
Cours
Introduction au data engineering
4 h
127.6K
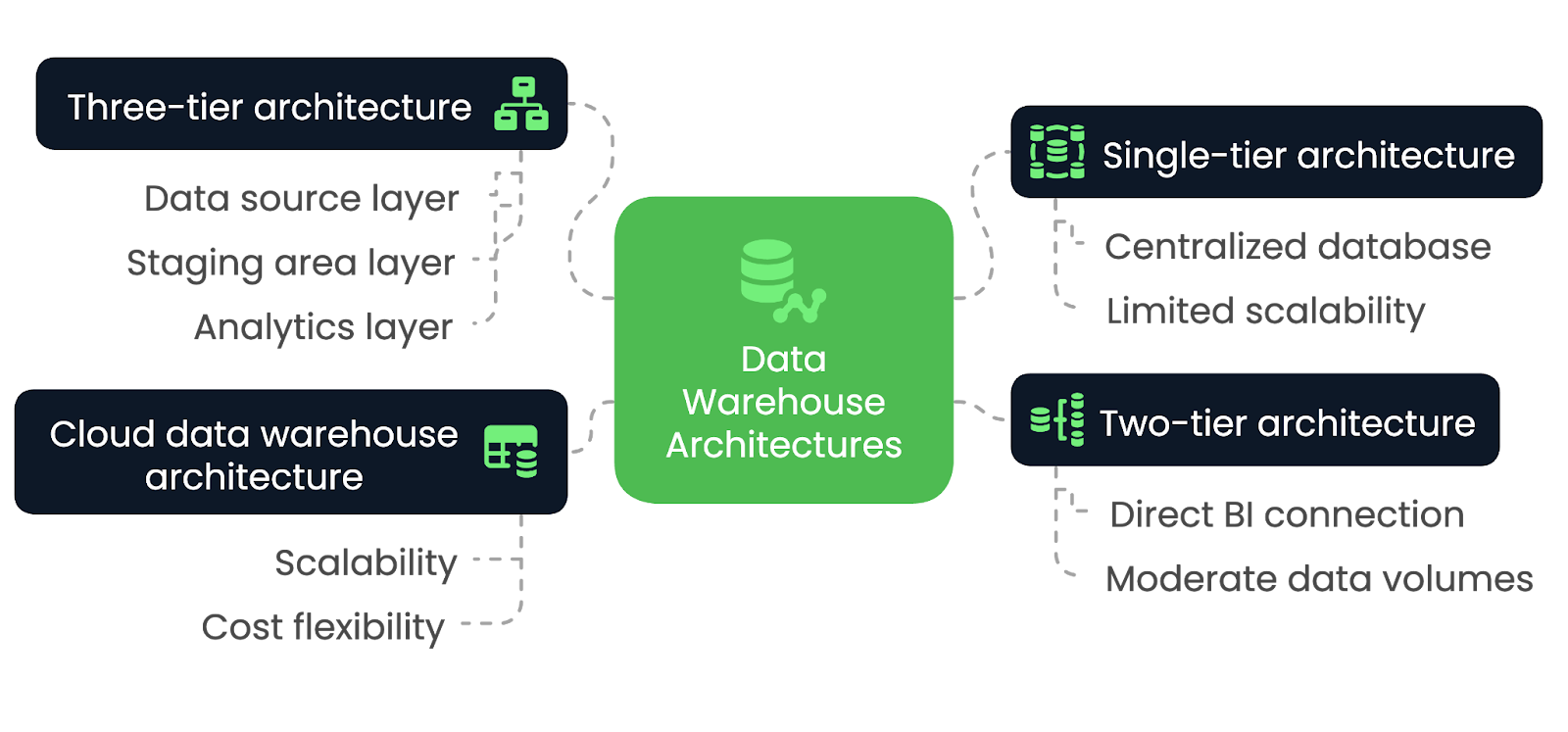
Le choix de la bonne architecture d'entrepôt de données est essentiel pour répondre aux besoins de votre organisation en matière de performance, d'évolutivité et d'intégration. Cependant, les différentes architectures offrent des avantages et des compromis uniques, en fonction de divers facteurs. Nous allons les explorer dans cette section.
Dans une architecture à un seul niveau, l'entrepôt de données est construit sur une base de données unique et centralisée qui consolide toutes les données provenant de différentes sources en un seul système. Cette architecture minimise le nombre de couches et simplifie la conception globale, ce qui permet d'accélérer le traitement et l'accès aux données. Toutefois, il ne dispose pas de la flexibilité et de la modularité que l'on trouve dans des architectures plus complexes.
L'architecture à un seul niveau convient le mieux aux applications à petite échelle et aux organisations ayant des besoins limités en matière de traitement des données. Il est idéal pour les entreprises qui privilégient la simplicité et la rapidité de mise en œuvre à l'évolutivité. Cependant, lorsque le volume de données augmente ou que des analyses plus avancées sont nécessaires, cette architecture peut avoir du mal à répondre efficacement à ces demandes.
Dans une architecture à deux niveaux, l'entrepôt de données se connecte directement aux outils de BI, souvent par l'intermédiaire d'un système OLAP. Bien que cette approche permette un accès plus rapide aux données à des fins d'analyse, elle peut se heurter à des difficultés lorsqu'il s'agit de traiter des volumes de données plus importants, car la mise à l'échelle devient difficile en raison de la connexion directe entre l'entrepôt et les outils d'analyse décisionnelle.
L'architecture à deux niveaux convient le mieux aux petites et moyennes entreprises qui ont besoin d'un accès plus rapide aux données pour l'analyse, mais qui n'ont pas besoin de l'évolutivité d'architectures plus grandes et plus complexes. Elle est idéale pour les entreprises qui ont des volumes de données modérés et des besoins relativement simples en matière de rapports ou d'analyses, car elle permet une intégration directe entre l'entrepôt de données et les outils de veille stratégique.
Cependant, à mesure que les données augmentent ou que les exigences analytiques deviennent plus sophistiquées, cette architecture peut avoir du mal à s'adapter et à gérer efficacement les charges de travail croissantes.
L'architecture à trois niveaux est le modèle le plus courant et le plus largement utilisé pour les entrepôts de données. Il sépare le système en couches distinctes : la couche de la source de données, la couche de la zone de transit et la couche d'analyse. Cette séparation permet des processus ETL efficaces, suivis d'analyses et de rapports.
L'architecture à trois niveaux est idéale pour les environnements d'entreprise à grande échelle qui requièrent évolutivité, flexibilité et capacité à gérer des volumes de données considérables. Elle permet aux entreprises de gérer les données plus efficacement et prend en charge l'analyse avancée, l'apprentissage automatique et les rapports en temps réel. La séparation des couches améliore les performances, ce qui permet de l'utiliser dans des environnements de données complexes.
Dans l'architecture d'entrepôt de données dans le cloud, toute l'infrastructure est hébergée sur des plateformes comme Amazon Redshift, Google BigQuery ou Snowflake. Les architectures basées sur le cloud offrent une évolutivité pratiquement illimitée, avec la possibilité de traiter des ensembles de données volumineux sans avoir besoin de matériel sur site. Ils offrent également une flexibilité des coûts grâce à des modèles de paiement à l'utilisation, ce qui les rend accessibles à un plus grand nombre d'entreprises.
L'architecture d'entrepôt de données dans le cloud est idéale pour les organisations de toutes tailles. C'est la solution idéale pour les entreprises qui recherchent une solution flexible et évolutive, car cette approche permet aux entreprises de faire évoluer les ressources de stockage et de calcul de manière dynamique.
Architectures d'entrepôts de données comparées-image par l'auteur.
Il existe plusieurs modèles de conception d'entrepôts de données, mais chacun répond à des besoins différents en fonction de la complexité des données et des types de requêtes exécutées. Explorons quelques-uns des plus courants et décryptons les scénarios les plus appropriés pour les utiliser avec un maximum d'efficacité.
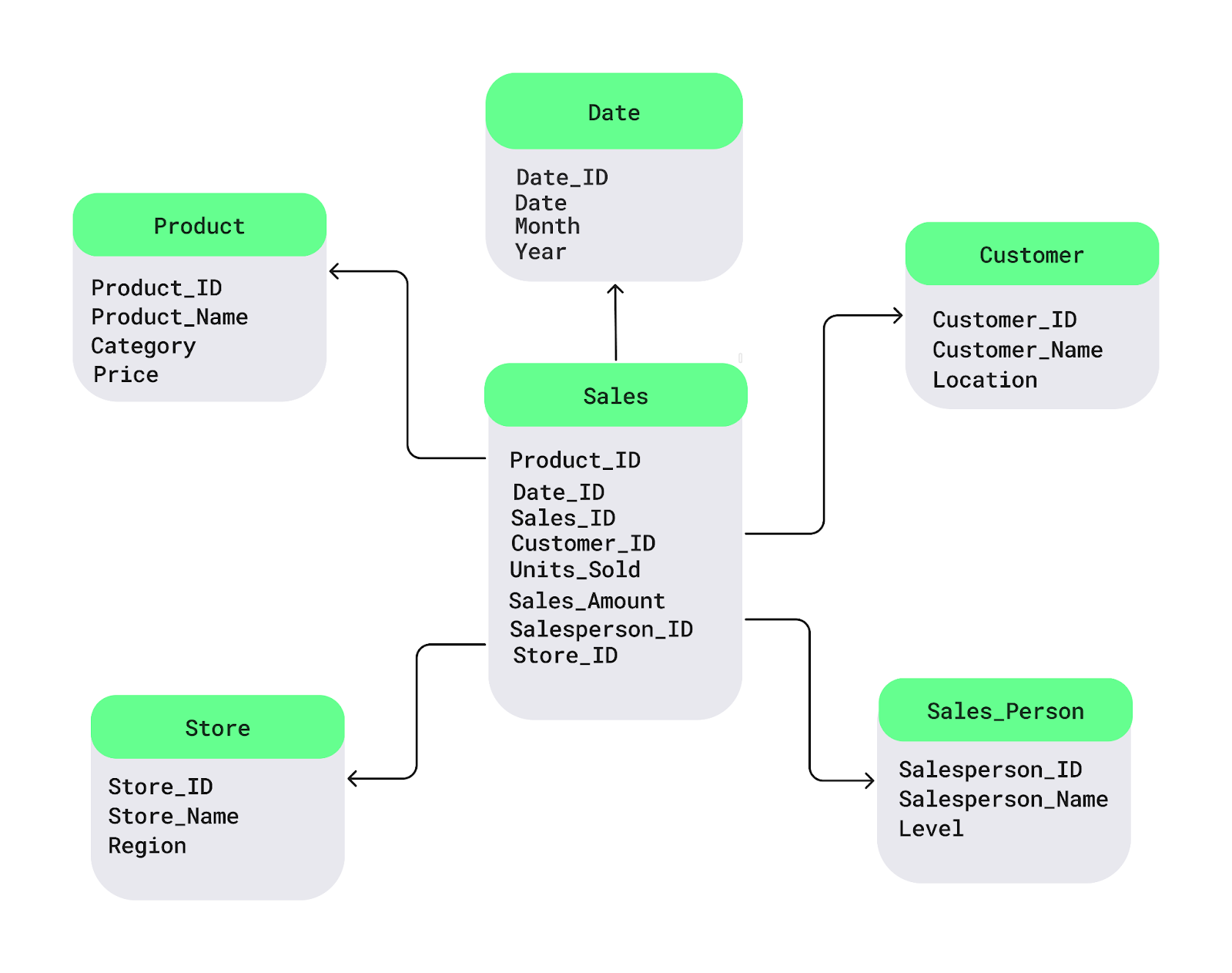
Le schéma en étoile est l'un des modèles de conception d'entrepôt de données les plus couramment utilisés. Il structure les données en :
Dans un scénario de vente au détail, le tableau des faits contient des données transactionnelles sur les ventes, tandis que les tableaux des dimensions fournissent un contexte sur les produits, les clients, les magasins et l'heure. Ce schéma améliore les performances des requêtes, ce qui le rend idéal pour les environnements ayant des besoins fréquents et simples en matière de rapports.
Exemple de schéma en étoile. Image source : DataCamp.
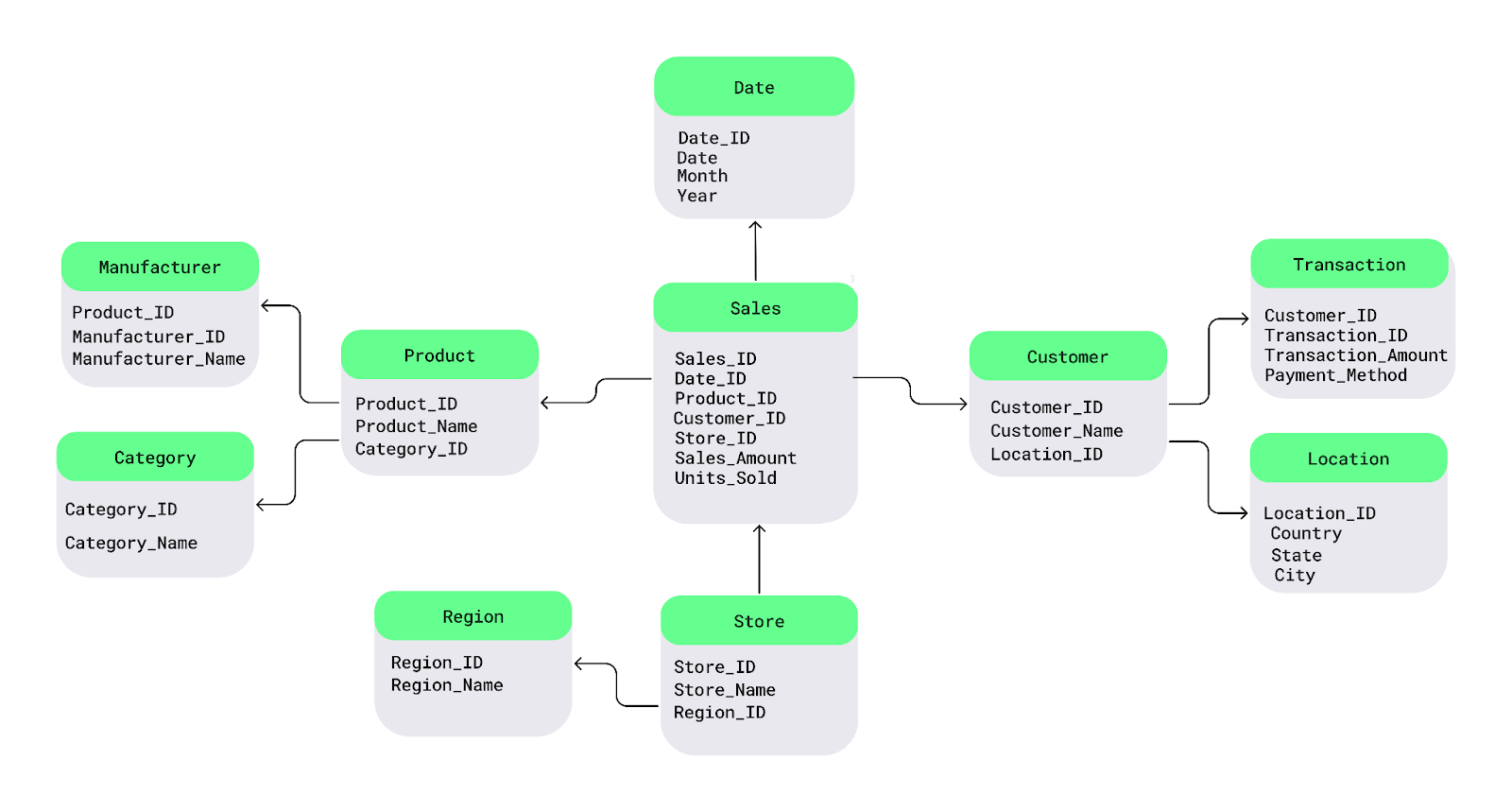
Le schéma Snowflake est une extension du schéma en étoile, qui introduit une normalisation supplémentaire dans les tableaux de dimensions. Les principales caractéristiques sont les suivantes
Ce schéma est idéal pour :
Bien que le schéma Snowflake permette d'économiser de l'espace de stockage, il peut conduire à des requêtes plus complexes en raison de sa nature hautement structurée.
Exemple de schéma Snowflake. Image source : DataCamp.
La modélisation de la voûte de données est un modèle de conception plus récent qui met l'accent sur la flexibilité, l'évolutivité et le cursus des données historiques. Il divise l'entrepôt de données en trois composants principaux :
Cette approche est très adaptable aux changements de processus d'entreprise, ce qui la rend bien adaptée aux environnements de développement agiles.
Le modèle de conception de la voûte de données est de plus en plus populaire en raison de sa capacité à gérer des environnements de données en constante évolution, à s'adapter aux changements de sources de données et à prendre en charge l'évolutivité à long terme. Il est devenu une solution idéale pour les organisations qui ont besoin d'un cursus historique détaillé, de modifications fréquentes des schémas ou d'une architecture hautement évolutive.
La mise en œuvre des meilleures pratiques dès le début est essentielle pour construire une architecture solide. Cette section aborde donc certaines des meilleures pratiques à suivre lors de la construction d'un entrepôt de données à haute performance.
Les volumes de données et les besoins de l'entreprise augmenteront inévitablement au fil du temps. Il est donc essentiel de s'assurer que l'architecture que vous choisissez peut gérer des charges de travail croissantes. Pour ce faire, il suffit d'utiliser des solutions de stockage évolutives, comme les plateformes basées sur le cloud, et de partitionner les grands tableaux pour obtenir de meilleures performances.
Rationalisez le pipeline ETL en minimisant les transformations de données inutiles, en tirant parti de stratégies de chargement incrémentiel et en parallélisant les tâches ETL lorsque c'est possible. Cela garantit que les données sont ingérées, transformées et chargées rapidement, sans goulots d'étranglement.
Le maintien d'une qualité élevée des données est un élément fondamental de la valeur d'un entrepôt de données (). Mettez en œuvre des procédures rigoureuses de validation et de déduplication des données afin de garantir l'exactitude et la cohérence des données qui entrent dans l'entrepôt. Des audits et des contrôles de qualité réguliers devraient faire partie du pipeline ETL afin de prévenir les problèmes qui pourraient conduire à des analyses incorrectes.
La sécurité des données doit être une priorité absolueorité - en particulier lorsqu'il s'agit d'informations sensibles ou réglementées. Vous devez prendre trois mesures essentielles :
Pour que l'entrepôt de données fonctionne efficacement, contrôlez régulièrement les éléments suivants :
Les cursus de suivi des performances peuvent aider à identifier les goulets d'étranglement, ce qui peut vous aider à procéder à des ajustements proactifs si nécessaire.
Devriez-vous opter pour un entrepôt de données basé sur le cloud ou tout conserver sur site ? Quels sont les principaux avantages et inconvénients de chaque approche ? Une solution hybride est-elle le meilleur des deux mondes ?
Dans cette section, nous allons explorer ces questions et vous aider à déterminer l'architecture la mieux adaptée à vos besoins.
Les entrepôts de données basés sur le cloud offrent une évolutivité et une flexibilité inégalées. Ces plateformes permettent aux entreprises de faire évoluer les ressources de stockage et de calcul à la demande, ce qui les rend idéales pour gérer des volumes de données importants et dynamiques sans coûts d'infrastructure initiaux.
Le modèle de tarification "pay-as-you-go" rend également les solutions cloud rentables, en particulier pour les entreprises dont la charge de travail est fluctuante. Toutefois, les environnements cloud peuvent susciter des inquiétudes quant à la gouvernance et à la conformité des données, en particulier pour les secteurs très réglementés.
Les fournisseurs de cloud les plus populaires sont les suivants :
Les entrepôts de données sur site conviennent mieux aux organisations qui exigent un contrôle strict des données. Grâce à l'architecture sur site, les entreprises conservent un contrôle total sur leur matériel et leurs données, ce qui est essentiel pour des secteurs tels que la finance, la santé et le gouvernement, où les informations sensibles doivent être protégées.
Mais il y a un hic. Si les systèmes sur site peuvent offrir de bonnes performances, ils s'accompagnent souvent de coûts initiaux élevés pour le matériel et la maintenance. La mise à l'échelle peut également s'avérer difficile, car elle nécessite des mises à niveau manuelles et l'acquisition de matériel, ce qui est moins flexible que les solutions en nuage.
Les architectures d'entrepôts de données hybrides combinent des composants dans le cloud et sur site, offrant ainsi une plus grande flexibilité aux entreprises qui doivent trouver un équilibre entre sécurité, conformité et évolutivité. Par exemple, les données sensibles peuvent être stockées sur site, tandis que les données moins critiques ou les charges de travail analytiques peuvent être traitées dans le cloud.
Les architectures hybrides sont particulièrement utiles pour les entreprises qui doivent passer progressivement au cloud ou qui ont des exigences spécifiques en matière de confidentialité des données. Ce modèle offre le meilleur des deux mondes, mais nécessite une orchestration minutieuse pour garantir une intégration transparente des données entre les environnements.
|
Fonctionnalité |
Architecture basée sur le cloud |
Architecture sur site |
Architecture hybride |
|
Évolutivité |
Allocation de ressources à la demande et hautement évolutive |
Limité par le matériel sur site, nécessite des mises à jour manuelles |
Combine des ressources cloud évolutives avec un contrôle sur site. |
|
Coût |
Tarification à l'utilisation, coûts initiaux réduits |
Investissement initial élevé dans le matériel et la maintenance continue |
Coûts hybrides, équilibre entre les économies réalisées dans le cloud et les dépenses sur site. |
|
Flexibilité |
Extrêmement flexible, idéal pour les charges de travail dynamiques |
Moins flexible, limité par l'infrastructure physique |
Flexible, combinant l'agilité du cloud et le contrôle sur site. |
|
Sécurité et conformité |
Peut susciter des inquiétudes dans les secteurs hautement réglementés |
Contrôle total de la sécurité des données et de la conformité réglementaire |
Garantit la conformité des données sensibles tout en tirant parti du cloud. |
|
Performance |
Peut varier en fonction du fournisseur de cloud et de la configuration. |
Performances élevées, mais dépendantes des investissements en matériel |
Performances équilibrées en fonction de la répartition de la charge de travail |
|
Maintenance |
Maintenance minimale, gérée par le fournisseur de cloud. |
Nécessite une maintenance informatique interne permanente |
Approche hybride avec des services cloud assurant une partie de la maintenance. |
|
Cas d'utilisation |
Idéal pour les entreprises dont les volumes de données sont importants et fluctuants |
Idéal pour les organisations ayant des besoins stricts en matière de sécurité et de conformité |
Idéal pour les organisations en transition vers le cloud ou ayant des besoins mixtes. |
Voici un aperçu de quelques-unes des plateformes d'entrepôt de données les plus utilisées dans le cloud.
Amazon Redshift est une solution d'entrepôt de données dans le cloud entièrement managed pour l'analyse de données à grande échelle. Son architecture est basée sur un système de traitement massivement parallèle, qui permet aux utilisateurs d'interroger rapidement de vastes ensembles de données. Grâce à sa capacité à évoluer en fonction des besoins de la charge de travail, Redshift est bien adapté aux entreprises qui ont besoin d'une évolutivité rentable et d'une intégration avec d'autres services AWS.
Google BigQuery est une plateforme d'entrepôt de données sans servicerless et hautement évolutive, conçue pour des analyses rapides et en temps réel. Son architecture unique découple le stockage et le calcul, ce qui permet aux utilisateurs d'interroger des pétaoctets de données sans avoir à gérer l'infrastructure. La capacité de BigQuery à traiter des analyses à grande échelle avec un minimum de frais généraux en fait la solution idéale pour les entreprises dont la charge de travail est importante et qui ont besoin de requêtes rapides et complexes.
Snowflake offre une architecture de données partagées multi-cluster qui sépare le calcul et le stockage, offrant ainsi une flexibilité dans la mise à l'échelle indépendante des ressources. L'approche cloud-native de Snowflake permet aux entreprises de faire évoluer dynamiquement les charges de travail, ce qui en fait donc une option intéressante pour les organisations qui ont besoin d'une grande flexibilité et d'une gestion des charges de travail sur plusieurs plateformes cloud.
Microsoft Azure Synapse Analytics est une plateforme hybride de gestion de données qui combine l'entreposage de données et l'analyse de données massives. Son architecture s'intègre à des frameworks big data comme Apache Spark afin de fournir un environnement unifié pour la gestion des lacs de données et des entrepôts de données. Azure Synapse offre une intégration transparente avec d'autres services Microsoft et est idéal pour les entreprises ayant des besoins variés en matière d'analyse de données.
|
Plate-forme |
L'architecture |
Caractéristiques principales |
Cas d'utilisation |
|
Amazon Redshift |
Architecture MPP, écosystème AWS |
Scalable, requêtes rapides, intégration AWS |
Analyse à grande échelle, applications cloud-natives. |
|
Google BigQuery |
Stockage et calcul découplés, sans serveur |
Analyse en temps réel, infrastructure réduite |
Analyse rapide, traitement des données en temps réel |
|
Snowflake |
Architecture multi-cloud, à données partagées, cross-cloud (AWS, Azure, GCP). |
Séparation ordinateur-stockage, mise à l'échelle dynamique |
Mise à l'échelle flexible, charges de travail de plateforme cross-cloud. |
|
Azure Synapse |
Intégration de données hybrides et volumineuses |
Analyse unifiée, intégration de Spark |
Gestion de données hybrides, intégration avec les outils Microsoft |
Si les entrepôts de données offrent aux organisations de puissantes capacités d'analyse et de gestion de vastes quantités de données, ils s'accompagnent également de défis inhérents.
Voici quelques-uns des défis les plus importants et des solutions à prendre en compte lors de la conception et de la maintenance d'une architecture d'entrepôt de données.
Les organisations collectent des données à partir de sources multiples, chacune ayant des formats, des schémas et des structures différents, ce qui fait de l'intégration un défi complexe. Les principaux éléments à prendre en compte sont les suivants :
Pour relever ces défis, les entreprises ont besoin de processus ETL flexibles et d'outils de gestion des données qui prennent en charge divers formats de données et une intégration transparente entre les plateformes.
Au fur et à mesure que les entrepôts de données se développent, il devient difficile de maintenir des performances élevées en matière d'interrogation. Les opérations à grande échelle doivent traiter efficacement des millions, voire des milliards de lignes, tout en évitant les requêtes lentes, les coûts élevés et l'utilisation inefficace des ressources.
Les principales stratégies d'optimisation sont les suivantes :
Comme de plus en plus d'utilisateurs accèdent à l'entrepôt de données, l'efficacité de l'allocation des ressources devient critique. Les principaux éléments à prendre en compte sont les suivants :
En mettant en œuvre ces stratégies, les entreprises peuvent s'assurer que leur entrepôt de données évolue efficacement et reste performant à mesure que le volume de données et l'activité des utilisateurs augmentent.
Les entrepôts de données stockant des quantités croissantes d'informations sensibles, une gouvernance solide et des mesures de sécurité sont essentielles pour prévenir les violations, assurer la conformité et maintenir l'intégrité des données.
Dans cet article, nous avons exploré les composants clés de l'architecture d'un entrepôt de données, les défis courants et les stratégies pour les surmonter. En fin de compte, un entrepôt de données bien conçu ne se contente pas de stocker des données, il permet aux organisations de prendre des décisions éclairées, fondées sur des données, qui stimulent la croissance et l'innovation.
Vous souhaitez approfondir l'architecture des données et les meilleures pratiques ? Consultez ces ressources :
Apprenez-en plus sur l'ingénierie des données avec ces cours !
Cours
Cours
Cours
blog
Nathaniel Taylor-Leach
8 min
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach