
Kurs
Entwickeln von LLM-Anwendungen mit LangChain
3 Std.
46.3K
LangChain ist ein Open-Source-Framework zum Erstellen von agentenbasierten KI-Anwendungen, die LLMs mit Tools kombinieren. Version 1.0 ist der Startschuss für einen produktionsreifen Kern mit einer einfacheren API, klareren Grenzen und einer einheitlichen Nachrichtenverarbeitung über alle Anbieter hinweg.
In diesem Tutorial machen wir einen Streamlit Auto Meeting Recap Assistant, der rohe Notizen nimmt, eine kurze Zusammenfassung mit Aktionspunkten erstellt und die Zusammenfassung nach menschlicher Freigabe an ein Google Doc anhängt. Unterwegs siehst du den neuen „ create_agent “-Flow, Standard-Inhaltsblöcke und den schlankeren v1-Namespace in Aktion.
LangChain v1 ist eine überarbeitete, produktionsorientierte Version, die sich auf eine kleine, stabile Oberfläche für die Erstellung von Agenten konzentriert. Es stellt vor:
create_agent als Standardmethode zum Starten von Agenten (sauberer als ältere vorgefertigte Agenten).
Standardisierte Inhalte über content_blocks, damit die Nachrichten bei allen Anbietern gleich sind.
Strukturierte Ausgabe und Middleware für typisierte Antworten und sichere, von Menschen genehmigte Aktionen.
Das Langchain-Paket konzentriert sich auf Agent-Bausteine, sodass die alten Module zu Langchain-Classic verschoben werden, was die Auffindbarkeit und Upgrades vereinfacht.
Im Vergleich zu v0.x macht v1 die Sache einfacher und vermeidet Probleme mit Anbietern, indem es die Nachrichteninhalte und die Koordination der Agenten standardisiert. Du bekommst das gleiche mentale Modell, egal ob du bei OpenAI, Anthropic oder anderen bist.
Die ursprüngliche Version Langchain v0.x hatte viele Muster zum Erstellen von Agenten, aber die Version v1 fasst sie mit dem Block „ create_agent ” zu einem klaren Pfad zusammen, damit deine Agenten einfacher zu verstehen, zu testen und zu versenden sind. Es kommt mit einem Reinigungswerkzeug, macht das Debuggen einfacher durch standardisierte Inhalte und eine vorhersehbare Agentenschleife.
Hier sind ein paar wichtige technische Verbesserungen, die in der neuesten Version enthalten sind:
create_agent Arbeitsablauf: Mit dieser einsatzbereiten Agentenschleife kann das Modell entscheiden, wann Tools aufgerufen und wann der Vorgang beendet werden soll. Also müssen wir nicht mehr mit mehreren Mustern jonglieren, was die Anpassung echt einfach macht.
Standard-Inhaltsblöcke: Eine anbieterunabhängige Methode zum Lesen von Nachrichten ist das Auswerten von Spuren, Tool-Aufrufen, Zitaten und sogar multimodalen Bits über eine einheitliche API namens „ content_blocks “. Die Tools und Protokolle sehen bei allen Anbietern gleich aus.
Strukturierte Ausgabe: Die neueste Version hat erstklassige Unterstützung für typisierte Schemata, sodass du dich auf vorhersehbares JSON ohne komplizierte reguläre Ausdrücke verlassen kannst. Das reduziert Parsing-Fehler und zusätzliche Aufrufe.
Middleware: Die hängen sich in die Agentenschleife ein, um riskante Aktionen zu genehmigen, lange Verläufe zusammenzufassen und personenbezogene Daten vor Anrufen zu schwärzen.
Vereinfachter Namensraum: Das Paket „ langchain “ konzentriert sich jetzt auf wichtige Bausteine für Agenten, während LangGraph unter der Haube für zuverlässige Funktionen wie Persistenz und Zeitreise sorgt.
In diesem Abschnitt machen wir eine Streamlit-App, die die Zusammenfassungen von Meetings komplett automatisch erledigt. Die App nimmt rohe Besprechungsnotizen zusammen mit optionalen Metadaten (Titel, Datum und Teilnehmer) auf. Dann erstellt es ein typisiertes Dokument namens „ RecapDoc “ mit dem Titel, der Zusammenfassung, den Entscheidungen und den Aktionspunkten in einer strukturierten Ausgabe. Mit einem Klick wird die genehmigte Zusammenfassung (mit dem Datum der Besprechung davor) an ein bestimmtes Google Doc angehängt.
Bevor wir den Auto Meeting Recap Assistant entwickeln, brauchen wir ein kleines Toolkit für die Benutzeroberfläche, das LLM, die typisierte Validierung und den Zugriff auf Google Docs. Die folgenden Befehle installieren alles, was du brauchst, und richten den Modellschlüssel ein, damit deine App mit dem Anbieter kommunizieren kann.
pip install -U streamlit langchain langchain-openai pydantic python-dotenv
pip install -U google-api-python-client google-auth google-auth-oauthlib google-auth-httplib2
export OPENAI_API_KEY=...Hier ist, was jede Voraussetzung macht:
Streamlit: Es lässt die Web-App lokal mit einer einfachen, Python-ähnlichen Benutzeroberfläche laufen.
langchain und langchain-openai: Das hier bietet die vereinfachte Oberfläche von LangChain v1 (init_chat_model, strukturierte Ausgabe) und die OpenAI-Anbieterbrücke.
pydantic: Diese Bibliothek legt das strenge Schema „ RecapDoc “ fest, damit das Modell typisierte Felder zurückgibt.
Python-dotenv: Das lädt während der Entwicklung Umgebungsvariablen aus einer Datei namens „ .env “.
google-auth: Das wird benutzt, um OAuth und die Google Docs API zu verarbeiten, damit wir die Zusammenfassung an ein Dokument hängen können.
OPENAI_API_KEY: Der OpenAI-API-Schlüssel checkt unsere LLM-Aufrufe und wird als Umgebungsvariable gesetzt (oder man nutzt einen Secrets Manager).
Anmerkung: Wenn du einen anderen Anbieter (Anthropic, Google oder ein lokales Modell) benutzt, installier die passende Integration „ langchain-* “ und leg stattdessen den API-Schlüssel dieses Anbieters fest.
Wenn du diese Abhängigkeiten installiert und „ OPENAI_API_KEY “ gesetzt hast, ist die Umgebung fertig. Als Nächstes richten wir die Google Docs-API über Google Cloud ein.
Um jede Zusammenfassung der Meetings in einem lebenden Dokument zu speichern, braucht die App die Erlaubnis, in Google Docs zu schreiben. Dieser Schritt richtet den End-to-End-Zugang ein. Zuerst haben wir:
Hol dir einen OAuth-Client Datei (credentials.json) von Google Cloud
Dann such die Google Doc-ID, die du anhängen willst.
Lass die App schließlich beim ersten Start, nachdem du den Zugriff in deinem Browser genehmigt hast, einen wiederverwendbaren „ token.json “ erstellen.
Sobald diese drei Teile eingerichtet sind, kann die App mit einem Klick Zusammenfassungen an dein ausgewähltes Google Doc anhängen. Du kannst den Zugriff jederzeit widerrufen oder erneuern, indem du „ token.json “ löschst und die App erneut startest.
Die Datei „ credentials.json“ ist der Schlüssel deiner App zur Google Docs-API. Du erstellst ihn einmalig in der Google Cloud Console als Desktop-App-OAuth-Client. Los geht's:
Jetzt ist unser Projekt erstellt. Aktivieren wir die API, die man braucht, um in Google Docs zu schreiben.
Sobald die API aktiviert ist, müssen wir als Nächstes die Authentifizierung für unsere bevorzugte E-Mail-Adresse einrichten.
Der letzte Schritt ist, die Datei credentials.json zu erstellen und runterzuladen. Dafür:
Geh zu „APIs & Services “ und klick auf „Anmeldedaten“.
Klick auf „ + CREATE CREDENTIALS “ (OAuth-Client-IDs verwalten) , um zur OAuth-Client-ID zu gelangen.
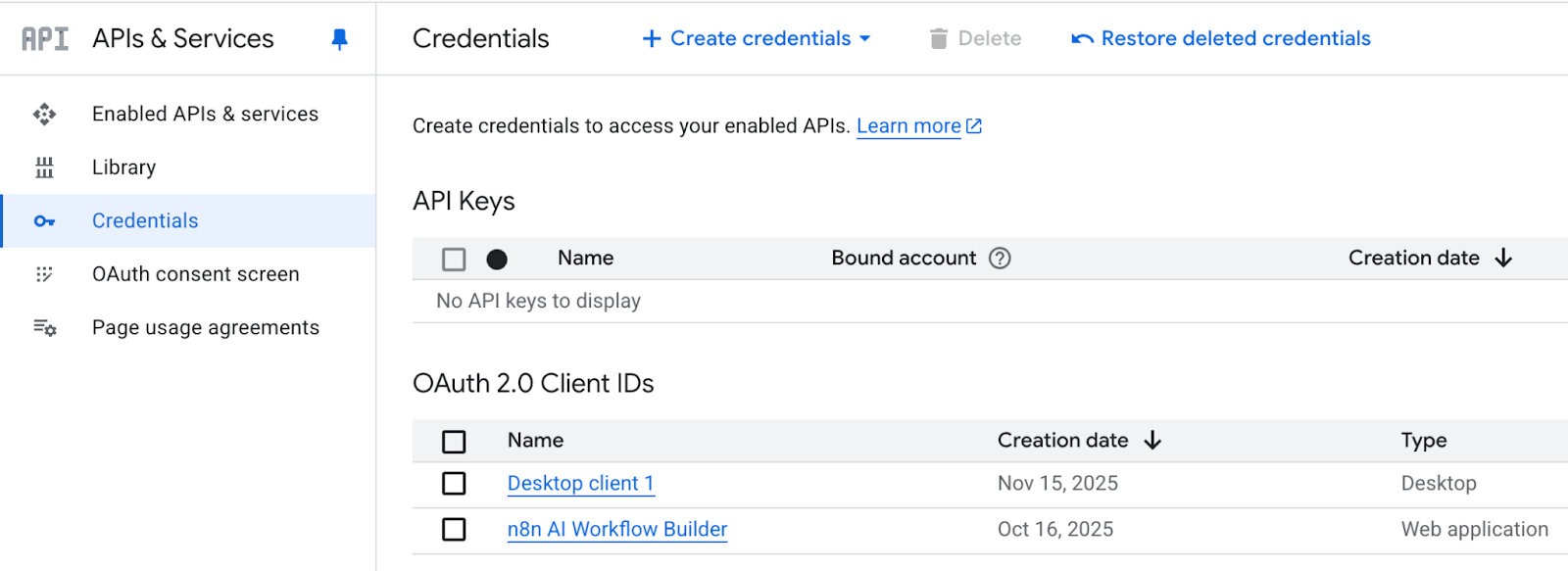
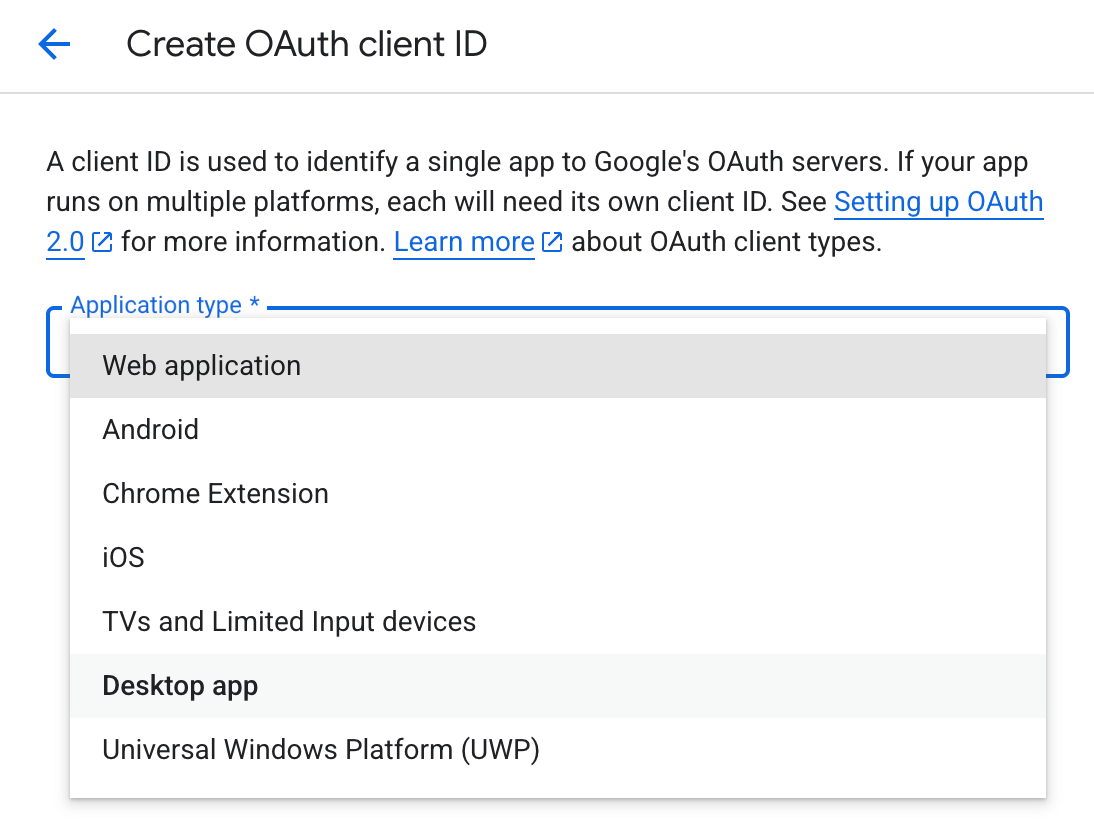
Es kann bis zu 5 Minuten dauern, bis die Client-ID und der geheime Schlüssel zusammen mit einer herunterladbaren JSON-Datei generiert sind.
Speicher die JSON-Datei als „ credentials.json ” im selben Ordner wie deine „ app.py ” (oder gib den Pfad dazu in deinen App-Einstellungen an).
Du hast jetzt einen Desktop-OAuth-Client, mit dem die App eine browserbasierte Anmeldung starten und in deinem Namen die Berechtigung für den Zugriff auf Google Docs anfordern kann.
Die App muss wissen, an welches Dokument sie etwas anhängen soll. Dieses Dokument wird durch eine eindeutige ID identifiziert, die in der URL eingebettet ist. Für diesen Schritt
Öffne dein Google Doc in einem Browser.
Kopiere den Teil der URL zwischen /d/ und /edit, zum Beispiel: https://docs.google.com/document/d//edit
Füge das hier ein Doc-ID in das Feld „Google Doc ID” der App (oder die passende Konfigurationsvariable).
Mit der richtigen Dokument-ID speichert die App die Zusammenfassungen genau in dem Dokument, das du ausgewählt hast.
Beim ersten Anhängen braucht die App deine ausdrückliche Zustimmung, um auf das Dokument zugreifen zu können. Sobald du das okay gibst, schickt Google ein Token zurück, das die App lokal als „ token.json “ speichert. So wird diese Datei erstellt:
Starte die App und klick auf „An Google Doc anhängen “.
Es öffnet sich ein Browserfenster, in dem du dich mit einem der Testbenutzer anmelden musst, die du im vorherigen Schritt hinzugefügt hast, und den Umfang genehmigen musst.
Nachdem du das bestätigt hast, schreibt die App „ token.json “ neben deinen Code. Diese Datei hat deine wiederverwendbaren Zugriffs-/Aktualisierungstoken.
Anmerkung: Wenn du mal das Konto wechseln oder die Einwilligung erneut ausführen musst, lösche einfach „ token.json “ und klicke erneut auf „Zu Google Doc hinzufügen “.
Bevor wir irgendwelche Logik schreiben, importieren wir die Module, die die Benutzeroberfläche, typisierte Datenverträge, Modellaufrufe und die Google Docs-Integration unterstützen. Das Gruppieren von Importen nach Zweck hält den Code übersichtlich und macht klar, welche Ebene man überprüfen muss, wenn was nicht klappt.
import os
import io
import json
from datetime import date
from typing import List, Optional
import streamlit as st
from pydantic import BaseModel, Field
from dotenv import load_dotenv
# ---- LangChain v1 surface ----
from langchain.agents import create_agent
from langchain.messages import SystemMessage, HumanMessage
from langchain.chat_models import init_chat_model
# ---- Google Docs API ----
from google.oauth2.credentials import Credentials
from google_auth_oauthlib.flow import InstalledAppFlow
from googleapiclient.discovery import buildIn diesem Schritt importieren wir nur das, was die App braucht, also Standard-Utilities wie os, io, json, date und Typhinweise für Pfade, Puffer und leichte Serialisierung. Dann importieren wir Streamlit für die Benutzeroberfläche, Pydantic für die Typisierungsschemata von RecapDoc und dotenv zum Laden von Umgebungsvariablen. Die LangChain v1-Oberflächen init_chat_model und create_agent, um ein providerunabhängiges Chat-Modell zu starten und Prompts zu strukturieren, und schließlich dieGoogle Docs API-Teile, die OAuth verarbeiten und uns einen authentifizierten Client geben, um Zusammenfassungen an das ausgewählte Dokument anzuhängen.
Damit die Antwort des Modells zuverlässig und einfach zu benutzen ist, legen wir einen typisierten Vertrag für die Zusammenfassung fest. Durch die Verwendung von Pydantic-Modellen stellen wir sicher, dass das LLM vorhersehbare Felder zurückgibt, die unsere Benutzeroberfläche rendern, die API speichern und die Automatisierungen validieren kann.
class ActionItem(BaseModel):
owner: str = Field(..., description="Person responsible")
task: str = Field(..., description="Short, specific task")
due_date: str = Field(..., description="ISO date (YYYY-MM-DD) or natural language like 'next Friday'")
class RecapDoc(BaseModel):
title: str
date: str
attendees: List[str]
summary: str
decisions: List[str]
action_items: List[ActionItem]Hier sind die wichtigsten Teile des obigen Code-Blocks:
ActionItem Klasse: Es fasst die wichtigsten Punkte von Folgeaufgaben wie owner, task und due_date mit kurzen, klaren Beschreibungen zusammen, damit das Modell sie sauber ausfüllen kann. Die Zulassung von ISO-Datumsformaten wie„ “ oder natürlichen Ausdrücken macht die Eingabe flexibel und ermöglicht trotzdem eine spätere Analyse.
RecapDoc Klasse: Diese Klasse zeigt die ganze Zusammenfassung als ein einziges Objekt, einschließlich „ title “, „ date “, „ attendees “, einem knappen „ summary “, expliziten „ decisions “ und einer Liste von „ action_items “.
Mit LangChain v1 kannst du dieses Schema direkt über with_structured_output(RecapDoc) anfordern. Das macht das Parsen von Zeichenfolgen einfacher, verbessert die Validierung und lässt dich schnell erkennen, wenn Felder fehlen.
Die Systemaufforderung legt die Grundregeln für deinen Assistenten fest. Es sagt dem Modell genau, was es machen soll, was es vermeiden soll und wie es seine Ergebnisse so aufbauen soll, dass die nächsten Schritte immer zuverlässig funktionieren.
SYSTEM_PROMPT = """You are a precise assistant that produces concise, high-signal meeting recaps.
Return a structured RecapDoc with:
- title, date, attendees
- a brief summary (3–6 sentences)
- explicit decisions (bullet-style)
- action_items (each has owner, task, due_date)
Rules:
- Only include info supported by the notes or explicit user inputs.
- Keep action items specific with clear owners and due dates.
- If something is unknown, say "Unknown" rather than inventing details.
"""Die Systemaufforderung macht den Assistenten präzise und knapp, sodass er sich auf Zusammenfassungen mit hohem Informationsgehalt statt auf Transkripte konzentriert. Es druckt ein übersichtliches Schema aus, das einen Titel, das Datum, die Teilnehmer, eine Zusammenfassung, Entscheidungen und Aktionspunkte mit Regeln wie einer 3- bis 6-zeiligen Zusammenfassung, stichpunktartigen Entscheidungen und Aktionspunkten mit Verantwortlichem, Aufgabe und Fälligkeitsdatum enthält.
Mit einer klaren Systemaufforderung macht das Modell beim ersten Versuch immer brauchbare, strukturierte Zusammenfassungen.
In diesem Schritt machen wir eine Hilfsfunktion, die eine vertrauenswürdige, wiederverwendbare Verbindung zu Google Docs aufbaut, damit die App Zusammenfassungen an dein ausgewähltes Dokument anhängen kann. Es fragt nur den Docs-Bereich ab und kümmert sich um die erstmalige Einwilligung, die Aktualisierung des Tokens und den Aufbau des Dienstes.
SCOPES = ["https://www.googleapis.com/auth/documents"]
def get_google_docs_service(
credentials_path: Optional[str],
token_path: str = "token.json",
use_secrets: bool = False
):
creds = None
if use_secrets:
try:
if "google_credentials_json" in st.secrets:
with open("credentials_temp.json", "w") as f:
f.write(st.secrets["google_credentials_json"])
credentials_path = "credentials_temp.json"
except Exception:
pass
if os.path.exists(token_path):
creds = Credentials.from_authorized_user_file(token_path, SCOPES)
if not creds or not creds.valid:
if creds and creds.expired and creds.refresh_token:
try:
creds.refresh(Request())
except Exception:
pass
if not creds or not creds.valid:
if not credentials_path or not os.path.exists(credentials_path):
raise RuntimeError(
"Missing Google OAuth credentials. Provide 'credentials.json' "
"or set st.secrets['google_credentials_json']."
)
flow = InstalledAppFlow.from_client_secrets_file(credentials_path, SCOPES)
creds = flow.run_local_server(port=0)
with open(token_path, "w") as token:
token.write(creds.to_json())
return build("docs", "v1", credentials=creds)Die Funktion „ get_google_docs_service()“ kümmert sich um OAuth und die Erstellung von Diensten, indem sie:
Zugriffsbereich: Die obige Funktion nutzt vordefinierte „ SCOPES“, um die Berechtigungen für Google Docs einzuschränken.
Anmeldedaten werden geladen: Es liest aus einer lokalen Datei „ credentials.json “ oder aus„ st.secrets["google_credentials_json"] “, dem geheimen Speicher von Streamlit, wenn „ use_secrets=True “ ist.
Wiederverwendung von Tokens: Wenn die Datei „ token.json “ da ist, lädt der Code sie und aktualisiert sie stillschweigend, falls das Token abgelaufen ist.
Einmalige Zustimmung: Wenn kein gültiges Token gefunden wird, starten wir den Desktop- InstalledAppFlow, der den Benutzer im Browser zur Authentifizierung auffordert und dann token.json für zukünftige Ausführungen speichert.
Rückgabe eines Kunden: Zum Schluss erstellen und übergeben wir einen authentifizierten Docs-Client über die Funktion „ build()“.
Sobald du alles eingerichtet hast, kannst du denselben „ token.json ” für die Authentifizierung wiederverwenden oder das Token automatisch aktualisieren. Um den Zugriff zurückzusetzen, lösch einfach „ token.json “ und starte die App nochmal.
Als Nächstes machen wir aus einem getippten Dokument „ RecapDoc “ sauberes Markdown, das wir an das Google Doc angehängt haben. Eine Funktion macht die Zusammenfassung, während die andere am Ende des Dokuments das authentifizierte Schreiben macht.
def append_plaintext_to_doc(docs_service, document_id: str, text: str):
doc = docs_service.documents().get(documentId=document_id).execute()
end_index = doc.get("body", {}).get("content", [])[-1]["endIndex"]
requests = [
{
"insertText": {
"location": {"index": end_index - 1},
"text": text + "\n"
}
}
]
return docs_service.documents().batchUpdate(
documentId=document_id,
body={"requests": requests}
).execute()
def recap_to_markdown(recap: RecapDoc) -> str:
lines = [
f"# {recap.title} — {recap.date}",
"",
f"**Attendees:** {', '.join(recap.attendees) if recap.attendees else 'Unknown'}",
"",
"## Summary",
recap.summary.strip(),
"",
"## Decisions",
]
if recap.decisions:
for d in recap.decisions:
lines.append(f"- {d}")
else:
lines.append("- None recorded")
lines.append("")
lines.append("## Action Items")
if recap.action_items:
for ai in recap.action_items:
lines.append(f"- **{ai.owner}** — {ai.task} _(Due: {ai.due_date})_")
else:
lines.append("- None recorded")
return "\n".join(lines)Die beiden oben genannten Helfer arbeiten wie folgt zusammen:
Die Funktion „ recap_to_markdown() “ erstellt eine übersichtliche Zusammenfassung. Es hat einen Titel mit Datum, Teilnehmern, einer kurzen Zusammenfassung und Aktionspunkten mit Verantwortlichem, Aufgabe und Fälligkeitsdatum. Wenn Felder fehlen, wird auch „Unbekannt“ oder „Keine Angabe“ angezeigt.
Die Funktion „ append_plaintext_to_doc() “ ruft das Dokument ab, findet den aktuellen Endindex und sendet eine einzelne Anfrage „ insertText “ über „ documents() “. Der Text hat am Ende einen Zeilenumbruch, damit die nächsten Einträge in einer neuen Zeile starten.
Anmerkung: Bei leeren Dokumenten solltest du den Einfügeindex auf 1 setzen, wenn „ endIndex ” nicht verfügbar ist.
Nachdem wir Markdown-Rendering und -Anhängen eingerichtet haben, machen wir uns als Nächstes an unseren Recap-Generator.
Diese Funktion ist das Herzstück der App. Es nimmt Rohnotizen und optionale Metadaten, ruft ein Chat-Modell auf und gibt ein typisiertes „ RecapDoc “ zurück, damit alles nachgelagerte vorhersehbar bleibt.
def generate_recap(model_name: str, notes: str, title: str, date_str: str, attendees_csv: str) -> RecapDoc:
model = init_chat_model(model=model_name)
structured_llm = model.with_structured_output(RecapDoc)
attendees_hint = [a.strip() for a in attendees_csv.split(",")] if attendees_csv.strip() else []
user_prompt = (
"You will receive meeting notes and metadata.\n\n"
f"Title: {title or 'Unknown'}\n"
f"Date: {date_str or 'Unknown'}\n"
f"Attendees: {attendees_hint if attendees_hint else 'Unknown'}\n\n"
"Notes:\n"
f"{notes.strip()}\n"
)
messages = [
SystemMessage(content=SYSTEM_PROMPT),
HumanMessage(content=user_prompt)
]
try:
recap = structured_llm.invoke(messages)
except Exception as e:
st.error(f"Error generating recap: {e}")
recap = RecapDoc(
title=title or "Unknown",
date=date_str or "Unknown",
attendees=attendees_hint or [],
summary=f"Error generating summary: {str(e)}",
decisions=[],
action_items=[]
)
return recapDer Recap-Generator hat drei Hauptteile:
Modellinitialisierung: Die Funktion „ init_chat_model() ” macht ein Chat-Modell für den Anbieter, den du ausgewählt hast. Dann rufen wir die Funktion „ with_structured_output() “ auf, um dem Modell genau zu sagen, welche Form es zurückgeben soll. Es gibt ein Python-Objekt aus, das mit den Feldern „ RecapDoc “ übereinstimmt.
Schnelle Montage: Wir normalisieren Eingaben und verschicken zwei Nachrichten: eine „ SystemMessage “ mit strengen Regeln (die Systemaufforderung) und eine „ HumanMessage “ mit Titel, Datum, Teilnehmern und Rohnotizen.
Strukturierte Erzeugung: Die Funktion „ structured_llm.invoke() “ gibt ein validiertes „ RecapDoc “ zurück, wodurch Parsing vermieden und Halluzinationen reduziert werden.
Wenn du dein GPT-Modell über den strukturierten Ausgabe-Wrapper von LangChain laufen lässt, wird der Recap-Schritt zuverlässig und bereit für die Markdown-Darstellung, ohne dass du irgendwelche nachgelagerten Logiken ändern musst.
Dieser Schritt verbindet die ganze Demo zu einer einseitigen Streamlit-App. Der Nutzer fügt Notizen ein, kann Metadaten hinzufügen, erstellt eine strukturierte Zusammenfassung, schaut sie sich als Markdown an und hängt sie mit einem Klick an ein Google Doc an.
def main():
load_dotenv()
st.set_page_config(page_title="Meeting Recap Assistant (LangChain v1)", page_icon=" ", layout="wide")
st.markdown("<h1 style='text-align: center;'>Meeting Recap Assistant With LangChain v1</h1>", unsafe_allow_html=True)
model_name = os.getenv("LC_MODEL", "gpt-4o-mini")
document_id = "10G1k8-2JG_phkpjWM3xZEy2wNg5trUO0SJ2WN7kR3po"
cred_mode = "credentials.json file"
credentials_path = os.getenv("GOOGLE_CREDENTIALS_JSON", "credentials.json")
st.subheader(" Add your meeting notes")
colL, colR = st.columns([2, 1])
with colL:
notes = st.text_area(" ", height=300, placeholder="Paste your raw notes here...")
with colR:
title = st.text_input("Meeting Title", value="")
date_str = st.date_input("Meeting Date", value=date.today())
attendees_csv = st.text_input("Attendees (comma-separated)", value="")
if "recap" not in st.session_state:
st.session_state.recap = None
if "markdown_text" not in st.session_state:
st.session_state.markdown_text = None
col1, col2, col3 = st.columns([1, 1, 2])
with col1:
generate_btn = st.button("Generate Recap")
with col2:
append_btn = st.button("Append to Google Doc", disabled=(st.session_state.recap is None))
if generate_btn:
if not notes.strip():
st.error("Please paste some notes.")
st.stop()
try:
recap = generate_recap(
model_name=model_name,
notes=notes,
title=title,
date_str=str(date_str),
attendees_csv=attendees_csv,
)
st.session_state.recap = recap
st.session_state.markdown_text = recap_to_markdown(recap)
st.rerun()
except Exception as e:
st.exception(e)
st.stop()
if append_btn and st.session_state.recap is not None:
try:
use_secrets = (cred_mode == "Streamlit secrets")
service = get_google_docs_service(
credentials_path=credentials_path if cred_mode == "credentials.json file" else None,
use_secrets=use_secrets
)
final_text = f"\n\n===== {st.session_state.recap.title} — {st.session_state.recap.date} =====\n\n" + st.session_state.markdown_text
append_plaintext_to_doc(service, document_id, final_text)
st.success("Recap appended to the Google Doc")
except Exception as e:
st.exception(e)
if st.session_state.recap is not None:
st.markdown("---")
st.markdown(st.session_state.markdown_text)
if __name__ == "__main__":
main()Die Streamlit-App verbindet eine einzige Aktion „Zusammenfassung erstellen“ mit dem Modell und macht sie über eine lokale Web-Benutzeroberfläche zugänglich, indem sie Folgendes verwendet:
Eingaben (linke/rechte Spalte): Der linke Bereich ist ein großes Notizfeld namens „ st.text_area “ für deine Notizen. Im rechten Fensterbereich werden Titel, Datum und Teilnehmer angezeigt.
Ausgaben (Vorschau-Bereich): Wenn es eine Zusammenfassung gibt, zeigt die App einen Trennbalken und eine Markdown-Vorschau der strukturierten Zusammenfassung an, damit du sie schnell checken kannst.
Schnittstellenverkabelung (Aktionen): Diese Aktionen sind das Herzstück unserer App. Es umfasst:
Zusammenfassung erstellen: Es überprüft Notizen, ruft die Funktion „generate_recap()“ auf, die sie in Markdown umwandelt, und „ st.rerun() “, um sie zu aktualisieren.
An Google Doc anhängen: Als Nächstes erstellen wir einen authentifizierten Client mit „ get_google_docs_service() “, der einen datierten Header hinzufügt und an das Zieldokument anhängt.
Zustand: Die Methode „ st.session_state “ speichert die neuesten Werte für „ RecapDoc “ und „ markdown_text “, damit die Benutzeroberfläche bei jedem Neustart stabil bleibt.
App-Einrichtung: Schließlich liest die Methode „ load_dotenv() “ die Umgebungsvariablen, während „ st.set_page_config() “ das Layout festlegt und die Pfade für die Anmeldedaten aus der Umgebung oder den Standardeinstellungen kommen.
Speicher das als „ app.py “ und mach den folgenden Befehl im Terminal.
streamlit run app.pyJetzt hast du ein Tool für die komplette Zusammenfassung von Meetings, das so aussieht:


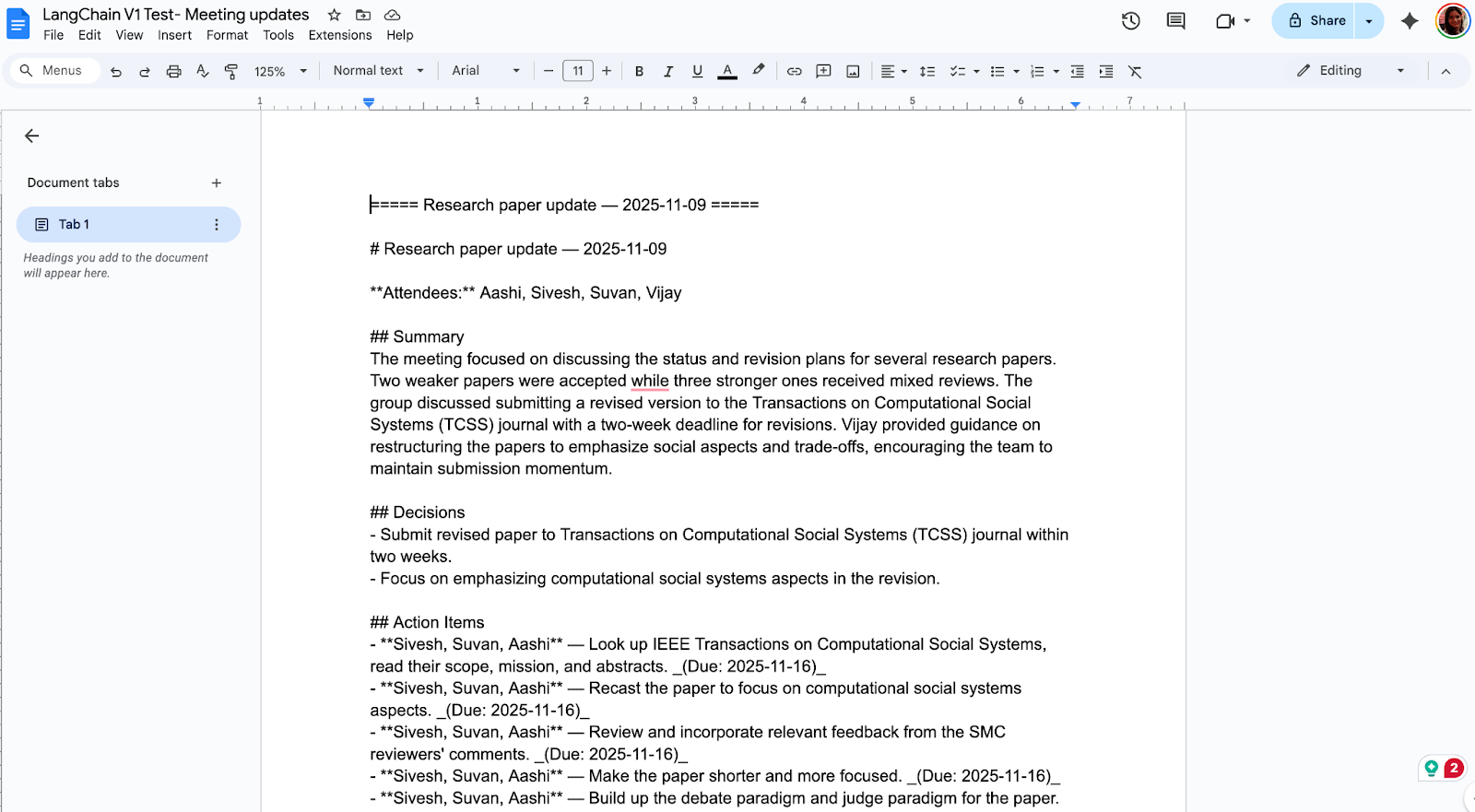
LangChain v1 macht das Erstellen von Agenten einfacher, mit leichteren Importen und zuverlässigeren Ergebnissen, weil es strukturierte Ausgaben und Standard-Inhaltsblöcke hat. Wenn du von Version 0 kommst, mach das Upgrade wie jede andere Produktionsänderung mit Pin-Versionen, Refaktorisierung von Importen und neuen Primitiven.
Ein paar Sachen, die du beachten solltest, sind:
LangChain v1 nutzt „ create_agent ” anstelle der alten vorgefertigten Agenten, die auf Standard-Inhaltsblöcken und strukturierter Ausgabe basierten. Beachte, dass einige ältere Teile zu „ langchain-classic ” verschoben wurden.
Wenn du ein Upgrade machst, setz „ langchain>=1.0 “ als Pin und nimm Python 3.10+. Nimm lieber Pydantic-Modelle für die Ausgabe, füge Middleware nur hinzu, wenn es sinnvoll ist (Genehmigungen, Schwärzung personenbezogener Daten, Zusammenfassungen), und behalte langchain-classic, wenn du noch alte Retriever brauchst.
Schick zuerst eine kleine Eingabe und schau dir die Spuren und Fehler an, während du die Abhängigkeiten festhältst.
LangChain v1 bietet dir übersichtlichere Primitive für echte Apps, strukturierte Ausgaben, auf die du dich verlassen kannst, standardisierte Inhaltsblöcke für alle Anbieter und eine einheitliche Methode zum Erstellen von Agenten. Hier sind ein paar praktische Tipps, wie du das umsetzen kannst, und ein paar Probleme, die bei der Einführung auftauchen können.
Einige wichtige Anwendungsfälle dieser Version sind:
Bei den wirklich wichtigen Anwendungsfällen gibt's ein paar Herausforderungen:
Für die Zukunft können wir davon ausgehen, dass es weiterhin um Ausdauer, Zeitreisen und Beobachtbarkeit (über LangGraph und LangSmith) gehen wird, zusammen mit einer breiteren Unterstützung von Anbietern für Standard-Inhaltsblöcke und klareren Kontrollen für Produktionsteams.
LangChain v1 ist eine solide Basis, um zuverlässige und wartungsfreundliche Agenten zu entwickeln. Dieser Assistent für automatische Besprechungszusammenfassungen zeigt, wie „ create_agent “, Standardinhaltsblöcke und strukturierte Ausgaben zusammenarbeiten, um einen echten Arbeitsablauf mit menschlicher Genehmigung und nahtloser Übergabe an Google Docs zu bewältigen. Nutze die offiziellen Migrationsanleitungen, um alten Code auf den neuesten Stand zu bringen, und fang mit einer kleinen Tutorial-App wie dieser an, um dich langsam reinzuarbeiten.
Wenn du mehr praktische Erfahrung mit der Entwicklung von KI-gestützten Anwendungen sammeln möchtest, empfehle ich dir unseren Kurs „Entwickeln von Anwendungen mit LangChain ”.
Lerne mit DataCamp
Kurs
Kurs
Kurs
Blog
Tutorial
DataCamp Team
Tutorial
Mark Pedigo
Tutorial
Satyabrata Pal
Tutorial
Adel Nehme
