
Curso
Desenvolvimento de aplicativos de LLM com LangChain
3 h
46.2K
LangChain é uma estrutura de código aberto pra construir aplicativos de IA que juntam LLMs com ferramentas. A versão 1.0 marca uma mudança para um núcleo de nível de produção com uma API simplificada, limites mais claros e tratamento de mensagens padronizado entre os provedores.
Neste tutorial, vamos criar um Assistente de Resumo Automático de Reuniões Streamlit que pega notas brutas, faz um resumo curto junto com itens de ação e, depois que alguém aprovar, adiciona o resumo a um Google Doc. Ao longo do caminho, você vai ver o novo fluxo create_agent, blocos de conteúdo padrão e o namespace v1 mais enxuto em ação.
LangChain v1 é uma versão reestruturada e voltada para a produção, focada em uma superfície pequena e estável para a criação de agentes. Apresenta:
create_agent como a maneira padrão de ativar agentes (mais limpa do que os agentes pré-construídos antigos).
Conteúdo padronizado por meio do content_blocks para que as mensagens sejam consistentes entre os provedores.
Saída estruturada e middleware para respostas digitadas e ações seguras e aprovadas por humanos.
O pacote langchain foca nos blocos de construção do agente, de modo que os módulos antigos vão para o langchain-classic, facilitando a descoberta e as atualizações.
Comparado com a versão v0.x, a versão v1 reduz a carga cognitiva e as peculiaridades do provedor, padronizando o conteúdo das mensagens e a orquestração do agente. Você tem o mesmo modelo mental, seja na OpenAI, na Anthropic ou em outras empresas.
A versão original Langchain v0.x tinha vários padrões pra criar agentes, mas a v1 juntou tudo num caminho mais claro usando um bloco de create_agent, pra facilitar a compreensão, o teste e o envio dos seus agentes. Ele vem com uma ferramenta mais limpa, depuração mais fácil por meio de conteúdo padronizado e loop de agente previsível.
Aqui estão algumas melhorias técnicas importantes que foram incluídas nesta versão mais recente:
create_agent fluxo de trabalho: Esse loop de agente pronto para produção permite que o modelo decida quando chamar as ferramentas e quando terminar. Então, não precisamos mais lidar com vários padrões, o que facilita a personalização.
Blocos de conteúdo padrão: Uma maneira independente do provedor para ler mensagens é por meio de rastreamento de raciocínio, chamadas de ferramentas, citações e até mesmo bits multimodais, tudo por meio de uma API unificada content_blocks. As ferramentas e os registros parecem iguais em todos os provedores.
Saída estruturada: A versão mais recente vem com suporte de primeira para esquemas tipados, então você pode contar com JSON previsível sem expressões regulares complicadas. Isso reduz erros de análise e chamadas extras.
Middleware: Eles se conectam ao ciclo do agente para aprovar ações arriscadas, resumir o histórico quando longo e editar informações pessoais identificáveis antes das chamadas.
Espaço de nomes simplificado: O pacote langchain agora foca nos blocos de construção essenciais do agente, enquanto o LangGraph dá suporte a recursos de confiabilidade, como persistência e viagem no tempo, nos bastidores.
Nesta seção, vamos implementar um aplicativo Streamlit que automatiza resumos de reuniões do início ao fim. O aplicativo aceita notas de reunião em formato bruto, juntamente com metadados opcionais (título, data e participantes). Em seguida, gera um documento digitado RecapDoc, incluindo o título, resumo, decisões e itens de ação, em uma saída estruturada. Com um único clique, o resumo aprovado (prefixado com a data da reunião) é anexado a um documento do Google Docs designado.
Antes de criarmos o Assistente de Resumo Automático de Reuniões, precisamos de um kit de ferramentas básico para a interface do usuário, o LLM, a validação digitada e o acesso ao Google Docs. Os comandos abaixo instalam tudo o que é necessário e definem a chave do modelo para que seu aplicativo possa se comunicar com o provedor.
pip install -U streamlit langchain langchain-openai pydantic python-dotenv
pip install -U google-api-python-client google-auth google-auth-oauthlib google-auth-httplib2
export OPENAI_API_KEY=...Aqui está o que cada pré-requisito faz:
Streamlit: Ele roda o aplicativo web localmente com uma interface de usuário simples e em Python.
langchain e langchain-openai: Isso fornece a interface simplificada do LangChain v1 (init_chat_model, saída estruturada) e a ponte do provedor OpenAI.
pydantic: Essa biblioteca define o esquema estrito RecapDoc para que o modelo retorne campos tipados.
Python-dotenv: Isso carrega variáveis de ambiente de um arquivo .env durante o desenvolvimento.
google-auth: Isso é usado para lidar com OAuth e a API do Google Docs, para que possamos anexar o resumo a um documento.
OPENAI_API_KEY: A chave API da OpenAI autentica nossas chamadas LLM e a define como uma variável de ambiente (ou usa um gerenciador de segredos).
Observação: Se você estiver usando outro provedor (Anthropic, Google ou um modelo local), instale a integração correspondente langchain-* e defina a chave API desse provedor.
Com essas dependências instaladas e o OPENAI_API_KEY configurado, o ambiente está pronto. Nas próximas etapas, vamos configurar a API do Google Docs pelo Google Nuvem.
Para salvar cada resumo da reunião em um documento ativo, o aplicativo precisa de permissão para gravar no Google Docs. Essa etapa configura o acesso de ponta a ponta. Primeiro, nós:
Pega um arquivo de cliente OAuth (credentials.json) no Google Nuvem.
Depois, identifique o ID do Google Doc que você quer anexar ao
Por fim, deixe o aplicativo criar um token de acesso reutilizável ( token.json ) na primeira execução, depois de aprovar o acesso no seu navegador.
Depois que essas três partes estiverem prontas, o aplicativo pode adicionar resumos ao documento do Google Docs que você escolher com um único clique. Você pode cancelar ou renovar o acesso a qualquer momento, apagando token.json e abrindo o aplicativo de novo.
O arquivo ` credentials.json` é a chave do seu aplicativo para a API do Google Docs. Você gera uma vez no Google Cloud Console como um cliente OAuth de aplicativo para desktop. Pra começar:
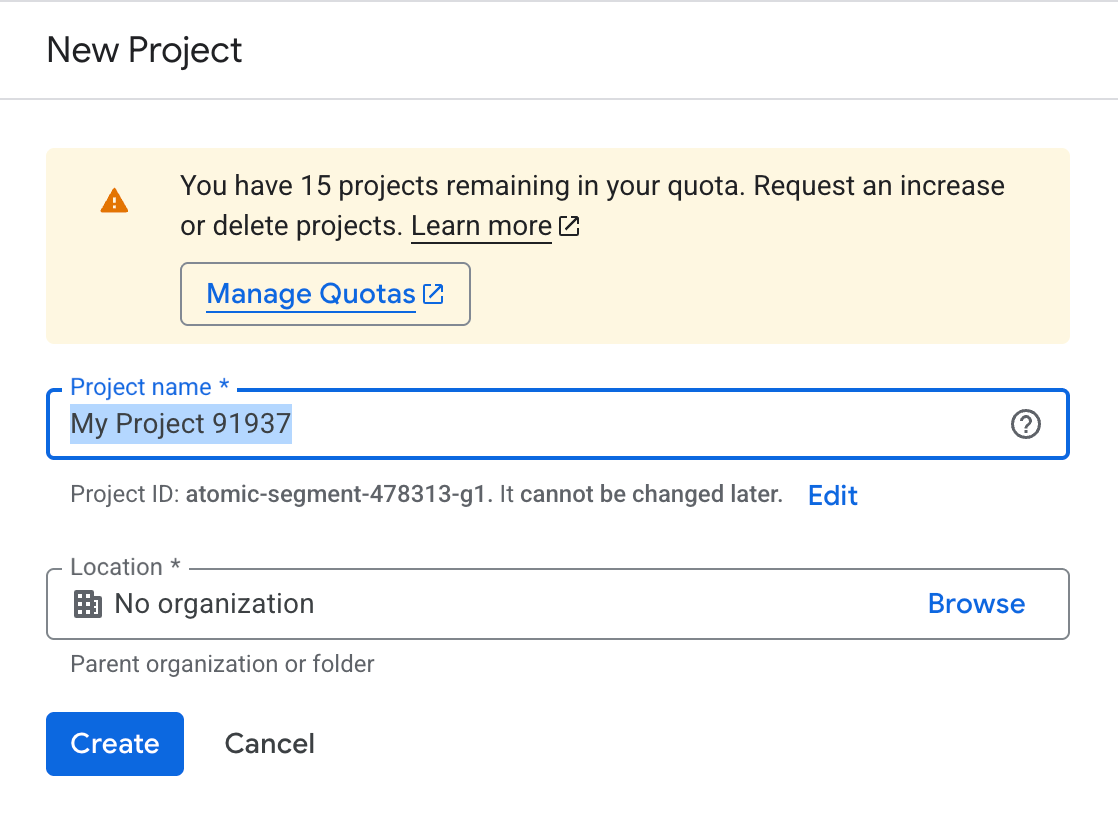
Agora que nosso projeto está criado. Vamos habilitar a API necessária para escrever no Google Docs.
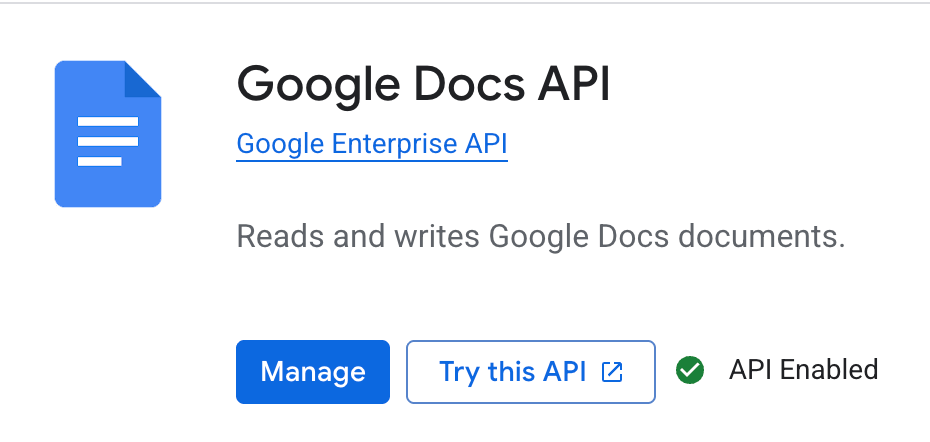
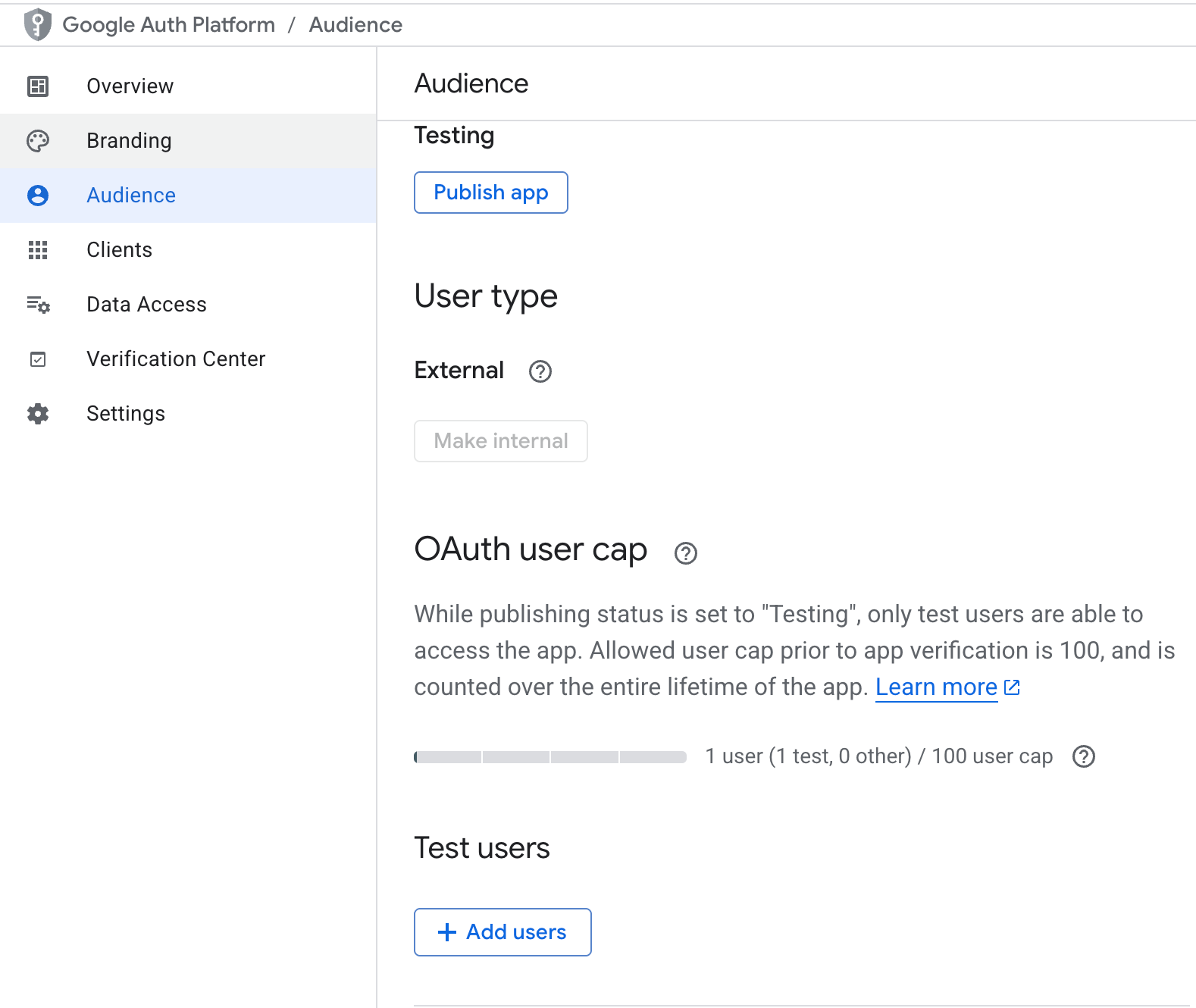
Depois que a API estiver ativada, precisamos configurar a autenticação para o nosso e-mail preferido.
A última etapa é gerar e baixar o arquivo credentials.json. Para isso:
Vá para APIs e serviços e clique em Credenciais.
Clique em “ + CREATE CREDENTIALS ” (Criar um cliente OAuth), que vai te levar para o ID do cliente OAuth.
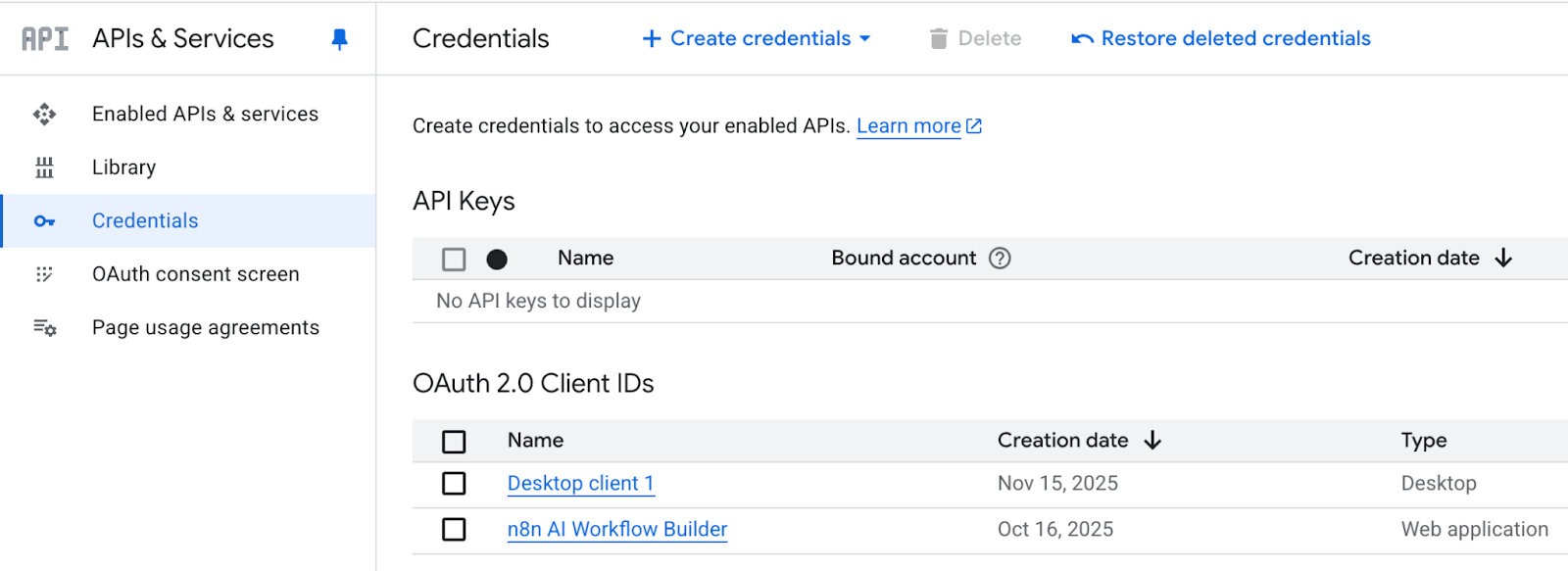
Pode demorar até 5 minutos para gerar o ID do cliente e a chave secreta, junto com um arquivo JSON para baixar.
Salve o arquivo JSON como credentials.json na mesma pasta que o seu app.py (ou coloque o caminho dele nas configurações do seu aplicativo).
Agora você tem um cliente OAuth para desktop que o aplicativo pode usar para iniciar um login baseado no navegador e pedir permissão para acessar o Google Docs em seu nome.
O aplicativo precisa saber em qual documento deve ser anexado. Esse documento é identificado por um ID único que está na URL. Para essa etapa,
Abra o documento do Google Docs que você quer usar no navegador.
Copie a sequência de caracteres na URL entre /d/ e /edit, por exemplo: https://docs.google.com/document/d//edit
Coloque isso Doc ID no campo “Google Doc ID” do aplicativo (ou na variável de configuração apropriada).
Com o Doc ID certo, o aplicativo vai escrever resumos no documento exato que você escolheu.
Na primeira vez que você anexar, o aplicativo vai precisar da sua aprovação explícita para acessar o documento. Depois que você aprovar, o Google vai te dar um token que o aplicativo guarda localmente como token.json. Veja como esse arquivo é gerado:
Abra o aplicativo e clique em Anexar ao Google Doc.
Uma janela do navegador vai abrir pedindo pra você fazer login com um dos usuários de teste que você adicionou na etapa anterior e aprovar o escopo.
Depois que você confirmar, o aplicativo vai escrever “ token.json ” ao lado do seu código. Esse arquivo tem seus tokens de acesso/atualização reutilizáveis.
Observação: Se precisar trocar de conta ou renovar o consentimento, é só apagar o token.json e clicar em “Anexar ao Google Doc” de novo.
Antes de escrever qualquer lógica, importamos os módulos que alimentam a interface do usuário, contratos de dados digitados, chamadas de modelo e integração com o Google Docs. Agrupar as importações por finalidade mantém o código legível e deixa claro qual camada deve ser verificada quando algo dá errado.
import os
import io
import json
from datetime import date
from typing import List, Optional
import streamlit as st
from pydantic import BaseModel, Field
from dotenv import load_dotenv
# ---- LangChain v1 surface ----
from langchain.agents import create_agent
from langchain.messages import SystemMessage, HumanMessage
from langchain.chat_models import init_chat_model
# ---- Google Docs API ----
from google.oauth2.credentials import Credentials
from google_auth_oauthlib.flow import InstalledAppFlow
from googleapiclient.discovery import buildNesta etapa, importamos só o que o aplicativo precisa, tipo utilitários padrão como os, io, json, date e dicas de digitação para caminhos, buffers e serialização leve. Depois, importamos o Streamlit para a interface do usuário, o Pydantic para os esquemas digitados RecapDoc e o dotenv para carregar as variáveis de ambiente. A superfície LangChain v1 init_chat_model e create_agentpra inicializar um modelo de chat independente do provedor e estruturar prompts e, por fim, as partesda API do Google Docs que lidam com OAuth e nos dão um cliente autenticado pra adicionar resumos ao documento escolhido.
Para tornar a resposta do modelo confiável e fácil de usar, definimos um contrato tipado para a recapitulação. Usar modelos Pydantic garante que o LLM retorne campos previsíveis que nossa interface do usuário pode renderizar, a API pode armazenar e as automações podem validar.
class ActionItem(BaseModel):
owner: str = Field(..., description="Person responsible")
task: str = Field(..., description="Short, specific task")
due_date: str = Field(..., description="ISO date (YYYY-MM-DD) or natural language like 'next Friday'")
class RecapDoc(BaseModel):
title: str
date: str
attendees: List[str]
summary: str
decisions: List[str]
action_items: List[ActionItem]Aqui estão os principais componentes do bloco de código acima:
ActionItem classe: Ele pega o essencial de uma tarefa de acompanhamento, tipo owner, task e due_date , com descrições curtas e diretas, pra que o modelo as preencha direitinho. Permitir datas ISO ou frases naturais mantém a entrada flexível, sem deixar de ser analisável a jusante.
RecapDoc classe: Essa classe representa todo o resumo como um único objeto, incluindo title, date, attendees, um summary conciso, um decisions explícito e uma lista de action_items.
Com o LangChain v1, você pode pedir esse esquema direto pelo with_structured_output(RecapDoc), o que reduz a análise frágil de strings, melhora a validação e permite que você falhe rápido quando faltam campos.
O sistema define as regras básicas para o seu assistente. Ele diz ao modelo exatamente o que produzir, o que evitar e como organizar sua saída para que as etapas seguintes funcionem bem sempre.
SYSTEM_PROMPT = """You are a precise assistant that produces concise, high-signal meeting recaps.
Return a structured RecapDoc with:
- title, date, attendees
- a brief summary (3–6 sentences)
- explicit decisions (bullet-style)
- action_items (each has owner, task, due_date)
Rules:
- Only include info supported by the notes or explicit user inputs.
- Keep action items specific with clear owners and due dates.
- If something is unknown, say "Unknown" rather than inventing details.
"""O sistema faz com que o assistente seja preciso e direto, focando em resumos importantes em vez de transcrições. Imprime um esquema claro, incluindo título, data, participantes, resumo, decisões, itens de ação com regras como resumo de 3 a 6 frases, decisões em tópicos e itens de ação com responsável, tarefa e data de vencimento.
Com um prompt de sistema claro, o modelo produz consistentemente resumos úteis e estruturados na primeira tentativa.
Nesta etapa, vamos definir uma função auxiliar que cria uma conexão confiável e reutilizável com o Google Docs para que o aplicativo possa adicionar resumos ao documento que você escolher. Ele só pede o escopo do Docs e cuida do consentimento inicial, da atualização do token e da construção do serviço.
SCOPES = ["https://www.googleapis.com/auth/documents"]
def get_google_docs_service(
credentials_path: Optional[str],
token_path: str = "token.json",
use_secrets: bool = False
):
creds = None
if use_secrets:
try:
if "google_credentials_json" in st.secrets:
with open("credentials_temp.json", "w") as f:
f.write(st.secrets["google_credentials_json"])
credentials_path = "credentials_temp.json"
except Exception:
pass
if os.path.exists(token_path):
creds = Credentials.from_authorized_user_file(token_path, SCOPES)
if not creds or not creds.valid:
if creds and creds.expired and creds.refresh_token:
try:
creds.refresh(Request())
except Exception:
pass
if not creds or not creds.valid:
if not credentials_path or not os.path.exists(credentials_path):
raise RuntimeError(
"Missing Google OAuth credentials. Provide 'credentials.json' "
"or set st.secrets['google_credentials_json']."
)
flow = InstalledAppFlow.from_client_secrets_file(credentials_path, SCOPES)
creds = flow.run_local_server(port=0)
with open(token_path, "w") as token:
token.write(creds.to_json())
return build("docs", "v1", credentials=creds)A função get_google_docs_service()cuida do OAuth e da criação de serviços da seguinte forma:
Acesso ao escopo: A função acima usa o SCOPESpré-definido para limitar as permissões ao Google Docs.
Carregando credenciais: Ele lê a partir de um arquivo local credentials.json ou de st.secrets["google_credentials_json"] ,que é o repositório de segredos do streamlit quando use_secrets=True.
Reutilizando tokens: Se existir um token de sessão ( token.json ), o código o carrega e, se o token tiver expirado, ele o atualiza silenciosamente.
Consentimento inicial: Se nenhum token válido for encontrado, a gente abre o Desktop InstalledAppFlow, que pede pro usuário se autenticar no navegador e depois salva token.json pra futuras execuções.
Devolvendo um cliente: Por fim, criamos e retornamos um cliente Docs autenticado por meio da função ` build()`.
Depois de configurar, você pode usar o mesmo token de autenticação ( token.json ) para autenticação ou atualizar o token automaticamente. Para redefinir o acesso, basta excluir token.json e executar o aplicativo novamente.
Depois, a gente transforma um RecapDoc digitado em Markdown limpo que é anexado ao Google Doc de destino. Uma função gera o resumo, enquanto a outra faz a gravação autenticada no final do documento.
def append_plaintext_to_doc(docs_service, document_id: str, text: str):
doc = docs_service.documents().get(documentId=document_id).execute()
end_index = doc.get("body", {}).get("content", [])[-1]["endIndex"]
requests = [
{
"insertText": {
"location": {"index": end_index - 1},
"text": text + "\n"
}
}
]
return docs_service.documents().batchUpdate(
documentId=document_id,
body={"requests": requests}
).execute()
def recap_to_markdown(recap: RecapDoc) -> str:
lines = [
f"# {recap.title} — {recap.date}",
"",
f"**Attendees:** {', '.join(recap.attendees) if recap.attendees else 'Unknown'}",
"",
"## Summary",
recap.summary.strip(),
"",
"## Decisions",
]
if recap.decisions:
for d in recap.decisions:
lines.append(f"- {d}")
else:
lines.append("- None recorded")
lines.append("")
lines.append("## Action Items")
if recap.action_items:
for ai in recap.action_items:
lines.append(f"- **{ai.owner}** — {ai.task} _(Due: {ai.due_date})_")
else:
lines.append("- None recorded")
return "\n".join(lines)Os dois auxiliares acima funcionam juntos assim:
A função ` recap_to_markdown() ` cria um resumo fácil de ler. Inclui um título com data, participantes, um resumo curto e itens de ação com responsável, tarefa e prazo. Também volta para “Desconhecido” ou “Nenhum registrado” quando faltam campos.
Enquanto a função ` append_plaintext_to_doc() ` pega o documento, encontra o índice final atual e faz uma única solicitação ` insertText ` via ` documents()`. O texto é acrescentado com uma nova linha no final, para que as entradas seguintes comecem numa nova linha.
Observação: Para documentos vazios, considere definir o índice de inserção como 1 por padrão, caso endIndex não esteja disponível.
Com a renderização e o acréscimo do Markdown em funcionamento, a seguir configuramos nosso gerador de recapitulação.
Essa função é o coração do aplicativo. Ele pega notas brutas e metadados opcionais, chama um modelo de bate-papo e devolve um objeto RecapDoc digitado para que tudo a jusante continue previsível.
def generate_recap(model_name: str, notes: str, title: str, date_str: str, attendees_csv: str) -> RecapDoc:
model = init_chat_model(model=model_name)
structured_llm = model.with_structured_output(RecapDoc)
attendees_hint = [a.strip() for a in attendees_csv.split(",")] if attendees_csv.strip() else []
user_prompt = (
"You will receive meeting notes and metadata.\n\n"
f"Title: {title or 'Unknown'}\n"
f"Date: {date_str or 'Unknown'}\n"
f"Attendees: {attendees_hint if attendees_hint else 'Unknown'}\n\n"
"Notes:\n"
f"{notes.strip()}\n"
)
messages = [
SystemMessage(content=SYSTEM_PROMPT),
HumanMessage(content=user_prompt)
]
try:
recap = structured_llm.invoke(messages)
except Exception as e:
st.error(f"Error generating recap: {e}")
recap = RecapDoc(
title=title or "Unknown",
date=date_str or "Unknown",
attendees=attendees_hint or [],
summary=f"Error generating summary: {str(e)}",
decisions=[],
action_items=[]
)
return recapO gerador de recapitulação tem três partes principais:
Inicialização do modelo: A função ` init_chat_model() ` cria um modelo de chat para o provedor que você escolheu. Depois, chamamos a função ` with_structured_output() ` para dizer ao modelo exatamente qual forma retornar. Ele gera um objeto Python que combina com os campos RecapDoc.
Montagem rápida: A gente normaliza as entradas e manda duas mensagens, incluindo um SystemMessage com regras rígidas (o prompt do sistema) e um HumanMessage com título, data, participantes e notas em bruto.
Geração estruturada: A função structured_llm.invoke() retorna um RecapDoc validado, evitando a análise e reduzindo as alucinações.
Ao passar seu modelo GPT pelo wrapper de saída estruturada do LangChain, a etapa de recapitulação fica confiável e pronta para renderização Markdown sem mudar nenhuma lógica a jusante.
Essa etapa conecta toda a demonstração em um aplicativo Streamlit de uma página. O usuário cola notas, adiciona metadados opcionais, gera um resumo estruturado, visualiza como Markdown e anexa a um documento do Google Docs com um clique.
def main():
load_dotenv()
st.set_page_config(page_title="Meeting Recap Assistant (LangChain v1)", page_icon=" ", layout="wide")
st.markdown("<h1 style='text-align: center;'>Meeting Recap Assistant With LangChain v1</h1>", unsafe_allow_html=True)
model_name = os.getenv("LC_MODEL", "gpt-4o-mini")
document_id = "10G1k8-2JG_phkpjWM3xZEy2wNg5trUO0SJ2WN7kR3po"
cred_mode = "credentials.json file"
credentials_path = os.getenv("GOOGLE_CREDENTIALS_JSON", "credentials.json")
st.subheader(" Add your meeting notes")
colL, colR = st.columns([2, 1])
with colL:
notes = st.text_area(" ", height=300, placeholder="Paste your raw notes here...")
with colR:
title = st.text_input("Meeting Title", value="")
date_str = st.date_input("Meeting Date", value=date.today())
attendees_csv = st.text_input("Attendees (comma-separated)", value="")
if "recap" not in st.session_state:
st.session_state.recap = None
if "markdown_text" not in st.session_state:
st.session_state.markdown_text = None
col1, col2, col3 = st.columns([1, 1, 2])
with col1:
generate_btn = st.button("Generate Recap")
with col2:
append_btn = st.button("Append to Google Doc", disabled=(st.session_state.recap is None))
if generate_btn:
if not notes.strip():
st.error("Please paste some notes.")
st.stop()
try:
recap = generate_recap(
model_name=model_name,
notes=notes,
title=title,
date_str=str(date_str),
attendees_csv=attendees_csv,
)
st.session_state.recap = recap
st.session_state.markdown_text = recap_to_markdown(recap)
st.rerun()
except Exception as e:
st.exception(e)
st.stop()
if append_btn and st.session_state.recap is not None:
try:
use_secrets = (cred_mode == "Streamlit secrets")
service = get_google_docs_service(
credentials_path=credentials_path if cred_mode == "credentials.json file" else None,
use_secrets=use_secrets
)
final_text = f"\n\n===== {st.session_state.recap.title} — {st.session_state.recap.date} =====\n\n" + st.session_state.markdown_text
append_plaintext_to_doc(service, document_id, final_text)
st.success("Recap appended to the Google Doc")
except Exception as e:
st.exception(e)
if st.session_state.recap is not None:
st.markdown("---")
st.markdown(st.session_state.markdown_text)
if __name__ == "__main__":
main()O aplicativo Streamlit conecta uma única ação “Gerar resumo” ao modelo e a expõe a uma interface de usuário da web local, usando:
Entradas (colunas esquerda/direita): O painel esquerdo é um grande bloco de notas ( st.text_area ) para anotações em bruto. Enquanto o painel direito mostra o título, a data e quem vai participar.
Resultados (área de pré-visualização): Quando tem um resumo, o app mostra uma divisória e uma pré-visualização em Markdown do resumo estruturado pra você dar uma olhada rápida.
Fiação da interface (ações): Essas ações são o ponto principal do nosso aplicativo. Inclui:
Gerar resumo: Ele valida notas, chama a função generate_recap(), que converte para Markdown, e st.rerun() para atualizar.
Adicionar ao Google Doc: Depois, criamos um cliente autenticado com get_google_docs_service(), que adiciona um cabeçalho datado e anexa ao documento de destino.
Estado: O método ` st.session_state ` guarda os últimos valores de ` RecapDoc ` e ` markdown_text ` para que a interface do usuário fique estável nas repetições.
Configuração do aplicativo: Por fim, o método ` load_dotenv() ` lê as variáveis de ambiente, enquanto ` st.set_page_config() ` define o layout e os caminhos das credenciais que vêm do ambiente ou dos padrões.
Salve como app.py e execute o seguinte comando no terminal.
streamlit run app.pyAgora você tem uma ferramenta completa para recapitular reuniões que se parece com isto:


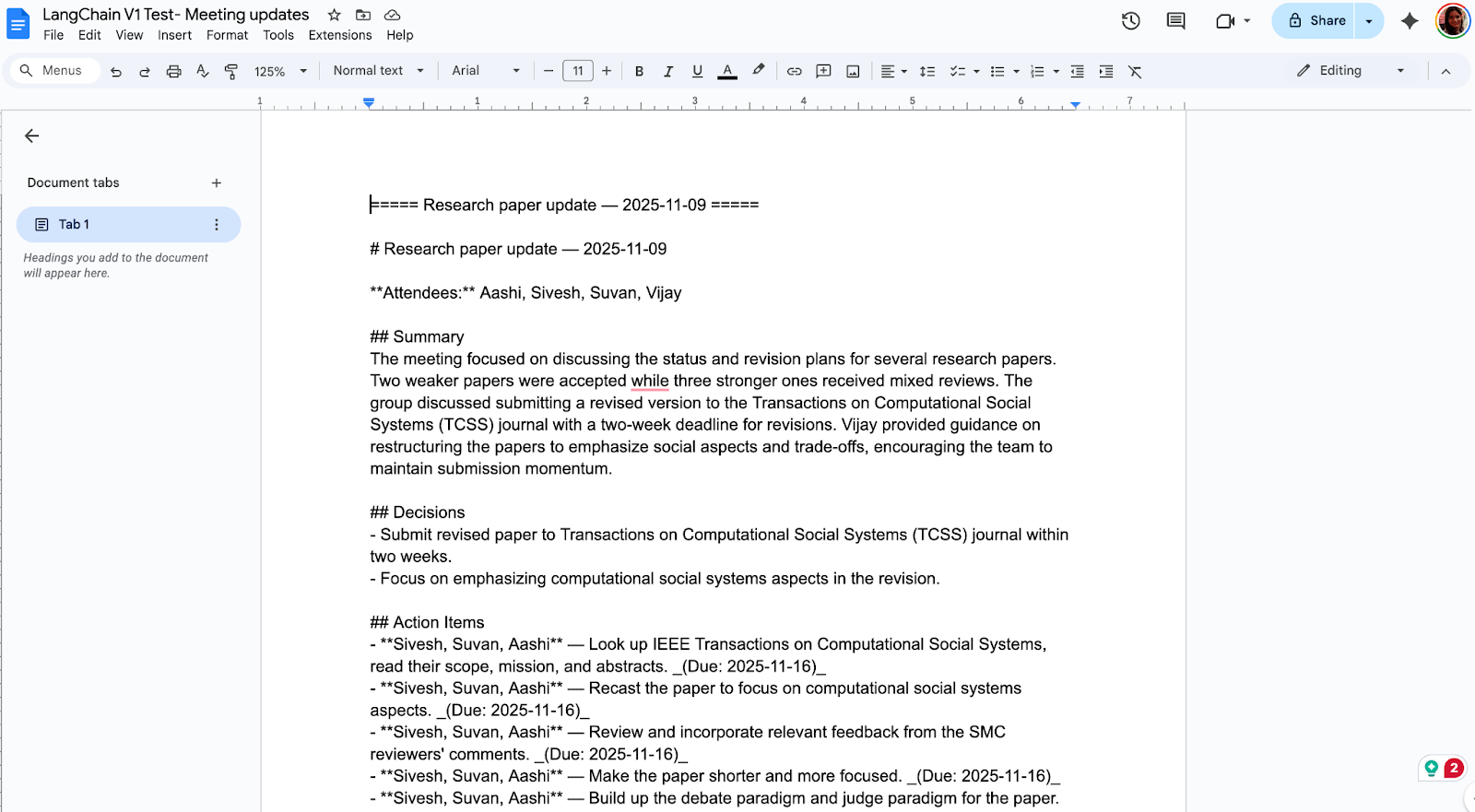
O LangChain v1 simplifica a criação de agentes com importações mais fáceis e resultados mais confiáveis, graças à sua saída estruturada e blocos de conteúdo padrão. Se você está vindo da versão v0, faça a atualização como qualquer mudança de produção com versões fixas, refatoração de importações e novas primitivas.
Algumas coisas pra ter em mente são:
O LangChain v1 usa create_agent em vez dos antigos agentes pré-construídos que dependiam de blocos de conteúdo padrão e saída estruturada. Vale lembrar que algumas partes mais antigas foram transferidas para langchain-classic.
Quando você atualizar, use o pin langchain>=1.0 e o Python 3.10+. Prefira modelos Pydantic para saídas, adicione middleware só onde for útil (aprovações, redação de PII, resumos) e mantenha langchain-classic se ainda precisar de recuperadores legados.
Por fim, manda primeiro uma entrada pequena e fica de olho nos traços e erros enquanto mantém as dependências fixadas.
O LangChain v1 oferece primitivas mais limpas para aplicativos reais, resultados estruturados em que você pode confiar, blocos de conteúdo padrão entre provedores e uma maneira unificada de criar agentes. Abaixo estão algumas maneiras práticas de colocar isso em prática, junto com alguns desafios que você pode encontrar durante a adoção.
Alguns casos de uso de alto impacto desta versão incluem:
Com casos de uso de alto impacto, surgem alguns desafios:
Olhando para o futuro, podemos esperar persistência contínua, viagem no tempo e observabilidade (via LangGraph e LangSmith), junto com um suporte mais amplo dos provedores para blocos de conteúdo padrão e controles mais claros para as equipes de produção.
O LangChain v1 é uma base sólida para criar agentes confiáveis e fáceis de manter. Esse Assistente de Resumo Automático de Reuniões mostra como o create_agent, blocos de conteúdo padrão e saída estruturada se juntam para lidar com um fluxo de trabalho real com aprovação humana no ciclo e uma transferência perfeita para o Google Docs. Use os guias oficiais de migração para modernizar o código legado e comece aos poucos com um aplicativo tutorial como este para ganhar confiança.
Se você quer se aprofundar na criação de aplicativos com inteligência artificial, recomendo nosso curso Desenvolvimento de aplicativos com LangChain .
Aprenda com o DataCamp
Curso
Curso
Curso
Tutorial
Bex Tuychiev
Tutorial
Moez Ali
Tutorial
Ryan Ong
Tutorial
Zoumana Keita
Tutorial
Josep Ferrer
Tutorial
Matt Crabtree

