R ist ein leistungsstarkes Werkzeug für die Implementierung der KNN-Klassifizierung und wird von Datenwissenschaftlern und Statistikern für verschiedene Machine-Learning-Anwendungen verwendet.
In diesem Tutorium lernen wir die K-Nächsten Nachbarn kennen, wie sie funktionieren und welche Vor- und Nachteile sie haben. Außerdem werden wir das R-Paket "class" und "caret" verwenden, um das KNN-Klassifizierungsmodell einfach zu implementieren.
Was sind K-Nächste Nachbarn?
K-Nearest Neighbors (KNN) ist ein überwachtes maschinelles Lernmodell, das sowohl für Regressions- als auch für Klassifizierungsaufgaben verwendet werden kann. Der Algorithmus ist nicht parametrisch, das heißt, er macht keine Annahmen über die zugrunde liegende Verteilung der Daten.
Der KNN-Algorithmus sagt die Kennzeichnungen des Testdatensatzes voraus, indem er die Kennzeichnungen der nächsten Nachbarn im Merkmalsraum des Trainingsdatensatzes betrachtet. K" ist der wichtigste Hyperparameter, der zur Optimierung der Leistung des Modells eingestellt werden kann.
KNN ist ein einfacher und intuitiver Algorithmus, der bei einer Vielzahl von Klassifizierungsproblemen gute Ergebnisse liefert. Es ist einfach zu implementieren und zu verstehen und gilt sowohl für kleine als auch für große Datensätze. Sie hat jedoch auch einige Nachteile. Der größte Nachteil ist, dass sie für große Datensätze oder hochdimensionale Merkmalsräume rechenintensiv sein kann.
Der KNN-Algorithmus wird in E-Commerce-Empfehlungsmaschinen, der Bilderkennung, der Betrugserkennung, der Textklassifizierung, der Erkennung von Anomalien und vielem mehr eingesetzt. In diesem Lernprogramm werden wir den KNN-Algorithmus für ein Kreditgenehmigungssystem verwenden.
Wenn du verwirrt bist und nicht weißt, wie du deine Reise in die Datenwissenschaften beginnen sollst, nimm den Lernpfad Data Scientist Professional with R und bereite dich auf eine erfolgreiche Karriere in den Datenwissenschaften vor. Der Lernpfad hilft dir, R-Programmierung, Dateneingabe, Datenbereinigung, Datenmanipulation, Datenvisualisierung, maschinelles Lernen, Hypothesentests, Versuchspläne, SQL und Git zu beherrschen.
Wie funktioniert die K-Nearest Neighbors-Klassifizierung?
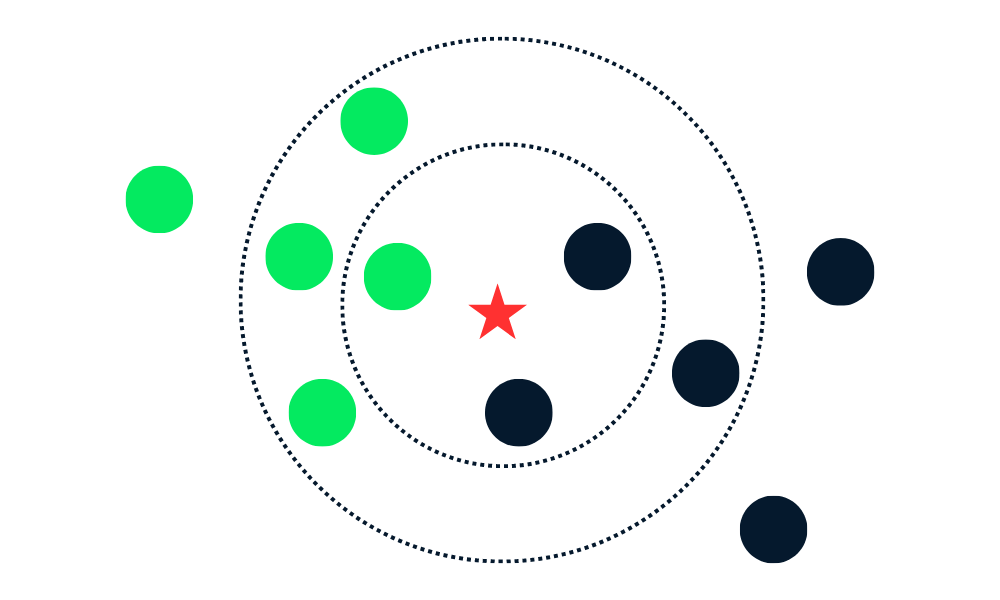
Der KNN-Klassifizierungsalgorithmus funktioniert, indem er K Nachbarn (nächstgelegene Datenpunkte) im Trainingsdatensatz zu einem neuen Datenpunkt findet. Dann ordnet es den neuen Datenpunkten das Label der Mehrheitsklasse unter den Nachbarn zu.
Lass uns die Algorithmen in mehrere Teile aufteilen.
Zuerst wird der Abstand zwischen den neuen Datenpunkten und allen anderen Datenpunkten im Trainingssatz berechnet und die K nächstliegenden Punkte ausgewählt. Die Metrik, die zur Berechnung der Entfernung verwendet wird, kann je nach Problemstellung variieren. Die am häufigsten verwendete Metrik ist der euklidische Abstand.
Nachdem er die K nächsten Nachbarn ermittelt hat, weist der Algorithmus dem neuen Datenpunkt das Label der Mehrheitsklasse unter diesen Nachbarn zu. Wenn zum Beispiel zwei Labels "blau" und ein Label "rot" sind, weist der Algorithmus das Label "blau" einem neuen Datenpunkt zu.
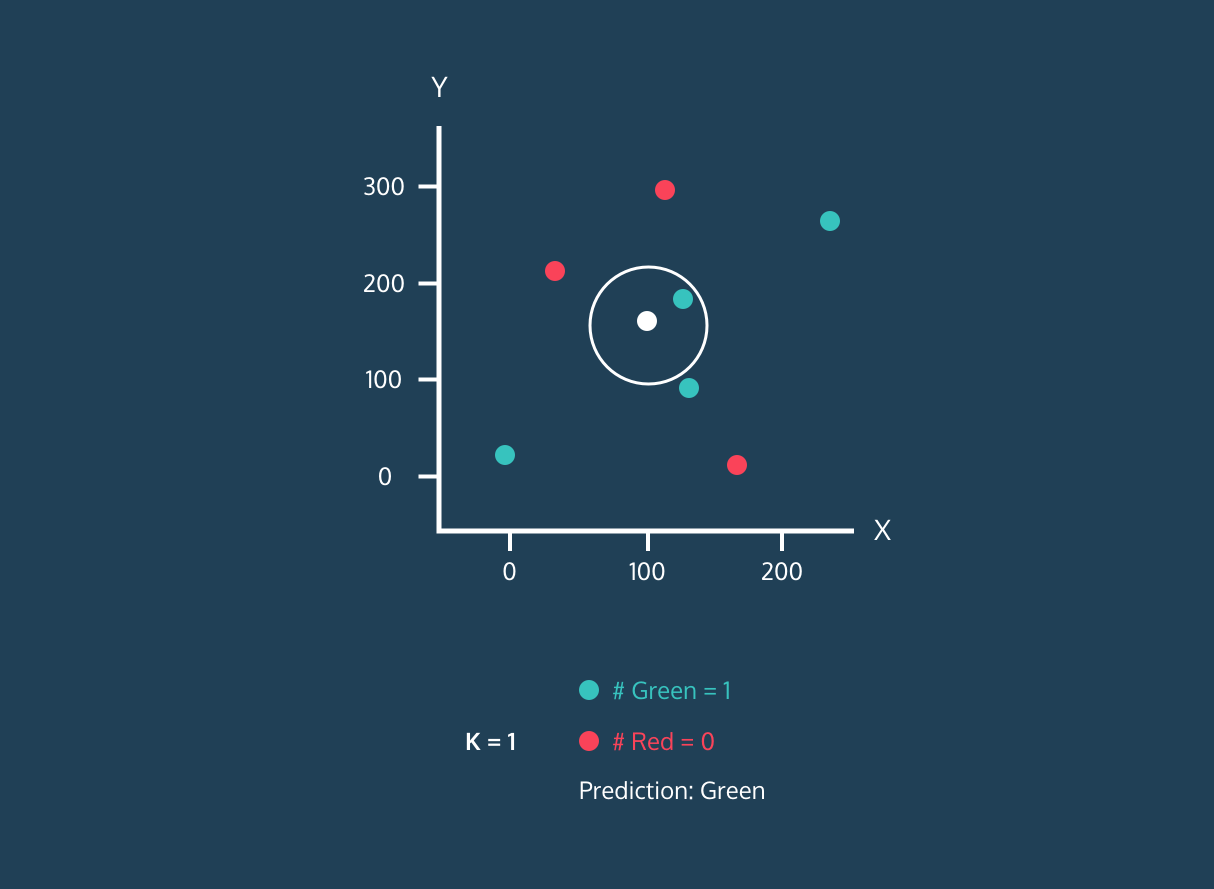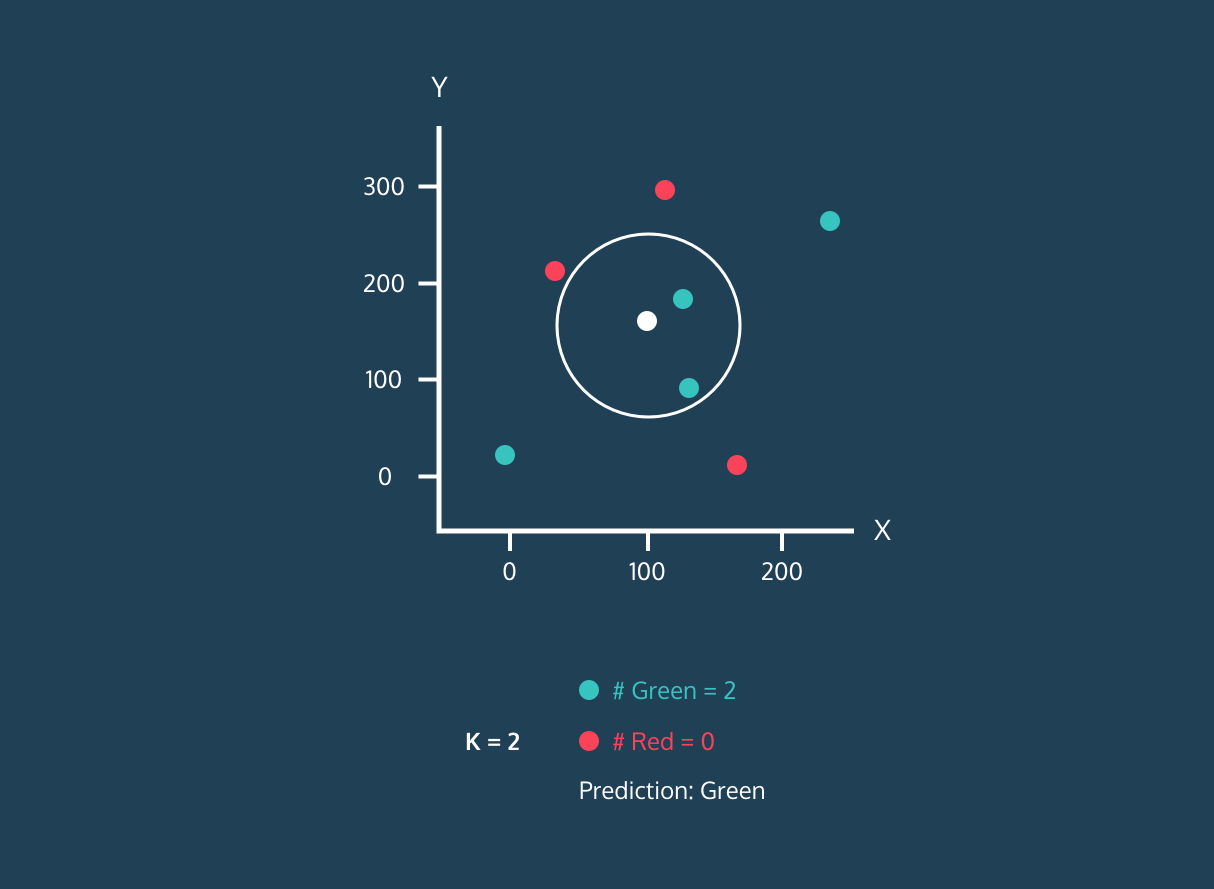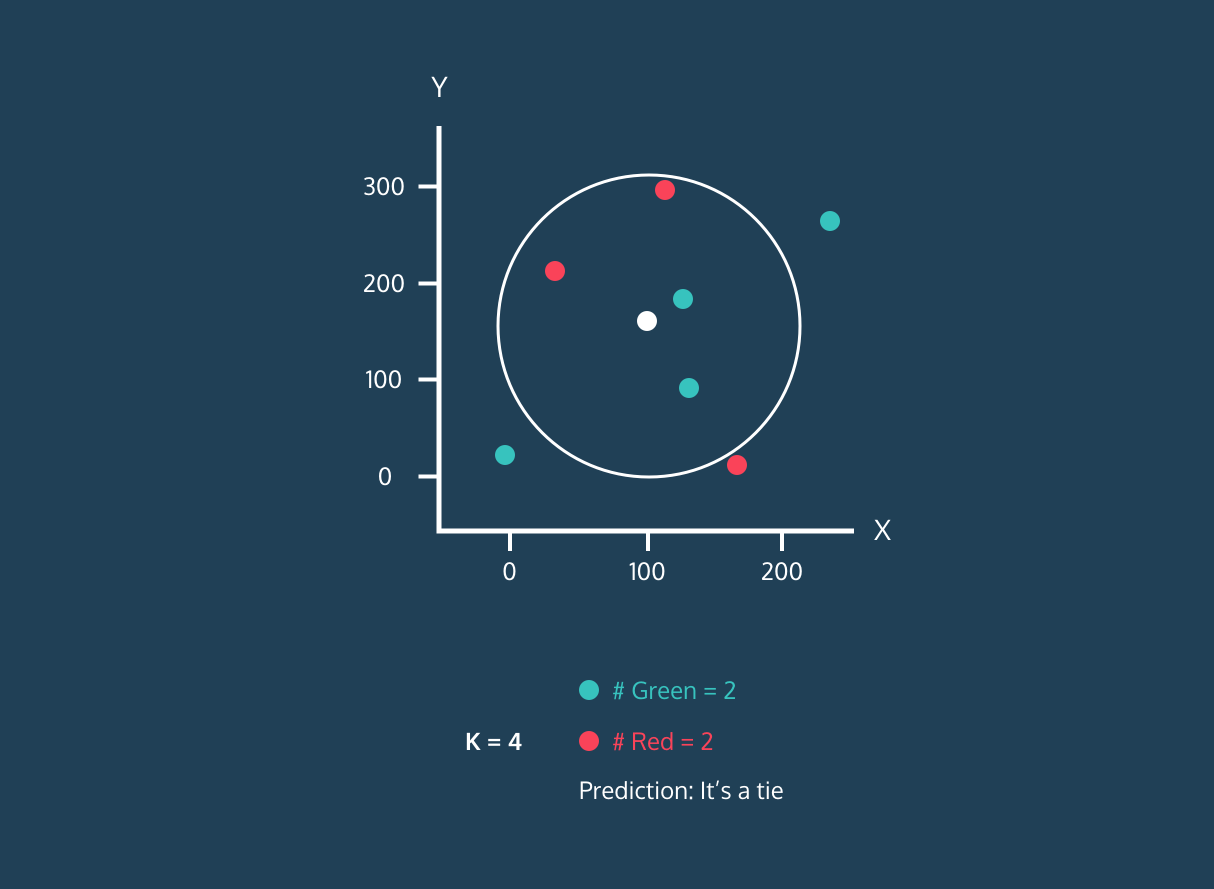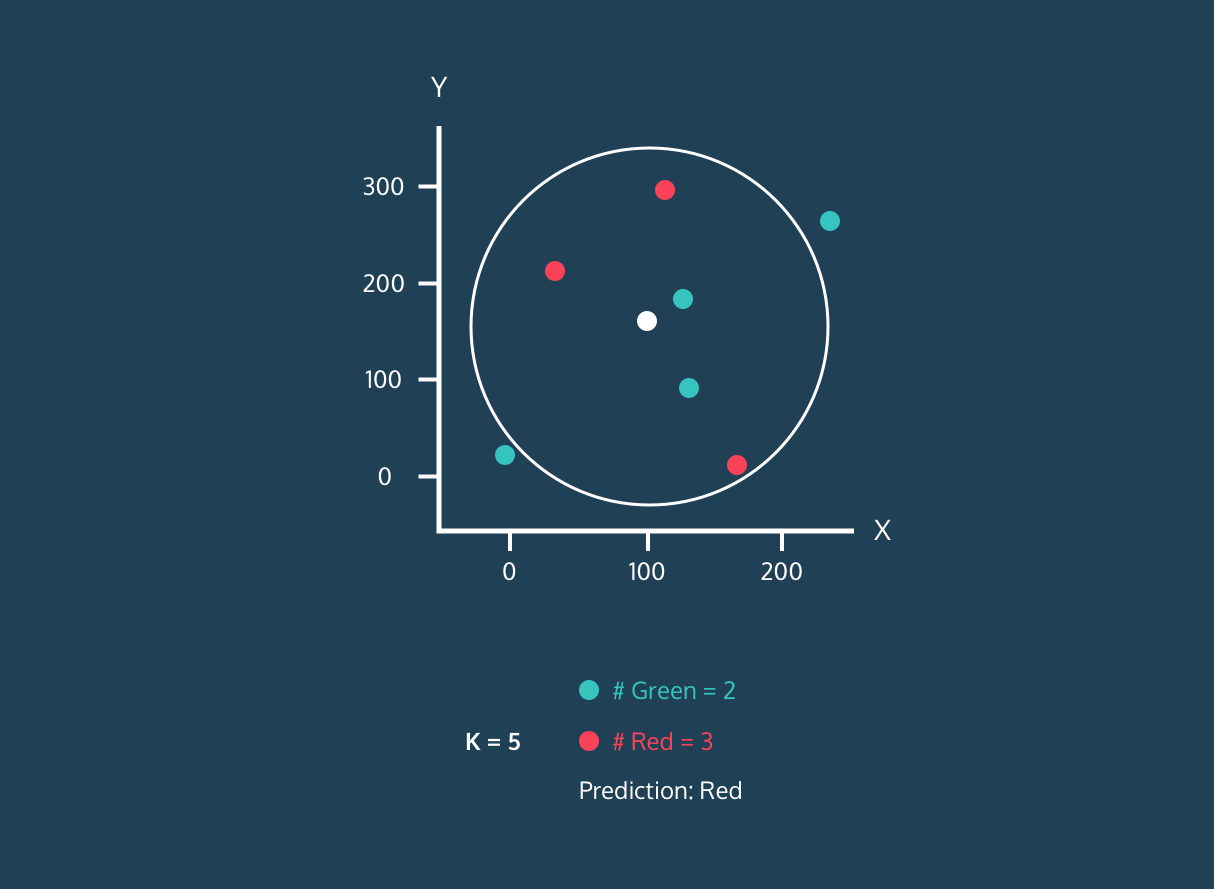
Gif von eunsukim.me
Zusammenfassung:
- Wir wählen den Wert von K, der die Anzahl der nächsten Nachbarn angibt, die für die Vorhersage verwendet werden.
- Berechne den Abstand zwischen diesem Punkt und allen Punkten in der Trainingsmenge.
- Wähle die K nächsten Nachbarn basierend auf den berechneten Entfernungen.
- Weise dem neuen Datenpunkt die Bezeichnung der Mehrheitsklasse zu.
- Wiederhole die Schritte 2 bis 4 für alle Datenpunkte im Testsatz.
- Beurteile die Genauigkeit des Algorithmus.
Der Wert von "K" wird vom Benutzer festgelegt und kann zur Optimierung der Leistung des Algorithmus verwendet werden. Kleinere K-Werte können zu einer Überanpassung und größere Werte zu einer Unteranpassung führen. Deshalb ist es wichtig, optimale Werte zu finden, die Stabilität und die beste Passform bieten.
Implementierung von KNN in R
In diesem Abschnitt verwenden wir Darlehensdaten und trainieren die KNN-Klassifizierung mit dem Paket class. Der Datensatz besteht aus 10.000 Krediten, und wir werden anhand der Daten des Kunden herausfinden, ob ein Kredit zurückgezahlt wird.
Laden der Daten
Wir werden die tidyverse Bibliothek importieren, um auf wichtige R-Pakete für das Laden, die Manipulation und die Visualisierung von Daten zuzugreifen. Die suppressPackageStartupMessages wird die Warnungen unterdrücken und du bekommst eine saubere Ausgabe.
Danach laden wir mit read_csv den Datensatz, entfernen mit der Funktion subset die Spalte "Zweck" aus dem DataFrame und zeigen die 3 besten Beispiele an.
suppressPackageStartupMessages(library(tidyverse))
data <- read_csv('data/loans.csv.gz', show_col_types = FALSE)
data <- subset(data, select = -c(purpose))
head(data,3)
Split trainieren und testen
Wir können den Datensatz manuell aufteilen, aber die caTools Bibliothek ist viel sauberer.
- Setze Samen für die Reproduzierbarkeit.
- Verwende
sample.split, um einen Index für Trainings- und Testdatensätze in einem Verhältnis von 75:25 zu erstellen. - Verwende
subset, um einen Trainings- und einen Testdatensatz zu erstellen, wie unten gezeigt.
library(caTools)
set.seed(255)
split = sample.split(data$not_fully_paid,
SplitRatio = 0.75)
train = subset(data,
split == TRUE)
test = subset(data,
split == FALSE)Merkmal Skalierung
Wir skalieren nun sowohl das Trainings- als auch das Testset. Am Backend verwendet die Funktion (x - mean(x)) / sd(x). Wir skalieren nur die Merkmale und entfernen die Zielbeschriftungen sowohl aus den Test- als auch aus den Trainingsmengen.
train_scaled = scale(train[-13])
test_scaled = scale(test[-13])KNN-Klassifikator trainieren und vorhersagen
Die Bibliothek class ist sehr beliebt für das Training der KNN-Klassifizierung. Es ist einfach und schnell. Wir stellen einen skalierten Trainings- und Testdatensatz, eine Zielspalte und den Hyperparameter "k" zur Verfügung.
library(class)
test_pred <- knn(
train = train_scaled,
test = test_scaled,
cl = train$not_fully_paid,
k=10
)Modellbewertung
Um die Ergebnisse des Modells zu bewerten, werden wir eine Konfusionsmatrix mit Hilfe der Funktion table anzeigen. Wir haben die Funktion table mit tatsächlichen (Testziel) und vorhergesagten Bezeichnungen versehen, und wie wir sehen können, haben wir recht gute Ergebnisse für die Mehrheitsklasse.
Der KNN-Algorithmus ist nicht gut darin, mit unausgewogenen Daten umzugehen, und das ist der Grund, warum wir eine schlechte Leistung in Minderheitsklassen sehen.
actual <- test$not_fully_paid
cm <- table(actual,test_pred)
cm test_pred
actual 0 1
0 1988 23
1 373 10Wir können die Genauigkeit berechnen, indem wir die wahren positiven Werte aus der Konfusionsmatrix zusammenzählen und durch die Gesamtlänge der Zielspalten dividieren.
Wie wir sehen können, haben wir eine gute Genauigkeit bei einem Vanillemodell. Wir können diese Genauigkeit verbessern, indem wir den Hyperparameter "K" anpassen und den Datensatz ausbalancieren.
accuracy <- sum(diag(cm))/length(actual)
sprintf("Accuracy: %.2f%%", accuracy*100)'Accuracy: 83.46%'KNN-Klassifizierung in R mit Caret
In diesem Abschnitt werden wir für alles caret verwenden. caret ist ein R-Paket zum Erstellen und Auswerten von Machine-Learning-Modellen. Es bietet eine Schnittstelle für die wichtigsten Algorithmen des maschinellen Lernens.
Wir werden sie nutzen, um den Datensatz aufzuteilen und vorzuverarbeiten, die Hyperparameter abzustimmen und die Modelle zu trainieren und zu bewerten.
Split trainieren und testen
Wir werden das caret Paket importieren und den Seed für die Reproduzierbarkeit setzen. Danach wandeln wir die Zielvariable von einer Ganzzahl in einen Faktor um. Am Ende werden wir createDataPartition verwenden, um den Datensatz im Verhältnis 80:20 in Trainings- und Testdatensätze aufzuteilen.
suppressPackageStartupMessages(library(caret))
set.seed(255)
data$not_fully_paid <- factor(data$not_fully_paid, levels = c(0, 1))
trainIndex <- createDataPartition(data$not_fully_paid,
times=1,
p = .8,
list = FALSE)
train <- data[trainIndex, ]
test <- data[-trainIndex, ]Datenvorverarbeitung
Anschließend skalieren wir sowohl die Trainings- als auch die Testmenge mit der Funktion preProcess.
preProcValues <- preProcess(train, method = c("center", "scale"))
trainTransformed <- predict(preProcValues, train)
testTransformed <- predict(preProcValues, test)Model Tuning
Bevor wir unser KNN-Modell trainieren, müssen wir mithilfe der Trainingsfunktion den optimalen Wert von "K" finden. Die train-Funktion erfordert eine Formel, einen skalierten Trainingsdatensatz, den Modellnamen, die train-Kontrollmethode (Kreuzvalidierung) und eine Liste von Hyperparametern. Wir werden die Leistung des Modells überprüfen, wenn "K" 3, 5 und 7 ist.
knnModel <- train(
not_fully_paid ~ .,
data = trainTransformed,
method = "knn",
trControl = trainControl(method = "cv"),
tuneGrid = data.frame(k = c(3,5,7))
)Ausbildung des leistungsstärksten Modells
Nachdem wir den besten Wert für "K" gefunden haben, trainieren wir das KNN-Klassifizierungsmodell mit einem skalierten Trainingsdatensatz.
best_model<- knn3(
not_fully_paid ~ .,
data = trainTransformed,
k = knnModel$bestTune$k
)Modellbewertung
caret bietet eine einfache und leistungsstarke Funktion zur Modellbewertung. Um die Leistungsergebnisse des Modells zu zeigen, müssen wir zunächst Labels für den ungesehenen Testdatensatz vorhersagen. Anschließend verwenden wir die vorhergesagten und tatsächlichen Werte, um die Leistung des Modells mit der Funktion confusionMatrix zu bewerten.
predictions <- predict(best_model, testTransformed,type = "class")
# Calculate confusion matrix
cm <- confusionMatrix(predictions, testTransformed$not_fully_paid)
cmAls Ergebnis erhalten wir die Konfusionsmatrix, die Modellgenauigkeit, den P-Wert, die Modellsensitivität und andere wichtige Metriken, die uns helfen, die Stabilität und Leistung des Modells zu bestimmen.
Wie wir sehen können, hat das Modell bei "Neg Pred Value", einer Minderheitenklasse, ziemlich schlecht abgeschnitten, und unsere ausgeglichene Genauigkeit liegt bei 51 %. Wir können ein ähnliches Ergebnis mit dem Münzwurf erzielen.
Wir können das Ergebnis verbessern, indem wir die Klassen mit Oversampling- und Undersampling-Methoden ausgleichen. Wir können auch Feature-Engineering betreiben und neue Features erstellen und stark korrelierte Features löschen.
Confusion Matrix and Statistics
Reference
Prediction 0 1
0 1570 288
1 39 18
Accuracy : 0.8292
95% CI : (0.8116, 0.8458)
No Information Rate : 0.8402
P-Value [Acc > NIR] : 0.9091
Kappa : 0.0516
Mcnemar's Test P-Value : <2e-16
Sensitivity : 0.97576
Specificity : 0.05882
Pos Pred Value : 0.84499
Neg Pred Value : 0.31579
Prevalence : 0.84021
Detection Rate : 0.81984
Detection Prevalence : 0.97023
Balanced Accuracy : 0.51729
'Positive' Class : 0Wir können unser Ergebnis auch vereinfachen, indem wir es als Datenrahmen anzeigen lassen.
data.frame(Accuracy = cm$overall["Accuracy"],
Sensitivity = cm$byClass["Sensitivity"],
Specificity = cm$byClass["Specificity"])
Wenn du Python liebst und lernen willst, wie man eine KNN-Klassifizierung durchführt, lies unser K-Nearest Neighbors (KNN)-Klassifizierungstutorial mit scikit-learn, um die KNN-Konzepte und den Arbeitsablauf anhand von Beispielen zu verstehen.
Vorteile und Nachteile der Verwendung von KNN
Vorteile
- Es ist ein einfacher Algorithmus, der leicht zu verstehen und umzusetzen ist.
- Sie ist vielseitig und kann sowohl für Regressions- als auch für Klassifizierungsaufgaben verwendet werden.
- Sie liefert interpretierbare Ergebnisse, die visualisiert und verstanden werden können, da die vorhergesagte Klasse auf den Bezeichnungen der nächsten Nachbarn in den Trainingsdaten basiert.
- KNN macht keine Annahmen über die Entscheidungsgrenze zwischen den Klassen und kann daher auch nichtlineare Beziehungen zwischen den Merkmalen erfassen.
- Der Algorithmus macht keine Annahmen über die Verteilung der Daten, wodurch er sich für eine Vielzahl von Problemen eignet.
- KNN erstellt das Modell nicht. Es speichert die Trainingsdaten und nutzt sie für die Vorhersage.
Benachteiligungen
- Bei großen und komplexen Datensätzen ist es rechen- und speicherintensiv.
- Die KNN-Leistung sinkt bei unausgewogenen Daten. Sie zeigt eine Voreingenommenheit gegenüber der Mehrheitsklasse, was zu schlechten Leistungen von Minderheitsklassen führen kann.
- Sie ist nicht für verrauschte Daten geeignet. Da die nächsten Nachbarn eines Datenpunktes möglicherweise nicht repräsentativ für die wahre Klassenbezeichnung sind.
- Sie eignet sich nicht für hochdimensionale Daten, da die hohe Dimensionalität dazu führen kann, dass der Abstand zwischen allen Datenpunkten ähnlich wird.
- Die Suche nach der optimalen Anzahl von K Nachbarn kann zeitaufwändig sein.
- KNN ist empfindlich gegenüber Ausreißern, da es die Nachbarn anhand der Evidenzmetrik auswählt.
- Es ist nicht gut darin, fehlende Werte im Trainingsdatensatz zu verarbeiten.
Fazit
In diesem Tutorial haben wir gelernt, wie man die K-Nächste-Nachbarn-Klassifizierung (KNN) mit R anwendet. Wir haben das grundlegende Konzept von KNN und seine Funktionsweise behandelt. Außerdem haben wir zwei Bibliotheken kennengelernt, class und caret, mit denen wir KNN-Klassifizierungsmodelle auf einem realen Datensatz trainieren und evaluieren können.
Nimm an der Supervised Learning in R teil: Klassifizierung, um andere überwachte Algorithmen für maschinelles Lernen mit R-Programmierung kennenzulernen. Du lernst Naive Bayes, Logistische Regression und Klassifikationsbäume anhand von Beispielen und Code-Übungen kennen.
Die R-Tutorials beinhalten Schritte zur Manipulation, zum Teilen und Verarbeiten des Datensatzes, zum Abstimmen der Hyperparameter, zum Trainieren der Modelle und zum Auswerten der Ergebnisse. Aufgrund eines unausgewogenen Datensatzes erzielten wir die schlechteste Leistung in der Minderheitenklasse.
Du musst verstehen, dass der KNN-Algorithmus nicht perfekt ist, er hat auch einige Nachteile, und wir müssen viele Dinge berücksichtigen, bevor wir ihn als primäres Modell auswählen.
