
Cursus
Les fondamentaux du lama
4 h
Langflow est un outil à code bas qui nous permet de créer des flux de travail d'agents d'IA et d'automatiser des tâches en utilisant diverses API.
Dans cet article, je vais vous expliquer pas à pas comment utiliser Langflow pour créer des flux de travail d'agents d'IA personnalisés à l'aide de Python. Je vais vous montrer comment construire un agent d'intelligence artificielle qui aide l'utilisateur à pratiquer ses compétences en lecture lorsqu'il apprend une nouvelle langue.
Langflow nous permet d'automatiser des flux de travail en connectant différents composants, sans avoir à écrire de code. Chaque composant reçoit des sorties d'autres composants, effectue une action spécifique et fournit ensuite de nouvelles données en sortie.
Par exemple, lors de la création d'un chatbot d'IA, nous pouvons connecter un composant d'entrée de chat à un modèle de langage (LLM). La sortie du composant LLM peut ensuite être liée à un autre composant de sortie de chat.
En plus de la vaste collection de composants prédéfinis, nous pouvons construire des composants personnalisés à l'aide de Python. À un niveau élevé, un composant personnalisé est une fonction Python qui reçoit certaines entrées et émet certaines données.
Nous allons apprendre à utiliser des composants personnalisés pour construire un tuteur linguistique IA à l'aide de Python. Si vous souhaitez créer ce type de flux de travail sans code, je vous recommande de consulter ce tutoriel n8n (n8n est un outil similaire, et dans ce tutoriel, j'explique comment adopter une approche sans code pour construire un agent d'intelligence artificielle qui traite automatiquement les factures de votre boîte aux lettres électronique).
Nous pouvons utiliser Langflow gratuitement, soit sur leur site officiel soit en l'installant localement.
Dans ce tutoriel, nous utiliserons une configuration locale avec Docker. Vous n'avez pas besoin de connaître Docker pour suivre ce tutoriel. Mais si vous voulez en savoir plus, consultez ce guide Docker pour les débutants et ce cours sur Docker.
Docker est un outil qui nous permet d'exécuter des applications dans des environnements isolés appelés conteneurs, ce qui facilite le développement, le test et le déploiement de logiciels de manière cohérente. Dans notre cas, nous utilisons Docker car il offre plus de flexibilité pour construire des composants personnalisés avec Python, car nous pourrons utiliser une base de données locale et n'aurons pas besoin de nous connecter à un service externe.
Langflow fournit un exemple préconstruit prêt à être exécuté, de sorte que nous n'aurons pas à le configurer nous-mêmes.
Pour exécuter Langflow localement avec Docker, suivez les étapes suivantes :
docker_example.docker compose up.Maintenant, Langflow doit être lancé sur notre machine locale. Nous devrions voir ce message dans le terminal :
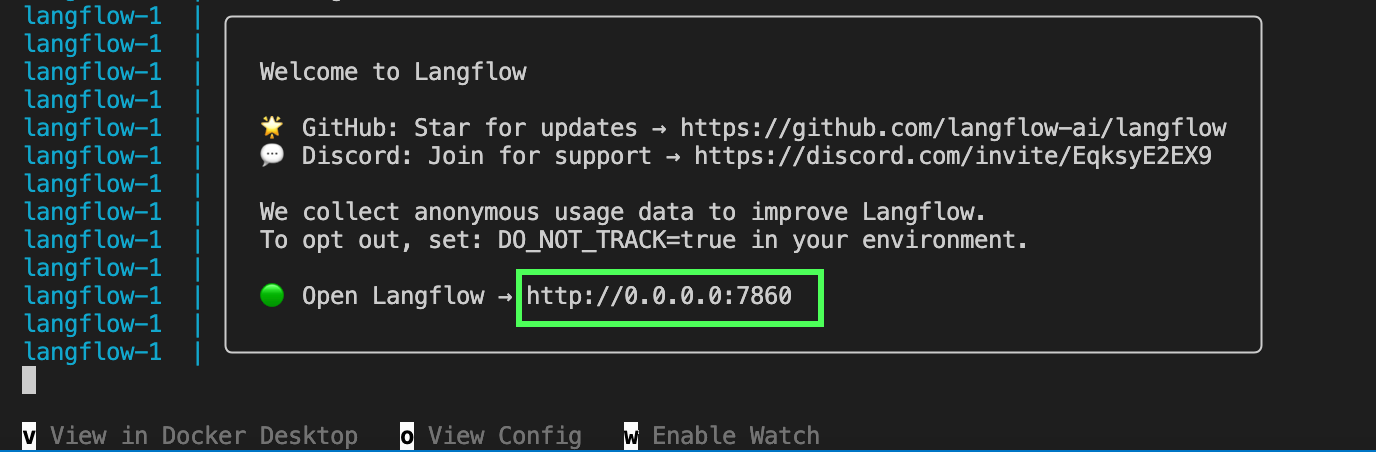
Nous pouvons ouvrir l'application en visitant l'URL affichée dans le terminal, http://0.0.0.0:7860 dans l'exemple ci-dessus.
Dans cette section, nous explorons le fonctionnement de Langflow en examinant le modèle simple d'agent d'intelligence artificielle de Langflow. Pour ce faire, nous sélectionnons "Agent simple" sur le premier écran.
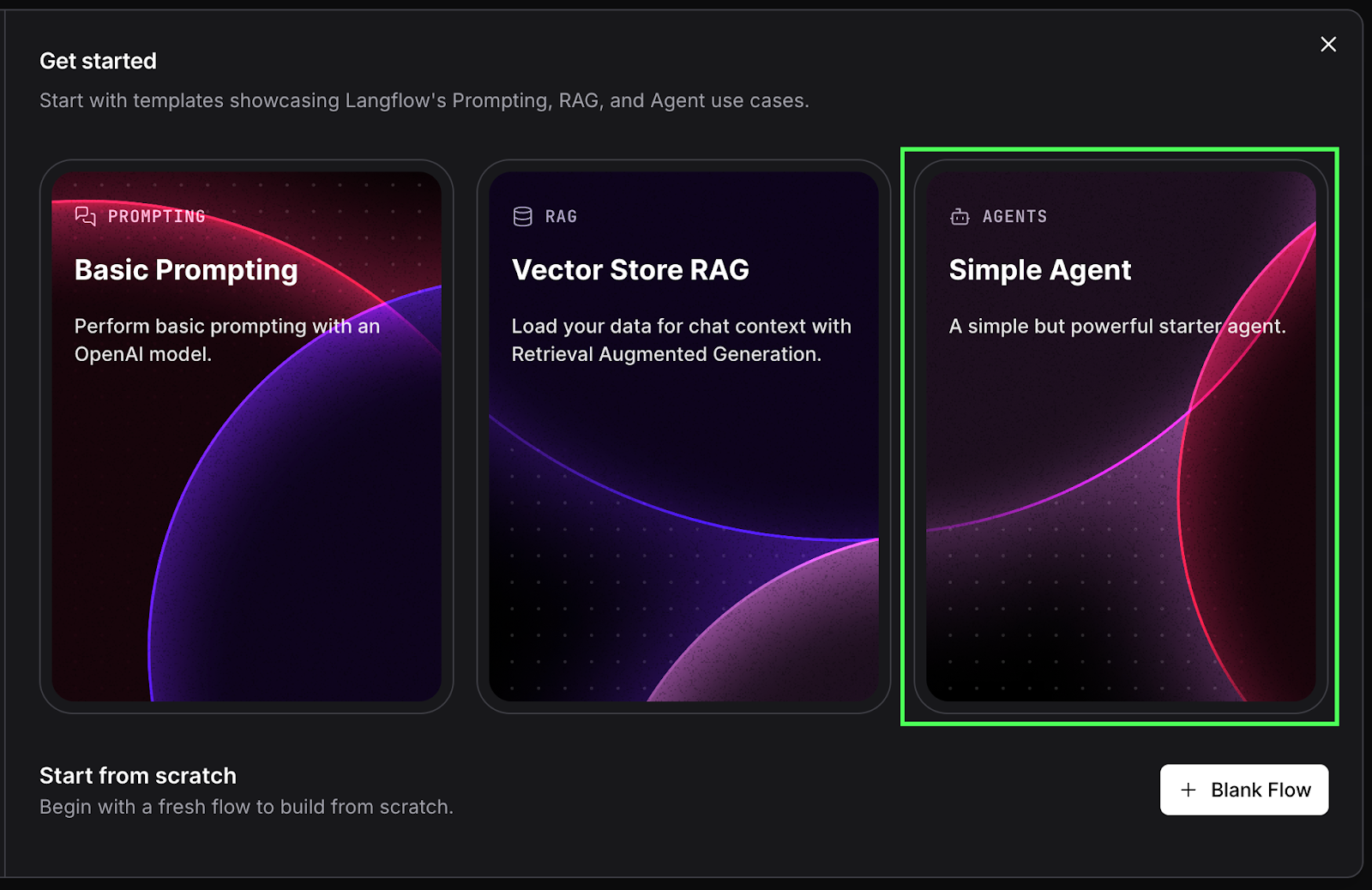
Cela créera un flux de travail de l'agent comme celui-ci :
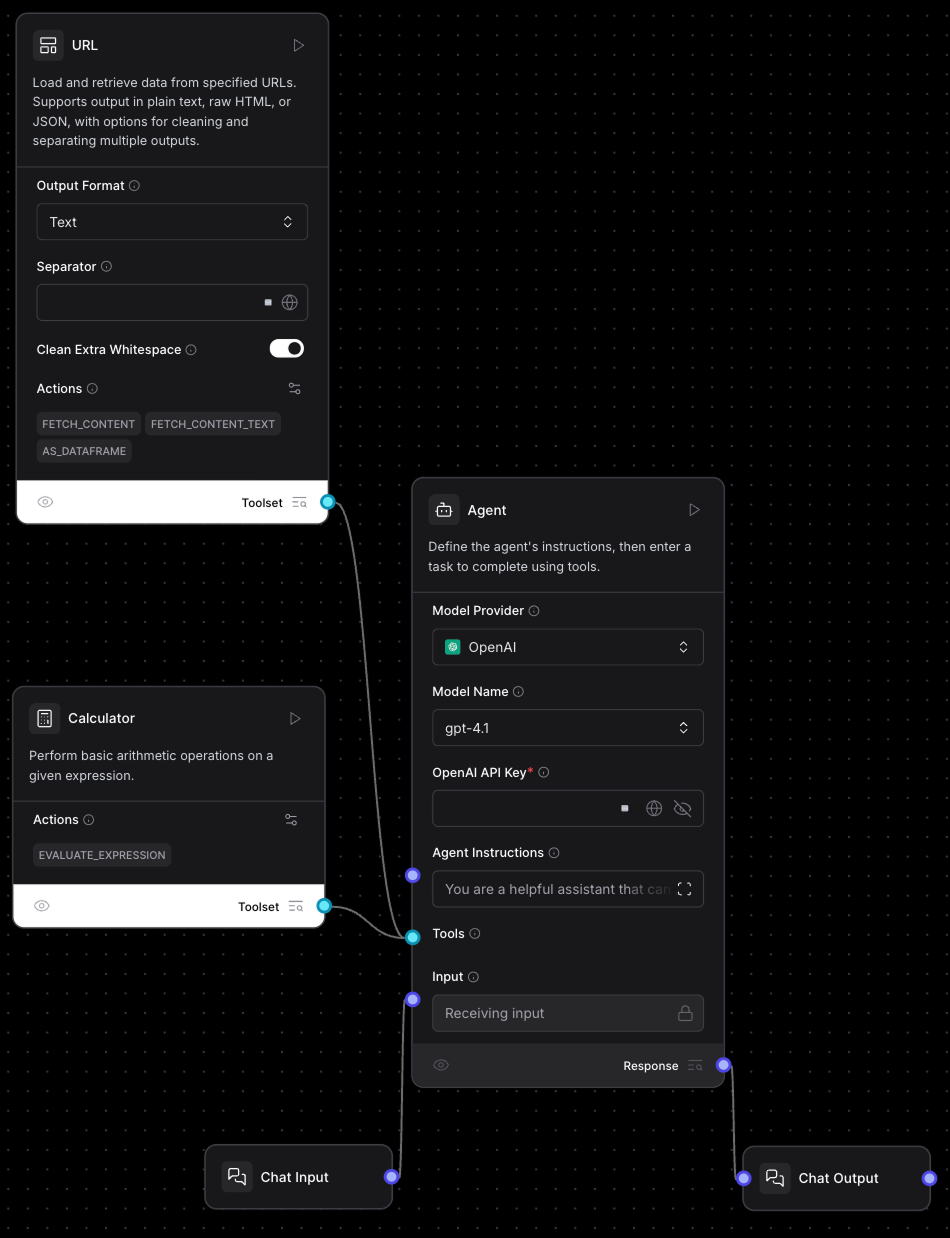
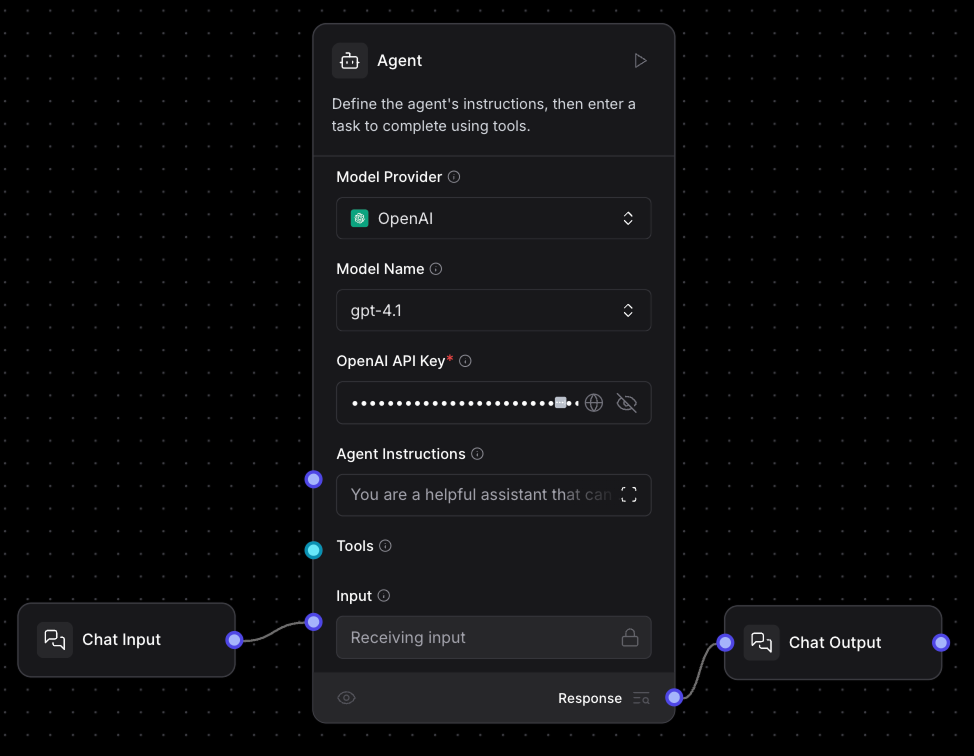
Le composant principal de ce flux de travail est le composant "Agent" situé au milieu :
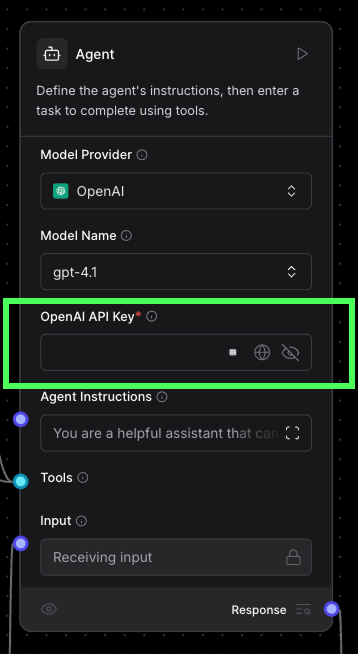
Cet agent utilise le modèle gpt-4.1 d'OpenAI. Pour l'utiliser, nous devons coller une clé API OpenAI. Si vous n'en avez pas encore, vous pouvez en créer un ici.
Sur la gauche du composant agent, nous voyons les entrées et les outils dont il dispose (voir l'image ci-dessous). Dans ce cas, il dispose de deux outils et d'une entrée :
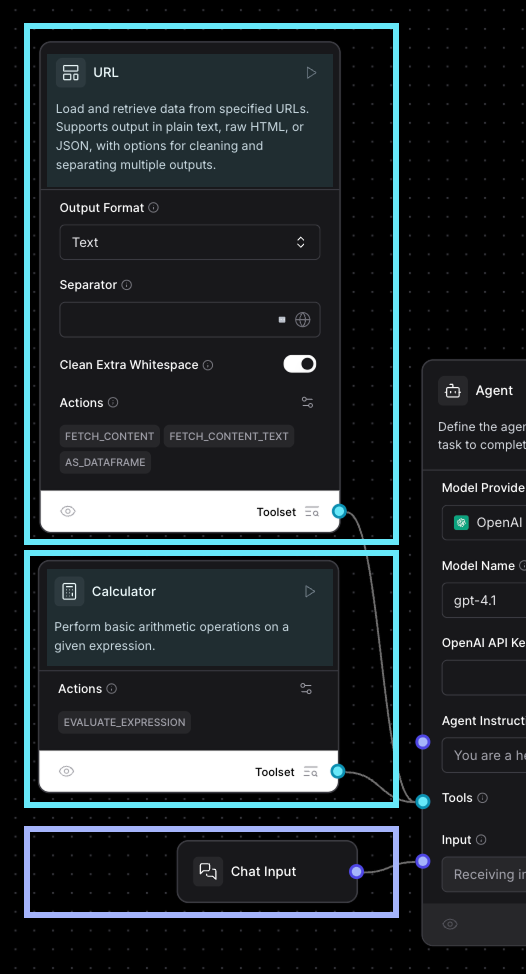
L'entrée "chat" signifie que lorsque nous exécutons le flux de travail, nous pouvons utiliser l'interface de chat intégrée à Langflow pour envoyer des messages au modèle. En haut de chaque outil, nous voyons une description. Le modèle utilise ces informations pour décider d'appeler ou non chaque outil.
À droite, nous voyons les résultats. Dans ce cas, il n'y a qu'un seul composant de sortie, qui est un composant de sortie de chat, indiquant que la réponse de l'agent doit être envoyée au chat.
Avant d'exécuter l'agent simple, utilisons le composant URL pour comprendre le fonctionnement général des composants. Créons-en une copie pour l'expérimenter.
En haut du nouveau composant, il y a un interrupteur "Tool Mode" ; désactivez-le.
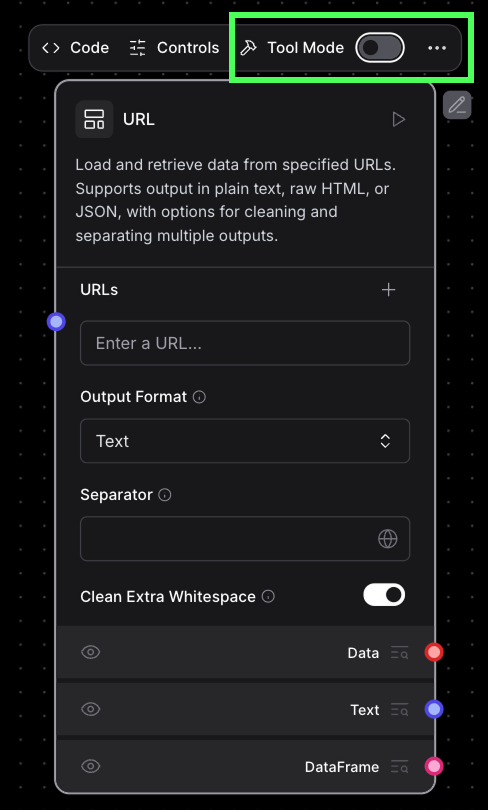
Dans le champ URL, indiquez, par exemple, https://en.wikipedia.org/wiki/Data_science, la page Wikipédia sur la science des données. Exécutez le composant en cliquant sur la flèche d'exécution dans le coin supérieur droit.
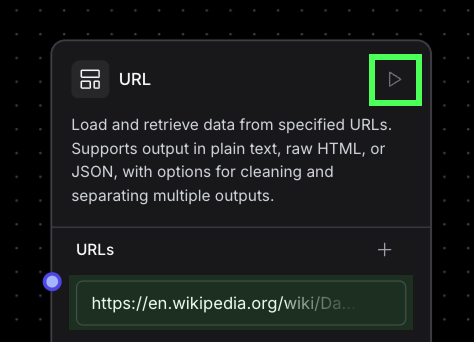
Le composant s'exécutera et chargera le contenu à partir de l'URL que nous avons fournie. Nous pouvons le voir en cliquant sur l'inspecteur à côté des liens de sortie. Chacun représente un format de sortie différent.
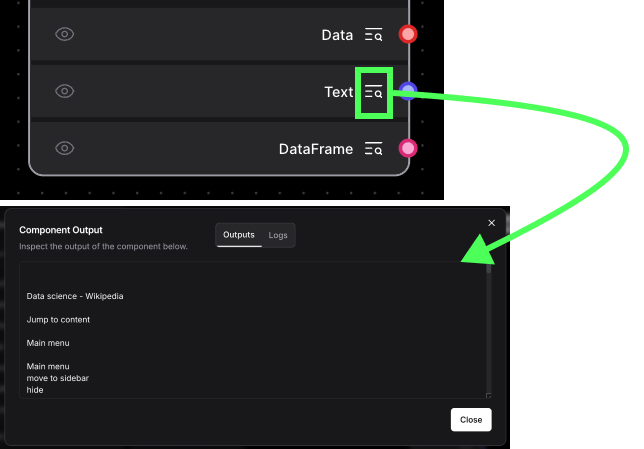
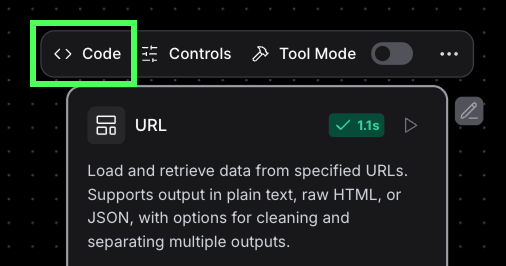
En coulisses, chaque nœud est un script Python. Nous en apprendrons plus à ce sujet lorsque nous construirons des nœuds personnalisés. Nous pouvons inspecter le code en cliquant sur le bouton "Code" en haut de la page :
Dans le flux de travail original de l'agent simple, le nœud URL est configuré pour être un outil. Cela signifie qu'il est destiné à être utilisé par un agent. Dans ce cas, les URL ne sont pas indiqués explicitement. Au lieu de cela, l'agent fournira lui-même les URL.
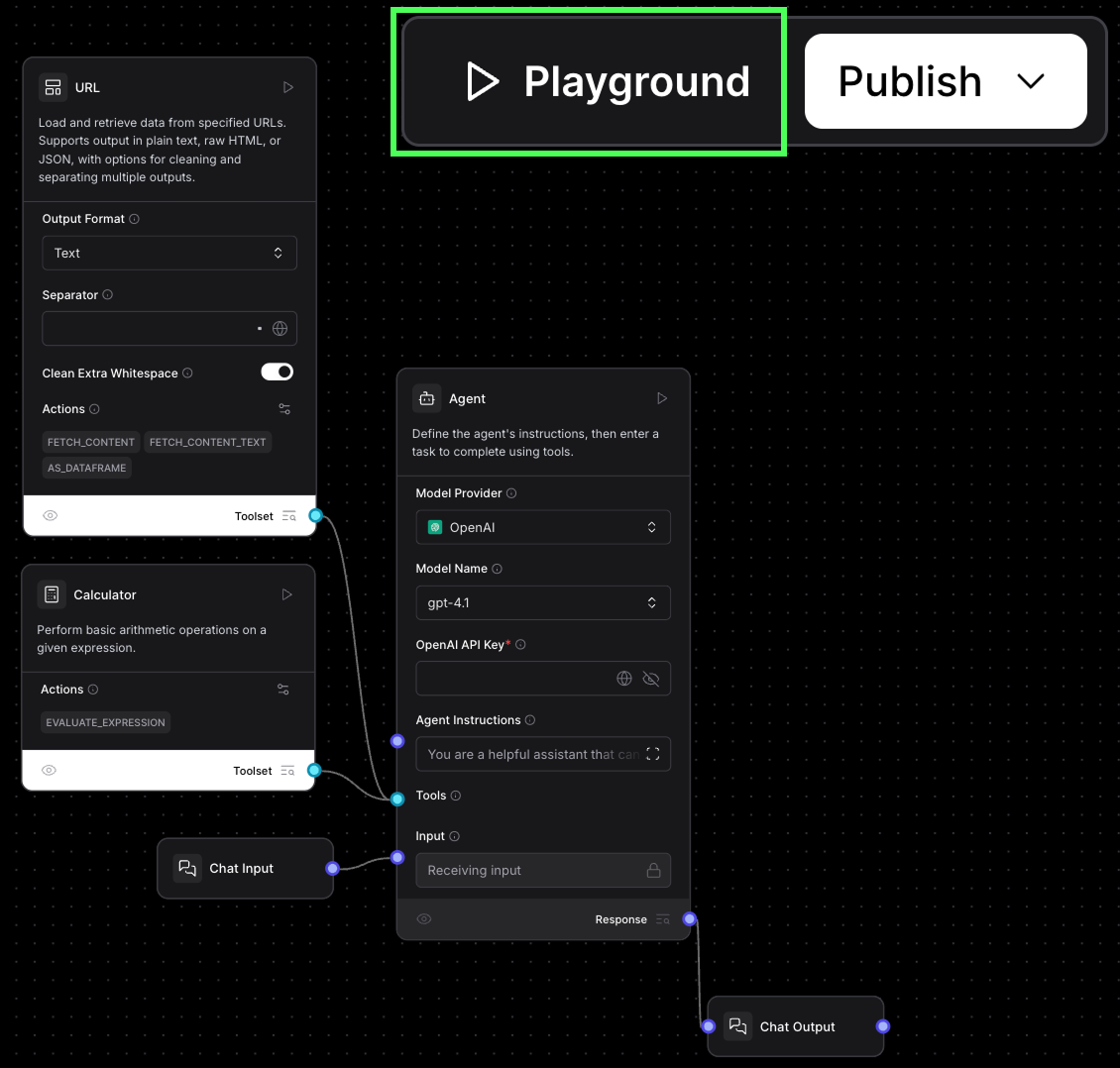
Revenons à l'agent simple, nous pouvons l'exécuter en cliquant sur le bouton "Playground" dans le coin supérieur droit. Cela ouvre l'interface de chat, qui nous permet de discuter avec l'agent.
Demandons-lui de résumer la page Wikipedia sur la science des données :
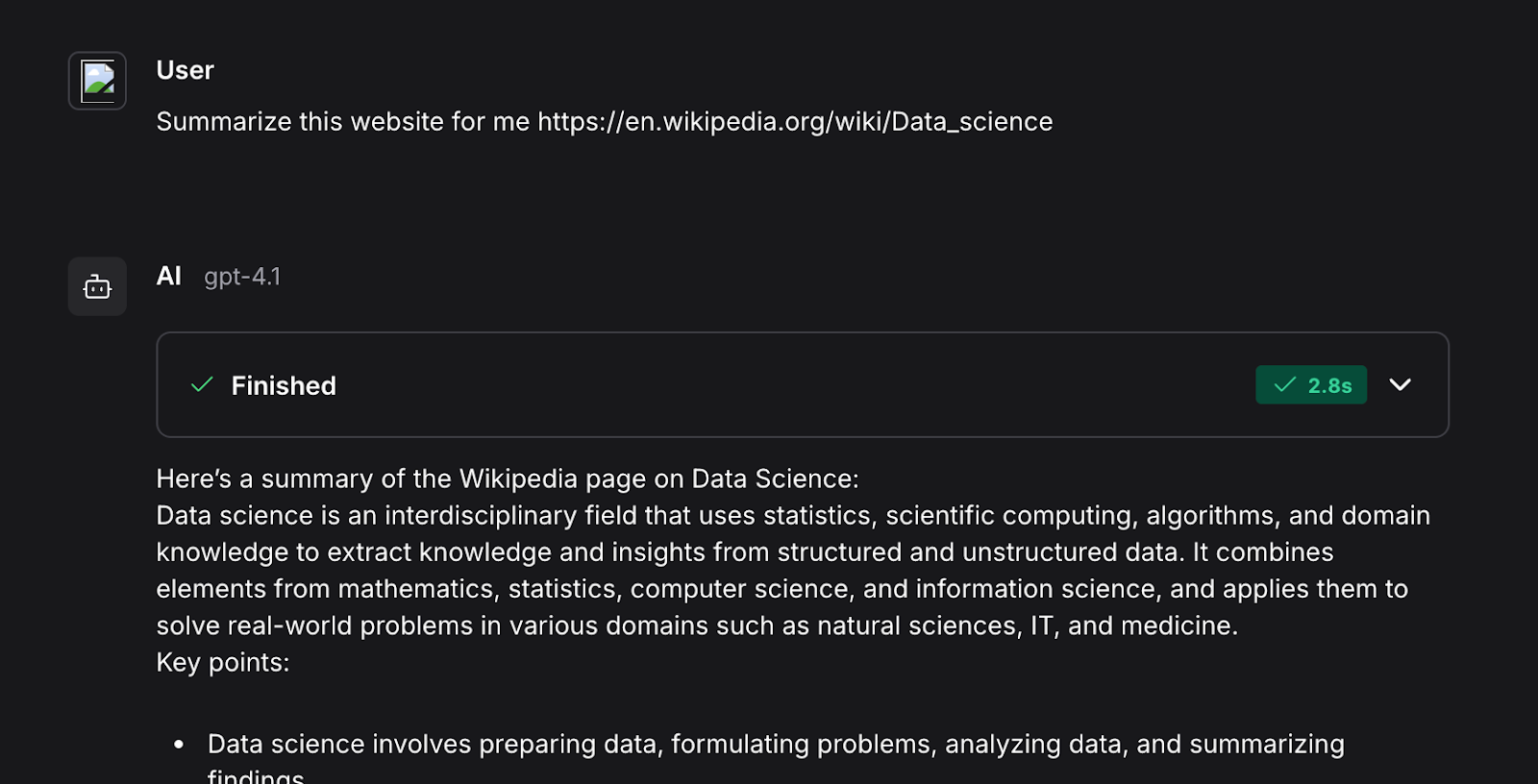
Si nous développons la boîte en haut de la réponse, nous verrons les étapes qui ont été exécutées dans le flux de travail.
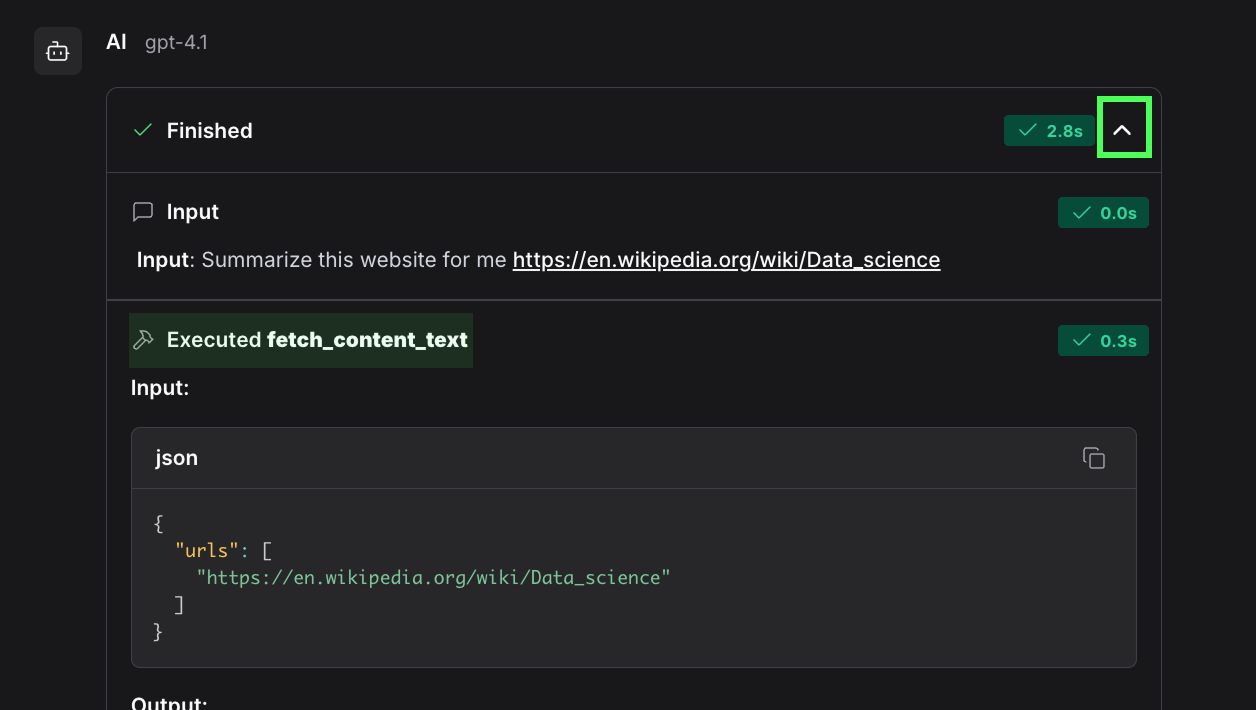
Nous voyons ici, par exemple, qu'il utilise la fonction fetch_content_text(), qui est définie dans l'outil URL que nous avons fourni à l'agent.
Nous pouvons tester son utilisation de l'outil Calcul en lui demandant d'effectuer un calcul. L'expression sera analysée et envoyée à l'outil pour évaluation. Cela permet d'obtenir une réponse plus fiable que si l'on se fie uniquement au LLM.
Dans cette section, nous apprenons à créer des composants personnalisés. Pour commencer, cliquez sur le bouton "Nouveau composant personnalisé" en bas à gauche :
Par défaut, cela crée un composant qui prend une valeur textuelle en entrée et produit ce même texte en sortie. L'entrée par défaut est "Hello, World !" et si nous l'exécutons et inspectons la sortie, nous constatons que c'est exactement ce que nous obtenons.
En inspectant le code, nous constatons ce qui suit :
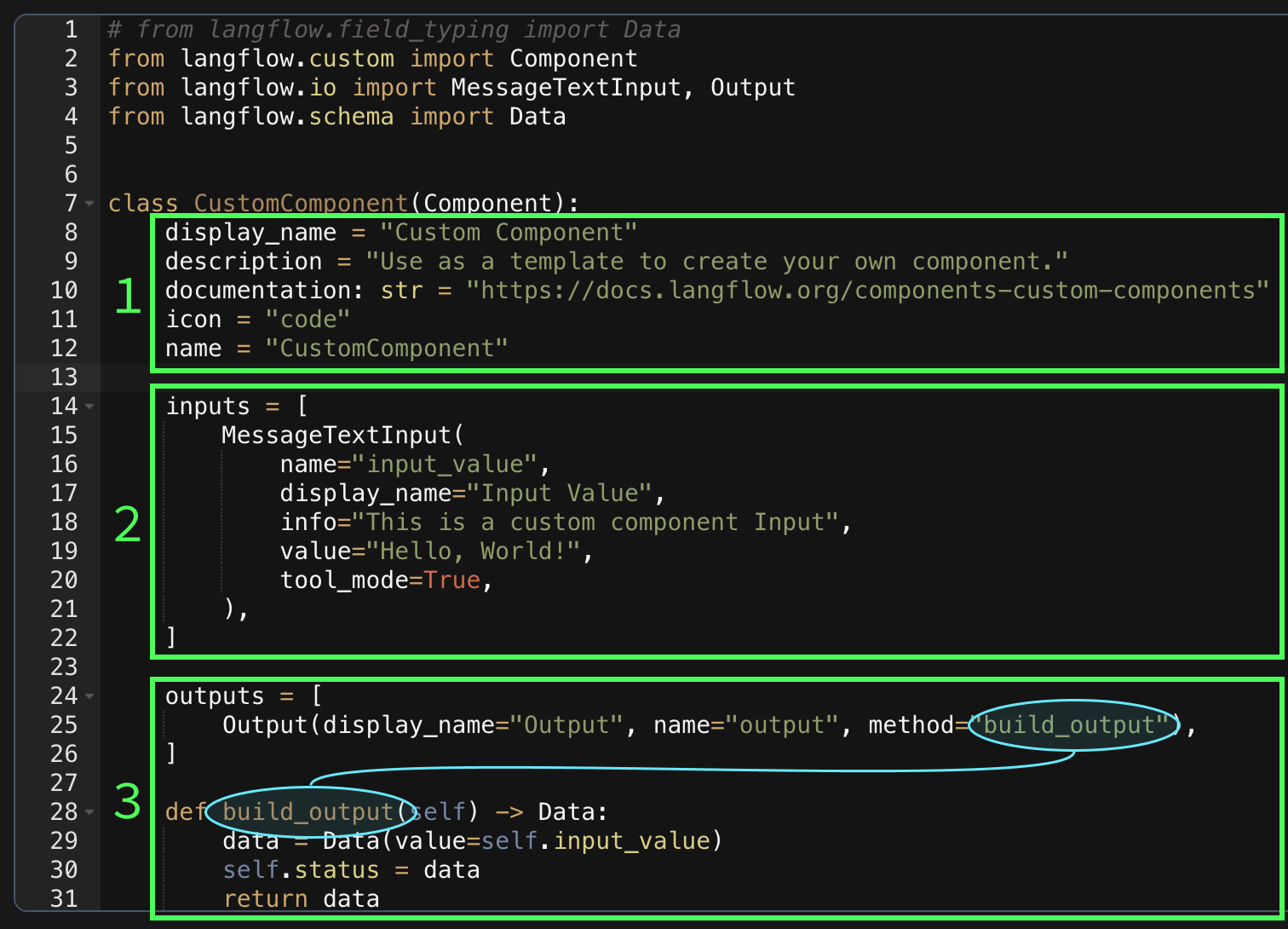
inputs spécifie les types d'entrées disponibles pour le composant. Dans ce cas, il comprend une seule entrée de la classe MessageTextInput nommée input_value, qui correspond au champ de texte. Le nom doit être un nom de variable Python valide car il devient un attribut de la classe. Lorsqu'un composant est défini comme un outil, ces entrées sont automatiquement remplies par l'agent d'intelligence artificielle. Il utilise le champ info pour déterminer la nature de l'entrée. Langflow prend en charge plusieurs types d'entrées. Vous trouverez ici une liste complète des entrées prises en charge.method indique la fonction qui est exécutée pour générer la sortie. La fonction a accès à l'entrée via self. Par exemple, l'entrée dans cette instance est nommée input_value, nous pouvons donc y accéder en utilisant self.input_value. La valeur de retour doit être une classe parmi les classes de sortie prises en charge.Pour plus d'informations sur la création d'un composant personnalisé, consultez la documentation officielle de Langflow sur les composants.
Voici un exemple de la façon dont nous pouvons créer un composant qui additionne deux nombres :
from langflow.custom import Component
from langflow.io import MessageTextInput, Output
from langflow.schema import Data
class AddNumbers(Component):
display_name = "Add Numbers"
description = "This component adds two numbers together"
icon = "code"
name = "AddNumbers"
inputs = [
IntInput(
name="number1",
display_name="First Number",
info="The first number to add",
),
IntInput(
name="number2",
display_name="Second Number",
info="The second number to add",
),
]
outputs = [
Output(display_name="Output", name="output", method="add_numbers"),
]
def add_numbers(self) -> Data:
result = self.number1 + self.number2
data = Data(value=result)
return dataConstruisons un agent d'intelligence artificielle pour nous aider à pratiquer nos compétences en lecture lors de l'apprentissage d'une nouvelle langue.
D'après mon expérience, lorsque vous apprenez une nouvelle langue, l'un des moyens d'améliorer vos compétences est de lire. Bien sûr, au début, vous ne connaissez que quelques mots, et la lecture d'un livre est donc impossible. C'est pourquoi nous voulons disposer de matériel de lecture qui se concentre sur le vocabulaire que nous connaissons déjà.
Nous utiliserons un LLM pour générer de petites histoires à lire. Cependant, pour une expérience d'apprentissage personnalisée, nous voulons que les histoires qu'il génère se concentrent sur le vocabulaire que nous connaissons déjà.
Voici un aperçu de ce dont nous avons besoin :
Lorsque nous utilisons Docker pour exécuter Langflow, il démarre une base de données Postgres. Nous pouvons y accéder en utilisant le paquetage psycopg2. Pour en savoir plus sur Postgres, consultez ce tutoriel PostgreSQL.
Nous allons créer un nœud où nous pourrons télécharger un fichier CSV avec des mots connus pour initialiser la base de données. Mon fichier CSV se présente comme suit :
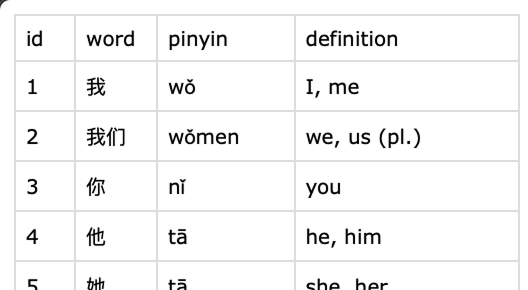
J'ai créé un composant avec deux entrées.
Voici le code du composant :
from langflow.custom import Component
from langflow.io import MessageTextInput, Output
from langflow.schema import Message
import psycopg2
import csv
def connect_to_database():
# Connect to the Postgres database provided by the Docker setup
conn = psycopg2.connect(
dbname="langflow",
user="langflow",
password="langflow",
host="postgres",
port="5432"
)
conn.autocommit = True
return conn.cursor()
def add_word(cursor, word):
# Add a word to the database
cursor.execute(
"INSERT INTO words (word) VALUES (%s) ON CONFLICT (word) DO NOTHING;",
(word,)
)
def initialize_database(cursor):
# Initialize the database by creating the word table if it doesn't yet exist
create_table_query = """
CREATE TABLE IF NOT EXISTS words (
word TEXT PRIMARY KEY
);
"""
cursor.execute(create_table_query)
class UploadWordFile(Component):
display_name = "Upload Word File"
description = "Upload a CSV file of words to the database."
icon = "code"
name = "UploadWordFile"
inputs = [
StrInput(
name="column_name",
display_name="Column Name",
info="The name of the column containing the words",
),
FileInput(
name="csv_file",
display_name="CSV file",
info="CSV input file",
file_types=["csv"]
),
]
outputs = [
Output(display_name="Output", name="output", method="load_words_into_database"),
]
def load_words_into_database(self) -> Message:
try:
cursor = connect_to_database()
initialize_database(cursor)
with open(self.csv_file, "rt") as f:
rows = list(csv.reader(f))
headers = list(map(lambda header: header.lower(), rows[0]))
column_index = headers.index(self.column_name)
for row in rows[1:]:
add_word(cursor, row[column_index])
return "Success"
except Exception as e:
return f"Error: {str(e)}"Le composant se présente comme suit :
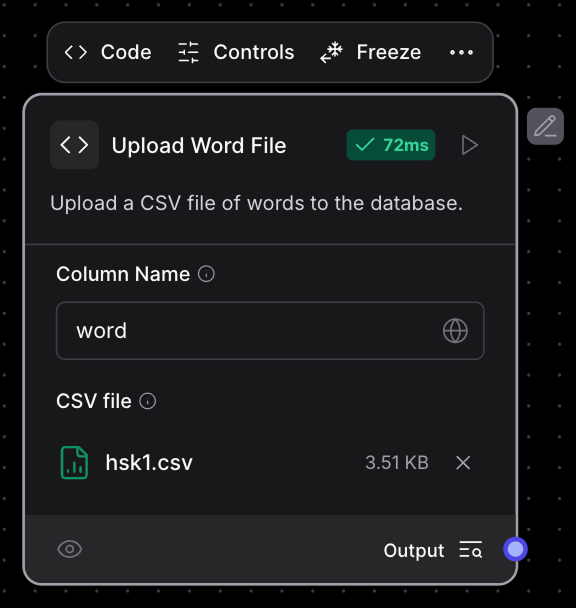
Il est conçu pour être utilisé seul et n'est relié à aucun autre composant. Nous pouvons l'utiliser pour télécharger manuellement des mots dans la base de données.
Nous créons ici un outil que l'agent IA peut utiliser pour ajouter de nouveaux mots à la base de données. Ainsi, l'utilisateur peut facilement ajouter de nouveaux mots en envoyant un message à l'agent.
Ce code réutilise les fonctions connect_to_database() et add_word() du nœud précédent. Avec une meilleure configuration de Docker, nous pouvons éviter de répéter le code, mais pour ce tutoriel, nous allons rester simples.
Voici le code de cet outil :
# from langflow.field_typing import Data
from langflow.custom import Component
from langflow.io import MessageTextInput, Output
from langflow.schema import Message
def connect_to_database():
# Connect to the Postgres database provided by the Docker setup
conn = psycopg2.connect(
dbname="langflow",
user="langflow",
password="langflow",
host="postgres",
port="5432"
)
conn.autocommit = True
return conn.cursor()
def add_word(cursor, word):
# Add a word to the database
cursor.execute(
"INSERT INTO words (word) VALUES (%s) ON CONFLICT (word) DO NOTHING;",
(word,)
)
class AddWordTool(Component):
display_name = "Add word tool"
description = "Use this tool to add a new word"
icon = "code"
name = "AddWordTool"
inputs = [
MessageTextInput(
name="word",
display_name="Word",
info="The word to add",
tool_mode=True,
),
]
outputs = [
Output(display_name="Output", name="output", method="add_new_word"),
]
def add_new_word(self) -> Message:
cursor = connect_to_database()
add_word(cursor, self.word)
return f"Added word: {self.word}"Notez que cet outil suppose que la base de données a été créée au préalable. Il ne fonctionnera pas sans que le composant précédent ait été exécuté au moins une fois.
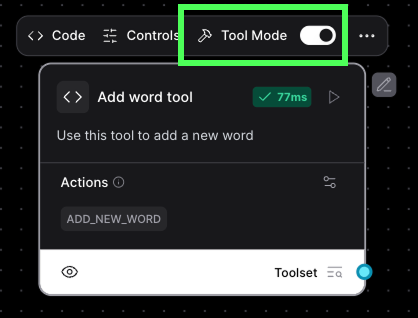
N'oubliez pas de le mettre en mode outil :
Pour créer une histoire, nous utilisons un agent d'intelligence artificielle. Voici la structure :
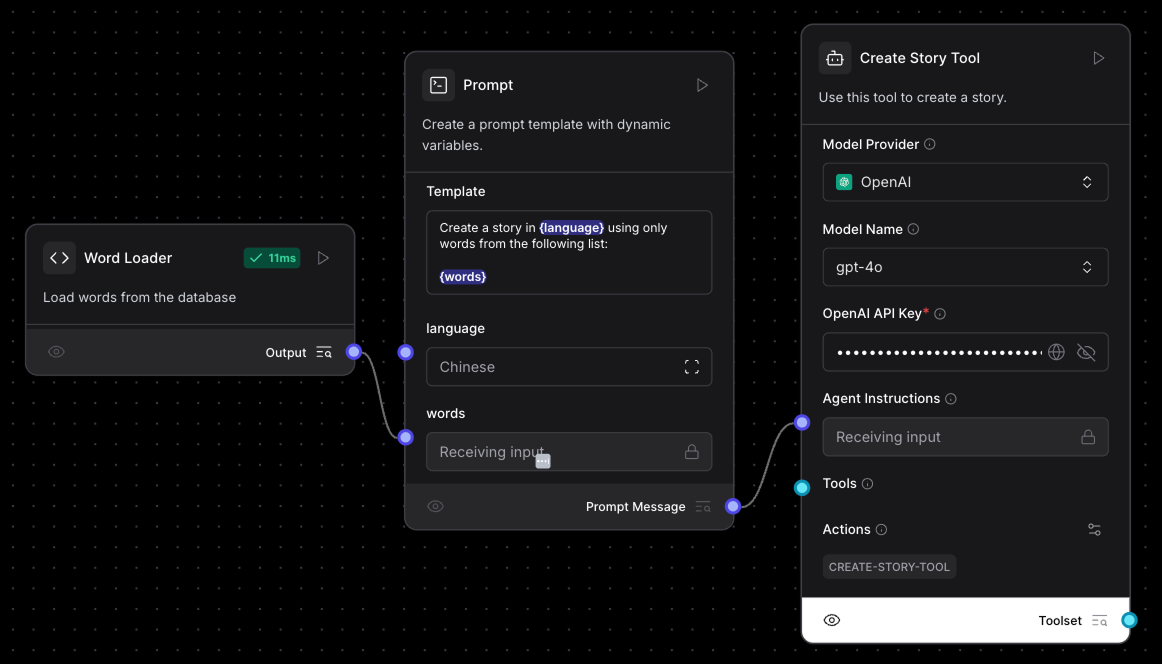
Dans les instructions destinées aux agents, au lieu d'ajouter l'invite directement dans le composant, nous avons utilisé un composantPrompt qui nous permet d'ajouter des paramètres à l'invite. Voici l'invite que nous avons utilisée :
Create a story in {language} using only words from the following list:
{words}L'invite a deux paramètres, {language} et {words}. Lorsque vous ajoutez des paramètres de cette manière, un champ est ajouté au composant pour chacun d'entre eux.
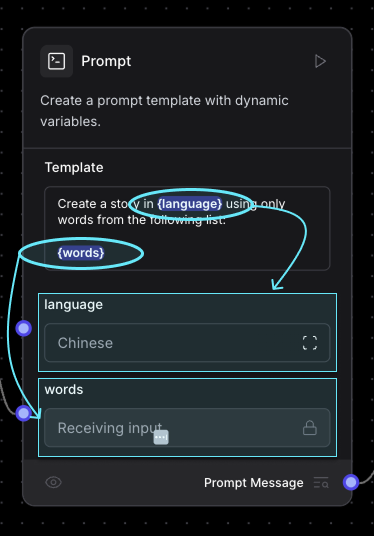
Pour la valeur de la langue, il suffit de l'indiquer dans la zone de texte. Les mots doivent être chargés à partir de la base de données, nous avons donc créé un composant personnalisé qui charge tous les mots à partir de la base de données, et nous avons connecté la sortie de ce nœud au champ "mots".
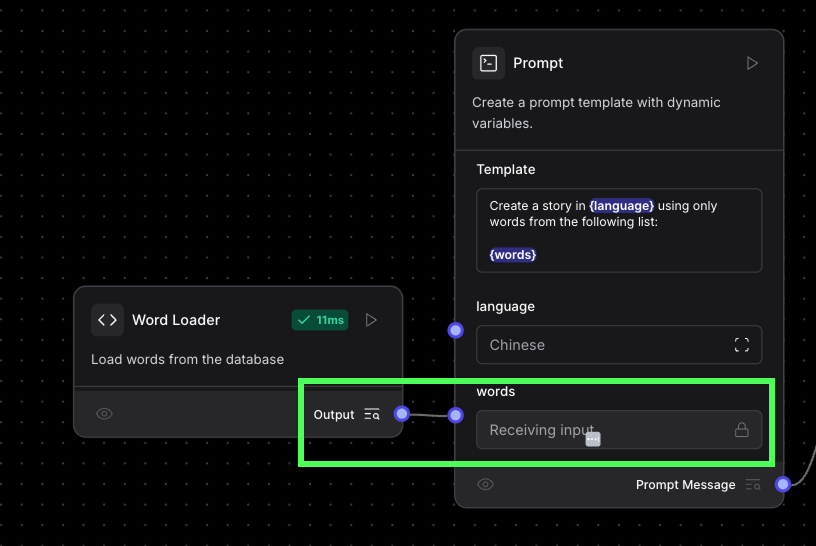
Voici le code du composant "word loader" :
from langflow.custom import Component
from langflow.io import MessageTextInput, Output
from langflow.schema import Message
import psycopg2
def load_words():
conn = psycopg2.connect(
dbname="langflow",
user="langflow",
password="langflow",
host="postgres",
port="5432"
)
cursor = conn.cursor()
cursor.execute("""
SELECT * FROM words;
""")
rows = cursor.fetchall()
return map(lambda row: row[0], rows)
class WordLoader(Component):
display_name = "Word Loader"
description = "Load words from the database"
icon = "code"
name = "WordLoader"
outputs = [
Output(display_name="Output", name="output", method="build_output"),
]
def build_output(self) -> Message:
return str(", ".join(load_words()))Ensuite, nous définissons l'agent comme un outil. De cette façon, l'agent principal (que nous créons ensuite) pourra utiliser celui-ci pour générer une histoire en cas de besoin.
Enfin, nous renommons l'agent et modifions la description de l'outil pour que l'IA sache quand utiliser cet outil :
Pour l'agent principal, nous utilisons un composant de nœud d'agent d'IA ordinaire lié aux deux outils que nous avons créés. Cet agent utilise un composant d'entrée et un composant de sortie de chat afin que nous puissions interagir avec lui à l'aide de l'interface de chat.
Voici l'architecture finale :
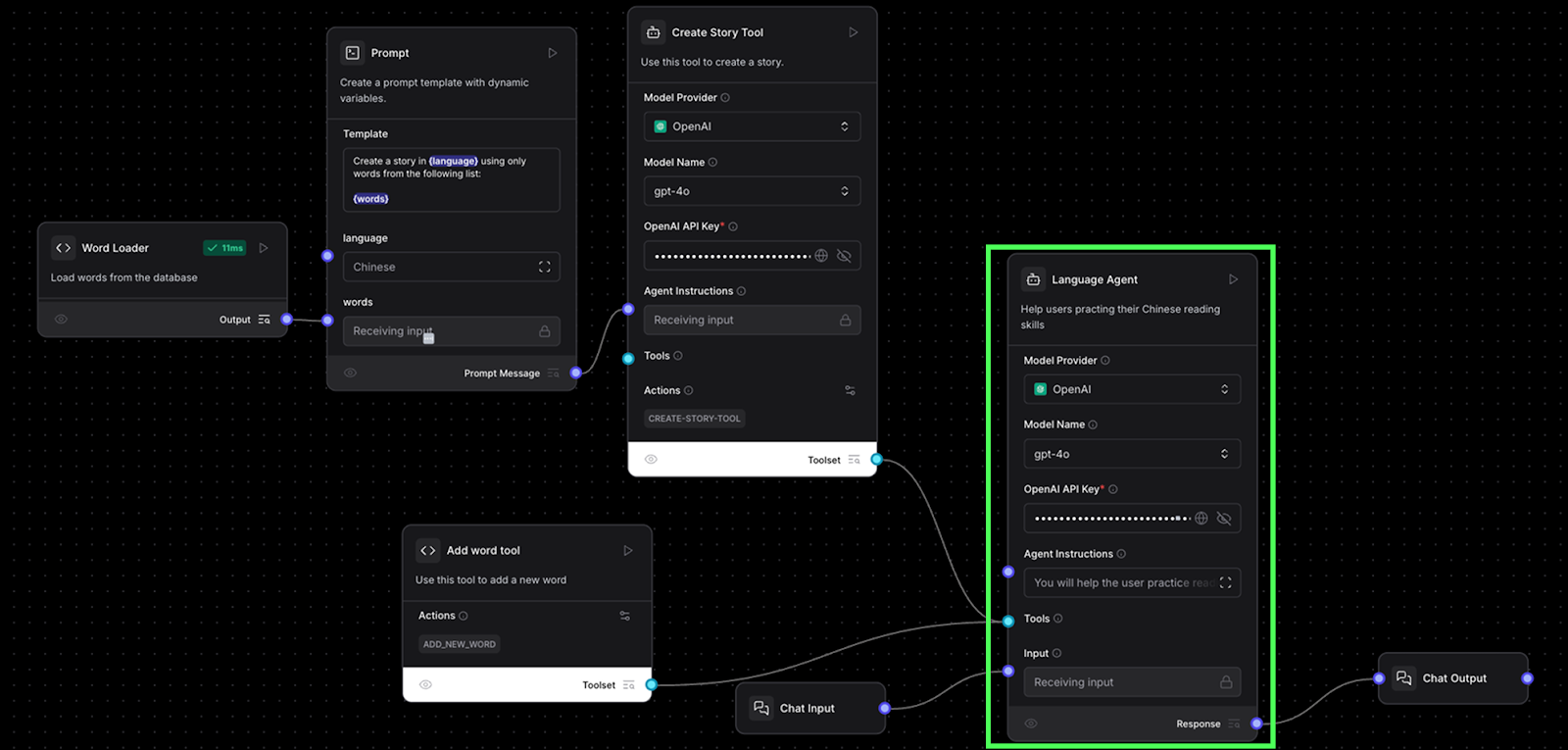
L'invite que nous avons utilisée était la suivante :
You will help the user practice their language skills. You will either be asked to create a story or to add a new word to the vocabulary.
- If the user asks you to create a story, use the story generation tool.
- If the user asks you to add a word, use the word add tool.
When using a tool, your answer should just be the result from the tool and nothing else.Nous pouvons exécuter le flux de travail complet en cliquant sur le bouton "Playground". Voici un exemple d'interaction :
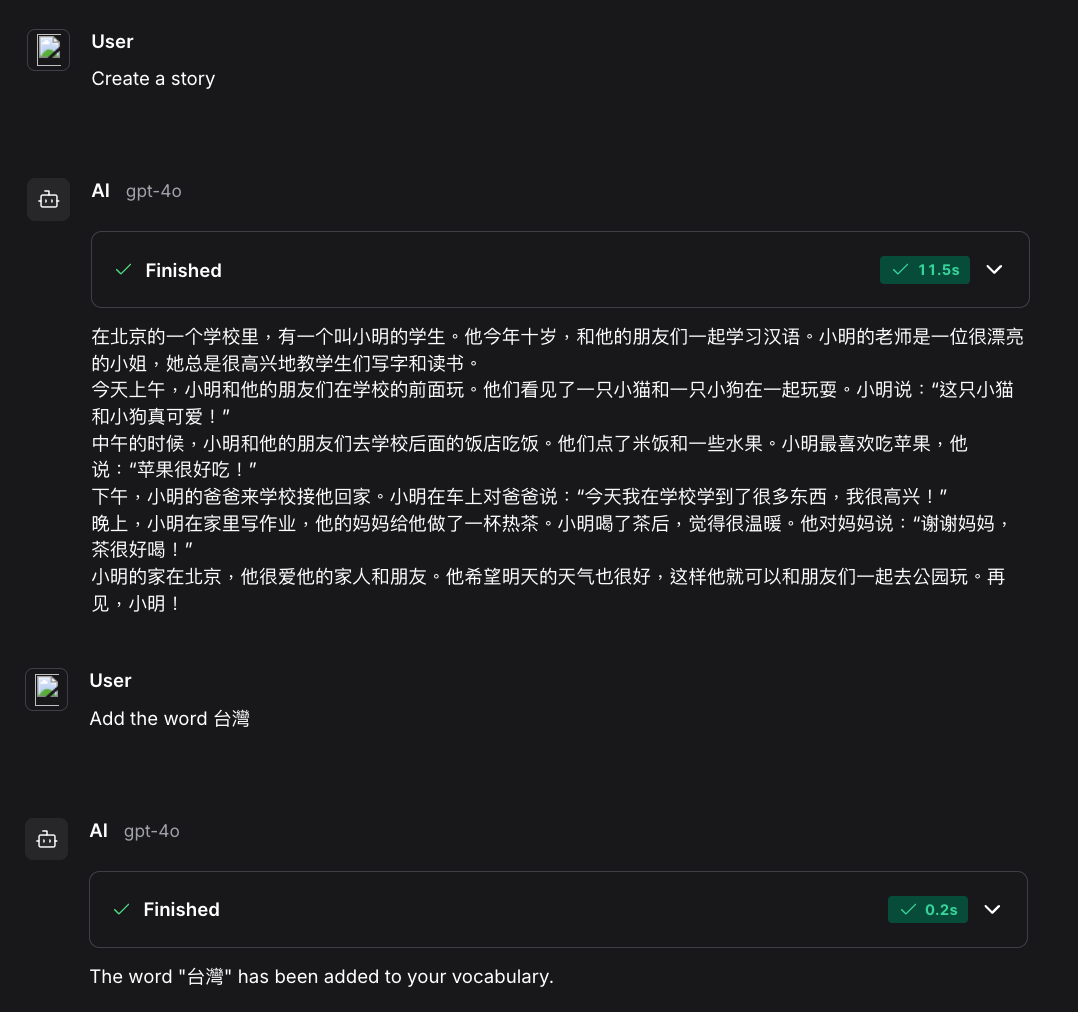
Nous avons exploré les aspects fondamentaux de Langflow et la manière dont il peut être utilisé pour construire un agent d'intelligence artificielle qui aide les utilisateurs à pratiquer leurs compétences en lecture. En utilisant Python pour créer des composants personnalisés, nous débloquons davantage de possibilités.
Cette approche hybride fusionne le meilleur des deux mondes : la flexibilité des scripts Python, qui permettent l'exécution de n'importe quelle tâche souhaitée, et l'interface graphique intuitive de Langflow, qui simplifie la construction de flux de travail sans avoir à plonger dans un code complexe.
Pour en savoir plus sur les agents d'intelligence artificielle, je vous recommande de lire ces blogs :
Apprenez l'IA avec ces cours !
Cursus
Cours
Cours
blog
blog
Kurtis Pykes
15 min
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
8 min
blog
Fereshteh Forough
4 min