prevalence : 0.97023
Balanced Accuracy : 0.51729
'Positive' Class : 0Nous pouvons également simplifier notre résultat en l'affichant sous la forme d'un cadre de données.
data.frame(Accuracy = cm$overall["Accuracy"],
Sensitivity = cm$byClass["Sensitivity"],
Specificity = cm$byClass["Specificity"])
Si vous êtes un amoureux de Python et que vous souhaitez apprendre à effectuer une classification KNN, lisez notre tutoriel Classification des voisins les plus proches (KNN) avec scikit-learn pour comprendre les concepts et le flux de travail KNN à l'aide d'exemples.
Avantages et inconvénients de l'utilisation du KNN
Avantages
- Il s'agit d'un algorithme simple à comprendre et à mettre en œuvre.
- Il est polyvalent et peut être utilisé pour des tâches de régression et de classification.
- Il fournit des résultats interprétables qui peuvent être visualisés et compris car la classe prédite est basée sur les étiquettes des voisins les plus proches dans les données d'apprentissage.
- Le KNN ne fait pas d'hypothèses sur la limite de décision entre les classes, et cette caractéristique lui permet de saisir les relations non linéaires entre les caractéristiques.
- L'algorithme ne fait pas d'hypothèses sur la distribution des données, ce qui le rend adapté à un large éventail de problèmes.
- KNN ne construit pas le modèle. Il stocke les données d'apprentissage et les utilise pour la prédiction.
Inconvénients
- Elle est coûteuse en termes de calcul et de mémoire pour les ensembles de données complexes et de grande taille.
- Les performances de KNN diminuent pour les données déséquilibrées. Elle montre des préjugés en faveur de la classe majoritaire, ce qui peut se traduire par des performances médiocres pour les classes minoritaires.
- Elle n'est pas adaptée aux données bruitées. Étant donné que les voisins les plus proches d'un point de données peuvent ne pas être représentatifs de la véritable étiquette de la classe.
- Elle n'est pas adaptée aux données à haute dimension, car la distance entre tous les points de données peut devenir similaire en raison de la haute dimension.
- La recherche du nombre optimal de K voisins peut prendre beaucoup de temps.
- KNN est sensible aux valeurs aberrantes, car il choisit les voisins sur la base d'une métrique d'évidence.
- Il ne gère pas bien les valeurs manquantes dans l'ensemble de données d'apprentissage.
Conclusion
Dans ce tutoriel, nous avons appris à utiliser la classification K-Nearest Neighbors (KNN) avec R. Nous avons abordé le concept de base de KNN et son fonctionnement. En outre, nous avons découvert deux bibliothèques, class et caret, qui permettent d'entraîner et d'évaluer des modèles de classification KNN sur un ensemble de données réel.
Suivez le cours Supervised Learning in R : Classification pour découvrir d'autres algorithmes d'apprentissage automatique supervisé avec la programmation R. Vous apprendrez à connaître Naive Bayes, la régression logistique et les arbres de classification à l'aide d'exemples et d'exercices de code.
Les tutoriels R comprennent des étapes pour la manipulation, la division et le traitement de l'ensemble de données, l'ajustement des hyperparamètres, l'entraînement des modèles et l'évaluation des résultats. En raison d'un ensemble de données déséquilibré, nous avons obtenu les plus mauvaises performances dans la classe minoritaire.
Vous devez comprendre que l'algorithme KNN n'est pas parfait, qu'il présente également des inconvénients et qu'il faut tenir compte d'un grand nombre d'éléments avant de le sélectionner comme modèle principal.
