O R é uma ferramenta avançada para a implementação da classificação KNN e geralmente é usado por cientistas de dados e estatísticos para vários aplicativos de aprendizado de máquina.
Neste tutorial, aprenderemos sobre o K-Nearest Neighbors, como ele funciona e analisaremos algumas vantagens e desvantagens. Além disso, usaremos o pacote R "class" e "caret" para implementar facilmente o modelo de classificação KNN.
O que é o K-Nearest Neighbors?
O K-Nearest Neighbors (KNN) é um modelo de aprendizado de máquina supervisionado que pode ser usado para tarefas de regressão e classificação. O algoritmo é não paramétrico, o que significa que ele não faz nenhuma suposição sobre a distribuição subjacente dos dados.
O algoritmo KNN prevê os rótulos do conjunto de dados de teste observando os rótulos de seus vizinhos mais próximos no espaço de recursos do conjunto de dados de treinamento. O "K" é o hiperparâmetro mais importante que pode ser ajustado para otimizar o desempenho do modelo.
O KNN é um algoritmo simples e intuitivo que fornece bons resultados para uma ampla gama de problemas de classificação. É fácil de implementar e entender, e se aplica a conjuntos de dados pequenos e grandes. No entanto, ele também tem algumas desvantagens, e a principal delas é que pode ser computacionalmente caro para grandes conjuntos de dados ou espaços de recursos de alta dimensão.
O algoritmo KNN é usado em mecanismos de recomendação de comércio eletrônico, reconhecimento de imagens, detecção de fraudes, classificação de texto, detecção de anomalias e muito mais. Neste tutorial, usaremos o algoritmo KNN para um sistema de aprovação de empréstimos.
Se você está confuso e não sabe como começar sua jornada na ciência de dados, faça o curso Data Scientist Professional with R e prepare-se para uma carreira de sucesso na ciência de dados. A trilha de habilidades o ajudará a dominar a programação em R, a ingestão de dados, a limpeza de dados, a manipulação de dados, a visualização de dados, o aprendizado de máquina, os testes de hipóteses, os projetos experimentais, o SQL e o Git.
Como funciona a classificação do K-Nearest Neighbors?
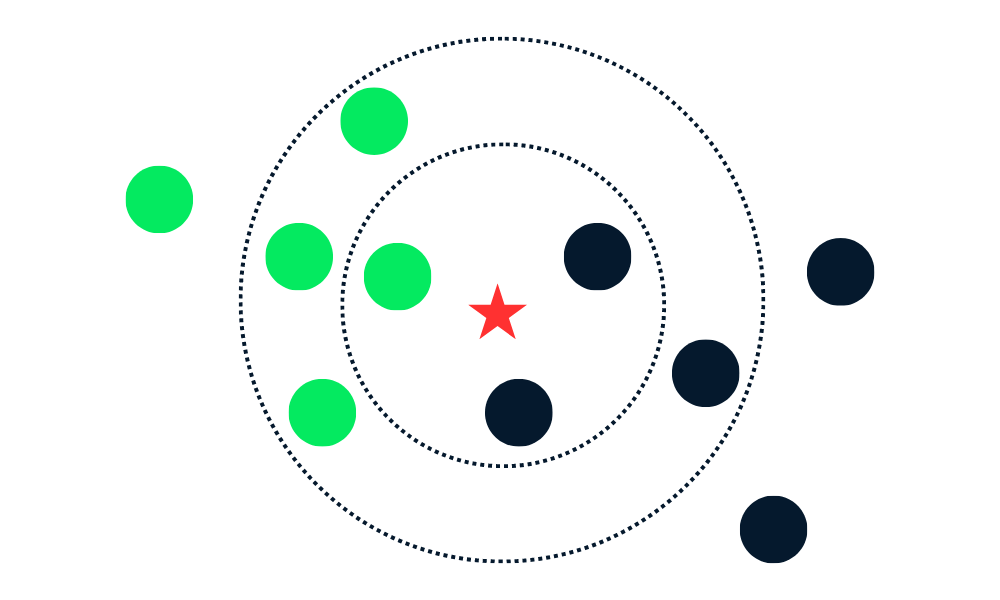
O algoritmo de classificação KNN funciona encontrando K vizinhos (pontos de dados mais próximos) no conjunto de dados de treinamento para um novo ponto de dados. Em seguida, ele atribui o rótulo da classe majoritária entre os vizinhos aos novos pontos de dados.
Vamos dividir os algoritmos em várias partes.
Primeiro, ele calcula a distância entre os novos pontos de dados e todos os outros pontos de dados no conjunto de treinamento e seleciona K pontos mais próximos. A métrica usada para calcular a distância pode variar de acordo com os problemas. A métrica mais usada é a distância euclidiana.
Depois de identificar os K vizinhos mais próximos, o algoritmo atribui o rótulo da classe majoritária entre esses vizinhos ao novo ponto de dados. Por exemplo, se os dois rótulos forem "azul" e um rótulo for "vermelho", o algoritmo atribuirá o rótulo "azul" a um novo ponto de dados.
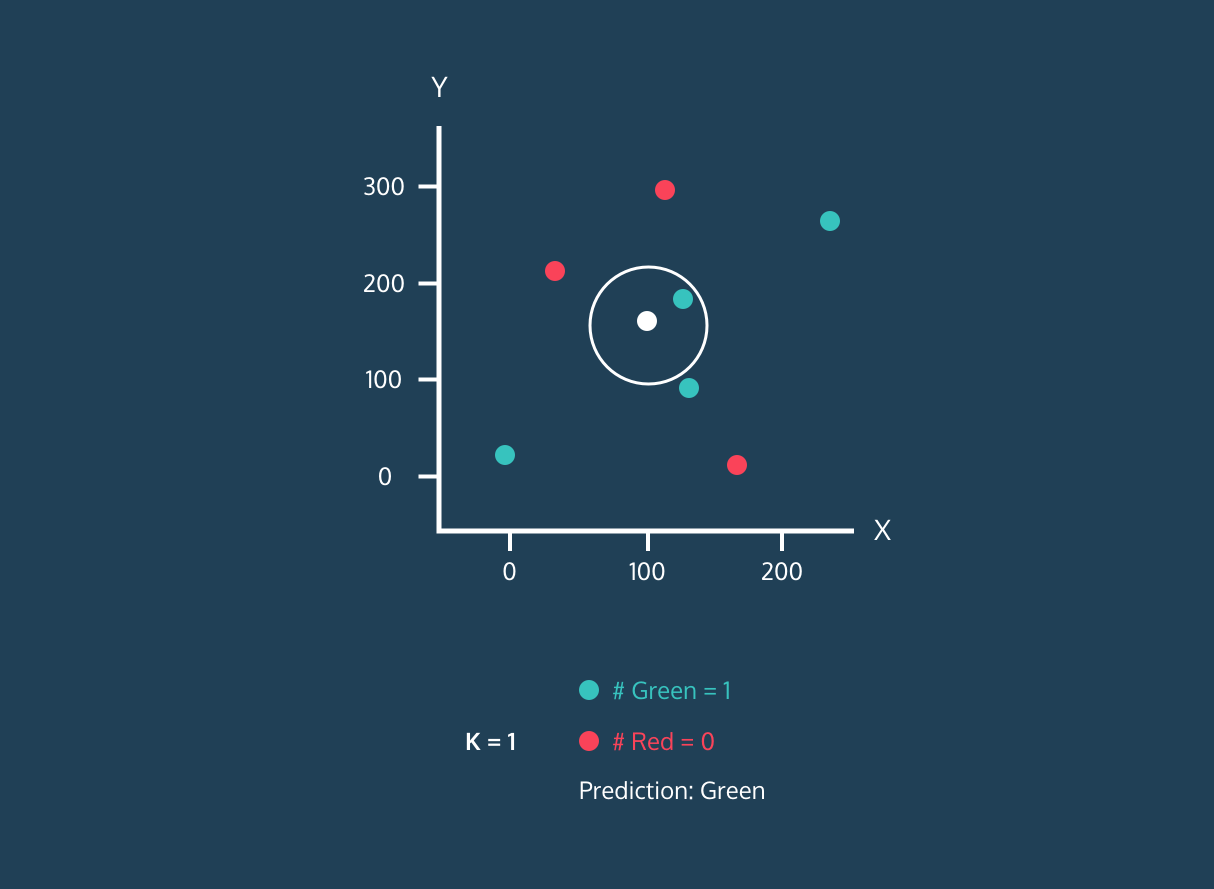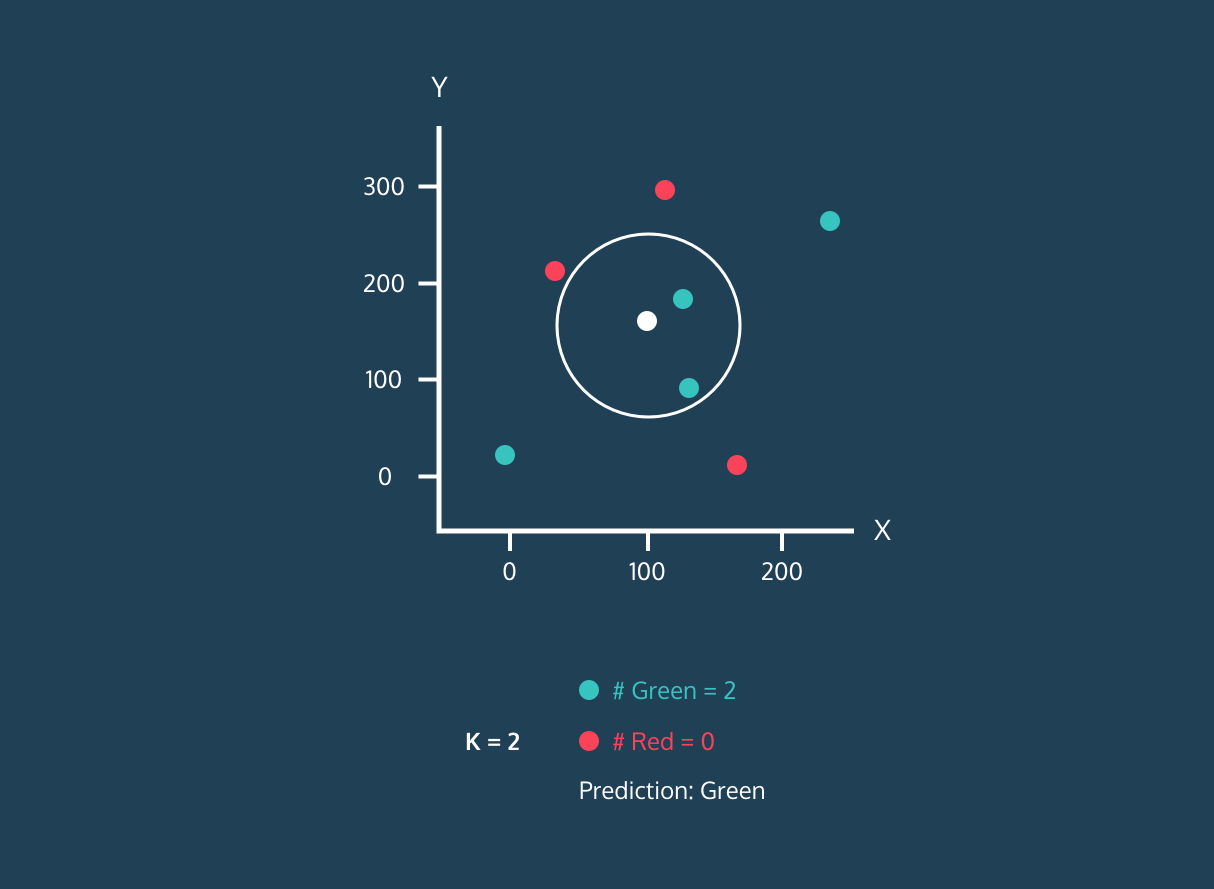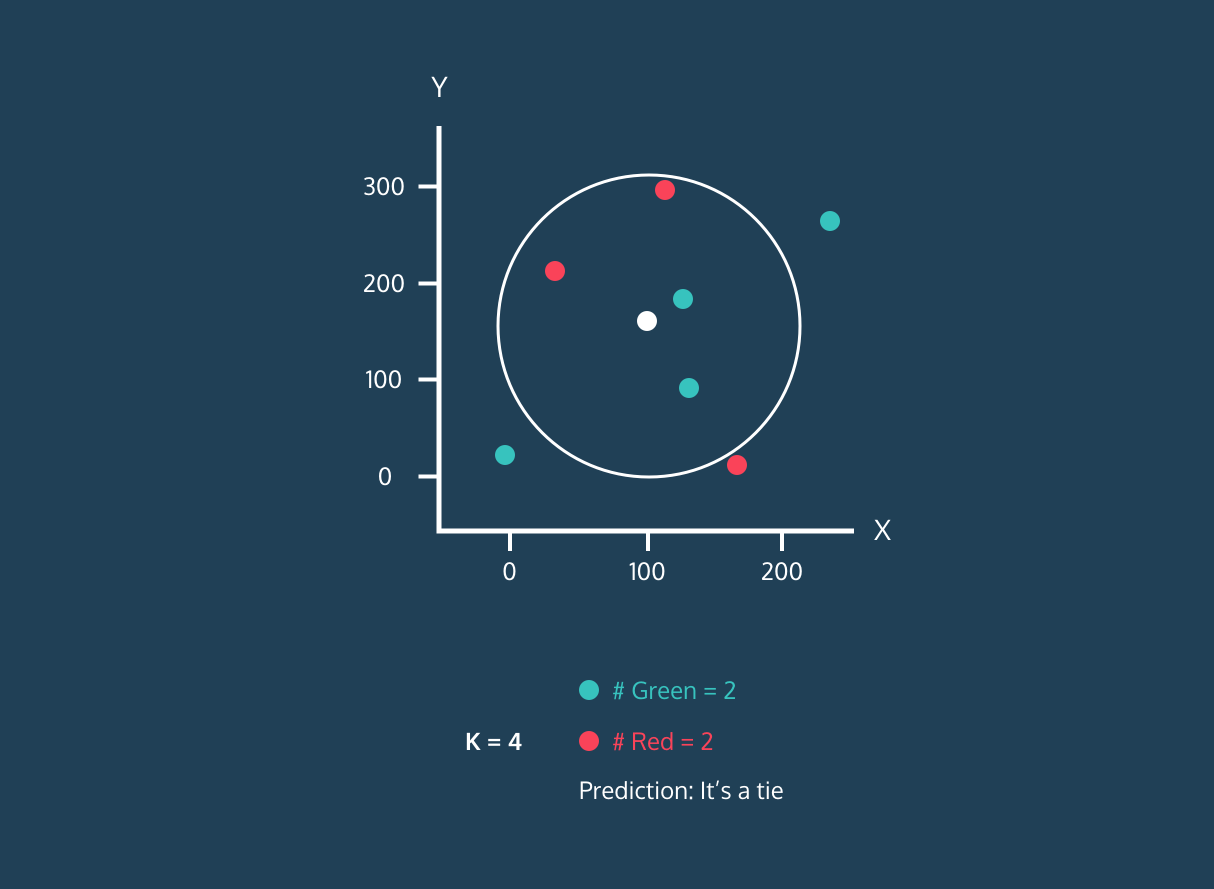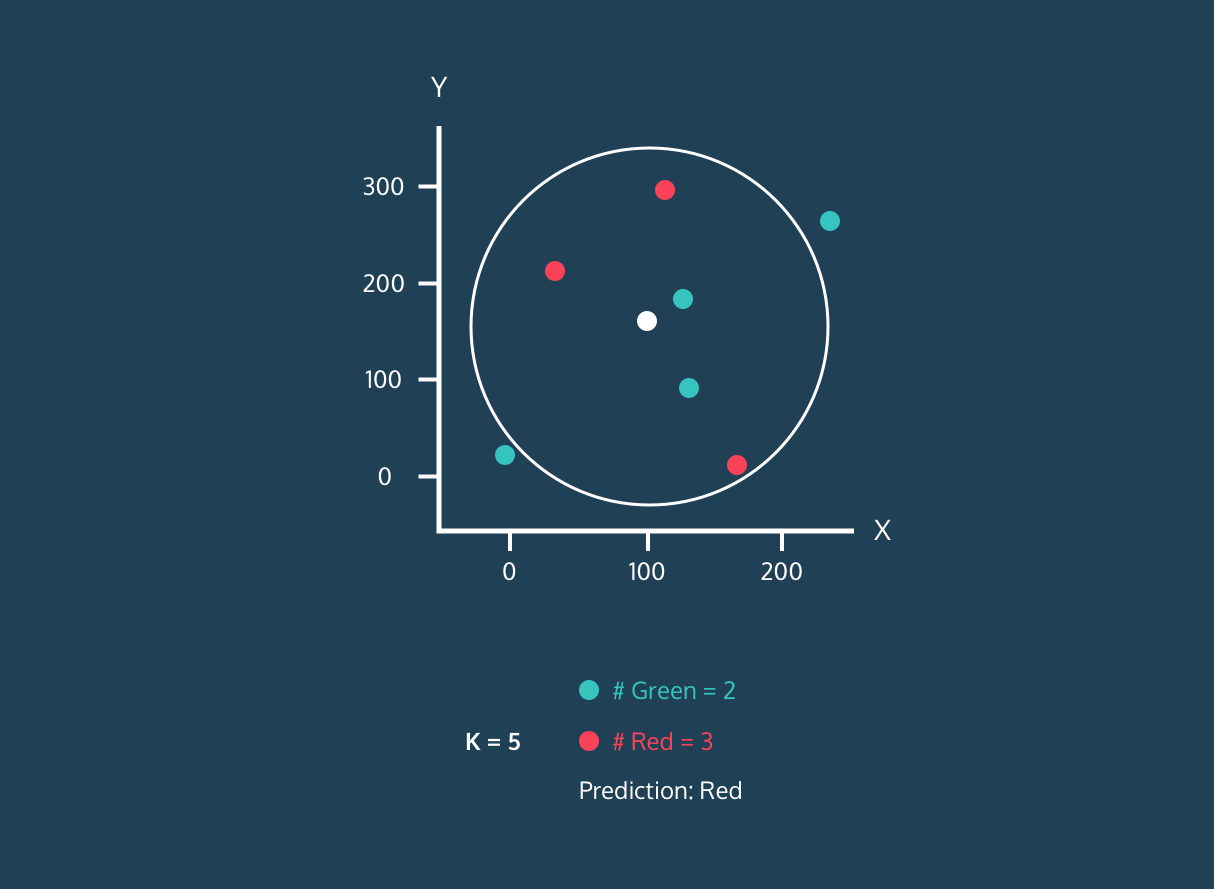
Gif de eunsukim.me
Resumo:
- Escolheremos o valor de K, que é o número de vizinhos mais próximos que serão usados para fazer a previsão.
- Calcule a distância entre esse ponto e todos os pontos do conjunto de treinamento.
- Selecione os K vizinhos mais próximos com base nas distâncias calculadas.
- Atribua o rótulo da classe majoritária ao novo ponto de dados.
- Repita as etapas 2 a 4 para todos os pontos de dados no conjunto de teste.
- Avalie a precisão do algoritmo.
O valor de "K" é fornecido pelo usuário e pode ser usado para otimizar o desempenho do algoritmo. Valores menores de K podem levar a um ajuste excessivo, e valores maiores podem levar a um ajuste insuficiente. Portanto, é fundamental encontrar valores ideais que proporcionem estabilidade e o melhor ajuste.
Implementação do KNN em R
Nesta seção, usaremos os dados de empréstimo e treinaremos a classificação KNN usando o pacote class. O conjunto de dados consiste em 10.000 empréstimos, e descobriremos se um empréstimo será pago com base nos dados do cliente.
Carregando os dados
Importaremos a biblioteca tidyverse para acessar pacotes essenciais do R para carregamento, manipulação e visualização de dados. O site suppressPackageStartupMessages suprimirá os avisos e você obterá uma saída limpa.
Depois disso, usaremos o site read_csv para carregar o conjunto de dados, remover a coluna "purpose" do dataframe usando a função subset e exibir as três principais amostras.
suppressPackageStartupMessages(library(tidyverse))
data <- read_csv('data/loans.csv.gz', show_col_types = FALSE)
data <- subset(data, select = -c(purpose))
head(data,3)
Treinamento e teste de divisão
Podemos dividir o conjunto de dados manualmente, mas usar a biblioteca caTools é muito mais limpo.
- Definir sementes para reprodutibilidade.
- Use o site
sample.splitpara criar um índice para conjuntos de dados de treinamento e teste em uma proporção de 75:25. - Use o site
subsetpara criar um conjunto de dados de treinamento e teste, conforme mostrado abaixo.
library(caTools)
set.seed(255)
split = sample.split(data$not_fully_paid,
SplitRatio = 0.75)
train = subset(data,
split == TRUE)
test = subset(data,
split == FALSE)Dimensionamento de recursos
Agora, dimensionaremos o conjunto de treinamento e de teste. No back-end, a função está usando (x - mean(x)) / sd(x). Estamos apenas dimensionando os recursos e removendo os rótulos de destino dos conjuntos de teste e treinamento.
train_scaled = scale(train[-13])
test_scaled = scale(test[-13])Treinamento do classificador KNN e previsão
A biblioteca class é bastante popular para treinar a classificação KNN. É simples e rápido. Forneceremos um conjunto de dados de treinamento e teste em escala, uma coluna de destino e um hiperparâmetro "k".
library(class)
test_pred <- knn(
train = train_scaled,
test = test_scaled,
cl = train$not_fully_paid,
k=10
)Avaliação do modelo
Para avaliar os resultados do modelo, exibiremos uma matriz de confusão usando a função table. Fornecemos rótulos reais (alvo de teste) e previstos para a função table e, como podemos ver, temos resultados muito bons para a classe majoritária.
O algoritmo KNN não é bom para lidar com dados desequilibrados, e é por isso que vemos um desempenho ruim em classes minoritárias.
actual <- test$not_fully_paid
cm <- table(actual,test_pred)
cm test_pred
actual 0 1
0 1988 23
1 373 10Podemos calcular a precisão somando os valores positivos verdadeiros da matriz de confusão e dividindo-os pelo comprimento total das colunas de destino.
Como podemos observar, temos boa precisão em um modelo vanilla. Podemos melhorar essa precisão ajustando o hiperparâmetro "K" e equilibrando o conjunto de dados.
accuracy <- sum(diag(cm))/length(actual)
sprintf("Accuracy: %.2f%%", accuracy*100)'Accuracy: 83.46%'Classificação KNN em R usando caret
Nesta seção, usaremos caret para tudo. caret é um pacote R para criar e avaliar modelos de aprendizado de máquina. Ele fornece uma interface para os principais algoritmos de aprendizado de máquina.
Nós o usaremos para dividir e pré-processar o conjunto de dados, realizar o ajuste de hiperparâmetros e treinar e avaliar modelos.
Treinamento e teste de divisão
Importaremos o pacote caret e definiremos a semente para reprodutibilidade. Depois disso, converteremos a variável de destino de um número inteiro para um fator. No final, usaremos o site createDataPartition para dividir o conjunto de dados em conjuntos de dados de treinamento e teste usando uma proporção de 80:20.
suppressPackageStartupMessages(library(caret))
set.seed(255)
data$not_fully_paid <- factor(data$not_fully_paid, levels = c(0, 1))
trainIndex <- createDataPartition(data$not_fully_paid,
times=1,
p = .8,
list = FALSE)
train <- data[trainIndex, ]
test <- data[-trainIndex, ]Pré-processamento de dados
Em seguida, dimensionaremos o conjunto de treinamento e teste usando a função preProcess.
preProcValues <- preProcess(train, method = c("center", "scale"))
trainTransformed <- predict(preProcValues, train)
testTransformed <- predict(preProcValues, test)Ajuste de modelo
Antes de treinarmos nosso modelo KNN, precisamos encontrar o valor ideal de "K" usando a função de treinamento. A função train requer uma fórmula, um conjunto de dados de treinamento em escala, o nome do modelo, o método de controle de treinamento (validação cruzada) e uma lista de hiperparâmetros. Vamos verificar o desempenho do modelo quando "K" for 3, 5 e 7.
knnModel <- train(
not_fully_paid ~ .,
data = trainTransformed,
method = "knn",
trControl = trainControl(method = "cv"),
tuneGrid = data.frame(k = c(3,5,7))
)Treinamento do modelo de melhor desempenho
Depois de encontrar o melhor valor de "K", treinaremos o modelo de classificação KNN com um conjunto de dados de treinamento em escala.
best_model<- knn3(
not_fully_paid ~ .,
data = trainTransformed,
k = knnModel$bestTune$k
)Avaliação do modelo
O caret oferece uma função de avaliação de modelo simples e avançada. Para exibir os resultados de desempenho do modelo, primeiro precisamos prever rótulos para o conjunto de dados de teste não visto. Depois disso, usaremos os valores previstos e reais para avaliar o desempenho do modelo usando a função confusionMatrix .
predictions <- predict(best_model, testTransformed,type = "class")
# Calculate confusion matrix
cm <- confusionMatrix(predictions, testTransformed$not_fully_paid)
cmComo resultado, obtemos a matriz de confusão, a precisão do modelo, o valor P, a sensibilidade do modelo e outras métricas importantes que nos ajudarão a determinar a estabilidade e o desempenho do modelo.
Como podemos ver, o modelo teve um desempenho muito ruim em "Neg Pred Value", que é uma classe minoritária, e nossa precisão equilibrada é de 51%. Podemos obter um resultado semelhante com o lançamento de uma moeda.
Podemos melhorar o resultado equilibrando as classes usando os métodos de sobreamostragem e subamostragem. Também podemos realizar a engenharia de recursos, criar novos recursos e eliminar recursos altamente correlacionados.
Confusion Matrix and Statistics
Reference
Prediction 0 1
0 1570 288
1 39 18
Accuracy : 0.8292
95% CI : (0.8116, 0.8458)
No Information Rate : 0.8402
P-Value [Acc > NIR] : 0.9091
Kappa : 0.0516
Mcnemar's Test P-Value : <2e-16
Sensitivity : 0.97576
Specificity : 0.05882
Pos Pred Value : 0.84499
Neg Pred Value : 0.31579
Prevalence : 0.84021
Detection Rate : 0.81984
Detection Prevalence : 0.97023
Balanced Accuracy : 0.51729
'Positive' Class : 0Também podemos simplificar nosso resultado exibindo-o como um quadro de dados.
data.frame(Accuracy = cm$overall["Accuracy"],
Sensitivity = cm$byClass["Sensitivity"],
Specificity = cm$byClass["Specificity"])
Se você gosta de Python e quer aprender a realizar a classificação KNN, leia nosso tutorial K-Nearest Neighbors (KNN) Classification with scikit-learn para entender os conceitos de KNN e o fluxo de trabalho com exemplos.
Vantagens e desvantagens do uso do KNN
Vantagens
- É um algoritmo simples de entender e implementar.
- Ele é versátil e pode ser usado para tarefas de regressão e classificação.
- Ele fornece resultados interpretáveis que podem ser visualizados e compreendidos, pois a classe prevista é baseada nos rótulos dos vizinhos mais próximos nos dados de treinamento.
- O KNN não faz suposições sobre o limite de decisão entre as classes, e esse recurso permite que ele capture relações não lineares entre os recursos.
- O algoritmo não faz suposições sobre a distribuição dos dados, o que o torna adequado para uma ampla gama de problemas.
- O KNN não constrói o modelo. Ele armazena os dados de treinamento e os utiliza para a previsão.
Disadvantages
- Ele é caro em termos de computação e memória para conjuntos de dados grandes e complexos.
- O desempenho do KNN cai para dados desequilibrados. Ele mostra preconceitos em relação à classe majoritária, o que pode resultar em desempenho ruim para as classes minoritárias.
- Não é adequado para dados com ruído. Como os vizinhos mais próximos de um ponto de dados podem não ser representativos do rótulo da classe verdadeira.
- Ele não é adequado para dados de alta dimensão, pois a alta dimensionalidade pode fazer com que a distância entre todos os pontos de dados se torne semelhante.
- Encontrar o número ideal de K vizinhos pode ser demorado.
- O KNN é sensível a outliers, pois escolhe vizinhos com base na métrica de evidência.
- Ele não é bom para lidar com valores ausentes no conjunto de dados de treinamento.
Conclusão
Neste tutorial, aprendemos a usar a classificação K-Nearest Neighbors (KNN) com o R. Abordamos o conceito básico de KNN e como ele funciona. Além disso, aprendemos sobre duas bibliotecas, class e caret, para treinar e avaliar modelos de classificação KNN em um conjunto de dados real.
Acesse Aprendizagem supervisionada em R: Classificação curso para aprender sobre outros algoritmos de aprendizado de máquina supervisionados com programação R. Você aprenderá sobre Naive Bayes, Regressão Logística e Árvores de Classificação com exemplos e exercícios de código.
Os tutoriais em R envolvem etapas para manipulação, divisão e processamento do conjunto de dados, ajuste de hiperparâmetros, treinamento dos modelos e avaliação dos resultados. Devido a um conjunto de dados desequilibrado, obtivemos o pior desempenho na classe minoritária.
Você precisa entender que o algoritmo KNN não é perfeito, ele também tem algumas desvantagens, e é preciso levar em conta vários aspectos antes de selecioná-lo como modelo principal.
