
Cours
Développement d'applications LLM avec LangChain
3 h
46.2K
LangChain est un réseau de frame open source permettant de créer des applications d'IA agentique qui combinent des LLM avec des outils. La version 1.0 marque le passage à un noyau de qualité production avec une API simplifiée, des limites plus claires et une gestion standardisée des messages entre les fournisseurs.
Dans ce tutoriel, nous allons créer un assistant Streamlit pour la synthèse automatique des réunions qui prend en charge les notes brutes, produit une synthèse concise accompagnée de mesures à prendre et, après validation humaine, ajoute la synthèse à un document Google Doc. Au cours de votre exploration, vous découvrirez le nouveau flux d'create_agent, les blocs de contenu standard et l'espace de noms v1 simplifié en action.
LangChain v1 est une version restructurée, orientée vers la production, axée sur une surface réduite et stable pour la création d'agents. Il présente :
create_agent comme méthode standard pour lancer des agents (plus propre que les agents pré-intégrés existants).
Contenu standardisé via content_blocks afin que les messages soient cohérents entre les différents fournisseurs.
Sortie structurée et intergiciel pour des réponses typées et des actions sécurisées et approuvées par l'utilisateur.
Le package langchain se concentre sur les composants de base des agents, de sorte que les modules existants sont transférés vers langchain-classic, ce qui facilite leur découverte et leur mise à niveau.
Par rapport à la version v0.x, la version v1 réduit la charge cognitive et les particularités des fournisseurs en normalisant le contenu des messages et l'orchestration des agents. Vous obtenez le même modèle mental, que vous utilisiez OpenAI, Anthropic ou d'autres.
La version originale Langchain v0.x proposait de nombreux modèles pour la création d'agents. Cependant, la version v1 les regroupe en une seule voie claire à l'aide d'un bloc d'create_agent, ce qui facilite la compréhension, le test et la livraison de vos agents. Il est fourni avec un outil de nettoyage, un débogage simplifié grâce à un contenu standardisé et une boucle d'agent prévisible.
Voici quelques améliorations techniques majeures qui ont été intégrées à cette dernière version :
create_agent processus de travail : Cette boucle d'agent prête pour la production permet au modèle de déterminer quand faire appel aux outils et quand terminer. Ainsi, nous n'avons plus à jongler avec plusieurs modèles, ce qui facilite la personnalisation.
Blocs de contenu standard : Une méthode indépendante du fournisseur pour lire les messages consiste à analyser les traces, les appels d'outils, les citations, voire les bits multimodaux, le tout via une API d'content_blocks s unifiée. Les outils et les journaux sont identiques chez tous les fournisseurs.
Sortie structurée : La dernière version offre une prise en charge de premier ordre des schémas typés, vous permettant ainsi de compter sur un JSON prévisible sans avoir recours à des expressions régulières complexes. Cela réduit les erreurs d'analyse et les appels supplémentaires.
Intergiciel : Ces éléments s'intègrent à la boucle de l'agent pour approuver les actions à risque, résumer l'historique lorsqu'il est long et expurger les informations personnelles identifiables avant les appels.
Espace de noms simplifié : Le package langchain se concentre désormais sur les composants essentiels des agents, tandis que LangGraph assure les fonctionnalités de fiabilité telles que la persistance et le voyage dans le temps en arrière-plan.
Dans cette section, nous allons mettre en œuvre une application Streamlit qui automatise les comptes rendus de réunion de bout en bout. L'application accepte les notes de réunion brutes ainsi que des métadonnées facultatives (titre, date et participants). Il génère ensuite un document structuré, comprenant le titre, le résumé, les décisions et les mesures à prendre, à partir de l'RecapDoc. D'un simple clic, le compte rendu approuvé (précédé de la date de la réunion) est ajouté à un document Google Doc désigné.
Avant de développer l'assistant de récapitulatif automatique des réunions, nous avons besoin d'un ensemble minimal d'outils pour l'interface utilisateur, le LLM, la validation typée et l'accès à Google Docs. Les commandes ci-dessous installent tous les éléments nécessaires et configurent la clé du modèle afin que votre application puisse communiquer avec le fournisseur.
pip install -U streamlit langchain langchain-openai pydantic python-dotenv
pip install -U google-api-python-client google-auth google-auth-oauthlib google-auth-httplib2
export OPENAI_API_KEY=...Voici ce que fait chaque prérequis :
Streamlit: Il exécute l'application web localement avec une interface utilisateur simple et Python.
langchain et langchain-openai: Ces éléments fournissent l'interface simplifiée de LangChain v1 (init_chat_model, sortie structurée) et le pont fournisseur OpenAI.
pydantic: Cette bibliothèque définit le schéma strict d'RecapDoc, de sorte que le modèle renvoie des champs typés.
Python-dotenv: Ceci charge les variables d'environnement à partir d'un fichier .env pendant le développement.
google-auth: Ceci est utilisé pour gérer OAuth et l'API Google Docs afin que nous puissions ajouter le récapitulatif à un document.
OPENAI_API_KEY: La clé API OpenAI authentifie nos appels LLM et la définit comme variable d'environnement (ou utilise un gestionnaire de secrets).
Remarque : Si vous utilisez un autre fournisseur (Anthropic, Google ou un modèle local), veuillez installer l'intégration d'langchain-* s correspondante et définir la clé API de ce fournisseur à la place.
Une fois ces dépendances installées et OPENAI_API_KEY configuré, l'environnement est prêt. Dans les étapes suivantes, nous allons configurer l'API Google Docs via Google Cloud.
Afin d'enregistrer chaque compte rendu de réunion dans un document évolutif, l'application requiert l'autorisation d'écrire dans Google Docs. Cette étape configure l'accès de bout en bout. Tout d'abord, nous :
Obtenir un fichier client OAuth (credentials.json) auprès de Google Cloud.
Ensuite, veuillez identifier l'identifiant Google Doc que vous souhaitez ajouter.
Enfin, veuillez autoriser l'application à créer un identifiant réutilisable ( token.json ) lors de sa première utilisation, après avoir approuvé l'accès dans votre navigateur.
Une fois ces trois éléments en place, l'application peut ajouter des résumés au document Google Doc de votre choix en un seul clic. Vous pouvez révoquer ou renouveler l'accès à tout moment en supprimant token.json et en relançant l'application.
Le fichier credentials.jsonest la clé d'accès de votre application à l'API Google Docs. Vous devez le générer une fois dans Google Cloud Console en tant que client OAuth d'application de bureau. Pour commencer :
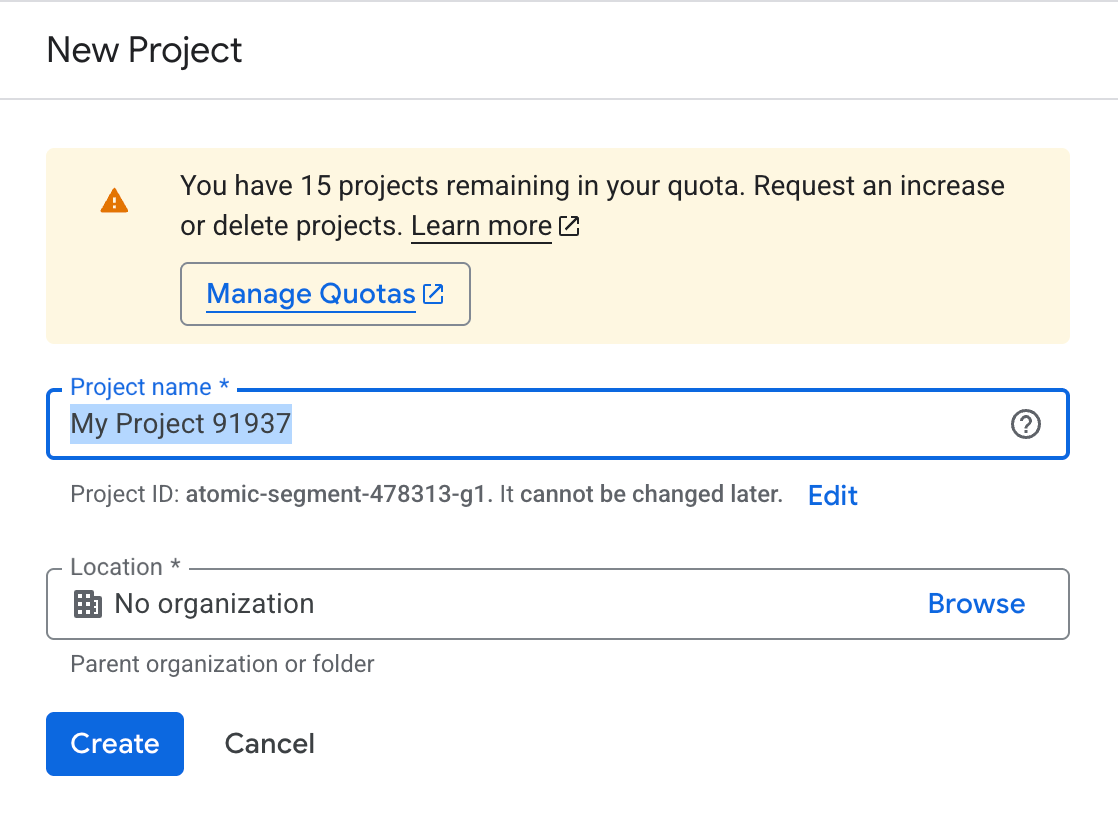
Maintenant que notre projet est créé. Veuillez activer l'API nécessaire pour écrire dans Google Docs.
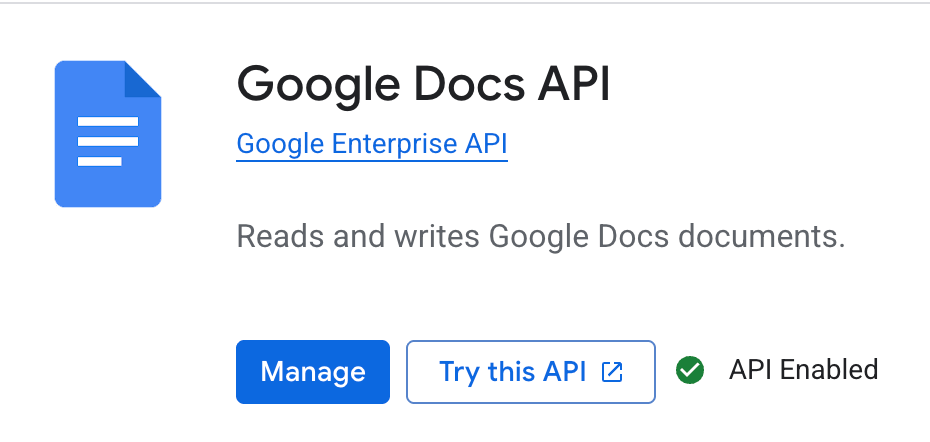
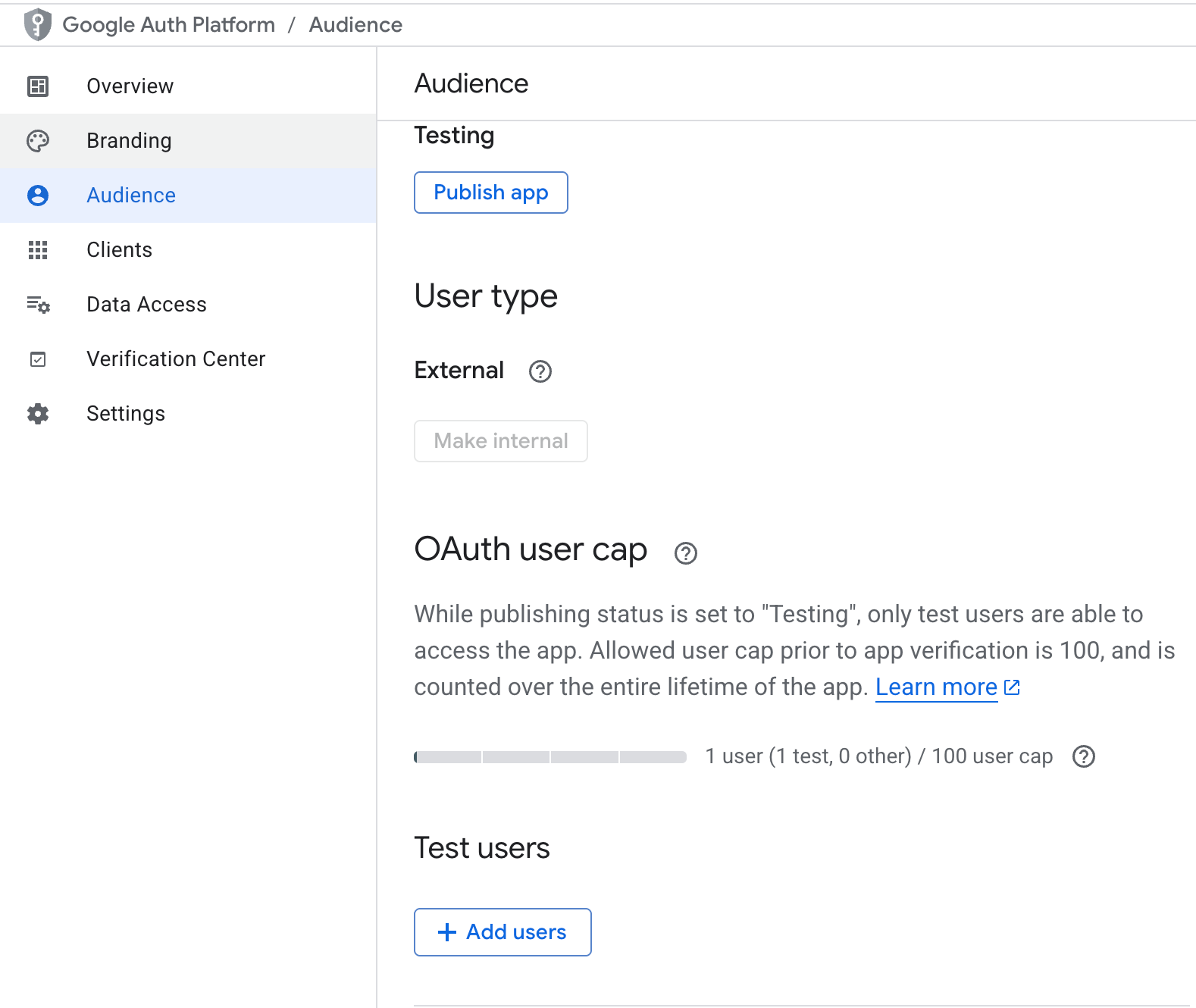
Une fois l'API activée, nous devons ensuite configurer l'authentification pour notre adresse e-mail préférée.
La dernière étape consiste à générer et télécharger le fichier credentials.json. À cet effet :
Veuillez vous rendre dans la section API et services et cliquer sur Identifiants.
Veuillez cliquer sur le lien + CREATE CREDENTIALS qui vous redirigera vers l'identifiant client OAuth.
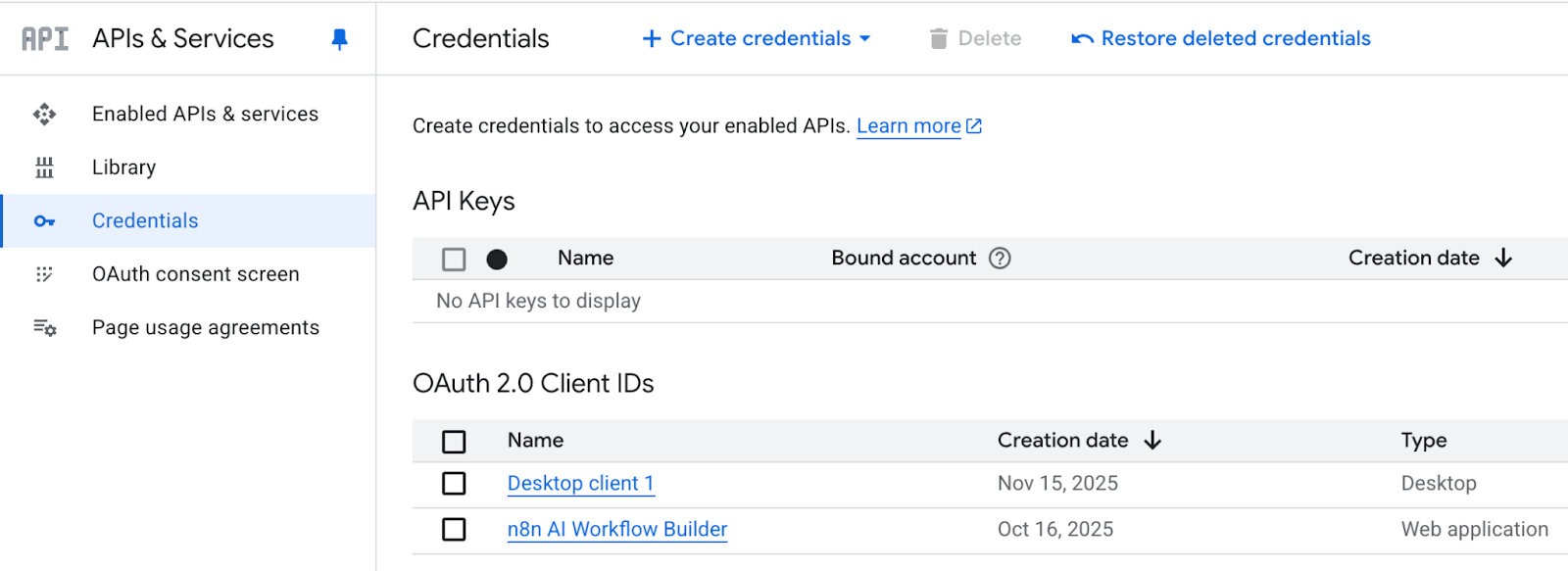
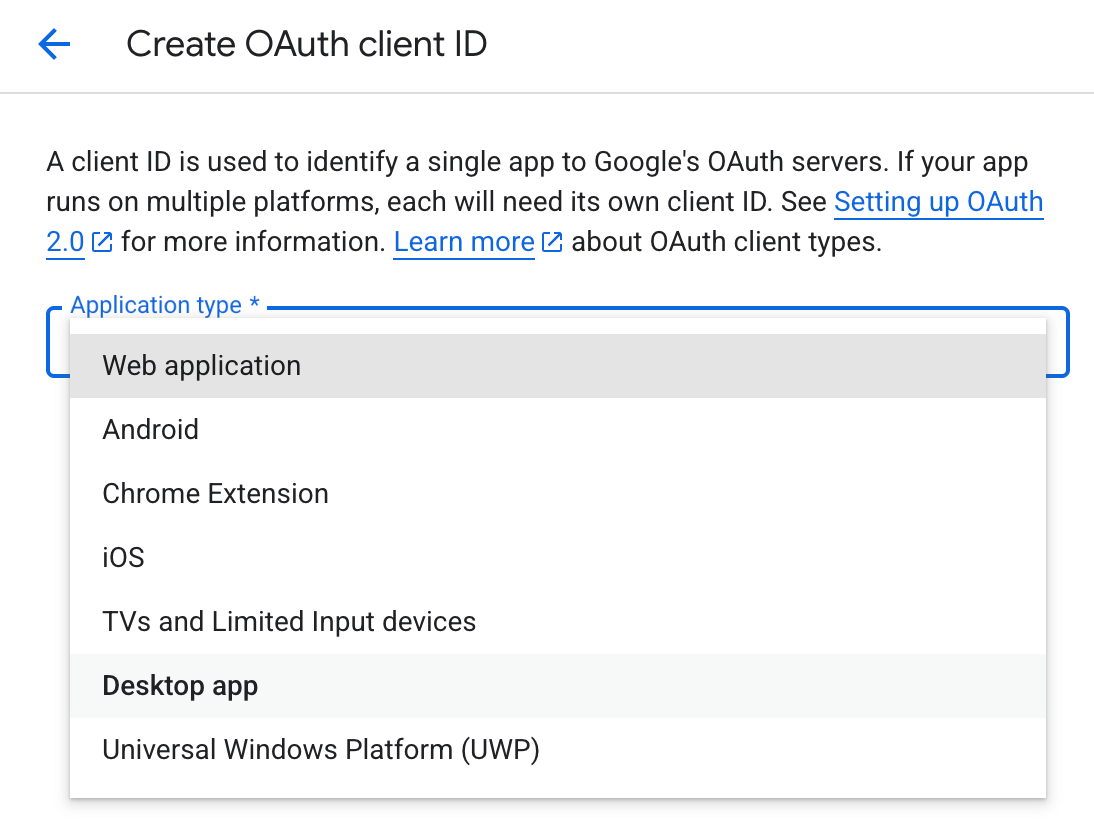
La génération de l'identifiant client et de la clé secrète, ainsi que du fichier JSON téléchargeable, peut prendre jusqu'à 5 minutes.
Veuillez enregistrer le fichier JSON sous le nom credentials.json dans le même dossier que votre fichier app.py (ou indiquez son chemin d'accès dans les paramètres de votre application).
Vous disposez désormais d'un client OAuth de bureau que l'application peut utiliser pour lancer une connexion via un navigateur et demander l'autorisation d'accéder à Google Docs en votre nom.
L'application doit savoir à quel document ajouter les informations. Ce document est identifié par un identifiant unique intégré dans l'URL. Pour cette étape,
Veuillez ouvrir le document Google Docs souhaité dans un navigateur.
Veuillez copier la chaîne de caractères dans l'URL entre /d/ et /edit, par exemple : https://docs.google.com/document/d//edit
Veuillez coller ceci Doc ID dans le champ « Google Doc ID » de l'application (ou dans la variable de configuration appropriée).
Avec l'identifiant de document correct, l'application enregistrera les résumés dans le document exact que vous avez sélectionné.
Lors de la première utilisation, l'application requiert votre autorisation explicite pour accéder au document. Une fois votre approbation reçue, Google renvoie un jeton que l'application stocke localement sous le nom token.json. Voici comment ce fichier est généré :
Veuillez exécuter l'application et cliquer sur « Ajouter à Google Doc ».
Une fenêtre de navigateur s'ouvre et vous invite à vous connecter avec l'un des utilisateurs test que vous avez ajoutés à l'étape précédente et à approuver la portée.
Une fois que vous avez confirmé, l'application affiche « token.json » à côté de votre code. Ce fichier contient vos jetons d'accès/d'actualisation réutilisables.
Remarque : Si vous avez besoin de changer de compte ou de renouveler votre consentement, veuillez supprimer token.json et cliquer à nouveau sur « Append to Google Doc » (Ajouter à Google Doc ).
Avant de rédiger toute logique, nous importons les modules qui alimentent l'interface utilisateur, les contrats de données typés, les appels de modèle et l'intégration Google Docs. Le regroupement des importations par objectif permet de conserver la lisibilité du code et d'identifier clairement la couche à dépanner en cas de dysfonctionnement.
import os
import io
import json
from datetime import date
from typing import List, Optional
import streamlit as st
from pydantic import BaseModel, Field
from dotenv import load_dotenv
# ---- LangChain v1 surface ----
from langchain.agents import create_agent
from langchain.messages import SystemMessage, HumanMessage
from langchain.chat_models import init_chat_model
# ---- Google Docs API ----
from google.oauth2.credentials import Credentials
from google_auth_oauthlib.flow import InstalledAppFlow
from googleapiclient.discovery import buildPour cette étape, nous importons uniquement ce dont l'application a besoin, c'est-à-dire les utilitaires standard tels que os, io, json, date, ainsi que les conseils de saisie pour les chemins d'accès, les tampons et la sérialisation légère. Ensuite, nous importons Streamlit pour l'interface utilisateur, Pydantic pour les schémas d'RecapDoc s de type et dotenv pour charger les variables d'environnement. L'init_chat_model de surface LangChain v1 et create_agentpour initialiser un modèle de chat indépendant du fournisseur et structurer les invites, et enfin, les élémentsde l'API Google Docs qui gèrent OAuth et nous fournissent un client authentifié pour ajouter des résumés au document sélectionné.
Afin de rendre la réponse du modèle fiable et facile à utiliser, nous définissons un contrat typé pour le récapitulatif. L'utilisation des modèles Pydantic garantit que le LLM renvoie des champs prévisibles que notre interface utilisateur peut afficher, que l'API peut stocker et que les automatisations peuvent valider.
class ActionItem(BaseModel):
owner: str = Field(..., description="Person responsible")
task: str = Field(..., description="Short, specific task")
due_date: str = Field(..., description="ISO date (YYYY-MM-DD) or natural language like 'next Friday'")
class RecapDoc(BaseModel):
title: str
date: str
attendees: List[str]
summary: str
decisions: List[str]
action_items: List[ActionItem]Voici les éléments clés du bloc de code ci-dessus :
ActionItem classe : Il capture les éléments essentiels d'une tâche de suivi telle que owner, task et due_date avec des descriptions courtes et explicites afin que le modèle les remplisse de manière claire. Autoriser les dates ISO ou les expressions naturelles permet une saisie flexible tout en restant analysable en aval.
RecapDoc classe : Cette classe représente l'ensemble du récapitulatif sous la forme d'un objet unique, comprenant l'title, l'date, l'attendees, une summary concise, l'decisions explicite et une liste d'action_items.
Avec LangChain v1, vous pouvez demander ce schéma directement via with_structured_output(RecapDoc), ce qui réduit l'analyse syntaxique fragile des chaînes, améliore la validation et vous permet d'échouer rapidement lorsque des champs sont manquants.
Le message système définit les règles de base pour votre assistant. Il indique au modèle exactement ce qu'il doit produire, ce qu'il doit éviter et comment structurer son output afin que les étapes en aval fonctionnent de manière fiable à chaque fois.
SYSTEM_PROMPT = """You are a precise assistant that produces concise, high-signal meeting recaps.
Return a structured RecapDoc with:
- title, date, attendees
- a brief summary (3–6 sentences)
- explicit decisions (bullet-style)
- action_items (each has owner, task, due_date)
Rules:
- Only include info supported by the notes or explicit user inputs.
- Keep action items specific with clear owners and due dates.
- If something is unknown, say "Unknown" rather than inventing details.
"""Le système incite l'assistant à être précis et concis, en privilégiant les résumés riches en informations plutôt que les transcriptions. Il imprime un schéma clair comprenant un titre, une date, les participants, un résumé, les décisions, les points d'action avec des règles telles que : résumé de 3 à 6 phrases, décisions sous forme de liste à puces et points d'action avec responsable, tâche et date d'échéance.
Grâce à une invite système claire, le modèle produit systématiquement des résumés structurés et exploitables dès la première tentative.
Dans cette étape, nous définissons une fonction d'aide qui établit une connexion fiable et réutilisable à Google Docs afin que l'application puisse ajouter des résumés au document de votre choix. Il ne demande que l'autorisation Docs et gère le consentement initial, l'actualisation du jeton et la construction du service.
SCOPES = ["https://www.googleapis.com/auth/documents"]
def get_google_docs_service(
credentials_path: Optional[str],
token_path: str = "token.json",
use_secrets: bool = False
):
creds = None
if use_secrets:
try:
if "google_credentials_json" in st.secrets:
with open("credentials_temp.json", "w") as f:
f.write(st.secrets["google_credentials_json"])
credentials_path = "credentials_temp.json"
except Exception:
pass
if os.path.exists(token_path):
creds = Credentials.from_authorized_user_file(token_path, SCOPES)
if not creds or not creds.valid:
if creds and creds.expired and creds.refresh_token:
try:
creds.refresh(Request())
except Exception:
pass
if not creds or not creds.valid:
if not credentials_path or not os.path.exists(credentials_path):
raise RuntimeError(
"Missing Google OAuth credentials. Provide 'credentials.json' "
"or set st.secrets['google_credentials_json']."
)
flow = InstalledAppFlow.from_client_secrets_file(credentials_path, SCOPES)
creds = flow.run_local_server(port=0)
with open(token_path, "w") as token:
token.write(creds.to_json())
return build("docs", "v1", credentials=creds)La fonction get_google_docs_service()gère OAuth et la création de services en :
Accès à la portée: SCOPESLa fonction ci-dessus utilise des autorisations prédéfinies pour restreindre l'accès à Google Docs.
Chargement des informations d'identification: Il lit à partir d'un fichier local credentials.json ou à partir de st.secrets["google_credentials_json"] ,qui est le conteneur de secrets de Streamlit lorsque use_secrets=True.
Réutilisation des jetons: Si token.json existe, le code le charge et, si le jeton a expiré, il le rafraîchit de manière transparente.
Consentement initial: Si aucun jeton valide n'est trouvé, nous lançons l'InstalledAppFlow, qui invite l'utilisateur à s'authentifier dans le navigateur, puis enregistre l'token.json pour les exécutions futures.
Retour d'un client: Enfin, nous créons et renvoyons un client Docs authentifié via la fonction ` build()`.
Une fois configuré, vous pouvez réutiliser la même token.json pour l'authentification ou actualiser automatiquement le jeton. Pour réinitialiser l'accès, veuillez supprimer token.json et relancer l'application.
RecapDoc Ensuite, nous convertissons un document Google Docs saisi en Markdown propre qui est ajouté au document Google Docs cible. Une fonction génère le récapitulatif tandis que l'autre effectue l'écriture authentifiée à la fin du document.
def append_plaintext_to_doc(docs_service, document_id: str, text: str):
doc = docs_service.documents().get(documentId=document_id).execute()
end_index = doc.get("body", {}).get("content", [])[-1]["endIndex"]
requests = [
{
"insertText": {
"location": {"index": end_index - 1},
"text": text + "\n"
}
}
]
return docs_service.documents().batchUpdate(
documentId=document_id,
body={"requests": requests}
).execute()
def recap_to_markdown(recap: RecapDoc) -> str:
lines = [
f"# {recap.title} — {recap.date}",
"",
f"**Attendees:** {', '.join(recap.attendees) if recap.attendees else 'Unknown'}",
"",
"## Summary",
recap.summary.strip(),
"",
"## Decisions",
]
if recap.decisions:
for d in recap.decisions:
lines.append(f"- {d}")
else:
lines.append("- None recorded")
lines.append("")
lines.append("## Action Items")
if recap.action_items:
for ai in recap.action_items:
lines.append(f"- **{ai.owner}** — {ai.task} _(Due: {ai.due_date})_")
else:
lines.append("- None recorded")
return "\n".join(lines)Les deux assistants ci-dessus fonctionnent ensemble de la manière suivante :
La fonction ` recap_to_markdown() ` génère un résumé lisible. Il comprend un titre avec la date, les participants, un résumé concis et les mesures à prendre avec le responsable, la tâche et la date d'échéance. Il revient également à « Inconnu » ou « Aucune donnée enregistrée » lorsque des champs sont manquants.
La fonction append_plaintext_to_doc() récupère le document, identifie l'index de fin actuel et émet une seule requête insertText via documents(). Le texte est suivi d'un caractère de nouvelle ligne afin que les entrées suivantes commencent sur une nouvelle ligne.
Remarque : Pour les documents vides, envisagez de définir l'index d'insertion par défaut sur 1 si endIndex n'est pas disponible.
Une fois le rendu Markdown et l'ajout mis en place, nous configurons ensuite notre générateur de récapitulatif.
Cette fonctionnalité constitue le cœur de l'application. RecapDoc Il prend en charge les notes brutes et les métadonnées facultatives, fait appel à un modèle de chat et renvoie une réponse dactylographiée afin que tout ce qui suit reste prévisible.
def generate_recap(model_name: str, notes: str, title: str, date_str: str, attendees_csv: str) -> RecapDoc:
model = init_chat_model(model=model_name)
structured_llm = model.with_structured_output(RecapDoc)
attendees_hint = [a.strip() for a in attendees_csv.split(",")] if attendees_csv.strip() else []
user_prompt = (
"You will receive meeting notes and metadata.\n\n"
f"Title: {title or 'Unknown'}\n"
f"Date: {date_str or 'Unknown'}\n"
f"Attendees: {attendees_hint if attendees_hint else 'Unknown'}\n\n"
"Notes:\n"
f"{notes.strip()}\n"
)
messages = [
SystemMessage(content=SYSTEM_PROMPT),
HumanMessage(content=user_prompt)
]
try:
recap = structured_llm.invoke(messages)
except Exception as e:
st.error(f"Error generating recap: {e}")
recap = RecapDoc(
title=title or "Unknown",
date=date_str or "Unknown",
attendees=attendees_hint or [],
summary=f"Error generating summary: {str(e)}",
decisions=[],
action_items=[]
)
return recapLe générateur de récapitulatifs comprend trois composants principaux :
Initialisation du modèle: La fonction init_chat_model() crée un modèle de chat pour le fournisseur que vous avez sélectionné. Nous appelons ensuite la fonction ` with_structured_output() ` pour indiquer au modèle la forme exacte à renvoyer. Il génère un objet Python qui correspond aux champs de l'RecapDoc.
Assemblage rapide: SystemMessage Nous normalisons les entrées et envoyons deux messages, dont un message d'invitation avec des règles strictes (l'invitation du système) et un message d'HumanMessage ion contenant le titre, la date, les participants et les notes brutes.
Génération structurée: La fonction structured_llm.invoke() renvoie une adresse RecapDoc validée, ce qui évite l'analyse syntaxique et réduit les erreurs.
En acheminant votre modèle GPT via le wrapper de sortie structurée de LangChain, l'étape de récapitulatif devient fiable et prête pour le rendu Markdown sans modifier aucune logique en aval.
Cette étape permet de connecter l'ensemble de la démonstration à une application Streamlit d'une seule page. L'utilisateur peut coller des notes, ajouter des métadonnées facultatives, générer un récapitulatif structuré, le prévisualiser au format Markdown et l'ajouter à un document Google Doc d'un simple clic.
def main():
load_dotenv()
st.set_page_config(page_title="Meeting Recap Assistant (LangChain v1)", page_icon=" ", layout="wide")
st.markdown("<h1 style='text-align: center;'>Meeting Recap Assistant With LangChain v1</h1>", unsafe_allow_html=True)
model_name = os.getenv("LC_MODEL", "gpt-4o-mini")
document_id = "10G1k8-2JG_phkpjWM3xZEy2wNg5trUO0SJ2WN7kR3po"
cred_mode = "credentials.json file"
credentials_path = os.getenv("GOOGLE_CREDENTIALS_JSON", "credentials.json")
st.subheader(" Add your meeting notes")
colL, colR = st.columns([2, 1])
with colL:
notes = st.text_area(" ", height=300, placeholder="Paste your raw notes here...")
with colR:
title = st.text_input("Meeting Title", value="")
date_str = st.date_input("Meeting Date", value=date.today())
attendees_csv = st.text_input("Attendees (comma-separated)", value="")
if "recap" not in st.session_state:
st.session_state.recap = None
if "markdown_text" not in st.session_state:
st.session_state.markdown_text = None
col1, col2, col3 = st.columns([1, 1, 2])
with col1:
generate_btn = st.button("Generate Recap")
with col2:
append_btn = st.button("Append to Google Doc", disabled=(st.session_state.recap is None))
if generate_btn:
if not notes.strip():
st.error("Please paste some notes.")
st.stop()
try:
recap = generate_recap(
model_name=model_name,
notes=notes,
title=title,
date_str=str(date_str),
attendees_csv=attendees_csv,
)
st.session_state.recap = recap
st.session_state.markdown_text = recap_to_markdown(recap)
st.rerun()
except Exception as e:
st.exception(e)
st.stop()
if append_btn and st.session_state.recap is not None:
try:
use_secrets = (cred_mode == "Streamlit secrets")
service = get_google_docs_service(
credentials_path=credentials_path if cred_mode == "credentials.json file" else None,
use_secrets=use_secrets
)
final_text = f"\n\n===== {st.session_state.recap.title} — {st.session_state.recap.date} =====\n\n" + st.session_state.markdown_text
append_plaintext_to_doc(service, document_id, final_text)
st.success("Recap appended to the Google Doc")
except Exception as e:
st.exception(e)
if st.session_state.recap is not None:
st.markdown("---")
st.markdown(st.session_state.markdown_text)
if __name__ == "__main__":
main()L'application Streamlit relie une seule action « Générer un récapitulatif » au modèle et l'expose à une interface utilisateur Web locale, en utilisant :
Entrées (colonnes gauche/droite): Le volet gauche est un grand espace d'st.text_area s pour les notes brutes. Le volet droit affiche le titre, la date et les participants.
Résultats (zone d'aperçu): Lorsqu'un récapitulatif est disponible, l'application affiche un séparateur et un aperçu Markdown du récapitulatif structuré pour une consultation rapide.
Câblage de l'interface (actions): Ces actions constituent l'élément central de notre application. Il comprend :
Générer un récapitulatif: Il valide les notes, appelle la fonction generate_recap() qui les convertit au format Markdown, et utilise l'st.rerun() e pour actualiser.
Ajouter à Google Doc: Ensuite, nous créons un client authentifié avec get_google_docs_service() qui ajoute un en-tête daté et l'ajoute au document de destination.
État: La méthode st.session_state stocke les dernières valeurs d'RecapDoc et markdown_text afin que l'interface utilisateur reste stable lors des réexécutions.
Configuration de l'application: Enfin, la méthode ` load_dotenv() ` lit les variables d'environnement tandis que ` st.set_page_config() ` définit la disposition et les chemins d'accès aux informations d'identification provenant de l'environnement ou des valeurs par défaut.
Veuillez enregistrer le fichier sous le nom « app.py » et exécutez la commande suivante dans le terminal.
streamlit run app.pyVous disposez désormais d'un outil complet de récapitulatif de réunion qui se présente comme suit :


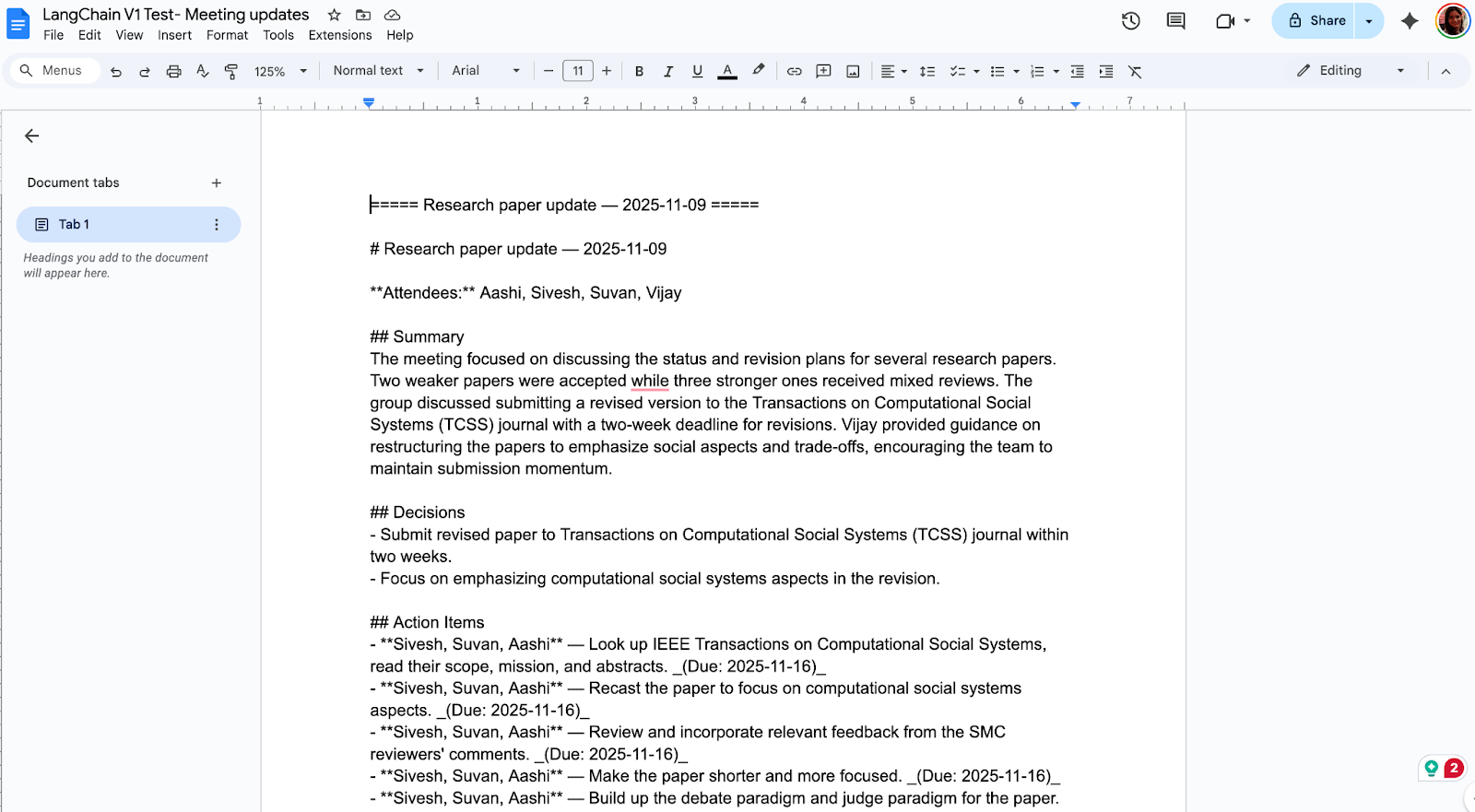
LangChain v1 simplifie la création d'agents grâce à des importations plus simples et des résultats plus fiables, grâce à sa sortie structurée et à ses blocs de contenu standard. Si vous venez de la version v0, veuillez gérer la mise à niveau comme n'importe quel changement de production avec des versions pin, refactoriser les importations et les nouvelles primitives.
Voici quelques éléments à prendre en considération :
LangChain v1 utilise create_agent au lieu des anciens agents pré-construits qui s'appuyaient sur des blocs de contenu standard et des sorties structurées. Veuillez noter que certains éléments plus anciens ont été déplacés vers langchain-classic.
Lorsque vous effectuez la mise à niveau, veuillez utiliser l'langchain>=1.0 et Python 3.10 ou une version supérieure. Nous recommandons d'utiliser les modèles Pydantic pour les sorties, d'ajouter des intergiciels uniquement lorsque cela est utile (approbations, expurgation des informations personnelles identifiables, résumés) et de conserver langchain-classic si vous avez encore besoin d'anciens récupérateurs.
Enfin, veuillez d'abord envoyer une petite entrée et surveiller les traces et les erreurs tout en conservant les dépendances épinglées.
LangChain v1 vous offre des primitives plus claires pour les applications réelles, des résultats structurés fiables, des blocs de contenu standardisés pour tous les fournisseurs et une méthode unifiée pour créer des agents. Vous trouverez ci-dessous des méthodes pratiques pour le mettre en œuvre, ainsi que quelques difficultés auxquelles vous pourriez être confronté lors de son adoption.
Parmi les cas d'utilisation à fort impact de cette version, on peut citer :
Les cas d'utilisation à fort impact s'accompagnent de quelques défis :
À l'avenir, nous pouvons nous attendre à une persistance continue, à des voyages dans le temps et à une observabilité (via LangGraph et LangSmith), ainsi qu'à une prise en charge plus large par les fournisseurs des blocs de contenu standard et à des contrôles plus clairs pour les équipes de production.
LangChain v1 constitue une base solide pour créer des agents fiables et faciles à maintenir. Cet assistant de récapitulatif automatique des réunions démontre comment l'create_agent, les blocs de contenu standard et la sortie structurée se combinent pour gérer un flux de travail réel avec l'approbation humaine dans la boucle et un transfert transparent vers Google Docs. Veuillez utiliser les guides de migration officiels pour moderniser le code existant et commencer modestement avec une application tutorielle comme celle-ci afin de renforcer votre confiance.
Si vous souhaitez approfondir vos connaissances pratiques en matière de création d'applications basées sur l'IA, je vous recommande notre cours « Développer des applications avec LangChain ».
Apprenez avec DataCamp
Cours
Cours
Cours
blog
blog
Kurtis Pykes
15 min
blog
Nathaniel Taylor-Leach
8 min
Tutoriel
DataCamp Team
Tutoriel
Mark Pedigo