Cours
Visualiser des Big Data avec Trelliscope en R
4 h
6.3K

Apprenez les compétences dont vous avez besoin à votre propre rythme, des notions essentielles de non-codage à la science des données et à l'apprentissage automatique.
Les histogrammes sont des visualisations qui montrent les distributions de fréquence des variables continues (numériques). Les histogrammes nous permettent de voir le nombre d'observations dans les données à l'intérieur des plages que la variable continue couvre.
Nous devons d'abord importer la bibliothèque ggplot2 à l'aide de la fonction library. Vous obtiendrez ainsi toutes les fonctions intégrées disponibles dans la bibliothèque ggplot2. Si vous n'avez pas encore installé ggplot2, vous devrez l'installer en exécutant la commande install.packages(). Nous ferons de même avec la bibliothèque readr, qui nous permettra de lire un fichier csv, et dplyr, qui nous permettra de travailler plus facilement avec les données que nous lisons.
install.packages("ggplot2")
install.packages("readr")
install.packages("dplyr")
library(ggplot2)
library(readr)
library(dplyr)Pour ce tutoriel, nous utiliserons cet ensemble de données sur le logement qui comprend des détails sur différentes listes de maisons, y compris la taille de la maison, le nombre de pièces, le prix et des informations sur l'emplacement.
Nous pouvons lire les données à l'aide de la fonction read_csv(). Nous pouvons le lire directement à partir de l'URL ou télécharger le fichier csv dans un répertoire et le lire à partir de notre stockage local. Le premier attribut de read_csv() est l'emplacement des données, et l'attribut col_select nous permet de choisir les colonnes qui nous intéressent.
home_data <- read_csv(
"https://raw.githubusercontent.com/rashida048/Datasets/master/home_data.csv",
col_select = c(price, condition)
)Nous pouvons ensuite examiner les premières lignes de données à l'aide de la fonction head()
head(home_data)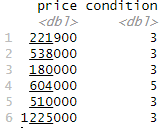
Nous pouvons maintenant créer l'histogramme. Quel que soit le type de graphique que nous créons dans ggplot2, nous commençons toujours par la fonction ggplot(), qui crée un canevas sur lequel nous ajoutons des éléments de tracé. Il prend deux paramètres.
home_data.aes(). Ici, nous faisons correspondre la colonne des prix à l'axe des abscisses.Jusqu'à présent, notre code est le suivant
ggplot(data = home_data, aes(x = price))En soi, cela n'apportera rien d'utile. Pour obtenir un histogramme, nous ajoutons une géométrie d'histogramme à l'aide de geom_histogram().
ggplot(data = home_data, aes(x = price)) +
geom_histogram()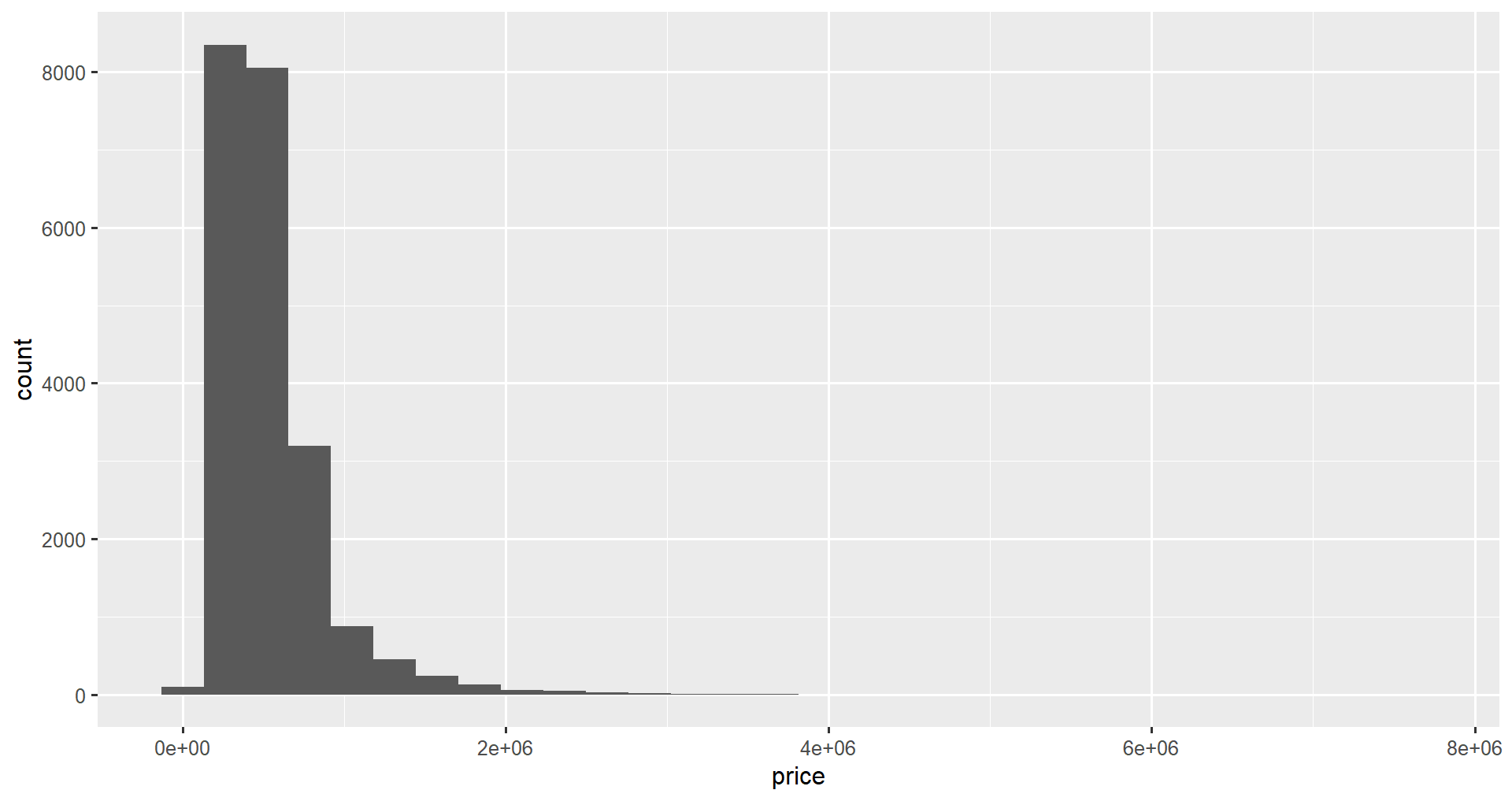
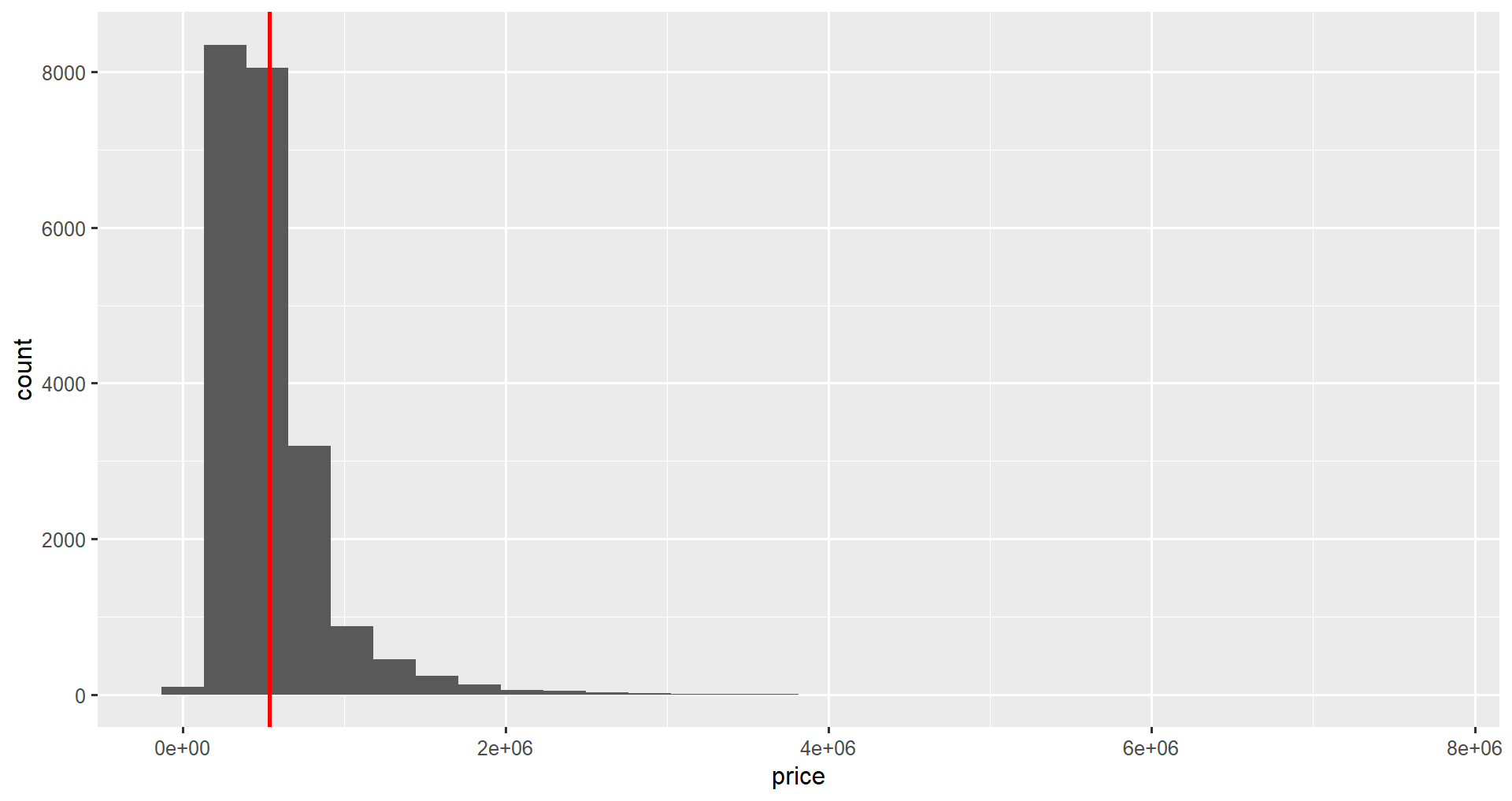
geom_vline()Nous pouvons ajouter des statistiques descriptives à notre graphique à l'aide de la fonction geom_vline(). Cela ajoute une ligne géométrique verticale au tracé.
Tout d'abord, nous calculons une statistique descriptive, en l'occurrence le prix moyen, à l'aide de la fonction summarize() de dplyr.
price_stats <- home_data |>
summarize(mean_price = mean(price))
price_stats# A tibble: 1 × 1
mean_price
<dbl>
1 540088.La fonction prend le paramètre xintercept et les attributs facultatifs color et linewidth pour personnaliser la couleur et la taille des lignes, respectivement. Nous ajouterons une ligne moyenne en utilisant le signe plus comme nous l'avons fait dans la section précédente.
ggplot(home_data, aes(x = price)) +
geom_histogram() +
geom_vline(aes(xintercept = mean_price), price_stats, color = "red", linewidth = 2)Remarquez que dans les fonctions geom_, les arguments de mapping et de données sont intervertis par rapport à ggplot().
Pour ajouter une ligne de densité de probabilité à l'histogramme, nous modifions d'abord l'axe des ordonnées pour qu'il soit mis à l'échelle de la densité. Dans la fonction aes(), nous fixons y à after_stat(density).
Nous pouvons ensuite ajouter une couche de densité à notre graphique à l'aide de la fonction geom_density(). Ici, nous définissons l'attribut color comme étant vert et l'attribut linewidth comme étant 2.
ggplot(home_data, aes(x = price, y = after_stat(density))) +
geom_histogram() +
geom_vline(aes(xintercept = mean_price), price_stats, color = "red", linewidth = 2) +
geom_density(color = "green", linewidth = 2)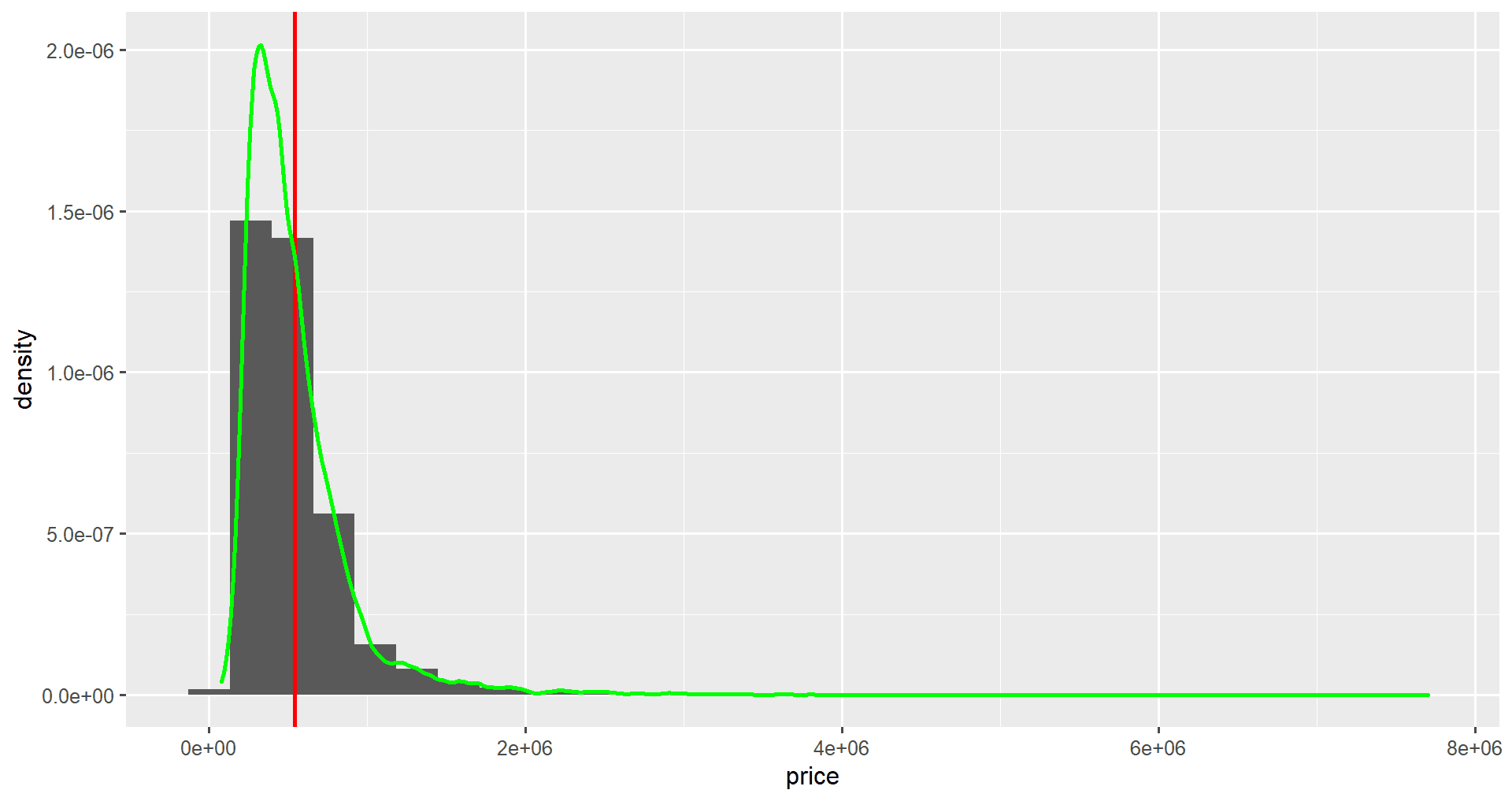
Remarquez que les chiffres de l'axe des ordonnées ont changé.
Comme vous commencez à le voir, la syntaxe de ggplot2 est simple mais très puissante. Nous pouvons ajouter plusieurs couches à un graphique simple pour le rendre plus complexe grâce à la logique additive et à certaines fonctions intégrées bien définies.
Nous pouvons mettre à jour le binning de notre histogramme ggplot2 en utilisant l'attribut bin. Nous définissons les attributs bin comme étant égaux au nombre de bins que nous voulons afficher sur notre graphique. Cela nous aidera à voir des données plus ou moins granulaires dans notre histogramme.
ggplot(data = home_data, aes(x = price)) +
geom_histogram(bins = 100)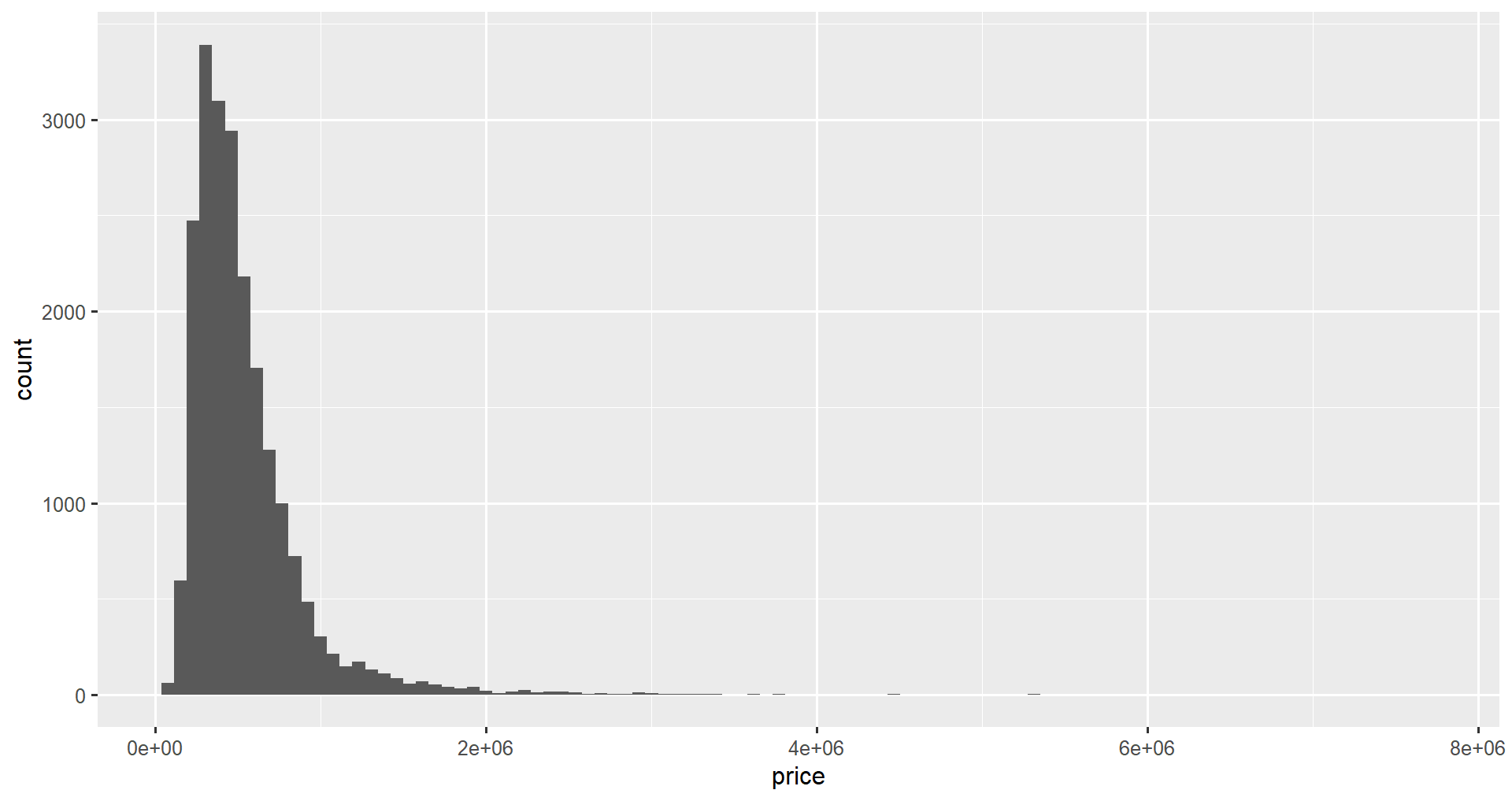
Nous pouvons également définir manuellement la largeur des cases en utilisant l'attribut binwidth de geom_histogram().
ggplot(data = home_data, aes(x = price)) +
geom_histogram(binwidth = 50000)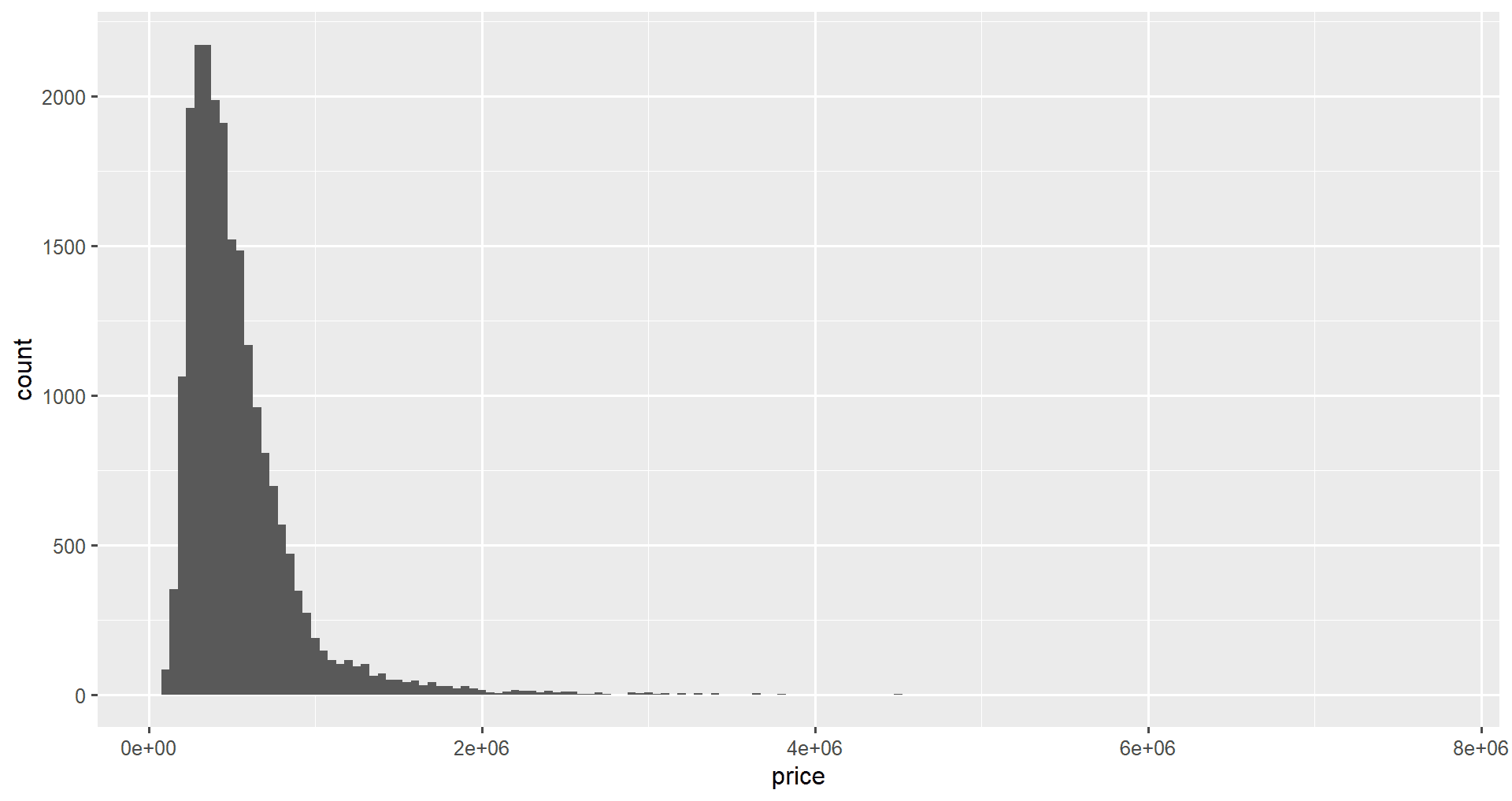
Enfin, vous pouvez aligner les limites à l'aide des attributs de centrage ou de délimitation. Si vous souhaitez que les limites des bacs correspondent à des multiples spécifiques, vous pouvez utiliser ces attributs (un seul peut être utilisé à la fois). Pour s'assurer que les cases se terminent par des valeurs entières, définissez l'attribut comme étant égal à 1.
ggplot(data = home_data, aes(x = price)) +
geom_histogram(boundary = 1)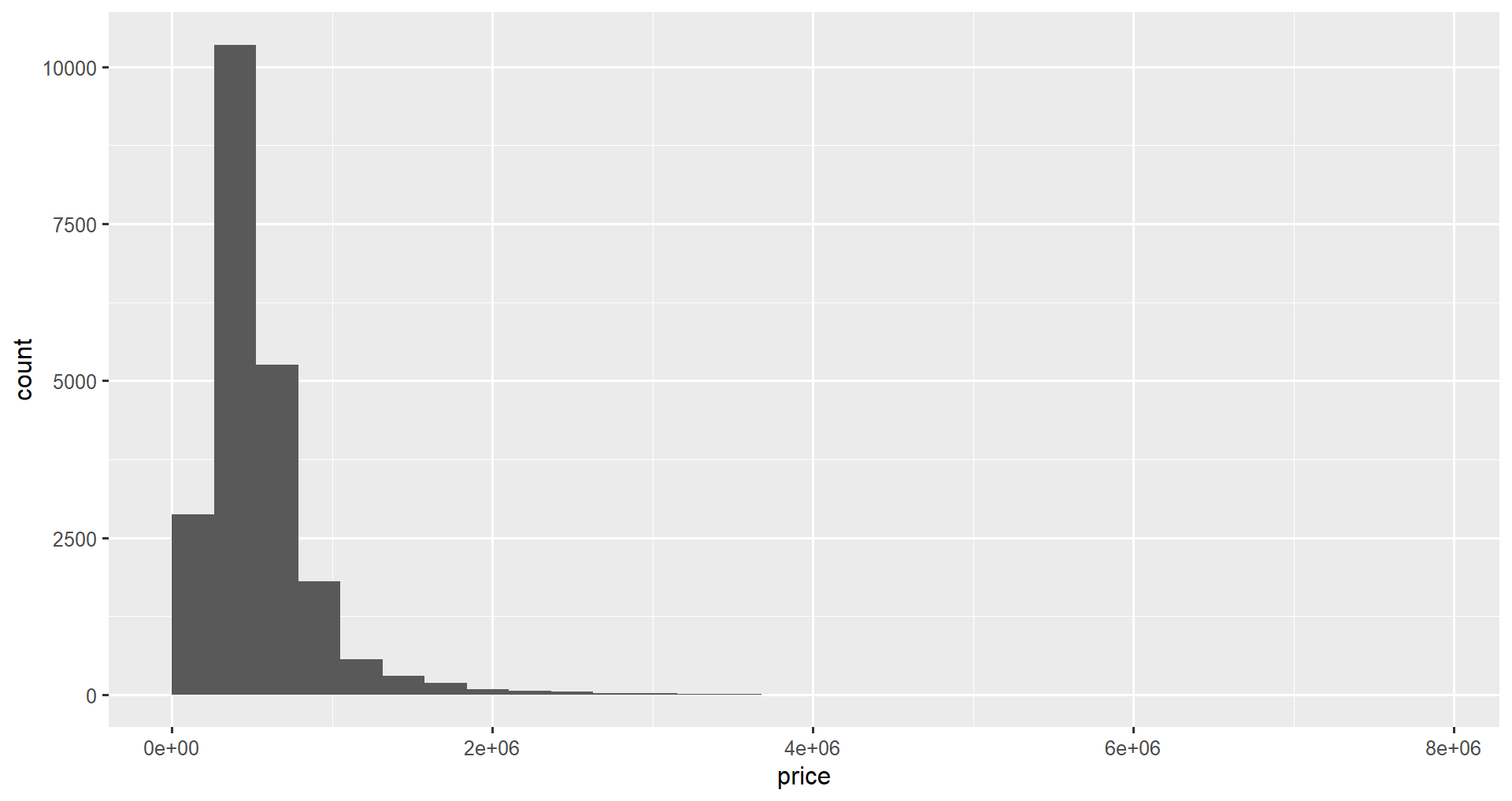
Dans cette section, nous allons modifier les couleurs de l'histogramme. Nous pouvons personnaliser la couleur des contours de chaque barre à l'aide de l'attribut color, et nous pouvons modifier le remplissage des barres à l'aide de l'attribut fill de geom_histogram(). Nous allons remplir les barres de bleu et changer la couleur du contour en blanc.
ggplot(data = home_data, aes(x = price)) +
geom_histogram(color = "white", fill = "blue")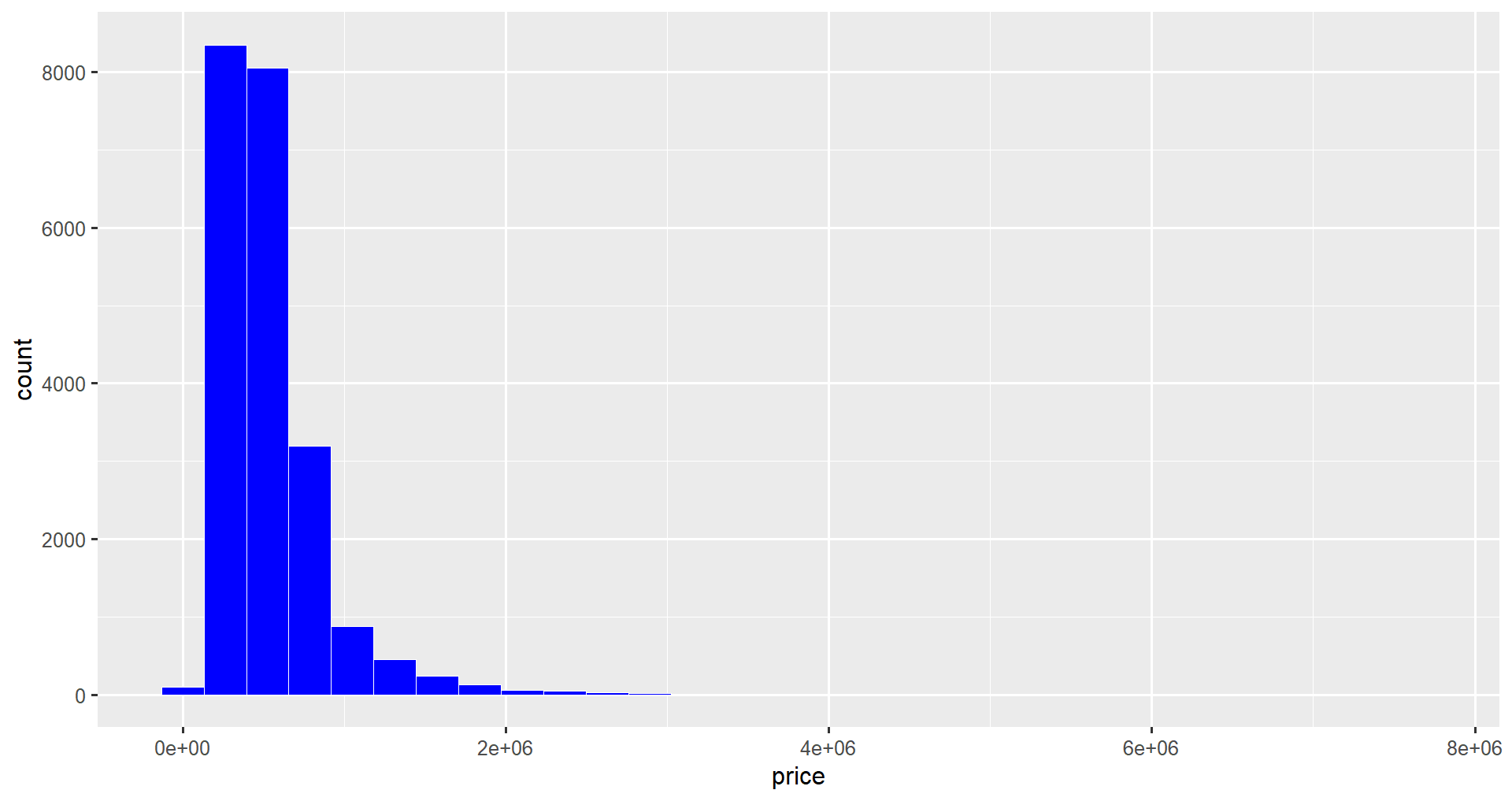
Vous pouvez personnaliser les couleurs des barres de l'histogramme.
La modification de l'esthétique de fill (à l'intérieur de aes() la fonction) changera les couleurs intérieures des barres en fonction de la valeur d'une variable dans l'ensemble de données. Cette variable devrait être catégorique (un facteur) plutôt que des nombres entiers, nous pouvons donc la convertir à l'aide de la fonction factor(). Pour cet exemple, nous nous intéresserons à la variable condition, une valeur allant de 1 (mauvais état) à 5 (excellent état).
home_data <- home_data |>
mutate(condition = factor(condition))
ggplot(data = home_data, aes(x = price, fill = condition)) +
geom_histogram()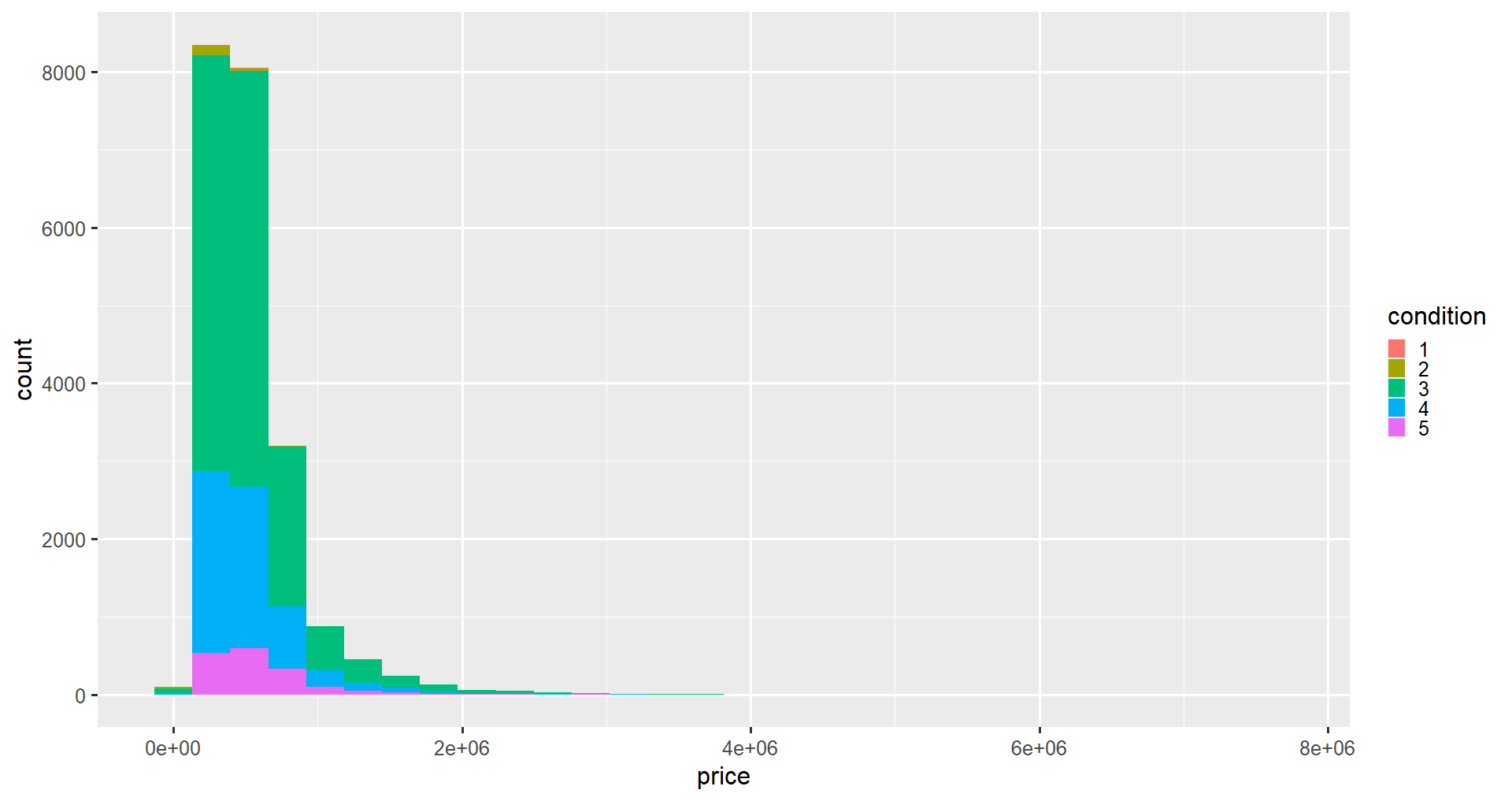
Ensuite, nous ajoutons des titres et des étiquettes à notre graphique à l'aide de la fonction labs(). Nous définissons les attributs x, y et title sur les étiquettes souhaitées.
ggplot(data = home_data, aes(x = price)) +
geom_histogram() +
labs(x ='Price (USD)', y='Number of Listings', title = 'Housing Price Distributions')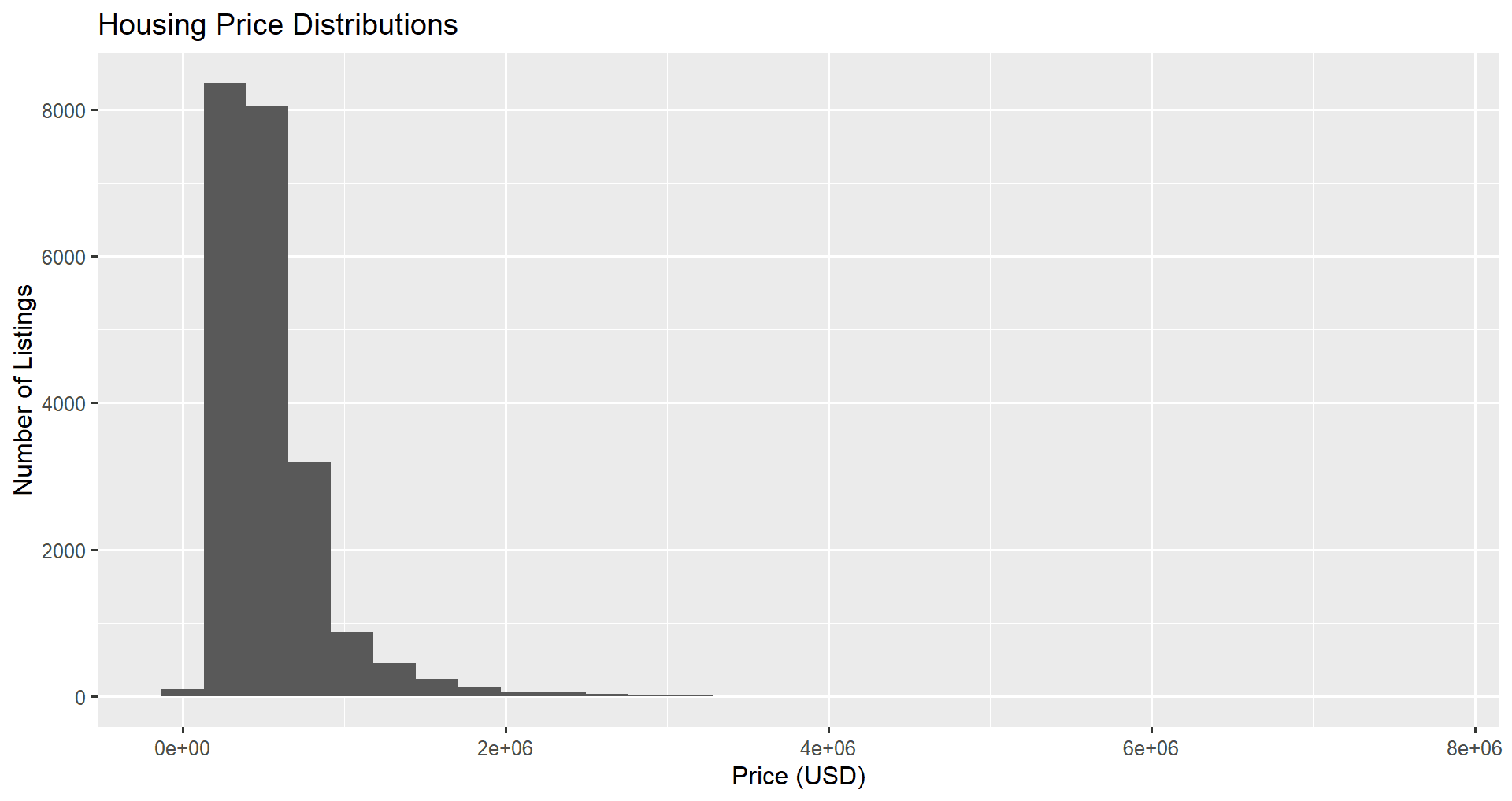
Nous pouvons définir les limites de l'axe x de notre graphique en utilisant la fonction xlim() pour zoomer sur les données qui nous intéressent. Par exemple, il est parfois utile de se concentrer sur la partie centrale de la distribution plutôt que sur la longue queue que l'on voit actuellement lorsque l'on regarde l'ensemble du graphique.
Il est également possible de modifier les limites de l'axe des ordonnées (en utilisant ylim()), mais cela est moins utile pour les histogrammes car les valeurs calculées automatiquement sont presque toujours idéales.
Nous nous concentrerons sur les prix compris entre 0 et 2 millions de dollars.
ggplot(home_data, aes(x = price)) +
geom_histogram(bins = 100) +
xlim(0, 2000000)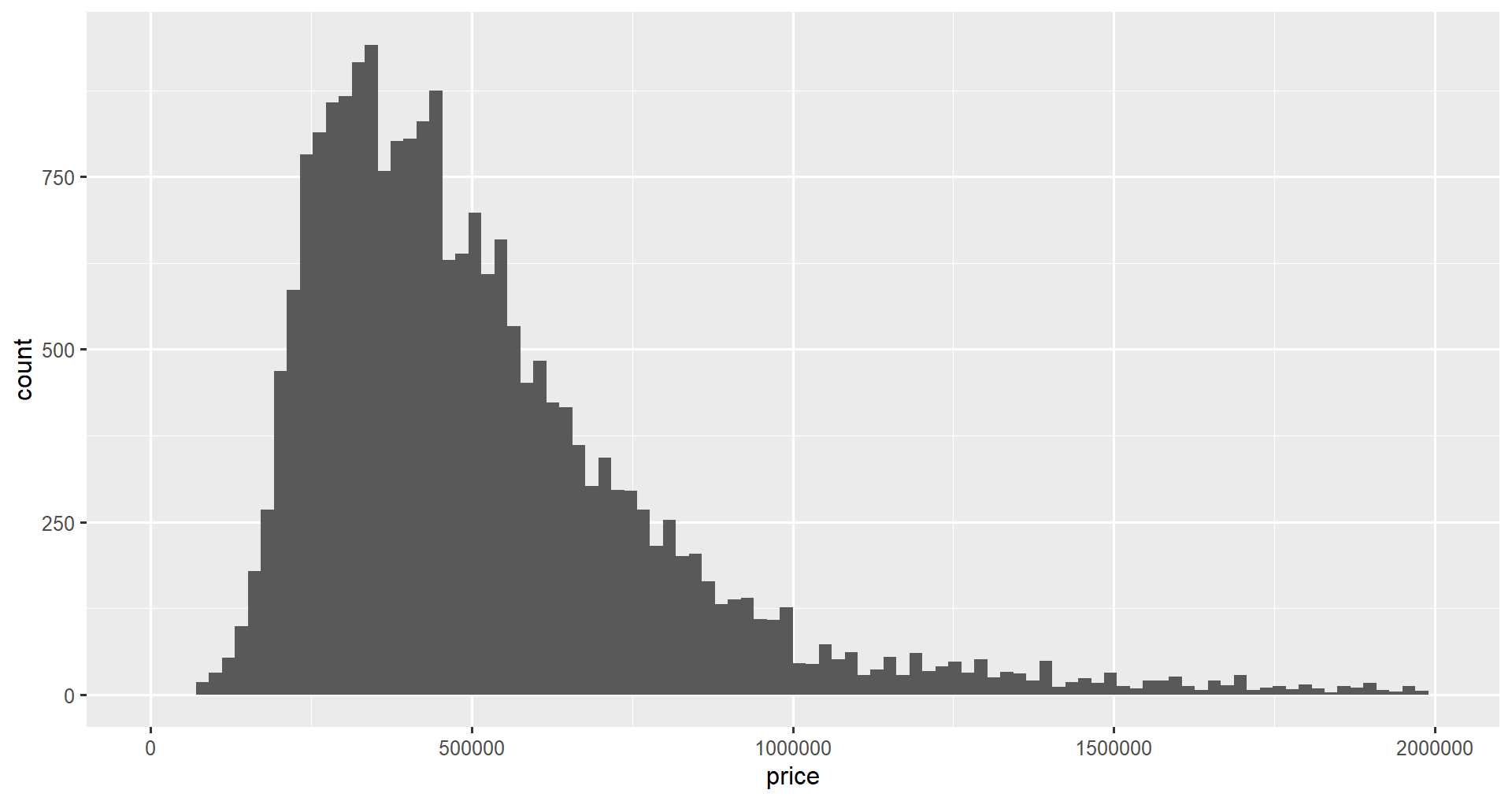
Si vous souhaitez déplacer la légende de votre graphique, par exemple lorsque vous visualisez la condition en différentes couleurs, vous pouvez utiliser la fonction theme() et l'attribut legend.position. Les valeurs prises par legend.position sont “bottom”, “top”, “right” ou “bottom”. Vous pouvez également transmettre les coordonnées de la légende à l'aide de c(x, y).
ggplot(home_data, aes(x = price, fill = condition)) +
geom_histogram() +
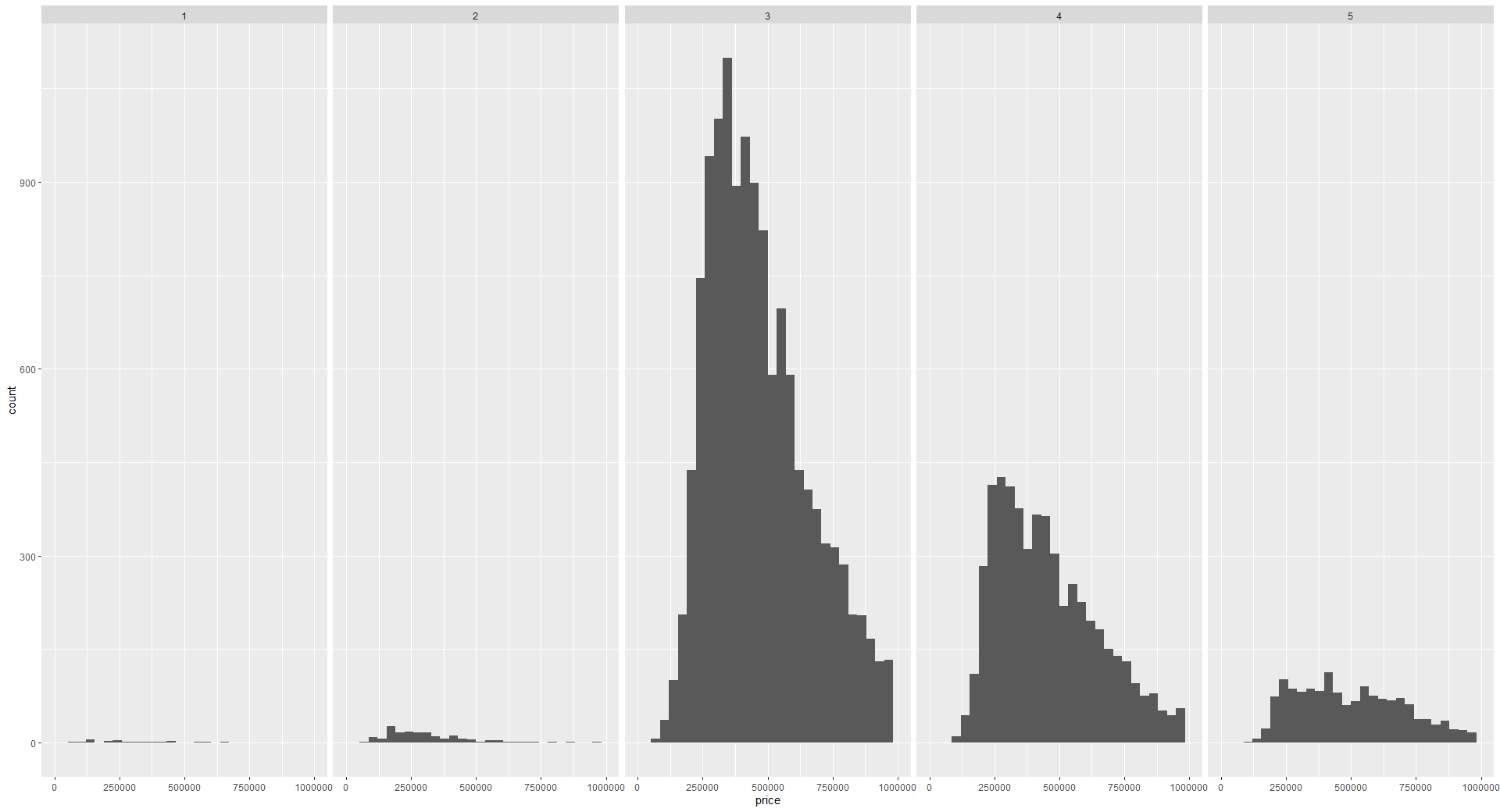
theme(legend.position = "bottom")Enfin, nous pouvons visualiser les données de différents groupes dans des graphiques distincts à l'aide de facettes. Cette opération permet de diviser la visualisation en plusieurs sous-graphes pour chaque catégorie. Vous pouvez le faire en utilisant la fonction facet_grid(). Nous allons visualiser ci-dessous la distribution des prix en fonction des différentes valeurs de condition.
ggplot(home_data, aes(x = price)) +
geom_histogram() + facet_grid(vars(condition))Les facettes sont traitées plus en détail dans le tutoriel Facets for ggplot in R.
Pour créer un histogramme dans ggplot2, vous commencez par construire la base avec la fonction ggplot() et les paramètres data et aes(). Vous ajoutez ensuite les couches du graphique, en commençant par le type de fonction du graphique. Pour un histogramme, vous utilisez la fonction geom_histogram(). Vous pouvez ensuite ajouter d'autres couches de personnalisation telles que labs() pour les titres des axes et du graphique, xlim() et ylim() pour définir les plages des axes, et theme() pour déplacer la légende et apporter d'autres personnalisations visuelles au graphique.
ggplot2 facilite la création de visualisations en R. Vous pouvez créer des graphiques simples ou plus complexes, tout en vous appuyant sur la même syntaxe additive simple. Il s'agit de la bibliothèque de graphiques la plus populaire de R.
ggplot2 est traité en profondeur dans le cursus Visualisation de données en R, en commençant par Introduction à la visualisation de données avec ggplot2. Vous pouvez apprendre à combiner les visualisations de données ggplot2 avec d'autres outils Tidyverse dans le cursus Tidyverse Fundamentals with R. Pour une référence pratique sur tout ce que vous venez d'apprendre, téléchargez une copie de l'aide-mémoire ggplot2.
En savoir plus sur R
Cours
Cours
Cours
blog
Kurtis Pykes
15 min
Tutoriel
DataCamp Team
Tutoriel
Aditya Sharma
Tutoriel
Sejal Jaiswal
Tutoriel
Aditya Sharma
Tutoriel
Laiba Siddiqui
